目录
[1 · 链表的概念与结构](#1 · 链表的概念与结构)
[2 · 链表的分类](#2 · 链表的分类)
[3 · 单链表的实现](#3 · 单链表的实现)
[3 - 1 · 接口总览与结构定义](#3 - 1 · 接口总览与结构定义)
[3 - 2 · 申请结点,销毁,打印](#3 - 2 · 申请结点,销毁,打印)
[3 - 2 - 1 · 申请一个结点](#3 - 2 - 1 · 申请一个结点)
[3 - 2 - 2 · 销毁](#3 - 2 - 2 · 销毁)
[3 - 2 - 3 · 打印](#3 - 2 - 3 · 打印)
[3 - 2 - 4 · 测试](#3 - 2 - 4 · 测试)
[3 - 3 · 头插,头删](#3 - 3 · 头插,头删)
[3 - 3 - 1 · 头插](#3 - 3 - 1 · 头插)
[3 - 3 - 2 · 头删](#3 - 3 - 2 · 头删)
[3 - 3 - 3 · 测试](#3 - 3 - 3 · 测试)
[3 - 4 · 尾插,尾删](#3 - 4 · 尾插,尾删)
[3 - 4 - 1 · 尾插](#3 - 4 - 1 · 尾插)
[3 - 4 - 2 · 尾删](#3 - 4 - 2 · 尾删)
[3 - 4 - 3 · 测试](#3 - 4 - 3 · 测试)
[3 - 5 · 查找,指定位置之后插入,指定位置之后删除](#3 - 5 · 查找,指定位置之后插入,指定位置之后删除)
[3 - 5 - 1 · 查找](#3 - 5 - 1 · 查找)
[3 - 5 - 2 · 指定位置之后插入](#3 - 5 - 2 · 指定位置之后插入)
[3 - 5 - 3 · 指定位置之后删除](#3 - 5 - 3 · 指定位置之后删除)
[3 - 5 - 4 · 测试](#3 - 5 - 4 · 测试)
[4 · 单链表缺陷](#4 · 单链表缺陷)
1 · 链表的概念与结构
链表也是一种线性表,因此链表在逻辑上是线性结构的。
概念:链表是一种物理存储结构上非连续 、非顺序的存储结构,数据元素的逻辑顺序 是通过链表中的指针链接次序实现的 。
在结构上,链表一般是采用链式结构的,如下图:
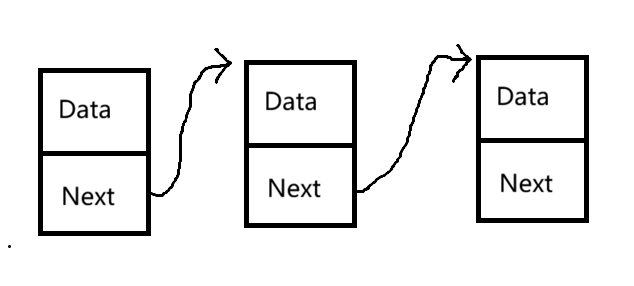
其中 Data 是存放的数据, Next 是指向下一个结点的指针。
从形态上来看,链式结构有点类似于火车的一节节车厢。
注意:
-
链式结构在逻辑上是连续的,但是在物理结构上不一定连续
-
结点一般是从堆上申请出来的
-
连续两次从堆上申请空间,这两次申请到的空间可能连续,也可能不连续。
2 · 链表的分类
实际中,链表的结构非常多样。
一个链表有三种选择:
1. 单向或双向
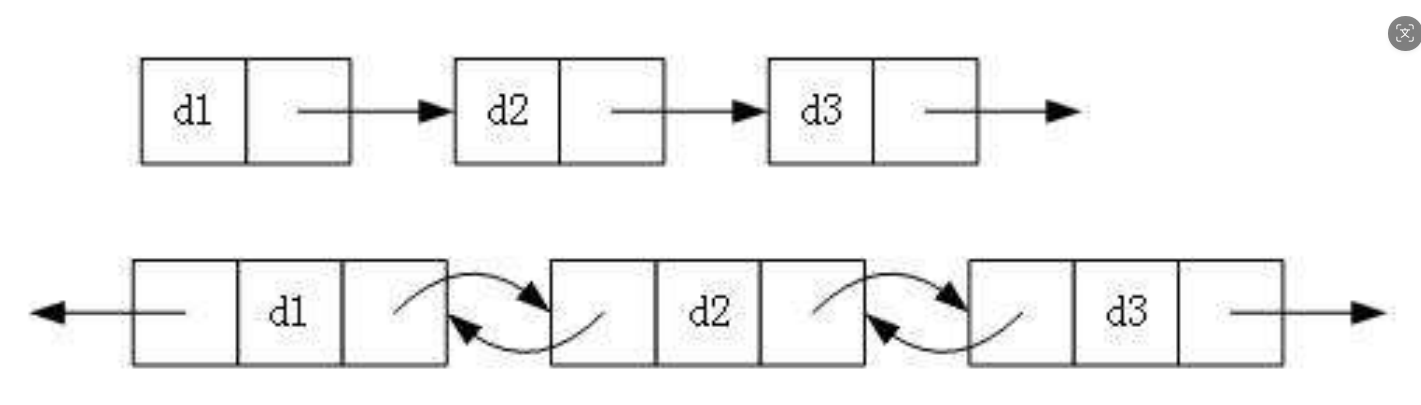
2. 带头或不带头
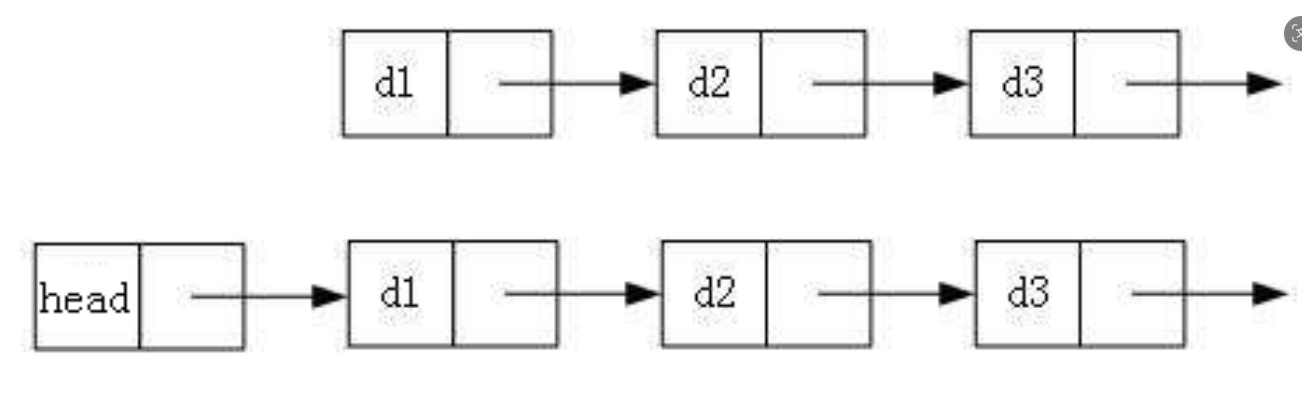
3. 循环或不循环
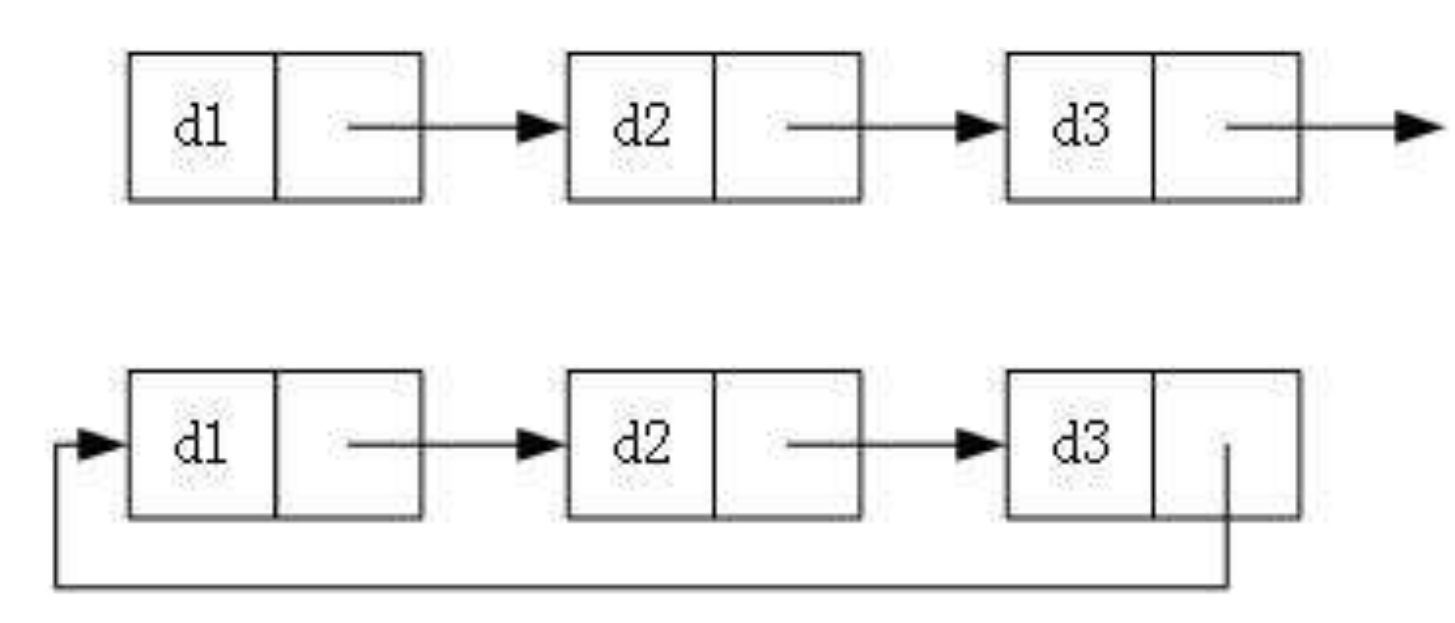
每种选择可以随心搭配,这么算下来,链表一共就有8种结构了。
虽然有这么多结构,但最常用的是下面这两种:
-
单向 不带头 不循环 链表,也称为 单链表
-
双向 带头 循环 链表, 也称为 双向链表
当然,掌握了这两种,掌握剩下六种也不是问题。
单链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结
构,如哈希桶、图的邻接表等等。
双向链表: 结构最复杂 ,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向 循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而 简单了。
本篇介绍的是单链表。
3 · 单链表的实现
3 - 1 · 接口总览与结构定义
如下:
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
typedef int SLDataType;
typedef struct SListNode
{
SLDataType data;
struct SListNode* next;//指向下一个结点
}SListNode;
//申请一个结点
SListNode* BuyNode(SLDataType x);
//打印
void SListPrint(SListNode* plist);
//头插
void SListPushFront(SListNode** pplist, SLDataType x);
//头删
void SListPopFront(SListNode** pplist);
//尾插
void SListPushBack(SListNode** pplist, SLDataType x);
//尾删
void SListPopBack(SListNode** pplist);
//查找
SListNode* SListFind(SListNode* plist, SLDataType x);
// 对指定位置的后一个位置插入
void SListInsertAfter(SListNode* pos, SLDataType x);
// 对指定位置的后一个位置删除
void SListEraseAfter(SListNode* pos);
//销毁
void SListDestroy(SListNode** ppl);这里用到了 typedef ,最上面的是方便进行存储类型的修改,在代码实现中用 SLDataType,到时候如果想要修改存储的类型,只需要改这里一处即可。
下面在结构体 这里的 typedef 是方便后续使用,可以少写 struct。
这里结构体当中的 struct SListNode* next 中的struct 是不能省略的,因为typedef 是在结构体定义完成之后再进行重命名的,如果结构体中的这个 struct 省略的话,会导致编译器不认识这个成员的类型。
3 - 2 · 申请结点,销毁,打印
3 - 2 - 1 · 申请一个结点
代码如下:
SListNode* BuyNode(SLDataType x)
{
SListNode* newNode = (SListNode*)malloc(sizeof(SListNode));
if (newNode == NULL)
{
perror("malloc");
exit(1);
}
newNode->data = x;
newNode->next = NULL;
return newNode;
}链表没有最大容量的概念,当需要的时候就申请一个结点。那么就需要使用到有关内存开辟的函数,因此我们拿到的是一个指向这个结点的指针。
3 - 2 - 2 · 销毁
代码如下:
void SListDestroy(SListNode** pplist)
{
assert(pplist);
//空表不用删
if (*pplist)
{
return;
}
SListNode* pcur = *pplist;
while (pcur != NULL)
{
SListNode* pnext = pcur->next;
free(pcur);
pcur = pnext;
}
*pplist = NULL;
}我们到时候对链表进行访问的时候,会定义一个指向第一个结点的一级指针变量,相当于火车头,然后由火车头开始一节一节访问车厢。
而如若需要对这个一级指针变量进行修改,那么传参就需要传地址,形参就需要用二级指针来接收。
这里的 pcur 均可换成 *pplist ,不过需要注意的是 ->(结构体成员访问操作符) 的优先级高于 *(解引用操作符),所以如果要换 pcur->next; 应换成 (*pplist)->next;
3 - 2 - 3 · 打印
代码如下:
void SListPrint(SListNode* plist)
{
SListNode* pcur = plist;
while (pcur)
{
printf("%d -> ", pcur->data);
pcur = pcur->next;
}
printf("NULL");
printf("\n");
}简单来说,就是一边一个一个结点遍历,一边打印,直到走到表尾,即结点的指针域为空指针。
为了更加直观,所以在打印的时候加上了箭头(->)
3 - 2 - 4 · 测试
测试一下上面的功能:
#include "SingleList.h"
void Test1()
{
SListNode* p = NULL;
SListNode* node1 = BuyNode(1);
SListNode* node2 = BuyNode(2);
SListNode* node3 = BuyNode(3);
p = node1;
node1->next = node2;
node2->next = node3;
SListPrint(p);
SListDestroy(&p);
}
int main()
{
Test1();
//Test2();
//Test3();
//Test4();
return 0;
}这里我们手动将结点连接起来了,直接运行试试:

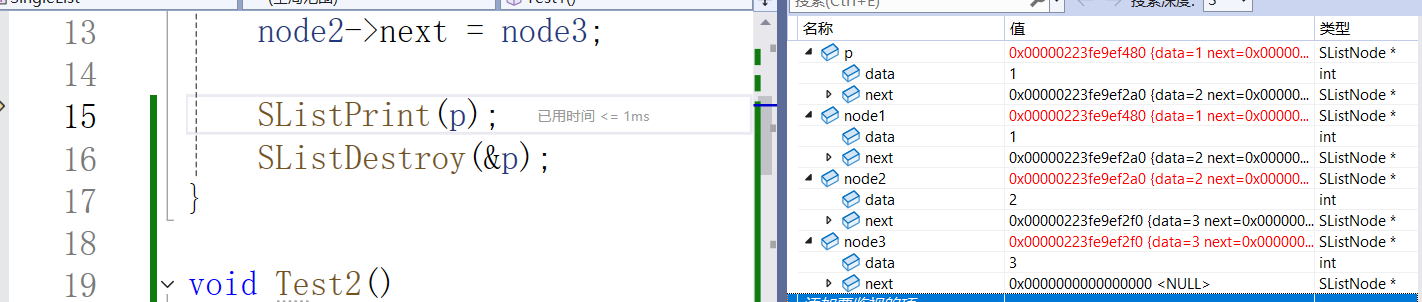
下面我们用调试看看销毁:
销毁前:
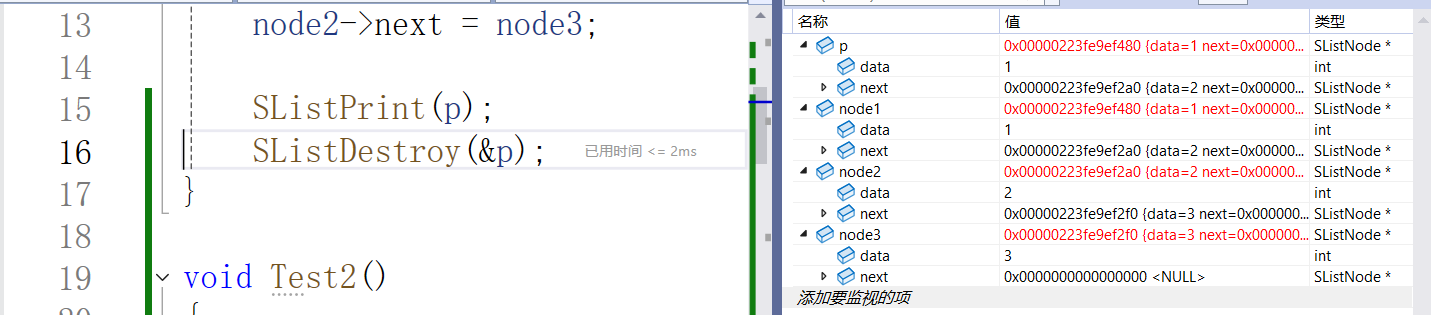
销毁后:
3 - 3 · 头插,头删
3 - 3 - 1 · 头插
头插就是在表头进行插入,代码如下:
void SListPushFront(SListNode** pplist, SLDataType x)
{
assert(pplist);
SListNode* pcur = *pplist;
SListNode* newNode = BuyNode(x);
newNode->next = pcur;
*pplist = newNode;
}我们画个图方便理解:
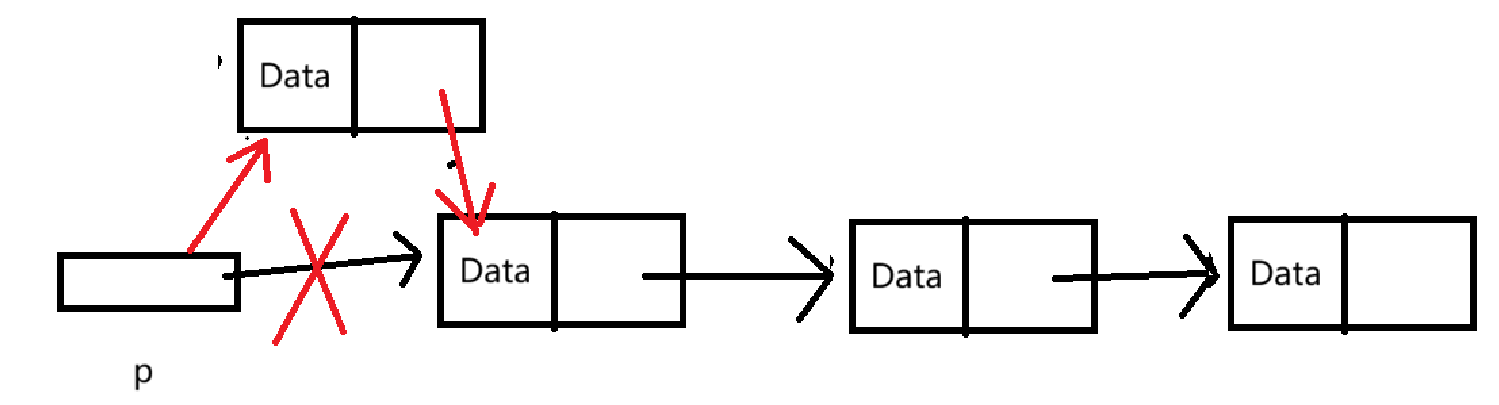
其中,红色是我们需要进行的操作。
p是指向单链表第一个元素的指针,方便我们进行访问,因此我们是需要修改这个一级指针的,那么传参时传的是一级指针的地址,形参就需要用二级指针接收。后文的形参使用二级指针均是由于p可能需要修改,后文将不再赘述。
我们也能看出,我们的操作需要按照一定的顺序来进行,需要先进行对 newNode 的指针域的修改,再改变p的指向,否则将找不到p原本指向的结点。
3 - 3 - 2 · 头删
头删就是删除表头的结点,代码如下:
void SListPopFront(SListNode** pplist)
{
//空表不能删
assert(pplist && *pplist);
SListNode* pcur = *pplist;
SListNode* newNext = pcur->next;
free(pcur);
*pplist = newNext;
}我们画个图方便理解:
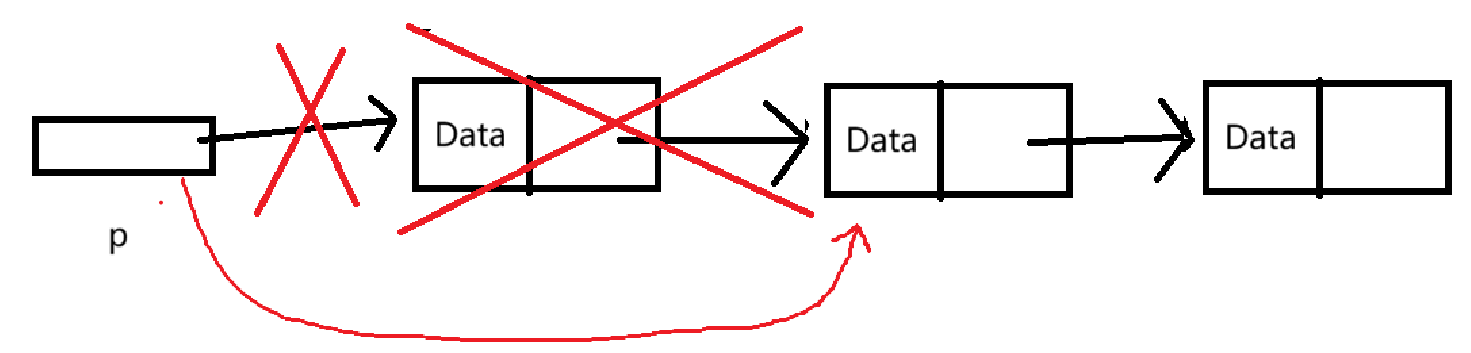
其中,红色是我们需要进行的操作。
空表是不能进行删除的,空表的判定是 指向第一个结点的指针为空,即p == NULL 。
我们的结点是动态开辟出来的,因此删除时需要使用 free函数。
需要注意的是,当删除一个结点后,结点的指针域也就没了,此时就找不到该结点指向的下一个结点了。因此在删除前,需要记录下将删除结点的指针域。
3 - 3 - 3 · 测试
我们对上面的功能测试一下:
void Test2()
{
SListNode* p = NULL;
SListPushFront(&p, 1);
SListPrint(p);
SListPushFront(&p, 2);
SListPrint(p);
SListPopFront(&p);
SListPrint(p);
SListPopFront(&p);
SListPrint(p);
//SListPopFront(&p);
//SListPrint(p);
SListDestroy(&p);
}
int main()
{
//Test1();
Test2();
//Test3();
//Test4();
return 0;
}运行一下:

此时再进行一次头删,便会触发assert断言:
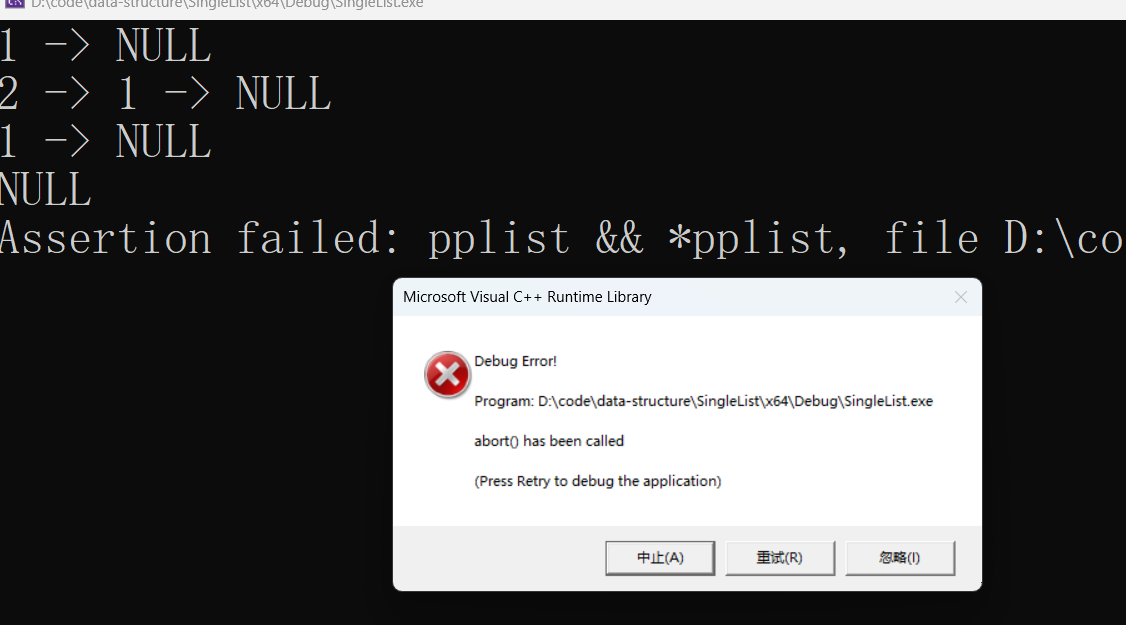
3 - 4 · 尾插,尾删
3 - 4 - 1 · 尾插
尾插就是在表尾进行插入,代码如下:
void SListPushBack(SListNode** pplist, SLDataType x)
{
assert(pplist);
SListNode* pcur = *pplist;
SListNode* newNode = BuyNode(x);
//如果是空表,直接给
if (pcur == NULL)
{
*pplist = newNode;
}
//非空表
else
{
//找尾
while (pcur->next)
{
pcur = pcur->next;
}
//尾插
pcur->next = newNode;
}
}我们画张图方便理解:
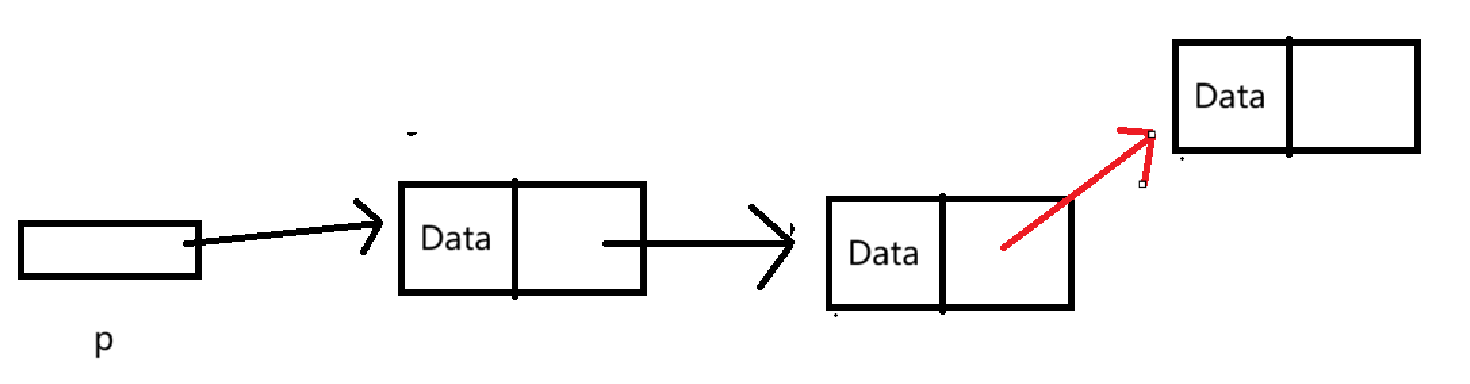
其中 红色是我们需要进行的操作。
由于链式结构在物理结构上极大概率是不连续的,因此无法直接找到表尾,需要一个一个结点走下来才能找到表尾。
因此需要进行对成员变量next进行访问,此时就会产生问题,如果为空表,那么p == NULL ,此时对next 进行访问就发生了对空指针解引用的问题。
由此分出两种情况:空表与非空表。
3 - 4 - 2 · 尾删
尾删就是对表尾进行删除,代码如下:
void SListPopBack(SListNode** pplist)
{
//空表不能删
assert(pplist && *pplist);
SListNode* pcur = *pplist;
//如果只有一个元素
if (pcur->next == NULL)
{
free(pcur);
*pplist = NULL;
}
//表中有多个元素
else
{
//表尾的前一个
SListNode* prev = pcur;
//找尾
while (pcur->next)
{
prev = pcur;
pcur = pcur->next;
}
free(pcur);
prev->next = NULL;
}
}方便理解,我们画张图:

其中 红色是我们需要进行的操作。
需要将表尾的结点进行删除,并且将新表尾的指针域置空。
因此需要定义两个指针,一个前一个后,相差一步。
需要注意的是:如果表中只有一个元素的情况,是需要将p 置空的。
因此分出两种情况:表中只有一个元素与表中有多个元素。
3 - 4 - 3 · 测试
我们对上面的功能测试一下:
void Test3()
{
SListNode* p = NULL;
SListPushBack(&p, 1);
SListPrint(p);
SListPushBack(&p, 2);
SListPrint(p);
SListPushBack(&p, 3);
SListPrint(p);
SListPopBack(&p);
SListPrint(p);
SListPopBack(&p);
SListPrint(p);
SListPopBack(&p);
SListPrint(p);
//SListPopBack(&p);
//SListPrint(p);
SListDestroy(&p);
}
int main()
{
//Test1();
//Test2();
Test3();
//Test4();
return 0;
}运行一下:

此时再进行一次尾删,便会触发 assert断言。
3 - 5 · 查找,指定位置之后插入,指定位置之后删除
3 - 5 - 1 · 查找
找到第一个符合所给值的结点,代码如下:
SListNode* SListFind(SListNode* plist, SLDataType x)
{
SListNode* pcur = plist;
while (pcur)
{
if (pcur->data == x)
{
return pcur;
}
pcur = pcur->next;
}
//没找到
return NULL;
}简单来说,就是遍历一遍,查找,如果没找到就返回空指针。
3 - 5 - 2 · 指定位置之后插入
在指定的位置的后一个位置进行插入,代码如下:
void SListInsertAfter(SListNode* pos, SLDataType x)
{
assert(pos);
SListNode* newNode = BuyNode(x);
newNode->next = pos->next;
pos->next = newNode;
}方便理解,我们画张图:
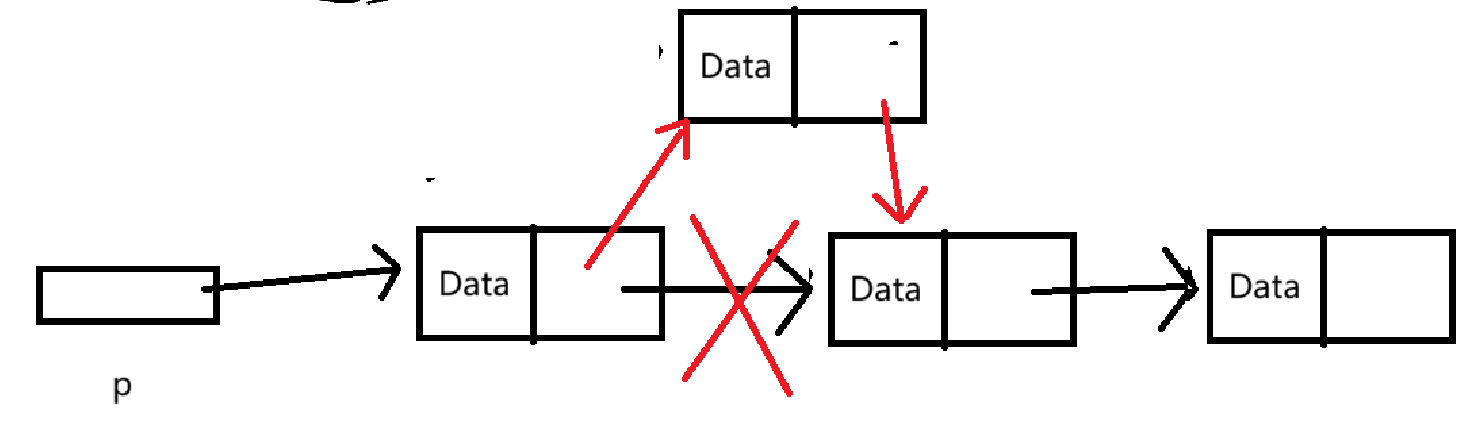
红色是我们需要进行的操作。
可以看到,和头插的操作差不多,当然也有对顺序的要求。
现在你可能会有疑问:为什么没有 指定位置之前插入 这个接口?
如果要在指定位置之前插入,那么就需要先找到 指向这个指定位置的结点,即指定位置的直接前驱结点。我们可以发现,对于单链表,找后继结点容易,可以顺着指针域一个一个找到,但是找前驱结点是难的。
如果要找到指定位置的直接前驱结点,需要加上一个参数:SListNode** pplist , 从表头开始一个一个遍历,才能找到指定位置的直接前驱结点。显然比较麻烦。
3 - 5 - 3 · 指定位置之后删除
对指定位置的后一个位置进行删除,代码如下:
void SListEraseAfter(SListNode* pos)
{
//如果pos在表尾,后一个不能删
assert(pos && pos->next);
SListNode* pnext = pos->next;
pos->next = pnext->next;
free(pnext);
pnext = NULL;
}方便理解,我们画个图:
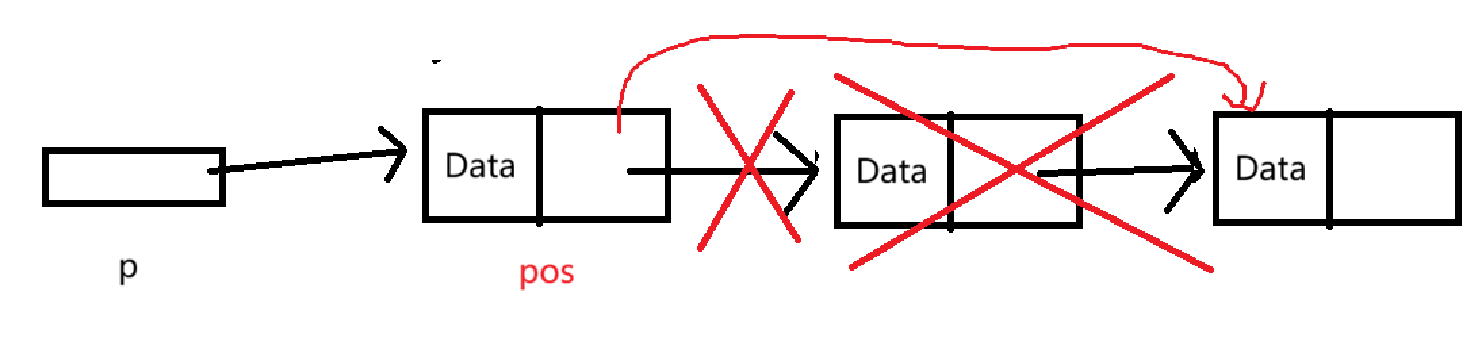
红色是我们需要进行的操作。
可以看出,与头删类似,需要先保存将删除结点的指针域。
由于是对指定位置的后一个位置删除,自然指定位置是不能为表尾的。
那么这时候你可能会疑惑,为什么没有 删除指定位置 的接口?
原因与没有 指定位置之前插入 这个接口类似,如果删除指定位置,那么就需要更改 指定位置的直接前驱结点 的指针域,在单链表中找直接前驱结点是很麻烦的。
3 - 5 - 4 · 测试
我们对上面的功能进行测试:
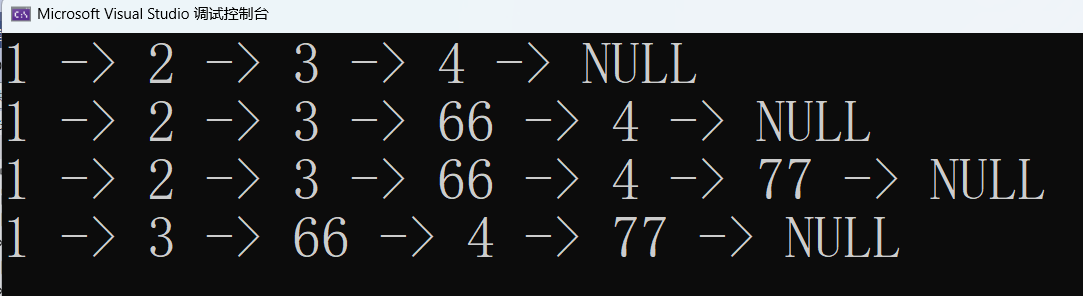
void Test4()
{
SListNode* p = NULL;
SListPushBack(&p, 1);
SListPushBack(&p, 2);
SListPushBack(&p, 3);
SListPushBack(&p, 4);
SListPrint(p);
SListNode* find = SListFind(p, 3);
SListInsertAfter(find, 66);
SListPrint(p);
find = SListFind(p, 4);
SListInsertAfter(find, 77);
SListPrint(p);
find = SListFind(p, 1);
SListEraseAfter(find);
SListPrint(p);
SListDestroy(&p);
}
int main()
{
//Test1();
//Test2();
//Test3();
Test4();
return 0;
}运行一下:
4 · 单链表缺陷
我们可以看到,上面的接口其实是不一致的,有的使用一级指针,有的却使用的是二级指针。
并且单链表找前面的结点是很困难的。因此对于 在指定位置之后插入 与 对指定位置进行删除,实现起来是很麻烦的。
总结
以上简单介绍了单链表有关内容,关于数据结构其余内容,请期待后续更新。
以上内容如有错误或不准确之处,欢迎指出,或者你有更好的想法,也欢迎交流。