意图驱动的多智能体大语言模型网络管理:Confucius框架
第一作者:Zhaodong Wang
翻译工具:TRAE、Gemini 3.1 Pro Proview、MinerU等
摘要
大语言模型(LLMs)的进步正在显著改变网络管理实践。在本文中,我们介绍了在 Meta 开发多智能体网络管理框架 Confucius 的经验。我们将网络管理工作流建模为有向无环图(DAGs)以辅助规划。我们的框架将大语言模型与现有的管理工具相集成,实现了无缝的操作整合;采用了检索增强生成(RAG)以改善长期记忆;并建立了一组原语来系统地支持人机交互。为了确保关键网络操作的准确性,Confucius 与现有的网络验证方法紧密集成,并结合了自身的验证框架以防止出现退化。值得注意的是,Confucius 是一个面向生产环境的大语言模型开发框架,已经运行了两年,并接入了超过 60 个应用程序。据我们所知,这是首个关于将多智能体大语言模型应用于超大规模网络的报告。
关键词
大语言模型 (LLMs),检索增强生成 (RAG),网络规划
1 引言
网络管理是大型服务网络的重要组成部分,在确保海量互连服务器的可靠性、性能和可扩展性方面发挥着关键作用。尽管在流量工程 19, 44、网络配置 16, 38, 46 和自动化诊断 30, 52 方面已经有了大量的研究工作,但企业仍然需要投入大量的工程资源来有效管理其网络。大语言模型(LLMs)12, 18, 47, 53 已经成为一种能够增强网络管理的极具前景的解决方案。
生产环境中的网络管理涉及复杂的多步骤任务,需要借助不同的工具和专业知识来应对复杂的解决方案空间。例如,诊断失败的服务请求需要一个细致的过程:排查网络问题、分析路由路径并缩小潜在原因的范围。类似地,评估拓扑扩容计划的影响也需要多个步骤,包括流量预测生成、拓扑扩充、故障模拟和结果分析。鉴于这些任务的复杂性和特定领域的性质,仅仅依靠大语言模型单步处理它们是无效的。相反,需要一种更细致的方法,将领域专业知识与迭代改进相结合。
为了应对这些挑战,我们引入了 Confucius,一个新颖的多智能体大语言模型框架。Confucius 将复杂的管理任务分解为更小、结构化的子任务,每个子任务都可以使用专门的特定领域工具和数据库来执行。Confucius 引入了三个关键组件,可有效地将特定领域知识整合到通用的多智能体大语言模型框架中:
利用结构化网络程序增强规划:Confucius 将现有的结构化网络程序(例如代码化的操作流程 (MOPs) 或工作流 51)与大语言模型推理相集成。这些程序通常是用领域特定语言(DSLs)编写的,它们使用预定义的函数来编码较小的操作。Confucius 引入了编程原语,弥合了人类友好的结构化数据与基础模型之间的鸿沟。这种集成有助于大语言模型将复杂的网络管理任务分解为多个较小的任务,并结合多个智能体的输出来实现更好的规划效果。
利用领域特定语言连接工具:我们的核心理念是利用众多现有的网络管理工具,而不是开发新工具。然而,有效地使用这些工具需要具备编写正确输入和命令的深厚领域专业知识。我们提出了一组原语,可将人类友好的指令转换为兼容各个工具的 DSL 输入。基于我们的经验,我们确定了网络管理中广泛使用的三种 DSL:拓扑图、网络时间序列数据和网络数据模型 46。Confucius 具有内置模块来提供对这三种 DSL 的翻译,从而实现 Confucius 智能体与许多现有网络管理工具之间的无缝交互。
利用领域特定检索增强长期和短期记忆:Confucius 开发了高级的记忆管理机制以有效处理对话上下文,利用分层树结构进行短期记忆管理。对于需要大量上下文的情况,Confucius 采用检索增强生成(RAG)11, 27, 31, 32 作为一种长期记忆形式。例如,Confucius 利用独立的数据库中的 RAG 来索引数十万个网络数据模型,使大语言模型能够高效地搜索和检索。此外,它允许开发人员配置要存储在内存中的细节级别,并根据特定查询提取相关信息。
| 类别 (Category) | 用例 (Use Cases) | 提交给大语言模型的请求示例 (Example Requests to LLM) |
|---|---|---|
| 网络设计 (Network Design) | 拓扑 (Topology) | 将北美所有光纤的最大容量更新为 X |
| 网络设计 | 设计 (Design) | 将每个 POD 中的前向交换机 (FSW) 数量翻倍。 |
| 网络设计 | 配置生成 (Configuration Generation) | 生成配置以移除交换机 X 的 BGP 对等体。 |
| 网络设计 | 了解容量 (Understanding Capacity) | 某个数据中心每种机架类型的总部署功率是多少? |
| 网络设计 | 状况 (Situation) | 区域 A 中 EBB 未来六个月的计划容量是多少? |
| 网络设计 | 容量假设分析 (Capacity What-ifAnalysis) | 将第 3 层路由器的最大容量更新为来自 "node_cap_manager" 的值,使用 "hose" 需求类型和 p90 百分位数运行 "cap_planner",并将结果与最新的黄金版本进行比较。 |
| 网络运营 (Network Operations) | 创建操作 (Create Operations) | 编写一个升级交换机角色 X 软件版本的工作流。 |
| 网络运营 | 工作流 (Workflows) | 我可以使用哪个构建块在 FBNet 中创建新设备? |
| 网络运营 | 生成迁移命令 (Generate Migration Command) | 生成交换机 X 的软排空 (soft drain) 命令。 |
| 网络运营 | 监控操作状态 (Monitor Operations Status) | 显示过去 3 天内耗时最长的操作。 |
| 监控与诊断 (Monitoring & Diagnosis) | 监控网络健康状况 (Monitoring Network Health) | 你能给我看下 5 月 20 日 Ads 存储服务从区域 A 到区域 B 的黄金流量吗? |
| 监控与诊断 | 异常检测 (Anomaly Detection) | 3 月 8 日在 1.1.1.1 观察到了多少个不同的源 IP? |
| 知识共享 (Knowledge Sharing) | 知识共享 | 我在哪里可以找到关于生产网络性能的数据? |
表 1: 用例示例。
系统性地确保正确性:为了保证管理任务的安全性和可靠性,Confucius 被设计为与现有的验证和确认系统紧密集成。此外,Confucius 提供了一组原语,以促进频繁的人类反馈。不仅如此,Confucius 还包含一个基准测试系统,使开发人员能够在不同配置、提示算法和基础模型下轻松评估他们的应用程序。
Confucius 已在生产环境中成功部署了两年,服务于数千名用户并支持超过 60 个网络管理应用程序。值得注意的是,Confucius 为开发人员节省了大量时间,平均每周减少 17 个工程师小时的开发时间,同时保持了高准确性。我们的评估表明,与仅依赖基础模型的解决方案相比,Confucius 将准确性提高了高达 21%。我们分享了开发 Confucius 和接入应用程序的经验,为在生产网络中使用大语言模型所面临的挑战和机遇提供了宝贵的见解。据我们所知,本文提出了首个用于开发和部署大语言模型辅助网络管理应用程序的全面框架。我们希望本文能激发这一激动人心的新领域的未来研究,推动向真正意图驱动的网络管理进行创新。
2 动机 (Motivation)
在过去的两年里,我们使用 Confucius 成功开发并部署了多个应用程序。本节概述了我们的生产用例,重点强调了遇到的关键挑战。我们通过两个示例来说明这些挑战,讨论了大语言模型 (LLM) 的优势,并概述了采用过程中面临的挑战。
2.1 网络管理用例 (Network Management Use Cases)
网络管理涉及需要手动操作和深厚领域知识的复杂任务。表 1 展示了 Confucius 支持的网络管理应用程序类别以及查询示例。我们将这些用例大致分为网络管理生命周期的四个类别。
网络设计 (Network Design) 涉及生成满足容量和性能要求的拓扑设计。这项任务需要在最佳决策与不断发展的技术、复杂的需求以及有限的资源之间取得平衡。虽然传统方法创建抽象图并手动将其转换为具体的数据模型 46,但 LLM 可以协助将抽象设计自动转换为具体的数据模型,从而减少时间和错误。在不同模型和网络产品的选择中,LLM 可以根据高层意图和需求辅助进行选择。在 §2.2 中,我们提供了作为网络设计示例的容量规划的更多细节。
网络运营 (Network Operations) 涉及遵循既定的操作流程 (MOPs) 执行配置更新、软件安装和硬件更换等任务。这些任务对网络的可靠性和性能至关重要,但手动执行可能既耗时又容易出错。LLM 可以通过建议现有的 MOPs、生成新的 MOPs、执行复杂指令、监控操作状态以及降低内部工具的使用门槛来改善这些流程。LLM 可以将新产品引入和部署转化为更高效的过程。
网络监控 (Network Monitoring) 涉及从各个供应商的 API 收集数据,但由于供应商的异构性,管理这些 API 可能具有挑战性。即使使用 Thrift 16 这样的标准化 API,在复杂的结构中导航并解析检索到的数据也可能很困难。LLM 通过建议和编写 API 以及自动解析检索到的数据,提供了一个极具前景的解决方案。LLM 不仅可以显著提高效率,还可以通过自学习开发新的故障排查流程。我们在 §2.3 中提供了故障诊断的详细示例。
知识库与入职 (Knowledge Base and Onboarding) 涉及网络领域特定的术语和工具,这可能会使新工程师对 EBB 19 和 FA 9 等复杂概念感到不知所措。网络数据需要特定的上下文才能正确使用。LLM 可以通过充当知识管理平台来提供这种上下文。
2.2 容量假设分析 (Capacity What-if Analysis)
接下来,我们深入探讨网络设计和网络监控类别中的两个具体应用程序。在每个示例中,我们都指出了基于 LLM 构建的 Confucius 是如何提供具体帮助的。
Meta 的容量规划涉及确定在何处以及何时增加网络容量,以确保长期的网络健康。这一过程依赖于假设分析和优化 6, 7。例如,为了满足 AI 训练的需求,Meta 部署了新的数据中心 4,并利用新技术扩充了现有的数据中心。一个关键的挑战是确定骨干拓扑应如何改变,以合适的容量互连这些新区域。Confucius 通过各种子任务来回答这个问题。
规划子任务。图 1 展示了一个旨在响应新数据中心部署而增加骨干网容量的假设分析示例。在进行分析之前,用户必须首先收集当前的网络拓扑结构以及即将部署的光纤信息。接下来,用户提出假设问题,例如,"如果我在特定路径上启用更多通道会怎样?" 为了解决这些问题,用户创建一个包含几个步骤的执行计划:更新流量预测、使用即将部署的光纤扩充拓扑、运行故障模拟,并分析结果以支持 A/B 测试。
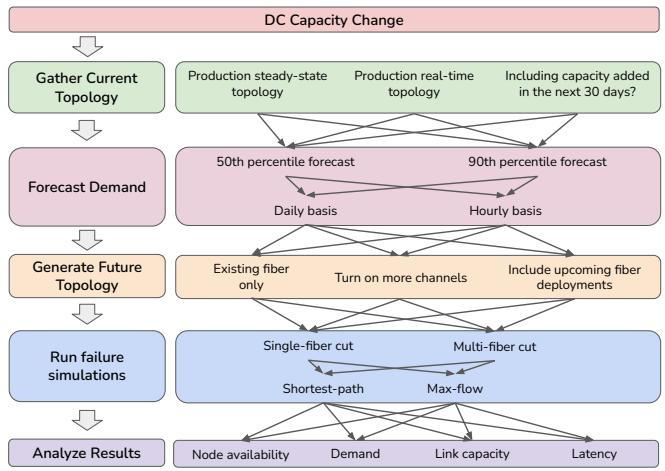
图 1: 容量假设分析示例。
子任务的复杂性。每个子任务可以有多个变体,例如用于需求预测的不同百分位数或用于故障模拟的不同网络弹性策略,如图 1 所示。传统上,网络规划人员手动配置和链接这些工具,导致过程耗时且并行化不理想。Confucius 通过自动生成操作的有向无环图 (DAG),并根据规划人员定义的假设场景编排远程执行,从而简化了此工作流。此外,Confucius 减少了查询实时拓扑数据所需的领域专业知识和人工工作量,因为这些数据可能包含噪声且无法准确反映计划的变更。用户通过自然语言接口与容量相关的信息进行交互,使他们能够提出诸如"过去 90 天内增加的总容量是多少?"之类的问题,而无需了解表结构或查询语法。
鉴于存在许多子任务变体,手动分析数十个输出是不切实际的。Confucius 根据总丢弃流和 SLO 未命中等关键指标总结结果。它还利用其多模态功能提供差异的可视化分析,帮助用户快速解释和比较结果。
2.3 网络性能诊断 (Network Performance Diagnosis)
故障诊断对于解决网络问题至关重要,但复杂性和各种潜在原因带来了重大挑战。网络工程师必须筛选大量的监控数据并考虑众多潜在原因。Confucius 通过分析数千个计数器和指标来协助故障诊断。在图 2 所示的示例中,我们需要诊断在特定时间段内 Instagram 推理请求失败的情况。这涉及分析网络问题、主要区域、路由路径、受影响的前缀,并确定是否有任何网络变更与这些因素相关联。
规划子任务。诊断网络问题的第一步是规划复杂诊断任务的执行。在生产环境中,我们使用由子工作流或步骤组成的工作流或运行手册 (runbooks) 51,每个子工作流或步骤都调用不同的工具。面对数百个工作流,很难确定应该为特定的诊断问题使用哪一个。例如,图 2 涉及四个步骤:(1) 按区域和前缀识别主机,(2) 检查 TCP 重传以查找异常,(3) 分析 NetNORAD 30 数据以查找丢包,以及 (4) 检查与受影响的 LSP 路径链接的网络变更日志。
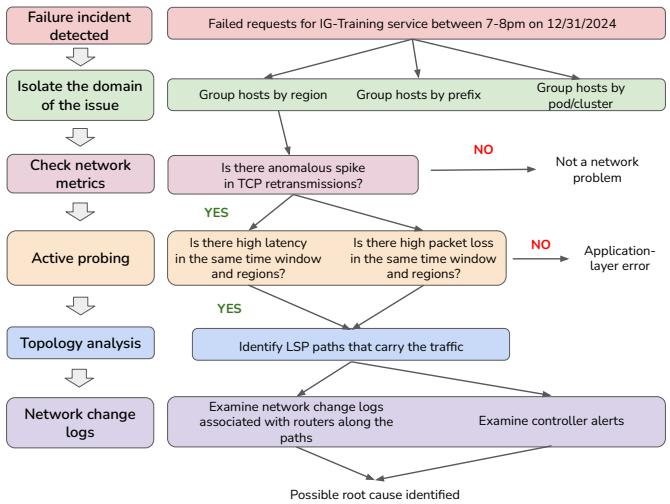
图 2: 故障诊断示例。
子任务的复杂性。每个子任务都需要查询特定的数据集,由于需要大量的数据集和领域知识,这可能具有挑战性。例如,过滤和聚合诸如 SNMP 日志之类的原始数据是识别模式所必需的,而用于性能下降的异常检测需要选择算法并设置不同的参数 17。目前,网络工程师必须手动创建和管理包含数十个步骤的工作流,这既繁琐又耗时,需要数小时甚至数天。Confucius 通过自动生成模板、建议可重用的构建块、执行查询并识别关联性来自动化这一过程。它通过减少分类和根本原因分析所需的人时来提高诊断效率。
2.4 观察与挑战 (Observations and Challenges)
我们总结了上述示例和用例中的关键观察结果。
多步骤复杂任务:网络管理任务很复杂,涉及多个需要领域特定知识的步骤。例如,假设分析将任务分解为需求预测、拓扑建模和策略定义等子任务。
专用工具:尽管存在复杂性,但已经开发了许多专用工具来解决网络管理的特定方面,包括网络建模、基于意图的路由、容量规划、拓扑设计、监控和诊断。在 Meta,我们有数百个涵盖骨干网、数据中心和边缘网络的工具和 API,并且这个数字正在迅速增长以支持新的用例。
庞大的搜索空间:现代网络的规模和异构性导致网络管理任务的搜索空间巨大。例如,设计一个新的数据模型需要在数十万个现有模型中进行导航。
高安全性要求:网络管理要求极高的可靠性,这使得仅依靠 AI 变得不切实际。
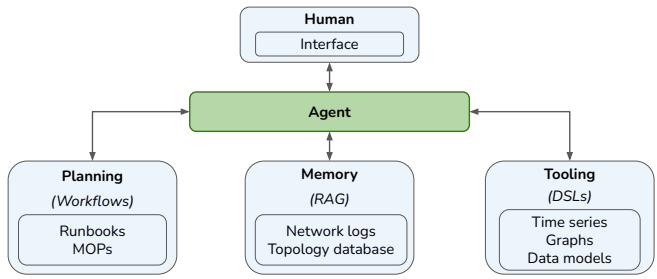
图 3: 多智能体架构。
例如,必须仔细检查设备排空 (draining) 操作以防止引入丢包。类似地,更改路由配置需要密切审查,以避免产生破坏现有流量的黑洞。
隐私问题:网络数据是高度专有的,必须保护敏感信息以防止恶意攻击。用户在交互时可能会无意中输入敏感细节,如姓名、电子邮件地址和 IP 地址。因此,在将输入数据发送给 LLM 之前,必须进行仔细的数据脱敏。
3 概述 (Overview)
在本节中,我们将介绍 Confucius 中的原理、关键设计思想和编程框架。
3.1 原理 (Principles)
在过去两年中,我们探索了利用 LLM 进行网络管理的各种方式,从聊天机器人风格的问答界面到与系统和工具的更深层次集成。基于我们的经验,我们总结了 Confucius 的以下指导原则:
• 将推理与事实知识分离:我们利用 LLM 执行它们擅长的推理任务,同时依靠现有的运行手册、工具和数据库来检索事实信息。
• 利用现有专业知识:我们利用网络管理中成熟的工具和专家知识,这类似于现有的整合领域知识的方法 3。
• 使用精心设计的提示词进行编排:受"认知架构" 1 的启发,我们将管理任务分解为各个组件,并使用精心设计的提示词来指导 LLM 的推理。这使我们能够保持对推理过程的控制。
• 优先考虑迭代改进:我们优先考虑基础实现以快速开发功能系统,并随着时间的推移进行迭代改进。
• 不依赖于微调:我们将我们的方法设计为与不需要微调作为先决条件的基础模型有效配合。这使我们能够利用 LLM 的最新进展,同时最大限度地减少对昂贵且耗时的微调的依赖。
3.2 关键设计思想 (Key Design Ideas)
我们将我们的设计选择与 §2.4 中概述的挑战结合起来。功能块概述如图 3 所示。
多智能体框架:在网络管理中,必须将复杂任务分解为多个相互关联的子任务,每个子任务都需要不同的专用工具和领域知识。一种简单的解决方案是使用单个 LLM 从头到尾处理整个任务,但这在处理足够复杂的任务时显得力不从心,会导致提示词过多且性能不可靠。通过采用多智能体框架,Confucius 将复杂的工作流分解为可以由多个专业智能体处理的独特子任务。图 3 显示了 LLM 智能体与四个部分的交互:规划、记忆、工具和人类。我们构建了特定于网络的原语来促进它们之间的交互。
利用现有的 MOPs 和工作流进行规划:MOPs 和运行手册是用于网络任务的预定义工作流,以结构化格式提供 51。为了让 LLM 从这些工作流中学习,我们必须克服三个挑战:1) 弥合结构化语言(例如 Python 或 DSL)与自然语言之间的鸿沟;2) 整合深厚的领域知识,例如 BGP 路由优先级;3) 管理众多工作流。Confucius 提供了编程原语,以弥合结构化数据与 LLM 之间的鸿沟。它还结合了多个智能体的输出以实现更好的规划。
用于连接工具的结构化数据:网络工程师依赖于操作结构化数据的复杂工具。专业知识在于选择正确的工具并格式化命令以实现所需的操作。我们将 Confucius 智能体设计为使用一组原语与多个特定领域的工具交互,这些原语将自然语言输入转换为符合 DSL 的输出。
用于长期和短期记忆的领域特定检索:在多智能体 LLM 框架中,每个智能体都专注于特定的子任务。为了协调智能体,Confucius 提供了记忆功能来跟踪与人类和工具的交互。它提供短期记忆管理,用户可以控制每个会话的记忆级别。对于长期记忆,Confucius 利用 RAG 来处理大量的上下文。
通过验证和人工输入确保正确性:Confucius 与现有的验证框架(包括试运行和配置验证系统)集成,以确保关键任务的正确性。输出在呈现给用户之前经过验证,并且高度敏感的任务强制需要人工批准。为了支持人工监督,Confucius 使用名为 Collector(收集器)的原语通过结构化的人机交互系统地收集用户输入。
3.3 Confucius 编程框架 (Confucius Programming Framework)
Confucius 是一个编程框架,通过原语和抽象简化了应用程序开发,如图 4 所示。它为用户交互提供了一个类似聊天的交互式界面。
编程抽象:Confucius 的核心基于 Pydantic 构建,Pydantic 是一种用于定义自定义数据结构的 Python 模式语言。核心抽象类是 Analect,它包含用于输入、输出和运行时的可重用逻辑和数据。它类似于一个函数,但提供了执行日志记录,简化了整个系统中的重用。所有 Analect 共享几个基本运算符。这些运算符实现了基本功能,包括 JSON 解析器、在内部数据库中自动收集和记录执行轨迹的 Tracer(追踪器),以及支持人在回路 (human-in-the-loop) 交互的 I/O 函数。
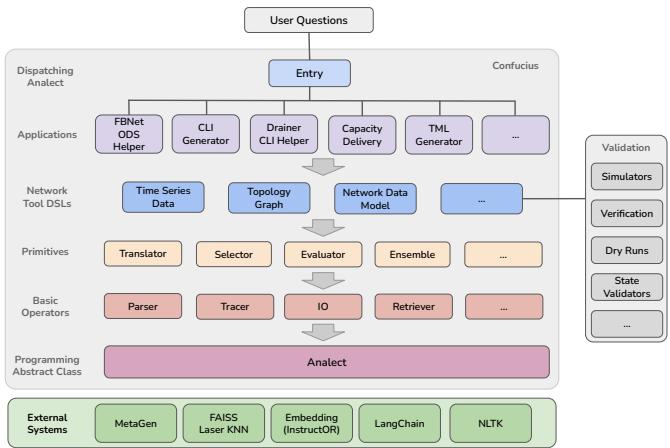
图 4: 编程框架。
Confucius 原语:这些是实现一项特定操作的专门 Analect。它们可以应用于各种用例。Analect 是所有原语的抽象类。一个例子是 Translator(翻译器)原语,它将自然语言输入转换为结构化输出,例如将用户的英语查询翻译为命令行。用户可以专注于编写示例,而无需担心格式化输入和解析结果。Translator 还促进了不同 CLI 命令、查询和特定于供应商的配置之间的语言转换。
工具 DSLs:Confucius 支持网络管理应用程序中常用的三种 DSL,这将在后面的 §4.2 中更详细地讨论。随着新用例的接入,该层可以进行扩展以容纳更多的 DSL。
应用程序:类似于 SDN 应用程序,不同的团队开发了各种基于 LLM 的网络管理应用程序来解决特定领域的问题。例如,数据中心设计工程师创建一个应用程序来设计新的 AI 数据中心网络。
外部系统:Confucius 利用几个外部系统来增强其功能,包括 LangChain 13、用于 AI 模型访问的 MetaGen API 23、用于高效相似性搜索的 FAISS 21、用于嵌入的 Instructor 45 以及用于自然语言处理的 NLTK 10。
4 Confucius 的设计 (Confucius' Design)
本节从四个维度深入探讨设计细节:规划、工具、记忆和验证。
4.1 规划阶段 (Planning Phase)
我们现在介绍规划方法和原语。
4.1.1 网络工作流 (Network Workflows):
从历史上看,像 Meta 这样的公司在执行网络管理任务时依赖于 MOPs(自然语言编写的分步操作流程)14, 15。然而,它们的歧义性和松散的文档记录使得执行变得困难。为了解决这个问题,Meta 开发了一个工作流系统 51,将 MOPs 编码并分解为更小、模块化的构建块(BBs),从而促进了更好的模块化和代码重用。BBs 是使用各种编程语言或作为二进制文件编写的灵活脚本或配置片段(设计为在设备和工作流中重用的模块化"配置片段")。这种方法被广泛采用 34。
4.1.2 利用工作流进行大语言模型规划 (Leverage Workflows for LLM Planning):
我们设计了一种提示工程方法来教导大语言模型学习工作流。
DAG 表示:我们将网络任务的规划逻辑表示为有向无环图 (DAG),使用基于 Python 的 DSL 实现。DAG 中的每个节点代表一个子任务,即一个构建块。大语言模型解析每个节点的输出,并将其用作后续节点的输入。独立的子任务可以并行执行,运行时环境根据输入/输出依赖关系自动确定最佳执行计划。图 5 展示了一个用于容量假设分析的 DAG 示例。用户定义的场景(涉及修改网络拓扑、扩展需求以及在多种条件下评估结果)被分解为离散的、可组合的子任务。每个操作都被封装为 DAG 中的一个节点,以实现模块化执行和清晰的数据流。
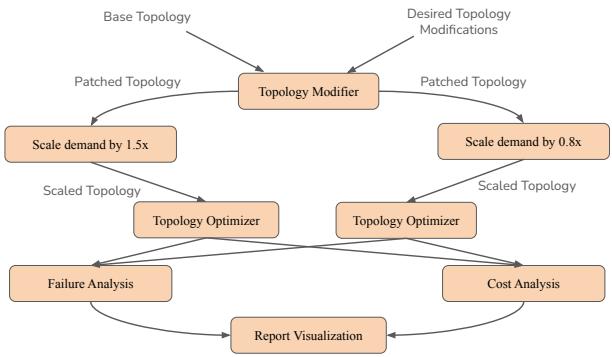
图 5: 规划 DAG 示例。
建议现有工作流:在我们的生产环境中,我们在工作流和 BB 发现方面面临挑战。面对数百个工作流和数千个 BB,工程师很难确定哪些最适合特定任务。为了解决这个问题,我们开发了一种基于 RAG 的方法,以高效地搜索和推荐工作流和 BB。图 16 展示了该设计。系统架构由两个主要组件组成:Indexer(索引器)和 Retriever(检索器)。索引器利用大语言模型分析每个工作流和 BB,提取关键信息以计算语义嵌入,然后将其存储在数据库中。检索器分两步运行:粗粒度相似性搜索以选择约 10 个候选工作流/BB,然后进行细粒度选择以将选项缩减到 3 个以下。
4.1.3 用于规划的 Confucius 原语 (Confucius Primitives for Planning):
Ensemble(集成) 针对单个任务并行调用多个大语言模型,并将其结果组合成单个输出。这保持了原有的字符串到字符串的接口,使其能够无缝替换标准的大语言模型调用。图 15 展示了其编程构造的一个示例。要激活 Ensemble,用户需向支持的 API 提供 LLMParams 列表。我们的系统支持四种组合模式:1) First-mode 选择最快智能体的结果;2) Merge-mode 合并所有智能体的结果以供人工审查;3) Filter-with-Validation 使用验证框架过滤掉错误结果;以及 4) Return-all 以集合形式返回所有答案。Ensemble 还接受自定义组合函数,从而实现灵活的策略,确保从可能不可靠的构建块中获得可靠的结果。

图 6: Collector 实现。
Orchestrator(编排器) 是一个新颖的 AI 框架,它使大语言模型能够通过以循序渐进的方式调用构建块来自动创建工作流,类似于 42。这种方法需要在提示词中提供详细的示例和说明,告知大语言模型应该使用哪些构建块以及何时使用。Orchestrator 在自主操作和受控执行之间取得了谨慎的平衡;这使我们能够充分利用现代大语言模型增强的推理和规划能力,同时保持我们应用程序所需的可靠性。
4.2 工具:网络管理抽象 (Tools: Network Management Abstraction)
为了与现有的网络管理工具集成,我们必须将自然语言转换为这些工具可以处理的结构化数据 (DSLs)。
4.2.1 用于工具的 Confucius 原语 (Confucius Primitives for Tools).
为了促进转换,Confucius 引入了三个原语,这些原语系统地定义了转换逻辑并收集完成转换所需的附加信息。
Translator(翻译器) 将自然语言转换为结构化输出(例如命令行或配置),允许用户专注于编写示例,而无需担心格式化和解析。它可以处理多种语言,并在不同的 CLI 命令、查询和特定供应商配置之间进行翻译。
Selector(选择器) 使用可定制的逻辑(例如,语言模型或相似性搜索方法)根据用户的查询选择相关的子集选项。它被广泛用于从大型数据集或数据库中进行选择。使用选择器的基本原理是,虽然大语言模型通常可以将范围缩小到结构化数据的子集,但它们需要额外的信息才能生成精确的输出。
Collector(收集器) 从各种来源(包括用户)收集和处理数据,以阐明意图并识别相关实体。这个原语是基于观察到自然语言通常包含歧义而设计的。它还可以提出后续问题以完善用户的指令。通过减轻自然语言中的歧义,收集器提高了下游任务的性能。由于篇幅限制,我们仅讨论收集器的详细信息,如图 6 所示。用户通过定义特定于其用例的 CollectorTask 来实例化 Collector 类。除了提供直接指令外,CollectorTask 还允许用户提供少样本的 CollectorExample 对象。CollectorExample 包含一个用户输入的示例,配对封装在 CollectorArtifact 中的正确响应,以及一个包含得出答案的逐步逻辑的 CollectorThinking 对象。基于这些类创建的具体对象的示例在图 18 中提供。
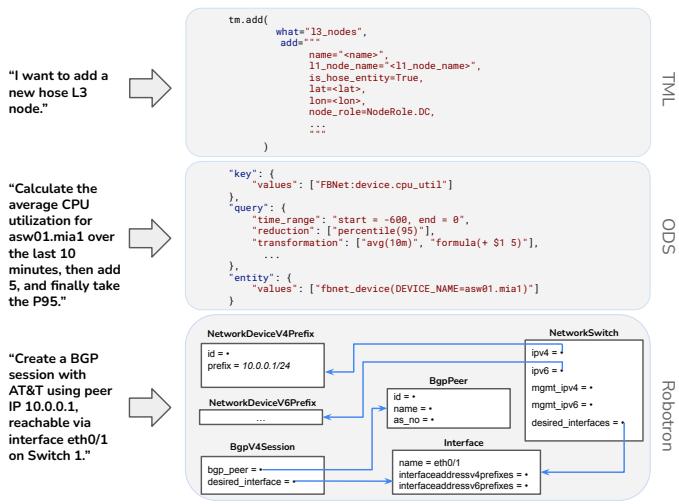
图 7: 三种 DSL 的示例。
4.2.2 基础网络管理 DSL (Foundational Network Management DSLs).
虽然 Translator 原语用于将自然语言转换为结构化数据,但仍需要确定要转换成哪种结构化数据格式。现有的网络工具依赖于各种结构化数据格式。基于我们的生产经验,我们确定了网络管理中三种广泛使用的 DSL 类别。支持这三种 DSL 能够更容易地接入大量工具。
网络图 (Network Graph)。网络拓扑图是容量规划、风险分析、路由和流量工程等各种应用程序中的基本要素。我们使用 Thrift 定义的图来表示拓扑,其中包括区域 (regions)、第 1 层节点、第 3 层节点、第 1 层光纤边缘、第 3 层 IP 边缘和流量。一个见解是,节点的命名约定对于理解拓扑至关重要。例如,区域通常以机场代码命名(例如,ATN),而 L1 节点代表区域内的第 1 层设备组,通常通过将区域代码与数字组合来命名(ATN1)。这些命名约定提供了有关拓扑属性和角色的宝贵信息。它举例说明了我们明确嵌入到大语言模型提示词中的特定领域知识类型,以便大语言模型能够识别和解释 DSL 中的这些模式。我们使用一种名为 TML(拓扑修改语言 Topology Modification Language)的基于 Python 的 DSL 来促进对图的修改。这种 DSL 支持系统性地更新、转换和选择拓扑对象。图 7(a) 显示了一个这样的示例。
时间序列网络数据 (Time Series Network Data) 。时间序列网络数据是网络管理中的一个基本构造,应用范围从流量分析和网络健康监控到异常检测。在 Meta,时间序列数据存储在称为 ODS(操作数据存储 Operations Data Store)41 的键值存储中。数据的基本单位是一个实体,它可以代表测量下的任何对象,例如接口丢包或 CPU 利用率。每个实体的数据由一系列 <time, value> 快照组成,如图 7(b) 所示。为了让大语言模型熟悉时间序列数据,我们将特定领域知识嵌入到提示词中。换句话说,我们明确指示大语言模型如何处理这种类型的数据;这包括聚合时间序列数据的方法,例如计算平均值或第 90 个百分位数,以及生成数学公式以操作此数据的约定。
网络数据模型 (Network Data Model)。将网络管理数据存储在结构化模型中是一种常见做法 38, 46。现代生产网络通常将其真相源数据保留在管理数据库中,并在其之上提供对象关系映射 (ORM) 层以便于访问。在 Meta,Robotron 数据模型 46 是几乎所有管理工具的基础组件。图 7© 说明了如何将创建 BGP 会话的意图转换为一组网络对象模型的示例。一个接口由多个组件组成,每个组件都链接到关系数据库中的其他对象,例如 IP 地址、BGP 会话和相邻端口。
我们发现 Robotron 是一种强大的 DSL,可将大语言模型与各种现有网络管理工具连接起来。它将高级网络设计意图捕获为关系数据对象,然后将这些对象转换为低级、特定于供应商的设备配置和网络操作。大语言模型通过将用户的自然语言意图映射到 Robotron,进而映射到低级配置,进一步提升了这种抽象水平。这种转换的主要挑战在于涉及的大量模型。为了解决这个问题,我们开发了一种检索增强生成 (RAG) 方法,这将在后面详细描述。
总之,我们确定了许多管理任务中经常使用的三种常见 DSL,在图 7 中用自然语言的具体翻译对它们进行了说明,并重点指出了相关的挑战。接下来我们深入探讨使这些翻译既准确又高效的技术。
4.2.3 提示工程技术 (Prompt Engineering Techniques).
提高翻译准确性的一种有效方法是设计适当的提示工程技术。我们为每个 DSL 翻译任务精心选择量身定制的最佳提示词组合。在下文中,我们总结了这些技术并将它们与各自的 DSL 翻译任务联系起来。
• 零样本思维链 (Zero-shot chain of thought) 要求模型在翻译前进行思考。例如,在 ODS(时间序列 DSL)中,我们在请求中使用"Thought"字段来教导大语言模型在遇到诸如"rsw1aa.*prn1"之类的字符串时利用正则表达式匹配。这迫使模型首先考虑输入文本的网络上下文,而不是直接生成字面翻译。
• 少样本思维链 (Few-shot chain of thought) 为模型提供用于翻译的相关示例。例如,我们给出一个示例来教导大语言模型理解 ODS 示例中的"entity"字段。
• 对比思维链 (Contrastive chain of thought) 涉及给模型错误的示例并告诉它们这些是错误的。例如,
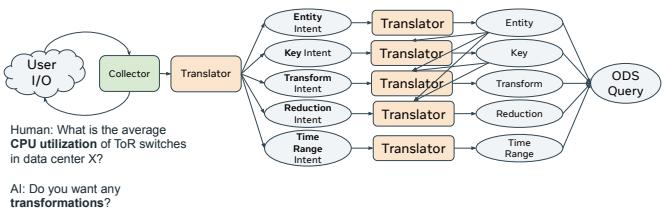
图 8: ODS 用例中 Analects 的组合。
在 ODS 翻译中,我们可以创建一个关于不包含任何名为"prn2"的区域中的交换机的反例。
• 工具调用 (Tool calling):我们为模型提供 API、CLI、库和数据库的访问权限,以实现智能体规划。在 ODS 中,我们直接调用 ODS 查询 API,并在必要时将返回的消息连同原始查询包含在后续迭代中,以允许大语言模型执行自我纠正。
• 推理与行动 (Reason and act):它使用编排器让大语言模型在网络调查中针对复杂任务进行自我规划。通过允许模型规划其自身行动,我们可以帮助它生成更连贯有效的翻译。这种方法在模型需要执行多项任务或响应不断变化的情况时特别有效。如下所述,ODS 查询被分解为 5 个子任务。
• 代码即推理 (Code as reasoning):我们让大语言模型编写代码来回答数据检索问题。例如,我们不要求大语言模型直接修改拓扑结构;相反,我们让大语言模型编写 TML 代码,该代码通过编译器和 TML 引擎来修改拓扑。主要是,这种方法允许生成的代码容易被编译器或人工验证。此外,人工可以修改代码或合并多个代码片段,从而实现更易管理和可追踪的任务分解。
ODS 提示示例:图 8 说明了使用 Translator 将用户查询转换为子问题。
• Key(键) :使用 Selector 缩小相关键的范围
• Entity(实体) :识别查询中涉及的特定实体
• Reduction(归约) :为常见的归约运算符(例如 groupby, top, avg)提供内置提示
• Time Range(时间范围) :将时间范围转换为开始和结束值
• Transformation(转换):应用复杂的函数,如平滑和计算样本之间的差异
如图 8 所示,ODS 提示示例使用 Translator 将用户查询转换为子问题,包括使用 Selector 缩小相关键的范围,识别查询中的特定实体,为常见归约运算符提供内置提示,将时间范围描述转换为开始和结束值,并应用诸如平滑或计算样本间差异等复杂函数。
4.2.4 内置验证 (Built-in Validation).
网络用例具有严格的安全要求,这使得 Confucius 必须包含各种验证。我们强调内置验证,这减少了人工验证所需的手动工作量,同时使错误消息能够自动反馈给大语言模型进行自动纠正。具体而言,Confucius 采用三种内置方法来验证生成 DSL 的正确性。
• 内置解析器 (Built-in Parser):对于某些专门的 DSL(例如 TML),我们使用自定义解析器来检查语法。如果解析器失败,它会提供一条清晰的错误消息,该消息会反馈给大语言模型,使其能够从错误中学习并调整其下一次尝试。这个迭代过程会一直持续,直到输出成功解析或达到允许的最大尝试次数。
• 外部 API (External API):我们依靠消费 DSL 的 API 来检查它们的正确性。例如,Robotron 模型通过读取和写入操作进行验证。数据库的 ORM 层在读取操作期间检测错误,而"试运行"模式在不向数据库提交更改的情况下模拟写入操作。
• 外部工具 (External Tools):我们利用单独的验证系统来保证操作安全。例如,对于 TML 生成的图,我们使用图验证器根据预定义的不变量(如全连通性和最小路径要求)检查拓扑。检测到的错误会被反馈给大语言模型。
4.3 记忆管理 (Memory Management)
Confucius 使用记忆管理来保持对话连贯性并启用上下文搜索。Confucius 维护短期记忆和长期记忆,短期记忆包括单个用户会话中的对话历史记录,长期记忆包括与同一用例的不同会话相关的外部领域知识。
4.3.1 短期记忆 (Short-Term Memory).
短期记忆存储了一个用户在不同 Analect 中的上下文。例如,如果用户询问了区域 A 的总出站流量,然后询问了区域 B 的情况,那么第一个问题中的上下文应有效地被重用于第二个查询。为了支持跨 Analect 的上下文共享,我们开发了一个专用的记忆管理器组件,它使用消息树作为记忆的抽象。每个 Analect 都有自己的记忆管理器,该管理器维护一个私有消息列表以及指向父记忆、会话记忆和其他相关上下文的指针。这种分层结构允许 Analect 访问和管理其父级、祖父级、条目和会话中的消息,从而全面理解对话历史记录。Analect 可以独立控制对其消息的访问,确保消息历史的完整性和隔离性。系统还在父级以原子方式分组和处理消息,有效地管理并发的子 Analect 调用,从而提高系统的效率和准确性。
4.3.2 RAG.
我们发现许多网络管理用例需要外部索引以提高大语言模型查询的效率。例如,面对数十万个网络数据模型,其中许多具有相似性,如果没有特定领域的知识,很难区分它们。为了解决这种复杂性,我们开发了一种专门为网络数据模型设计的新颖 RAG 方法。我们的方法涉及通过将相似模型分组在一起,并一次将每个模型馈送给大语言模型,来预先计算嵌入存储。这在查询处理期间实现了高效的相似性搜索,有效管理了我们数据库的规模和复杂性。当用户提交查询时,它被分解为子查询以进行更有效、更准确的处理。使用相似性搜索算法将每个子查询与我们存储库中的嵌入进行比较,该算法识别出最相似的嵌入。检索到的嵌入然后连同用户的原始查询一起反馈到大语言模型中。图 16 显示了一个示例。我们在下文根据不同的用例应用不同的 RAG。
• 基础 RAG (Naive RAG):它为各种数据源构建向量存储并执行相似性搜索。适用于小数据集。
• 混合 RAG (Hybrid RAG):我们使用两阶段过滤方法来检索相关信息:首先获取相似性搜索结果并按相关性对其进行排名,然后我们应用其他过滤器,如陈旧度、评级和使用频率。预过滤的结果被发送到大语言模型以基于语义进行二次过滤。它应用于 Wiki、Workflow 和 Robotron Model。
• 查询转换 (Query Transformations):我们使用大语言模型来优化用户查询,生成更准确和相关的搜索结果。这涉及两个步骤:根据用户输入优化问题,并采用收集器模式通过与用户的对话来收集额外的上下文。这种方法在网络任务可以通过多种模糊方式描述的情况下非常有用。
4.3.3 隐私 (Privacy).
为了防止与第三方大语言模型共享敏感信息,我们实施了一个预处理步骤来匿名化敏感数据。用户在与大语言模型交互时可能会无意中输入个人身份信息 (PII) 数据;示例包括来自客户端的 IP 地址、设备标识符、姓名、电子邮件和用户位置。我们使用由不同团队开发的标识符脱敏服务 (Identifier Redaction Service) 来识别并将 40 种类型的敏感信息替换为虚构的占位符。在处理内容并收到大语言模型的响应后,我们反转匿名化过程,将占位符替换为原始的敏感数据。这确保了所有交互中用户信息的完整性和机密性。
4.4 基准测试框架 (Benchmarking Framework)
我们创建 Confucius 是为了让网络工程师能够跨各种网络用例快速接入和原型化不同的应用程序。然而,优化 Confucius 应用程序可能是一项复杂的任务,用户通常希望在特定数据集上比较不同模型和提示工程技术的性能。为了简化这一过程,我们开发了一个具有三项功能的基准测试框架:1) 使用开发人员为其特定用例提供的数据进行测试,2) 评估不同提示技术和基础模型的影响,以及 3) 优化端到端性能并调整准确性和计算成本之间的权衡。这标准化了评分过程,消除了临时手动测试的需求,并确保了评估的一致性。
工作流 (Workflow)。评估管道由三个关键组件组成:用户提供的数据集、Confucius 应用程序和一组评估标准。评估器首先读取输入-输出对的数据集,并在这些输入上调用应用程序。然后,它收集实际输出,并使用预定义的标准针对预期输出进行评分。用户可以将分数可视化,以比较不同评估之间的性能。
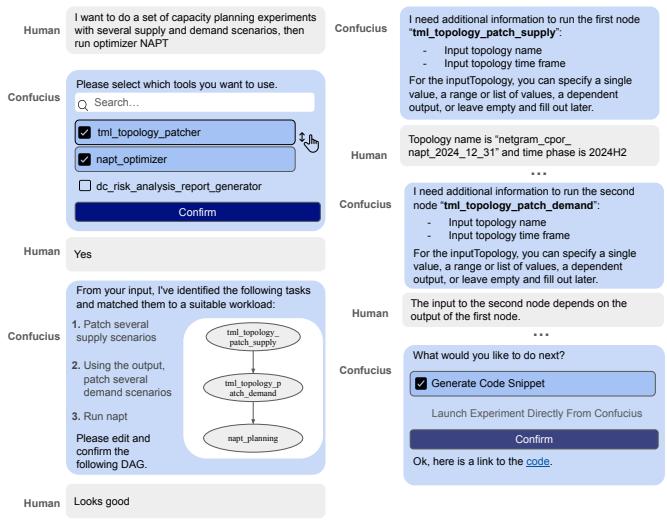
图 9: 容量假设分析会话示例。
评估标准 (Evaluation Criteria) 。我们提供三种内置评估标准:1) 精确匹配 (Exact Match) :用于确定性和数字输出,例如验证集群中的设备数量;2) 正则表达式匹配 (Regex Match) :适用于集合或字符串输出,以验证特定的关键字;3) LLM 作为裁判 (LLM-as-a-Judge):对于复杂的输出,它判断含义的相似度。我们通过使用实际和预期输出调用大语言模型,并提示大语言模型根据准确性分配分数来实现 LLM-as-a-Judge。这种方法支持复杂的推理并提供整体评分。我们的评估框架已在生产环境中成功实施,大大减少了在提示工程和识别回归上花费的时间。它用于生成 §7 中的评估结果。
请注意,基准测试框架是生产系统的组成部分,就像测试框架对软件开发过程不可或缺一样。我们的基准测试框架采用软件测试的概念,同时广泛利用大语言模型来处理模糊匹配情况。
5 应用程序案例研究 (Application Case Study)
在本节中,我们分享了两个用于容量规划和故障排查的应用程序。
5.1 容量假设分析 (Capacity What-Ifs)
Meta 开发了各种工具来促进对不同拓扑规划场景的分析。然而,运行实验仍然具有挑战性。在 Confucius 之前,生成实验计划很复杂,并且涉及几个步骤:识别输入工作负载、理解输入/输出结构以及编写顺序工具调用的脚本。用户面临多重挑战。首先,实验可能很快变得复杂,涉及多个工作负载和场景。一些工作流需要多次运行规划软件 NAPT 8,每次耗时数小时。其次,许多任务是重复的。容量规划人员经常不得不反复克隆和启动工作流来修改单个输入参数,导致效率低下。第三,跟踪和记录实验结果很繁琐。最后,工作负载之间的互操作性很低。例如,规划人员可能知道如何生成需求预测,但在将其与 NAPT 集成时会遇到困难,这增加了工作流的摩擦。
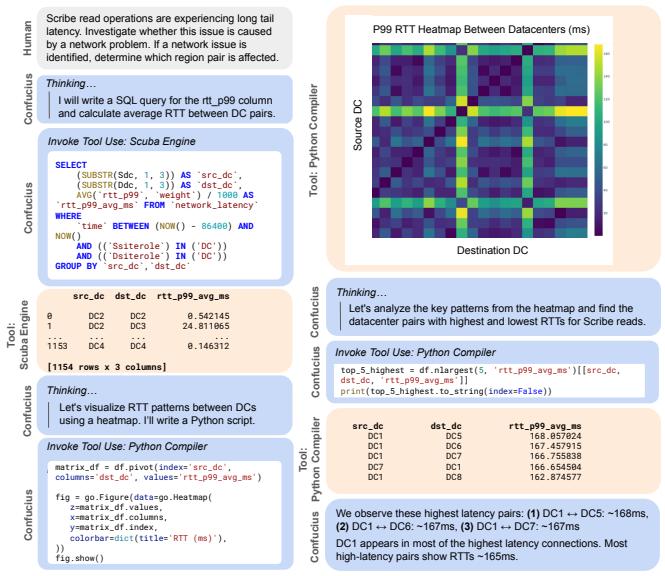
图 10: 故障诊断会话示例
为了缓解这些困难,我们在 Confucius 上构建了一个假设分析,包括一个用于创建 DAG 工作流的规划智能体、一个用于将拓扑更改转换为 TML 的工具智能体,以及一个用于记录每次运行结果的短期记忆。这被新手规划人员用来描述和执行实验。图 9 显示了一个示例工作流。首先,用户描述一个意图:生成 TML 以修补几个供应场景,然后生成 TML 以修补几个需求场景,最后运行 NAPT。这个过程涉及几个关键步骤,从创建 DAG 开始,Confucius 根据用户意图协助选择工作负载。用户使用 Selector 从实时注册的工作负载列表中进行选择,之后规划智能体创建相应的 DAG。对于每个节点,系统提供输入预选、使用自然语言的输入/输出传递以及节点信息收集过程的可视化,以及特定于输入的提示,以确保节点之间的互操作性。最后,Confucius 使用 Translator 生成 TML 代码片段。在每个步骤中,Confucius 通过使用 Collector 支持人工干预来确保灵活性和准确性。
5.2 故障诊断 (Fault Diagnosis)
传统上,即使对于经验丰富的工程师来说,网络故障排查也具有挑战性。本节介绍了一个使用 Code Assist(代码助手)的示例,这是一个利用 Orchestrator 进行高级规划的 AI 编码助手。图 10 说明了故障排查工作流。用户请求诊断与 Scribe 发布/订阅系统 26 中的读取操作相关的网络延迟问题。Confucius Code Assist 随后执行一系列交错的思考和工具使用步骤,例如使用 SQL 查询 Scuba 5 日志并编写用于数据分析和可视化的 Python 代码。它甚至生成了 RTT 数据的热图以提供见解,展示了其先进的多模态功能。最终,Confucius 识别出具有最高延迟的区域对涉及"DC1"数据中心,并将这些发现呈现给用户。
通过查询和分析常见的监控数据和运行时指标,可以解决许多故障排查场景。这些数据可以以各种方式进行过滤和聚合,从而产生为特定场景量身定制的工作流。用户不提供预定义的工作流,而是向 Confucius Orchestrator 提供一个工具使用函数列表,例如在特定数据库上执行 Python 或 SQL 代码。这些工具表示为可定制的智能体。利用 Claude 3.7 Sonnet 等高级模型,Confucius Orchestrator 充当智能主管,执行"思考"步骤以确定调用哪些智能体工具以及传递哪些参数。这种架构提供了灵活性,允许 Orchestrator 根据对话历史和可用工具决定下一步,而不是遵循固定的工作流。
6 实现 (Implementation)
Confucius 是使用 Python 开发的,允许它利用广泛的可重用外部系统和基于 Python 的内部服务。其工程组件也如图 4 所示。核心抽象类 Analect 充当 LangChain Runnable 的轻量级包装器。每个 Analect 都是强类型的,需要 Pydantic Input、Pydantic Output 和 impl 方法。Pydantic 2 是一种 Python 模式语言,它提供了贯穿 Confucius 使用的几个基本功能,例如类型验证、序列化、泛型和继承。使用基类 Analect,我们定义了前面提到的所有其他原语,包括 Translator、Selector、Collector、Ensemble 和 Orchestrator。为了开发人员的方便,我们还定义了一个称为 Entry 的专用 Analect。Entry 确保输入和输出类型都是字符串,分别封装在 EntryInput 和 EntryOutput 对象中。短期记忆使用内置的 AnalectRunContext 实现,这是一个自定义的 Pydantic 对象,存储相关的元数据和上下文数据,例如会话 ID、对话历史记录和先前生成的工件。可选地,AnalectRunContext 可以为长期记忆指定记忆管理器,这通过访问基于 MySQL 的数据库系统来实现。附录中的图 17 说明了使用 Pydantic 和 AnalectRunContext 来实现 ODS 翻译的 Analect。
7 评估 (Evaluation)
我们在各种网络管理任务上系统地评估了 Confucius。首先,我们展示了基于集成的自洽性提高了性能。接下来,我们展示了 Confucius 如何利用不同的基础模型来执行 DSL 翻译,并且准确率高于微调的基线模型。最后,我们评估了 RAG 的优势。
7.1 方法 (Methodology)
数据集 (Datasets) 。我们为以下用例策划了合成数据集:TML、ODS 转换、ODS 归约、Robotron、Netgram 和 Wiki Q&A。每个数据点包含一个自然语言查询及其真实答案。每个数据集的大小 NNN 如图 12 和图 13 所示。
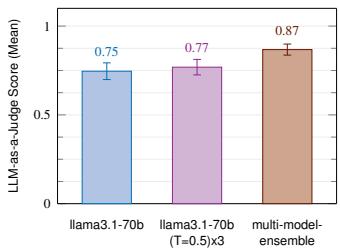
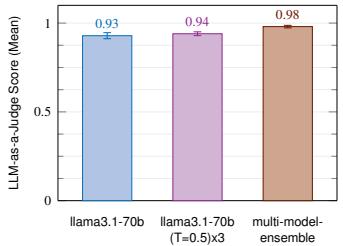
图 11: 单模型与集成模型在 ODS 归约(左)和转换(右)上的性能对比。
指标 (Metrics)。为了评估 Netgram,我们使用"正则表达式匹配 (regex match)",如果大语言模型输出包含真实 Netgram 块的名称以及指向该块源代码的正确 URL 链接,则得 1 分;如果只正确识别了其中一个,则得 0.5 分。对于所有其他数据集,我们使用 LLM-as-a-Judge 给出介于 0 和 1 之间的整体评分。
模型 (Models)。在我们的实验中,我们利用了几个通用的基础模型:Llama 3.1 和 3.3,Claude 3.5 Sonnet,Gemini 1.5 Pro 和 2.0 Flash,以及 GPT-4o。我们还使用了一个在特定领域数据(包括代码数据、wiki 文档和内部问答)上微调的内部模型。
基线 (Baselines)。在 §7.2 中,我们使用 Llama 3.1 评估了集成 (Ensemble) 与单模型生成的对比。在 §7.3 中,我们在几个 DSL 翻译任务上将 Confucius 与微调模型进行了比较,说明了将领域知识精心嵌入到提示词中的优势,而不是将这些领域知识包含在模型的训练数据中。在 §7.4 中,我们在几个依赖大量特定于这些用例的知识的用例上评估了 Confucius。与 DSL 评估类似,我们将 Confucius 与微调模型进行比较,以说明通过 RAG 检索领域知识的优势,而不是将领域知识嵌入到模型的训练数据中。我们还展示了如 §4.3.2 中所述的混合 RAG 和查询转换的有效性。
7.2 用于多智能体推理的集成 (Ensemble for Multi-Agent Reasoning)
Ensemble 是提高规划准确性的关键原语。我们评估了它对翻译 ODS 归约和转换的准确性的影响,设置如下:(1) 使用 Llama 3.1 的单模型生成,(2) 结合三个温度为 0.5 的 Llama 3.1 模型的同构集成,以及 (3) 结合一个 Llama 3.1、Claude 3.5 Sonnet 和 Gemini 2.0 Flash 模型的异构集成。对于集成实验,我们使用 Llama 3.1 根据 Confucius 关于任务的内部知识选择最佳答案。
图 11 显示,对于这两个数据集,所有集成设置的表现都严格优于单模型设置。我们观察到多模型集成实现了最佳性能,在 ODS 归约上得分为 0.87,在转换上得分为 0.98。此外,集成通过聚合不同智能体输出中的不一致性来减少分数的差异。图 11 显示,多模型集成将基线的标准误差分别降低了 34%(ODS 归约)和 57.6%(转换)。
(a) TML (NNN = 20)
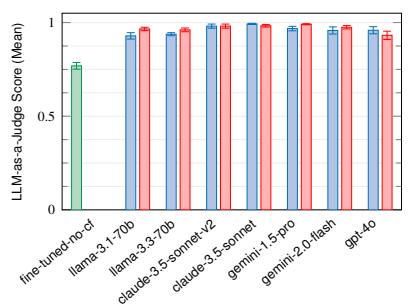
(b) ODS 转换 (NNN = 91)
© ODS 归约 (NNN = 48)
图 12: DSL 翻译的评估结果。
7.3 DSL 翻译 (DSL Translation)
实验设置 (Experimental Setup)。我们针对 §4.2 中介绍的结构化数据类型评估 DSL 翻译:用于拓扑图的 TML,用于数据模型的 Robotron,以及用于时间序列的 ODS 归约/转换。我们将 Confucius 与微调基线进行比较,以强调仔细进行提示工程的好处。
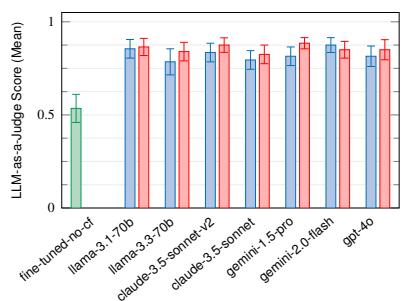
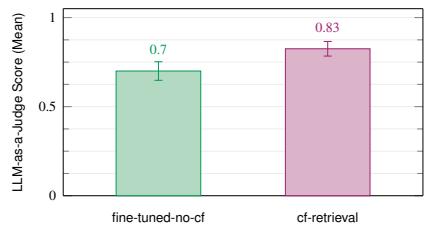
结果与分析 (Results and Analysis)。对于 Robotron 用例,我们使用 Llama 3.1 评估 Confucius 的端到端性能,这涉及使用 Translator 从自然语言查询中提取和关联实体,以及使用检索来查找最相关的数据模型。图 13a 显示 Confucius 的性能超过微调基线 13%。这不仅强调了其将自然语言翻译为 Robotron 查询的能力的有效性,而且强调了其通过上下文检索识别正确数据模型的能力。
对于 TML 和 ODS 实验,我们在 7 个不同的基础模型上评估了 Confucius,比较了使用和不使用思维链 (CoT) 提示的性能。如图 12 所示,Confucius 的表现优于基线:在 TML 上提高了高达 35%,在 ODS 转换上提高了 22.4%,在 ODS 归约上提高了 23%。我们将这些结果归因于 Confucius 领域感知提示词的有效性,特别是其使用结构化提示词和内置验证来生成准确、格式良好的响应。此外,Confucius 在不同的基础模型上表现一致。与受训练数据限制的微调模型不同,Confucius 为开发人员提供了更大的灵活性,以利用新的大语言模型。
图 12 还显示,通过结合 CoT 提示词,Confucius 进一步提高了其在大多数基础模型上的性能,在 TML 上使用 Gemini 2.0 Flash 的准确性显著提高了 7%。在少数情况下,使用 CoT 会影响性能;例如,当使用 GPT-4o 进行 ODS 转换时,Confucius 在没有 CoT 的情况下的平均得分为 0.959,而在有 CoT 的情况下的平均得分为 0.932。在这些情况下,我们发现 CoT 有时会鼓励模型过度思考并生成过于复杂的响应。为了说明这一点,考虑一个请求"计算过去 10 分钟内的数据点"。虽然正确的 ODS 转换是"count(10m)",但 CoT 提示词导致模型包含了在提示词中看到的不必要术语,结果变为"latest(10m), count(10m)"。尽管如此,CoT 提示词仍然提高了所有翻译数据点中 92.4% 的准确性,强调了中间推理步骤在 DSL 翻译中的价值。
| 指标 (Metric) | 值 (Value) |
|---|---|
| 总用户数 (Total users) | 4.16K |
| 月活跃用户 (Monthly active users) | 2.63K |
| 总会话数 (Total sessions) | 241.38K |
| 总消息数 (Total messages) | 31.62M |
| 接入用例数 (Use cases onboarded) | 64 |
| AI 与人类消息比例 (AI to human msg ratio) | 20.54 |
| 指标 (Metric) | 性能诊断 (Performance Diagnosis) | 假设规划 (What-if Planning) |
|---|---|---|
| 总用户数 (Total users) | 121 | 605 |
| 总会话数 (Total sessions) | 1.86K | 2.66K |
| 总耗时(小时) (Total time spent (hr)) | 835.58K | 207.33K |
| 总消息数 (Total messages) | 4.17M | 2.36M |
| AI 与人类消息比例 (AI to human msg ratio) | 2.46 | 7.65 |
表 2: Confucius 使用统计。
7.4 用于知识检索的 RAG (RAG for Knowledge Retrieval)
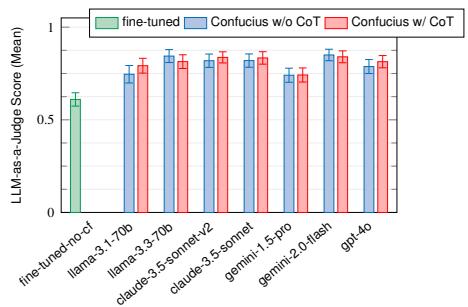
实验设置 (Experimental Setup)。我们评估了 RAG 与微调数据中的领域知识的使用,以及混合 RAG 和查询转换在 Meta 的 3 个网络用例上的优势:Robotron、Netgram 和 Wiki Q&A。
• Robotron:Confucius 通过上下文学习从 400 多个所需模型中进行检索。(有关此实验的讨论,请参见 §7.3。)
• Netgram:Confucius 从包含 118.6K 个向量和大约 1.24 GB 内存占用的嵌入存储中进行检索。
• Wiki Q&A:Confucius 从包含 3.3M 个向量和大约 33.5 GB 内存占用的嵌入存储中进行检索。
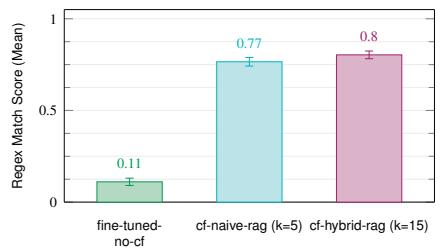
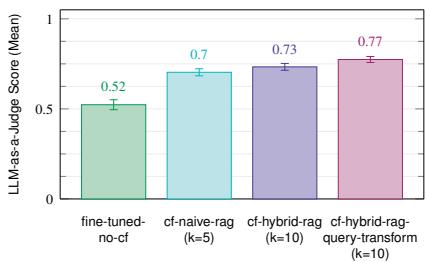
结果与分析 (Results and Analysis) 。如图 13 所示,Confucius 在所有检索任务上均优于微调基线。我们针对不同的 KKK 值评估了 RAG,其中 KKK 是通过相似性搜索检索到的邻居数量。当 KKK > 5 时,我们应用混合 RAG 技术从检索到的候选项中过滤出前 5 个最相关的响应。我们的结果表明,当我们将 Netgram 和 Wiki Q&A 的 KKK 分别增加到 15 和 10 时,混合 RAG 使性能提高了 3%。然而,虽然 RAG 受益于更大的初始候选项池,但将 KKK 增加到某个点之后会导致收益递减。对于 Wiki Q&A,为了减少匹配长文档时的噪声,我们应用查询转换技术在检索之前使用大语言模型从用户查询中提取关键术语。图 13c 显示,该技术在 KKK = 10 时将 Confucius 的性能从 0.73 提高到 0.77。
7.5 采用和使用统计 (Adoption and Usage Statistics)
我们提供了有关 Confucius 在真实生产中使用的见解。Confucius 在过去一年中取得了显着的增长和采用,拥有 4.16K 名总独立用户、241.38K 个会话和 31.62M 条消息(参见表 2)。自初步发布以来,我们已接入了 60 多个用例;著名的应用程序包括容量规划的性能诊断和假设分析,它们分别生成了 4.17M 和 2.36M 条消息。易于开发的设计使得接入的用例以及开发人员社区能够如此快速地增长。我们还观察到 AI 生成的消息与人类消息的比例很高:所有用例的比例为 20.54,性能诊断的比例为 2.46,假设规划的比例为 7.65。这表明在大多数交互中需要的人为干预相对较少,而性能诊断的较低比例反映了故障排查任务的难度。表 3 总结了跨不同网络管理任务类别的应用程序,详细说明了使用的原语、Analects 和代码行数 (LoC)。最后,图 14 显示了每个应用程序每周节省的总工程师小时数,正如调查数据所报告的那样。
(a) Robotron (NNN = 12)
(b) Netgram (NNN = 226)
© Wiki Q&A (NNN = 250)
图 13: RAG 的评估结果。
| 应用程序 (Apps) | 使用的原语 (Primitives Used) | 使用的基础 Analects (Foundational Analects Used) | 每周使用次数 (# Usage per week) | 代码行数 (LoC) | 每次使用节省的小时数 (Per Usage Saved Hours) |
|---|---|---|---|---|---|
| ODS | 时间序列 (Time Series) | Collector, Translator, Selector | 50 | ~1600 | 0.25 |
| 假设分析 (What-if) | 时间序列、图 (Time Series Graph) | Collector, Translator, Selector | 20 | ~3500 | 0.5 |
| 网络设计 (Network Design) | 图 (Graph) | Collector | 50 | ~1000 | 0.2 |
| 工作流 (Workflow) | 图、数据模型 (Graph Data Model) | Collector, RAG | 30 | ~800 | 0.3 |
| 监控 (Monitoring) | 数据模型 (Data Model) | Collector, RAG | 80 | ~600 | 0.5 |
| 故障排查 (Troubleshooting) | 时间序列、图 (Time Series, Graph) | Collector, Ensemble, Orchestrator | 100 | ~6400 | 0.2 |
表 3: 应用程序摘要。
8 经验 (Experiences)
本节分享我们开发 Confucius 和接入应用程序的生产经验。
8.1 Meta 内部基于 LLM 的网络助手的演变 (Evolution of LLM-based network assistants at Meta)
最初,我们尝试使用 MetaMate 来执行网络管理任务。MetaMate 是一个通用的内部聊天机器人,旨在提高跨产品垂直领域和工作职能的生产力。它旨在帮助开发人员从代码和非代码源进行代码创建和知识获取、合成以及理解。为了实现这些目标,我们使用 Meta 的内部上下文微调了 AI 模型,包括除了技术和非技术知识之外的我们的代码库。我们还利用公开可用的知识来增强模型的功能。尽管 MetaMate 显示出了前景,但我们遇到了一些挑战,这导致我们设计了 Confucius,一个更专业的网络助手。
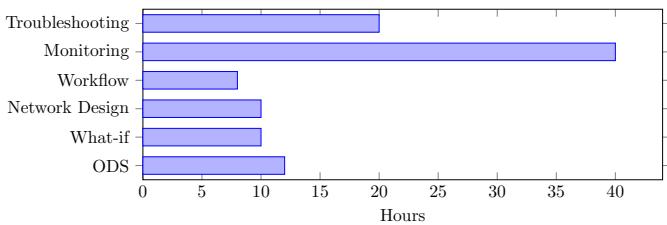
图 14: 每周节省的工程师小时数。
与 MetaMate 相比,Confucius 在目的、功能和目标受众方面有所不同:
• 目的 :MetaMate 是一个通用的 AI 助手,而 Confucius 专为 MetaMate 结果可能欠佳的特定用例而设计。
• 功能 :MetaMate 提供聊天 UI、命令执行和代码补全等功能,而 Confucius 依赖于在安全环境中执行的自定义脚本。
• 目标受众:MetaMate 适用于通用的内部数据检索和协助 Meta 内不同平台上的用户,而 Confucius 则是为需要执行需要自定义脚本并在执行中具有更高安全级别的特定任务的用户量身定制的。
8.2 哪些做法行之有效 (What Worked Well)
针对网络问题的检索和总结。我们观察到许多网络应用程序具有一个共同的模式:利用现有内容来建议类似的项目,并通过用户修改生成新的项目。一些示例包括基于数据库中的现有模型编写新模型、通过调整现有的供应商/设备配置来生成设备配置,以及通过组合多个现有工作流中的步骤来创建自定义工作流。Confucius 的嵌入和检索方法能够与 RAG 提示工程直接集成,通常会产生令人满意的结果。
与现有的管理工具集成以实现快速采用。最初的一个挑战是吸引一致的用户使用该应用程序。用户会将其作为一种新奇事物来尝试,但很难将其纳入他们的日常工作中。我们发现与现有的自动化系统和工具集成是更广泛采用的关键。这些系统具有定义良好的输入和输出结构以辅助自动化。通过理解和生成这些结构化数据,大语言模型可以被添加到现有的自动化管道中,从而促进日常使用。
例如,我们的维护事件解析器可以解析供应商电子邮件并生成结构化票据,它已作为票据管理系统的一部分每天被调用数百次。
8.3 经验教训 (Lessons learned)
网络问题中迭代过程的重要性。我们发现许多网络管理任务很复杂,通常被建模为调用多个工具的工作流。然而,准确地编写工作流需要对所有涉及的工具有深厚的领域知识。为了解决这个挑战,Confucius 的设计包含一个在 UI 中演示中间步骤的工件,允许开发人员逐步处理工作流。这种方法使开发人员能够首先勾勒出整体步骤,然后放大每个单独步骤的细节。
大语言模型在网络故障排查中的局限性。在所有应用程序中,我们观察到网络故障排查问题的变体最多,并且很难实现与领域专家同等的性能。事实上,专家也是基础模型和命令的大师,这使得大语言模型很难作为辅助工具带来显著的价值。这类似于 ChatGPT 可以帮助学生改进写作,但可能对专业作家的帮助不那么大。网络故障排查由于缺乏结构也具有挑战性。虽然大语言模型可以遵循 MOP 来诊断简单的问题,但最困难的问题通常无法通过 MOP 解决,因此无法通过清晰的步骤进行建模,这使得大语言模型力不从心。
失败场景。我们明确强调了我们观察到的 Confucius 和大语言模型普遍存在的问题。1) 上下文传播可能会在会话的后期丢失。例如,在故障排查场景中,用户可能首先询问一天中特定时间段内的丢包情况。虽然 Confucius 遵循故障排查计划,但特定的时间限制可能无法一致地应用于所有后续操作,特别是在步骤很长的情况下。在这些情况下,采用提示工程重申重要的约束可以帮助缓解这个问题。2) 幻觉和未能尽早失败。在网络应用程序中,幻觉仍然是一个重大问题。当大语言模型无法从指定的数据源中找到答案时,它们往往会捏造响应。这种行为与尽早确定性失败的原则相矛盾,而该原则是大多数计算机系统的基础。这些捏造的答案会导致人工调查的效率低下。3) 隐私问题。一些网络调查需要访问应用程序和服务数据,每种数据都具有不同级别的隐私。由于违反隐私而导致的错误并没有被大语言模型清楚地强调,构成了潜在风险。
9 相关工作 (Related work)
通用的智能体框架 (General-Purpose Agentic Frameworks)。Confucius 建立在 LangChain 13 之上,并提供了几个额外的优势,包括追踪、常见原语和可运行项的可重用性,以及跨工具的互操作性。与 Confucius 类似,LangGraph 29 将复杂任务分解为有向图,节点代表子任务。AutoGen 50 是另一个多智能体框架,它将任务分解为由定制智能体执行的更小子任务。我们的工作有所不同,我们通过对数百个现有工作流进行检索来为特定领域任务建议 DAG,而不是依赖于基于对话的控制流,后者可能会为敏感的网络任务引入不确定性。
结合大语言模型的网络任务 (Networking Tasks with LLMs)。He 等人 25 采用大语言模型开发自适应比特率 (ABR) 算法,这是在流媒体传输中动态调整视频质量的关键组件。Sharma 等人 43 提出了 PROSPER,这是一个基于大语言模型的框架,用于从 IETF 征求意见稿 (RFCs) 描述的网络协议中提取有限状态机 (FSMs)。Mani 等人 35 使用大语言模型生成用于拓扑管理的图形操作代码,而 Mondal 等人 39 应用大语言模型来综合路由器配置。定制的大语言模型也得到了开发 20, 37, 49, 53,其中利用网络数据(如流量流)构建了超越自然语言的基础模型,这些模型可适用于诸如流量分类和攻击检测等下游任务。
系统级应用 (System-Level Applications)。Lian 等人 33 开发了一个名为 Ciri 的基于大语言模型的框架,以增强部署前的配置验证,消除了对人工检查和工程的严重依赖。Kotaru 28 引入了操作员数据智能助手 (DIO Copilot),这是一个利用大语言模型进行高效数据检索和分析的自然语言界面,建立在语义搜索和少样本学习之上。除了数据检索和分析之外,还探索了其他应用程序,例如事件管理和调查 24, 54、机器可读协议语法提取引擎 ChatAFL 36 以及基于大语言模型的 DDoS 防御框架 ShieldGPT 48 等。最近的工作也开发了用于复杂系统管理的智能体框架,包括 LLo11yPop 22(用于 GPU 机队管理的可观测性智能体框架)和 AssetOpsBench 40(编排用于工业资产管理的多智能体工作流)。
10 结论 (Conclusion)
在本文中,我们介绍了 Confucius,这是一个多智能体大语言模型 (LLM) 框架,旨在解决 Meta 网络管理的复杂挑战。通过将推理与特定领域的知识和工具解耦,Confucius 实现了与现有基础模型的有效协作,而无需进行微调。我们的框架将管理任务分解为更小、结构化的子任务,允许使用特定领域的工具和数据库进行精确执行。我们通过 Confucius 在生产环境中的部署展示了它的有效性,服务了数千名用户和超过 60 个管理任务。Confucius 具有实现并彻底改变真正的基于意图的网络管理的潜力。
这项工作没有引发任何伦理问题。
11 致谢 (Acknowledgment)
这项工作是 Meta 网络基础设施团队内部密切合作的成果,特别是我们的实习生 Rae Wong 和 Jenny Li。我们要感谢 Steve Politis 和 Vipul Deokar 的领导支持,我们的指导者 Li Chen,以及匿名审稿人对本出版物早期草稿提供的建设性和宝贵反馈。Minlan Yu 得到了美国国家科学基金会拨款 CCF-2326605 和 ACE 的支持。
参考文献 (References)
1 2019. Cognitive Architectures: A Way Forward for Intelligent Systems. In Journal of Artificial Intelligence Research.
2 2024. Pydantic. https://docs.pydantic.dev/latest/.
3 2025. Knowledge Graph. https://en.wikipedia.org/wiki/Knowledge_graph.
4 2025. Meta Data Centers. https://datacenters.atmeta.com/.
5 Lior Abraham, John Allen, Oleksandr Barykin, Vinayak Borkar, Bhuwan Chopra, Ciprian Gerea, Daniel Merl, Josh Metzler, David Reiss, Subbu Subramanian, Janet L. Wiener, and Okay Zed. 2013. Scuba: diving into data at facebook. Proc. VLDB Endow. 6, 11 (Aug. 2013), 1057--1067.
6 Satyajeet Singh Ahuja, Vinayak Dangui, Kirtesh Patil, Manikandan Somasundaram, Varun Gupta, Mario Sanchez, Guanqing Yan, Max Noormohammadpour, Alaleh Razmjoo, Grace Smith, Hao Zhong, Abhinav Triguna, Soshant Bali, Yuxiang Xiang, Yilun Chen, Prabhakaran Ganesan, Mikel Jimenez Fernandez, Petr Lapukhov, Guyue Liu, and Ying Zhang. 2022. Network entitlement: contractbased network sharing with agility and SLO guarantees. In Proceedings of the ACM SIGCOMM 2022 Conference (Amsterdam, Netherlands) (SIGCOMM '22). Association for Computing Machinery, New York, NY, USA, 250--263.
7 Satyajeet Singh Ahuja, Varun Gupta, Vinayak Dangui, Soshant Bali, Abishek Gopalan, Hao Zhong, Petr Lapukhov, Yiting Xia, and Ying Zhang. 2021. Capacity-Efficient and Uncertainty-Resilient Backbone Network Planning with Hose. In Proceedings of the 2021 ACM SIGCOMM 2021 Conference (SIGCOMM '21). Association for Computing Machinery, New York, NY, USA, 547--559.
8 Satyajeet Singh Ahuja, Varun Gupta, Vinayak Dangui, Soshant Bali, Abishek Gopalan, Hao Zhong, Petr Lapukhov, Yiting Xia, and Ying Zhang. 2021. Capacityefficient and uncertainty-resilient backbone network planning with hose. In Proceedings of the 2021 ACM SIGCOMM 2021 Conference (Virtual Event, USA) (SIGCOMM '21). Association for Computing Machinery, New York, NY, USA, 547--559.
9 Alexey Andreyev, Xu Wang, and Alex Eckert. 2019. Reinventing Facebook's Data Center Network. https://engineering.fb.com/2019/03/14/data-centerengineering/f16-minipack/.
10 Steven Bird. 2006. NLTK: the natural language toolkit. In Proceedings of the COLING/ACL 2006 Interactive Presentation Sessions. 69--72.
11 Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, Diego De Las Casas, Aurelia Guy, Jacob Menick, Roman Ring, Tom Hennigan, Saffron Huang, Loren Maggiore, Chris Jones, Albin Cassirer, Andy Brock, Michela Paganini, Geoffrey Irving, Oriol Vinyals, Simon Osindero, Karen Simonyan, Jack Rae, Erich Elsen, and Laurent Sifre. 2022. Improving Language Models by Retrieving from Trillions of Tokens. In Proceedings of the 39th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 162), Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato (Eds.). PMLR, 2206--2240.
12 Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems (Vancouver, BC, Canada) (NIPS '20). Curran Associates Inc., Red Hook, NY, USA, Article 159, 25 pages.
13 Harrison Chase. 2024. LangChain: A Framework for Developing Applications Powered by Large Language Models (LLMs). https://github.com/langchainai/langchain.
14 Xu Chen, Yun Mao, Z. Morley Mao, and Jacobus Van der Merwe. 2010. Declarative configuration management for complex and dynamic networks. In Proceedings of the 6th International Conference (Philadelphia, Pennsylvania) (Co-NEXT '10). Association for Computing Machinery, New York, NY, USA, Article 6, 12 pages.
15 Xu Chen, Z. Morley Mao, and Jacobus Van der Merwe. 2009. PACMAN: a platform for automated and controlled network operations and configuration management. In Proceedings of the 5th International Conference on Emerging Networking Experiments and Technologies (Rome, Italy) (CoNEXT '09). Association for Computing Machinery, New York, NY, USA, 277--288.
16 Sean Choi, Boris Burkov, Alex Eckert, Tian Fang, Saman Kazemkhani, Rob Sherwood, Ying Zhang, and Hongyi Zeng. 2018. FBOSS: building switch software at scale (SIGCOMM '18). Association for Computing Machinery, New York, NY, USA, 342--356.
17 Mike Chow, Yang Wang, William Wang, Ayichew Hailu, Rohan Bopardikar, Bin Zhang, Jialiang Qu, David Meisner, Santosh Sonawane, Yunqi Zhang, Rodrigo Paim, Mack Ward, Ivor Huang, Matt McNally, Daniel Hodges, Zoltan Farkas, Caner Gocmen, Elvis Huang, and Chunqiang Tang. 2024. ServiceLab: Preventing Tiny Performance Regressions at Hyperscale through Pre-Production Testing. In 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Association, Santa Clara, CA, 545--562. https://www.usenix.org/conference/osdi24/presentation/chow
18 Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sashank Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier Garcia, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Diaz, Orhan Firat, Michele Catasta, Jason Wei, Kathy Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, and Noah Fiedel. 2023. PaLM: scaling language modeling with pathways. J. Mach. Learn. Res. 24, 1, Article 240 (Jan. 2023), 113 pages.
19 Marek Denis, Yuanjun Yao, Ashley Hatch, Qin Zhang, Chiun Lin Lim, Shuqiang Zhang, Kyle Sugrue, Henry Kwok, Mikel Jimenez Fernandez, Petr Lapukhov, Sandeep Hebbani, Gaya Nagarajan, Omar Baldonado, Lixin Gao, and Ying Zhang. 2023. EBB: Reliable and Evolvable Express Backbone Network in Meta. In Proceedings of the ACM SIGCOMM 2023 Conference (New York, NY, USA) (ACM SIGCOMM '23). Association for Computing Machinery, New York, NY, USA, 346--359.
20 Alexander Dietmüller, Siddhant Ray, Romain Jacob, and Laurent Vanbever. 2022. A new hope for network model generalization. In Proceedings of the 21st ACM Workshop on Hot Topics in Networks. 152--159.
21 Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. 2024. The faiss library. arXiv preprint arXiv:2401.08281 (2024).
22 Aaron Erickson. 2024. Optimizing Data Center Performance with AI Agents and the OODA Loop Strategy. https://developer.nvidia.com/blog/optimizingdata-center-performance-with-ai-agents-and-the-ooda-loop-strategy. NVIDIA Developer Blog.
23 David Gutiérrez-Avilés, Manuel Jesús Jiménez-Navarro, José Francisco Torres-Maldonado, and Francisco Martínez-Álvarez. 2024. MetaGen: A Framework for Metaheuristic Development and Hyperparameter Optimization. https://github.com/Data-Science-Big-Data-Research-Lab/MetaGen.
24 Pouya Hamadanian, Behnaz Arzani, Sadjad Fouladi, Siva Kesava Reddy Kakarla, Rodrigo Fonseca, Denizcan Billor, Ahmad Cheema, Edet Nkposong, and Ranveer Chandra. 2023. A Holistic View of AI-driven Network Incident Management. In Proceedings of the 22nd ACM Workshop on Hot Topics in Networks. 180--188.
25 Zhiyuan He, Aashish Gottipati, Lili Qiu, Francis Y Yan, Xufang Luo, Kenuo Xu, and Yuqing Yang. 2024. LLM-ABR: Designing Adaptive Bitrate Algorithms via Large Language Models. arXiv preprint arXiv:2404.01617 (2024).
26 Manolis Karpathiotakis, Dino Wernli, and Milos Stojanovics. 2017. Scribe: Transporting petabytes per hour via a distributed, buffered queueing system. https://engineering.fb.com/2019/10/07/data-infrastructure/scribe/.
27 Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open-Domain Question Answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 6769--6781.
28 Manikanta Kotaru. 2023. Adapting Foundation Models for Operator Data Analytics. In Proceedings of the 22nd ACM Workshop on Hot Topics in Networks. 172--179.
29 LangChain-AI. 2025. LangGraph. https://github.com/langchain-ai/langgraph.
30 Petr Lapukhov and Aijay Adams. 2016. NetNORAD: Troubleshooting networks via end-to-end probing. https://engineering.fb.com/2016/02/18/coredata/netnorad-troubleshooting-networks-via-end-to-end-probing/.
31 Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Proceedings of the 34th International Conference on Neural Information Processing Systems (Vancouver, BC, Canada) (NIPS '20). Curran Associates Inc., Red Hook, NY, USA, Article 793, 16 pages.
32 Yanhong Li, Karen Livescu, and Jiawei Zhou. 2024. Chunk-Distilled Language Modeling. arXiv preprint arXiv:2501.00343 (2024).
33 Xinyu Lian, Yinfang Chen, Runxiang Cheng, Jie Huang, Parth Thakkar, and Tianyin Xu. 2023. Configuration Validation with Large Language Models. arXiv preprint arXiv:2310.09690 (2023).
34 Ajay Mahimkar, Carlos Eduardo de Andrade, Rakesh Sinha, and Giritharan Rana. 2021. A composition framework for change management. In Proceedings of the 2021 ACM SIGCOMM 2021 Conference (Virtual Event, USA) (SIGCOMM '21). Association for Computing Machinery, New York, NY, USA, 788--806.
35 Sathiya Kumaran Mani, Yajie Zhou, Kevin Hsieh, Santiago Segarra, Trevor Eberl, Eliran Azulai, Ido Frizler, Ranveer Chandra, and Srikanth Kandula. 2023. Enhancing network management using code generated by large language models. In Proceedings of the 22nd ACM Workshop on Hot Topics in Networks. 196--204.
36 Ruijie Meng, Martin Mirchev, Marcel Böhme, and Abhik Roychoudhury. 2024. Large language model guided protocol fuzzing. In Proceedings of the 31st Annual Network and Distributed System Security Symposium (NDSS).
37 Xuying Meng, Chungang Lin, Yequan Wang, and Yujun Zhang. 2023. Netgpt: Generative pretrained transformer for network traffic. arXiv preprint arXiv:2304.09513 (2023).
38 Jeffrey C. Mogul, Drago Goricanec, Martin Pool, Anees Shaikh, Douglas Turk, Bikash Koley, and Xiaoxue Zhao. 2020. Experiences with modeling network topologies at multiple levels of abstraction. In Proceedings of the 17th Usenix Conference on Networked Systems Design and Implementation (Santa Clara, CA, USA) (NSDI'20). 403--418.
39 Rajdeep Mondal, Alan Tang, Ryan Beckett, Todd Millstein, and George Varghese. 2023. What do LLMs need to Synthesize Correct Router Configurations?. In Proceedings of the 22nd ACM Workshop on Hot Topics in Networks. 189--195.
40 Dhaval Patel, Shuxin Lin, James Rayfield, Nianjun Zhou, Roman Vaculin, Natalia Martinez, Fearghal O'Donncha, and Jayant Kalagnanam. 2025. AssetOpsBench: Benchmarking AI Agents for Task Automation in Industrial Asset Operations and Maintenance. arXiv:2506.03828
41 Tuomas Pelkonen, Scott Franklin, Justin Teller, Paul Cavallaro, Qi Huang, Justin Meza, and Kaushik Veeraraghavan. 2015. Gorilla: a fast, scalable, in-memory time series database. Proc. VLDB Endow. 8, 12 (Aug. 2015), 1816--1827.
42 Erik Schluntz, Simon Biggs, Dawn Drain, Eric Christiansen, Shauna Kravec, Felipe Rosso, Nova DasSarma, and Ven Chandrasekaran. 2025. Raising the Bar on SWEbench Verified with Claude 3.5 Sonnet. https://www.anthropic.com/research/swebench-sonnet.
43 Prakhar Sharma and Vinod Yegneswaran. 2023. PROSPER: Extracting Protocol Specifications Using Large Language Models. In Proceedings of the 22nd ACM Workshop on Hot Topics in Networks. 41--47.
44 Arjun Singh, Joon Ong, Amit Agarwal, Glen Anderson, Ashby Armistead, Roy Bannon, Seb Boving, Gaurav Desai, Bob Felderman, Paulie Germano, et al. 2015. Jupiter rising: A decade of Clos topologies and centralized control in Google's datacenter network. In SIGCOMM.
45 Hongjin Su, Weijia Shi, Jungo Kasai, Yizhong Wang, Yushi Hu, Mari Ostendorf, Wen-tau Yih, Noah A. Smith, Luke Zettlemoyer, and Tao Yu. 2023. One Embedder, Any Task: Instruction-Finetuned Text Embeddings. In Findings of the Association for Computational Linguistics: ACL 2023, Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (Eds.). Association for Computational Linguistics, Toronto, Canada, 1102--1121.
46 Yu-Wei Eric Sung, Xiaozheng Tie, Starsky H.Y. Wong, and Hongyi Zeng. 2016. Robotron: Top-down Network Management at Facebook Scale. In Proceedings of the 2016 ACM SIGCOMM Conference (Florianopolis, Brazil) (SIGCOMM '16). Association for Computing Machinery, New York, NY, USA, 426--439.
47 Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023).
48 Tongze Wang, Xiaohui Xie, Lei Zhang, Chuyi Wang, Liang Zhang, and Yong Cui. 2024. ShieldGPT: An LLM-based Framework for DDoS Mitigation. In Proceedings of the 8th Asia-Pacific Workshop on Networking (Sydney, Australia) (APNet '24). Association for Computing Machinery, New York, NY, USA, 108--114.
49 Duo Wu, Xianda Wang, Yaqi Qiao, Zhi Wang, Junchen Jiang, Shuguang Cui, and Fangxin Wang. 2024. Netllm: Adapting large language models for networking. In Proceedings of the ACM SIGCOMM 2024 Conference. 661--678.
50 Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang (Eric) Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Ahmed Awadallah, Ryen W. White, Doug Burger, and Chi Wang. 2024. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. In COLM 2024.
51 Jiarong Xing, Kuo-Feng Hsu, Yiting Xia, Yan Cai, Yanping Li, Ying Zhang, and Ang Chen. 2024. Occam: A Programming System for Reliable Network Management. In Proceedings of the Nineteenth European Conference on Computer Systems (Athens, Greece) (EuroSys '24). Association for Computing Machinery, New York, NY, USA, 148--162.
52 Ying Zhang, Nathan Hu, Carl Verge, and Scott O'Brien. 2022. Cross-layer diagnosis of optical backbone failures. In Proceedings of the 22nd ACM Internet Measurement Conference (Nice, France) (IMC '22). Association for Computing Machinery, New York, NY, USA, 419--432.
53 Jiawei Zhou, Woojeong Kim, Zhiying Xu, Alexander M Rush, and Minlan Yu. 2024. NetFlowGen: Leveraging Generative Pre-training for Network Traffic Dynamics. arXiv preprint arXiv:2412.20635 (2024).
54 Yajie Zhou, Nengneng Yu, and Zaoxing Liu. 2023. Towards Interactive Research Agents for Internet Incident Investigation. In Proceedings of the 22nd ACM Workshop on Hot Topics in Networks. 33--40.
附录 (Appendix)
附录是未经同行评审的支持材料。
A 补充图表 (Supplemental Figures)
bazel
ensemble_out = await self.invoke_anaelect(
AnalectEnsemble(),
AnalectEnsemble.input(
analect=analect_to_call,
inputs=inputs,
llm_params=[
LLMParams(model="llama3-70b-instruct"),
LLMParams(model="illama"),
],
output_mode=AnalectEnsembleOutputMode.FIRST,
) 图 15: Ensemble Struct 示例。
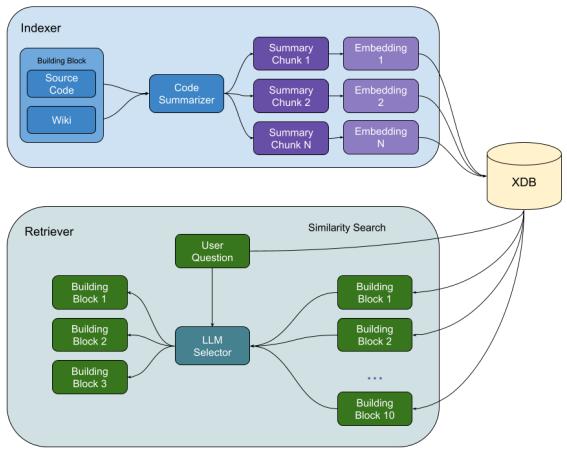
图 16: RAG 辅助规划。
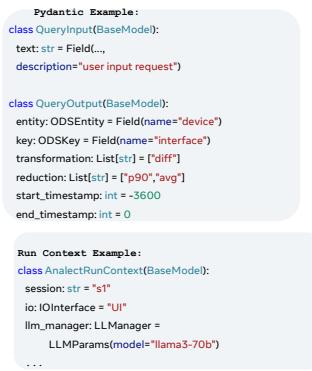

图 17: Pydantic、Analect 和 Run Context 的示例。

图 18: TML 用例的 Collector 示例。