npu硬件实现cnn标准卷积计算细节
input image 细节
-
示例输出
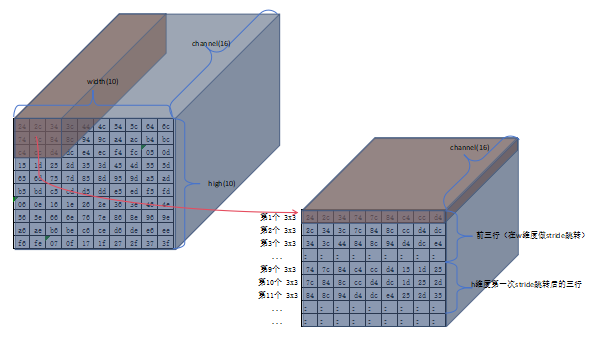
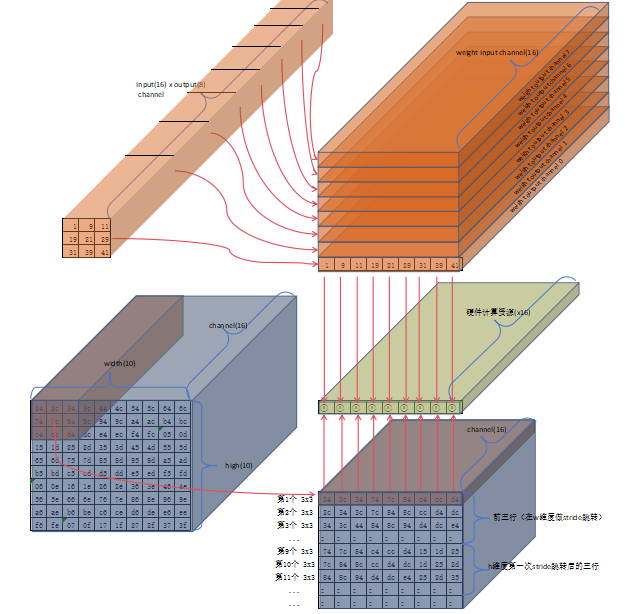
Image为计算中间过程的输入图像,大小为16x10x10(channel\*width\*high) -
示例的卷积核为
3x3
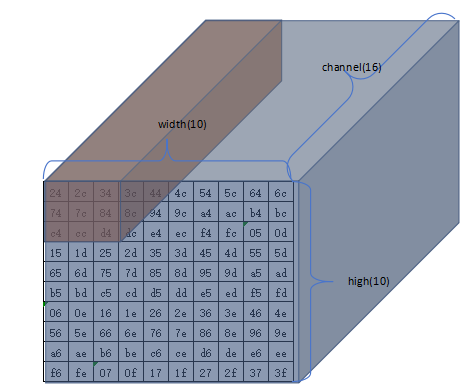
-
将
image从ddr移动的计算单元的可视化过程(stride为1)
-
第一个3x3
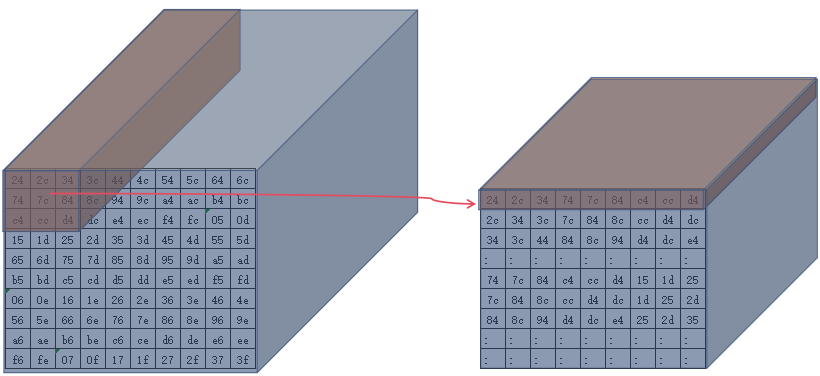
-
第二个3x3
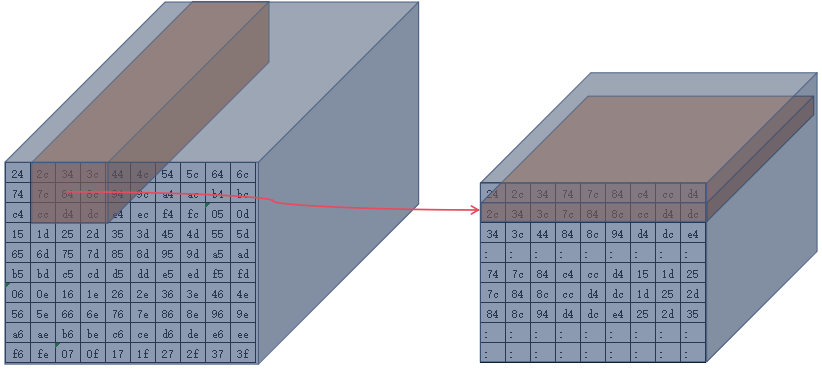
-
第三个3x3
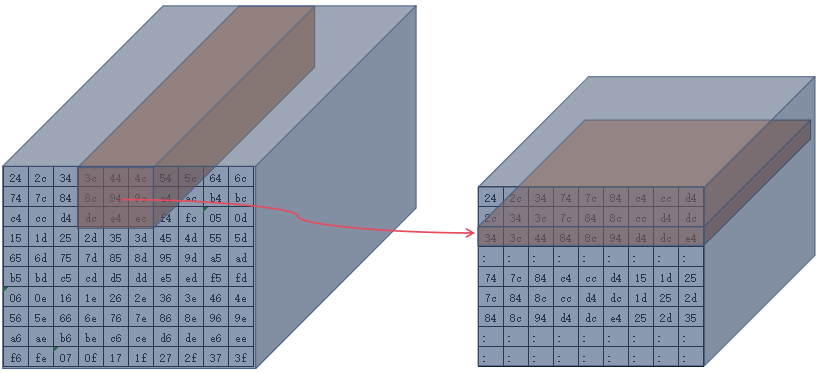
-
(直到移动完整个
width后,开始从high维度做stride)第1次移动high维度的3x3
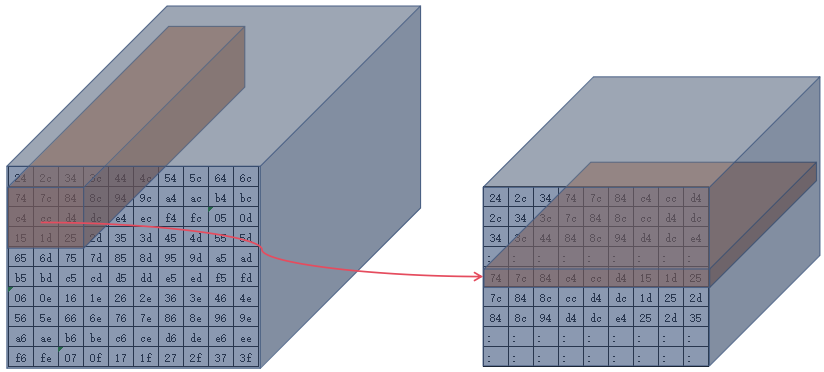
-
第1次移动
high维度的第2个3x3
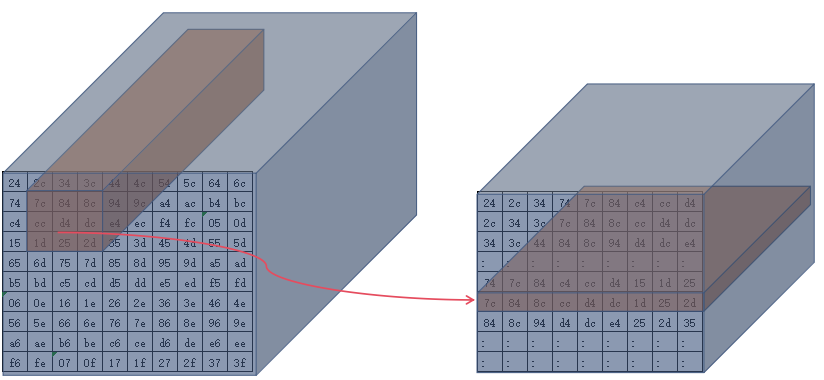
- 按照如上规则将整个
image排列好准备进入计算单元(这是一个动态的过程,究竟一次能排列多少个3x3看硬件的存储资源能力,不一定一次排列好所有数据) - 完整的将
image读入排列好准备计算的示例
input weight 细节
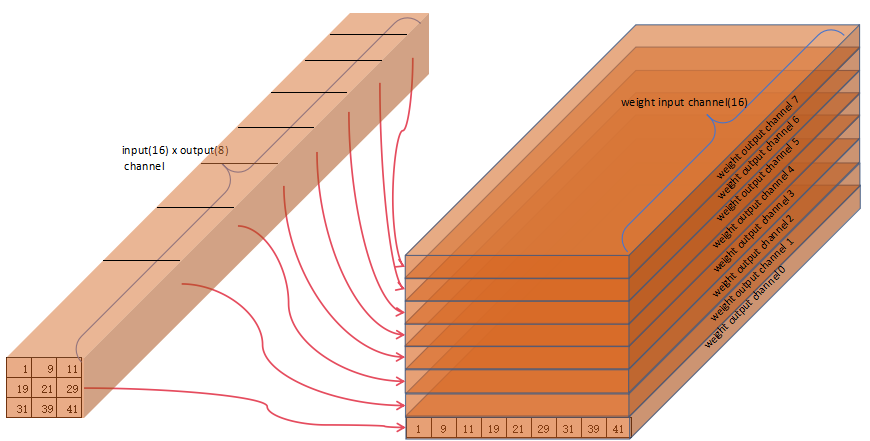
Weight的大小取决于输入输出- 示例
weight为16\*8\*(3x3)(input_channel \* output_channel\*kernel_size) weight从ddr移动到计算单元相对比较简单,依次取出所有的weight进行计算即可(每次取出多少看硬件的计算资源大小,示例硬件计算资源为16\*3x3,一次可以完成1个所有input通道的3x3卷积计算)
硬件资源介绍
- 硬件资源为
(16\*9)个乘法器 和(14\*9 + 8)个加法器, 意味着一次可以对一个3x3的图形的16个通道完成一次乘加 - 由加法的交换律可得在
channel维度和image维度的加法的前后并不影响计算结果,示例的硬件资源先做channel维度的加法,再做kernel的加法 npu的实现根据需求会有各种不同,本文只是做了一个很小的计算描述,真实的npu计算需要适配各种功能,实现会非常复杂
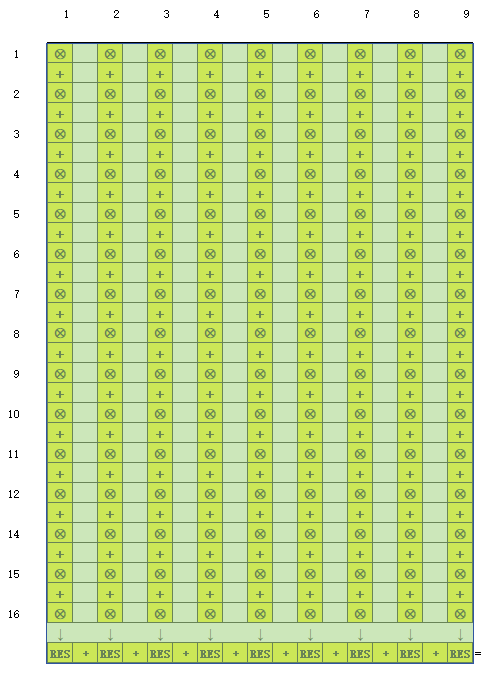
计算步骤描述
-
依照之前的描述我们已经获得一个
input image的队列,一个input weight的队列,只需要"依次 "将image和weight放入计算资源做乘加即可以得到卷积计算结果 -
-
这里需要仔细理解,虽然目前有了
weight和image队列,但是这两个队列对于计算资源并不是一一对应的 ,由于我们有
16\*3\*3的硬件资源,1次计算既可以完成一个kernel_sizeweight的output通道乘加(1个output通道由16个输入通道组成),需要8次计算既可以完成一个kernel_size的所有的输入输出通道的乘加 -
所以第一次计算我们会拿
image的第一个16\*3\*3和weight的第一个输出通道(16\*3\*3)计算,第二次计算 会切换image到第二个16\*3*\3即stride在width维度偏移1次,但是weight是不做切换 的,(因为在一个width\*high维度上weight是固定的),这样在计算完第一行的image后,理论上会换high维度继续做width\*high,但是这样在做完所有的image后需要重新加载weigh和image计算其他输出通道,会有很多的重复加载(缓存资源有限),所以这里的解决方案是在前三行width维度完成计算后,会切回到起始点 然后切换weight做乘加,直到8个输出通道的weight都完成计算,才会切换high维度 -
计算详解
计算步骤 切换维度 image weight 说明 1 width width0_high0 3x3 output channel 1 第一个3x3 2 width width1_high0 3x3 output channel 1 w维度切换stride 3 width width2_high0 3x3 output channel 1 w维度切换stride 4 width width3_high0 3x3 output channel 1 w维度切换stride 5 width width4_high0 3x3 output channel 1 w维度切换stride 6 width width5_high0 3x3 output channel 1 w维度切换stride 7 width width6_high0 3x3 output channel 1 w维度切换stride 8 width width7_high0 3x3 output channel 1 w维度切换stride 9 width->width width0_high0 3x3 output channel 2 返回第一个3x3,切换weight 10 width width1_high0 3x3 output channel 2 w维度切换stride 11 width width2_high0 3x3 output channel 2 w维度切换stride 12 width width3_high0 3x3 output channel 2 w维度切换stride 13 width width4_high0 3x3 output channel 2 w维度切换stride 14 width width5_high0 3x3 output channel 2 w维度切换stride 15 width width6_high0 3x3 output channel 2 w维度切换stride 16 width width7_high0 3x3 output channel 2 w维度切换stride 17 width->width **width0_high0 3x3 ** output channel 3 返回第一个3x3,切换weight 18 width width01_high0 3x3 output channel 3 w维度切换stride ... ... ... ... ... 64 width width7_high0 3x3 output channel 8 完成所有维度的weight和前三行image的乘加 65 width->high **width0_high1 3x3 ** output channel 1 h维度切换stride,第2,3,4行的第一个3x3 66 width width1_high1 3x3 output channel 1 w维度切换stride 67 width width2_high1 3x3 output channel 1 w维度切换stride 68 width width3_high1 3x3 output channel 1 w维度切换stride ... ... ... ... 重复上述步骤直到完成所有的Image -
通过上述计算既可以完成一个10*10*16通道
input, 输出为10*10*8通道的卷积运算