++最近很多朋友在部署AI++ ++大模型时遇到一个常见问题:明明算力够用,推理却慢得让人崩溃。输入一段话,等半天才能看到回复。问题出在哪?很多人第一反应是"++ ++算力不够"++ ++,但实际上AI++ ++大模型推理的性能瓶颈往往不在算力,而在带宽。++
AI 大模型推理为什么这么吃带宽
要理解带宽的重要性,先得知道AI大模型推理时到底在干什么。
大语言模型本质上是一个巨大的矩阵运算器。当你输入一段文字,模型要做的事情说起来很简单:把输入转成向量,然后在几十层神经网络里反复做矩阵乘法和激活函数运算。
关键问题来了:每次运算都需要从显存里读取模型参数。一个7B参数的模型,光参数本身就要占用14GB显存(FP16精度)。而一次前向传播,模型里的每一个权重都要被访问无数次。
这就像一个厨师做菜,厨房里堆满了食材,但食材分散在仓库各处,他得不停地跑出去拿。你给他再快的刀,如果每次切菜之前要先跑五分钟去仓库取菜,整体效率还是上不去。
**核心结论:**AI大模型推理是"访存密集型"任务。算力再强,如果数据喂不进去,GPU大部分时间都在等待,而不是计算。显存带宽决定了数据能多快地喂进GPU。
主流GPU 显卡带宽参数对比
先来看各款GPU显卡的带宽差距。这里分成了三个阵营:NVIDIA数据中心级、消费级,以及国产加速卡。
NVIDIA 数据中心级GPU 显卡
|----------------|-----------|--------|------------|-----------|
| GPU显卡型号 | 显存带宽 | 显存容量 | FP16算力 | 参考价格 |
| H100 80GB | 3.35 TB/s | 80 GB | 989 TFLOPS | ~35000 |
| **H200 141GB** | 4.8 TB/s | 141 GB | 990 TFLOPS | \~30000+ |
| A100 80GB | 2 TB/s | 80 GB | 312 TFLOPS | ~15000 |
| **L40S** | 864 GB/s | 48 GB | 362 TFLOPS | \~10000 |
NVIDIA 消费级GPU 显卡
|--------------|----------|-------|------------|---------|
| GPU显卡型号 | 显存带宽 | 显存容量 | FP16算力 | 参考价格 |
| RTX 4090 | 1 TB/s | 24 GB | 330 TFLOPS | ~1600 |
| **RTX 3090** | 936 GB/s | 24 GB | 142 TFLOPS | \~1500 |
国产AI 加速卡国产
|----------------|----------|-------|------------|-----------|
| GPU显卡型号 | 显存带宽 | 显存容量 | FP16算力 | 备注 |
| 昇腾910B | 1.2 TB/s | 64 GB | 376 TFLOPS | 华为自研达芬奇架构 |
| 海光DCU K100 | 896 GB/s | 64 GB | 128 TFLOPS | 类CUDA兼容生态 |
| 寒武纪MLU590 | 2 TB/s | 96 GB | 256 TFLOPS | 国内领先水平 |
这张表里有几个值得注意的点:
性价比RTX 4090 的带宽是H100 的三分之一,但价格差了20 **多倍。**这是为什么很多场景下4090反而是更理性的选择。
国产卡这几年进步很明显。华为昇腾910B的1.2TB/s带宽已经接近A100的水平,海光DCU也号称能达到A100 40%以上的性能。不过软件生态还是最大的短板,CUDA生态的护城河不是一朝一夕能填平的。
**选卡提示:**消费级GPU显卡和专业数据中心卡的差异主要体现在显存类型(HBM vs GDDR6X)、NVLink互联、ECC校验三个方面。H100的900GB/s NVLink带宽让多卡协作效率远超消费级GPU显卡,这也是4090不适合AI大模型训练的重要原因。
带宽与推理速度的量化关系
带宽对推理速度的影响,可以用一个简单的公式来理解:
每秒生成Token数 ≈ 显存带宽 / (参数量 × 每个参数的字节数)
以7B模型为例,FP16精度下每个参数占2字节:
- RTX 4090 (1 TB/s): 1000 GB/s ÷ 14 GB ≈ 71 tokens/s
- H100 (3.35 TB/s): 3350 GB/s ÷ 14 GB ≈ 239 tokens/s
- 昇腾910B (1.2 TB/s): 1200 GB/s ÷ 14 GB ≈ 86 tokens/s
这个计算当然是最理想的情况,实际推理还要考虑KV缓存、中间激活值等开销。但它揭示了一个关键规律:带宽基本决定了推理速度的上限。
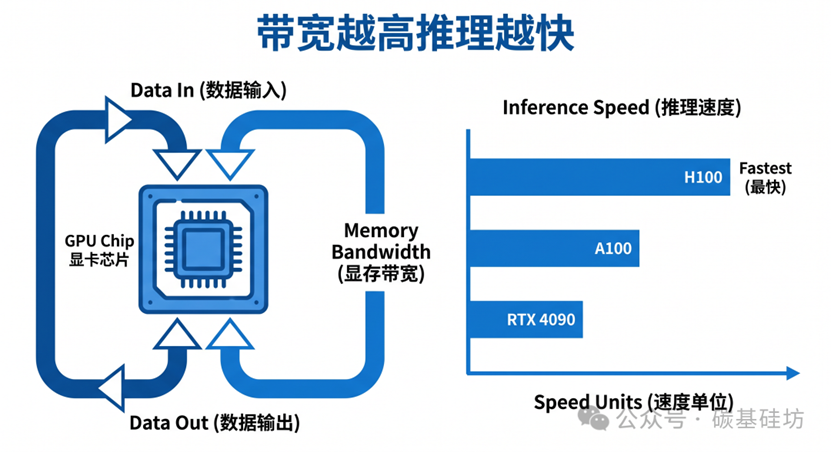
显存带宽直接影响AI 大模型推理的Token 生成速度
**重要例外:**当模型无法完整放进单张GPU显卡时,带宽优势会被多卡通信开销抵消。比如跑70B模型,单张4090放不下,必须多卡并行,此时NVLink的缺失会导致性能大幅下降。
你的模型需要多大显存
选GPU显卡首先要搞清楚的是:你的模型需要多少显存。
显存需求 ≈ 参数量 × 精度字节数
FP32: 4字节 | FP16: 2字节 | INT8: 1字节 | INT4: 0.5字节
|------|----------|---------|----------|-----------------|
| 模型规模 | FP16精度 | INT8量化 | INT4量化 | 推荐GPU显卡 |
| 7B | ~14 GB | ~7 GB | ~3.5 GB | RTX 4090单卡 |
| 13B | ~26 GB | ~13 GB | ~6.5 GB | RTX 4090 / A100 |
| 30B | ~60 GB | ~30 GB | ~15 GB | A100 × 2 |
| 70B | ~140 GB | ~70 GB | ~35 GB | A100/H100 × 2 |
以RTX 4090的24GB显存为例:7B模型(FP16)稳跑,13B模型(FP16)基本能跑但长序列有压力,30B及以上不量化基本跑不了。这也是为什么4090在推理圈里口碑两极分化。
热门开源模型显存需求与选型
通义千问Qwen3 系列
Qwen3是阿里开源的最新一代AI大模型,分Dense和MoE两种架构。MoE架构(混合专家)通过只激活部分参数来降低显存需求,这是一个重要的技术趋势。
Qwen3.5 轻量稠密系列(Q4_K_M 量化)
|--------------|------|-------|-----------------|
| 模型 | 总参数量 | Q4显存 | 推荐GPU显卡 |
| Qwen3.5-0.8B | 0.8B | 1.0GB | RTX 3060 |
| Qwen3.5-2B | 2B | 2.7GB | RTX 3060 |
| Qwen3.5-4B | 4B | 3.4GB | RTX 3060/4060 |
| Qwen3.5-9B | 9B | 6.6GB | RTX 4090 |
| Qwen3.5-27B | 27B | 17GB | RTX 4090双卡/A100 |
Qwen3.5 中型MoE 系列(Q4_K_M 量化)
|-------------------|------|------|------|-------------|
| 模型 | 总参数量 | 激活参数 | Q4显存 | 推荐GPU显卡 |
| Qwen3.5-35B-A3B | 35B | 3B | 24GB | RTX 4090单卡 |
| Qwen3.5-122B-A10B | 122B | 10B | 81GB | 多卡A100/H100 |
Qwen3.5 旗舰MoE 系列(Q4_K_M 量化)
|-------------------|------|------|-----|---------|---------|
| 模型 | 总参数量 | 激活参数 | 上下文 | Q4显存 | 推荐GPU显卡 |
| Qwen3.5-397B-A17B | 397B | 17B | 1M | ~200GB | 多卡H100 |
Qwen3.6 系列(2026 年最新,Q4_K_M 量化)
|-----------------|------|------|------------|
| 模型 | 总参数量 | Q4显存 | 推荐GPU显卡 |
| Qwen3.6-27B | 27B | 17GB | RTX 4090双卡 |
| Qwen3.6-35B-A3B | 35B | 24GB | RTX 4090单卡 |
Qwen3.6-27B是270亿参数的稠密多模态模型,支持多模态思考与非思考模式,在智能体编程方面达到旗舰级表现,全面超越前代Qwen3.5-397B-A17B。
MoE **架构优势:**397B总参数量的旗舰模型,实际激活只有17B参数,显存需求只有34GB。这意味着部署成本大幅降低的同时,性能依然强大。Qwen3.5-35B-A3B甚至可以在单张RTX 4090上运行,性价比极高。
Google Gemma4 系列
Gemma4是Google DeepMind推出的新一代开源模型,基于Gemini技术体系构建,全系支持原生多模态(图像、视频、音频)。
|----------------|------|------|------------|------|-------|---------------|
| 模型 | 总参数量 | 激活参数 | 类型 | 上下文 | Q4显存 | 推荐GPU显卡 |
| Gemma4-E2B | ~5B | ~2B | PLE原生VL+音频 | 128K | 7.2GB | RTX 3060 |
| Gemma4-E4B | ~8B | ~4B | PLE原生VL+音频 | 128K | 9.6GB | RTX 3060/4060 |
| Gemma4-26B-A4B | 26B | 4B | MoE原生VL | 256K | 18GB | RTX 4090单卡 |
| Gemma4-31B | 31B | 31B | Dense原生VL | 256K | 20GB | A100/多卡4090 |
Gemma4的技术亮点在于Per-Layer Embeddings(PLE)机制,实际推理仅需加载部分核心权重,大幅降低终端硬件门槛。31B模型在Arena AI排行中位列开源模型前三,在性能上超过部分参数规模高出约20倍的模型。所有模型支持140+种语言,并原生支持函数调用、结构化JSON输出及系统指令。
不同场景下GPU 显卡选择建议
++场景一:个人开发者、中小企业,7B-13B++ ++文本模型++
RTX 4090 最能发挥优势的场景
RTX 4090的24GB显存可以容纳FP16精度的7B模型,或者INT8精度的13B模型。在这个规模下,单卡推理4090的性能与A100几乎持平(模型能完整放在一张卡里,不涉及多卡通信),但价格只有A100的十分之一。
按照实测数据,4090跑LLaMA-7B大概在60-90 tokens/s,完全可以满足日常使用需求。如果用INT8量化,还能进一步提升吞吐量。
++场景二:多模态模型(视觉+++ ++文本)多模态++
显存需求更高,建议更保守的选型
7B 级别VLM : RTX 4090单卡可以跑,但建议预留一些显存给图像处理
13B-27B 级别VLM : 需要A100或双卡4090
72B 级别VLM : 必须使用多卡A100/H100
如果预算有限,可以考虑量化后的模型,比如INT4量化的72B VLM可以压在单张RTX 4090上,虽然精度会有所损失。
++场景三:国产替代需求++ ++国产++
受限于出口管制,很多企业需要考虑国产替代方案
昇腾910B **:**华为自研,算力达到376 TFLOPS(FP16),带宽1.2TB/s,配合MindIE推理引擎可以跑主流开源模型。主要问题是软件生态不够完善,需要做一定的适配工作。
海光DCU **:**兼容CUDA生态,迁移成本较低。支持DeepSeek、Qwen等主流国产AI大模型。性能大概能达到A100的40%-60%。
寒武纪MLU590 **:**带宽2TB/s,96GB显存,性能在国内属于领先水平。
选择国产卡的关键考量是软件生态。昇腾需要使用MindIE或vLLM-ascend,海光可以用类CUDA接口直接迁移。寒武纪的生态相对薄弱,适配成本高。
++场景四:70B++ ++以上AI++ ++大模型,需要多卡并行++
NVLink 互联成为刚需
单张4090显存24GB,放不下70B模型(需要140GB)。必须多卡并行,但4090没有NVLink,多卡之间走PCIe会损失大量性能。
通常的做法:
- 2张4090跑70B INT4量化(35GB × 2 = 70GB,刚好够)
- 但多卡并行时通信成为瓶颈,实际性能不如单卡理想
如果预算允许,A100 80GB(需要2卡,共160GB)或H100 80GB是更合理的选择。H100的900GB/s NVLink带宽让多卡协作效率远超消费级GPU显卡。
带宽之外还需要考虑什么
带宽是核心指标,但选GPU显卡不能只看带宽。
- **显存容量是第一个门槛:**带宽再高,显存装不下模型也是白搭
- **算力决定特定场景性能:**比如开启大batch处理时
- **功耗和散热不容忽视:**4090满载450W,多卡部署电源和散热成本很高
- **生态和驱动很关键:**NVIDIA的CUDA生态最成熟,问题容易解决
- **国产化政策因素:**涉及政府、金融、央企等敏感领域,国产化可能是硬性要求
经验总结:
• 7B-13B文本模型 → RTX 4090,性价比最优
• 多模态模型 → 建议预留更多显存,A100更稳妥
• 有国产化需求 → 昇腾910B或海光DCU
• 70B以上AI大模型 → A100/H100,舍得花钱就上H100
• 记住:带宽决定推理速度上限,显存决定能不能跑
* 实际测试结果可能因驱动版本、模型实现、测试环境等因素有所差异。国产GPU显卡性能数据来源于各厂商官方资料,实际表现可能存在差异。