进程(三)------进程切换、O (1) 调度、环境变量、命令行参数
文章目录
- [进程(三)------进程切换、O (1) 调度、环境变量、命令行参数](#进程(三)——进程切换、O (1) 调度、环境变量、命令行参数)
-
- 一、底层内存基础
- 二、Linux是怎么管理进程的
- [三、O (1) 调度器原理](#三、O (1) 调度器原理)
-
- [1、 优先级数组:queue140](#1、 优先级数组:queue[140])
- [2、 位图bitmap5:快速检索工具](#2、 位图bitmap[5]:快速检索工具)
- [3、 调度的公平优化:活跃和过期队列](#3、 调度的公平优化:活跃和过期队列)
- [4、 进程完整调度流程](#4、 进程完整调度流程)
- [5、 O(1)调度器原理通俗解](#5、 O(1)调度器原理通俗解)
-
- [(1) 医院有140个诊室------对应内核queue140](#(1) 医院有140个诊室——对应内核queue[140])
- [(2) 医生的"大黑板"------对应内核 bitmap](#(2) 医生的“大黑板”——对应内核 bitmap)
- [(3) 医生的操作------对应内核调度器的工作](#(3) 医生的操作——对应内核调度器的工作)
- 四、环境变量
-
- [1、 运行程序为什么要加./?](#1、 运行程序为什么要加./?)
- [2、 什么是环境变量?](#2、 什么是环境变量?)
-
- [(1) 环境变量的本质](#(1) 环境变量的本质)
- [(2) 常见的环境变量](#(2) 常见的环境变量)
- [(3) 查看环境变量的常用命令](#(3) 查看环境变量的常用命令)
- [(4) 环境变量的组织方式:内存里的表](#(4) 环境变量的组织方式:内存里的表)
- 五、main函数的隐藏技能------命令行参数
-
- [1、 argc和argv](#1、 argc和argv)
-
- [(1) argc:参数个数](#(1) argc:参数个数)
- [(2) argv:参数数组](#(2) argv:参数数组)
- [2、 为什么需要命令行参数](#2、 为什么需要命令行参数)
- 六、在C语言中怎么获取环境变量
-
- [1、main函数的第三个参数char *env\[\]](#1、main函数的第三个参数char *env[])
- [2、全局变量char **environ](#2、全局变量char **environ)
- [3、 最常用的getenv()函数](#3、 最常用的getenv()函数)
- 七、环境变量VS本地变量有啥区别
-
- [1、 本地变量(Shell变量)](#1、 本地变量(Shell变量))
- 2、环境变量
- [3、 环境变量的全局属性:可以被子进程继承](#3、 环境变量的全局属性:可以被子进程继承)
- 4、我们打开shell登录用户的过程,就是配环境的过程
一、底层内存基础
1、多字节变量的地址规则
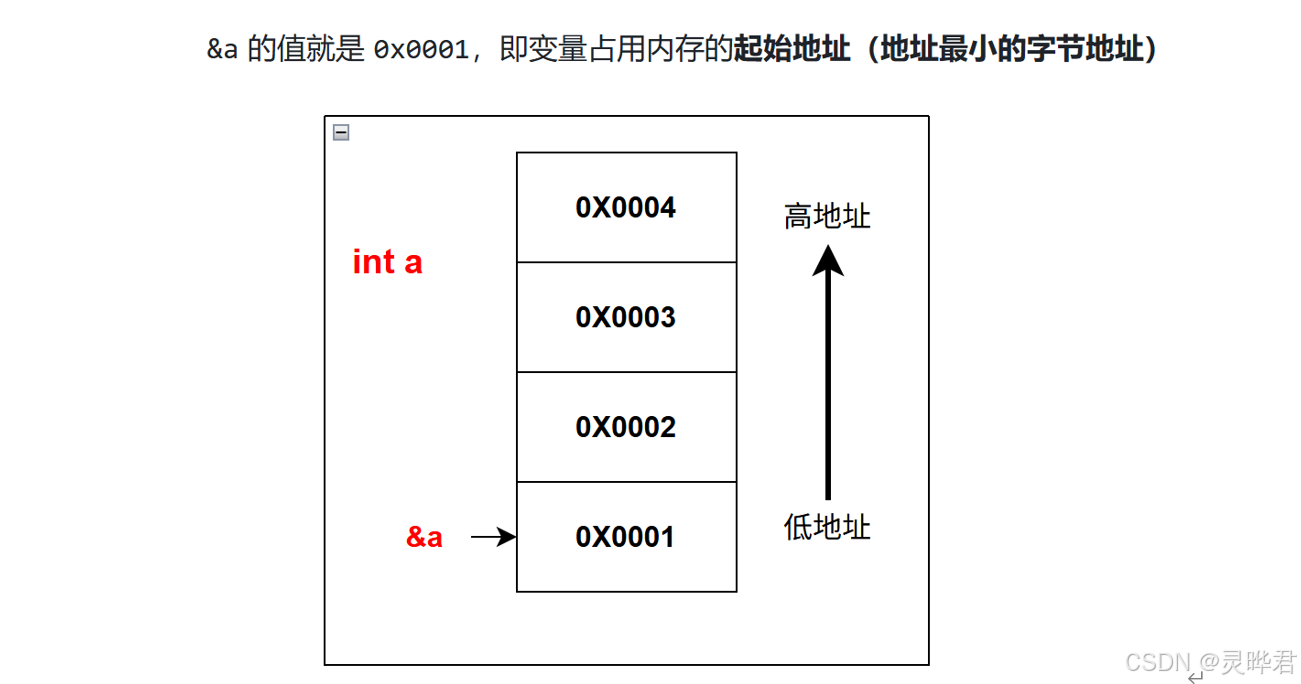
在C语言中,int 类型有4个字节,每个字节在内存中都有独立地址,明明有4个地址但我们通过取地址符&获取变量地址时,只会返回一个地址,返回的是哪个地址呢?
- C 语言规定:任何变量、数组、结构体的地址 ,只取它所占用所有字节中地址数值最小的那一个字节的地址
- 内存存储顺序 :数据永远从低地址向高地址顺序存放
- 所以:
&a 取的是 4 个字节里最开头、地址最小的那个字节
数组名 = 数组首元素地址 (同样取最小地址)
结构体变量地址 = 结构体第一个成员的起始地址
2、结构体偏移量
如果你只知道成员 c 的地址 &c,怎么算出整个 struct A 变量的起始地址?
c
struct A {
int a;
int b;
int c;
double d;
};- 结构体每个成员,距离结构体起始位置,都有一个固定距离,这个距离就叫偏移量
- 结构体起始地址 = 已知成员地址 - 该成员的偏移量
- 用成员c的地址 - 偏移量 就能得到结构体的起始地址 。而内核container_of 宏也是这个原理
二、Linux是怎么管理进程的
我们都知道task_struct包含了进程的所有属性,所以管理进程也就转变成管理task_struct
1、Linux内核的"神奇链表"
如果按照传统的双向链表结构,给每个task_struct 都写一套 next/prev 指针,那每个结构体都要重复写链表逻辑,维护起来很麻烦
为了提高效率,Linux设计了一个解耦式通用的链表结构体struct list_head
c
struct list_head {
struct list_head *next;
struct list_head *prev;
};它只包含 next 和 prev 指针 ,不存任何数据,可以嵌入到任何结构体里
把struct list_head tasks嵌入 task_struct ,所有进程通过这个 tasks 成员串成链表
c
struct task_struct {
// 进程的所有属性...
struct list_head tasks; // 嵌入的链表节点
};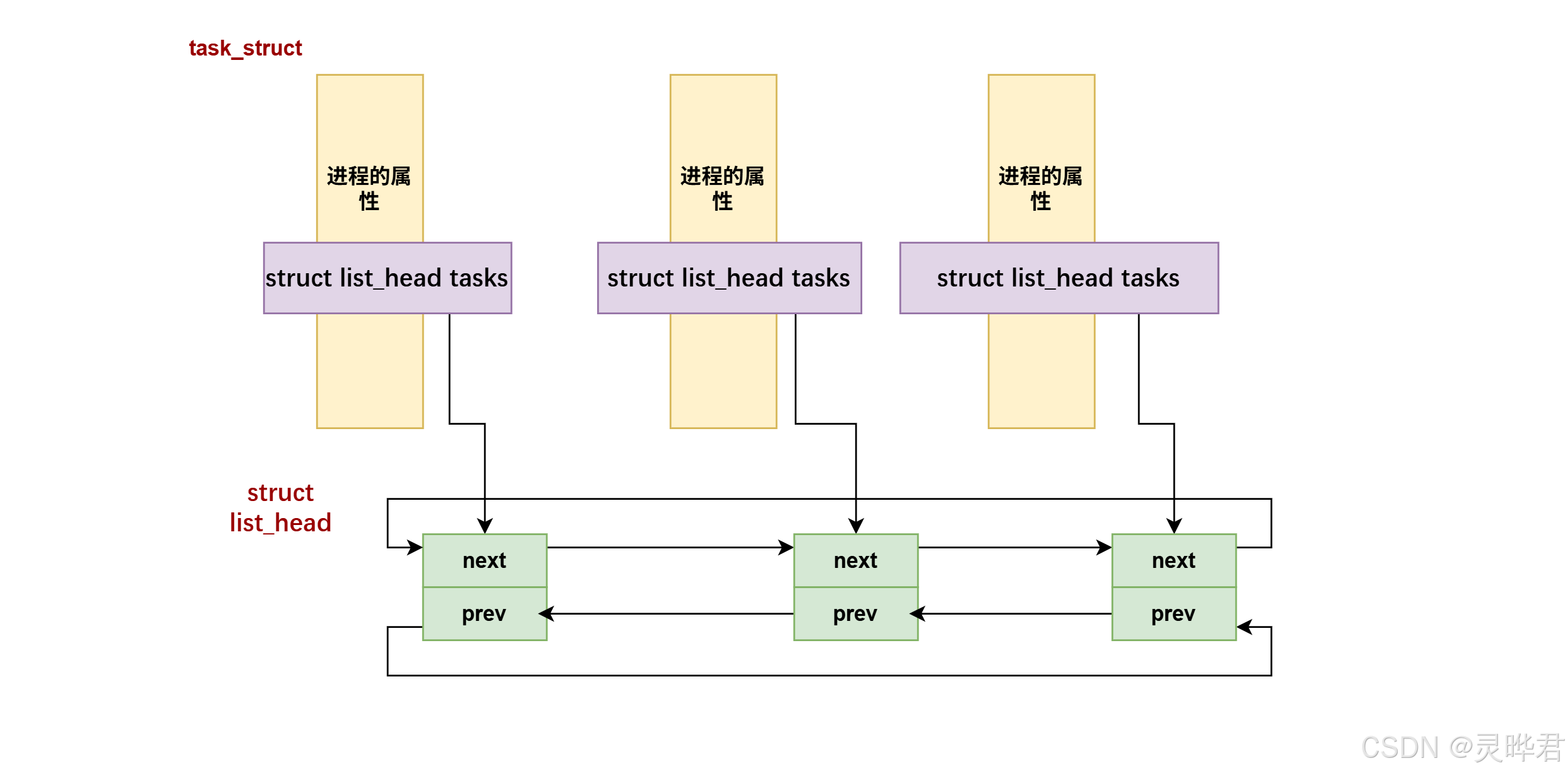
通用链表怎么串起系统所有进程?
- 每个 task_struct 里都嵌入一个 struct list_head 节点
- 所有进程靠这个内嵌节点互相连成双向循环链表
- 遍历链表拿到的只是 struct list_head* 指针
- 再用结构体偏移量原理,节点地址 减去 它在task_struct 里的偏移量 ,直接反推出整个 task_struct 起始地址
- 从而拿到任意进程完整信息,访问 PID、状态、优先级等所有进程数据
2、Linux进程全局管理机制
我们来重新梳理一下:
- 系统每创建一个进程,内核就会分配一个task_struct结构体,结构体存储进程所有核心信息:PID、父进程ID、进程状态、优先级、寄存器上下文、内存映射信息等
- Linux将所有不同状态的进程,通过内嵌通用链表节点,串联成一张全局双向循环链表 。这张链表就像进程的花名册,保证内核可以搜索到任意一个进程
你可能会有疑惑 ,既然所有进程都在全局双链表中,进程是如何变成运行/阻塞状态呢 ?
- 全局双向链表,是进程创建就会被永久挂在这里的
- 每个进程的task_struct 里自带好几个 list_head 链表节点,不是只有一个。
- 当进程想要进入运行态时,内核把它其中一个 list_head 节点,挂到 CPU 的 runqueue 运行队列链表上 ,同时给进程标记为运行状态
- 当进程要进入阻塞状态时,内核把这个 list_head 节点从运行队列摘下来 ,重新挂到阻塞 / 等待队列的链表上 ,同时把进程状态改成阻塞态
- 全局链表负责全进程登记,状态队列负责按运行状态调度排队;进程状态切换无需迁移 task_struct 本身,仅通过内嵌链表节点完成跨队列挂靠即可实现
三、O (1) 调度器原理
O(1)调度,不管系统里有10个进程,还是10000个进程,内核找下一个要运行的进程,永远只需要1步,速度不会随进程数量变缓
每一个CPU都有一个独立运行队列runqueue,runqueue是一个大结构体
1、 优先级数组:queue140
- 运行队列中包含优先级数组queue140
- 数组下标范围为 0~139,对应140个优先级,其中0 ~ 89 是实时进程,普通程序不参与。我们普通分时进程进程 + nice 值,只在 90 ~ 139 这个区间里生效
- 下标数值越小,进程优先级越高
- 每个数组下标都挂着一条链表,所有同优先级的进程,都在这条链表上排队,遵循FIFO先进先出的规则
- 优先级数字就是数组下标,查找时直接用优先级当下标,一步定位队列 ------进程筛选过程本质是哈希定位,通过下标直接锁定优先级队列,不需要遍历全部进程
2、 位图bitmap5:快速检索工具
- 不用遍历140个队列,看一眼bitmap,就知道哪些优先级有进程
- 位图用于标记优先级队列状态 ,每一个二进制位对应一条优先级队列
位值为1 :当前优先级队列存在就绪进程
位值为0 :当前优先级队列为空 - 调度的时候,内核直接查找位图最左侧为1的二进制位,最快锁定最高优先级,大大优化了检索效率
调度器的核心工作
1. 查看bitmap,找到编号最小、有进程的优先级
2. 定位到queue数组对应的队列
3. 取出队首进程,分配CPU时间片,让它运行
3、 调度的公平优化:活跃和过期队列
-
内核划分两类队列:活跃队列和过期队列
-
活跃队列存放时间片还没有耗尽的进程,该队列的进程允许使用CPU
过期队列存放时间片耗尽的进程,暂时无法使用CPU -
调度规则是这样的 :
进程刚创建时,按照优先级直接插入活跃队列
活跃队列中的进程时间片耗尽后,会被移入过期队列
当活跃队列为空时,内核直接交换active 和 expired 队列的指针 ,不需要移动进程数据
原过期队列变为新的活跃队列,其中的进程将参与下一轮调度,获得执行机会。 -
活跃/过期队列能保证同等优先级进程,公平的使用 CPU
-
如果系统内低优先级进程(如优先级61)持续运行,不断有高优先级进程(如优先级60)插入,低优先级进程会长期抢占不到CPU资源,造成进程饥饿
-
如果优先级61在活跃队列中持续运行,优先级60却不断被创建,这些高优先级会直接插入活跃队列,优先被调度
只要不断有更高优先级进程进来,低优先级就是永远抢不到 CPU,照样饿死。 -
活跃 + 过期队列 并不能阻止高优先级一直插队 。它只能保证同优先级是公平的,
CFS 调度器 才真正解决低优先级饿死
4、 进程完整调度流程
-
进程创建:系统启动一个程序,内核为它创建 task_struct 结构体,接入全局双向链表完成系统登记
-
入队分类:根据进程的优先级,把它放进对应CPU运行队列(每个CPU有自己的运行队列)的优先级链表
-
检索进程:内核扫描bitmap位图,快速找到最高优先级的非空队列
-
CPU执行:遵循FIFO规则取出队首进程,分配CPU时间片运行;
-
队列转移:进程用完时间片后,被移出活跃队列,放进过期队列
-
队列轮换:当活跃队列为空时,内核交换活跃、过期队列的指针,开启新一轮调度,低优先级进程获得执行机会
5、 O(1)调度器原理通俗解
医院看病:
(1) 医院有140个诊室------对应内核queue140
- 内核里有一个 queue140 数组,就像医院有140个诊室,每个诊室对应一个"优先级"
- 数组下标从0到139,下标数字越小,优先级越高,就像0号诊室是急诊室,优先级最高
- 每个诊室里,都排着一队"同优先级的病人"(对应内核里,每个下标下挂着一条链表,存放所有同优先级的进程)
- 这就是内核的"优先级队列"设计:每个优先级一个队列,不用混在一起排队
(2) 医生的"大黑板"------对应内核 bitmap
- 如果医生一个个诊室去看"有没有病人",太慢了!所以医院放了一块大黑板,上面只写一句话:"哪些诊室有人在排队"。内核里的bitmap5,就相当于这块大黑板
- bitmap 是一块"快速查询表",每一个二进制位对应一个优先级队列
位值为1 :对应优先级的队列里有进程在等待(诊室里有病人 )
位值为0 :对应优先级的队列为空(诊室里没人) - 医生看一眼黑板,就知道哪些诊室有人;内核看一眼bitmap(,就知道哪些优先级有进程,不用一个个遍历,速度超快
(3) 医生的操作------对应内核调度器的工作
医生不用纠结,只做两件事,内核调度器也一样:
- 看黑板(bitmap),找到"数字最小的诊室"(最高优先级的非空队列)
- 去那个诊室,叫第一个病人(从对应队列里取出队首进程,让它上CPU运行)
这就是O(1)调度的核心:不管有多少病人(进程),医生(调度器)永远只需要2步,就能找到下一个要接诊的病人,效率不变
四、环境变量
当我们编译运行某个程序时,如果直接敲下程序名 (test1),系统就会报错 ,如果加上./ (./test1),就能正常的运行
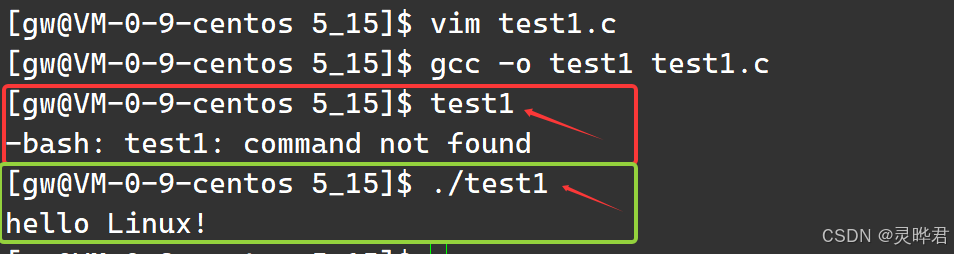
这背后的关键,就是PATH环境变量!
为了叙事方便这里先提一嘴:PATH是一种环境变量,存放着可执行程序的目录列表
1、 运行程序为什么要加./?
(1)./是什么?
./ 是相对路径,它明确告诉操作系统:我要执行的这个可执行文件,就在当前目录下,直接在这里找!
(2)如果不加./,Linux怎么找程序?
当我们输入mycommand,或者ls、pwd之类系统命令时,Linux不会在当前目录瞎找,而是先判断命令类型,再决定是否去PATH里查找
输入不带路径的指令
-
Shell是一个应用程序 ,是把输入的命令转化为内核能看得懂的翻译官 ,bash是shell的一种。如果shell是翻译官这个职业,bash就是某一个具体的翻译官,
-
Shell会先做第一步判断:这个命令是不是Shell内置命令?
如果是内置命令 (比如cd、echo、export):PATH不走查找,也不创建子进程,直接在当前bash进程内部执行
如果不是内置命令 (比如ls、pwd、gcc,以及你自己写的mycommand):判定为外部可执行程序,此时才会PATH严格遍历里记录的所有路径,挨个查找同名可执行文件 -
遍历规则 :按PATH中路径的顺序依次查找,找到就创建子进程运行,全部遍历完没找到,就会报command not found
我们可以先查看PATH的值 ,看看它的路径列表
这些冒号 : 就是路径分隔符,把 PATH 环境变量里的多个路径分开了

输入带./的指令
./相当于给系统"明确指令":指定当前工作目录。此时系统PATH不再查询 ,直接在当前目录查找对应的可执行文件,找到后直接创建子进程运行
(3)自己写的程序不加./怎么运行
还是我们上面编译的test1程序,把当前路径加入PATH,export PATH=$PATH:. 此时直接运行test1,运行成功
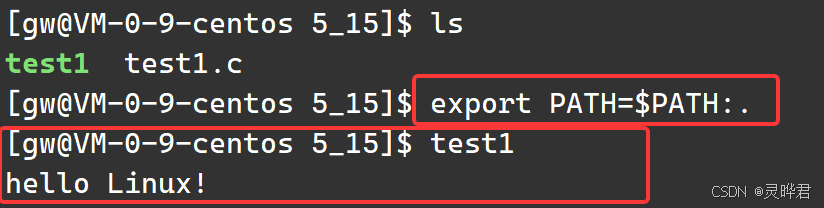
此时再查看PATH的具体路径 ,能看到当前路径已经被添加进去 ,不加./输入命令,会去PATH查找,发现就返回

把路径加到PATH会造成临时 "污染", 但只污染当前终端,终端关掉就消失了,对系统完全无害、永久无影响
Windows里的PATH环境变量和Linux的PATH作用完全一样 ,Java、Python安装时要求配置环境变量,本质就是把它们的bin目录加到Path里,让系统能找到对应的外部命令程序
2、 什么是环境变量?
环境变量,一般是指在操作系统中用来指定操作系统运行环境的一些参数
如:我们在编写C/C+++代码的时候,在链接的时候,从来不知道我们链接的动态静态库在哪里,但是照样能链接成功,生成可执行程序,原因就是有相关环境变量帮助编译器进行查找。
(1) 环境变量的本质
-
环境变量是键值对 ,名字=值(也像目录一样,名字就是路径,比如PATH=/usr/bin)
-
它是全局配置的,整个系统,所有程序都能看得到 ;它对所有的子进程都可见,就包括我们运行外部命令时创建的子进程(比如运行 ls 时,bash 会创建子进程执行 ls 程序)
-
这里的子进程,就是你在 bash 里运行的所有外部程序,比如 ls、gcc、你自己写的test程序
-
你打开的终端,本身就是一个 bash 进程 (我们叫它父进程)
在 bash 里运行的 ls,会被 bash 创建成一个独立的进程(就是 bash 的子进程) -
那么环境变量有什么用呢?
我们运行自己写的程序时,得先进到对应的目录下才能找到并运行 。
ls也是外部 ,PATH环境变量存放了一堆命令存放路径,我们运行ls这类外部命令时,就不需要写完整路径了,子进程靠着PATH自动搜索到程序位置
环境变量提前存好 系统、程序运行要用的各自配置信息,不用每次运行程序都手动设置,方便快速查找文件命令
(2) 常见的环境变量
- PATH ------命令的搜索路径,决定系统去哪里找可执行程序(仅针对外部命令)
- HOME ------当前用户的主目录,比如/home/gw,~符号就代表这个路径
- SHELL ------当前使用的Shell,通常是/bin/bash
- USER ------当前登录的用户名
- PWD ------当前工作目录
可以用echo $变量名就可以查看单个变量的值
(3) 查看环境变量的常用命令
Linux提供了多个命令来查看和操作环境变量 ,其中部分命令是Shell内置命令(不走PATH) ,部分是外部命令(走PATH),我们一个一个来看
- 内置命令(不走 PATH) :命令本身是bash自带的功能 ,不是磁盘上的独立程序,不创建子进程,不走PATH查找,直接在当前 Shell 里执行,速度比外部命令快
- 外部命令(走 PATH) :是磁盘上的独立二进制程序 (比如/usr/bin/env),Shell 要创建子进程去运行它,会依赖PATH环境变量查找路径
我们平时使用命令的时候并不觉得它们有什么区别,但是敲evn、ls这张外部命令,shell会先去PATH 里找这些程序的路径 (比如 /usr/bin/env、/usr/bin/ls),找到后创建子进程运行 。但因为PATH 里早就配置好了 /usr/bin 这些常用目录 ,系统找到程序、创建子进程的过程是毫秒级的 ,执行完子进程立刻退出,Shell 再回到交互状态。所以我们感受不到"创建了子进程""走了 PATH 查找",就像一个普通命令一样瞬间执行完了
**1. echo NAME(内置命令)** **作用** :**查看单个环境变量 / Shell 变量的值** **既可以看环境变量,也可以看本地变量**(比如你直接定义的MYENV=hello,用echo MYENV也能看到)

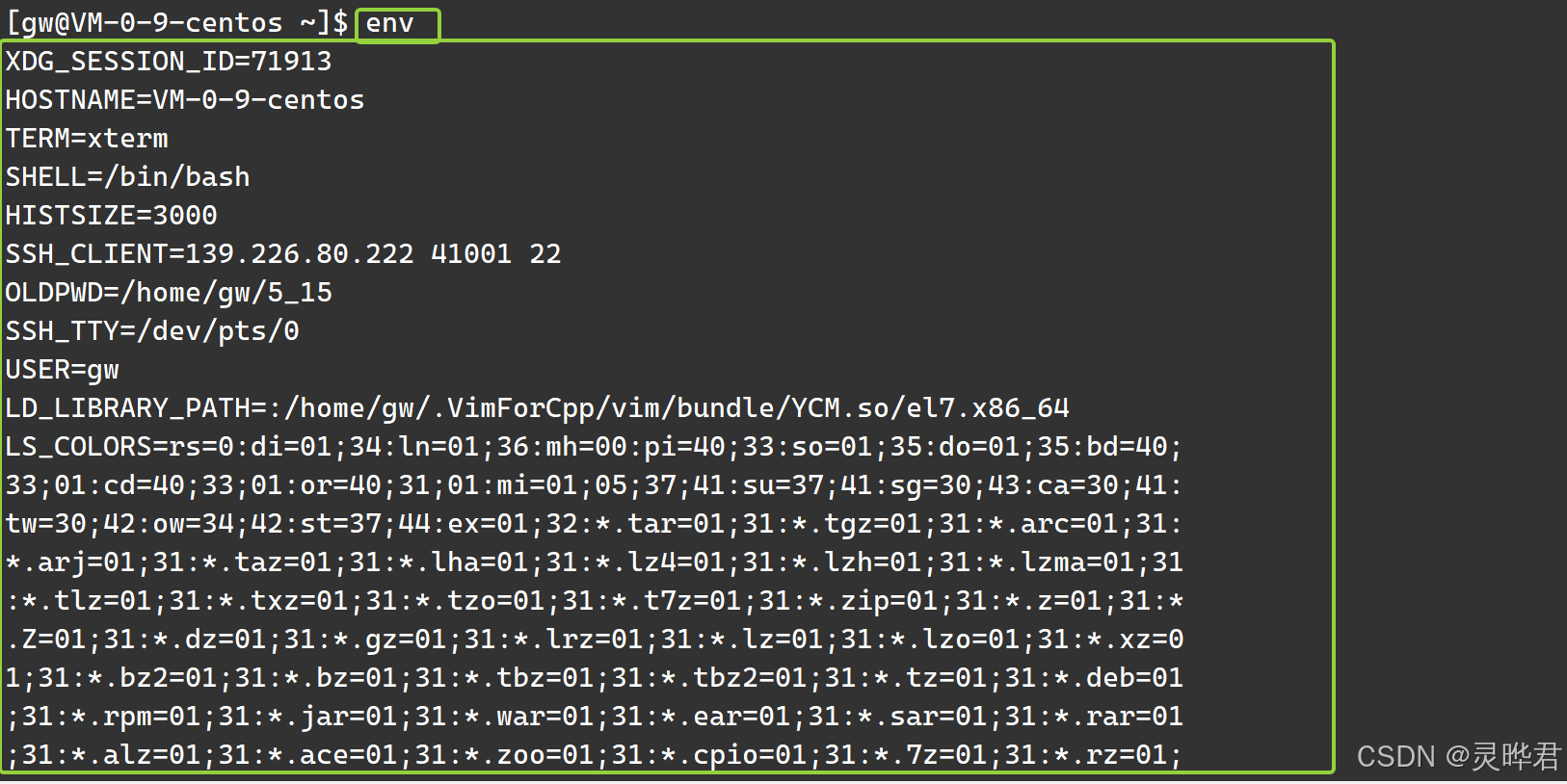
2. env(外部命令)
作用:显示所有环境变量 (只显示能被子进程继承的变量,不显示本地变量)
它是外部命令,运行时会创建子进程,所以它只能看到环境变量 ,看不到你当前 Shell 里的本地变量
还可以用它临时设置环境变量运行程序,比如env MYENV=hello ./test,只在这个子进程里生效
3. export(内置命令)
把本地变量升级为环境变量,让它能被子进程继承
直接敲export不带参数,也会显示所有环境变量,和env的输出类似,但它是内置命令,不创建子进程
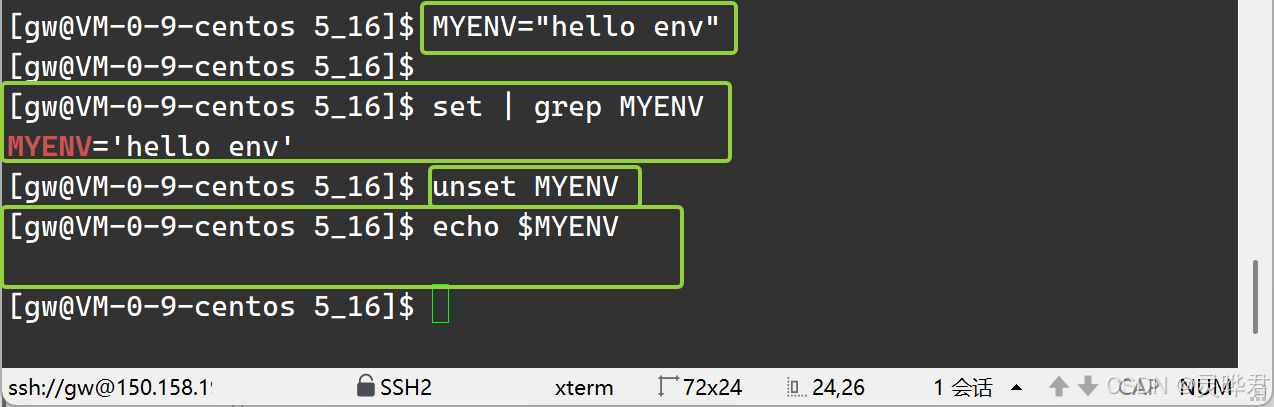
4. unset(内置命令)
作用:删除 Shell 变量(不管是本地变量还是环境变量都能删)
删的时候不用加$,直接写变量名就行
5. set(内置命令)
作用:显示所有 Shell 变量,包括本地变量 + 环境变量 + Shell 自带变量 (比如PS1命令提示符变量)
(4) 环境变量的组织方式:内存里的表
环境变量在内存中是以字符串数组的形式 组织的,每个元素都是一个"KEY=VALUE"格式(也就是前面说的键值对)的字符串,比如"PATH=/usr/bin:/bin"
数组的最后一个元素是NULL ,作为结束标记
这个数组的地址,由全局变量environ指向
简单理解就是 :
environ → "HOME=/home/whb", "PATH=/usr/bin:/bin", "SHELL=/bin/bash", ..., NULL
而我们运行外部命令时,Shell会把这个环境变量数组,完整传递给创建的子进程,所以子进程也能获取到系统的环境配置
五、main函数的隐藏技能------命令行参数
我们平时写的main函数,大多是简化版int main(),但它其实有完整形态,能直接接收我们在命令行输入的参数。和环境变量一样,都是程序启动时获取外部信息的重要方式
1、 argc和argv
main函数其实能接收参数
c
int main(int argc, char *argv[])(1) argc:参数个数
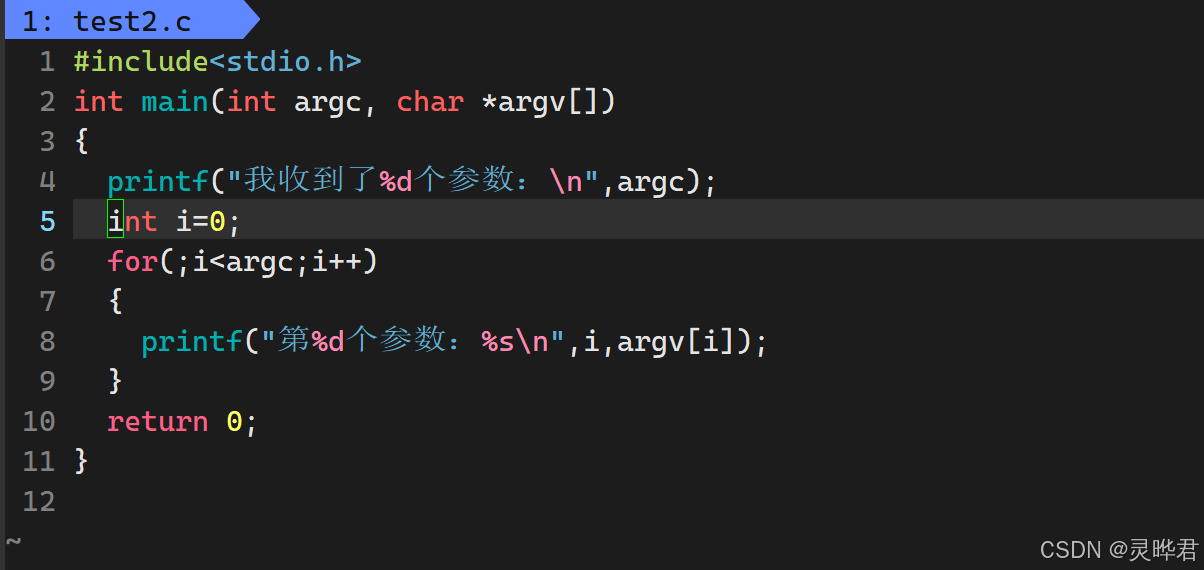
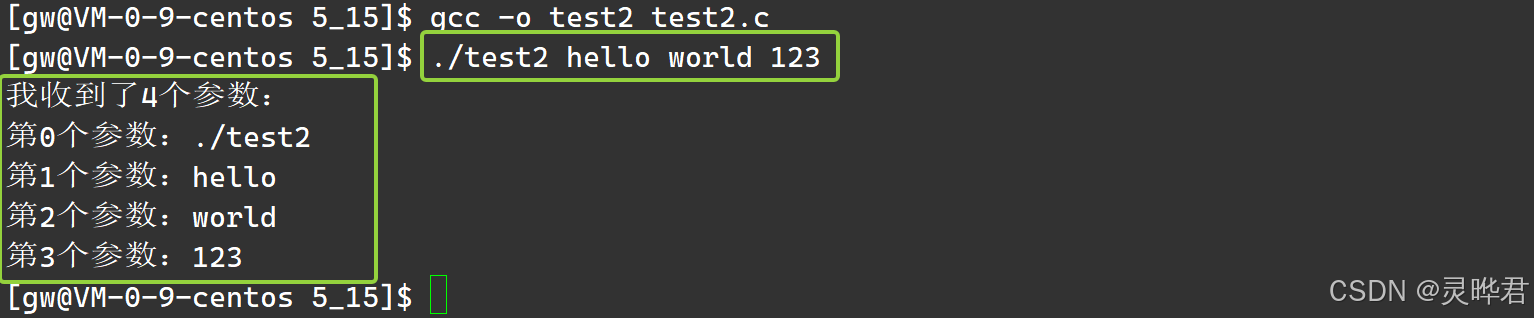
argc(argument count) ------参数个数 ,就是你输入的命令里,用空格隔开的所有"单词"的数量 ,必须包括程序名本身。
举个例子:输入./test hello world,这里的"单词"有 ./test(程序名)、hello、world,一共3个,所以argc = 3 。哪怕你只输入./test不带任何参数,argc也至少是1(只有程序名)
(2) argv:参数数组
argv(argument vector)------参数数组 ,它是一个字符串数组,会把你输入的每个"单词"依次存起来,最后以NULL结尾 (和环境变量的env数组一样)
还是用./test hello world举例,数组里的内容就是:
argv0 → "./test"(程序名,永远是第一个元素)
argv1 → "hello"(第一个参数)
argv2 → "world"(第二个参数)
argv3 → NULL(结束标记)
我们写个程序来直观看看参数的传递效果
可是程序的逻辑不都写在代码里了吗?为什么还要从命令行传东西?
2、 为什么需要命令行参数
它就是给程序加一个 "外部开关",核心作用就是:让一个程序,能根据不同的输入,实现不同的功能------这也是Linux命令选项的实现原理!
我们常用的命令就是数组来获取我们输入了什么指令
比如我们常用的ls指令:
- 输入ls(无参数):只列出当前目录的文件名
- 输入ls -l(带参数-l):列出文件的详细信息
- 输入ls -a(带参数-a):列出隐藏文件
刚开始我还以为这是3个不同的程序,但实际上,这三个命令,用的是同一个 /usr/bin/ls 程序 !只是给它传了不同的命令行参数,它就执行了不同的代码分支
它的逻辑是这样的:
- ls 程序启动时,会把你输入的所有东西(ls、-l、-a)解析成 argv 数组
- 程序读取 argv1 的值 :
如果是 -l → 走 "打印详细信息" 的代码分支
如果是 -a → 走 "显示隐藏文件" 的代码分支
如果啥都没传 → 走 "只打印文件名" 的默认分支 - 这就是命令行参数的意义:一个程序,多种玩法,全靠 argv 控制
- 小细节:所有参数都是字符串:哪怕你输入的是数字123,argv里存的也是字符串"123",如果需要用数字计算,得用atoi()函数转成整数
- argvargc == NULL:数组最后一个元素永远是NULL,可以用来判断数组是否遍历结束。
我们也来模仿一下
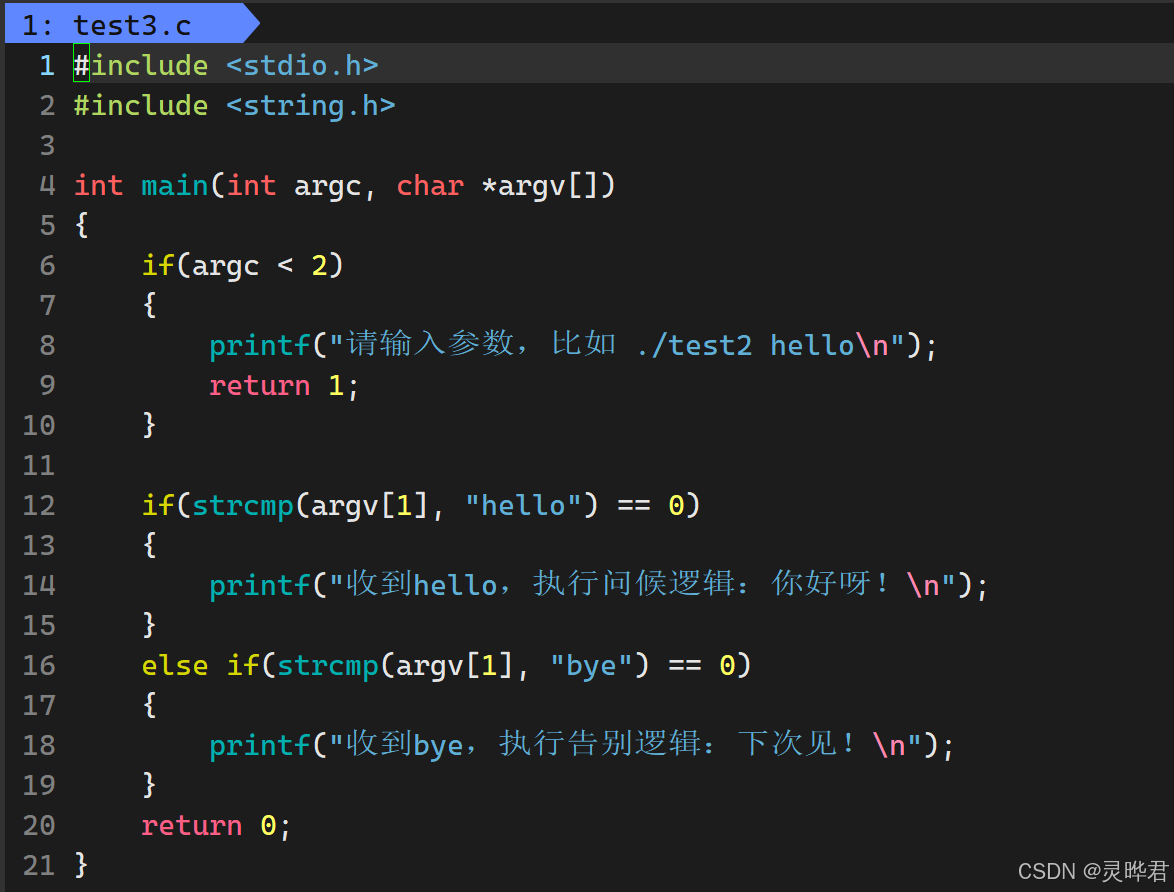
你看,同一个程序,传不同的参数,就能执行不同的逻辑。这就是命令行参数最核心的作用

六、在C语言中怎么获取环境变量
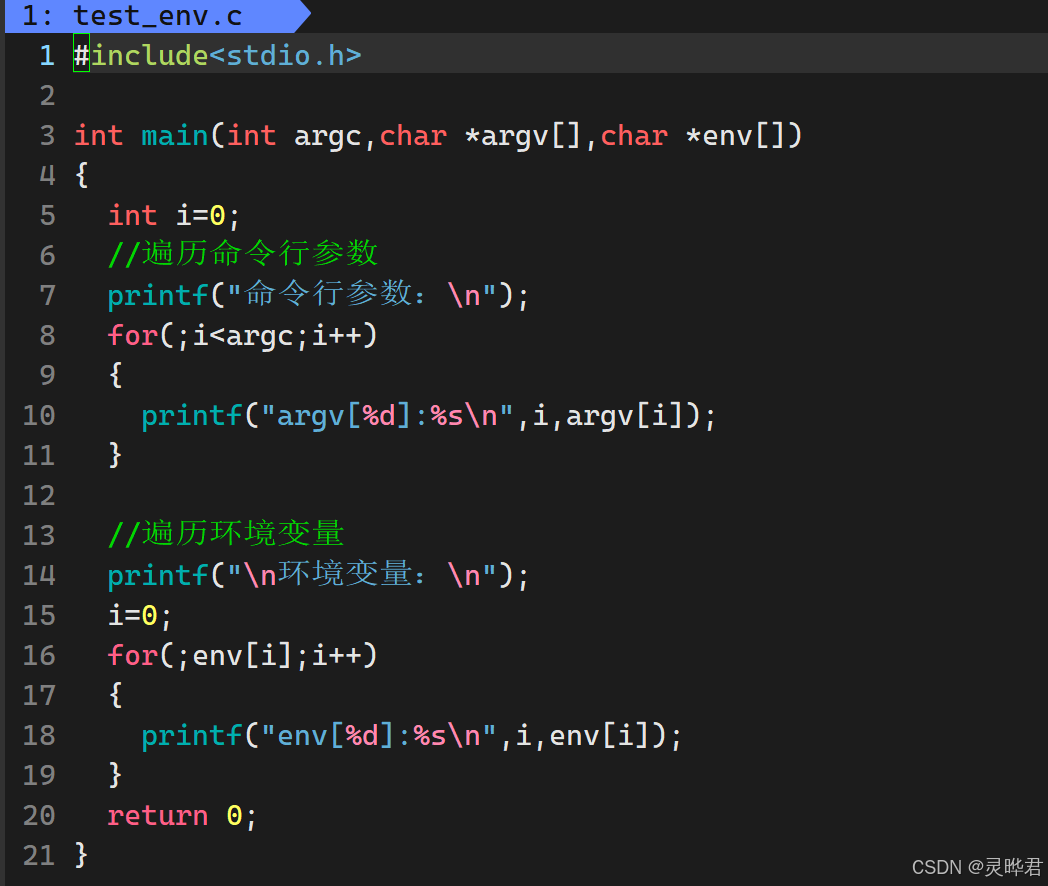
1、main函数的第三个参数char *env\[\]
main函数的完整定义其实有三个参数,除了我们刚才讲的argc和argv,第三个参数就是环境变量表
c
int main(int argc, char *argv[], char *env[])argc: 命令行参数个数
argv: 命令行参数数组
env:环境变量表,就是刚才说的字符串数组,每个元素都是"KEY=VALUE"格式,最后以NULL结尾
我们可以直接遍历env数组打印所有环境变量
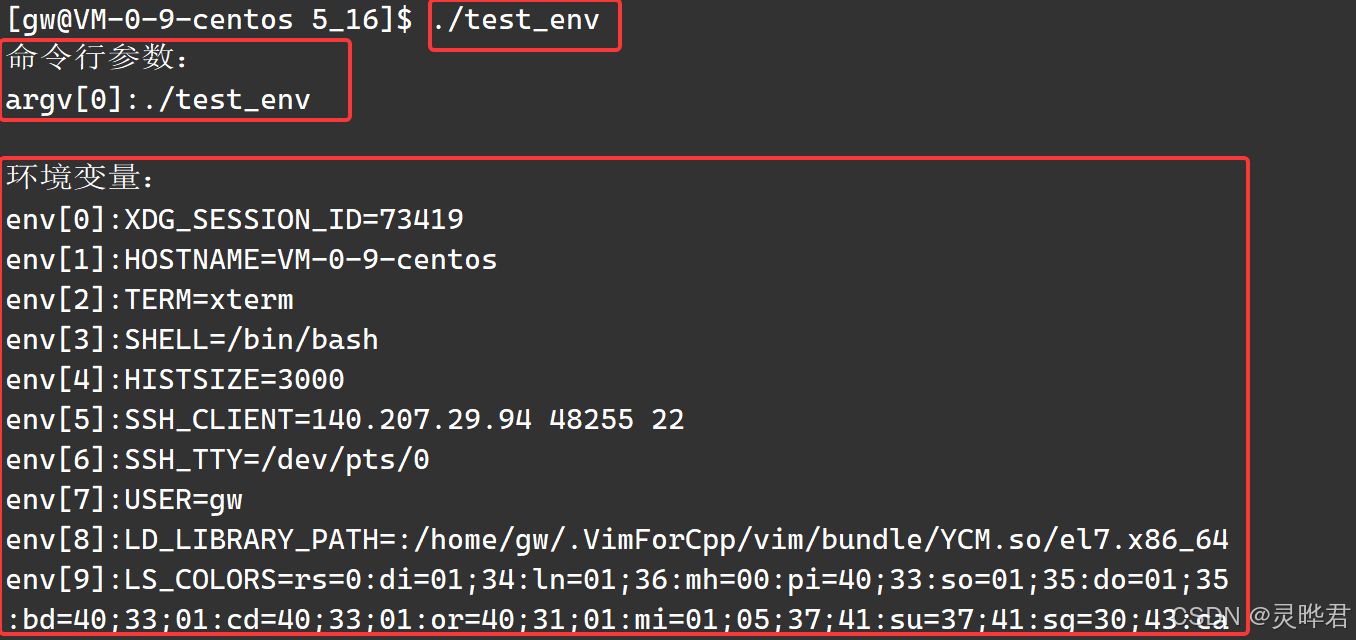
2、全局变量char **environ
Linux定义了一个全局变量environ,指向环境变量表 ,和env数组作用完全一样。使用时需要用extern声明,因为它没有包含在任何头文件中
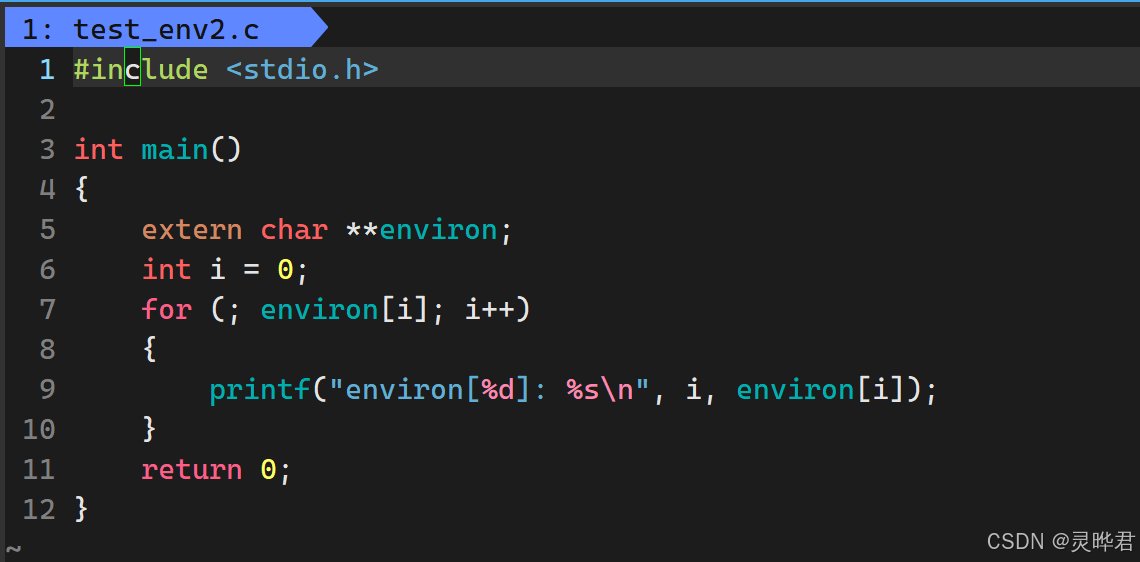
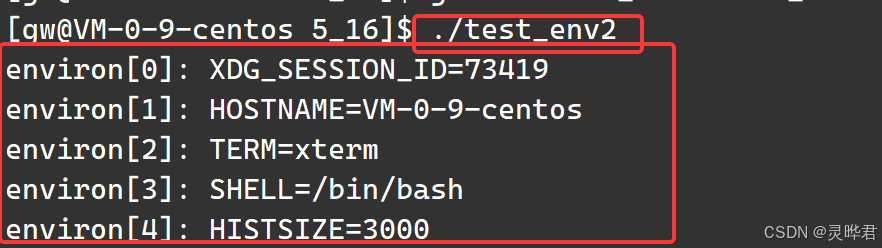
3、 最常用的getenv()函数
如果只想获取某个特定的环境变量,用getenv()最方便 ,它接收变量名,返回对应的字符串值,找不到则返回NULL
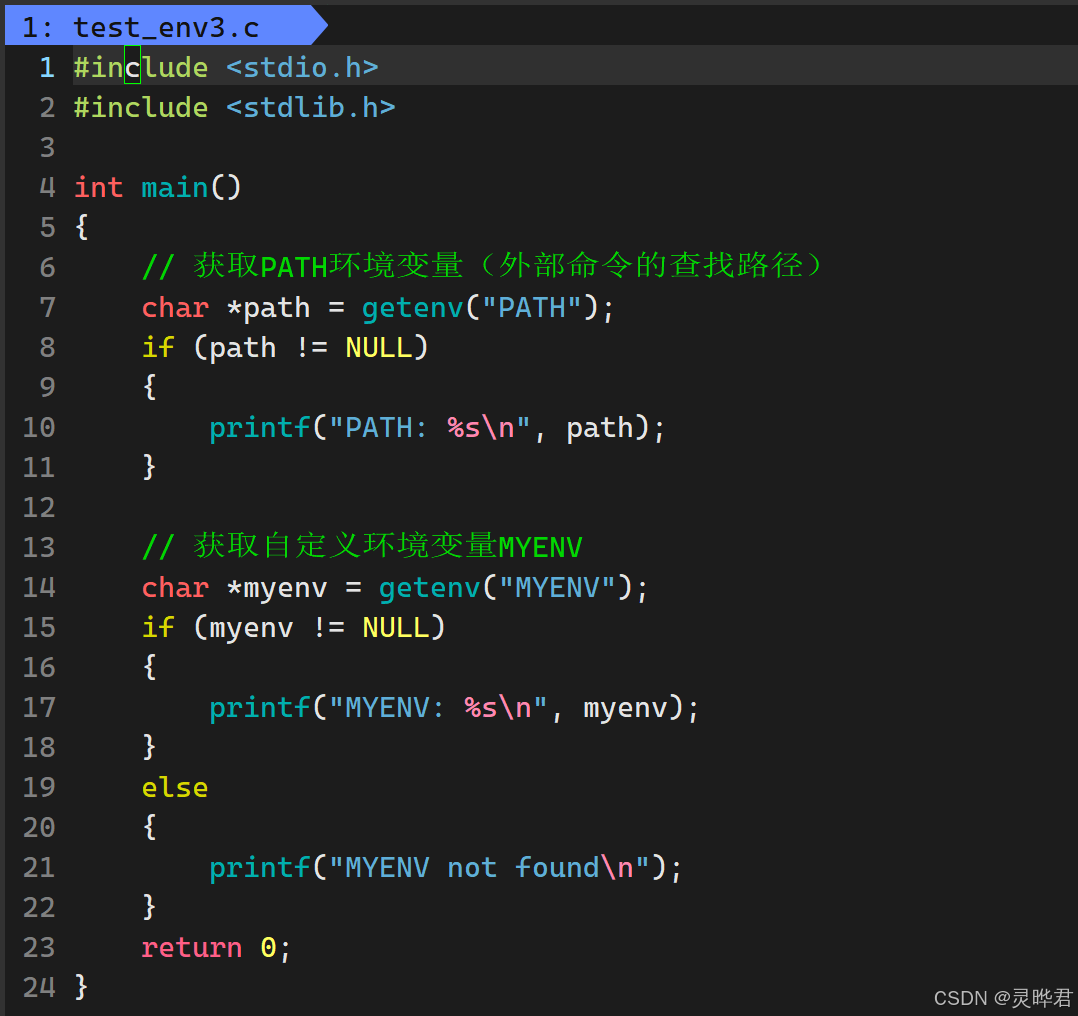
先定义一个环境变量(export是内置命令,不走PATH)
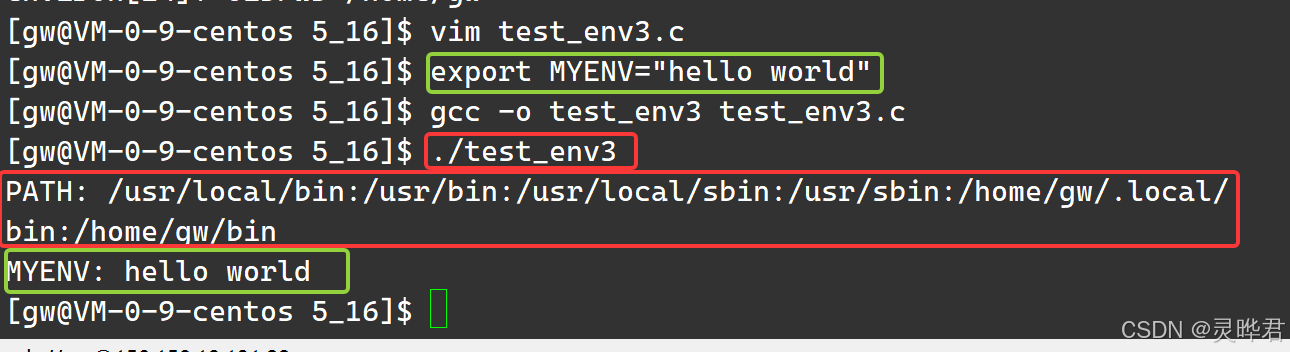
七、环境变量VS本地变量有啥区别
很多人会把环境变量和本地变量搞混,两者的核心区别在于是否能被子进程继承
1、 本地变量(Shell变量)
直接在shell中赋值的变量,默认是本地变量,仅在当前shell会话中有效,子进程无法继承
如图,定义本地变量直接赋值,用echo可以查到,用env命令看不到它 (env是外部命令,创建子进程,无法继承本地变量)
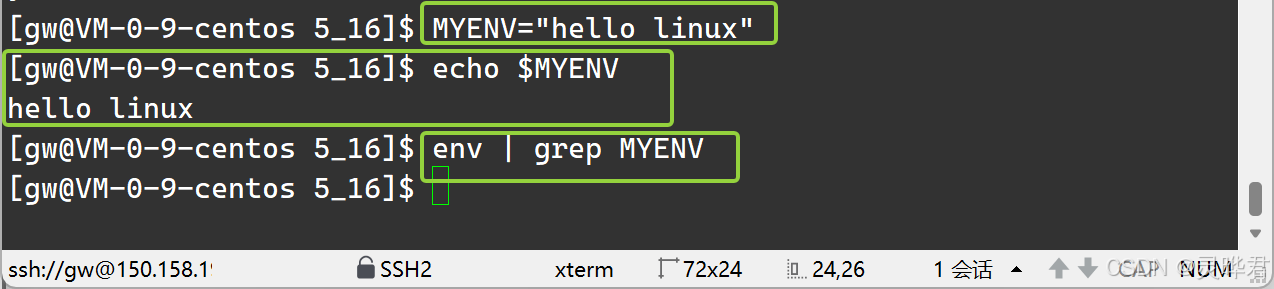
2、环境变量
用export导出的变量,就是环境变量,当前Shell和所有子进程都能继承(包括外部命令运行时创建的子进程)
export可以把本地变量升级为环境变量,让它能被子进程继承。此时用env就能查到了

3、 环境变量的全局属性:可以被子进程继承
环境变量最核心的特性就是全局属性:父进程定义的环境变量,子进程、孙进程都能继承 ------这也是为什么我们用export定义的环境变量,外部命令(子进程)能获取到的原因
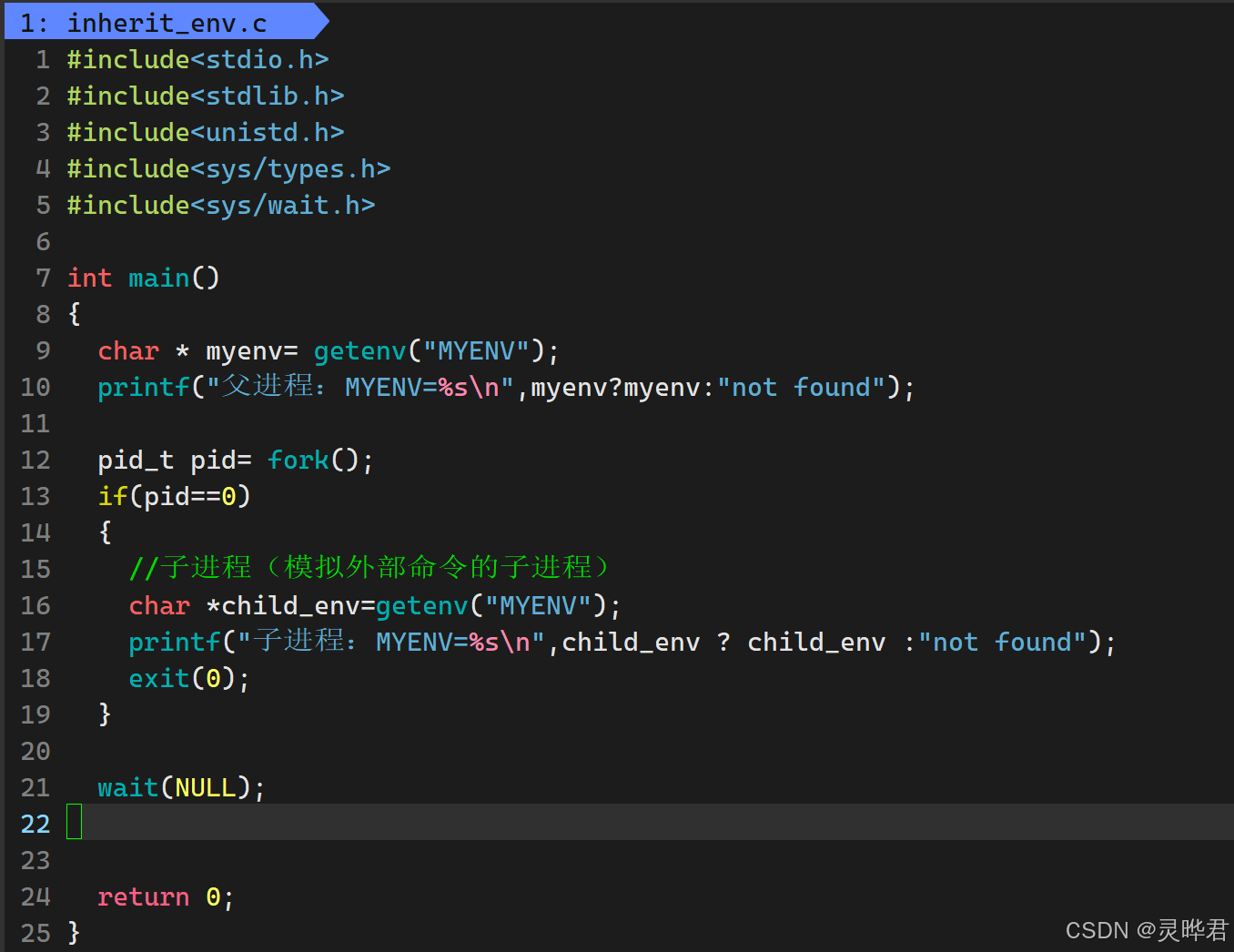
导出环境变量,export MYENV="I'm inherited" ,编译运行可以看到,子进程成功继承了父进程的MYENV环境变量
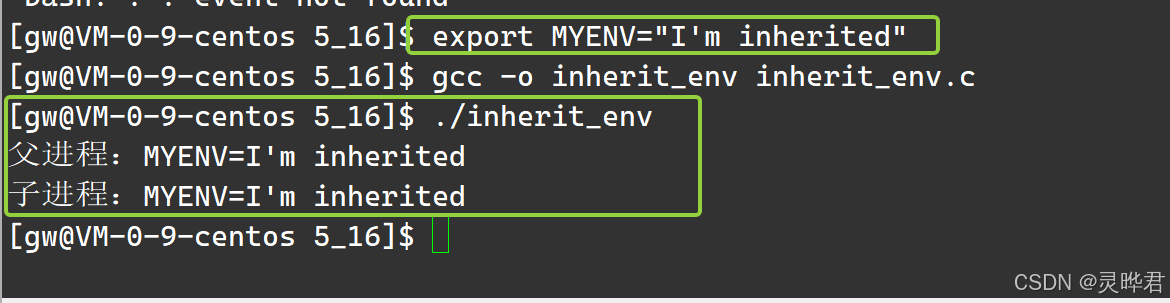
4、我们打开shell登录用户的过程,就是配环境的过程
登录shell时,系统在干些啥?
-
加载系统环境变量
比如 /etc/profile、/etc/bashrc 里的配置,给你初始化系统默认的 PATH、HOME、USER 这些全局环境变量,告诉 Shell"去哪里找命令、你的主目录在哪"
-
加载用户级配置
读取你自己家目录下的 /.bashrc、/.bash_profile,加载你自己定义的别名、自定义环境变量(比如你之前设置的 MYENV,或者 PATH 的自定义追加) -
创建 Shell 进程,把所有环境变量传给它
最后生成一个 bash 进程,把前面加载好的所有环境变量、配置信息,一股脑都塞给这个进程,你看到的命令行提示符,就是这个已经 "配好环境" 的 Shell 在等着你输入指令。
每次打开终端,都是一个全新的 Shell 进程,它需要知道: 我是谁?(USER) 我的主目录在哪?(HOME) 去哪里找命令?(PATH)
我的自定义配置是什么?(你写在 .bashrc 里的内容)