
🚀 欢迎来到我的CSDN博客:Optimistic _ chen
✨ 一名热爱技术与分享的全栈开发者,在这里记录成长,专注分享编程技术与实战经验,助力你的技术成长之路,与你共同进步!
🚀我的专栏推荐:
| 专栏 | 内容特色 | 适合人群 |
|---|---|---|
| 🔥C语言从入门到精通 | 系统讲解基础语法、指针、内存管理、项目实战 | 零基础新手、考研党、复习 |
| 🔥Java基础语法 | 系统解释了基础语法、类与对象、继承 | Java初学者 |
| 🔥Java核心技术 | 面向对象、集合框架、多线程、网络编程、新特性解析 | 有一定语法基础的开发者 |
| 🔥Java EE 进阶实战 | Servlet、JSP、SpringBoot、MyBatis、项目案例拆解 | 想快速入门Java Web开发的同学 |
| 🔥Java数据结构与算法 | 图解数据结构、LeetCode刷题解析、大厂面试算法题 | 面试备战、算法爱好者、计算机专业学生 |
| 🔥Redis系列 | 从数据类型到核心特性解析 | 项目必备 |
🚀我的承诺:
✅ 文章配套代码:每篇技术文章都提供完整的可运行代码示例
✅ 持续更新:专栏内容定期更新,紧跟技术趋势
✅ 答疑交流:欢迎在文章评论区留言讨论,我会及时回复(支持互粉)
🚀 关注我,解锁更多技术干货!
⏳ 每天进步一点点,未来惊艳所有人!✍️ 持续更新中,记得⭐收藏关注⭐不迷路 ✨
📌 标签:#技术博客 #编程学习 #Java #C语言 #算法 #程序员
文章目录
- 什么是RAG
- RAG增强LLM
- 构建向量数据库
- 简单上手
- ETL(提取,转化,加载)
-
- Document数据模型
-
- DocumentReader(⽂档阅读器)
- [DocumentTransformer(⽂档转换器)](#DocumentTransformer(⽂档转换器))
- DocumentWriter(⽂档编写器)
- 重排序
- 完结撒花!🎉
什么是RAG
官方给出的解释是:Retrieval Augmented Generation, 检索增强⽣成。是一种结合信息检索(retrieval)和文本生成(generation)的混合架构。
解释一下:传统⼤型语⾔模型(LLM)依赖训练数据中的知识,但⽆法获取最新信息以及⼀些⾮公开信息,所以当你询问一些私有信息时,就会出现"幻觉",答非所问。
RAG技术如同为LLM配备了实时更新的知识库。它不仅依靠预训练数据,还能通过检索特定知识片段来获取最新信息。这些检索到的内容作为上下文输入模型,使回答既准确又与时俱进,有效减少了信息误差,并实现了知识的动态更新。
RAG增强LLM
RAG技术有一套严谨的工作流程,为LLM的回答提供真实有效的依据。
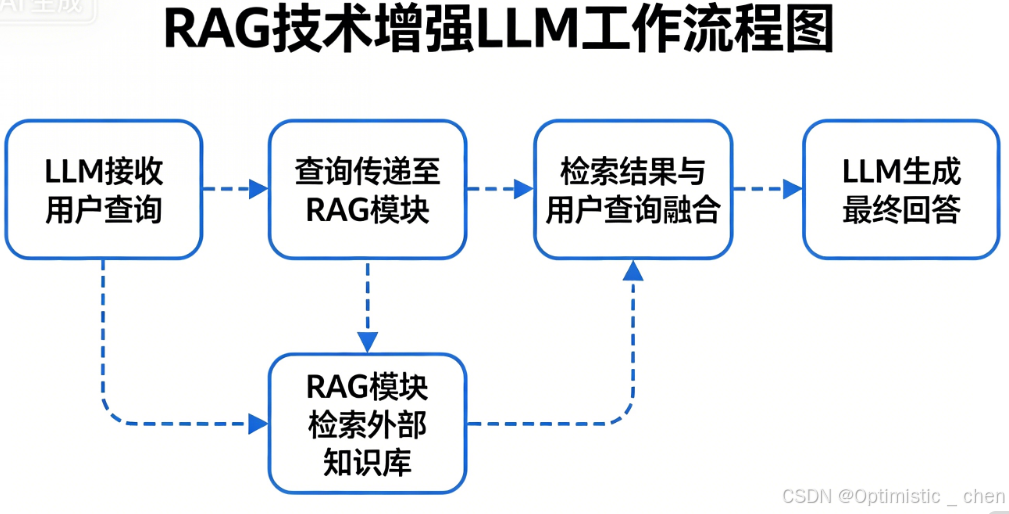
RAG第一个优势就是通过从外部知识库获取相关信息来增强⼤语⾔模型(LLM)的输出,从⽽⽣成更准确,上下⽂更丰富的回答,有效解决模型幻觉,知识过时等问题。
但是RAG知识库可能包含多种格式和语言的文档,导致这些数据难以被有效检索。因此,我们需要将这些数据进行进一步处理,构建出可以被高效检索的知识库。
构建向量数据库
什么是向量
向量是数学中的基本概念,表示高维空间中的一个坐标点。在机器学习领域,向量常被用来将文本、图像、音频等非结构化数据映射为高维空间中的点。每个维度代表潜在的语义特征,这些特征虽然不一定对应人类直观理解的具体概念(如"颜色"或"大小"),但共同编码了对象的语义信息。
核心特性在于:向量位置反映语义关系,语义相近的对象在向量空间中的位置也会更接近。
关于向量的计算方法,我们主要通过Embedding模型将自然语言转换为机器可理解的"语义编码"。具体计算过程不在本文讨论范围内,感兴趣的读者可以自行探索。
向量数据库
向量数据库(Vector Database)是⼀种专⻔⽤于存储、管理和⾼效检索⾼维向量数据的数据库系统。它以向量作为基本存储单元,⽀持对⾮结构化数据(如⽂本、图像、⾳频、视频)进⾏语义级相似性搜索。
对比传统关系型数据库的精准匹配,向量数据库的核心是
- 向量化处理:可以将原始数据转化为高维向量
- 相似性度量:使用余弦相似度、欧式距离等方法衡量向量间的语义接近程度
- 高效检索:采⽤⾼效的索引算法,大幅度提高查询速度
RAG的工作流程
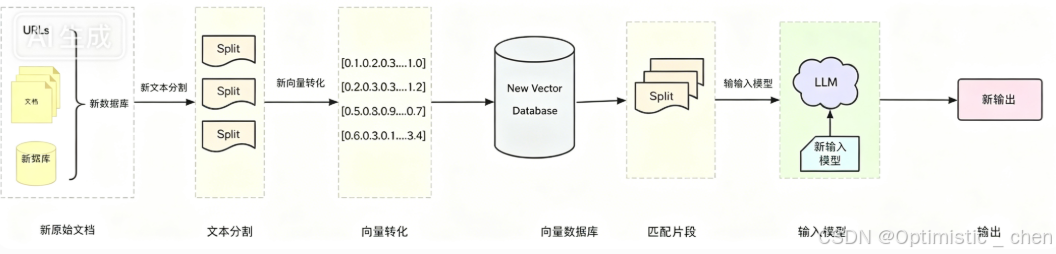
- 文档加载(Document Loading):加载不同来源的文档,不同的文档加载器可以加载不同格式的非结构化数据
- 文本分割(Splitting):文本分割把Document切分为指定大小的块
- 数据向量化:将切分好的Document块进行嵌入模型转化,即将⽂档块转换成向量的形式
- 存储(Storage):将Embedding后的向量数据,存储到向量数据库中
- 检索(Retrieval):数据存入向量数据库后,当我们需要进行数据检索时,通过检索算法找到与输入问题相似的文档块
- 增强上下文构建:系统将检索到的文本块与原始用户问题,按照一定模板组合成一个新的、内容丰富的提示词
- 输出:将上述增强后的Prompt发送给大模型,大模型生成的答案返回给用户
简单上手
文本向量化
添加pom.xml依赖
xml
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
</dependencies>文本向量化:这里需要引入嵌入模型来实现向量化,我使用的是阿里百炼平台提供的向量模型。

xml
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webflux</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>application.yml配置文件中添加配置:
yml
spring:
ai:
dashscope:
api-key: ${DASHSCOPE_API_KEY}相关代码可以观看官方文档向量化模型
向量存储
目前支持的向量数据库有Vector Database,也可以使用Redis、Oracle等数据库
学习阶段,我们使用SimpleVectorStore来存储向量,SimpleVectorStore 是SpringAI内置的⼀个"内存版"向量数据库,⽆需外部依赖,开箱即⽤。
定义VectorStore
java
//作⽤类似于 @Configuration ,但专⻔⽤于测试环境
@TestConfiguration
static class TestConfig {
@Bean
public VectorStore vectorStore(DashScopeEmbeddingModel embeddingModel){
return SimpleVectorStore.builder(embeddingModel).build();
}
}存储⽂档到VectorStore
java
@Test
public void init(@Autowired VectorStore vectorStore ){
Document doc=Docment.builder()
.text("2026年美加墨世界杯,预计吸引全球目光")
,build();
Document doc2=Docment.builder()
.text("枯藤老树昏鸦,小桥流水人家")
,build();
Document doc3=Docment.builder()
.text("基于机器学习的大语言模型")
,build();
Document doc4=Docment.builder()
.text("今天天气不错,适合出游")
,build();
//文本向量化
vectorStore.add(Arrays.asList(doc,doc2,doc3,doc4));
}相似性检索
向量存⼊到向量数据库之后,就可以来查找了
java
@Test
void similaritySearchTest(@Autowired VectorStore vectorStore) {
// 3. 相似性查询
SearchRequest searchRequest = SearchRequest
.builder().query("机器学习")
.topK(5)
.similarityThreshold(0.3)
.build();
List<Document> results = vectorStore.similaritySearch(searchRequest);
// 4.输出
System.out.println(results);
}调用similaritySearch方法时,会执行相似性搜索:
将"搜索词"转为向量,计算它与1向量库中文档的相似度,根据请求,过滤出相似度≥0.3的文档,并去top 5,最后返回这些匹配的原始文档列表。
Advisor让LLM"看到"向量数据库
Advisor机制是Spring AI提供的开箱即用支持,用于实现RAG技术。
QuestionAnswerAdvisor 和RetrievalAugmentationAdvisor是SpringAI中实现RAG的两个核⼼组件。
- QuestionAnswerAdvisor:⾯向问答场景的语义检索增强
- RetrievalAugmentationAdvisor:灵活可控的通⽤RAG增强层,它不局限于问答场景,⽽是作为⼀个通⽤的增强层,适⽤于任何需要引⼊外部知识的⽣成任务.
程序员通过自定义的Retriever接口来控制检索逻辑
java
@Bean
public RetrievalAugmentationAdvisor retrievalAugmentationAdvisor(
ChatModel chatModel,
VectorStore vectorStore) {
// 1. 创建检索器(指定返回3个文档)
var retriever = VectorStoreRetriever.builder(vectorStore)
.similarityThreshold(0.75) // 可选:相似度阈值
.topK(3) // 检索 top-3 结果
.build();
// 2. 自定义 Prompt 模板
String promptTemplateStr = """
你是一个企业智能助手,请根据以下【参考资料】回答问题。
如果资料中没有相关信息,请回答"抱歉,我无法找到相关信息。"
【参考资料】:
{documents}
【问题】:
{question}
【回答】:
""";
PromptTemplate template = new PromptTemplate(promptTemplateStr);
// 3. 构建 Advisor
return RetrievalAugmentationAdvisor.builder()
.documentRetriever(retriever) // 使用自定义检索器
.queryAugmenter(new ContextualQueryAugmenter(template)) // 注入模板
.build();假设开发⼈员已经将数据加载到中 VectorStore,就可以通过QuestionAnswerAdvisor实例来执⾏RAG
java
@Test
void chatRagTest(@Autowired VectorStore vectorStore,
@Autowired DashScopeChatModel chatModel
) {
ChatClient chatClient = ChatClient.builder(chatModel)
.build();
String message="世界杯什么时候举⾏";
String content =chatClient.prompt()
.advisors(new QuestionAnswerAdvisor(vectorStore))
.user(message).call().content();
System.out.println(content);
}ETL(提取,转化,加载)
RAG的核⼼理念是通过从⼤量数据中检索相关信息来增强⽣成式AI模型的能⼒,从⽽提⾼⽣成内容的质量和相关性。⽽ETL过程正是实现这⼀⽬标的关键环节------它将原始文档转化为可以被高效检索和使用的结构化数据,为后续检索和生成过程奠定基础。
- Extract:从原始数据源读取并捕获数据,输出为初步解析的中间格式
- Transform:转化原始数据为向量化数据
- Load:存入向量数据库,供检索使用
Document数据模型
Document是ETLAPI的核⼼数据模型,它构成了整个数据处理流程的基本单元。用来处理数据的提取、转化和加载。
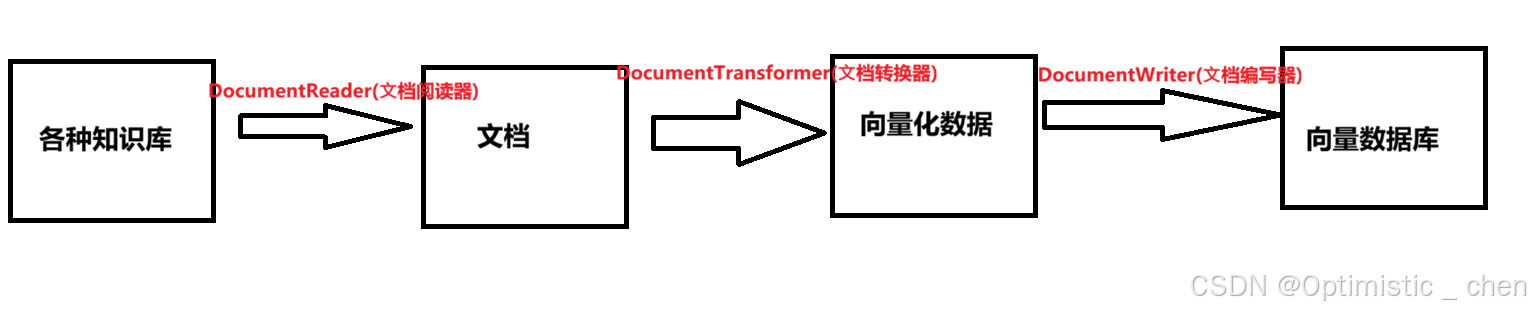
DocumentReader(⽂档阅读器)
java
public interface DocumentReader extends Supplier<List<Document>> {
default List<Document> read() {
return get();
}
}例如:JsonReader是一个用于将JSON数据转化为Document对象的工具类,主要用于从JSON文件中提取结构化数据并生成文档对象。
DocumentReader 是一个统一的顶层接口(或称抽象概念),代表所有文档读取器的总称。而 JsonReader 则是DocumentReader接口的一个具体实现。
简单来说,JsonReader 是一种对特定文档类型(即 JSON 格式文件)的读取器。
DocumentTransformer(⽂档转换器)
知识库中原始⽂档通常太⻓、格式混乱或缺乏结构化元数据,⽆法直接输⼊给LLM使⽤,对文本进行必要的转化和处理。
java
public interface DocumentTransformer extends Function<List<Document>,
List<Document>> {
default List<Document> transform(List<Document> transform) {
return apply(transform);
}
}主要有四个组件:
- TextSplitter(文本切分器):把⻓⽂切成⼩块
- ContentFormatTransformer(内容格式转换器): 统⼀清洗⽂本
- KeywordMetadataEnricher(关键词提取器):借助AI模型⾃动提取关键词,类似给⽂档"贴标签"
- SummaryMetadataEnricher(摘要⽣成器):借助AI模型⽣成⽂档摘要
DocumentWriter(⽂档编写器)
java
public interface DocumentWriter extends Consumer<List<Document>> {
default void write(List<Document> documents) {
accept(documents);
}
}FileDocumentWriter 是⼀个实现了 DocumentWriter 接⼝的类,⽤于将⼀组 Document 对象的内容写⼊到指定的⽂本⽂件中.适⽤于调试、⽇志记录或⽣成⼈类可读的⽂档输出。
java
FileDocumentWriter writer = new FileDocumentWriter("output.txt",
true, MetadataMode.ALL, false);向量化的存储,上面提到的SimpleVectorStore就是其中一种。
重排序
RAG已经实现了快速从海量⽂档中"找到看起来相关的⽚段",但是,在实际应⽤中,我们发现其排序结果并不总是最优;最相似的向量 ≠ 最相关的答案
Re-Ranking(重排序) 是指在初步检索出⼀批候选⽂档后,使⽤⼀个更加精细、专精于相关性判断的模
型,重新评估每个⽂档与查询之间的匹配程度,并按新得分重新排序。
- 粗排阶段:使⽤向量数据库进⾏快速ANN搜索,召回⼀批候选⽂档
- 精排阶段:调⽤更精细的排序模型(如Cross-Encoder类重排序模型),计算每个⽂档与原始查询之间的细粒度语义匹配分数
- 根据重排序后的得分重新排列⽂档顺序,选取top-k⾼质量上下⽂;
- 将优化后的上下⽂注⼊Prompt,交由LLM⽣成最终回答
Spring AI中提供了开箱即用的支持组件:RetrievalRerankAdvisor
java
@SpringBootTest
public class RerankTest {
private SimpleVectorStore simpleVectorStore;
@Autowired
public RerankTest(EmbeddingModel embeddingModel) {
this.simpleVectorStore = SimpleVectorStore.builder(embeddingModel).build();
}
@BeforeEach
void testSimpleVectorStore(@Value("classpath:/file/rule.txt")Resource resource){
//读取
TextReader reader = new TextReader(resource);
List<Document> documents = reader.get();
TokenTextSplitter splitter = new TokenTextSplitter(200, 50, 5, 1000, true);
List<Document> apply = splitter.apply(documents);
simpleVectorStore.add(apply);
System.out.println("向量存储写入完成");
}
@Test
void testRerank(@Autowired DashScopeRerankModel rerankModel,
@Autowired DashScopeChatModel chatModel){
ChatClient client = ChatClient.builder(chatModel).build();
//1. 定义一个advisor, 提供rerank模型
RetrievalRerankAdvisor rerankAdvisor = new RetrievalRerankAdvisor(simpleVectorStore,
rerankModel, SearchRequest.builder().topK(10).build());
//2. 把这个advisor 绑定给chatclient
String content = client.prompt()
.user("金卡会员打几折")
.advisors(rerankAdvisor)
.call()
.content();
System.out.println(content);
}
}完结撒花!🎉
如果这篇博客对你有帮助,不妨点个赞支持一下吧!👍
你的鼓励是我创作的最大动力~
✨ 想获取更多干货? 欢迎关注我的专栏 → optimistic_chen
📌 收藏本文,下次需要时不迷路!
我们下期再见!💫 持续更新中......
悄悄说:点击主页有更多精彩内容哦~ 😊