
🔥承渊政道: 个人主页
❄️个人专栏: 《C语言基础语法知识》 《数据结构与算法》 《C++知识内容》 《Linux系统知识》 《算法刷题指南》 《测评文章活动推广》 《大模型语言路线学习》
✨逆境不吐心中苦,顺境不忘来时路!✨ 🎬 博主简介:

在算法学习中,贪心算法一直是一个既"直观"又"容易踩坑"的专题.它的核心思想看似简单:每一步都选择当前看来最优的方案,最终希望得到全局最优解.但真正落到题目中,难点往往不在于"会不会贪",而在于如何找到正确的贪心策略,以及如何证明这个策略不会出错 .本篇文章将继续围绕贪心算法的经典实战应用展开,通过几个非常具有代表性的题目,进一步体会贪心思想在不同场景下的灵活运用.我们会依次分析:K 次取反后最大化的数组和、根据身高重建队列、优势洗牌、最长回文串、增减字符串匹配等问题.这些题目表面上涉及数组、排序、字符串、双指针等不同知识点,但背后都隐藏着一个共同思路:在合适的时机做出局部最优选择,并让这些选择逐步逼近整体最优.通过本篇内容,希望你不仅能够掌握这些题目的解法,更能理解每道题中贪心策略的设计逻辑,为后续解决更复杂的贪心问题打下基础.废话不多说,下面跟着小编的节奏🎵一起去疯狂的学习吧!

目录
1.K次取反后最⼤化的数组和(OJ题)

解法(贪心):
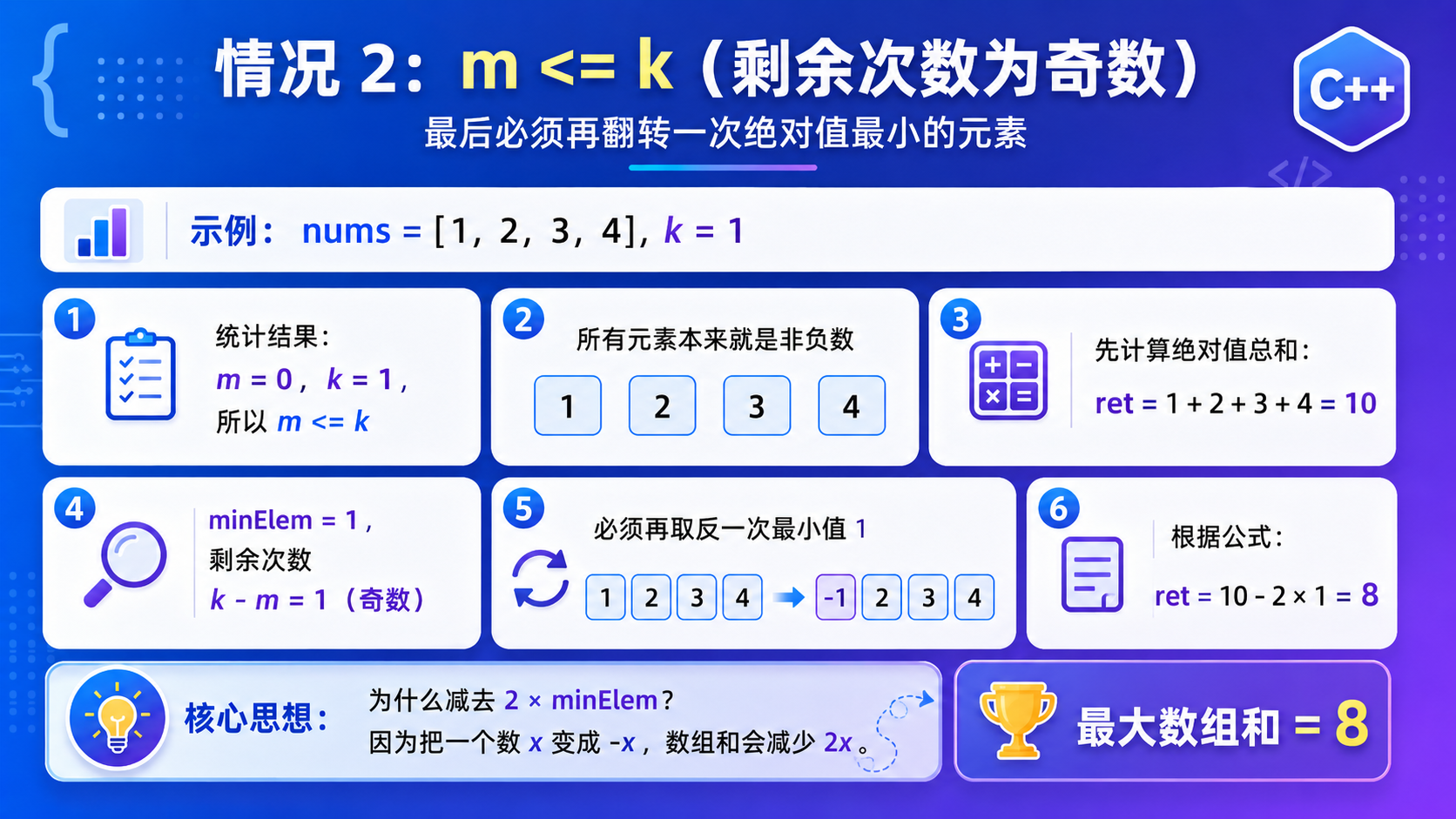
贪心策略 :分情况讨论,设整个数组中负数的个数为 m 个:
a. m > k:把前 k 小负数,全部变成正数;
b. m == k:把所有的负数全部转化成正数;
c. m < k:
i. 先把所有的负数变成正数;
ii. 然后根据 k - m 的奇偶分情况讨论:
-
如果是偶数,直接忽略;
-
如果是奇数,挑选当前数组中最小的数,变成负数.





核心代码
cpp
class Solution
{
public:
//函数功能:对数组进行k次取反操作,返回能得到的最大数组和
//参数:nums-目标数组;k-取反次数
int largestSumAfterKNegations(vector<int>& nums, int k)
{
//m:统计数组中**负数的个数**
//minElem:记录数组中**绝对值最小的元素**(初始为int最大值)
//n:数组的长度
int m = 0, minElem = INT_MAX, n = nums.size();
//第一次遍历数组:统计负数数量 + 找绝对值最小的数
for(auto x : nums)
{
//如果当前数字是负数,负数计数+1
if(x < 0)
m++;
//更新绝对值最小的元素
minElem = min(minElem, abs(x));
}
//最终结果:最大数组和
int ret = 0;
//情况1:负数的数量 大于 取反次数k
if(m > k)
{
//对数组升序排序(最小的负数排在最前面)
sort(nums.begin(), nums.end());
//把前k个最小的负数取反为正数,累加到结果
for(int i = 0; i < k; i++)
{
ret += -nums[i];
}
//剩余数字直接累加(保持原值)
for(int i = k; i < n; i++)
{
ret += nums[i];
}
}
//情况2:负数的数量 小于等于 取反次数k
else
{
//第一步:把所有负数都取反为正数,累加总和
for(auto x : nums)
ret += abs(x);
//剩余取反次数:k - m(所有负数转正后,还剩的取反次数)
//如果剩余次数是**奇数**:需要对绝对值最小的数再取反一次(总和 -= 2*minElem)
//如果剩余次数是**偶数**:取反两次抵消,无需操作
if((k - m) % 2)
{
ret -= minElem * 2;
}
}
//返回最终最大和
return ret;
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
class Solution
{
public:
// 函数功能:对数组进行 k 次取反操作,返回能得到的最大数组和
// 参数:nums - 目标数组;k - 取反次数
int largestSumAfterKNegations(vector<int>& nums, int k)
{
// m:统计数组中负数的个数
// minElem:记录数组中绝对值最小的元素
// n:数组的长度
int m = 0, minElem = INT_MAX, n = nums.size();
// 第一次遍历数组:统计负数数量 + 找绝对值最小的数
for (auto x : nums)
{
if (x < 0)
m++;
minElem = min(minElem, abs(x));
}
// 最终结果:最大数组和
int ret = 0;
// 情况1:负数的数量大于取反次数 k
if (m > k)
{
// 对数组升序排序,最小的负数排在最前面
sort(nums.begin(), nums.end());
// 把前 k 个最小的负数取反为正数,累加到结果
for (int i = 0; i < k; i++)
{
ret += -nums[i];
}
// 剩余数字直接累加
for (int i = k; i < n; i++)
{
ret += nums[i];
}
}
// 情况2:负数的数量小于等于取反次数 k
else
{
// 把所有负数都取反为正数,累加总和
for (auto x : nums)
ret += abs(x);
// 如果剩余次数是奇数,需要对绝对值最小的数再取反一次
if ((k - m) % 2)
{
ret -= minElem * 2;
}
}
return ret;
}
};
void printVector(const vector<int>& nums)
{
cout << "[";
for (size_t i = 0; i < nums.size(); i++)
{
cout << nums[i];
if (i != nums.size() - 1)
cout << ", ";
}
cout << "]";
}
int main()
{
Solution sol;
vector<pair<vector<int>, int>> testCases = {
{{4, 2, 3}, 1}, // 取反 2:[-2] -> 2,结果 5
{{3, -1, 0, 2}, 3}, // 有 0,剩余取反次数可作用在 0 上,结果 6
{{2, -3, -1, 5, -4}, 2}, // 取反 -4 和 -3,结果 13
{{-8, 3, -5, -3, -5, -2}, 6},// 负数数量 <= k,剩余次数为奇数
{{-1, -2, -3, -4}, 2}, // 负数数量 > k,只取反最小的两个负数
{{-1, -2, -3, -4}, 4}, // 所有负数都取反
{{-1, -2, -3, -4}, 5}, // 所有负数取反后,剩余奇数次
{{1, 2, 3, 4}, 2}, // 全是正数,偶数次取反,结果不变
{{1, 2, 3, 4}, 1}, // 全是正数,奇数次取反,取反最小值 1
{{0, 1, 2, 3}, 5}, // 有 0,剩余取反次数不影响结果
{{-5}, 1}, // 单个负数,取反后为 5
{{5}, 1}, // 单个正数,取反后为 -5
{{5}, 2}, // 单个正数,取反两次仍为 5
{{-2, 9, 9, 8, 4}, 5} // 剩余奇数次,取反绝对值最小的 2
};
for (int i = 0; i < testCases.size(); i++)
{
vector<int> nums = testCases[i].first;
int k = testCases[i].second;
cout << "测试用例 " << i + 1 << ":";
printVector(nums);
cout << ",k = " << k << endl;
cout << "最大数组和:";
cout << sol.largestSumAfterKNegations(nums, k) << endl;
cout << "------------------------" << endl;
}
return 0;
}
2.按身高排序(OJ题)

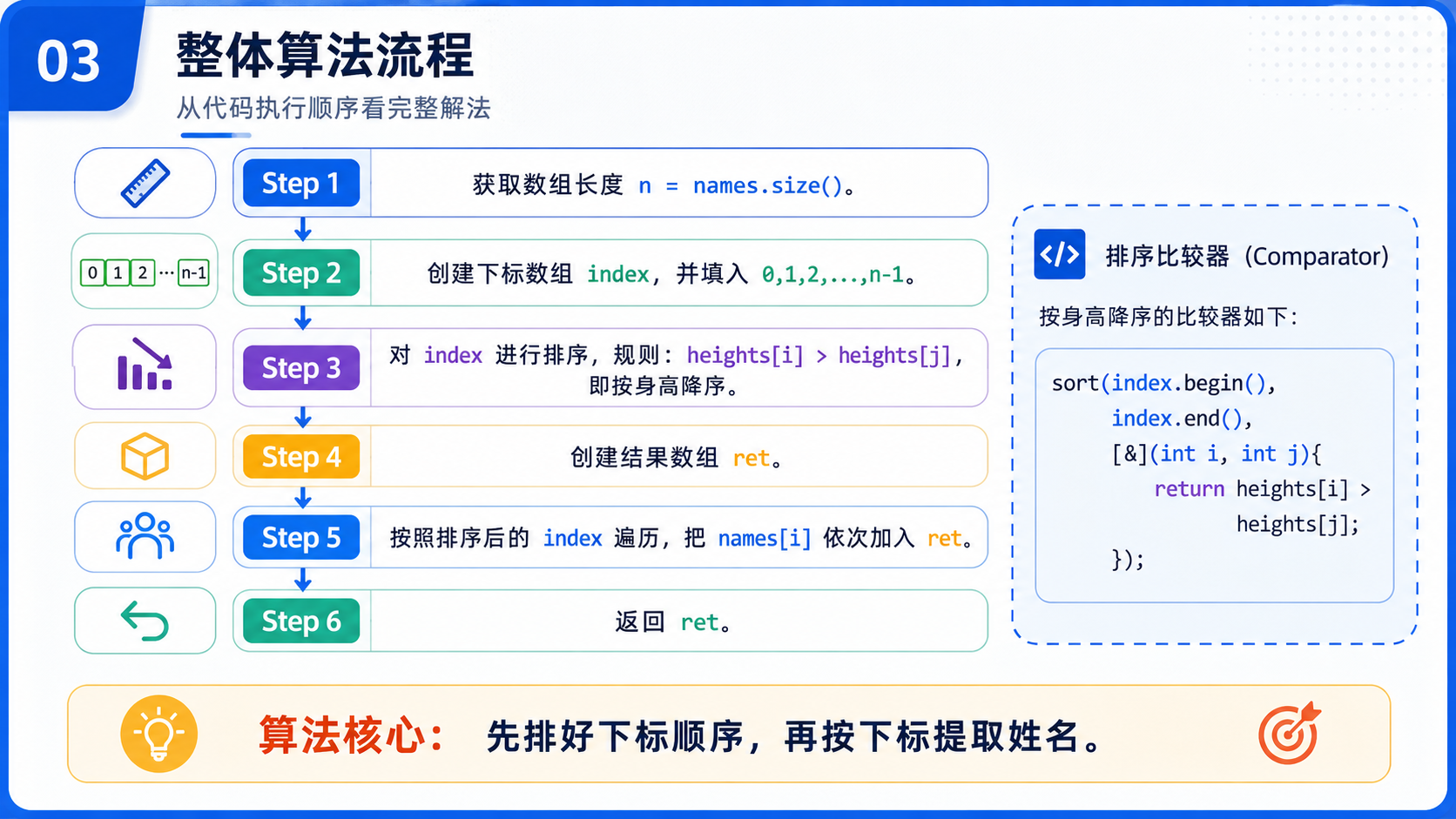
解法(通过排序"索引"的方式):
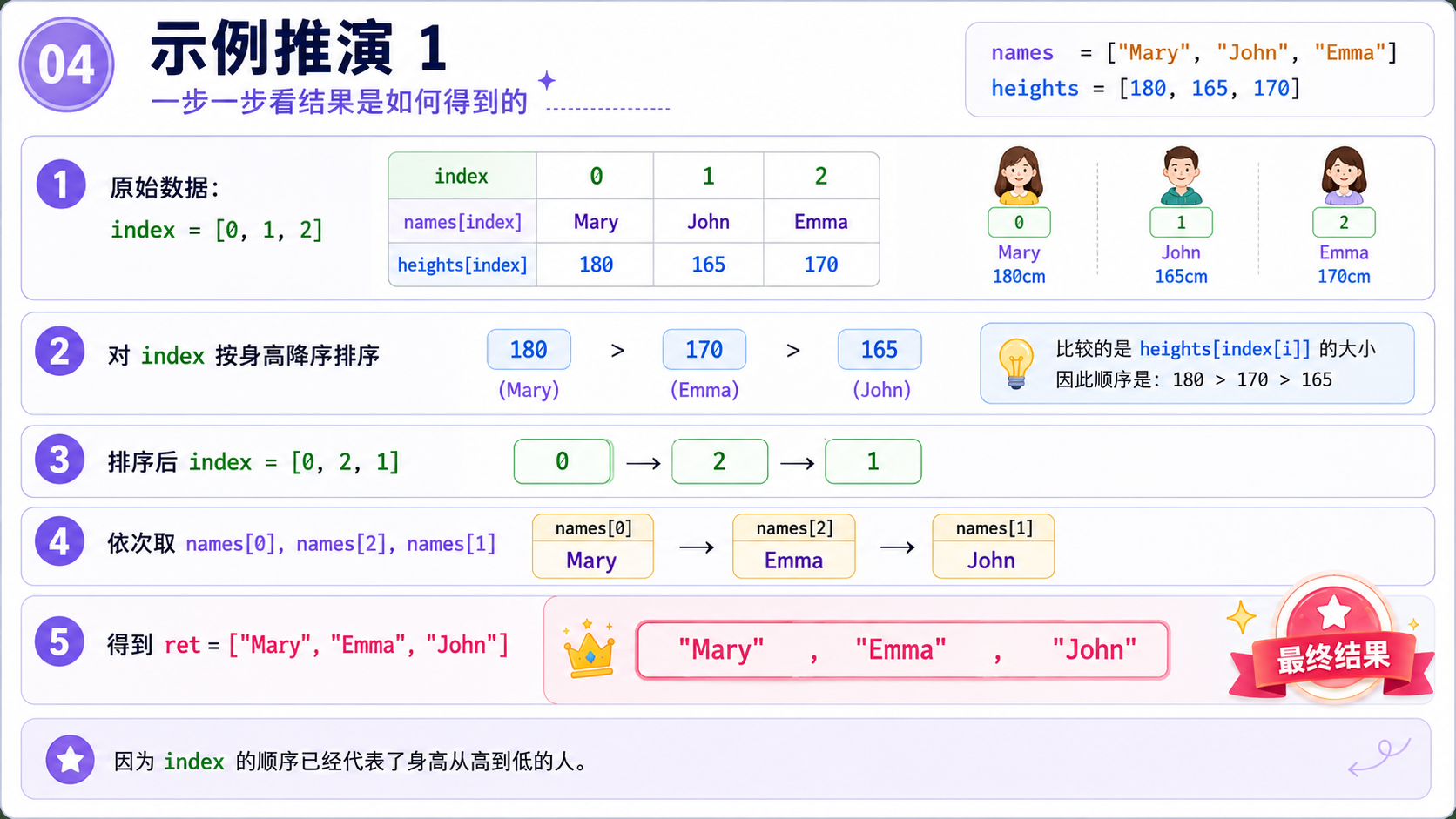
算法思路 :我们不能直接按照 i 位置对应的 heights 来排序,因为排序过程是会移动元素的,但是 names 内的元素是不会移动的.由题意可知,names 数组和 heights 数组的下标是一一对应的,因此我们可以重新创建出来一个下标数组,将这个下标数组按照 heights[i] 的大小排序.
那么,当下标数组排完序之后,里面的顺序就相当于 heights 这个数组排完序之后的下标.之后通过排序后的下标,依次找到原来的 name,完成对名字的排序.



核心代码
cpp
class Solution
{
public:
//参数:names-姓名数组;heights-身高数组(一一对应)
//返回值:按身高降序排列后的姓名数组
vector<string> sortPeople(vector<string>& names, vector<int>& heights)
{
//获取数组长度(姓名和身高长度一致)
int n = names.size();
//1.创建下标数组 index:存储 0,1,2...n-1 原始下标
//作用:不修改原数组,通过排序下标来关联姓名和身高,保证一一对应
vector<int> index(n);
for(int i = 0; i < n; i++)
index[i] = i;
//2.对下标数组进行自定义排序
//使用sort + lambda匿名函数:自定义排序规则
//规则:按照身高 降序 排列(heights[i] > heights[j])
sort(index.begin(), index.end(), [&](int i, int j)
{
//身高大的下标排在前面
return heights[i] > heights[j];
});
//3.根据排序后的下标,提取对应的姓名,生成结果数组
vector<string> ret;
//遍历排序后的下标数组
for(int i : index)
{
//按下标取出姓名,添加到结果中
ret.push_back(names[i]);
}
//返回最终排序后的姓名数组
return ret;
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <string>
#include <algorithm>
using namespace std;
class Solution
{
public:
// 参数:names - 姓名数组;heights - 身高数组(一一对应)
// 返回值:按身高降序排列后的姓名数组
vector<string> sortPeople(vector<string>& names, vector<int>& heights)
{
// 获取数组长度(姓名和身高长度一致)
int n = names.size();
// 1. 创建下标数组 index:存储 0,1,2...n-1 原始下标
// 作用:不修改原数组,通过排序下标来关联姓名和身高,保证一一对应
vector<int> index(n);
for (int i = 0; i < n; i++)
index[i] = i;
// 2. 对下标数组进行自定义排序
// 规则:按照身高降序排列
sort(index.begin(), index.end(), [&](int i, int j)
{
return heights[i] > heights[j];
});
// 3. 根据排序后的下标,提取对应的姓名,生成结果数组
vector<string> ret;
for (int i : index)
{
ret.push_back(names[i]);
}
return ret;
}
};
void printStringVector(const vector<string>& arr)
{
cout << "[";
for (size_t i = 0; i < arr.size(); i++)
{
cout << "\"" << arr[i] << "\"";
if (i != arr.size() - 1)
cout << ", ";
}
cout << "]";
}
void printIntVector(const vector<int>& arr)
{
cout << "[";
for (size_t i = 0; i < arr.size(); i++)
{
cout << arr[i];
if (i != arr.size() - 1)
cout << ", ";
}
cout << "]";
}
int main()
{
Solution sol;
vector<pair<vector<string>, vector<int>>> testCases = {
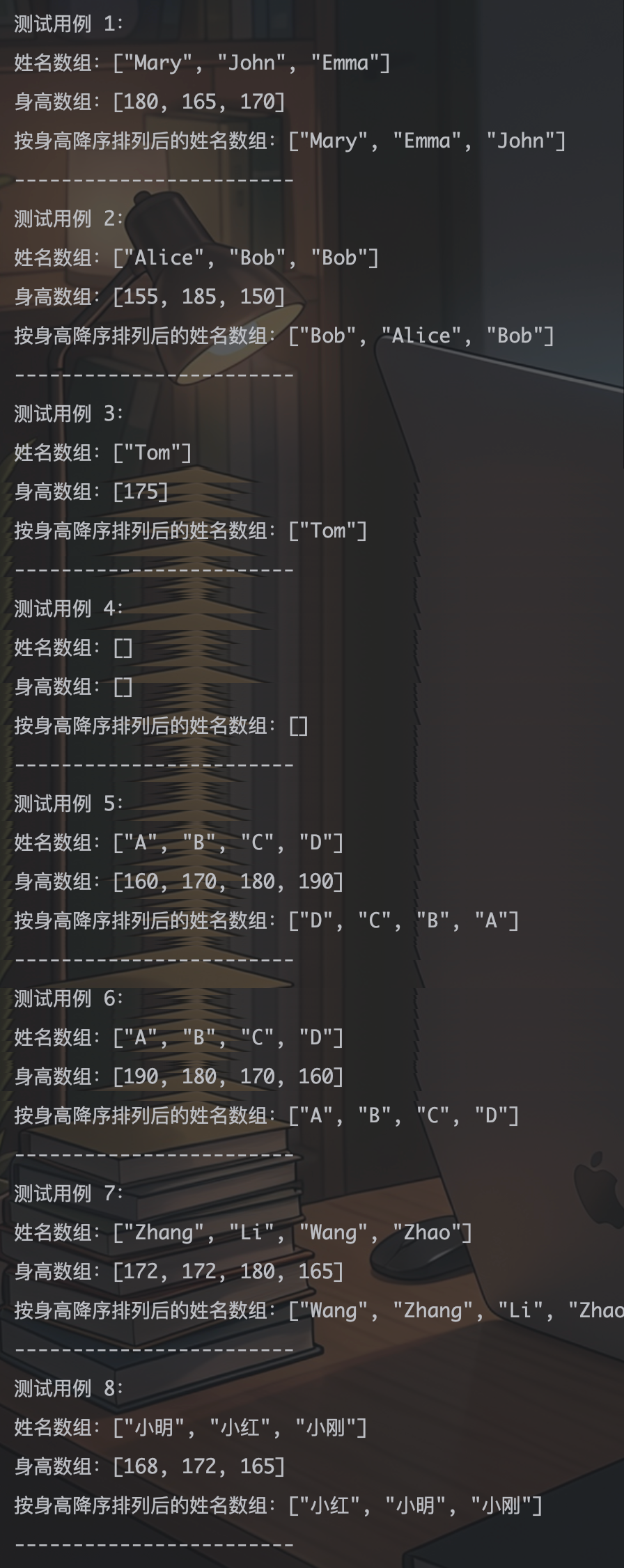
{{"Mary", "John", "Emma"}, {180, 165, 170}},
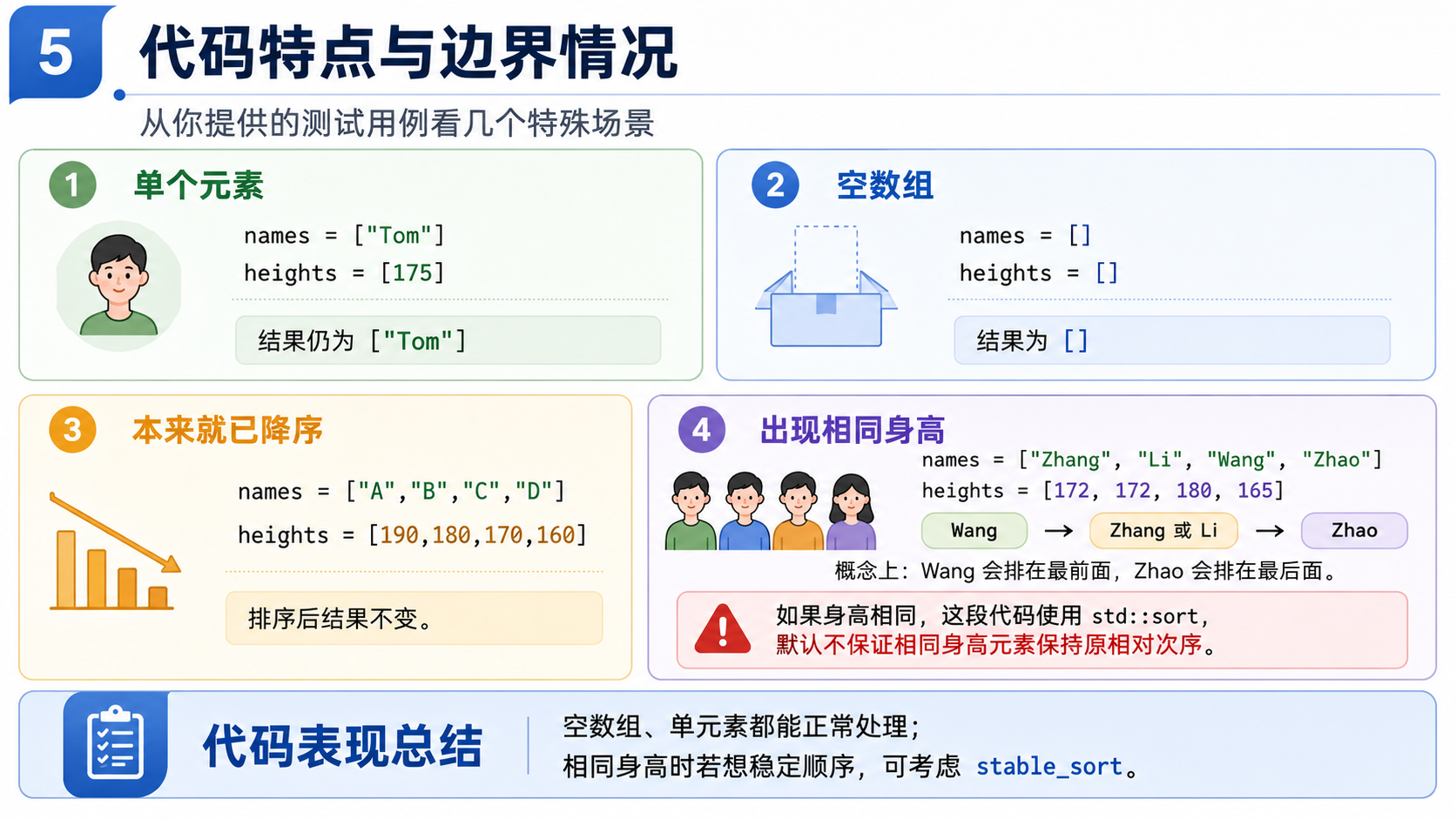
{{"Alice", "Bob", "Bob"}, {155, 185, 150}},
{{"Tom"}, {175}},
{{}, {}},
{{"A", "B", "C", "D"}, {160, 170, 180, 190}},
{{"A", "B", "C", "D"}, {190, 180, 170, 160}},
{{"Zhang", "Li", "Wang", "Zhao"}, {172, 172, 180, 165}},
{{"小明", "小红", "小刚"}, {168, 172, 165}}
};
for (int i = 0; i < testCases.size(); i++)
{
vector<string> names = testCases[i].first;
vector<int> heights = testCases[i].second;
cout << "测试用例 " << i + 1 << ":" << endl;
cout << "姓名数组:";
printStringVector(names);
cout << endl;
cout << "身高数组:";
printIntVector(heights);
cout << endl;
vector<string> result = sol.sortPeople(names, heights);
cout << "按身高降序排列后的姓名数组:";
printStringVector(result);
cout << endl;
cout << "------------------------" << endl;
}
return 0;
}
3.优势洗牌(田忌赛马)(OJ题)

解法(贪心):
讲一下田忌赛马背后包含的博弈论和贪心策略:
田忌赛马没听过的自行百度,这里讲一下田忌赛马背后的博弈决策,从三匹马拓展到 n 匹马之间博弈的最优策略.
田忌:下等马 中等马 上等马
齐王:下等马 中等马 上等马
a. 田忌的下等马 pk 不过齐王的下等马,因此把这匹马丢去消耗一个齐王的最强战马!
b. 接下来选择中等马 pk 齐王的下等马,勉强获胜;
c. 最后用上等马 pk 齐王的中等马,勉强获胜.
由此,我们可以得出一个最优的决策方式:
a. 当己方此时最差的比不过对面最差的时候,让我方最差的去处理掉对面最好的(反正要输,不如去拖掉对面一个最强的);
b. 当己方此时
c. 最差的能比得上对面最差的时候,就让两者比对下去(最差的都能获胜,为什么要输呢).
每次决策,都会使我方处于优势.





核心代码
cpp
class Solution
{
public:
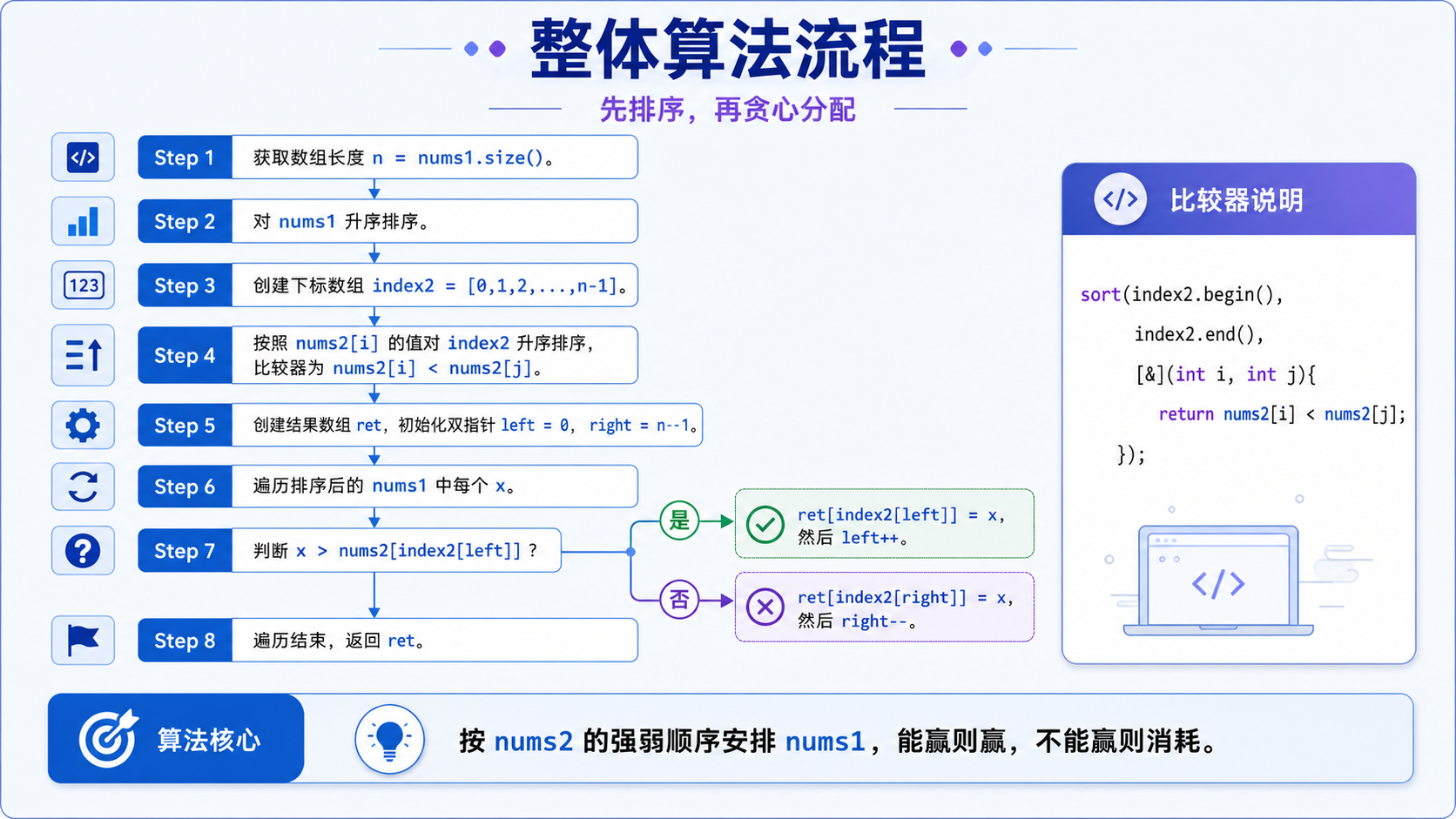
vector<int> advantageCount(vector<int>& nums1, vector<int>& nums2)
{
//获取数组长度(两个数组长度相同)
int n = nums1.size();
//第一步:预处理排序
//对 nums1 进行升序排序(从小到大,方便田忌赛马策略匹配)
sort(nums1.begin(), nums1.end());
//创建 nums2 的下标数组 index2:存储 0,1,2...n-1 原始下标
vector<int> index2(n);
for(int i = 0; i < n; i++)
index2[i] = i;
//对下标数组 index2 排序:按照 nums2 对应的值**升序**排列
//作用:记录 nums2 从小到大的原始位置,保证排序后不丢失原位置信息
sort(index2.begin(), index2.end(), [&](int i, int j)
{
return nums2[i] < nums2[j];
});
//第二步:田忌赛马贪心策略
//结果数组 ret:存储最终的优势排列
vector<int> ret(n);
//双指针:
//left 指向 nums2 中**最小元素**的原始下标
//right 指向 nums2 中**最大元素**的原始下标
int left = 0, right = n - 1;
//遍历**升序排序后的 nums1**(从小到大拿元素)
for(auto x : nums1)
{
//核心策略:
//如果当前 nums1 的最小元素 > nums2 的最小元素 → 用它赢下 nums2 的最小元素(对位)
if(x > nums2[index2[left]])
{
ret[index2[left++]] = x;
}
//否则 → 用它去对抗 nums2 的最大元素(送人头,牺牲最小元素保大的)
else
{
ret[index2[right--]] = x;
}
}
//返回最终的优势最大化排列
return ret;
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
class Solution
{
public:
vector<int> advantageCount(vector<int>& nums1, vector<int>& nums2)
{
// 获取数组长度(两个数组长度相同)
int n = nums1.size();
// 第一步:预处理排序
// 对 nums1 进行升序排序
sort(nums1.begin(), nums1.end());
// 创建 nums2 的下标数组 index2
vector<int> index2(n);
for (int i = 0; i < n; i++)
index2[i] = i;
// 对 index2 排序:按照 nums2 对应的值升序排列
sort(index2.begin(), index2.end(), [&](int i, int j)
{
return nums2[i] < nums2[j];
});
// 第二步:田忌赛马贪心策略
vector<int> ret(n);
int left = 0, right = n - 1;
// 遍历升序排序后的 nums1
for (auto x : nums1)
{
// 如果当前 x 能赢 nums2 中最小的元素,就用它去赢
if (x > nums2[index2[left]])
{
ret[index2[left++]] = x;
}
// 否则用它去对抗 nums2 中最大的元素
else
{
ret[index2[right--]] = x;
}
}
return ret;
}
};
void printVector(const vector<int>& nums)
{
cout << "[";
for (size_t i = 0; i < nums.size(); i++)
{
cout << nums[i];
if (i != nums.size() - 1)
cout << ", ";
}
cout << "]";
}
// 计算优势数量:result[i] > nums2[i] 的个数
int countAdvantage(const vector<int>& result, const vector<int>& nums2)
{
int count = 0;
for (size_t i = 0; i < result.size(); i++)
{
if (result[i] > nums2[i])
count++;
}
return count;
}
int main()
{
Solution sol;
vector<pair<vector<int>, vector<int>>> testCases = {
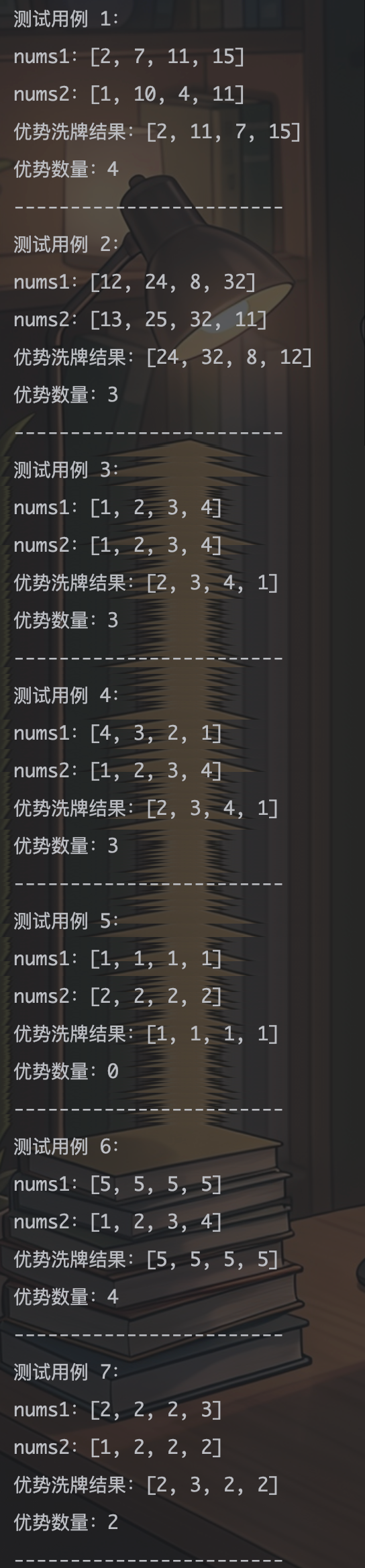
{{2, 7, 11, 15}, {1, 10, 4, 11}}, // 示例:可获得 4 个优势
{{12, 24, 8, 32}, {13, 25, 32, 11}}, // 示例:可获得 3 个优势
{{1, 2, 3, 4}, {1, 2, 3, 4}}, // 相同数组,可获得 3 个优势
{{4, 3, 2, 1}, {1, 2, 3, 4}}, // nums1 逆序输入
{{1, 1, 1, 1}, {2, 2, 2, 2}}, // 全部无法取胜
{{5, 5, 5, 5}, {1, 2, 3, 4}}, // 全部可以取胜
{{2, 2, 2, 3}, {1, 2, 2, 2}}, // 包含重复元素
{{8, 12, 24, 32}, {13, 25, 32, 11}}, // 接近示例,但 nums1 已升序
{{10}, {5}}, // 单个元素,能取胜
{{3}, {5}}, // 单个元素,不能取胜
{{}, {}} // 空数组
};
for (int i = 0; i < testCases.size(); i++)
{
vector<int> nums1 = testCases[i].first;
vector<int> nums2 = testCases[i].second;
cout << "测试用例 " << i + 1 << ":" << endl;
cout << "nums1:";
printVector(nums1);
cout << endl;
cout << "nums2:";
printVector(nums2);
cout << endl;
vector<int> result = sol.advantageCount(nums1, nums2);
cout << "优势洗牌结果:";
printVector(result);
cout << endl;
cout << "优势数量:";
cout << countAdvantage(result, nums2) << endl;
cout << "------------------------" << endl;
}
return 0;
}
4.最长回文串(OJ题)

解法(贪心):
贪心策略 :用尽可能多的字符去构造回文串:
a. 如果字符出现偶数个,那么全部都可以用来构造回文串;
b. 如果字符出现奇数个,减去一个之后,剩下的字符能够全部用来构造回文串;
c. 最后再判断一下,如果有字符出现奇数个,就把它单独拿出来放在中间.





核心代码
cpp
class Solution
{
public:
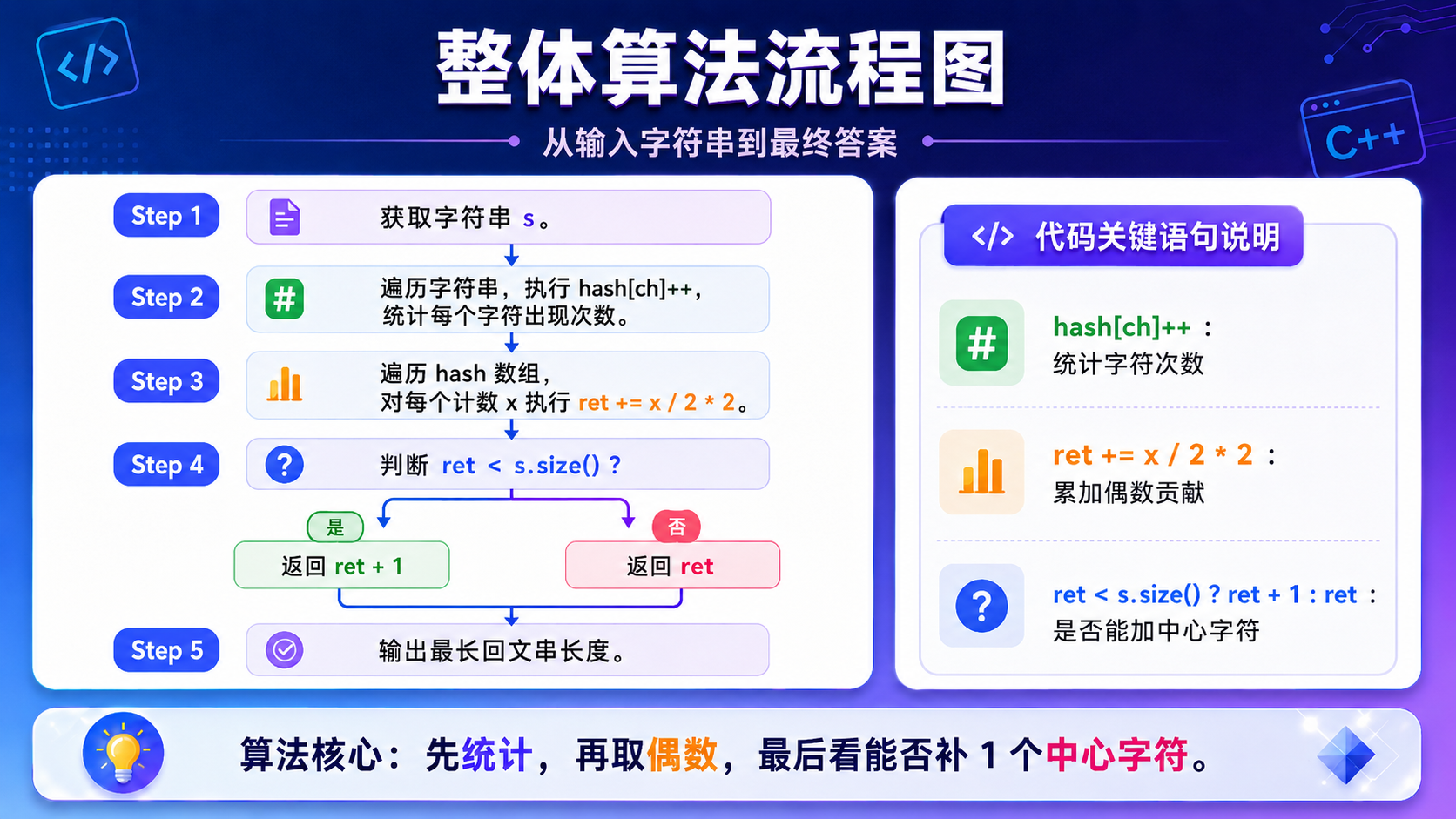
int longestPalindrome(string s)
{
//1.字符计数:用数组模拟哈希表
//ASCII码共127个字符,创建数组hash统计每个字符出现的次数,初始化为0
int hash[127] = { 0 };
//遍历字符串,统计每个字符的出现次数
for(char ch : s)
hash[ch]++;
//2.计算最长回文串的基础长度(仅统计偶数次字符)
int ret = 0;
//遍历所有字符的计数
for(int x : hash)
{
//回文串中,每个字符最多使用【偶数个】
//x/2*2:向下取偶,比如3→2,5→4,2→2
ret += x / 2 * 2;
}
//3.最终判断:
//如果基础长度 < 原字符串长度 → 说明存在出现奇数次的字符
//可以选1个奇数字符作为回文中心,总长度+1
//如果相等 → 所有字符都是偶数次,直接返回
return ret < s.size() ? ret + 1 : ret;
}
};完整测试代码
cpp
#include <iostream>
#include <string>
using namespace std;
class Solution
{
public:
int longestPalindrome(string s)
{
// 1.字符计数:用数组模拟哈希表
// ASCII 码共 127 个字符,创建数组 hash 统计每个字符出现的次数
int hash[127] = { 0 };
// 遍历字符串,统计每个字符的出现次数
for (char ch : s)
hash[ch]++;
// 2.计算最长回文串的基础长度(仅统计偶数次字符)
int ret = 0;
// 遍历所有字符的计数
for (int x : hash)
{
// 回文串中,每个字符最多使用偶数个
ret += x / 2 * 2;
}
// 3.如果存在奇数次字符,可以选 1 个作为回文中心
return ret < s.size() ? ret + 1 : ret;
}
};
int main()
{
Solution sol;
string testCases[] = {
"abccccdd", // dccaccd,长度 7
"a", // 单个字符,长度 1
"bb", // 两个相同字符,长度 2
"abc", // 只能选一个字符作为中心,长度 1
"Aa", // 区分大小写,长度 1
"ccc", // 可以使用 3 个 c,长度 3
"bananas", // a:3, n:2,最长长度 5
"", // 空字符串,长度 0
"aabbcc", // 全是偶数次,长度 6
"aabbccd", // 偶数字符 + 一个中心字符,长度 7
"aabbccdde", // 偶数字符 + 一个中心字符,长度 9
"aaaabbbbcccd" // a:4,b:4,c:3,d:1,最长长度 11
};
int n = sizeof(testCases) / sizeof(testCases[0]);
for (int i = 0; i < n; i++)
{
cout << "测试用例 " << i + 1 << ":" << endl;
cout << "字符串:\"" << testCases[i] << "\"" << endl;
cout << "最长回文串长度:";
cout << sol.longestPalindrome(testCases[i]) << endl;
cout << "------------------------" << endl;
}
return 0;
}
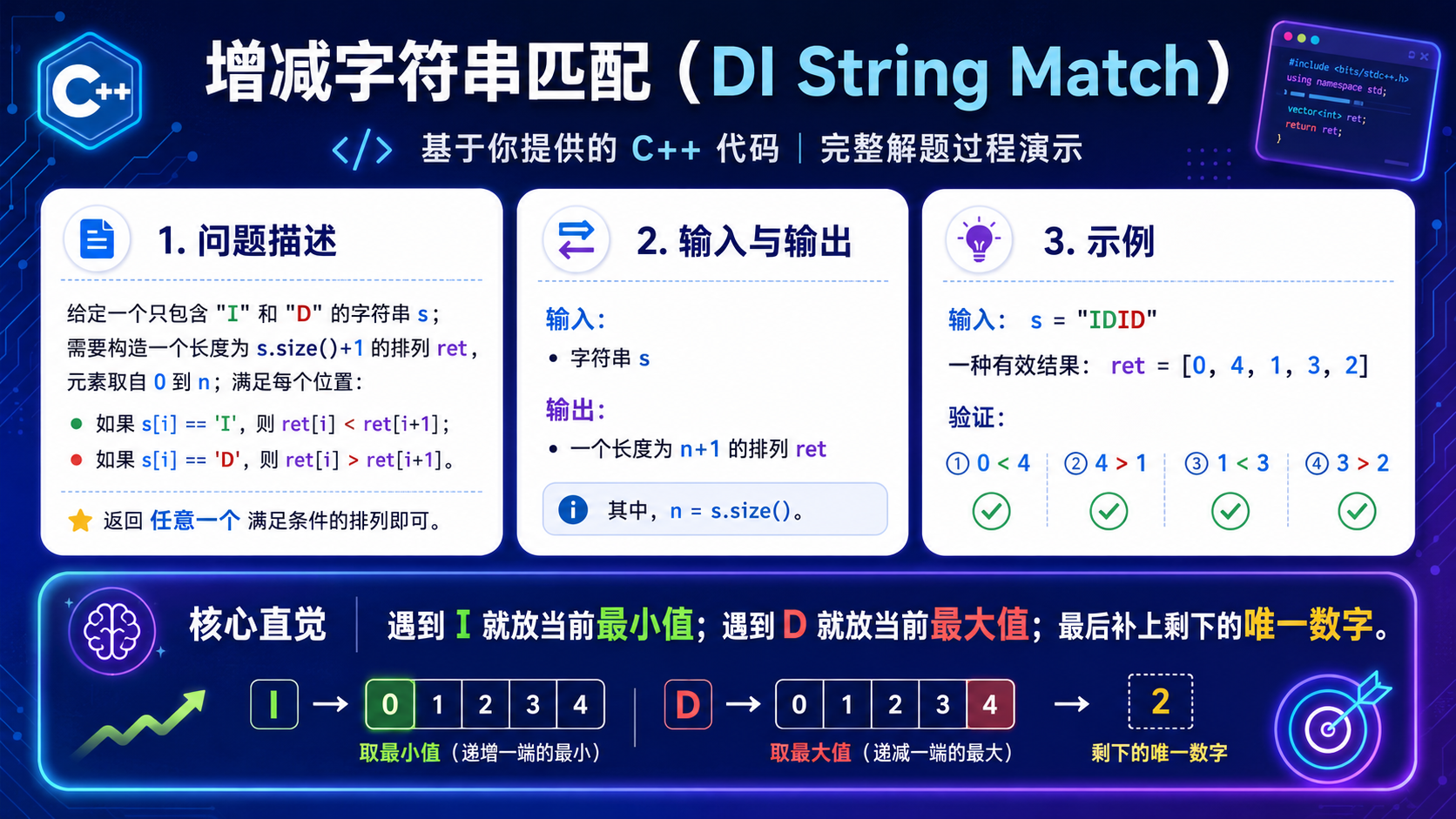
5.增减字符串匹配(OJ题)

解法(贪心):
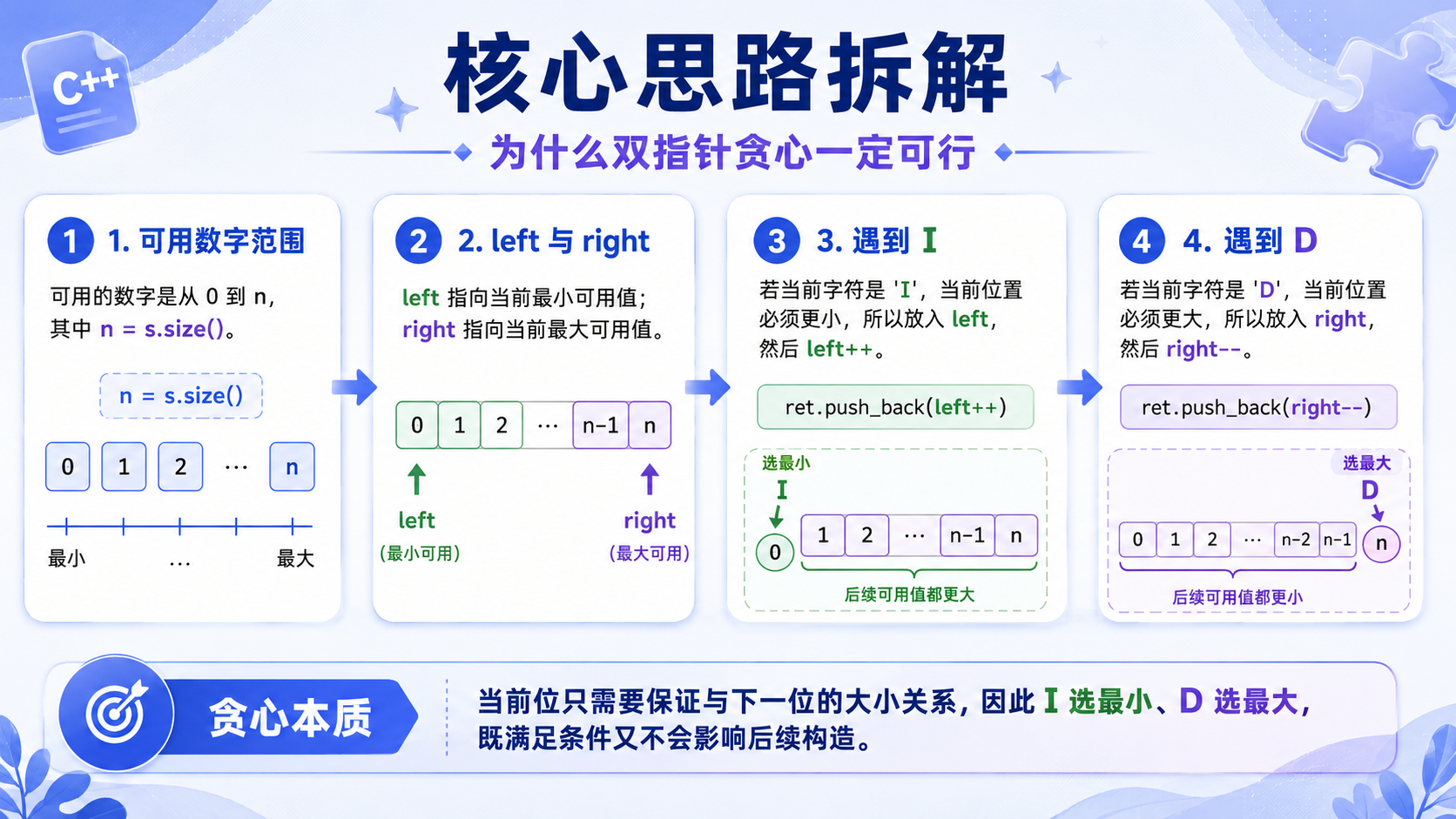
贪心策略 :
a. 当遇到 'I' 的时候,为了让下一个上升的数可选择的范围更多,当前选择最小的那个数;
b. 当遇到 'D' 的时候,为了让下一个下降的数可选择的范围更多,选择当前最大的那个数.


核心代码
cpp
class Solution
{
public:
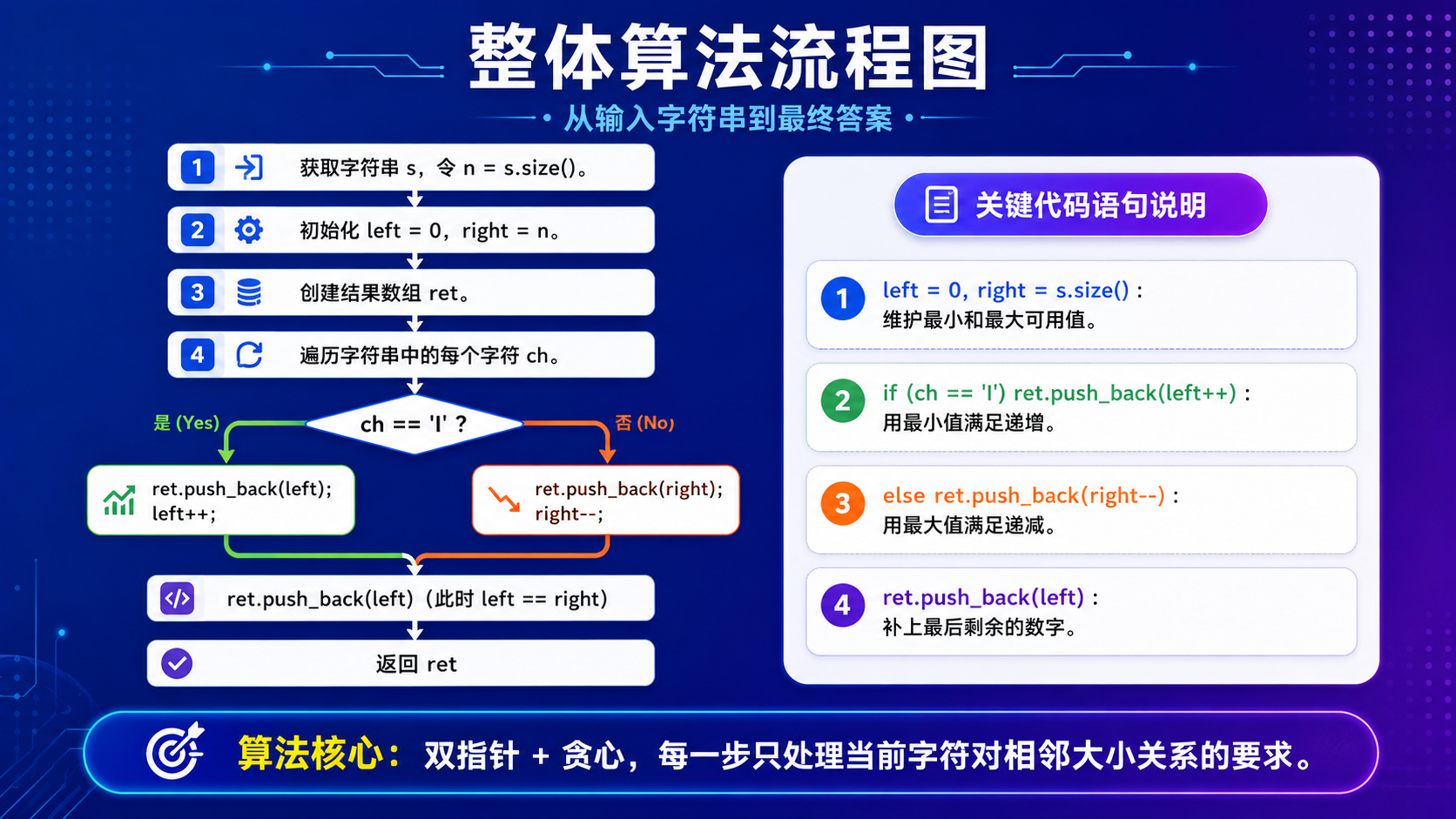
vector<int> diStringMatch(string s)
{
//双指针贪心策略:
//left 初始为 0(当前可用的最小值)
//right 初始为 s.size()(当前可用的最大值,因为结果数组长度是 n+1,数值范围 0~n)
int left = 0, right = s.size();
//存储最终结果的数组
vector<int> ret;
//遍历字符串中的每一个字符(I/D)
for(auto ch : s)
{
//遇到 'I' (Increase 递增):放入当前最小值,然后最小值+1
if(ch == 'I')
ret.push_back(left++);
//遇到 'D' (Decrease 递减):放入当前最大值,然后最大值-1
else
ret.push_back(right--);
}
//遍历结束后,left 和 right 指向同一个数字,将最后这个剩余数字加入结果
ret.push_back(left);
//返回满足条件的数组
return ret;
}
};完整测试代码
cpp
#include <iostream>
#include <vector>
#include <string>
using namespace std;
class Solution
{
public:
vector<int> diStringMatch(string s)
{
// 双指针贪心策略:
// left 初始为 0,表示当前可用的最小值
// right 初始为 s.size(),表示当前可用的最大值
int left = 0, right = s.size();
// 存储最终结果的数组
vector<int> ret;
// 遍历字符串中的每一个字符
for (auto ch : s)
{
// 遇到 'I':放入当前最小值,然后最小值 +1
if (ch == 'I')
ret.push_back(left++);
// 遇到 'D':放入当前最大值,然后最大值 -1
else
ret.push_back(right--);
}
// 最后 left 和 right 指向同一个剩余数字
ret.push_back(left);
return ret;
}
};
void printVector(const vector<int>& nums)
{
cout << "[";
for (size_t i = 0; i < nums.size(); i++)
{
cout << nums[i];
if (i != nums.size() - 1)
cout << ", ";
}
cout << "]";
}
// 验证结果是否满足 I / D 条件
bool checkResult(const string& s, const vector<int>& result)
{
if (result.size() != s.size() + 1)
return false;
for (int i = 0; i < s.size(); i++)
{
if (s[i] == 'I' && result[i] >= result[i + 1])
return false;
if (s[i] == 'D' && result[i] <= result[i + 1])
return false;
}
return true;
}
int main()
{
Solution sol;
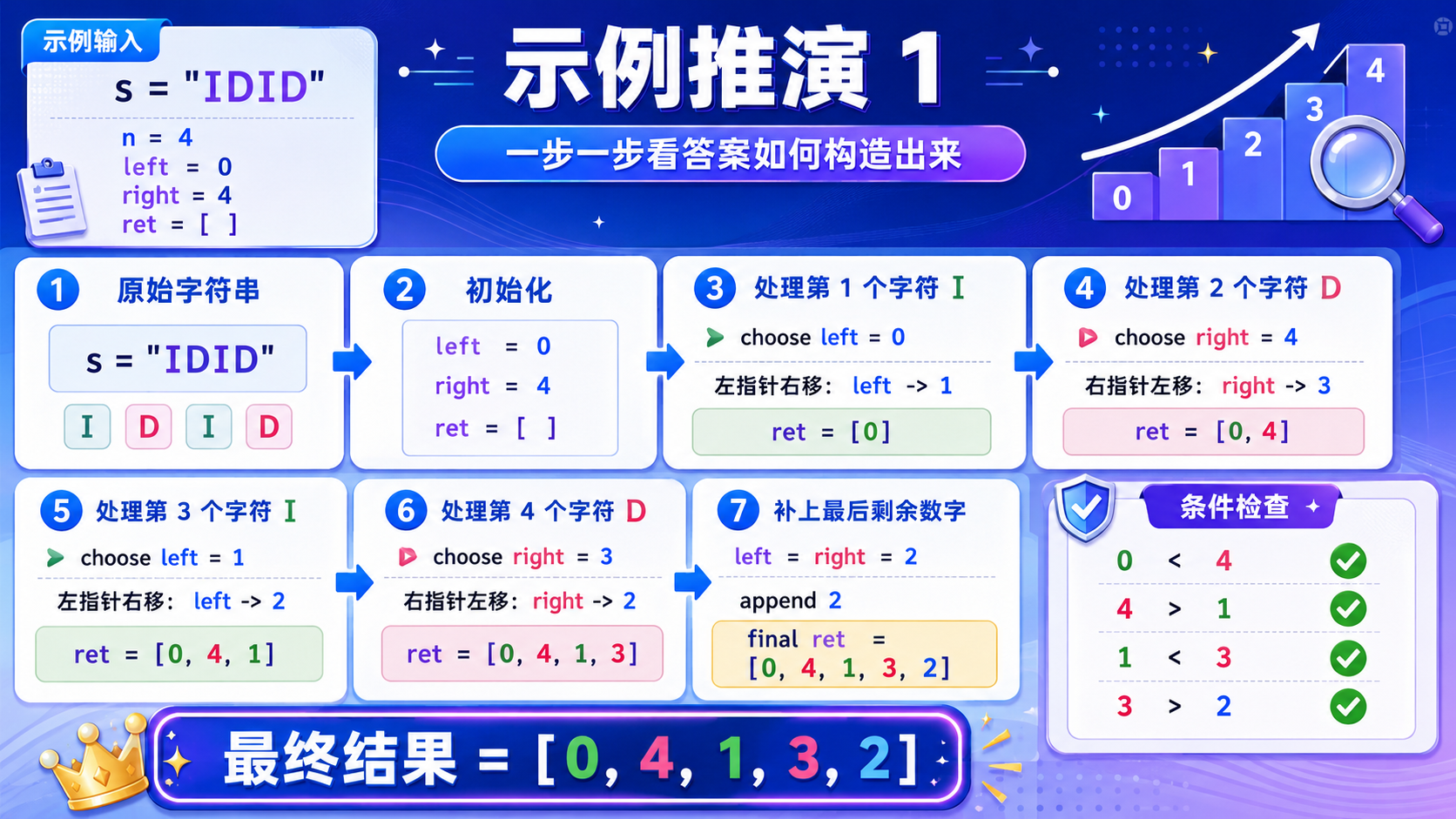
vector<string> testCases = {
"IDID", // 交替出现
"III", // 全部递增
"DDI", // 先降后升
"DDD", // 全部递减
"I", // 单个 I
"D", // 单个 D
"", // 空字符串
"IIDDD", // 前升后降
"DDIII", // 前降后升
"IDDDI" // 混合情况
};
for (int i = 0; i < testCases.size(); i++)
{
string s = testCases[i];
cout << "测试用例 " << i + 1 << ":" << endl;
cout << "字符串:\"" << s << "\"" << endl;
vector<int> result = sol.diStringMatch(s);
cout << "匹配结果:";
printVector(result);
cout << endl;
cout << "是否满足条件:";
cout << (checkResult(s, result) ? "true" : "false") << endl;
cout << "------------------------" << endl;
}
return 0;
}

🚀真正的勇者不是流泪的人,而是含泪奔跑的人!
敬请期待下一篇文章内容的更新【贪心算法】(经典实战应用解析(四):分发饼干、最优除法、跳跃游戏、跳跃游戏Ⅱ、加油站)
每日心灵鸡汤: 人生就是这样,做着做着就有出路了!
余华老师说:抛弃旧的东西是很难的,但是往往旧的东西都会阻碍你们往前走.人生也是一样,如何让自己往前走,有时候你真的不得不,把自己最喜爱,最熟练的东西放下来.我所说的放弃不是完全得抛弃,因为很可能过几年之后你又把它找回来了.只要是属于你的东西,它会永远跟随你,它不会离开你,只是你要知道,你在不同的时间点,需要的是不同的东西.当你不得不去完成某个让你倍感压力的任务时,最好的对策就是马上去做,勇敢地去尝试.在看似余额充足的青春里,我们应该踏实地耐心地去做点什么,以后的日子多长本事,多看世界,多读书,把英语学好,保证自己随时都有走出去的能力.
