Optimal Transport Aggregation for Visual Place Recognition
论文:[2311.15937 Optimal Transport Aggregation for Visual Place Recognition (arxiv.org)](https://arxiv.org/abs/2311.15937)
代码:https://github.com/serizba/salad
概括
提取特征 F F F和global token,先通过最优传输得到符合容量约束的分配 P,再用 P 作为权重,对降维特征 f 进行加权求和。最后结合全局token得到描述符。
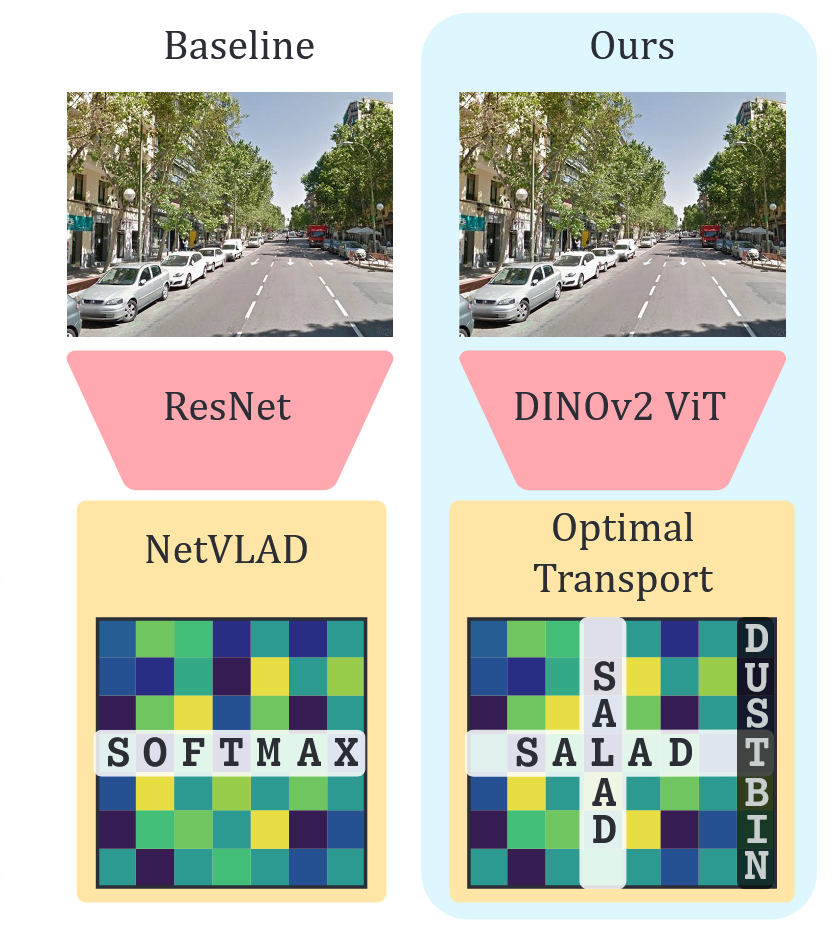
SALAD 相比 NetVLAD 的主要改进
1. 最优传输替代 Softmax 分配
- NetVLAD :使用 per-row softmax 计算每个特征到各聚类的软分配,只考虑特征→聚类的单向关系
- SALAD :将分配问题建模为最优传输(Optimal Transport) ,同时考虑特征→聚类和聚类→特征的双向约束,用 Sinkhorn 算法迭代求解
2. 引入 Dustbin(垃圾箱)聚类
- NetVLAD:所有特征都被强制分配到某个聚类,包括天空、道路等无信息区域
- SALAD :新增一个 dustbin 聚类,网络自动学习将非判别性特征 (动态物体、天空等)分配进去,仅用一个可学习参数 z z z 控制
3. 减少先验假设
- NetVLAD:用 k-means 初始化聚类中心,引入归纳偏置
- SALAD :score matrix 从随机初始化的全连接层 学习,聚合时直接求和而非减去聚类中心残差
4. 骨干网络升级
-
NetVLAD:使用 ResNet 等 CNN 骨干
-
SALAD :采用 DINOv2(ViT 架构),部分微调最后几层,显著提升特征表达力并缩短训练时间
## DINOv2 def forward(self, x): """ The forward method for the DINOv2 class Parameters: x (torch.Tensor): The input tensor [B, 3, H, W]. H and W should be divisible by 14. Returns: f (torch.Tensor): The feature map [B, C, H // 14, W // 14]. t (torch.Tensor): The token [B, C]. This is only returned if return_token is True. """ B, C, H, W = x.shape x = self.model.prepare_tokens_with_masks(x) # First blocks are frozen with torch.no_grad(): for blk in self.model.blocks[:-self.num_trainable_blocks]: x = blk(x) x = x.detach() # Last blocks are trained for blk in self.model.blocks[-self.num_trainable_blocks:]: x = blk(x) if self.norm_layer: x = self.model.norm(x) t = x[:, 0] f = x[:, 1:] # Reshape to (B, C, H, W) f = f.reshape((B, H // 14, W // 14, self.num_channels)).permute(0, 3, 1, 2) if self.return_token: return f, t return f
SALAD 的具体流程
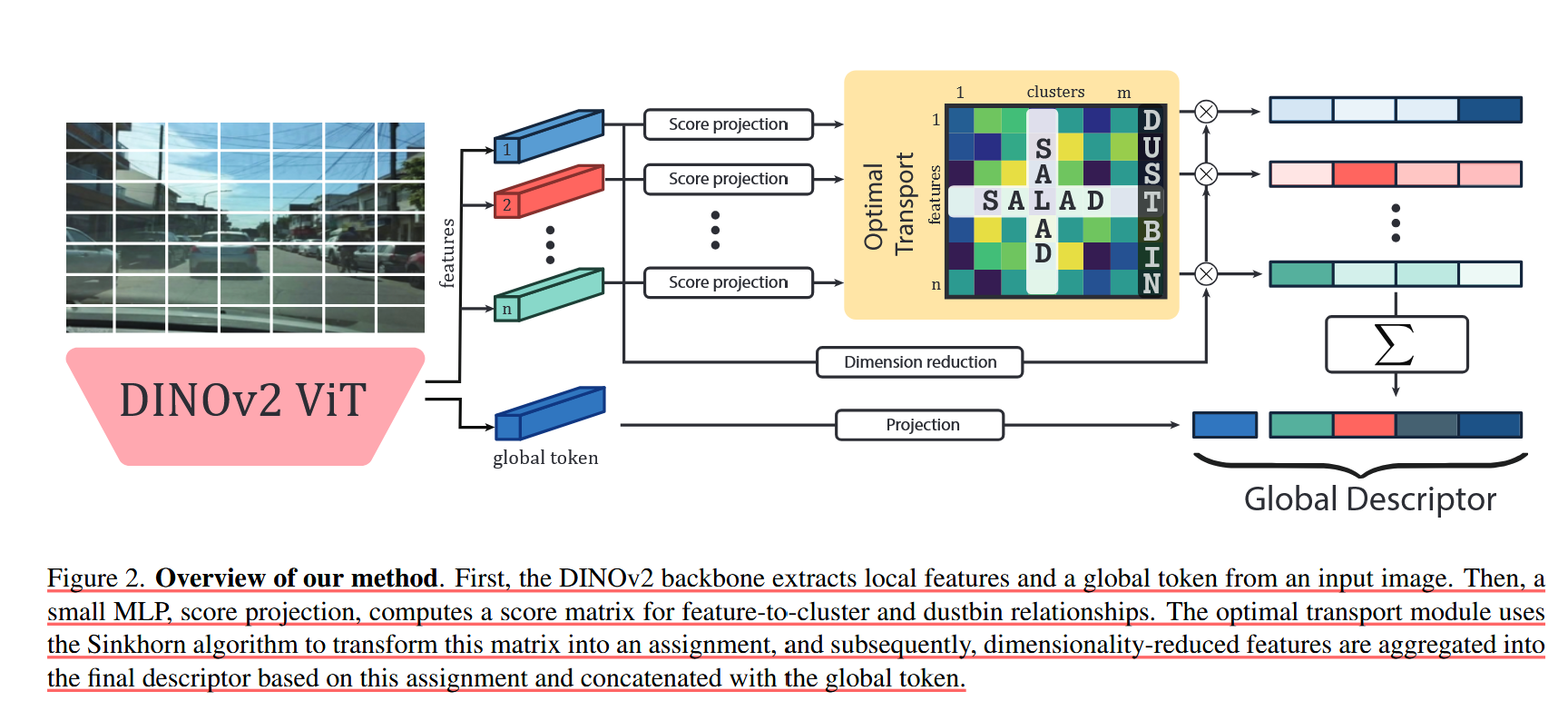
输入图像 → DINOv2 骨干 → 局部特征 + 全局 token → 降维 → 得分矩阵计算
→ Sinkhorn 最优传输分配 → 按分配聚合特征 → 拼接全局 token → L2 归一化 → 最终描述子论文核心代码
import math
import torch
import torch.nn as nn
# Code adapted from OpenGlue, MIT license
# https://github.com/ucuapps/OpenGlue/blob/main/models/superglue/optimal_transport.py
def log_otp_solver(log_a, log_b, M, num_iters: int = 20, reg: float = 1.0) -> torch.Tensor:
r"""Sinkhorn matrix scaling algorithm for Differentiable Optimal Transport problem.
This function solves the optimization problem and returns the OT matrix for the given parameters.
Args:
log_a : torch.Tensor
Source weights
log_b : torch.Tensor
Target weights
M : torch.Tensor
metric cost matrix
num_iters : int, default=100
The number of iterations.
reg : float, default=1.0
regularization value
"""
M = M / reg # regularization
u, v = torch.zeros_like(log_a), torch.zeros_like(log_b)
for _ in range(num_iters):
u = log_a - torch.logsumexp(M + v.unsqueeze(1), dim=2).squeeze()
v = log_b - torch.logsumexp(M + u.unsqueeze(2), dim=1).squeeze()
return M + u.unsqueeze(2) + v.unsqueeze(1)
# Code adapted from OpenGlue, MIT license
# https://github.com/ucuapps/OpenGlue/blob/main/models/superglue/superglue.py
def get_matching_probs(S, dustbin_score = 1.0, num_iters=3, reg=1.0): ## S (b,c(m),h*w(n))
"""sinkhorn"""
batch_size, m, n = S.size()
# augment scores matrix
S_aug = torch.empty(batch_size, m + 1, n, dtype=S.dtype, device=S.device)
S_aug[:, :m, :n] = S
S_aug[:, m, :] = dustbin_score ## 在channel维度上加了一层 c个聚类(m)+1个dustbin(初始化为1) (b,m+1,n)
# prepare normalized source and target log-weights
# 原本每个聚类m和描述符n(特征)的容量都是1,都除以n+m,得到每个聚类和描述符的容量为1/n+m,然后取对数为-ln(n+m)
norm = -torch.tensor(math.log(n + m), device=S.device)
log_a, log_b = norm.expand(m + 1).contiguous(), norm.expand(n).contiguous() ## log_a 每个聚类的容量 log_b 每个特征的质量 都是norm -log(n+m)
log_a[-1] = log_a[-1] + math.log(n-m) ## 聚类的最后一个dustbin容量是n-m,共除m+n,对数化得到ln(n-m/n+m) = -ln(n+m)+ln(n-m)
log_a, log_b = log_a.expand(batch_size, -1), log_b.expand(batch_size, -1) ## log_a (b,m+1) log_b (b,n)
log_P = log_otp_solver(
log_a, ## 源侧分布 (b,m+1)
log_b, ## 目标侧分布 (b,n)
S_aug, ## 源侧score矩阵 (b,m+1,n)
num_iters=num_iters, ## 迭代次数
reg=reg ## 正则化项 1.0
) ## 返回变化矩阵的对数矩阵 (b,m+1,n) 将聚类的容量分配给各个聚类,同时保证得分p*s最高
return log_P - norm ## 还原 ln(p*(n+m))
class SALAD(nn.Module):
"""
This class represents the Sinkhorn Algorithm for Locally Aggregated Descriptors (SALAD) model.
Attributes:
num_channels (int): The number of channels of the inputs (d).
num_clusters (int): The number of clusters in the model (m).
cluster_dim (int): The number of channels of the clusters (l).
token_dim (int): The dimension of the global scene token (g).
dropout (float): The dropout rate.
"""
def __init__(self,
num_channels=1536,
num_clusters=64,
cluster_dim=128,
token_dim=256,
dropout=0.3,
) -> None:
super().__init__()
self.num_channels = num_channels ## c1 或者 d
self.num_clusters= num_clusters ## c3 或者 m
self.cluster_dim = cluster_dim ## c2 或者 l
self.token_dim = token_dim ## c4 或者 g
if dropout > 0:
dropout = nn.Dropout(dropout)
else:
dropout = nn.Identity()
# MLP for global scene token g
self.token_features = nn.Sequential(
nn.Linear(self.num_channels, 512),
nn.ReLU(),
nn.Linear(512, self.token_dim)
)
# MLP for local features f_i
self.cluster_features = nn.Sequential(
nn.Conv2d(self.num_channels, 512, 1),
dropout,
nn.ReLU(),
nn.Conv2d(512, self.cluster_dim, 1)
)
# MLP for score matrix S
self.score = nn.Sequential(
nn.Conv2d(self.num_channels, 512, 1),
dropout,
nn.ReLU(),
nn.Conv2d(512, self.num_clusters, 1),
)
# Dustbin parameter z
self.dust_bin = nn.Parameter(torch.tensor(1.))
def forward(self, x):
"""
x (tuple): A tuple containing two elements, f and t.
(torch.Tensor): The feature tensors (t_i) [B, C, H // 14, W // 14].
(torch.Tensor): The token tensor (t_{n+1}) [B, C].
Returns:
f (torch.Tensor): The global descriptor [B, m*l + g]
"""
x, t = x # Extract features and token
f = self.cluster_features(x).flatten(2) ## 降维2层1*1conv (b,c1,h,w) -> (b,c2,h,w) -> (b,c2,h*w)
p = self.score(x).flatten(2) ## score和cluster_features结构是一样的 (b,m,h*w)
t = self.token_features(t) ## 两层MLP (b,c1) -> (b,c4)
# Sinkhorn algorithm
p = get_matching_probs(p, self.dust_bin, 3) ## 得到对数化的变换矩阵
p = torch.exp(p) ## 对数矩阵转换成概率矩阵 (b,m+1,h*w)
# Normalize to maintain mass
p = p[:, :-1, :] ## 丢弃最后一个dustbin (b,m,h*w)
p = p.unsqueeze(1).repeat(1, self.cluster_dim, 1, 1) ## (b,c2,m,h*w)
f = f.unsqueeze(2).repeat(1, 1, self.num_clusters, 1) ## (b,c2,m,h*w)
f = torch.cat([
nn.functional.normalize(t, p=2, dim=-1), ## t(b,c4) p=2代表L2范数 dim=-1代表最后一维
nn.functional.normalize((f * p).sum(dim=-1), p=2, dim=1).flatten(1) ## f(b,c2,m,n) p(b,c2,m,n) *逐元素相乘 -> (b,c2,m,n) 最后维度相加->(b,c2,m) flatten-> (b,c2*m)
], dim=-1)
return nn.functional.normalize(f, p=2, dim=-1)详细步骤
步骤 1:局部特征提取
-
图像输入 DINOv2(ViT),输出:
-
n n n 个 patch tokens { t 1 , . . . , t n } ∈ R d \{\mathbf{t}_1, ..., \mathbf{t}_n\} \in \mathbb{R}^d {t1,...,tn}∈Rd(局部特征)
-
1 个 global token t n + 1 \mathbf{t}_{n+1} tn+1(全局信息)
x, t = x # Extract features and token
-
步骤 2:特征降维
-
通过两层 MLP 将 token 维度从 d d d 压缩到 l l l(如 768 → 128):
-
代码中使用两个 1 × 1 1 \times 1 1×1conv
-
f i = W f 2 ( σ ( W f 1 t i + b f 1 ) ) + b f 2 \mathbf{f}i = \mathbf{W}{f_2}(\sigma (\mathbf{W}{f_1}\mathbf{t}i + \mathbf{b}{f_1})) + \mathbf{b}{f_2} fi=Wf2(σ(Wf1ti+bf1))+bf2
f = self.cluster_features(x).flatten(2) ## 降维2层1*1conv (b,c1,h,w) -> (b,c2,h,w) -> (b,c2,h*w) c1=d c2=l
步骤 3:计算得分矩阵(含 dustbin)
-
对每个特征 f i \mathbf{f}_i fi,通过 MLP 计算其到 m m m 个聚类和 1 个 dustbin 的得分:
- 聚类得分: s i = MLP ( f i ) \mathbf{s}_i = \text{MLP}(\mathbf{f}_i) si=MLP(fi)(随机初始化,无 k-means 先验)
- dustbin 得分: s ˉ i , m + 1 = z \bar{s}_{i,m+1} = z sˉi,m+1=z(可学习标量,所有特征共享)
-
拼接得到 S ~ ∈ R n × ( m + 1 ) \tilde{\mathbf{S}} \in \mathbb{R}^{n \times (m+1)} S~∈Rn×(m+1)
-
也是用两个 1 × 1 1\times1 1×1conv实现
p = self.score(x).flatten(2) ## score和cluster_features结构是一样的 2层conv
(b,c1,h,w) -> (b,m,h,w) -> (b,m,h*w) m个聚类的得分
batch_size, m, n = S.size() # augment scores matrix S_aug = torch.empty(batch_size, m + 1, n, dtype=S.dtype, device=S.device) S_aug[:, :m, :n] = S S_aug[:, m, :] = dustbin_score ## 在channel维度上加了一层 c个聚类(m)+1个dustbin(初始化为1) (b,m+1,n)
步骤 4:Sinkhorn 最优传输分配
-
定义质量分布:
- 特征质量: μ = 1 n \mu = \mathbf{1}_n μ=1n(每个特征总质量为 1)
- 聚类+dustbin 容量: κ = 1 m ⊤ , n − m ⊤ \kappa = \\mathbf{1}_m\^\\top, n-m^\top κ=1m⊤,n−m⊤(dustbin 可吸收多余质量)
-
用 Sinkhorn 算法求解分配矩阵 P ˉ ∈ R n × ( m + 1 ) \bar{\mathbf{P}} \in \mathbb{R}^{n \times (m+1)} Pˉ∈Rn×(m+1),满足:
P ˉ 1 m + 1 = μ , P ˉ ⊤ 1 n = κ \bar{\mathbf{P}}\mathbf{1}_{m+1} = \mu,\quad \bar{\mathbf{P}}^\top \mathbf{1}_n = \kappa Pˉ1m+1=μ,Pˉ⊤1n=κ -
丢弃 dustbin 列,得到最终分配 P ∈ R n × m \mathbf{P} \in \mathbb{R}^{n \times m} P∈Rn×m
# prepare normalized source and target log-weights # 原本每个聚类m和描述符n(特征)的容量/质量都是1,都除以n+m,得到每个聚类和描述符的容量为1/n+m,然后取对数为-ln(n+m) norm = -torch.tensor(math.log(n + m), device=S.device) log_a, log_b = norm.expand(m + 1).contiguous(), norm.expand(n).contiguous() ## log_a 每个聚类的容量 log_b 每个特征的质量 都是norm -log(n+m) log_a[-1] = log_a[-1] + math.log(n-m) ## 聚类的最后一个dustbin容量是n-m,除以m+n,对数化得到ln(n-m/n+m) = -ln(n+m)+ln(n-m) log_a, log_b = log_a.expand(batch_size, -1), log_b.expand(batch_size, -1) ## log_a (b,m+1) log_b (b,n) log_P = log_otp_solver( log_a, ## 源侧分布 (b,m+1) 聚类 log_b, ## 目标侧分布 (b,n) 特征 S_aug, ## 源侧score矩阵 (b,m+1,n) 聚类得分 num_iters=num_iters, ## 迭代次数 reg=reg ## 正则化项 1.0 ) ## 返回变化矩阵的对数矩阵 (b,m+1,n) 将聚类的容量分配给各个聚类,同时保证得分p*s最高 return log_P - norm ## 还原 ln(p*(n+m))Sinkhorn algorithm
p = get_matching_probs(p, self.dust_bin, 3) ## 得到对数化的变换矩阵 p = torch.exp(p) ## 对数矩阵转换成概率矩阵 (b,m+1,h*w) # Normalize to maintain mass p = p[:, :-1, :] ## 丢弃最后一个dustbin (b,m,h*w)
步骤 5:按分配聚合特征
-
对每个聚类 j j j 和维度 k k k,直接求和(不减去聚类中心):
V j , k = ∑ i = 1 n P i , j ⋅ f i , k V_{j,k} = \sum_{i=1}^n P_{i,j} \cdot f_{i,k} Vj,k=i=1∑nPi,j⋅fi,k -
输出 VLAD 矩阵 V ∈ R m × l \mathbf{V} \in \mathbb{R}^{m \times l} V∈Rm×l
p = p.unsqueeze(1).repeat(1, self.cluster_dim, 1, 1) ## (b,c2,m,h*w) c2=l f = f.unsqueeze(2).repeat(1, 1, self.num_clusters, 1) ## (b,c2,m,h*w) nn.functional.normalize((f * p).sum(dim=-1), p=2, dim=1).flatten(1) ## f(b,c2,m,n) p(b,c2,m,n) *逐元素相乘 -> (b,c2,m,n) 最后维度相加->(b,c2,m) flatten-> (b,c2*m)
步骤 6:全局 token 处理
-
将 DINOv2 的 global token 通过 MLP 映射到 g ∈ R 256 \mathbf{g} \in \mathbb{R}^{256} g∈R256
t = self.token_features(t) ## 两层MLP (b,c1) -> (b,c4) nn.functional.normalize(t, p=2, dim=-1), ## t(b,c4) p=2代表L2范数 dim=-1代表最后一维
步骤 7:描述子构建与归一化
-
将 V \mathbf{V} V 展平并与 g \mathbf{g} g 拼接
-
依次进行:per-dimension intra-normalization → 整体 L2 归一化
-
得到最终全局描述子
f = torch.cat([ nn.functional.normalize(t, p=2, dim=-1), ## t(b,c4) p=2代表L2范数 dim=-1代表最后一维 nn.functional.normalize((f * p).sum(dim=-1), p=2, dim=1).flatten(1) ## f(b,c2,m,n) p(b,c2,m,n) *逐元素相乘 -> (b,c2,m,n) 最后维度相加->(b,c2,m) flatten-> (b,c2*m) ], dim=-1) return nn.functional.normalize(f, p=2, dim=-1)
核心创新总结
- 最优传输分配:Sinkhorn 算法提供比 softmax 更全局优化的分配
- Dustbin 机制:自动丢弃无信息特征,提升描述子纯净度
- DINOv2 骨干:利用自监督视觉基础模型的特征表达力
- 减少先验:从零学习得分矩阵,避免 k-means 初始化偏差