1、Pushgateway组件介绍
Pushgateway是Prometheus监控系统中的一个重要组件,它采用被动push的方式获取数据,由应用主动将数据推送到pushgateway,然后Prometheus再从Pushgateway抓取数据。Pushgateway可以单独运行在任何节点上,并不一定要运行在被监控的客户端上。
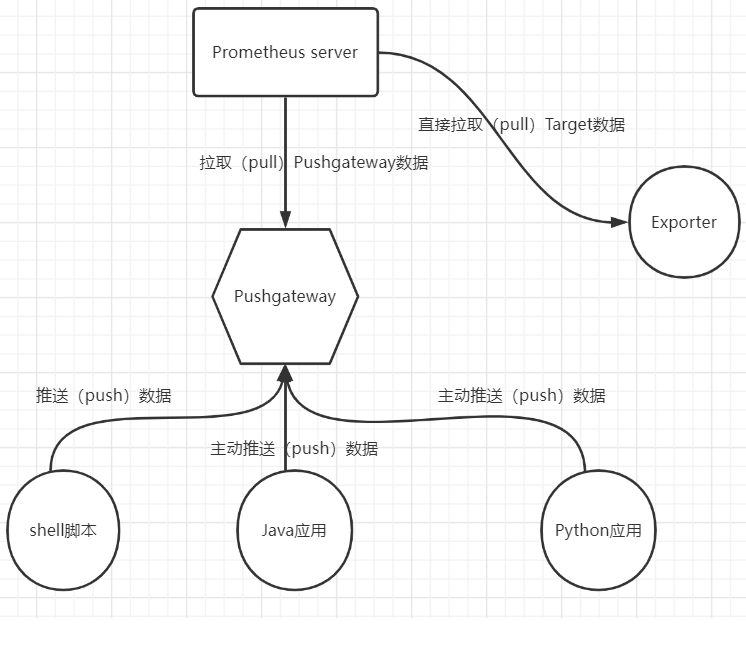
在某些特殊场景下,我们可以通过自定义编写脚本,把需要监控的数据push到pushgateway,然后Prometheus再从pushgateway拉取数据,最终实现数据汇总。
使用Pushgateway的场景:
- Prometheus和target由于某些原因网络不能互通,导致 Prometheus 无法直接拉取各个 target 数据,此时,需要经由Pushgateway做中转代理。
- 某些作业生命周期较短、批量任务等,没有足够的时间等待Prometheus抓取数据。所以可以先把数据推送到Pushgateway暂存,再让Prometheus来抓取。
- 将多个节点数据汇总到 pushgateway, 如果pushgateway挂了,多个监控节点会受到影响。
- 通过单个 Pushgateway监控多个实例时, Pushgateway将会成为单点故障和潜在瓶颈。
- Pushgateway可以持久化推送给它的所有监控数据。 因此,即使你的监控已经下线,prometheus还会拉取到旧的监控数据,因此,需要手动清理pushgateway下老旧的数据。
2、pushgateway的安装和配置
从https://prometheus.io/download/#pushgateway 下载对应版本的pushgateway二进制包即可。安装过程如下:
[root@docker-server data]# tar zxvf pushgateway-1.5.1.linux-amd64.tar.gz
[root@docker-server data]# mv pushgateway-1.5.1.linux-amd64 /usr/local/pushgateway
[root@docker-server data]# cd /usr/local/pushgateway
[root@docker-server pushgateway]#./pushgateway --web.listen-address=:9091编写service脚本启动pushgateway:
[root@docker-server data]# cat /usr/lib/systemd/system/pushgateway.service
[Unit]
Description=prometheus pushgateway
After=network.target
[Service]
Type=simple
User=root
Group=root
ExecStart=/usr/local/pushgateway/pushgateway --web.listen-address=:9091
ExecStop=/usr/bin/kill -HUP $MAINPID
[Install]
WantedBy=multi-user.target启动服务:
[root@docker-server data]# systemctl daemon-reload
[root@docker-server data]# systemctl start pushgateway.service验证端口监听
ss -tulpn | grep 9091
接着,还需要配置Prometheus,在prometheus.yml文件中,增加如下内容:
- job_name: "prometheus-gateway"
honor_labels: true
static_configs:
- targets: ["192.168.38.148:9091"]然后reload配置:
[root@prometheus-server prometheus]# curl -XPOST localhost:9090/-/reload最后,浏览器访问 IP:9091 验证pushgateway页面即可。

3、pushgateway的使用
(1)、推送数据格式
要推送数据到Pushgateway中,可以通过其提供的API接口来添加,默认推送URL地址为:
http://<ip>:9091/metrics/job/<job-name>/<label-name>/<label-value>其中job-name是必填项,是job标签的值,后边可以跟任意数量的标签&标签值对,一般会添加一个instance/标签来区分指标数据来源。
在推送的数据部分,格式定义如下:
## TYPE metric_name type
metric_name{lable_name="label_value",...} value例如,推送一个group定义为{job="some_job"}的数据:
echo "some_metric 3.14" | curl --data-binary @- http://192.168.38.148:9091/metrics/job/some_job- some_metric 3.14: 推送的键和值。
- job/some_job:相当于指定job_name为
job=some_job,多个标签直接往后添加即可。 - data-binary:以二进制数据格式发送post请求 。
推送到Pushgateway之后,就可以刷新Pushgateway界面,看到对应数据了,除了 some_metric外,同时还新增了 push_time_seconds 和 push_failure_time_seconds 两个指标,这两个是 PushGateway 系统自动生成的相关指标。
访问192.168.38.148:9091/metrics查看

又例如:推送一个group定义为{job="some_job",instance="some_instance"}的数据:
cat <<EOF | curl --data-binary @- http://192.168.38.148:9091/metrics/job/some_job/instance/192.168.38.148
# TYPE some_metric2 counter
some_metric2{label="val1"} 100
# TYPE another_metric gauge
# HELP another_metric Just an example.
another_metric 2398.283
EOF
重点,/metrics/job/some_job和 /metrics/job/some_job/instance/some_instance,它们都属于 some_job,但是,它们属于两个指标值,因为 instance 对二者做了区分。
注意:
Prometheus 会给每个抓取的指标附加一个 job 和 instance 的标签,job 标签来自 scrape 配置,我们这里抓取 Pushgateway 的 job 标签为 job="prometheus gateway",instance 标签的值会自动设置为抓取目标的主机和端口,所以所有从 Pushgateway 抓取的指标都会有 Pushgateway 的主机和端口作为 instance 标签,但是这可能会和你附加推送到 Pushgateway 指标上的 job 和 instance 标签冲突,这个时候 Prometheus 会将这些标签重命名为 exported_job 和 exported_instance。
但是,在抓取 Pushgateway 时,通常不希望出现这种行为。更多的时候你可能更希望保留推送到 Pushgateway 的指标的 job 和 instance 标签,这个时候我们只需要在 Pushgateway 的抓取配置中设置 honor_labels: true 即可。
(2)、复杂的数据的推送方法
如果一次性推送数据较多,可以将要推送的数据写到一个文件中,然后推送文件即可:
# 创建指标文件
cat > /data/mydata.txt <<EOF
# TYPE http_request_total counter
# HELP http_request_total get interface request count with different code.
http_request_total{code="200",interface="/v1/save"} 1398
http_request_total{code="404",interface="/v1/delete"} 1
http_request_total{code="500",interface="/v1/save"} 2
# TYPE http_request_time gauge
# HELP http_request_time get core interface http request time.
http_request_time{code="200",interface="/v1/core"} 0.201
EOF
# 推送文件
curl -XPOST --data-binary @/data/mydata.txt http://192.168.38.148:9091/metrics/job/app/instance/app-192.168.38.148(3)、编写采集脚本推送数据到Pushgateway
如果在某些特殊场景下,可以自写脚本,定时生成监控数据,然后推送到Pushgateway,例如下面脚本用来收集磁盘状态数据:
mkdir -p /app/shell
cat > /app/shell/disk_usage_metris.sh <<EOF
#!/bin/bash
hostname=\`hostname -f | cut -d '.' -f1\`
metrics=""
for line in \`df |awk 'NR>1{print \$NF "=" int(\$(NF-1))}'\`
do
disk_name=\`echo \$line|awk -F'=' '{print \$1}'\`
disk_usage=\`echo \$line|awk -F'=' '{print \$2}'\`
metrics="\$metrics\ndisk_usage{instance=\"\$hostname\",job=\"disk\",disk_name=\"\$disk_name\"} \$disk_usage"
done
echo -e "# HELP disk_usage Disk usage percentage.\n# TYPE disk_usage gauge\n\$metrics" | curl --data-binary @- http://192.168.38.148:9091/metrics/job/pushgateway/instance/\$hostname
EOF最后,将disk_usage_metris.sh脚本放到定时任务中,定期执行,例如:每1分钟推送一次数据,编辑crontab -e
chmod +x /app/shell/disk_usage_metris.sh
crontab -e
* * * * * /bin/bash /app/shell/disk_usage_metris.sh(4)、删除数据
# 删除某个instance下指标
curl -X DELETE http://192.168.38.148:9091/metrics/job/some_job/instance/192.168.38.148
# 删除整个job
curl -X DELETE http://192.168.38.148:9091/metrics/job/some_job
# 清空所有指标
curl -X PUT http://192.168.38.148:9091/api/v1/admin/wipe说明:
- 删除数据是以Group为单位的,Group由job name和URL中的label唯一标识。
- 举例中删除{job="some_job"}数据的语句并不会删除{job="some_job",instance="some_instance"}的数据。因为属于不同的Group。如需要删除{job="some_job",instance="some_instance"}下的数据,需要指定完整标签。
- 这里删除数据是指删除pushgateway中的数据,跟promethues没有关系。
要删除数据,还可以在pushgateway的web界面上完成。
(5)、PushGateway使用的注意事项
- 指标值只能是数字类型,非数字类型报错。
- 指标值支持最大长度为 16 位,超过16 位后默认置为 0
- PushGateway 推送及 Prometheus 拉取时间:设置 Prometheus 每次从 PushGateway 拉取的数据,并不是拉取周期内用户推送上来的所有数据,而是用户最后一次 Push 到 PushGateway 上的数据,所以建议设置推送时间小于或等于 Prometheus 拉取的时间,这样保证每次拉取的数据是最新 Push 上来的。
4、PushGateway 数据持久化
默认 PushGateway 不做数据持久化操作,当 PushGateway 重启或者异常挂掉,导致数据的丢失,可以通过启动时添加 -persistence.file 和 -persistence.interval 参数来持久化数据。
例如:
[root@docker-server data]# vi /usr/lib/systemd/system/pushgateway.service
[Unit]
Description=prometheus pushgateway
After=network.target
[Service]
Type=simple
User=root
Group=root
ExecStart=/usr/local/pushgateway/pushgateway --web.listen-address=:9091 --web.enable-admin-api --persistence.file=/usr/local/pushgateway/pushgateway_persist_file --persistence.interval=2m
ExecStop=/usr/bin/kill -HUP $MAINPID
[Install]
WantedBy=multi-user.target其中:
- --persistence.file:指定持久化文件路径或名称。如果没有指定存储,则监控指标仅保存在内存中,若出现pushgateway重启或意外故障,便会导致数据丢失。默认情况下,持久化文件每5分钟写一次。
- --persistence.interval:重新设置写入文件的时间间隔。
以上就是基于192.168.38.148 Prometheus环境,完整复刻Pushgateway的全部实操步骤,从安装部署、配置持久化,到指标推送、定时采集和数据删除,每一步都可直接复制执行,避开了标签冲突、数据丢失、指标异常等常见坑点。Pushgateway作为Prometheus的重要补充,完美解决了短周期任务监控、跨网络指标采集的痛点,但需注意单点故障风险和旧指标清理问题。如果在实操中遇到端口监听失败、Prometheus拉取异常、脚本执行报错等问题,欢迎在评论区留言,一起交流排查思路,也可以收藏本文,后续用到时直接查阅即可。