这个项目源自 Factory.ai 今年一月发布的 Agent Readiness 概念。Factory 是一个 AI Coding Agent 平台,他们的 Agent 叫 Droid,在帮企业客户大规模部署 Agent 的过程中发现了一个规律:Agent 表现好不好,最大的变量不是模型,而是代码仓库本身的工程基础。"The agent is not broken. The environment is." ------ Agent 没坏,是环境有问题。
Factory 基于这个认知做了一套评估体系,但它跟 Factory 平台深度绑定。我觉得这个思路太好了,不应该只能在一个平台上用,于是做了这个开源版本------不绑定任何 Agent 或平台,只要有 Git 仓库和 Node.js 就能跑。
一个真实的痛点
最近半年,我一直在用各种 AI Coding Agent 写代码------Claude Code、Cursor、Copilot,轮番上阵。体验下来有个很明显的感受:同样的 Agent,放在不同的仓库里,表现差距大得离谱。
有些项目里,Agent 干活特别顺。你说"加个接口",它就能顺着 lint 配置、测试框架、CI 流程一路跑通,甚至能帮你开 PR。但换到另一个仓库------哪怕是同一个团队的------它就开始犯傻:lint 规则不知道在哪,测试跑不起来,构建命令靠猜,折腾半天出来的代码还得你手动收拾。
问题不在 Agent,而在仓库本身。Agent 能力的天花板,很大程度上取决于它落地的那个环境是不是"agent-friendly"。
这个认知促使我做了 Agent Readiness 这个项目。
什么是 Agent Readiness
一句话讲:它是一个静态审计工具,用来衡量一个 Git 仓库到底有多"适合 AI Agent 来干活"。
你把它丢进任何一个 Git 仓库,它会自动扫描代码结构、发现应用边界、并行评估 82 个检查项,最后给你出一份 JSON 报告和一个 HTML Dashboard。整个过程不修改你的源代码,产物全部放在 .agent-readiness/ 目录下。
82 个检查项分布在 9 个大类里。Factory 把它们叫做"技术支柱"(Technical Pillars),每一个都对应着 Agent 在生产环境中一种具体的失败模式:
- Style & Validation ------ Linter、类型检查、格式化工具。没有它们,Agent 会在语法错误和风格不一致上浪费大量时间,等 CI 反馈才能发现本该秒级捕获的问题。
- Build System ------ 清晰、确定性的构建命令。Agent 需要知道跑什么命令来验证自己的改动能编译、能运行,而不是靠猜。
- Testing ------ 快速的单元测试和集成测试构成紧密的反馈循环。Agent 靠跑测试来判断自己的改动对不对,看到失败就迭代------没有可运行的测试,这个循环就断了。
- Documentation ------ 把"大家都知道"的隐性知识写下来。怎么搭环境、怎么跑测试、怎么部署、怎么排查问题。Agent 不在你的 Slack 频道里,它只能读文档。
- Development Environment ------ 可复现的开发环境。当开发者和 Agent 在一模一样的环境里干活时,一整类"在我机器上能跑"的问题就消失了。
- Debugging & Observability ------ 结构化日志、追踪和指标,让 Agent 对运行时行为有可见性。好的可观测性能把"它挂了"变成"它挂了,因为调用 Y 时 X 是 null"。
- Security ------ 分支保护、密钥扫描、CODEOWNERS。Agent 动作快------自动化护栏确保它快得安全。
- Task Discovery ------ 结构化的 issue 和模板,帮助 Agent 自主发现和理解要做什么工作。
- Product & Experimentation ------ 度量影响、跑实验、理解用户行为的工具。Agent 能看到功能有没有人用,能衡量自己的改动对用户行为的影响。
每个检查项不是简单给你一个 pass/fail。它会告诉你具体得分(比如"4 个应用里有 3 个通过"),还附上 rationale------为什么这么判的,证据是什么。这个很重要,因为你要知道的不光是"哪里不行",还有"为什么不行"。
为什么要做这件事
起因:Factory Droid 给了我一个启发
今年一月,Factory.ai 发布了一篇文章叫《Introducing Agent Readiness》。Factory 做的事情是 AI Coding Agent 平台,他们的 Agent 叫 Droid,服务过 Ernst & Young、Groq 这类企业客户。在大规模帮客户部署 Droid 的过程中,他们发现了一个规律:Agent 表现好不好,最大的变量不是模型能力,而是代码仓库本身的工程基础。
他们在文章里有句话说得很直白:"The agent is not broken. The environment is." Agent 没坏,是环境有问题。Missing pre-commit hooks 意味着 Agent 要等 10 分钟的 CI 反馈而不是 5 秒;没有文档的环境变量意味着 Agent 只能靠猜;构建流程全靠 Slack 里的口口相传意味着 Agent 根本不知道怎么验证自己的产出。这些都不是 Agent 的问题,是环境的问题,而且它们会叠加放大。
基于这个认知,Factory 做了一套 Agent Readiness 评估体系------9 个技术维度(Style & Validation、Build System、Testing、Documentation、Dev Environment、Debugging & Observability、Security、Task Discovery、Product & Experimentation)、5 个成熟度等级,能对任意仓库做一次"体检"。他们的 Level 体系设计得很务实:Level 1 是"能跑",Level 2 是"有文档",Level 3 是"标准化"(这是他们建议大部分团队首先瞄准的目标),Level 4 是"优化",Level 5 是"自治"。升级到下一个 Level 需要通过当前 Level 80% 的检查项。
他们还跑了一批知名开源项目的报告挂在网上:CockroachDB 拿到了 Level 4(74%),FastAPI 是 Level 3(53%),Express 只有 Level 2(28%)。都是优秀项目,但对 Agent 的友好程度差别很大。用他们的话说,一个反馈循环快、指引清晰的仓库会让任何 Agent 都更有效;而一个反馈循环差的仓库会击败你扔进去的任何 Agent。
我看完那篇文章的第一反应是:这个思路太对了。它不是在吹 Agent 多厉害,而是在冷静地讲------你想让 Agent 干好活,先把家里收拾好。
但接下来的问题是,Factory 的 Agent Readiness 是跟他们平台深度绑定的------CLI 要在 Droid 里跑 /readiness-report,Dashboard 在 Factory 的 Web 端看,API 也要用 Factory 的 key。如果你用的是 Claude Code、Cursor 或者其他 Agent,就没法直接享受到这套评估能力。
所以我决定自己做一个
我想做的是一个不绑定任何平台的开源版本。你用什么 Agent 都行,甚至不用 Agent 也行------只要有个 Git 仓库和 Node.js,就能跑起来。
整体框架延续了 Factory 的思路------同样的 9 个技术维度、5 个成熟度等级、Repository Scope 和 Application Scope 两种评估粒度。在这个基础上,我做了一些自己的调整和扩展:
Factory 提到过他们用 LLM 做评估时遇到了非确定性的问题(同一个仓库连跑两次分数不一样),他们的解法是用上一次报告来"锚定"当前评估。我这边走了另一条路:很多检查项不只是查文件存不存在,而是真的去读配置内容、甚至执行命令来确认功能是不是可用的------比如评估"测试能不能跑",不是看 package.json 有没有 test script,而是真的用 --listTests 跑一下看看框架是不是能正常工作。用更确定性的检查方式来减少 LLM 评估的摇摆。
技术实现上,整套审计流程被做成了一个标准的 skill(遵循开放的 Skills 规范)。任何支持 skill 加载的 Agent 平台都可以直接使用,不局限于某个特定的 Agent 或 IDE。核心的 validate、score、dashboard 生成用一个零依赖的 Node.js CLI 来保证确定性,不依赖 Agent 的输出稳定性。产出的 HTML Dashboard 是完全本地的,不需要登录任何平台就能看。
这件事本身的价值
抛开 Factory 不谈,为什么"衡量仓库对 Agent 的友好程度"这件事很重要?
先想想终局是什么样的。Factory 在文档里描述了一个"自治开发"的愿景:开发者只需要说一句"重构认证模块,支持 OAuth2 PKCE,保持向后兼容",系统就能自己生成代码、跑 lint 和测试、处理 PR 和 code review、更新文档、部署上线、监控异常。甚至设计师丢一个 Figma 稿,系统就能直接实现成带交互、带测试、带无障碍支持的前端组件,然后部署到 staging 等设计师 review。
这不是科幻。在工程基础足够好的仓库里,今天的 Agent 已经能做到其中的大部分------前提是环境到位。
我先说说不到位会怎样。当团队开始把 AI Agent 引入日常开发流程时,最常见的剧本是这样的:有人在某个项目里用 Claude Code 搞了个功能,效果不错,于是全组跟进。但到了别的仓库,发现同样的操作完全跑不通。大家开始怀疑 Agent 不行,或者觉得 AI 写代码这事不靠谱。
实际上呢?那些"Agent 用得好"的项目,往往是本身工程基础就扎实的项目:lint 完善、测试跑得通、CI 流程清晰、文档说人话。Agent 并没有什么魔法,它只是在好的工程环境里更容易发挥而已。
所以问题的关键不是"该不该用 Agent",而是"我们的仓库准备好了没有"。
但"准备好了没有"这个问题很难回答,因为你没有量化标准。AGENTS.md 写了吗?pre-commit hooks 配了吗?测试能一键跑吗?devcontainer 能用吗?feature flag 有没有?这些东西散落在仓库各处,靠人肉检查既慢又不全面。
Agent Readiness 就是把这些散落的信号收拢起来,给你一个统一的、可重复的、自动化的评估。
还有一个动机是趋势追踪。一次审计能告诉你现状,但如果你每次 merge 到主分支后都跑一次,它的 history 功能会记录分数变化。你能在 Dashboard 上看到一条曲线------团队在 agent readiness 这件事上是在进步还是退步。
这套东西是怎么工作的
整个审计分 5 个阶段,全自动跑完。
第一阶段:仓库扫描
先搞清楚你这个仓库是什么类型的。检测语言(JS/TS、Python、Rust、Go、Java、Ruby 等),扫描目录结构,找出配置文件、源码目录、测试目录的位置。
这一步的作用是给后续评估建立上下文。Agent 需要知道"这是个 TypeScript monorepo"还是"这是个 Python 单体应用",才能知道去哪里找对应的 lint 配置、测试框架、构建命令。
第二阶段:应用发现
如果你的仓库是 monorepo,这一步会识别出里面有几个独立可部署的应用。比如 apps/backend 是一个服务,apps/frontend 是另一个,packages/shared 是个共享库(不算应用)。
这个数字很关键。后续有 38 个检查项是"应用级别"的(比如"每个应用都有 lint 配置吗"),它们的分母就是这里发现的应用数量。另外 44 个是"仓库级别"的(比如"README 存在吗"),分母固定是 1。
发现 0 个应用的话,仓库根目录本身就被当成 1 个应用来算。
第三阶段:并行评估
这是核心步骤。9 个类别,每个类别派一个子 Agent 去独立评估,全部并行跑。
每个子 Agent 会读取对应类别的 criteria 定义文件,然后用 bash 命令(find、grep、ls 等)在仓库里实际检查证据。比如评估 lint_config 这个检查项,Agent 会去找 .eslintrc.* 或 eslint.config.* 文件;评估 unit_tests_runnable,它会找到测试命令后真的用 --listTests 跑一下看测试框架是不是可用的。
这不是简单的"文件存在就 pass"------很多检查项要求读配置内容来确认功能是否真正启用。比如 strict_typing,光有 tsconfig.json 不行,得确认里面有 "strict": true。
第四阶段:报告校验
9 个子 Agent 跑完后,结果会合并成一个大 JSON。这一步用 CLI 工具做 schema 校验:检查是不是恰好 82 个检查项、分母对不对、该 skip 的有没有瞎给分。通不过就打回去改,直到 clean。
第五阶段:出分 + 生成 Dashboard
最后一步,CLI 工具计算综合分数和 Level(Level 1 到 Level 5),生成三个文件:
agent-readiness-report.json------ 原始评估数据agent-readiness-score.json------ 汇总分数和等级agent-readiness-dashboard.html------ 可视化 Dashboard,浏览器打开就能看
同时会往 history/ 目录写一份快照,用于后续的趋势追踪。
跑完之后你会看到什么
光讲流程太抽象,直接看产出。
总览 Dashboard
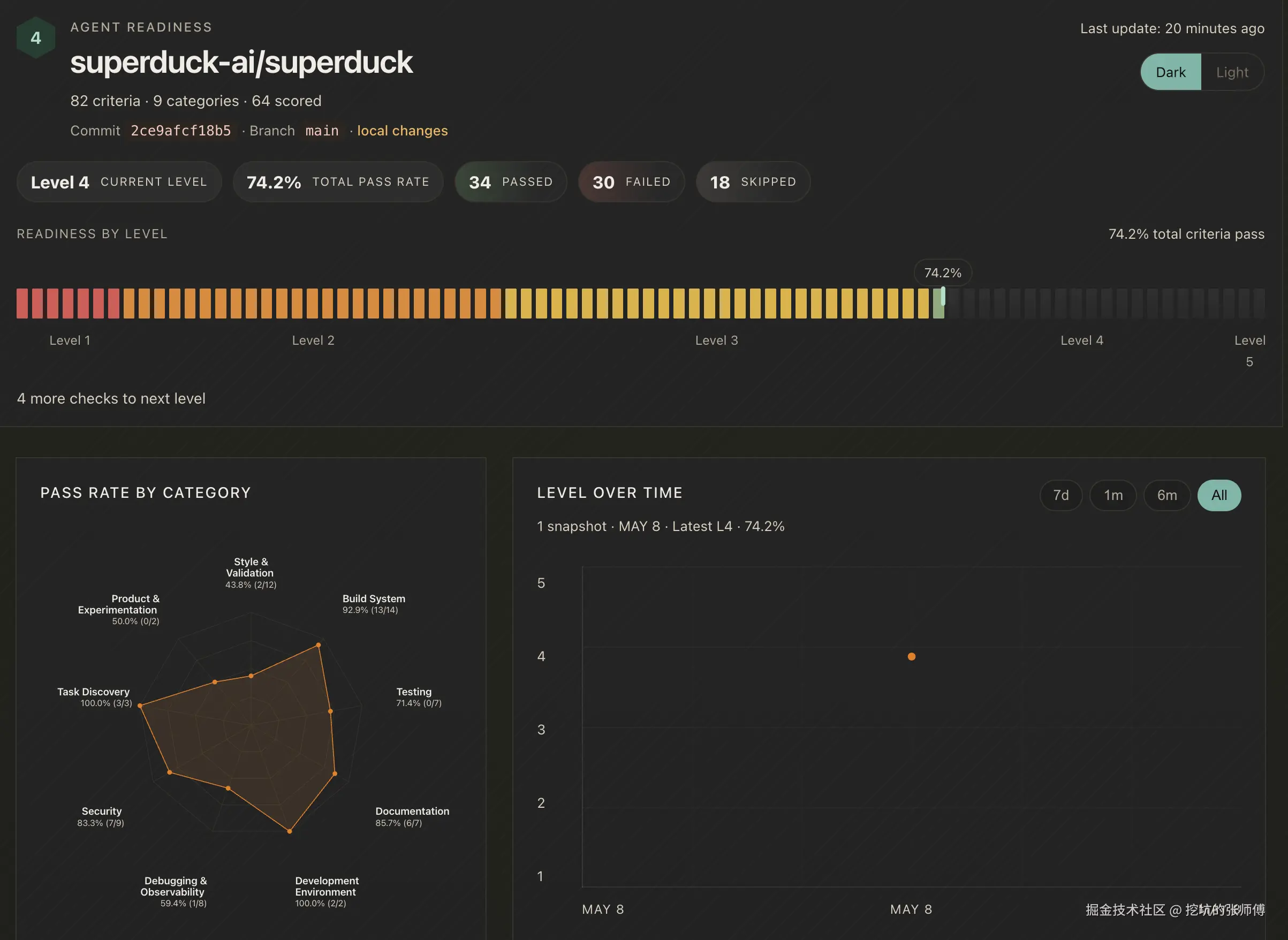
这是对一个真实仓库(4 个应用的 monorepo)跑出来的 Dashboard 总览。从上往下看:最顶部是仓库上下文------名称、commit hash、分支、是否有未提交的改动,一目了然。接着是当前 Level(这个仓库是 Level 4)和 Total Pass Rate(74.2%)。
中间那条彩色进度条叫"Readiness by Level",每个小格对应一个检查项------绿色是 pass,红色是 fail,黄色是 skip。小格按 Level 分段排列,你一眼就能看出哪些 Level 已经过了、当前卡在哪里。
下面两块最实用:左边的雷达图是"Pass Rate by Category",9 个维度的强弱对比一览无余------比如图里 Product & Experimentation 明显凹下去了,说明这是当前最大的短板。右边是"Level Over Time",从 history 目录读取历史快照画出的趋势曲线,能看到团队在 agent readiness 上是在进步还是停滞。
检查项浏览器
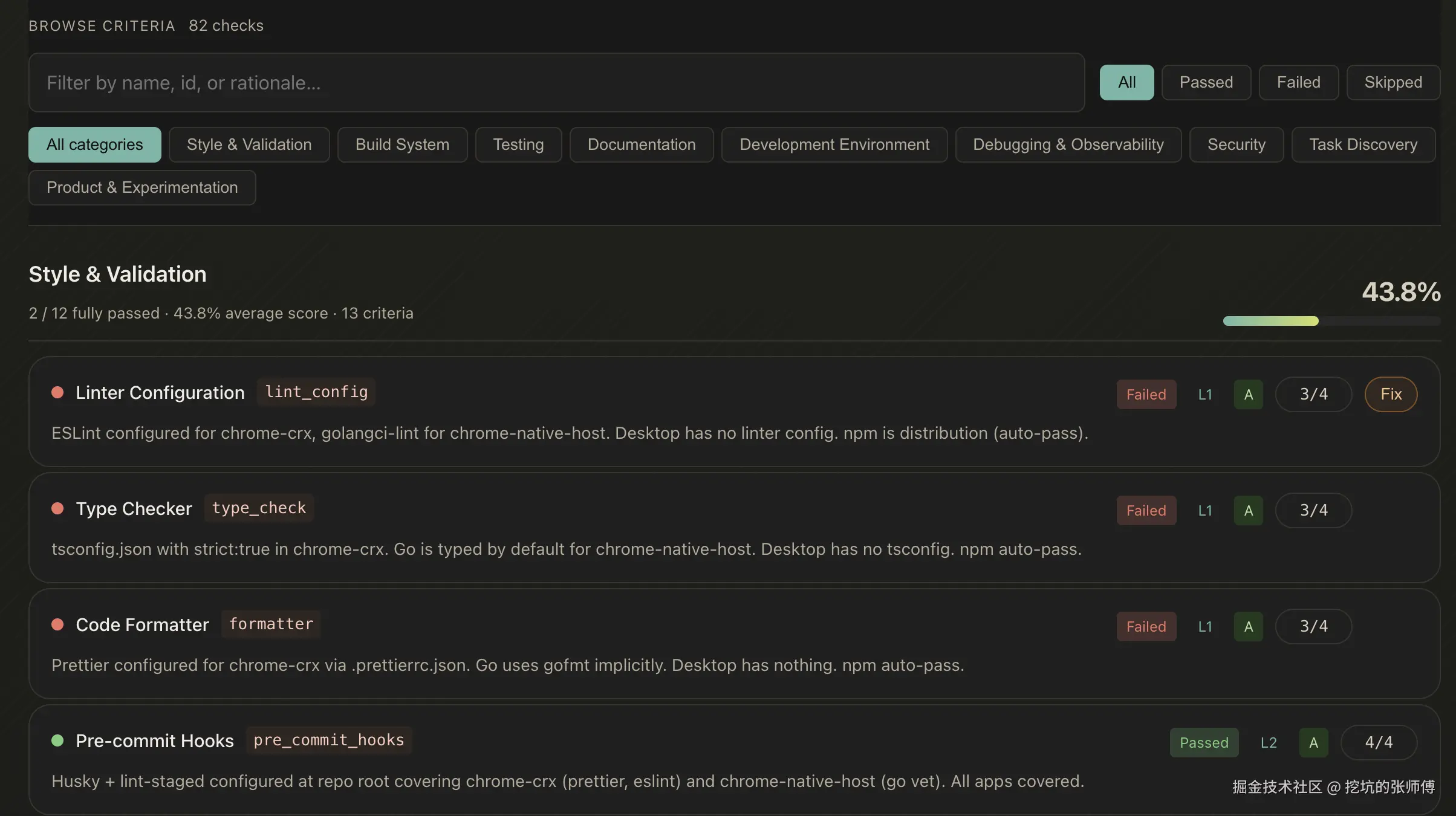
这是从总览下钻到具体检查项的页面。顶部有搜索框和筛选器,可以按状态(Passed / Failed / Skipped)和类别快速过滤。
每一行就是一个检查项。拿 lint_config 来举例:左边显示名称和 criterion ID,中间的 L1 标记说明它属于 Level 1,A 表示这是 Application Scope 的检查项(每个应用独立评估),右边的 3/4 表示 4 个应用里有 3 个通过了。如果是 Repository Scope 的检查项,分母固定是 1。
每个检查项下面有一行灰色小字,就是 rationale------解释具体是怎么判定的、证据是什么。比如 "ESLint configured for chrome-crx, golangci-lint for chrome-native-host. Desktop has no linter config. npm is distribution (auto-pass)."。这是整个报告里最有价值的部分,因为你不是在看一堆红绿灯,而是在看一份解释清楚的体检报告。
一键修复流程
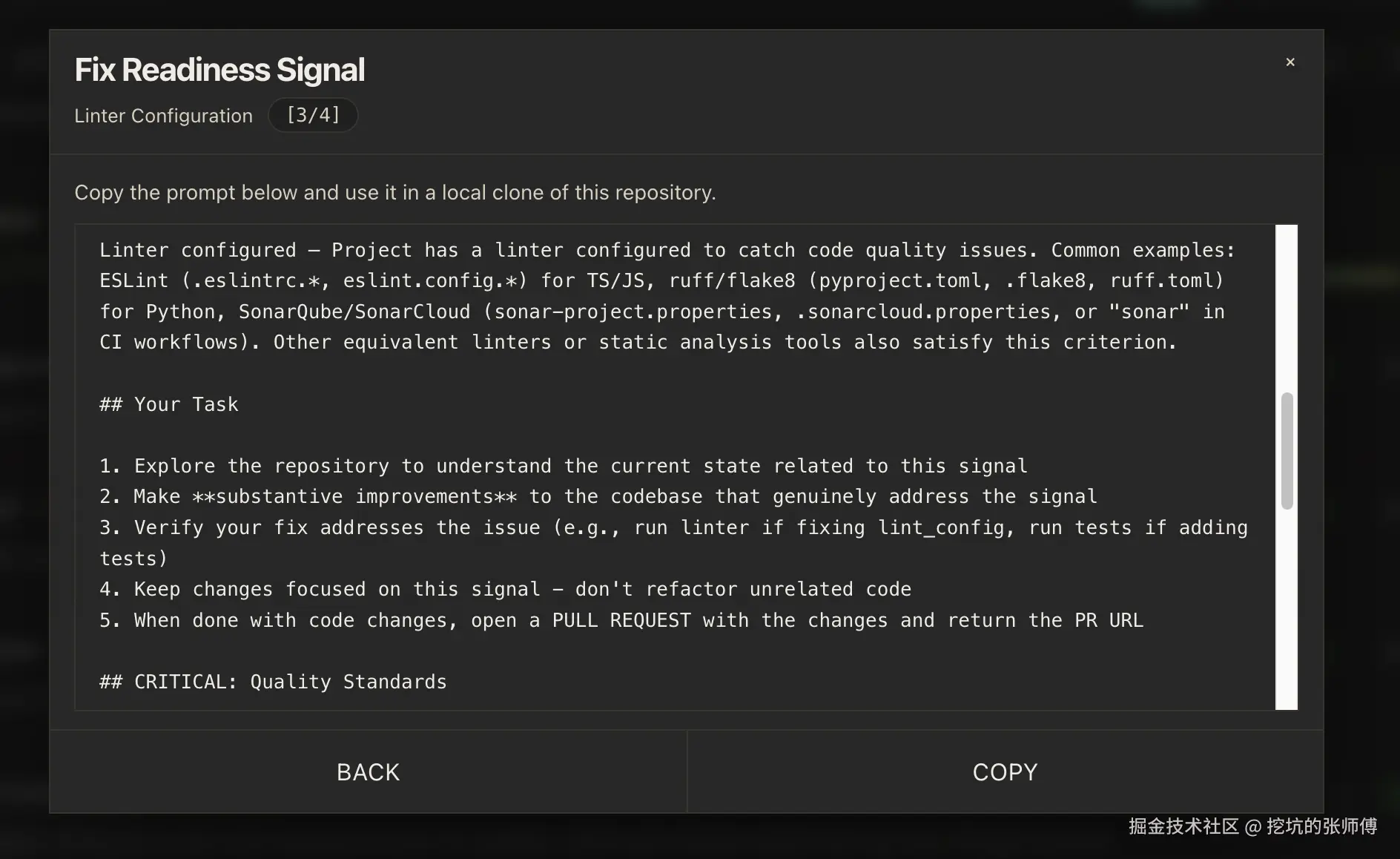 对于 failed 的检查项,详情页右边会出现一个 Fix 按钮。点开后弹出一个包含 remediation prompt 的窗口。
对于 failed 的检查项,详情页右边会出现一个 Fix 按钮。点开后弹出一个包含 remediation prompt 的窗口。
这段 prompt 不是泛泛的建议,它已经帮你组装好了完整的修复上下文:当前失败的 signal 是什么、评估规则是怎样的、具体要做什么(检查现状 → 实质性修复 → 验证 → 开 PR)。甚至还有质量护栏------明确写了不接受占位文件、不接受禁用检查项、不接受只为刷分的改动。
你可以直接复制这段 prompt 丢给任何 Agent 执行。从发现问题到修复问题,一个闭环。
82 个检查项都在查些什么
先说 Level 体系。5 个 Level 不只是数字上的递进,每个 Level 代表 Agent 能做的事情发生了质的变化。要解锁下一个 Level,需要通过当前 Level 80% 的检查项------这个门槛机制保证你是在打好基础的前提下往上走,而不是跳着摘高处的果子。
挑一些有代表性的来聊聊,让你感受一下粒度和思路。
Level 1: Functional(能跑)。 代码能跑,但需要手动搭建,缺少自动化校验。这些是最起码的门槛:有没有 README、有没有 .env.example、有没有 lint 配置、有没有测试文件存在、.gitignore 是否覆盖了 .env/node_modules 这些该忽略的东西。没有这些,Agent 连基本的上下文都建立不起来。
Level 2: Documented(有文档)。 基础文档和流程就位,工作流被写下来了,开始有一些自动化。构建命令有没有写在文档里、依赖有没有 lockfile、pre-commit hooks 配了没有、测试能不能跑起来(不是看有没有测试文件,而是真的执行一下看看)、有没有 AGENTS.md、有没有 CODEOWNERS、有没有 devcontainer。这些是让 Agent 从"能看懂代码"升级到"能参与开发"的关键。
Level 3: Standardized(标准化)。 清晰的流程被定义、文档化并通过自动化来执行。这是 Factory 建议大部分团队首先瞄准的目标。这一层开始查比较"讲究"的东西:死代码检测、重复代码检测、未使用依赖检测、release 自动化、结构化日志、分布式追踪、密钥扫描、issue 模板、PR 模板。到了这个 Level,Agent 可以独立处理日常维护工作------修 bug、写测试、更新文档、升级依赖。
Level 4: Optimized(优化)。 快速反馈循环和数据驱动的改进。CI 反馈在 10 分钟内、每周多次部署、flaky test 检测、Feature flag 基础设施、渐进发布、回滚自动化、circuit breaker。系统被设计为高效运转并持续度量。
Level 5: Autonomous(自治)。 系统具备自我改进的能力,复杂需求能自动分解并并行执行。这是终极目标,当前能真正达到的仓库不多。
有一类检查项叫 [Skippable],它们在特定场景下可以合法跳过。比如 n_plus_one_detection 在纯前端项目里没意义,health_checks 在 CLI 工具上也不适用。审计不是追求全绿,而是追求合理。
一些设计上的取舍
为什么是 82 个检查项而不是 20 个? 因为 agent readiness 是个多维度的事情。只查 lint 和 test 太片面,你需要覆盖从代码风格到安全合规到产品数据的完整链路。当然,不是每个项目都需要全部过关------Level 体系就是干这个的。
为什么要并行子 Agent? 9 个类别如果串行跑,你得等很久。并行之后快很多,而且每个子 Agent 只关注自己的类别,评估质量反而更好------它不用在脑子里同时装 82 个规则。
为什么不修改源文件? 审计就是审计,不该产生副作用。所有产物都放在 .agent-readiness/ 下,你爱 commit 就 commit,不 commit 也不影响任何东西。
为什么用 Node.js CLI 做 validate/score/dashboard? 这几步涉及 JSON schema 校验、分数计算、HTML 生成。让 Agent 拼 HTML 不靠谱,用确定性的 CLI 工具来做才稳定。打包后的 agent-readiness.mjs 是零依赖的(除了 Node.js 本身),方便分发。
怎么用
安装
从 GitHub 克隆或下载,然后把 agent-readiness/ 目录复制到 Claude Code 的 skills 目录下:
sh
git clone https://github.com/superduck-ai/agent-readiness.git
cp -r agent-readiness/agent-readiness ~/.claude/skills/这个 skill 是完全自包含的,打包后的 bin/agent-readiness.mjs 除了 Node.js >= 18.17 之外没有任何外部依赖。
运行审计
进到你想评估的 Git 仓库里,启动 Claude Code,触发 agent-readiness 这个 skill 就行。它会自动走完 5 个阶段,全程不需要你干预。
跑完之后,产物都在仓库根目录的 .agent-readiness/ 下:
bash
.agent-readiness/
├── .gitignore
├── history/
│ └── *.json ← 历史快照,建议 commit
└── latest/
├── agent-readiness-report.json ← 原始评估数据
├── agent-readiness-score.json ← 汇总分数和等级
└── agent-readiness-dashboard.html ← 浏览器打开就能看直接用浏览器打开 agent-readiness-dashboard.html 就能看到完整的可视化报告。
推荐的工作流
第一次跑完之后,你会得到一个 Level 和一份详细报告。大部分仓库第一次跑出来的分都不高------别慌,这是正常的。重要的是你现在有了一个明确的改进方向。
推荐的节奏是这样的:
- 先看 Dashboard 上的雷达图,找到最弱的类别
- 到检查项详情页,按 Failed 筛选,优先处理 Level 1 和 Level 2 里挂掉的项------这些对 Agent 日常工作的影响最大
- 对于每个 failed 的项,点 Fix 按钮拿到 remediation prompt,直接丢给 Agent 去修
- 修完再跑一次,看分数变化
如果你把 .agent-readiness/history/*.json commit 到仓库里,Dashboard 上的 "Level Over Time" 图表就能画出趋势曲线,团队里每个人都能看到进度。
适合什么样的团队
如果你的团队已经在用或者准备用 AI Coding Agent,那 Agent Readiness 能帮你找到工程基础设施的短板。它不是告诉你"该不该用 Agent",而是告诉你"如果想用好 Agent,你的仓库还差什么"。
如果你的团队暂时没有 Agent 的计划也没关系。这 82 个检查项本质上是一份工程最佳实践的 checklist。就算抛开 Agent 不谈,能通过大部分检查的仓库,人类开发者在里面干活也会舒服很多。
说白了,对 Agent 友好的仓库,对人也友好。这从来不是对立的关系。
最后
Agent Readiness 是一个开源项目,代码在 GitHub 上。欢迎试用、提 issue、贡献检查项。
如果你跑了一次审计发现分数惨不忍睹------恭喜你,至少你现在知道该从哪里开始了。