一、引言
在我们生产环境下Application提交运行模式下,Flink作业会启动至少1个JobManager(根据HA配置)与1个TaskManager(根据并行度与slot数计算)。在 Flink 架构中,TaskManager 宕机并不可怕,JobManager 会自动向资源管理器(如 YARN/K8s)申请新的容器来重启 Task。真正的痛点是 JobManager 宕机,默认情况下,Flink 的 JobManager 是一个单点故障(SPOF);如果 JobManager 宕机,整个作业就会失败且无法自动恢复。
为了解决这个问题,Flink 提供了强大的高可用(High Availability, HA)机制。本文将深入浅出地剖析 Flink HA 的核心机制、配置方法以及生产环境下的最佳实践。
二、Flink HA原理剖析
在深入 HA 之前,我们需要理解 Flink 容错的全貌:
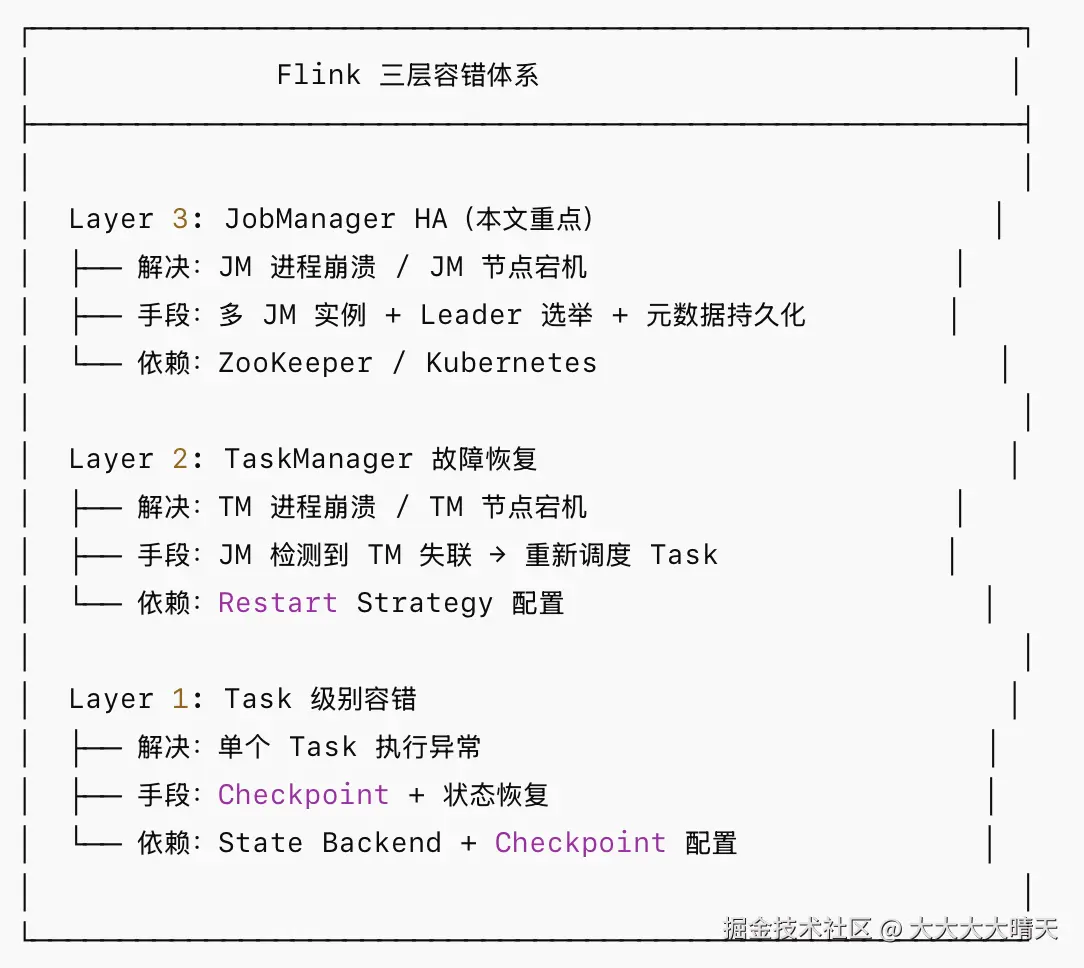
Flink HA 专门解决 Layer 3 问题------即 JobManager 单点故障。即使不配置 HA,Layer 1 和 Layer 2 仍然可以工作;但如果 JM 崩溃且无 HA,整个集群将不可用。
Flink HA 采用的是经典的"主备(Active/Standby)"架构。在 HA 模式下,集群会启动多个 JobManager 实例,但只有一个是 Leader(负责作业调度和状态管理),其余都是 Standby。当 Leader 宕机时,Standby 实例会通过分布式协调组件(ZooKeeper 或 Kubernetes)竞选成为新的 Leader,并从高可用存储(如 HDFS/S3)中恢复作业状态,从而接管集群。因此,Flink 的 HA 机制主要是围绕 JobManager 的多实例选主(Leader Election) 和 元数据持久化 展开的。
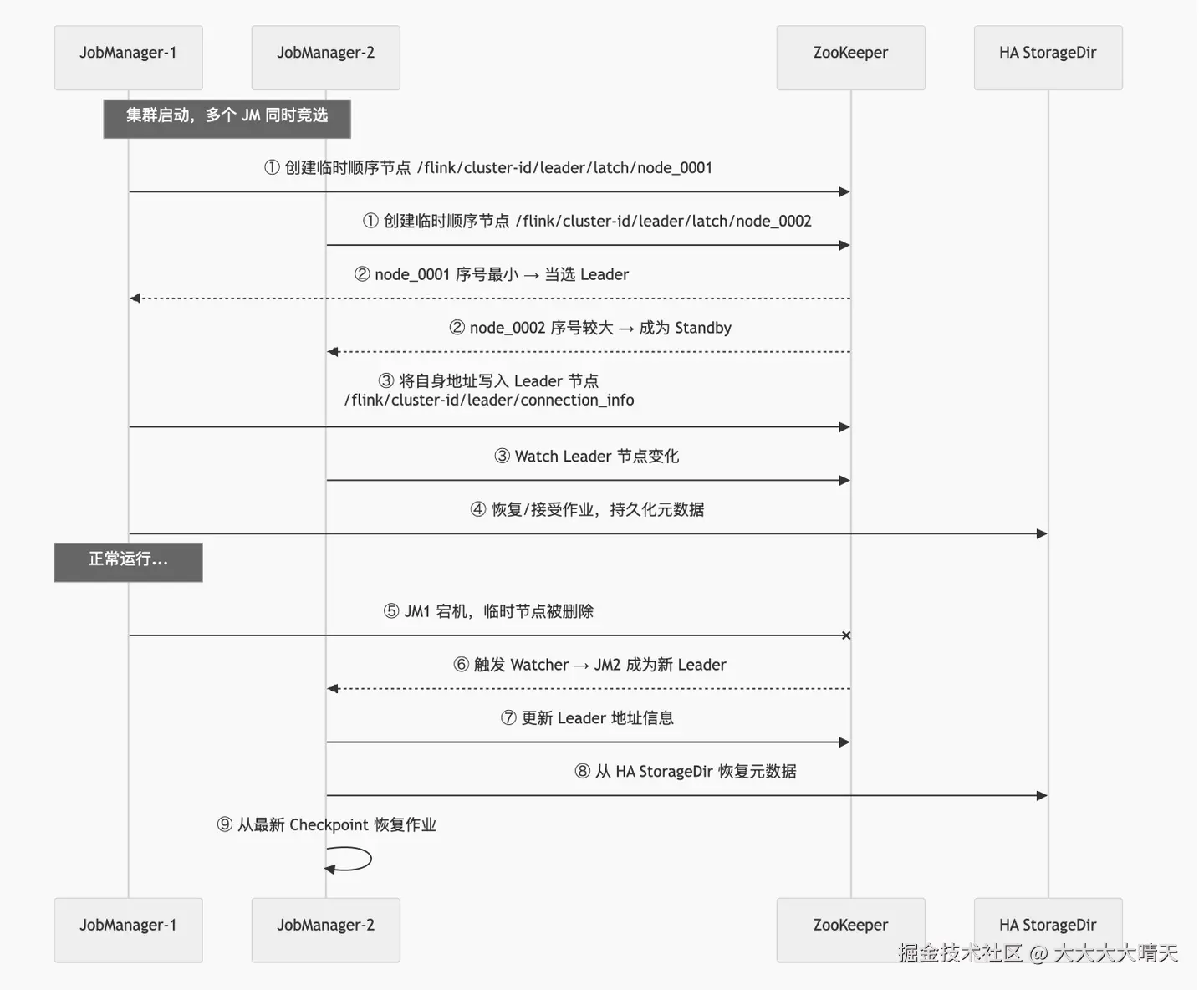
1.Leader 选举机制-ZooKeeper
Flink 使用 Apache Curator 框架进行 Leader 选举(基于 ZooKeeper 的临时顺序节点实现):
2.Leader 选举机制-Kubernetes
Kubernetes HA 使用ConfigMap作为分布式锁实现选举:

3.元数据持久化机制
HA 模式下,以下关键数据会被持久化到high-availability.storageDir:

为什么需要两级存储呢?
| 存储层 | 内容 | 特点 |
|---|---|---|
| ZooKeeper / K8s ConfigMap | Leader 地址、Checkpoint 计数器、少量指针信息 | 数据量小(KB级),读写快,ZK 有 znode 大小限制(默认 1MB) |
| HDFS / S3 | JobGraph、Checkpoint 元数据、Blob 文件 | 数据量可达 MB~GB 级,无大小限制 |
4.故障检测与恢复流程
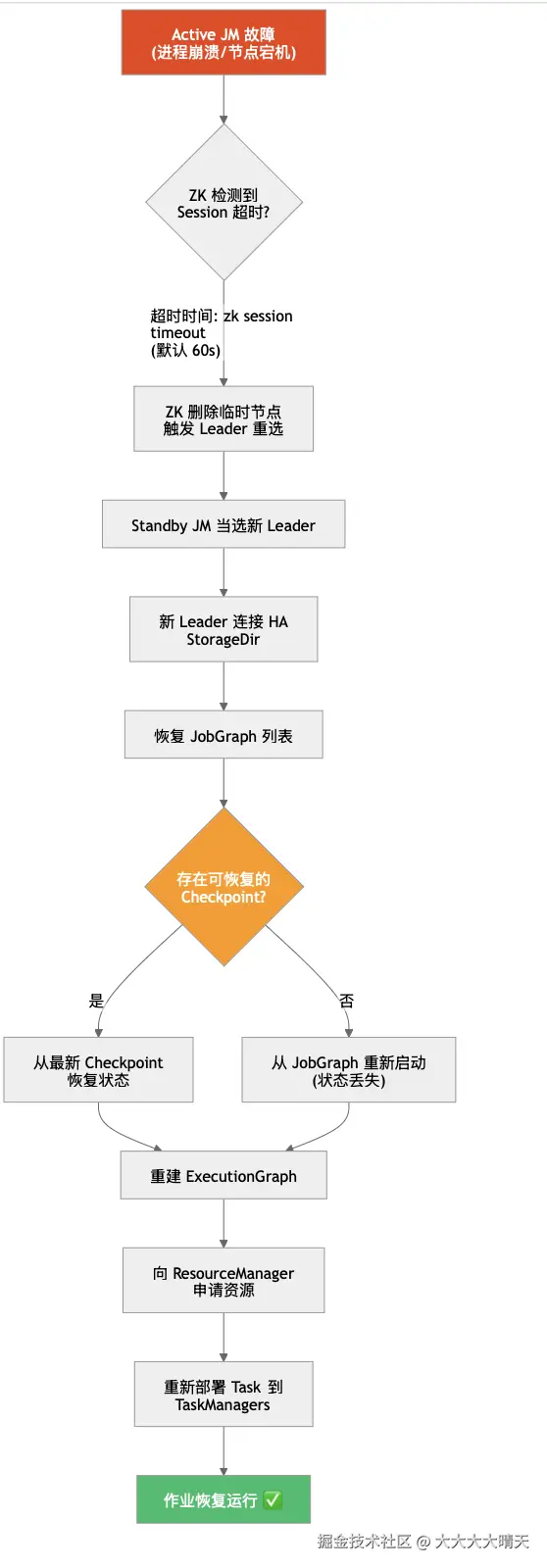
新 JM 会尽可能重用现有的 TM,不会无条件地全部重新申请资源。它会等待运行中的 TM 重新注册,并优先在这些 TM 已有的 Slot 上重新调度任务;只有在 Slot 不够或原有 TM 不可用时,才会向底层资源管理器申请新的 TM。
三、Flink HA配置方案
1.ZooKeeper HA 核心配置
yaml
# flink-conf.yaml
# 启用 ZooKeeper HA
high-availability.type: zookeeper
# ZooKeeper 集群地址
high-availability.zookeeper.quorum: zk1:2181,zk2:2181,zk3:2181
# ZK 根路径 (用于隔离不同 Flink 服务)
high-availability.zookeeper.path.root: /flink
# 集群 ID (同一 ZK 下区分不同 Flink 集群)
high-availability.cluster-id: /my-production-cluster
# HA 元数据存储目录 (必须是分布式文件系统)
high-availability.storageDir: hdfs:///flink/ha/
# ZK 客户端参数 (可选调优)
high-availability.zookeeper.client.session-timeout: 60000
high-availability.zookeeper.client.connection-timeout: 15000
high-availability.zookeeper.client.retry-wait: 5000
high-availability.zookeeper.client.max-retry-attempts: 3
high-availability.zookeeper.client.acl: open2.Kubernetes HA 核心配置
makefile
# flink-conf.yaml
# 启用 Kubernetes HA
high-availability.type: kubernetes
# 集群 ID(将用于 ConfigMap 命名前缀)
high-availability.cluster-id: my-flink-cluster
# HA 元数据存储目录 (仍需分布式文件系统)
high-availability.storageDir: s3://my-bucket/flink/ha/
# Kubernetes 命名空间 (可选,默认使用当前上下文)
kubernetes.namespace: flink-production3.方案对比
| 对比维度 | ZooKeeper HA | Kubernetes HA |
|---|---|---|
| 引入版本 | Flink 1.0+ | Flink 1.12+ |
| 外部依赖 | ZooKeeper 集群(≥3 节点) | Kubernetes API Server(已有) |
| 选举机制 | 临时顺序节点 + Watcher | ConfigMap + 租约 |
| 元数据存储 | ZK(指针) + HDFS/S3(数据) | ConfigMap(指针) + HDFS/S3(数据) |
| 运维复杂度 | 高(需维护 ZK 集群) | 低(复用 K8s 基础设施) |
| 适用部署模式 | Standalone / YARN / K8s | 仅 Kubernetes |
| 故障检测速度 | 取决于 ZK session timeout | 取决于 K8s 租约时间 |
| 社区成熟度 | 非常成熟,生产验证充分 | 较成熟,生产使用逐渐增多 |
| 扩展性 | ZK 本身有连接数瓶颈 | 受 K8s API Server 性能影响 |
| 网络分区处理 | ZK 的 Quorum 机制较成熟 | 依赖 K8s 的容错能力 |
4.Flink HA关联配置
yaml
# ==========================================
# Checkpoint 配置 (HA 的"灵魂搭档")
# ==========================================
execution.checkpointing.interval: 60000 # 60秒
execution.checkpointing.mode: EXACTLY_ONCE
execution.checkpointing.timeout: 600000 # 10分钟
execution.checkpointing.min-pause: 30000 # 两次 Checkpoint 间最小间隔
execution.checkpointing.max-concurrent-checkpoints: 1
state.checkpoints.dir: hdfs:///flink/checkpoints/ # 实际状态数据目录
state.checkpoints.num-retained: 3 # 保留最近3个 Checkpoint
# ==========================================
# State Backend 配置
# ==========================================
state.backend: hashmap # 或 rocksdb (大状态推荐)
state.backend.incremental: true # RocksDB 开启增量 Checkpoint
# ==========================================
# Restart Strategy 配置 (与 HA 配合)
# ==========================================
restart-strategy.type: failure-rate
restart-strategy.failure-rate.max-failures-per-interval: 10
restart-strategy.failure-rate.failure-rate-interval: 300s
restart-strategy.failure-rate.delay: 10s四、Flink HA最佳使用实践
我们在生产环境下使用Flink HA机制的过程中,可参考以下使用实践(避坑指南):
- HA StorageDir 规划:使用独立的分布式存储路径,避免使用本地文件系统;同时不要与 Checkpoint 目录相同
- Cluster ID 管理:每个集群使用唯一标识,禁止多个集群使用相同 cluster-id
- ZK Session Timeout 调优:网络偶尔抖动场景下适当增大,故障检查高要求场景下适当减小
- HA必须搭配Checkpoint使用,大状态场景下使用rocksdb、开启增量Checkpoint
- HA 元数据清理:作业取消/完成后,HA StorageDir 中的元数据不一定被及时清理,应配置定期清理策略
- 定期进行 HA 故障切换演练,确保切换可靠
Flink HA 本质上是解决 JobManager 单点故障问题,ZooKeeper HA通用成熟、支持所有部署模式 ,Kubernetes HA云原生首选、无额外依赖 。高可用只是容灾的底线,优秀的 Flink 架构还需要结合监控报警(Prometheus+Grafana)、合理的 Checkpoint 调优共同发力。