1.理解文件
1.1 Linux 文件概念
-
"文件 = inode(属性) + 数据块(内容)" 是基础模型。
-
目录 通过
文件名 → inode号的映射,将名字和文件关联起来。 -
各种文件操作,无论是
mv、chmod还是echo,本质上都是在操作这个模型的不同部分------要么修改目录的映射表,要么修改 inode 的属性,要么读写数据块。
1.2 狭义理解:文件在磁盘里
核心观点:从物理层面看,文件存放在磁盘上,对文件的操作本质上就是对磁盘这种外部设备的输入输出(IO)。
1. 磁盘是永久性存储介质
-
内存(RAM)断电即丢失数据。
-
磁盘(无论是机械硬盘还是固态硬盘)断电后数据依然存在。
-
因此,文件存储在磁盘上,意味着 文件是永久性存储的。
2. 磁盘是外设
-
计算机硬件分为主机 (CPU + 内存)和外部设备。
-
磁盘属于外设,且具有双重角色:
-
输出设备:当把内存中的数据写入文件保存到磁盘时,磁盘接收数据,是输出设备。
-
输入设备:当从磁盘读取文件数据加载到内存时,磁盘提供数据,是输入设备。
-
3. 文件操作的本质 = 对外设的 IO
这层理解把所有文件操作都统一成了一种模型:文件操作 = 输入/输出(IO)操作 = 与外设(磁盘)的数据交互 
关键结论:
- 操作系统的作用之一,就是隐藏底层硬件的复杂性,把"读写磁盘扇区"这种物理操作,封装成"打开文件、读写文件"这样简单的接口。
1.3 广义理解:Linux 下一切皆文件
核心观点:Linux 将系统中的几乎所有资源(硬件、进程、系统信息等)都抽象为文件。文件的概念被极大泛化,不再局限于磁盘上的数据。
为什么这样做?------ 统一接口
无论是读一个磁盘文件,还是读键盘输入,甚至读取网卡收到的数据,都可以使用同一套系统调用:open() 、read()、write()、 close()
于是,操作不同的硬件,变成了操作不同的文件。
一切都是怎么变成文件的?
系统通过虚拟文件系统(VFS) 和各种文件系统类型,把不同资源抽象成文件。下一篇将详细讲解
还有一些特殊的"文件":
-
/proc目录 :进程和系统信息。例如/proc/cpuinfo存放 CPU 信息,/proc/meminfo存放内存信息。它们是内核在访问时动态生成的"文件",内容读自内核,不在磁盘上。 -
/sys目录:设备和驱动信息。 -
管道(Pipe):进程间通信的一种方式,也以文件描述符的形式存在。
如何理解这种"抽象"?
抽象就是把复杂的东西打包,对外只暴露简单的操作接口。
-
底层复杂性被隐藏:你不需要知道键盘是 PS/2 还是 USB 接口,不需要知道显示器是液晶还是 CRT,你只需要面对一个"文件"。
-
本质是对外设 IO 的延伸 :回顾
1.2 狭义理解,文件操作本质是对磁盘这个外设的 IO。现在,这个 IO 的对象被扩展到了所有外设 ,甚至内核自身。
1.4 系统角度:文件操作的本质
核心观点:文件操作不是编程语言提供的功能,而是操作系统通过"系统调用"向进程提供的服务。磁盘这类硬件的管理者是操作系统,而非用户程序。
- 操作的主体是"进程"
-
文件不是自己在动,也不是编程语言在操作。
-
所有打开、读写、关闭文件的行为,最终都是由一个个正在运行的程序(进程) 发起的。
-
因此,文件操作 = 进程对文件的操作。
- 硬件的管理者是"操作系统"
-
回顾
1.2节,文件最终存储在磁盘上,而磁盘是硬件外设。 -
用户程序没有权限,也没有能力直接操控磁盘(比如指定磁头、扇区)。这种底层硬件资源的管理者是操作系统内核。
-
操作系统承担了管理者 和服务者的角色,它独占硬件的控制权,同时对外提供安全的服务接口。
- 库函数 vs 系统调用
我们通常写 C/C++ 代码时,用的是 fopen、fprintf、fclose 这些函数。但它们不是本质 。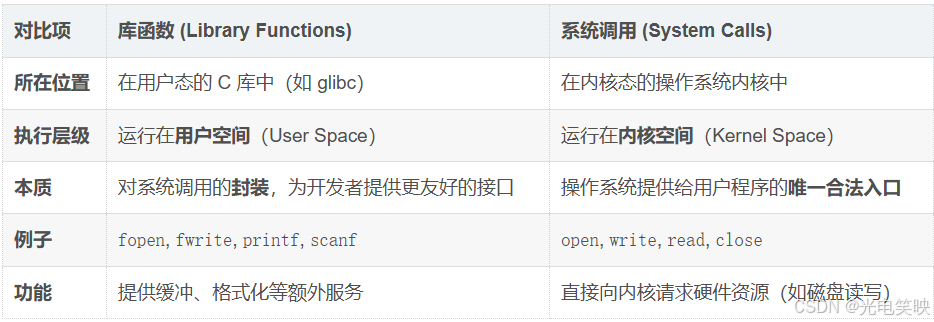
核心结论:
- 文件读写的本质,是通过文件相关的系统调用接口来实现的。
- 文件的最终管理者是操作系统,而进程是请求操作的主体。无论是 C 还是 C++,库函数都只是封装,真正触及硬件核心的,是操作系统提供的系统调用接口。
操作系统把文件(以及一切资源)的静态属性用 inode 这样的结构体描述出来,再把它们用目录、链表、哈希表等结构高效地组织起来,最后通过系统调用,向进程提供统一的、抽象的、安全的服务。这就是"先描述,再组织"思想在文件管理中的完整体现。
2.c语言文件接口
文件操作函数
基于 FILE * 流,带用户态缓冲区,可移植性好。 
六种文件打开基础模式 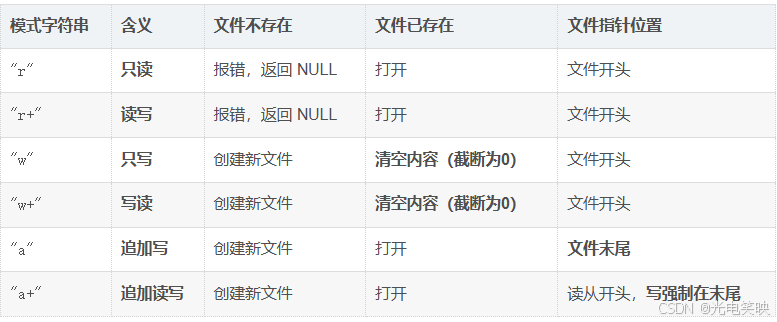
标准流(默认已打开,不用手动 fopen): 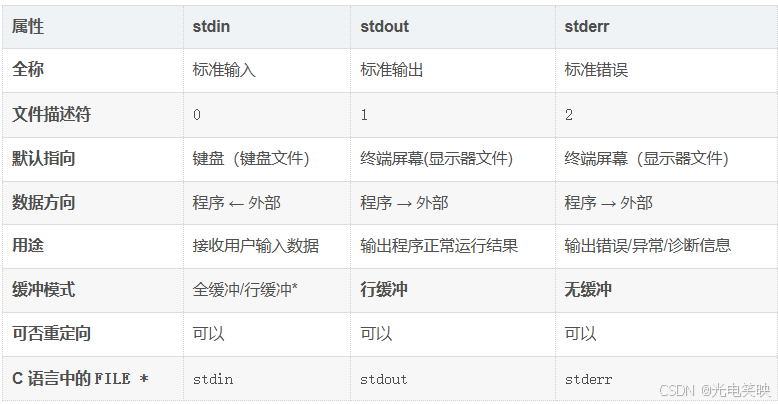
*stdin 的缓冲取决于连接对象:键盘输入通常是行缓冲,从文件重定向则是全缓冲。
C语言的stdin、stdout、stderr对应C++就是cin、cout、cerr
一切皆文件,一切 IO 都尽量统一成文件读写。 这也就是为什么要自动打开原因**,** 如果每次写程序都要自己手动
open("/dev/keyboard")、open("/dev/screen"),不仅繁琐,而且程序会丧失通用性 ------换个终端设备就没法用了。Linux的解决方案是:由父进程(通常是 shell)在启动程序之前,先把这三个 IO 通道准备好,然后程序直接继承过来即可。
程序是做数据处理的,默认打开三个标准 IO 文件的目的是给程序提供默认的数据流。
缓冲模式对比: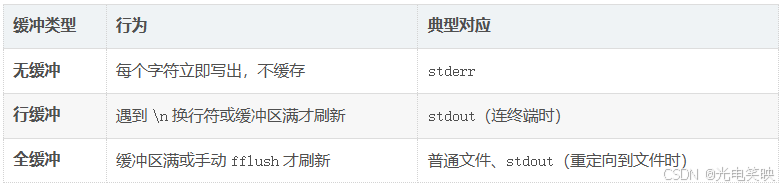
缓冲模式在下一篇将结合fork详细讲解
格式化输入输出 
简单演示:
bash
xqq@ubuntu-server:~/linux/moduleIX$ cat file.c
#include<stdio.h>
#include<string.h>
int main()
{
FILE*fp=fopen("log.txt","w");
if(fp==NULL)
{
perror("fopen");
return 1;
}
const char*msg="hello world";
for(int i=0;i<10;i++)
{
char buff[1024];
snprintf(buff,sizeof(buff),"%d:%s\n",i,msg);
fwrite(buff,strlen(buff),1,fp);
}
fclose(fp);
return 0;
}
xqq@ubuntu-server:~/linux/moduleIX$ ./file.exe
xqq@ubuntu-server:~/linux/moduleIX$ cat log.txt
0:hello world
1:hello world
//。。。
8:hello world
9:hello world跨平台性:为什么要有语言层的封装?
**"为什么我们不直接用系统调用,非要多一层 C 库?"**答案就是跨平台性:C 库屏蔽了不同操作系统的系统调用差异
我们写的代码遵循的是 C 语言标准,底层调用的却是各个操作系统私有的"方言"------Linux 的
write、Windows 的WriteFile、macOS 的write,互不兼容。如果直接写系统调用,代码换一个平台就报废了。C 语言的解决方案是:不让你直接和系统调用打交道,而是在上面铺了一层标准库,比如 glibc、MSVC CRT、musl。每个平台上的标准库,都用该平台原生的系统调用,把
printf、fopen、fwrite这些标准接口重新实现了一遍。 你在任何平台上写的都是printf("hello\n"),这行代码在 Linux 上被 glibc 翻译成write(1, buf, len),在 Windows 上被 MSVC CRT 翻译成WriteFile(GetStdHandle(...), buf, len, ...)。C 语言的可移植性,不是靠操作系统"统一接口",而是靠标准库在所有平台上"逐一适配"------把一套不变的 API 映射到千差万别的系统调用之上。上层接口统一,下层实现各表,差异由库文件彻底屏蔽。这就是 C 语言跨平台的根基。
而语言增加可移植性是为了将不同平台的用户全都吸引过来,增加使用该语言的人数已达到不被淘汰、增加市场占有率的目的
常见问题:
q:打开的myfile⽂件在哪个路径下?
a:在程序的当前路径下,那系统怎么知道程序的当前路径在哪⾥呢?
可以使⽤ ls /proc/进程id -l 命令查看当前正在运⾏进程的信息:
在之前的代码加一个死循环,方便观察
bashxqq@ubuntu-server:~$ ps axj|head -1&&ps ajx| grep file.exe|grep -v grep PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND 8614 8999 8999 8614 pts/0 8999 R+ 1001 0:07 ./file.exe xqq@ubuntu-server:~$ ls /proc/8999 -l total 0 //。。。 -r--r--r-- 1 xqq xqq 0 May 15 09:13 cpuset lrwxrwxrwx 1 xqq xqq 0 May 15 09:13 cwd -> /home/xqq/linux/moduleIX -r-------- 1 xqq xqq 0 May 15 09:13 environ lrwxrwxrwx 1 xqq xqq 0 May 15 09:13 exe -> /home/xqq/linux/moduleIX/file.exe dr-x------ 2 xqq xqq 0 May 15 09:13 fd dr-xr-xr-x 2 xqq xqq 0 May 15 09:13 fdinfo //。。。其中:
cwd:指向当前进程运⾏⽬录的⼀个符号链接。
exe:指向启动当前进程的可执⾏⽂件(完整路径)的符号链接。
打开⽂件,本质是进程打开,所以,进程知道⾃⼰在哪⾥,即便⽂件不带路径,进程也知道。由此OS 就能知道要创建的⽂件放在哪⾥。
q:\0的真相:C 字符串 vs 文件字节流
a:\0写入文件后,它就是一个值为 0 的普通字节。文件系统只记录字节个数(inode 中的 Size 字段),不解析字节含义。"字符串终止符"这一套约定,只对 C 语言的%s、strlen()等函数有效,对文件系统无效。这就是为什么:
文本文件 通常不包含
\0(因为 C 程序处理起来会"提前截断")二进制文件 (图片、可执行文件等)可以包含大量
\0字节(它们用精确的字节数来读写,不用%s)所以我们以后写程序时不要将\0写入到文件里
q:>>与>的本质
a:我们说过,要访问文件,要先把文件打开,就是 shell 在
open()系统调用中,一个传了O_TRUNC(清空),一个传了O_APPEND(追加)。这和用fopen("file", "w")和fopen("file", "a")本质完全相同。
模拟实现cat命令:
cpp
xqq@ubuntu-server:~/linux/moduleIX$ ./cat cat.c log.txt
#include <stdio.h>
#include <string.h>
int main(int argc, char *argv[])
{
if(argc == 1)
{
printf("Usage: %s filename\n", argv[0]);
return 1;
}
int i = 1;
while(argv[i])
{
FILE *fp = fopen(argv[i], "r");
if(fp == NULL)
{
perror("fopen fail");
i++;
continue; // 跳过这个文件,继续处理下一个
}
char buff[1024];
size_t n;
while((n = fread(buff, 1, sizeof(buff)-1, fp)) > 0)
{
buff[n] = '\0';
printf("%s", buff);
}
fclose(fp);
i++;
}
return 0;
}0:hello world
1:hello world
2:hello world
//。。。
8:hello world
9:hello world3. 系统文件I/O
*引言
在前两章中,我们站在 C 语言和标准库的角度学习了文件操作:能够快速地读写文件数据,但这些操作本质上都是语言层面提供的便捷封装。现在我们要追问一个更底层的问题:
当我们在 C 语言里调用
fopen的时候,操作系统到底做了什么?文件究竟是如何被"打开"的?数据又是如何从磁盘真正流入内存、从内存真正写入磁盘的?要回答这些问题,就必须越过 C 库的封装,直接面对操作系统提供的文件 IO 系统调用。
在 Linux 下,这套接口才是文件操作的最终实现者:
open()--- 打开或创建文件
read()--- 从文件读取数据
write()--- 向文件写入数据
close()--- 关闭文件
lseek()--- 移动文件读写位置dup2
()--- 复制文件描述符(它是重定向的底层基础)这些函数是操作系统内核提供给用户程序的原始服务接口。它们运行在内核态,直接操作硬件和文件系统,是我们之前说的"系统调用"的典型代表。
核心原则:对文件的任何操作都必须把文件加载到内核对应的文件缓存区内,而加载的本质就是从磁盘到内存的拷贝
3.1 一种传递标志位的方法:位图
位图传参 ------ 用 | 组合标志,用 & 检查标志 ,先上代码**:**
cpp
#include <stdio.h>
#define ONE 0001 //0000 0001
#define TWO 0002 //0000 0010
#define THREE 0004 //0000 0100
void func(int flags)
{ //检查标志
if (flags & ONE) printf("flags has ONE! ");
if (flags & TWO) printf("flags has TWO! ");
if (flags & THREE) printf("flags has THREE! ");
printf("\n");
}
int main()
{ //组合标志
func(ONE);
func(THREE);
func(ONE | TWO);
func(ONE | THREE | TWO);
return 0;
}一、这段代码在做什么?
这是位图(Bitmap)传参 演示。用一个整数的不同 bit 位表示不同的选项,多个选项可以通过按位或 | 组合成一个参数传递进去。
运行结果:
bash
xqq@ubuntu-server:~/linux/moduleIX$ ./bitmap
flags has ONE!
flags has THREE!
flags has ONE! flags has TWO!
flags has ONE! flags has TWO! flags has THREE! 二、核心原理拆解
1. 定义标志:每个标志独占一个 bit 位
cpp
#define ONE 0001 // 八进制 → 二进制:0000 0001 → bit 0
#define TWO 0002 // 八进制 → 二进制:0000 0010 → bit 1
#define THREE 0004 // 八进制 → 二进制:0000 0100 → bit 2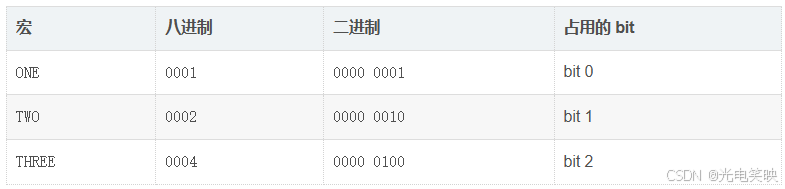
关键设计:每个值都是 2 的幂次(1, 2, 4, 8, 16...),二进制表示中只有一位是 1,其余全是 0。 这样多个标志做 | 运算时,各自的 1 不会互相干扰。
2. 组合标志:用按位或 | 打包多个选项
cpp
func(ONE | TWO); // 0001 | 0010 = 0011
func(ONE | TWO | THREE); // 0001 | 0010 | 0100 = 0111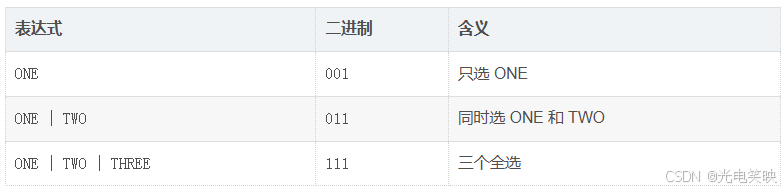
按位或 | 在这里的作用就是把多个标志的"1"拼在一起。
3. 检查标志:用按位与 & 提取某个 bit
cpp
if (flags & ONE) printf("flags has ONE! ");
if (flags & TWO) printf("flags has TWO! ");
if (flags & THREE) printf("flags has THREE! ");假设 flags = ONE | TWO = 0011(组合了ONE和TWO )
flags & ONE=0011 & 0001=0001≠ 0 真flags & TWO=0011 & 0010=0010≠ 0 真flags & THREE=0011 & 0100=0000= 0 假
按位与 & 的作用是"检查特定位上是否为 1"------只有当那个 bit 为 1 时,结果才非零。
三、为什么用八进制 0001 而不是十进制?
八进制每一位正好对应 3 个 bit,和二进制转换非常直观:
| 八进制 | 二进制 |
|---|---|
0 |
000 |
1 |
001 |
2 |
010 |
4 |
100 |
7 |
111 |
所以 0001(八进制)= 0b000000001,0004 = 0b000000100,一眼就能看出每个标志占的是哪个 bit 位。
在 open 系统调用的源码和系统编程中,标志位几乎都用八进制或十六进制定义
上面说的原理和下面 即将介绍3.3 open 的 flags 参数是完全一样的机制。 open 的第二个参数就是通过这种方式组合的: int fd = open("file.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644);因此上面写的 func(ONE | TWO),就是 open 的 O_WRONLY | O_CREAT 的迷你版原型。
四、位图传参的优缺点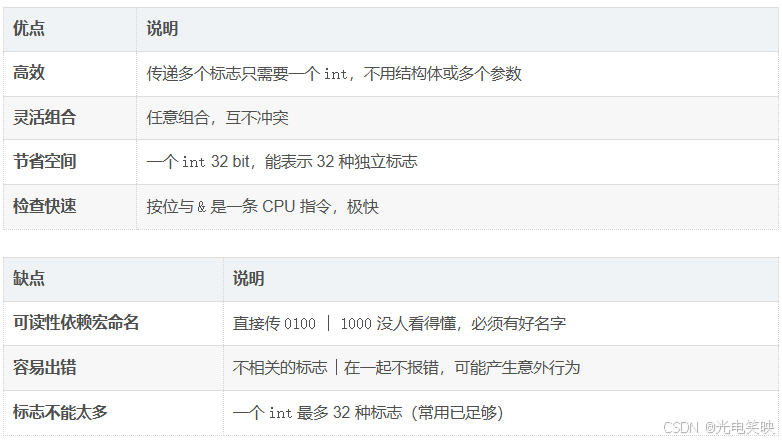
总结:位图传参就是用不同 bit 位代表不同含义,用 | 把多个标志打包成一个整数传进去,用 & 检查某个标志是否被设置。open 的 flags、waitpid 的 options、mmap 的 prot 等系统调用,全部依赖这个机制。
3.2 open 函数
open 函数 --- 打开/创建文件的系统调用
一、函数原型
cpp
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);注意: open 有两个版本 (两参数和三参数),这是 C 语言中极少见的"可变参数"设计,具体用哪个取决于 flags 中是否包含 O_CREAT。
二、参数说明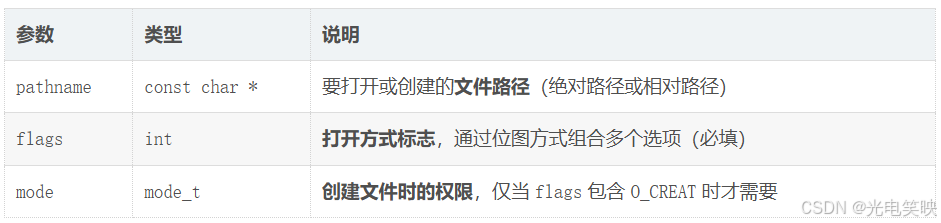
三、flags 参数详解(位图传参的典型应用)
flags 是一个 int 值,用不同 bit 位表示不同选项,通过按位或 | 组合使用。
3.1 访问模式(三选一,必填)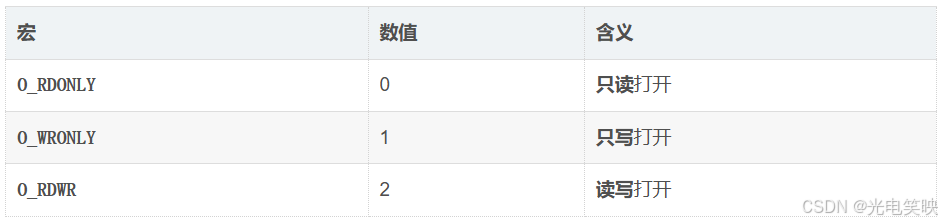
这三个是互斥 的,用
|连接没用意义(O_RDONLY | O_WRONLY等于O_RDWR,但不推荐这样写)。
3.2 常用可选标志(可多选,用 | 组合)
四、flags 组合对照表(和 fopen 模式的对应)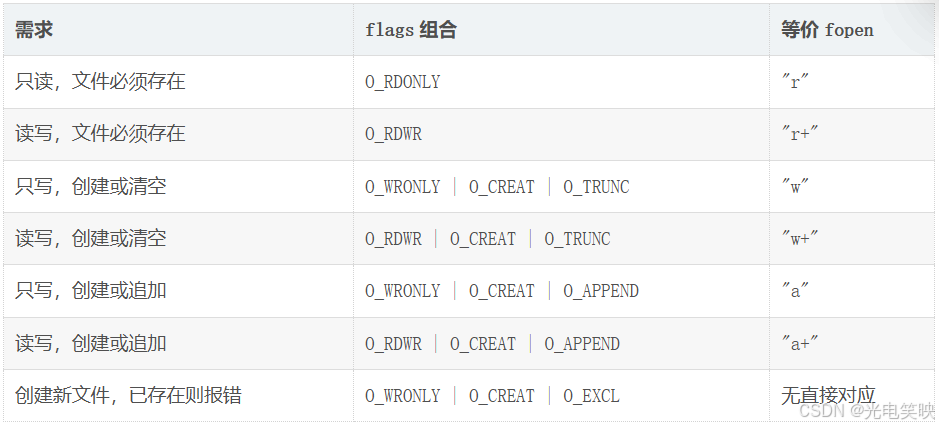
五、mode 参数(仅 O_CREAT 时需要)
当 flags 包含 O_CREAT 时,必须提供第三个参数指定新文件的访问权限:
cpp
int fd = open("newfile.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644);
// ^
// 八进制权限常用权限组合:
注意: 最终文件权限 =
mode & ~umask。如果umask是0002,那么mode=0666创建出来的文件实际权限是0664(rw-rw-r--)。如果不想受到umask影响可以用umask(0);
包含O_CREAT时不写mode会怎么样?
bashxqq@ubuntu-server:~/linux/moduleIX$ cat test_no_mode.c #include<stdio.h> #include<sys/types.h> #include<fcntl.h> #include<sys/stat.h> #include<unistd.h> int main() { int fd=open("test.txt",O_CREAT|O_WRONLY|O_TRUNC); if(fd<0) { perror("open fail!"); return 1; } close(fd); return 0; }xqq@ubuntu-server:~/linux/moduleIX$ ./test_no_mode xqq@ubuntu-server:~/linux/moduleIX$ ll total 108 drwxrwxr-x 2 xqq xqq 4096 May 16 20:31 ./ drwxrwxr-x 13 xqq xqq 4096 May 13 10:32 ../ -rwxrwxr-x 1 xqq xqq 17480 May 16 19:05 bitmap* -rw-rw-r-- 1 xqq xqq 415 May 16 19:05 bitmap.c -rwxrwxr-x 1 xqq xqq 19080 May 15 10:28 cat* -rw-rw-r-- 1 xqq xqq 671 May 15 10:28 cat.c -rw-rw-r-- 1 xqq xqq 624 May 16 19:05 file.c -rwxrwxr-x 1 xqq xqq 16232 May 15 10:28 file.exe* -rw-rw-r-- 1 xqq xqq 140 May 15 10:18 log.txt -rw-rw-r-- 1 xqq xqq 66 May 15 08:21 Makefile -rwxrwxr-x 1 xqq xqq 17424 May 16 20:29 test_no_mode* -rw-rw-r-- 1 xqq xqq 227 May 16 20:29 test_no_mode.c --wx-ws--T 1 xqq xqq 0 May 16 20:31 test.txt*当
flags包含O_CREAT但不提供第三个参数mode时,文件权限是"随机"的垃圾值。 具体来说,open会从栈上(或寄存器中)读取一个本应是mode的未定义值作为文件权限,导致创建的文件的权限位不可预测。
六、返回值
典型错误:
-
EACCES:权限不足 -
ENOENT:文件不存在(且没有指定O_CREAT) -
EEXIST:O_CREAT | O_EXCL时文件已存在 -
EISDIR:尝试以写方式打开一个目录
七、open 和 fopen 的本质关系
fopen 是 C 库对 open 的封装,内部调用链大致如下:fopen("log.txt", "w")
- 解析 mode 字符串"w" → O_WRONLY | O_CREAT | O_TRUNC
- 调用系统调用 open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666)受 umask 影响,最终权限 = 0666 & ~umask,返回值:fd = 3(假设 0/1/2 已被标准流占用)
- 在堆上分配 FILE 结构体
- 初始化缓冲区:根据打开模式分配读/写缓冲、设置缓冲模式(全缓冲/行缓冲/无缓冲)
- 返回 FILE * 指针给用户
用户拿到 FILE *fp,用它调用 fwrite / fprintf / fread 等、fopen 返回的 FILE * 里面,核心就包了一个 open 返回的 fd。
八、简单示例
cpp
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#include <errno.h>
int main()
{
// 以只写方式打开(创建或清空),权限 0644
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644);
if (fd == -1)
{
fprintf(stderr, "open failed: %s\n", strerror(errno));
return 1;
}
printf("文件打开成功,fd = %d\n", fd); // 通常输出 3(0/1/2 已被标准流占用)
// 写数据
const char *msg = "hello from open\n";
ssize_t bytes = write(fd, msg, strlen(msg));
printf("写入 %zd 字节\n", bytes);
// 关闭
close(fd);
return 0;
} 3.3 write 函数
向文件写入数据的系统调用
一、函数原型
cpp
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);二、参数说明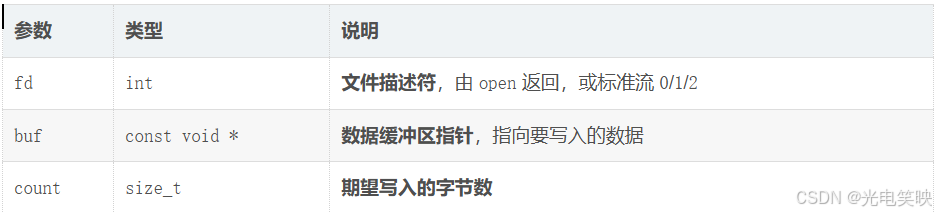
三、返回值
关键:
write的返回值是实际写入的字节数,不一定等于你请求的count。 健壮的代码必须检查返回值,必要时循环写入。
四、和 fwrite 的核心区别
总结:write 是 Linux 文件 IO 最底层的写入系统调用,没有 C 库缓冲,直接向内核提交数据。它的返回值是实际写入的字节数,健壮的代码必须检查返回值并处理部分写入的情况。
二进制写入vs文本写入
在 Linux 下进行文件 IO 时,我们有两种写入数据的基本方式:
-
二进制写入:直接把内存中的数据按字节原样复制到文件
-
文本写入:先把数据格式化成人类可读的字符串,再写入文件
这两种方式看似只是"格式"不同,但背后涉及文件存储、数据表示、跨平台兼容性等一系列深刻问题。本文通过一个简单的实验来揭示它们的本质区别。
示例代码
cpp
#include<stdio.h>
#include<string.h>
#include<sys/types.h>
#include<fcntl.h>
#include <sys/stat.h>
#include<unistd.h>
int main()
{
int fd=open("test.txt",O_CREAT|O_WRONLY|O_TRUNC,0664);
if(fd<0)
{
perror("open fail!");
return 1;
}
int a=123456;
///1.二进制写入
//int bytes=write(fd,&a,sizeof(a));
//2.格式化写入
char buff[16]={0};
snprintf(buff,sizeof(buff),"%d",a);
int bytes=write(fd,buff,strlen(buff));
printf("fd:%d\n",fd);
close(fd);
return 0;
}
bash
xqq@ubuntu-server:~/linux/moduleIX$ ./file.exe
fd:3
xqq@ubuntu-server:~/linux/moduleIX$ cat test.txt #vim 打开是这样的@?^A^@
@�xqq@ubuntu-server:~/linux/moduleIX$ ll
total 132
drwxrwxr-x 2 xqq xqq 4096 May 16 22:14 ./
drwxrwxr-x 13 xqq xqq 4096 May 13 10:32 ../
//。。。。
-rw-rw-r-- 1 xqq xqq 4 May 16 22:14 test.txt
^大小4字节
xqq@ubuntu-server:~/linux/moduleIX$ ./file.exe
fd:3
xqq@ubuntu-server:~/linux/moduleIX$ cat test.txt
123456xqq@ubuntu-server:~/linux/moduleIX$ ll
total 132
drwxrwxr-x 2 xqq xqq 4096 May 16 22:39 ./
drwxrwxr-x 13 xqq xqq 4096 May 13 10:32 ../
//......
-rw-rw-r-- 1 xqq xqq 6 May 16 22:39 test.txtcat试图把文件的原始字节当作 ASCII/UTF-8 文本解析,但读到的是整数123456的二进制补码表示,所以显示为乱码。- 当我们执行
snprintf+write时,先把123456转换成字符串"123456",再写入这 6 个 ASCII 字符。
格式化,就是把"给机器看的二进制数据"翻译成"给人看的文本字符",再把这份文本交给内核去存储。 内核的 write 根本不认识整数、浮点数、结构体,它只认一件事:从哪个内存地址开始,连续搬多少个字节到磁盘 。至于这四个字节 0x40 0xE2 0x01 0x00 是什么意思,内核毫不在乎。
"格式化"这个动作跟内核无关,它完全发生在用户态------要么调用 C 标准库的 printf/snprintf,要么调用 C++ 的 std::format/流操作符,要么你自己手写一个转换函数。做完格式化之后,内存里就不再是原始二进制了,而是一串 ASCII 或 UTF-8 字符,比如 "123456" 对应的 0x31 0x32 0x33 0x34 0x35 0x36。
所以"文本写入"本质上就是"先格式化,再写字节"。内核从头到尾只看到字节流;"文本"也好、"格式化"也好,全是语言层和应用程序自己赋予的含义。
3.4 read 和 close ------ 读取数据与关闭文件
一、read ------ 从文件读取数据
函数原型
cpp
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);参数说明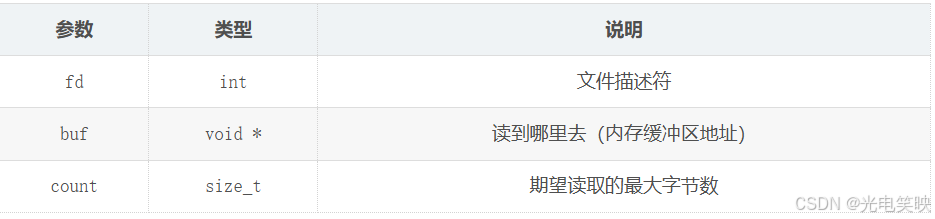
返回值 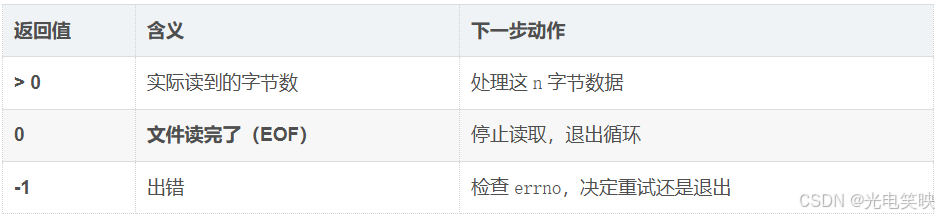
A判断文件结束的黄金法则:read 返回 0 就是 EOF,不需要也不应该用 feof 那一套。
与 fread 的核心区别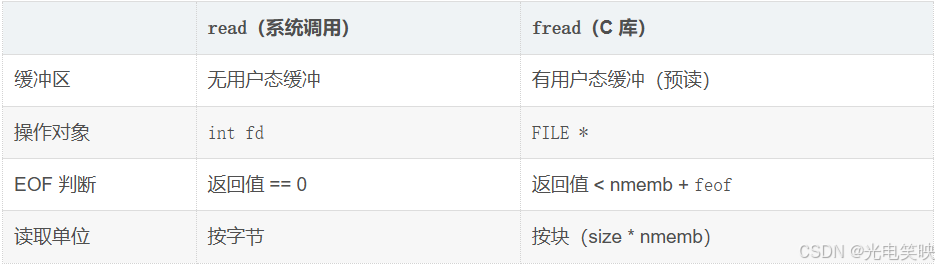
正确用法示例
cpp
char buf[1024];
ssize_t n;
while ((n = read(fd, buf, sizeof(buf) - 1)) > 0)
{
buf[n] = '\0'; // 手动加终止符,写的时候不加,读的时候加
printf("%s", buf);
}
if (n == -1) {
perror("read"); // 真正出错
}
// n == 0 表示读完,正常退出循环二、close ------ 关闭文件描述符
函数原型
cpp
#include <unistd.h>
int close(int fd);返回值
| 返回值 | 含义 |
|---|---|
0 |
关闭成功 |
-1 |
出错(如 fd 无效、已被关闭) |
close 到底做了什么?
-
释放文件描述符
fd(这个 slot 可以给后续open重用) -
减少内核
struct file的引用计数 -
如果引用计数降为 0,释放该
struct file,更新 inode 中的时间戳等信息 -
如果有脏数据在内核缓冲区,负责刷盘
为什么必须 close?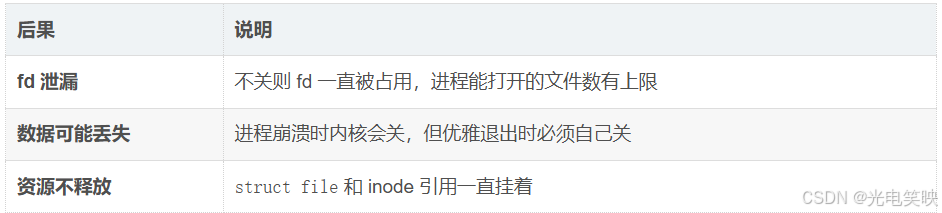
常见错误
cpp
// 忘记关闭
int fd = open("file", O_RDONLY);
// 用完没 close
// 重复关闭
close(fd);
close(fd); // 第二次返回 -1,errno = EBADF3.5 文件描述符 fd
一、fd 是什么?
文件描述符(file descriptor)是一个非负整数,是进程用来标识"已打开文件"的句柄。
当我们调用 open 成功打开一个文件后,内核会返回一个整数(比如 3),这个整数就是文件描述符。后续所有的 IO 操作------read、write、lseek、close------都用这个整数来指代这个文件。
对进程来说,fd 就是一个数字;但对内核来说,这个数字背后连着一整套复杂的数据结构。
二、fd 的本质:进程打开文件表的索引
之前说过,一个进程可以打开多个文件,有的文件刚刚被打开,有的文件要关闭,还有的文件正在被访问,这些文件状态各异、生命周期各不相同,进程必须对它们进行有效的管理
按照"先描述,再组织"的管理思想,操作系统是这样管理进程打开的文件:
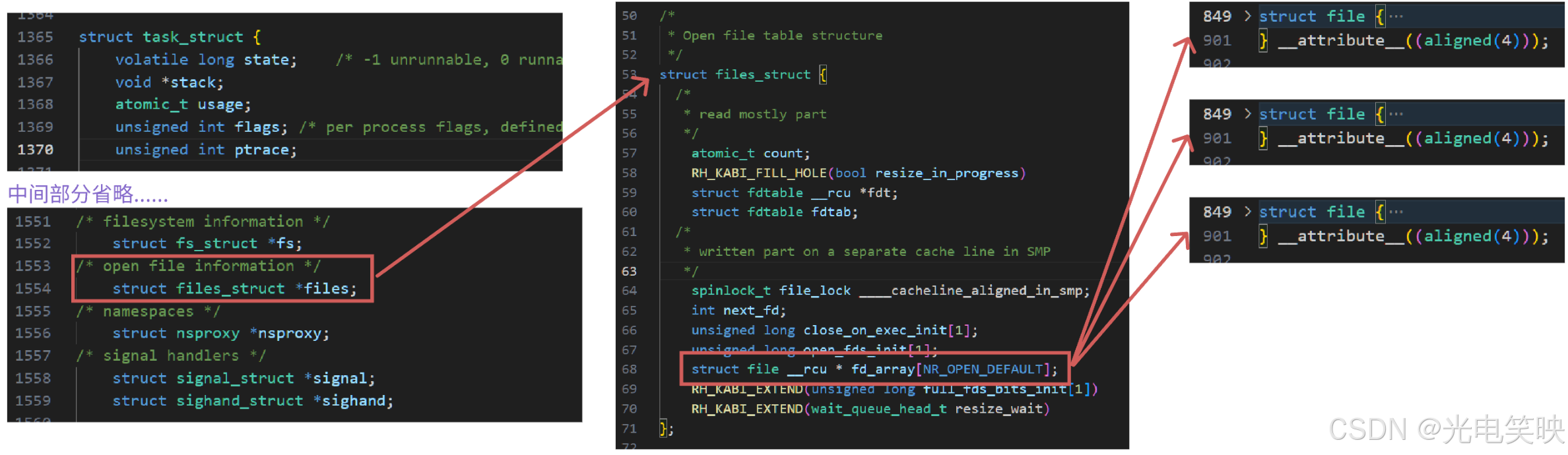
第一步:先描述
内核用两个核心结构体来描述 "进程打开了哪些文件、怎么打开的":
struct file 描述的是"一个文件被打开后,进程和它之间的动态关系"------读到哪了、以什么模式打开的;而 inode 描述的是"文件本身的静态属性"------大小、权限、数据块在哪。
第二步:再组织
有了描述还不够,还需要高效地组织起来。内核的做法是:
每个进程的 task_struct(进程控制块)中,有一个 files 指针,指向一张 files_struct 表。这张表的核心是一个数组,数组的每个下标就是 fd 编号,每个元素是指向 struct file 的指针。
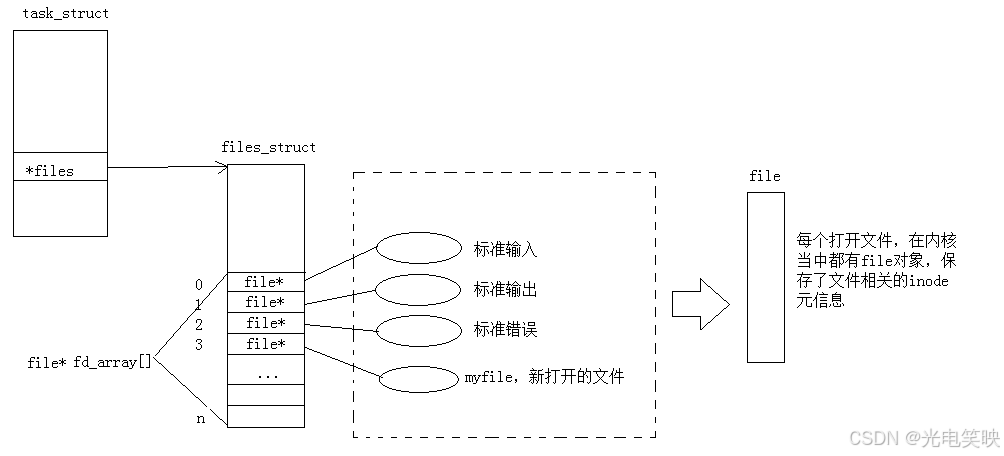
fd 就是这张数组的下标。read(fd, buf, size) 中的 fd 告诉内核:"去我的文件描述符表中,找到下标为 fd 的那个 struct file,然后从它指向的文件里读数据。"
部分源码:
三、fd 的分配规则:从小到大,找最小的空闲 slot
当调用 open 时,内核在 files_struct 中找一个最小的未被占用的下标,把它分配给新打开的文件。
cpp
int fd1 = open("a.txt", O_RDONLY); // 返回 3(0/1/2 已被标准流占用)
int fd2 = open("b.txt", O_RDONLY); // 返回 4
close(fd1); // 释放 3
int fd3 = open("c.txt", O_RDONLY); // 返回 3(最小的空闲 slot)重定向实验:
cpp
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
int main()
{
printf("stdin:%d\n",stdin->_fileno);
printf("stdout:%d\n",stdout->_fileno);
printf("stderr:%d\n",stderr->_fileno);//验证FILE结构体封装了fd文件描述符
close(1); // 关掉 stdout
int fd = open("test.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644);
// fd 会是 1,因为 1 现在是空闲的最小 slot
printf("fd = %d\n", fd); // 输出到屏幕?不!这会写入 test.txt
fprintf(stdout, "hello\n"); // stdout(fd=1) 现在指向 test.txt
close(fd);
return 0;
}缓冲模式存在 C 库的 FILE 结构体里,不是内核 struct file 里。FILE 第一次写入时检测底层 fd 指向什么,然后把缓冲模式写进 _flags,之后就不再改了。dup2 只换内核 fd 数组的指针,不影响 C 库 FILE 里已经设置好的缓冲模式。
运行结果:
bash
xqq@ubuntu-server:~/linux/moduleIX/testfd$ ./file
stdin:0
stdout:1
stderr:2
xqq@ubuntu-server:~/linux/moduleIX/testfd$ cat test.txt
fd = 1
hello结论:stdout就是fd=1只是fd=1被"调包"了
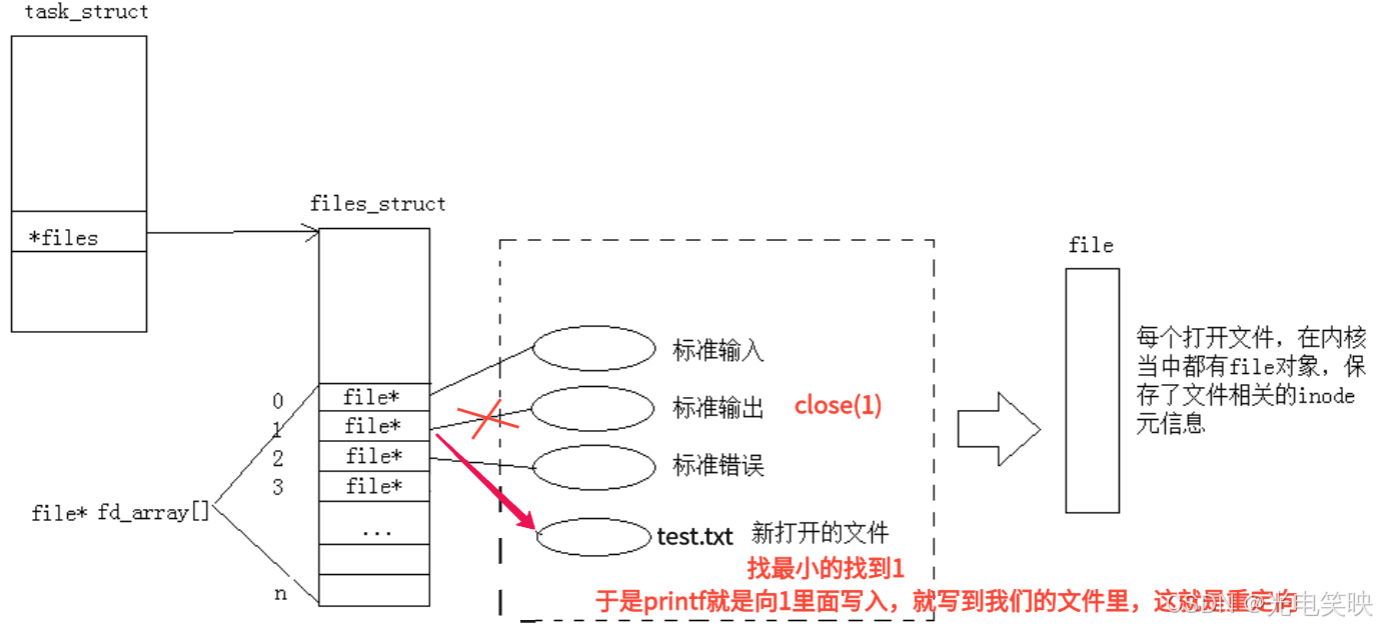 重定向的底层原理,就是把进程 fd 数组中某个 slot 里的
重定向的底层原理,就是把进程 fd 数组中某个 slot 里的 struct file * 指针,从默认的终端设备文件替换成目标文件。fd 编号不变,指向变了,程序无感知
四、dup2 系统调用
dup2就是重定向的正式系统调用,也只能是系统调用,因为要更改的是内核级数据结构
函数原型:
cpp
#include <unistd.h>
int dup2(int oldfd, int newfd);参数说明
| 参数 | 说明 |
|---|---|
oldfd |
已经打开的文件描述符(源) |
newfd |
想要复制到的目标文件描述符编号(目标) |
dup2(fd, 1)就是把槽位 1 里的指针换成槽位 fd 里的指针,1 从此指向 fd 指向的文件。参数顺序口诀:dup2(源, 目标),把"源"的指针拷贝到"目标"槽位,目标原来指向的东西被关掉。
dup2 做了什么?
**让 fd[newfd] 指向和 fd[oldfd] 相同的 struct file 对象。**分三步:
-
如果
newfd已经被占用,先关闭它 -
让
fd[newfd]指向fd[oldfd]指向的struct file -
struct file的引用计数 +1
返回值
| 返回值 | 含义 |
|---|---|
| 成功 | 返回 newfd(新文件描述符) |
| 失败 | 返回 -1,设置 errno(如 EBADF:oldfd 无效) |
示例代码:
- 输出重定向:
cpp
//输出重定向
int main()
{
// 1. 打开目标文件
int fd = open("output.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644);
if (fd == -1)
{
perror("open");
return 1;
}
printf("新文件的 fd = %d\n", fd); // 输出到屏幕(此时 1 还指向屏幕)
// 2. 重定向:把 fd[1] 的指针换成 fd 的指针
dup2(fd, 1);
close(fd); // fd 已经没用了,关掉(fd[1] 还指着 output.txt)
// 3. 这些输出全部进入 output.txt
printf("这行写入文件了\n");
printf("这行也写入文件了\n");
fprintf(stdout, "stdout 也指向文件了\n");
return 0;
}运行结果:
bash
xqq@ubuntu-server:~/linux/moduleIX/testfd$ ./file
新文件的 fd = 3
xqq@ubuntu-server:~/linux/moduleIX/testfd$ cat output.txt
这行写入文件了
这行也写入文件了
stdout 也指向文件了
xqq@ubuntu-server:~/linux/moduleIX/testfd$ - 输入重定向
cpp
//输入重定向
int main()
{
// 1. 打开output.txt文件,准备作为输入源
int fd = open("output.txt", O_RDONLY);
if (fd == -1) {
fprintf(stderr, "open: %s\n", strerror(errno));
return 1;
}
printf("输入文件的 fd = %d\n", fd); // 输出到屏幕(此时 0 还指向键盘)
// 2. 重定向:把 fd[0] 的指针换成 fd 的指针
dup2(fd, 0);
close(fd); // fd 已经没用了,关掉(fd[0] 还指着output.txt)
// 3. 现在从 stdin 读,实际读的是 output.txt
char line[256];
while (fgets(line, sizeof(line), stdin) != NULL) {
printf("读到: %s", line);
}
return 0;
}运行结果:
bash
xqq@ubuntu-server:~/linux/moduleIX/testfd$ ./file
输入文件的 fd = 3
读到: 这行写入文件了
读到: 这行也写入文件了
读到: stdout 也指向文件了
xqq@ubuntu-server:~/linux/moduleIX/testfd$ 五、fd 和 FILE * 的关系
FILE是c语言提供的结构体,本质上是typedef来的,里面封装了文件描述符fd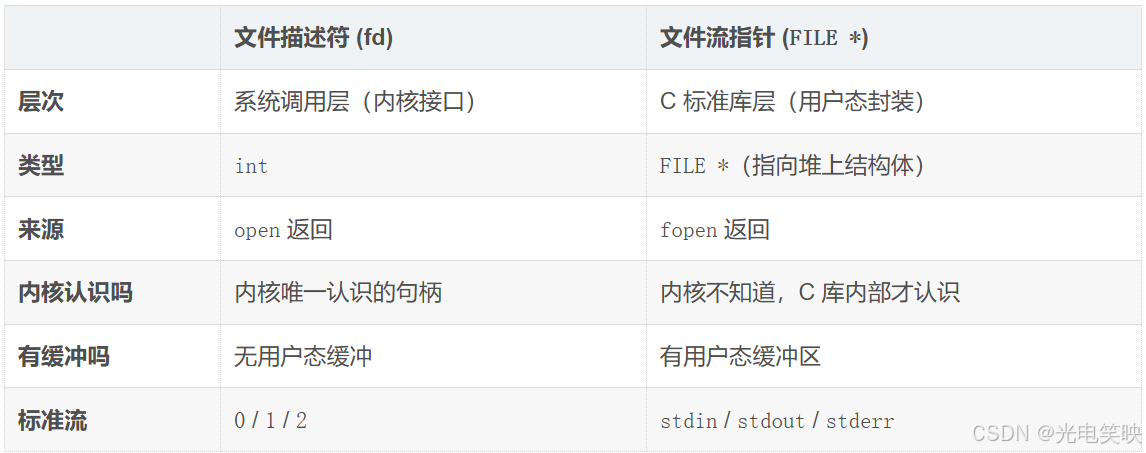
它们之间的桥梁:
cpp
FILE *fp = fopen("file.txt", "r");
int fd = fileno(fp); // 从 FILE * 获取底层 fd
int fd2 = open("file2.txt", O_RDONLY);
FILE *fp2 = fdopen(fd2, "r"); // 把 fd 包装成 FILE *在系统接口层面,os只认fd也就是文件描述符
六、fd 的极限
每个进程能打开的文件描述符数量是有上限的:超过这个上限,open 返回 -1,errno = EMFILE("Too many open files")。
bash
ulimit -n # 查看限制
xqq@ubuntu-server:~/linux/moduleIX$ ulimit -n
65535
cpp
long max = sysconf(_SC_OPEN_MAX); // 程序运行时获取七、fd 的生命周期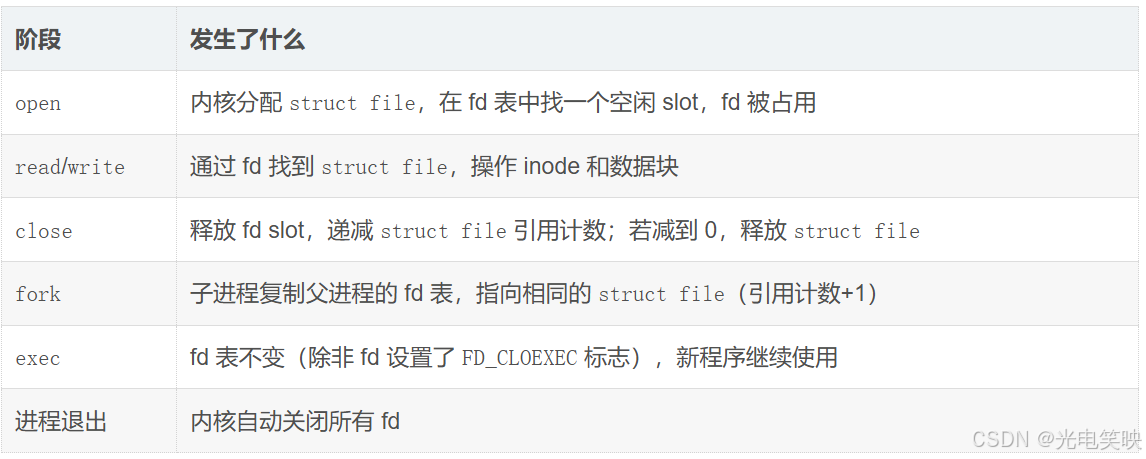
八、总结
文件描述符是进程和文件之间的"把手"------进程拿着这个整数,内核就能找到对应的
struct file和 inode,从而完成读写操作。它是 Linux 实现"一切皆文件"的基石:键盘、屏幕、普通文件、管道、socket,在进程眼里都只是一个 fd 编号,操作方式全都是read/write/close。
3.6 文件生命周期:打开、读写、关闭
从"先描述,再组织"视角看文件操作的完整生命周期
一、打开文件:open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644)
1. 内核层:先描述------创建 struct file 对象
内核首先在内存中分配一个全新的 struct file 结构体,用来描述这次打开的文件:
cpp
struct file {
文件偏移量 = 0 //刚打开,从头开始
打开模式 = O_WRONLY //只写
引用计数 = 1 //被一个进程引用
*f_inode //inode (磁盘上的 log.txt)
*f_op //文件操作函数集 (write, read, lseek...)
f_list → {next, prev} //预留链表节点,准备挂入全局链表
};同时,内核在磁盘上找到或创建 log.txt 对应的 inode。
2. 内核层:再组织------挂入全局链表
这个 struct file 被插入到内核维护的全局打开文件双向链表中
3. 进程层:再组织------挂入进程的 fd 数组
内核在调用进程的 files_struct 的 fd[] 数组中,找到最小的空闲 slot(槽位,就是数组一个下标位置),假设是 3,把这个 struct file * 指针填入:
cpp
进程 A 的 fd 数组:
fd[0] → struct file (标准输入)
fd[1] → struct file (标准输出)
fd[2] → struct file (标准错误)
fd[3] → struct file (log.txt) ← 新插入
fd[4] → NULL
...两种管理的区别:
4. 返回给用户
open 返回 3(就是数组下标)。进程拿到这个整数 fd=3。
此时的状态:同一个 struct file 对象,既挂在全局内核链表里,又挂在进程 A 的 fd3 上。
二、写文件:write(3, "hello", 5)
1. 进程层:通过 fd 找到 struct file
内核根据 fd=3,在当前进程的 files_struct->fd[3] 中取出 struct file * 指针。O(1) 查找。
2. 内核层:操作 struct file
内核读取 struct file 中的信息:
cpp
struct file {
文件偏移量 = 0 ← 当前写到哪里
打开模式 = O_WRONLY ← 检查是否有写权限
*f_op → write(...) ← 调用文件系统提供的 write 函数
}3. 更新 struct file 的状态
写入完成后,struct file 中的文件偏移量被更新:
cpp
struct file {
文件偏移量 = 5 ← 从 0 变成了 5,下次写入从第 5 字节开始
引用计数 = 1 ← 不变
...
}4. 数据落盘
-
文件系统根据 inode 中的数据块指针,找到磁盘上的空闲块
-
将 "hello" 5 个字节写入数据块
-
更新 inode 中的文件大小(Size 从 0 变成 5)
此时的状态:struct file 的偏移量变了,inode 的 Size 变了,磁盘数据块有了内容。但 struct file 仍然同时挂在全局链表和进程 fd3 上。
三、读文件:read(3, buf, 1024)
(接"写文件"之后,struct file 中的偏移量已经在写入时从 0 变成了 5)
1. 进程层:通过 fd 找到 struct file
内核根据 fd=3,在当前进程的 files_struct->fd[3] 中取出 struct file * 指针。O(1) 查找,和 write 完全一样的入口。
2. 内核层:检查权限,调用读函数
内核读取 struct file 中的信息:
cpp
struct file {
文件偏移量 = 5 ← 当前读位置(上次写完后偏移量停在这里)
打开模式 = O_RDONLY ← 检查是否有读权限
*f_op → read(...) ← 调用文件系统提供的 read 函数
*f_inode ─────────────→ inode
}如果文件是以 O_WRONLY(只写)方式打开的,read 会直接返回 -1,errno = EBADF("Bad file descriptor"------fd 有效,但没有读权限)。
3. 内核层:从磁盘读取数据到内核缓冲区
- 文件系统根据 inode 中的数据块指针,计算偏移量 5 对应哪个磁盘块
- 当前偏移量是 5,文件大小也是 5,说明已经读到文件末尾了。
4. 返回值:返回 0 表示 EOF
- 偏移量 5 >= Size 5 → 没有数据可读 → read 返回 0(EOF)
如果偏移量 < 文件大小(比如偏移量是 2),read 会从偏移量 2 开始读,读到数据后更新偏移量,返回实际读取的字节数。
5. 更新 struct file 的状态
如果读到了数据(返回值 > 0):
cpp
struct file {
文件偏移量 = 旧偏移量 + 实际读取字节数
...
};如果返回 0(EOF),偏移量保持不变。
6. 回到用户态
read 返回实际读取的字节数(或 0 表示 EOF,或 -1 表示出错),数据被复制到用户提供的 buf 中。
总结:read 和 write 本质都是拷贝函数,方向相反:read 把数据从内核 page cache 拷贝到用户 buf,write 把数据从用户 buf 拷贝到内核 page cache。磁盘和 page cache 之间的搬运由内核自动完成。struct file 不存数据,它只记录"当前读到/写到文件的哪个位置"。
四、关闭文件:close(3)
1. 进程层:从 fd 数组中移除
内核把 files_struct->fd[3] 置为 NULL,slot 3 重新变为空闲。
2. 内核层:递减引用计数
cpp
struct file {
文件偏移量 = 5
打开模式 = O_WRONLY
引用计数 = 1 → 0 ← 减 1
...
};3. 引用计数归零 → 从全局链表摘除
当 struct file 的引用计数变为 0 时,说明没有任何进程还在使用这个文件对象了。内核把它从全局双向链表中摘除
4. 释放 struct file 内存,更新 inode
-
释放
struct file占用的内存 -
更新 inode 中的时间戳(如修改时间)
-
inode 本身依然在磁盘上,等待下一次被打开
3.7 stdin、stdout 与 stderr ------ 标准流的分离与重定向
一、为什么已经有 stdout,还要有 stderr?
进程默认打开的三个标准流: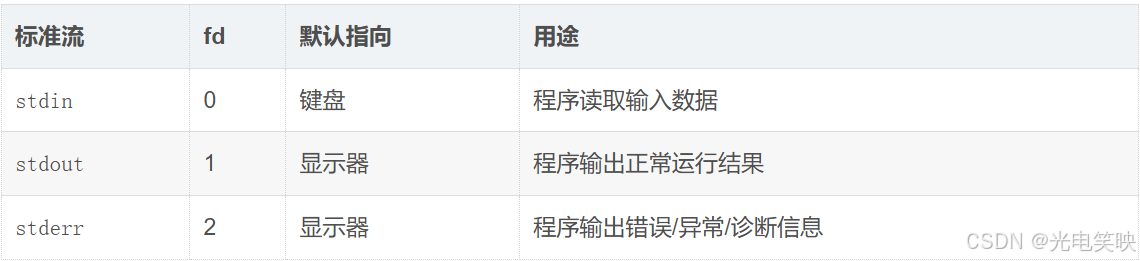
如果 stdout 和 stderr 都指向显示器,为什么需要两个?
答案:为了能分开重定向。 正常输出和错误信息混在一起时,无法单独提取错误日志。把它们设计成两个独立的 fd(1 和 2),就能通过重定向将它们分离------正常结果进一个文件,错误信息进另一个文件,或者只把错误显示在屏幕上。
二、验证实验:重定向只影响 stdout
cpp
// stream.cc
#include <cstdio>
#include <iostream>
int main()
{
// 向标准输出打印,stdout/cout → fd=1
std::cout << "C++ cout" << std::endl;
printf("C stdout\n");
// 向标准错误打印,stderr/cerr → fd=2
std::cerr << "C++ cerr" << std::endl;
fprintf(stderr, "C stderr\n");
return 0;
}正常运行(全部输出到屏幕):
bash
xqq@ubuntu-server:~/linux/moduleIX/teststderr$ ./a.out
C++ cout
C stdout
C++ cerr
C stderr重定向 stdout(> 等价于 1>):
bash
xqq@ubuntu-server:~/linux/moduleIX/teststderr$ ./a.out > log.txt
C++ cerr
C stderr#标准错误还打印到显示器
xqq@ubuntu-server:~/linux/moduleIX/teststderr$ cat log.txt
C++ cout
C stdout我们发现只有标准输出重定向到文件
三、本质解释
> 重定向只把新文件的 struct file * 覆盖到了 fd1(stdout)这个槽位,fd2(stderr)不动。
bash
重定向前:
fd[1] → 显示器
fd[2] → 显示器
执行 ./a.out > log.txt(等价于 dup2(fd_log, 1)):
fd[1] → log.txt ← 被替换
fd[2] → 显示器 ← 没动这就是为什么 printf/cout 进了文件,而 fprintf(stderr, ...)/cerr 还留在屏幕。
四、重定向的完整写法
五、分离 stdout 和 stderr(核心用途)
bash
./a.out 1>normal.txt 2>err.txt
这就是 stderr 存在的根本意义:把正常日志和错误日志分开,方便诊断问题。
六、合并 stdout 和 stderr 到同一个文件
方式一:各自重定向(注意用 >> 追加,避免覆盖)
bash
./a.out 1> log.txt 2>> log.txt注意:stderr 必须用 >>(追加),如果用 > 会覆盖 stdout 刚才写入的内容。
方式二:2>&1(推荐)
bash
./a.out > log.txt 2>&12>&1 的含义:把 fd2 指向 fd1 当前指向的文件。本质就是 dup2(1, 2),让 fd2 的指针和 fd1 指向同一个 struct file。
七、注意事项
stdout 和 stderr 是两条独立的通道。重定向只动你指定的那条,另一条纹丝不动。这正是它们分离设计的精妙所在------正常输出和错误信息互不干扰,方便日志分离和问题诊断。