C语言数据类型:整型、浮点型、字符型一次讲清楚
一、本篇文章要解决什么问题
上一篇我们搭好了环境、写出了第一个 C 程序。接下来你要面对的问题是:程序里的数据怎么存?
这篇文章就帮你搞清楚三件事:
- C 语言里有哪些基本数据类型,每种类型用来存什么?
- 整数、小数、字符在内存里是怎么表示的,各占多大空间?
- 什么叫数据溢出、浮点误差,为什么数据类型选错了会有 bug?
学完这篇,你就能根据实际需求选择合适的类型来存储数据,不会再写出"把手机号存成 int 导致丢数字"这种坑。
二、先用一个简单例子理解
你家里的收纳盒:
- 放袜子的盒子,小小一个就够了
- 放被子的柜子,得大很多
- 放证件的文件夹,大小居中但很重要
C 语言的数据类型和这些收纳盒是一样的道理:
- 你要存一个人的年龄(0~150 之间),用一个小盒子就够了
- 你要存一个班级 50 人的成绩,每个成绩带一位小数,就需要中等的盒子
- 你要存一个公司的年收入,数字很大还带小数,那就需要大盒子
选错盒子会怎样?
- 用小盒子装大东西 → 装不下,数据溢出(比如用
short存 50000,可能得到一个意想不到的负数,在某些常见环境中会变成 -15536) - 用装被子的柜子放一双袜子 → 浪费空间(虽然现代计算机不在乎这点空间,但在嵌入式设备上很关键)
所以 C 语言给了你不同大小的"盒子",它们的正式名字叫数据类型。
三、核心知识点讲解
3.1 什么是数据类型
数据类型规定了三件事:
- 这个变量能存什么种类的数据(整数?小数?字符?)
- 这个变量占多大内存空间(1 字节?4 字节?8 字节?)
- 这个变量能参与什么运算 (整数之间可以取余
%,小数不行)
在 C 语言里,使用任何变量之前都必须声明它的类型。这是 C 语言和 Python、JavaScript 最大的区别之一------C 是静态类型语言,变量在使用前需要声明类型,且类型一旦确定就不能随意改变。

图2-1 各数据类型内存占用对比图:让读者直观感受不同数据类型占空间的差异。
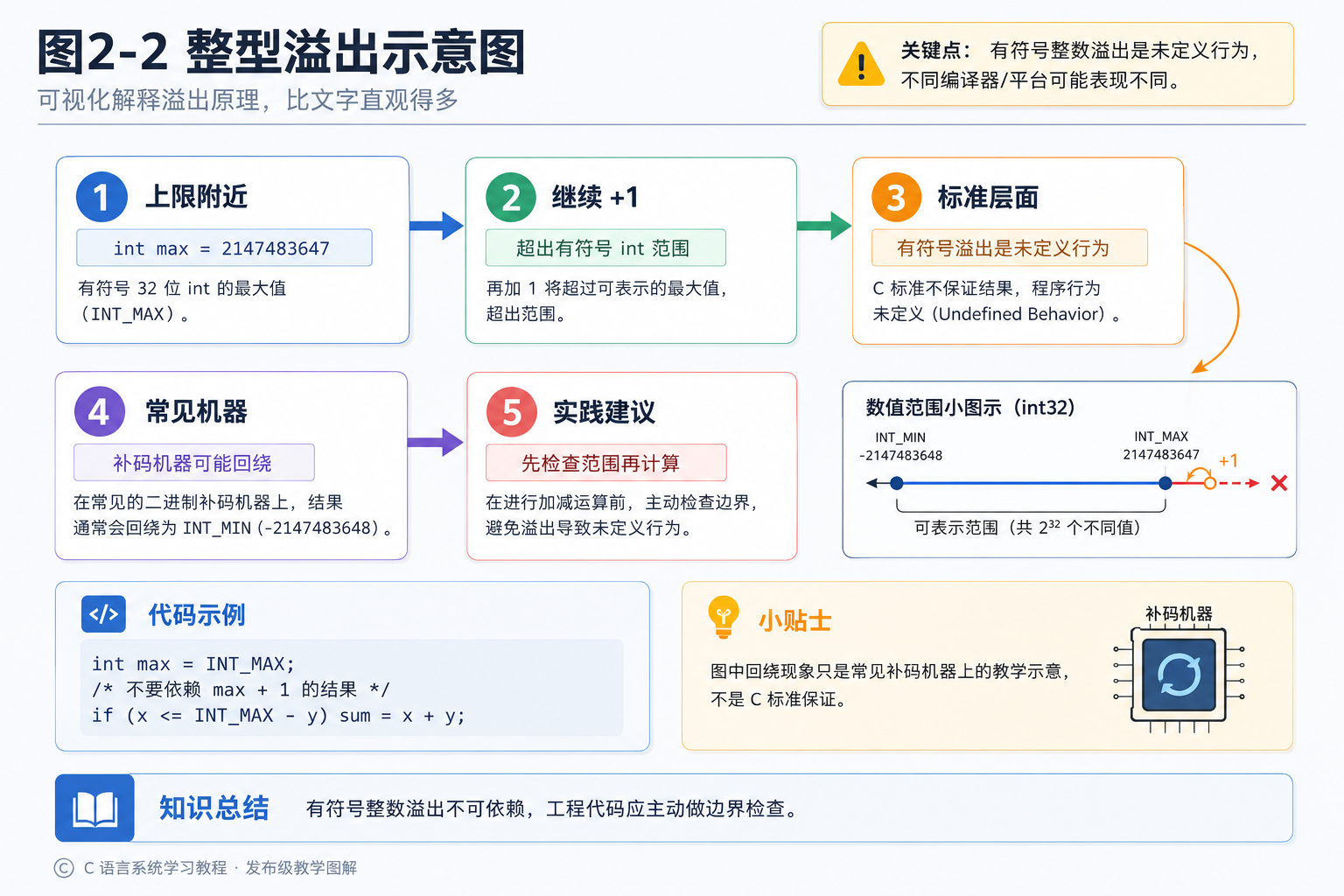
图2-2 整型溢出示意图:可视化解释溢出原理,比文字直观得多。
3.2 整型家族:short、int、long、long long
整数是最常用的数据类型。C 语言提供了 4 种不同大小的整数类型:
| 类型 | 通常字节数 | 通常取值范围 | 使用场景 |
|---|---|---|---|
short |
2 | -32,768 ~ 32,767 | 很小的整数,如年份偏移量 |
int |
4 | -2,147,483,648 ~ 2,147,483,647 | 最常用,如年龄、计数、循环变量 |
long |
4 或 8 | 视平台而定 | 需要跨平台时注意 |
long long |
8 | 约 ±9.22×10¹⁸ | 很大的整数,如学号、身份证号部分字段 |
注意 :
long的大小与平台和编译器有关。Windows/MSVC 下long通常是 4 字节;许多 64 位 Linux 环境(如 GCC on x86-64)下long通常是 8 字节。如果你的程序需要跨平台,或者需要保证 8 字节的整数,直接用long long。
无符号整数 :如果在类型前面加 unsigned,取值范围会变成 0 到正数上限的两倍。比如:
unsigned int:0 ~ 4,294,967,295- 适合存放"不可能为负数"的数据,如年龄、编号
代码演示------看看每种类型占多大:
c
#include <stdio.h>
int main(void)
{
printf("short 占用 %u 字节\n", (unsigned int)sizeof(short));
printf("int 占用 %u 字节\n", (unsigned int)sizeof(int));
printf("long 占用 %u 字节\n", (unsigned int)sizeof(long));
printf("long long 占用 %u 字节\n", (unsigned int)sizeof(long long));
return 0;
}
sizeof是 C 语言的关键字,可以测出类型或变量占用的字节数。一个字节(Byte)等于 8 个比特(bit)。sizeof的返回值类型是size_t,标准写法是用%zu来打印;本文中使用(unsigned int)强制转换后配合%u打印,是为了降低初学者的理解难度。
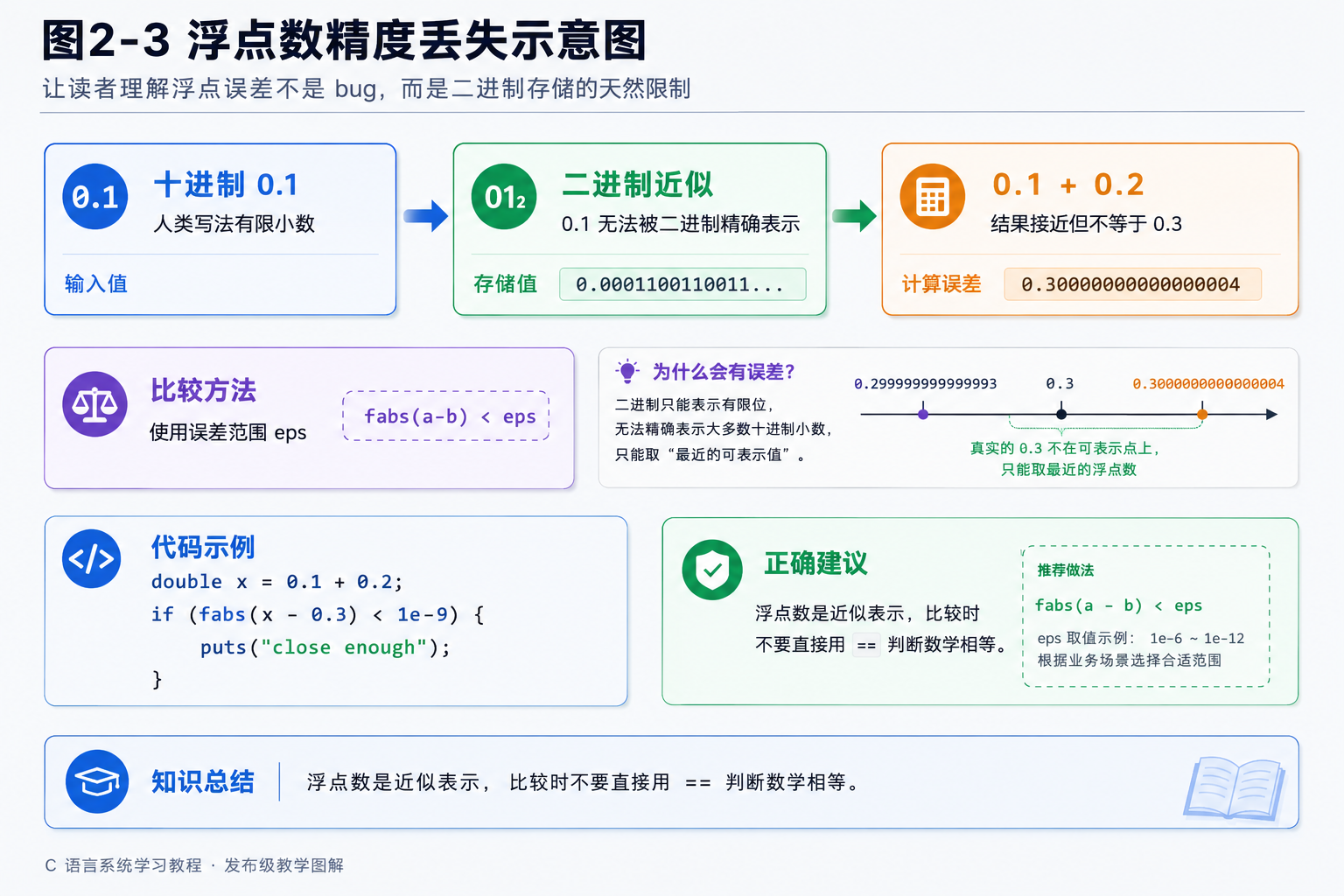
图2-3 浮点数精度丢失示意图:让读者理解浮点误差不是 bug,而是二进制存储的天然限制。
3.3 有符号和无符号的关键区别
c
#include <stdio.h>
int main(void)
{
int a = -100; // 有符号,可以存负数
unsigned int b = 100; // 无符号,不能存负数
unsigned int c = -100; // 危险!把负数赋给 unsigned
printf("a = %d\n", a);
printf("b = %u\n", b);
printf("c = %u\n", c); // 会输出一个巨大的正数!
return 0;
}运行结果:
text
a = -100
b = 100
c = 4294967196为什么 c 会输出 4294967196?因为当负数转换为无符号整数时,C 语言会按无符号类型的取值范围进行转换------具体来说,会把负数的二进制补码表示直接按无符号数来解释。在常见的 32 位 unsigned int 环境下,-100 的二进制补码被解释为无符号数时就是 4294967196。初学者很容易在赋值和比较时踩这个坑。
3.4 整型溢出:别把大数往小盒子里塞
c
#include <stdio.h>
int main(void)
{
short small = 32767; // short 的最大值
printf("small = %d\n", small);
small = small + 1; // 加 1 会怎样?
printf("small + 1 = %d\n", small);
return 0;
}运行结果:
text
small = 32767
small + 1 = -3276832767 + 1 竟然等于 -32768?不是算错了,是"溢出"了。 就像汽车里程表,到了 99999 再加 1 就变成 00000。short 只有 2 字节,装不下 32768,最高位变成了符号位,结果就成了负数。
重要提醒 :本示例在许多常见环境下会得到 -32768,但 C 语言标准规定有符号整数溢出是未定义行为 ------不同编译器、不同平台的结果可能不同。所以这个示例只是帮你理解"溢出"这个概念,实际开发中一定不要依赖溢出后的结果,而是应该选择足够大的数据类型来避免溢出。
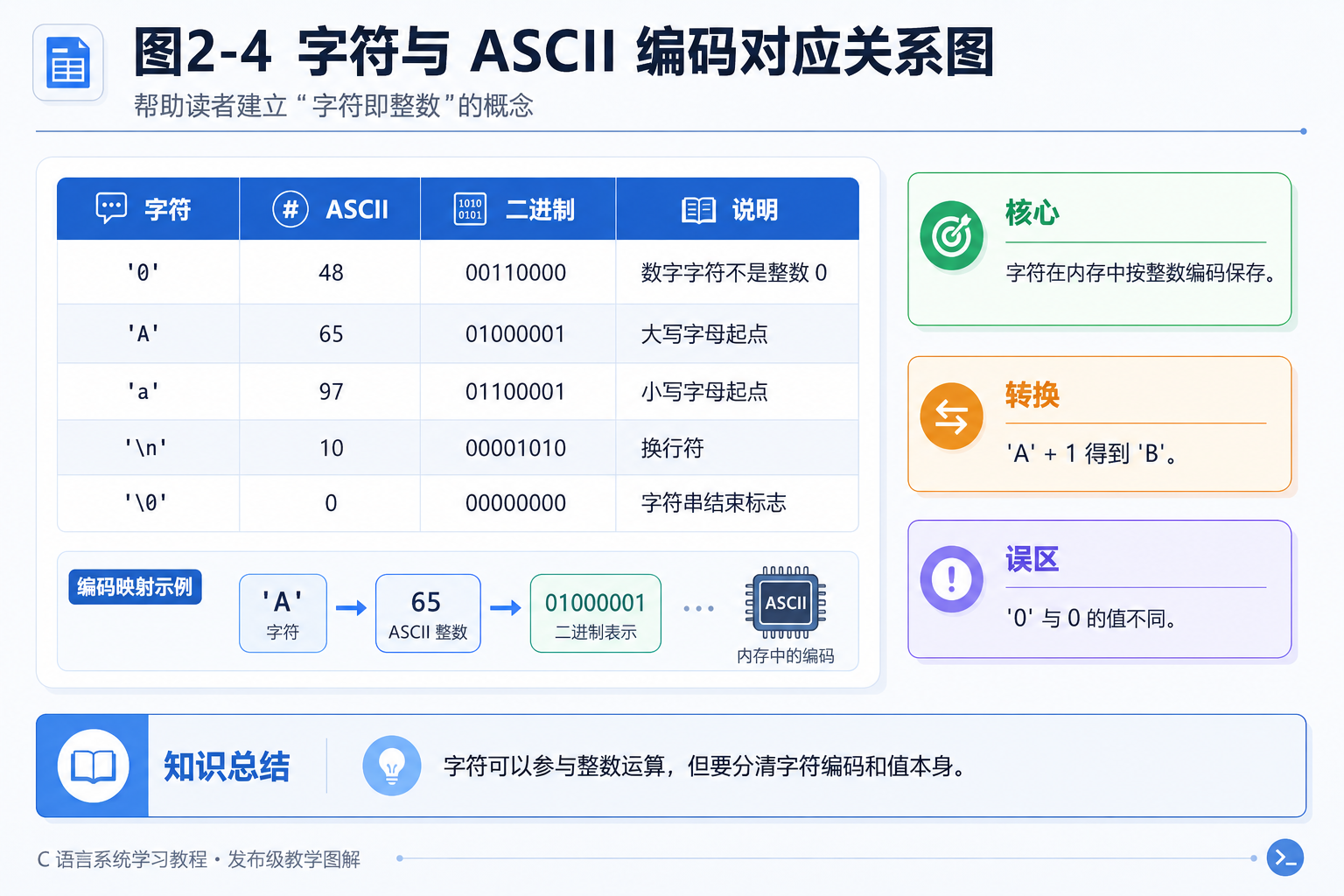
图2-4 字符与 ASCII 编码对应关系图:帮助读者建立"字符即整数"的概念。
3.5 浮点型:float 和 double
整数没法存小数。比如一个同学的成绩是 95.5,如果存成 int,小数部分直接就丢了。这时候就需要浮点型。
| 类型 | 字节数 | 有效位数 | 使用场景 |
|---|---|---|---|
float |
4 | 约 6~7 位十进制有效数字 | 对精度要求不高的小数 |
double |
8 | 约 15~16 位十进制有效数字 | 推荐,精度更高 |
建议:只要是小数,默认用
double。 现代计算机不在乎差这 4 个字节,但float的精度不足可能导致计算结果不对。
浮点误差演示:
c
#include <stdio.h>
int main(void)
{
float a = 0.1f;
float b = 0.2f;
float sum = a + b;
printf("0.1 + 0.2 = %.10f\n", sum);
if (sum == 0.3f)
{
printf("等于 0.3\n");
}
else
{
printf("不等于 0.3 !\n");
}
return 0;
}运行结果:
text
0.1 + 0.2 = 0.3000000119
不等于 0.3 !0.1 + 0.2 居然不等于 0.3?这是浮点数的"天性",不是 C 语言的 bug。 原因在于:0.1 和 0.2 在二进制中是无限循环小数,计算机只能存有限位数,所以产生微小误差。因此,永远不要用 == 直接判断两个浮点数是否相等,正确的做法是看它们的差是否小于一个很小的数(如 0.000001)。
3.6 字符型 char
char 用来存单个字符。在 C 语言里,字符的本质是一个整数------这个整数就是该字符在 ASCII 编码表中的编号。
c
#include <stdio.h>
int main(void)
{
char ch = 'A';
printf("字符:%c\n", ch);
printf("ASCII 码值:%d\n", ch);
// 字符和整数可以直接运算
printf("下一个字符:%c\n", ch + 1);
printf("A 到 a 的距离:%d\n", 'a' - 'A');
return 0;
}运行结果:
text
字符:A
ASCII 码值:65
下一个字符:B
A 到 a 的距离:32关键理解: 'A' 在内存里存的就是数字 65。printf 用 %c 格式时把它显示为字符,用 %d 格式时把它显示为数字。大小写字母之间刚好差 32,所以你经常看到代码里用 ch + 32 把大写转小写。
ASCII 编码速查(常用部分):
| 字符 | ASCII 值 |
|---|---|
| '0'~'9' | 48~57 |
| 'A'~'Z' | 65~90 |
| 'a'~'z' | 97~122 |
| '\n' (换行) | 10 |
| ' ' (空格) | 32 |
四、完整代码示例
下面这个程序把本节的知识点综合在一起,帮你在实践中理解各种数据类型:
c
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
int main(void)
{
// ===== 整型演示 =====
int age = 20;
unsigned int studentID = 20240101;
long long bigNumber = 9876543210LL;
printf("===== 整型 =====\n");
printf("年龄(int):%d\n", age);
printf("学号(unsigned int):%u\n", studentID);
printf("大数(long long):%lld\n", bigNumber);
printf("int 占用 %u 字节\n", (unsigned int)sizeof(int));
printf("long long 占用 %u 字节\n\n", (unsigned int)sizeof(long long));
// ===== 浮点型演示 =====
double height = 175.5;
double weight = 68.3;
double bmi = weight / ((height / 100.0) * (height / 100.0));
printf("===== 浮点型 =====\n");
printf("身高:%.1f cm\n", height);
printf("体重:%.1f kg\n", weight);
printf("BMI:%.2f\n", bmi);
printf("double 占用 %u 字节\n\n", (unsigned int)sizeof(double));
// ===== 字符型演示 =====
char grade = 'A';
printf("===== 字符型 =====\n");
printf("成绩等级:%c\n", grade);
printf("对应的 ASCII 码:%d\n", grade);
printf("char 占用 %u 字节\n", (unsigned int)sizeof(char));
return 0;
}五、运行结果
text
===== 整型 =====
年龄(int):20
学号(unsigned int):20240101
大数(long long):9876543210
int 占用 4 字节
long long 占用 8 字节
===== 浮点型 =====
身高:175.5 cm
体重:68.3 kg
BMI:22.22
double 占用 8 字节
===== 字符型 =====
成绩等级:A
对应的 ASCII 码:65
char 占用 1 字节六、代码逐行解析
第一部分 ------ 整型家族的实际使用
c
int age = 20;
unsigned int studentID = 20240101;
long long bigNumber = 9876543210LL;age用int,因为年龄在 0~150 之间,int完全够用studentID用unsigned int,因为学号不会是负数,用unsigned可以让正数范围翻倍bigNumber结尾的LL是字面量后缀,告诉编译器"这是一个long long类型的数字"- 选择原则:不大不小的数用 int,确定非负用 unsigned,超大的用 long long
c
printf("int 占用 %u 字节\n", (unsigned int)sizeof(int));sizeof 返回类型占用的字节数。它的返回值类型是 size_t(本质上是一个无符号整数)。标准写法是使用 %zu 格式占位符直接打印 size_t 值;这里用 (unsigned int) 强制转换后配合 %u,是为了让初学者更容易理解(减少需要记忆的格式占位符种类)。
第二部分 ------ 浮点型的实际使用
c
double bmi = weight / ((height / 100.0) * (height / 100.0));- 注意我们用了
100.0而不是100。这是因为整数除以整数会得到整数 (小数部分直接截掉)。175 / 100在 C 语言里结果是1,不是1.75 100.0是一个double类型的字面量,175.5 / 100.0得到正确结果1.755
c
printf("BMI:%.2f\n", bmi);%.2f 表示"输出浮点数,保留 2 位小数"。%.1f 就是保留 1 位。这个 .2 叫"精度控制",在打印价格、成绩等数据时非常常用。
第三部分 ------ 字符型的本质
c
char grade = 'A';
printf("成绩等级:%c\n", grade);
printf("对应的 ASCII 码:%d\n", grade);%c 以字符形式打印,%d 以整数形式打印。同一个变量 grade,用不同格式输出就显示不同的样子------这很好地说明了字符在内存里存的就是整数。
七、初学者常见错误
错误1:整数除以整数得到意料之外的结果
c
// 错误写法
double result = 5 / 2; // result = 2.0,不是 2.5!
printf("%f\n", result);
// 正确写法
double result = 5.0 / 2; // result = 2.5
double result = (double)5 / 2; // 也可以用强制类型转换原因 :5 / 2 是两个整数相除,C 语言按整数除法计算,结果是 2(小数截掉)。然后 2 才被转成 double 存到 result 里------但 2 的小数已经丢了。
错误2:用 %d 打印 unsigned int
c
unsigned int x = 3000000000U;
printf("%d\n", x); // 可能输出负数或错误值
printf("%u\n", x); // 正确:输出 3000000000每个类型都有自己对应的格式占位符:int 用 %d,unsigned int 用 %u,long long 用 %lld,unsigned long long 用 %llu。
错误3:误以为 float 够用
c
float f = 1234567.89f;
printf("%.2f\n", f); // 输出:1234567.88 或 1234568.00(精度丢失)float 只有约 7 位有效数字,1234567.89 已经接近它的精度极限。默认用 double 就不会有这个问题。
错误4:用 == 判断浮点数相等
c
// 错误写法
if (a == 0.3) { ... }
// 正确写法
if (a - 0.3 < 0.000001 && a - 0.3 > -0.000001) { ... }错误5:char 赋值时用了双引号
c
char ch = "A"; // 错误!双引号表示字符串(字符数组)
char ch = 'A'; // 正确!单引号表示单个字符八、练习题
练习题1:数据类型大小输出
写一个程序,用 sizeof 输出以下类型在你自己电脑上的字节数,并记录下来:
charshortintlonglong longfloatdouble
试试加上 unsigned 之后,大小是否一样?(比如 int 和 unsigned int)
练习题2:温度转换器
写一个程序,用户输入一个摄氏温度(允许小数),程序将它转换为华氏温度并输出。转换公式为:
华氏度 = 摄氏度 × 9 / 5 + 32
要求:
- 输入和输出都使用
double类型 - 输出结果保留 1 位小数
- 注意 9/5 如果写成整数会得到 1,需要使用 9.0/5.0
练习题3:大小写字母转换
写一个程序,提示用户输入一个大写字母,程序输出对应的小写字母。不查 ASCII 表,利用 'A' 和 'a' 的关系来计算。
提示:上一篇学过 scanf,这一篇知道了 'a' - 'A' = 32,结合起来就能做。
九、本篇总结
- 整数用 int,更大用 long long,非负用 unsigned,小数默认用 double
- 每种类型占不同大小:char = 1B, short = 2B, int/float = 4B, double/long long = 8B
- 整型溢出:超出类型范围值会"绕回去",选类型时留足余量
- 浮点数有天然误差 ,不能用
==比较,用"差的绝对值是否小于一个很小的数"来判断 - 字符的本质是整数(ASCII 码),大小写字母之间差 32