作者 :杨军1,∗^{1,*}1,∗,王东1^11,尹洪旭1^11,李洪鹏1^11,余建雄1^11
1^11西北工业大学自动化学院,陕西西安
通讯作者邮箱:junyang@nwpu.edu.cn
摘要
无人机检测在众多安全防护与反无人机应用中具有关键作用。然而,现有基于深度学习的方法通常难以在鲁棒特征表示与计算效率之间取得平衡。当在严重环境干扰下的复杂背景中检测微型无人机时,这一挑战尤为突出。为解决上述问题,我们提出 UAV-DETR,一种将小目标友好型架构与实时检测能力相融合的新型框架。具体而言,UAV-DETR 采用 WTConv 增强的骨干网络与滑动窗口自注意力(SWSA-IFI)编码器,在捕捉微小目标高频结构细节的同时大幅降低参数开销。此外,我们提出高效跨尺度特征重校准与融合网络(ECFRFN),以抑制背景噪声并聚合多尺度语义信息。为进一步提升检测精度,UAV-DETR 引入了 Inner-CIoU 与 NWD 混合损失策略,有效缓解标准 IoU 指标对小目标微小位置偏差的极端敏感性。大量实验表明,在自建无人机数据集上,UAV-DETR 显著优于基线 RT-DETR(mAP50:95 提升6.61%6.61\%6.61%,参数量减少39.8%39.8\%39.8%);在公开 DUT-ANTI-UAV 基准上亦取得优异表现(Precision 提升1.4%1.4\%1.4%,F1-Score 提升1.0%1.0\%1.0%)。这些结果确立了 UAV-DETR 在反无人机目标检测中效率与精度的卓越平衡。代码已开源:https://github.com/wd-sir/UAVDETR
关键词:无人机检测,反无人机,Transformer,轻量级网络,特征融合
一、引言 (INTRODUCTION)
无人机(UAV)的快速发展与广泛部署为民用和商业领域带来了显著便利。然而,无人机的滥用对公共安全、隐私保护及关键基础设施构成严重威胁1--4。因此,开发鲁棒的反无人机系统已成为关键的安全优先事项。与传统雷达5,6或射频传感器7,8相比,基于视觉的无人机检测以显著更低的部署成本提供具有竞争力的精度与可靠性9,10,并为后续跟踪、拦截及作战意图识别奠定基础。
尽管深度学习在通用目标检测领域取得成功,但由于空中目标固有的视觉特性,直接将这些算法应用于反无人机场景仍面临巨大挑战。无人机在视场中通常呈现为极小目标,且随距离变化表现出剧烈的尺度差异11。此外,真实场景中的无人机检测常受严重背景干扰影响,如厚重云层、山地地形及密集树木遮挡,使得微型目标极易与环境噪声混淆12,13。现有检测模型往往难以在高分辨率特征提取与计算效率之间实现有效平衡,而这一权衡对于资源受限的边缘部署尤为关键14。标准卷积操作在下采样过程中可能丢失微小目标关键的高频结构细节,而基于 Transformer 的重型架构则为实时应用带来难以承受的计算开销。此外,标准评估指标如交并比(IoU)对微型边界框的微小位置偏差高度敏感,严重损害训练稳定性15。
为解决上述挑战,我们提出 UAV-DETR,一种专为反无人机操作设计的高效高精度实时目标检测框架。本方法以实时检测 Transformer(RT-DETR)架构为基础,系统优化骨干网络、颈部及检测头的结构设计。具体而言:(1)在骨干网络中,我们将小波变换卷积(WTConv)集成至基础模块,构建 WTConv Block,精确保留关键高频空间细节,防止下采样过程中的信息损失;(2)颈部架构通过级联滑动窗口自注意力层内特征交互(SWSA-IFI)编码器与高效跨尺度特征重校准融合网络(ECFRFN)构建,二者协同工作以最小计算成本抑制背景噪声并聚合多尺度语义特征;(3)检测头采用 InnerCIoU 与归一化沃瑟斯坦距离(NWD)相结合的混合损失函数,显著改善微小目标的边界框回归性能。
本文主要贡献总结如下:
- 我们提出 UAV-DETR,一种新型轻量级检测框架,在大幅减少模型参数的同时显著提升复杂背景下微型无人机的检测精度。
- 我们设计了一种高效颈部架构,包含 SWSA-IFI 编码器与 ECFRFN 模块。该级联颈部设计能够高效捕获全局上下文并重校准跨尺度特征,且不会带来过高的计算负担。
- 我们通过在骨干网络基础模块中无缝集成 WTConv 构建 WTConv Block,增强高频结构细节的保留能力;并通过采用 InnerCIoU-NWD 混合损失优化检测头,缓解微小目标的位置敏感性。
- 在自建无人机数据集与公开 DUT-ANTI-UAV 基准上的大量实验表明,UAV-DETR 取得了最先进的性能,有效突破了高精度与轻量级部署之间的瓶颈。
二、相关工作 (RELATED WORK)
深度学习从根本上重塑了目标检测领域,从手工特征提取转向通过卷积神经网络(CNN)进行数据驱动的特征学习。早期里程碑由 Ren 等人奠定,其提出的 Faster R-CNN 引入区域提议网络(RPN)以生成高质量目标边界16。随后,Liu 等人提出单阶段多框检测器(SSD),首创使用多尺度特征图以实现更快的推理速度17。基于这些单阶段方法的基础,YOLO 系列持续主导实时目标检测领域。近期研究探索了采用无锚点设计与解耦头的 YOLOv818,而 Wang 等人提出的 YOLOv10 成功消除了非极大值抑制(NMS)步骤以降低延迟19。后续迭代如 YOLO11 和 YOLO12 持续优化网络拓扑与注意力机制20,21,同时出现了如 HyperYOLO 等高度定制化变体,旨在捕捉复杂的高阶特征交互关系22。为应对低空空中目标的特定挑战,研究者还提出了专用卷积模型如 PWM-YOLO 和 YOLO-GCOF,通过定制化特征提取模块提升无人机检测精度23,24。尽管标准卷积架构在各种应用中表现出卓越效率,但其本质上依赖于渐进式下采样,这一过程常导致高频结构细节的不可逆丢失,严重限制其在检测极小空中目标时的有效性。
2017 年 Vaswani 等人提出完全依赖自注意力机制的 Transformer 架构后25,该领域发生了显著的范式转变。为使该架构适配计算机视觉任务,Dosovitskiy 等人通过将图像转换为扁平化图像块序列引入了视觉 Transformer(ViT)26。在此基础上,Carion 等人提出检测 Transformer(DETR),将目标检测建模为二分匹配与直接集合预测问题27。为解决原始模型收敛缓慢的问题,Zhu 等人通过引入仅关注稀疏空间位置的可变形注意力模块开发了 Deformable DETR28。后续进展催生了如 DINO 等高度优化的架构,通过进一步优化查询去噪与对比训练实现最先进性能29。近期,Zhao 等人引入实时检测 Transformer(RT-DETR),成功弥合了注意力机制高精度与严格实时要求之间的差距30。在航拍图像领域,如 VRF-DETR 等模型展示了自注意力机制在提取通用小目标特征方面的强大适用性,表明其在微型无人机检测方面具有巨大潜力31。同样,如 OSFormer 等新方法开创性地将小目标友好型 Transformer 与单步检测范式相融合,有效抑制背景噪声并突出微小目标32。
在真实反无人机场景中,地对空视觉系统面临多方面挑战。空中目标通常表现出极端尺度变化,且在远距离捕获时往往仅占据少数像素4。这种极端微型化使其极易受复杂城市结构、密集植被或恶劣光照等严重背景干扰影响13。此外,微型无人机易与背景噪声或其他小型空中物体混淆。为克服这些固有困难并优化小目标检测,不同视觉领域已开发特定特征提取机制以保留高频细节并处理尺度变化。例如,Finder 等人提出小波卷积以高效扩大感受野33。在图像复原任务中,全核网络被引入以学习全面的从全局到局部的特征表示34。空间建模通过移位窗口自注意力机制得到进一步推进35。此外,上下文引导的空间特征重构显式提取金字塔上下文用于目标建模36,而选择性边界聚合在细化结构边界方面展现出显著前景37。最后,如 RepNCSPELAN4 等先进梯度路径被设计用于优化轻量级特征处理38。受这些专业化发展的启发,我们提出 UAV-DETR 以应对空中目标感知的复杂挑战。
三、方法 (METHODOLOGY)
3.1 整体架构
为从反无人机视角应对无人机检测的独特挑战,我们提出 UAV-DETR,一种基于实时检测 Transformer(RT-DETR)30 稳健基础构建的新型检测框架。如图 1 所示,UAV-DETR 被设计为端到端流水线,在保持实时效率的同时增强微型目标的多尺度特征表示。
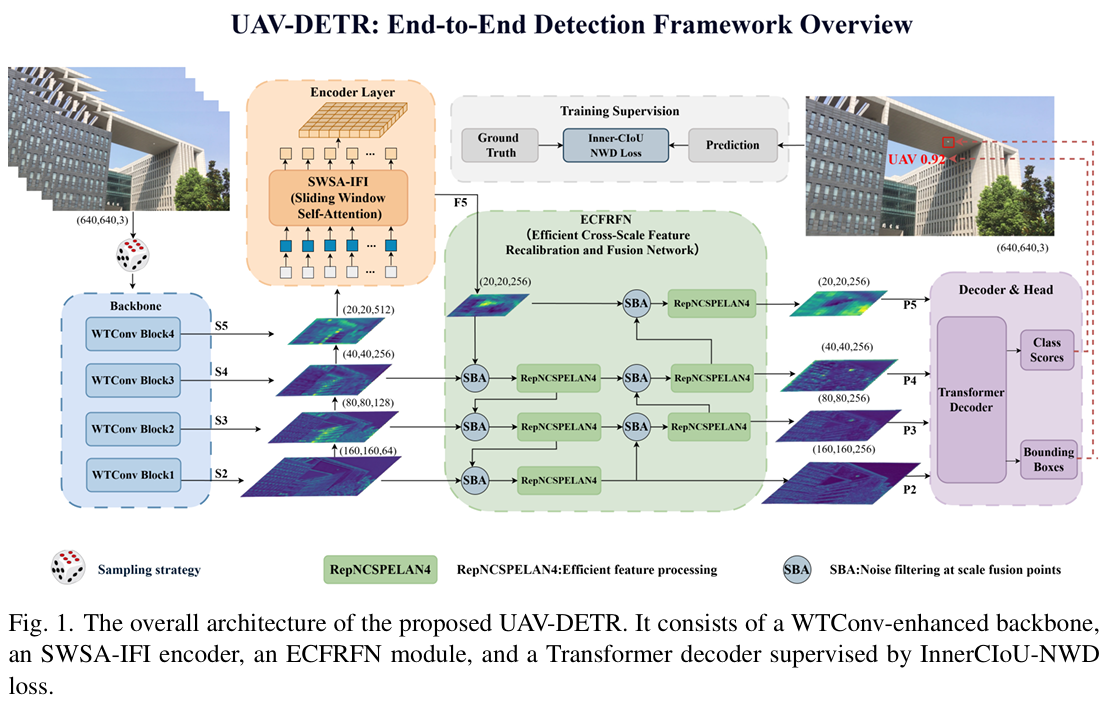
整体架构通过特征提取、尺度内编码、跨尺度融合及解码的连续序列处理输入图像。具体而言,为缓解连续视频帧间的高视觉冗余与缺乏方差问题,训练时采用随机采样策略,即每五帧中随机选择一帧。采样后的输入图像随后通过集成 WTConv Block 的分层骨干网络处理,以提取多尺度特征图(记为S2S_2S2、S3S_3S3、S4S_4S4和S5S_5S5)。最高层语义特征(S5S_5S5)随后通过包含 SWSA-IFI 模块的尺度内编码器处理,以高效捕获全局上下文。随后,生成的编码特征(F5F_5F5)与较浅层骨干特征(S2S_2S2、S3S_3S3、S4S_4S4)一同输入 ECFRFN。在该颈部架构内,选择性边界聚合(SBA)与 RepNCSPELAN4 模块协同工作以过滤背景噪声并融合不同尺度的特征,生成精炼的多尺度特征图(P2P_2P2至P5P_5P5)。最后,这些聚合特征由 Transformer 解码器处理以生成类别得分与边界框预测,训练时通过定制的 InnerCIoU-NWD 损失进行监督。
通过统一这些组件,UAV-DETR 有效平衡了视觉碎片化无人机目标的检测精度与计算速度。第 3.2 至 3.5 节将依次详细阐述 WTConv Block、SWSA-IFI、ECFRFN 及 InnerCIoU-NWD 损失的详细公式、结构机制与理论依据。
3.2 WTConv Block
在复杂环境中准确检测小型无人机需要一个能够保留细粒度细节同时捕获全局语义依赖的特征提取网络。以 ResNet-18 为代表的标准卷积神经网络(CNN)主要依赖堆叠小型3×33 \times 33×3卷积核。虽然对通用目标有效,但该范式扩展有效感受野(ERF)的速度较慢,这对于仅占据少数像素的小目标而言并非最优。因此,局部操作往往在形成有意义语义特征之前无意中放大高频背景噪声,导致误检或漏检。
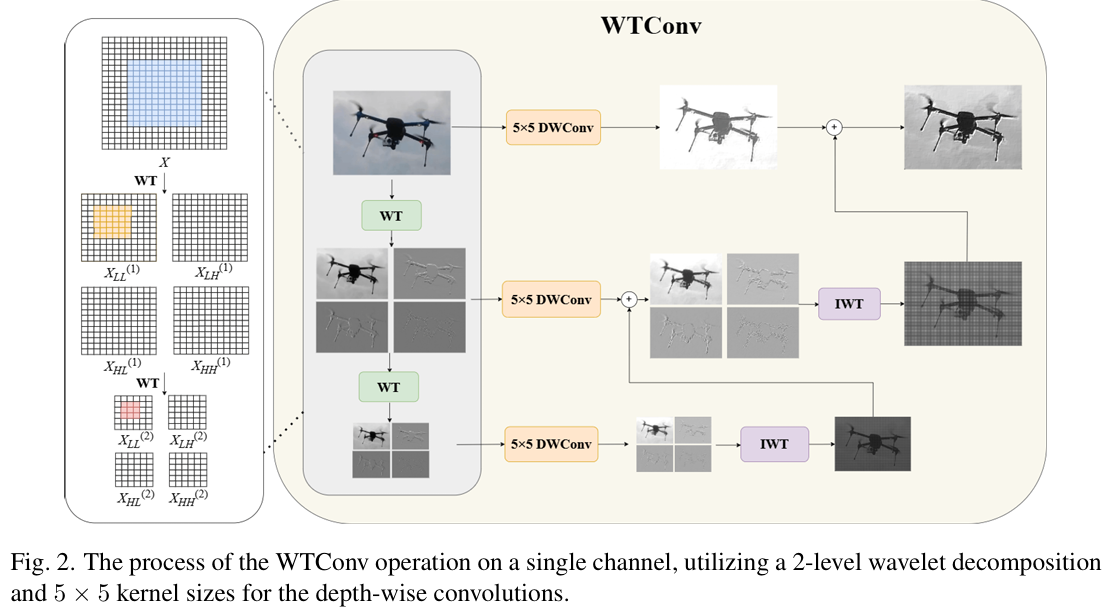
为缓解此问题,我们引入 WTConv Block 构建频率感知骨干网络。利用小波的多分辨率分析(MRA)特性,WTConv 使网络能够在快速扩展的空间范围内响应低频分量(对应目标形状)。这有效抑制高频噪声的同时增强了小型无人机的结构表示。如图 2 所示,WTConv 模块通过小波分解与频域交互的级联实现此目标。给定输入特征图XinX_{in}Xin,我们采用 2D Haar 小波变换(WT)将其递归分解为四个子带:低频近似XLLX_{LL}XLL与高频细节{XLH,XHL,XHH}\{X_{LH}, X_{HL}, X_{HH}\}{XLH,XHL,XHH},共LLL层。该级联过程生成特征金字塔,其中更深层次对应更低频率与指数级增大的感受野。为促进跨尺度交互,我们在每层iii拼接子带并应用深度卷积。该操作表述为:
Y(i)=S(i)(DWConv5×5(ConcatXLL(i),XLH(i),XHL(i),XHH(i)))(1)Y^{(i)} = S^{(i)}(\text{DWConv}_{5\times5}(\text{Concat}X_{LL}\^{(i)}, X_{LH}\^{(i)}, X_{HL}\^{(i)}, X_{HH}\^{(i)})) \quad (1)Y(i)=S(i)(DWConv5×5(ConcatXLL(i),XLH(i),XHL(i),XHH(i)))(1)
其中DWConv5×5\text{DWConv}_{5\times5}DWConv5×5表示使用5×55 \times 55×5卷积核的深度卷积以高效处理频率信息,S(i)S^{(i)}S(i)表示可学习的通道级缩放因子。卷积后,采用逆小波变换(IWT)进行递归重构。
关键在于,我们引入加性融合策略,使来自更深层次的全局结构上下文回流以指导较浅层次的特征重构。层次iii的重构定义为:
X^LL(i)=IWT(YLL(i)+X^LL(i+1),YLH(i),YHL(i),YHH(i))(2)\hat{X}{LL}^{(i)} = \text{IWT}(Y{LL}^{(i)} + \hat{X}{LL}^{(i+1)}, Y{LH}^{(i)}, Y_{HL}^{(i)}, Y_{HH}^{(i)}) \quad (2)X^LL(i)=IWT(YLL(i)+X^LL(i+1),YLH(i),YHL(i),YHH(i))(2)
其中X^LL(L+1)=0\hat{X}{LL}^{(L+1)} = 0X^LL(L+1)=0。项YLL(i)+X^LL(i+1)Y{LL}^{(i)} + \hat{X}_{LL}^{(i+1)}YLL(i)+X^LL(i+1)确保低频信息被更深层次捕获的全局上下文渐进增强。
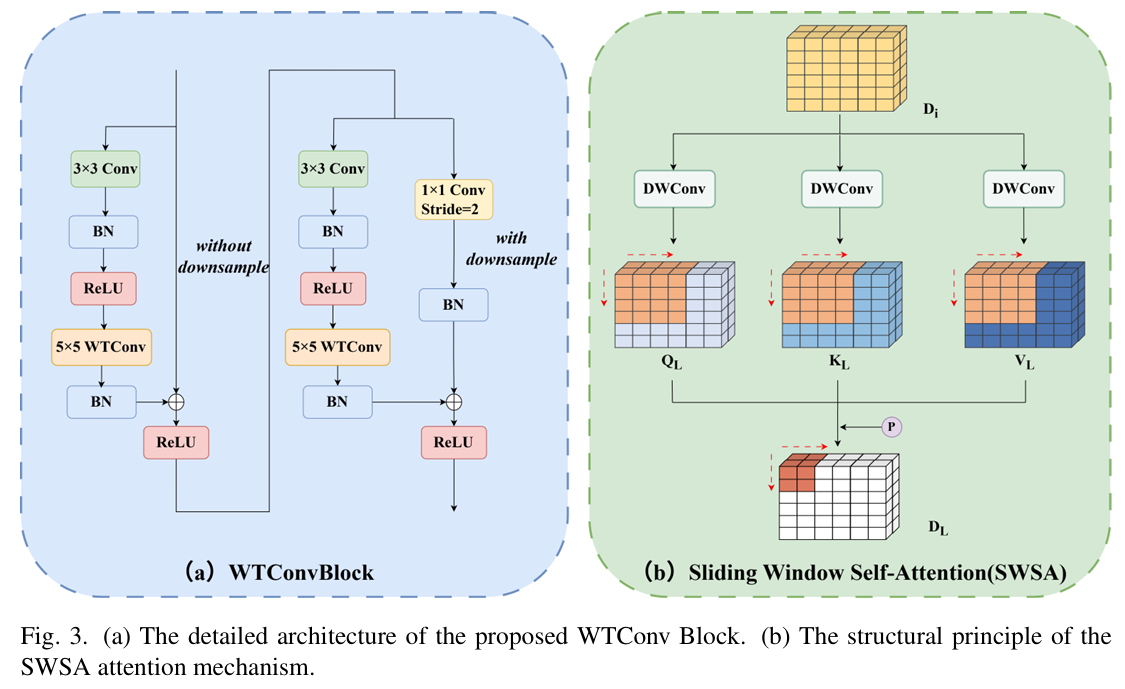
基于此机制,我们提出 WTConv Block 作为骨干网络的基本构建单元,如图 3(a) 所示。与标准残差块不同,我们将 WTConv Block 构建为由两个级联阶段组成的复合模块:语义精炼阶段(无下采样)后接空间压缩阶段(带下采样)。在每个阶段,我们修改标准 ResNet 架构,保留初始3×33 \times 33×3卷积以捕获局部纹理线索,同时用频率感知的 WTConv 模块替换后续卷积以扩展感受野。形式上,令xxx表示输入特征图。特征传播定义为两步过程。第一阶段,特征在原始分辨率下通过x′=σ(F(x)+x)x' = \sigma(F(x) + x)x′=σ(F(x)+x)进行精炼,其中σ\sigmaσ表示 ReLU 激活函数,F(⋅)F(\cdot)F(⋅)表示残差映射函数:
F(x)=BN(WTConv(σ(BN(Conv3×3(x)))))(3)F(x) = \text{BN}(\text{WTConv}(\sigma(\text{BN}(\text{Conv}_{3\times3}(x))))) \quad (3)F(x)=BN(WTConv(σ(BN(Conv3×3(x)))))(3)
随后,精炼后的中间特征x′x'x′作为下采样阶段的输入以生成最终输出yyy:
y=σ(Fs=2(x′)+BN(Conv1×1,s=2(x′)))(4)y = \sigma(F_{s=2}(x') + \text{BN}(\text{Conv}_{1\times1, s=2}(x'))) \quad (4)y=σ(Fs=2(x′)+BN(Conv1×1,s=2(x′)))(4)
其中Fs=2F_{s=2}Fs=2表示步长为 2 的残差映射,项BN(Conv1×1,s=2(x′))\text{BN}(\text{Conv}_{1\times1, s=2}(x'))BN(Conv1×1,s=2(x′))表示用于空间下采样的投影捷径。该级联设计建立了双通路机制:第一阶段优先考虑局部细节保留与背景噪声过滤,第二阶段专注于将全局结构完整性编码为紧凑表示。
3.3 特征编码与融合颈部
在 WTConv 增强骨干网络的分层特征提取之后,建立全局上下文并有效融合多尺度特征以适应无人机的极端尺度变化至关重要。为此,我们设计了一个由两个顺序组件组成的综合中间处理架构:尺度内特征编码器与跨尺度融合网络。首先,骨干网络输出的最深语义特征被处理以捕获全局依赖关系。随后,这些丰富的高层特征与较浅层高分辨率特征图聚合,构建鲁棒的多尺度表示,在此过程中有效过滤背景噪声。这两个核心组件(即 SWSA-IFI 与 ECFRFN)的具体设计详见以下小节。
3.3.1 SWSA-IFI 编码器
虽然标准 RT-DETR 利用基于注意力的尺度内特征交互(AIFI)模块在高层特征图上捕获全局语义依赖,但其在小型无人机检测方面存在局限性。小目标通常占据极少像素,而标准全局自注意力(在整个图像上计算依赖关系)常引入过多背景噪声。这种全局上下文可能掩盖小目标的弱特征表示。为缓解此问题并增强模型对局部上下文信息的关注,我们提出用滑动窗口自注意力(SWSA)机制替换 AIFI 中的标准编码器层。
SWSA 旨在将注意力计算限制在局部区域内,从而在保留细粒度细节的同时减少计算冗余。在架构上,SWSA 将 Transformer 块分解为令牌混合器(Token Mixer)与通道混合器(Channel Mixer),如图 3(b) 所示。与依赖密集线性层的标准多头注意力不同,令牌混合器通过采用1×11 \times 11×1深度卷积生成查询(QQQ)、键(KKK)和值(VVV)矩阵以促进局部特征投影。该特定卷积设计本质上作为独立每通道标量乘法运行,与标准投影相比大幅减少参数冗余。此外,注意力机制在由大小www和步长sss定义的滑动窗口内运行。通过确保w>sw > sw>s,重叠窗口促进边界间的信息流动,从而保持空间连续性。
由于自注意力机制本质上是排列不变的,因此需要显式空间先验。我们引入可学习的相对位置编码(RPE),记为PrelP_{rel}Prel。窗口内的注意力输出计算为:
Q,K,V=DWConv1×1(X)(5)Q, K, V = \text{DWConv}_{1\times1}(X) \quad (5)Q,K,V=DWConv1×1(X)(5)
Attention(Q,K,V)=Softmax(QK⊤dk+Prel)V(6)\text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^\top}{\sqrt{d_k}} + P_{rel}\right)V \quad (6)Attention(Q,K,V)=Softmax(dk QK⊤+Prel)V(6)
其中XXX表示输入特征图,dkd_kdk为缩放因子。PrelP_{rel}Prel使网络能够学习像素的空间排列,这对于区分小型无人机的结构细节至关重要。在局部聚合与残差相加之后,通道混合器促进跨通道信息交换。我们通过包含两个1×11 \times 11×1卷积层的卷积前馈网络(FFN)实现此功能。为确保训练稳定并与优化推理架构对齐,最终输出在后续残差连接与层归一化(LN)后获得,表述如下:
O′=LN(FFN(O)+O)=LN(Conv1×1(σ(Conv1×1(O)))+O)(7)O' = \text{LN}(\text{FFN}(O) + O) = \text{LN}(\text{Conv}{1\times1}(\sigma(\text{Conv}{1\times1}(O))) + O) \quad (7)O′=LN(FFN(O)+O)=LN(Conv1×1(σ(Conv1×1(O)))+O)(7)
其中σ\sigmaσ表示激活函数(如 GELU),OOO表示来自前序令牌混合器的输出。在提出的 SWSA-IFI 模块中,我们用此基于 SWSA 的架构替换标准 Transformer 编码器层。高层特征图首先由令牌混合器(包含滑动窗口与 RPE)处理,随后由卷积通道混合器处理。该设计使模型能够高效捕获空间相邻区域内的像素级关系,有效过滤背景噪声的同时突出微型无人机目标。
3.3.2 ECFRFN 模块
解决小型无人机检测中固有的尺度变化需要一个鲁棒机制来整合碎片化特征。分层特征的朴素拼接常导致语义模糊与冗余,因为深层语义图与浅层细节图具有不同分布。为解决此问题,我们提出 ECFRFN 作为检测器的融合颈部。如图 4 所示,ECFRFN 作为高级特征金字塔运行,无缝聚合高层语义与细粒度空间细节。该架构以两个战略组件为特色:用于精确特征对齐的 SBA 模块,以及在不牺牲表示深度的情况下确保计算效率的 RepNCSPELAN4 模块。
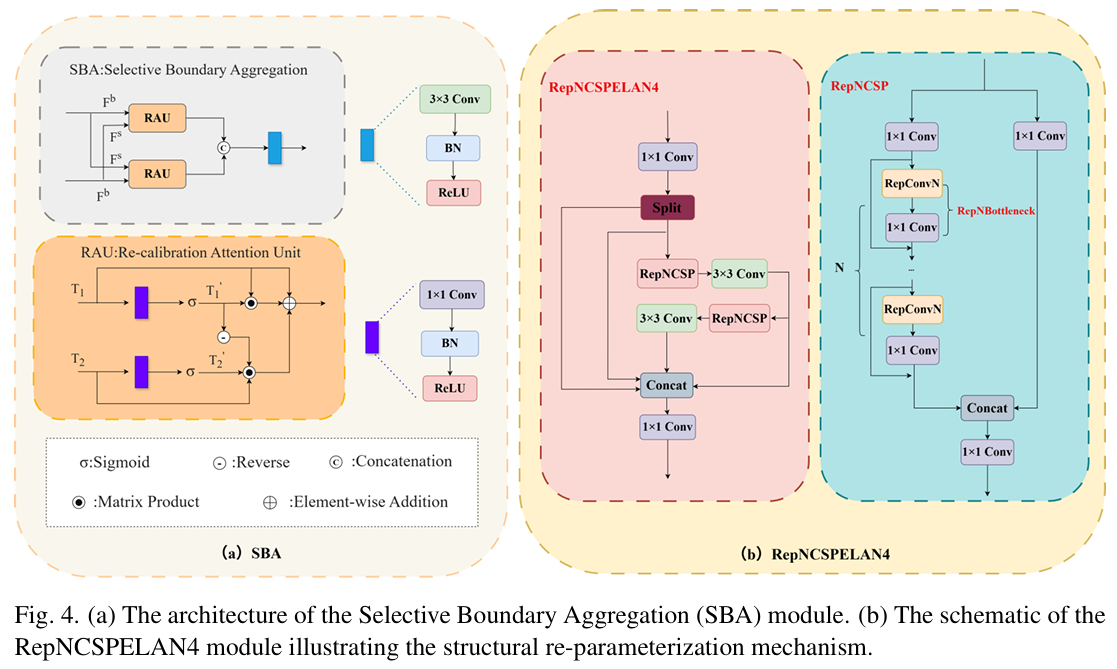
SBA 模块:传统特征融合机制通常依赖线性上采样后接逐元素相加,常因尺度间语义差距导致空间错位。这种错配对小型无人机尤为有害,因为边界模糊可能在复杂背景下导致严重检测失败。为缓解此问题,我们引入 SBA 模块以在融合前自适应重校准特征响应。如图 4(a) 所示,SBA 包含重校准注意力单元(RAU),显式建模边界划定与内部纹理间的依赖关系。通过动态加权输入特征,RAU 抑制上采样过程中的背景噪声放大,同时增强目标的结构完整性。这确保仅最具判别性的线索被传播至后续检测头。
RepNCSPELAN4 :在资源受限的边缘环境中部署的无人机检测器,平衡检测精度与实时推理速度仍是关键瓶颈。我们通过用提出的 RepNCSPELAN4 模块替换特征聚合路径中的标准卷积块来解决此限制。如图 4(b) 所示,该架构协同了跨阶段部分网络固有的高效梯度流与 ELAN 的鲁棒层聚合能力。关键在于,我们在瓶颈层引入结构重参数化。该范式有效解耦训练与推理架构:优化期间,模块利用多分支拓扑捕获多样特征表示;而部署时,这些组成分支被代数融合为单个3×33 \times 33×3卷积。因此,该设计在保持丰富梯度流的同时大幅减少总参数量与浮点运算量,使 ECFRFN 高度优化以适应延迟敏感的硬件执行。
3.4 InnerCIoU-NWD 混合损失
在无人机检测背景下,目标通常以微小尺度与复杂背景为特征。传统损失函数如 GIoU 严重依赖预测框与真实框之间的几何重叠。然而,对小目标而言,该方法存在明显局限:对位置偏差高度敏感(少数像素的偏移导致 IoU 急剧下降),且当预测框被真实框包含时收敛缓慢。
为解决这些挑战,我们提出融合 NWD 与 Inner-CIoU 的混合损失函数。由于小目标常缺乏足够外观信息,纯几何重叠不足。我们采用 NWD 指标将边界框建模为 2D 高斯分布而非刚性矩形。对于边界框B=(cx,cy,w,h)B = (c_x, c_y, w, h)B=(cx,cy,w,h),建模为N(μ,Σ)\mathcal{N}(\mu, \Sigma)N(μ,Σ),预测AAA与真实BBB之间的相似度通过沃瑟斯坦距离度量:
W22(NA,NB)=∥μA−μB∥22+∥ΣA1/2−ΣB1/2∥F2(8)W_2^2(\mathcal{N}_A, \mathcal{N}_B) = \|\mu_A - \mu_B\|_2^2 + \|\Sigma_A^{1/2} - \Sigma_B^{1/2}\|_F^2 \quad (8)W22(NA,NB)=∥μA−μB∥22+∥ΣA1/2−ΣB1/2∥F2(8)
相应地,NWD 损失表述为:
LNWD=1−exp(−W22(NA,NB)C)(9)L_{NWD} = 1 - \exp\left(-\frac{\sqrt{W_2^2(\mathcal{N}_A, \mathcal{N}_B)}}{C}\right) \quad (9)LNWD=1−exp(−CW22(NA,NB) )(9)
其中CCC为数据集特定常数。NWD 的概率特性确保即使非重叠框也能产生非零梯度,为微小目标提供连续学习信号。
虽然 NWD 确保鲁棒性,但高精度定位需要进一步优化。为此,我们用 Inner-CIoU 替换标准 CIoU,后者采用缩放因子为rrr的辅助边界框。对于给定边界框B=(cx,cy,w,h)B = (c_x, c_y, w, h)B=(cx,cy,w,h),通过缩放其宽高同时保持中心坐标生成辅助内框Binner=(cx,cy,r⋅w,r⋅h)B_{inner} = (c_x, c_y, r \cdot w, r \cdot h)Binner=(cx,cy,r⋅w,r⋅h)。为构建优化目标,我们基于标准 CIoU 指标。基础几何重叠(IoU)与综合 CIoU 损失逻辑表述为:
IoU=∥Bp∩Bgt∥∥Bp∪Bgt∥(10)\text{IoU} = \frac{\|B_p \cap B_{gt}\|}{\|B_p \cup B_{gt}\|} \quad (10)IoU=∥Bp∪Bgt∥∥Bp∩Bgt∥(10)
LCIoU(Bp,Bgt)=1−IoU+ρ2(bp,bgt)c2+αv(11)L_{CIoU}(B_p, B_{gt}) = 1 - \text{IoU} + \frac{\rho^2(b_p, b_{gt})}{c^2} + \alpha v \quad (11)LCIoU(Bp,Bgt)=1−IoU+c2ρ2(bp,bgt)+αv(11)
其中BpB_pBp与BgtB_{gt}Bgt分别表示预测框与真实框。项ρ(⋅)\rho(\cdot)ρ(⋅)表示其中心点bpb_pbp与bgtb_{gt}bgt之间的欧氏距离,ccc为最小包围框的对角线长度。参数v=4π2(arctanwgthgt−arctanwphp)2v = \frac{4}{\pi^2}\left(\arctan\frac{w_{gt}}{h_{gt}} - \arctan\frac{w_p}{h_p}\right)^2v=π24(arctanhgtwgt−arctanhpwp)2度量长宽比一致性,α=v(1−IoU)+v\alpha = \frac{v}{(1-\text{IoU})+v}α=(1−IoU)+vv为动态权衡权重。
通过将此综合几何约束严格应用于局部内区域,Inner-CIoU 在高 IoU 场景中放大有效梯度,从而加速收敛。具体损失通过将缩放框代入式(11)构建,定义为式(12)。最后,为平衡鲁棒性与精度,总边界框回归损失LboxL_{box}Lbox通过整合两个组件构建如式(13):
LInner−CIoU=LCIoU(Bp,inner,Bgt,inner)(12)L_{Inner-CIoU} = L_{CIoU}(B_{p,inner}, B_{gt,inner}) \quad (12)LInner−CIoU=LCIoU(Bp,inner,Bgt,inner)(12)
Lbox=λ⋅LInner−CIoU+(1−λ)⋅LNWD(13)L_{box} = \lambda \cdot L_{Inner-CIoU} + (1-\lambda) \cdot L_{NWD} \quad (13)Lbox=λ⋅LInner−CIoU+(1−λ)⋅LNWD(13)
其中λ\lambdaλ为调节其相对贡献的超参数。与基线相比,该组合策略显著提升小型无人机的检测性能。
3.5 伪代码
算法 1 系统详述了所提 UAV-DETR 的算法实现。该端到端优化流水线涵盖四个关键过程:
算法 1:UAV-DETR 训练方案
输入 :输入图像III,真实标签BgtB_{gt}Bgt, CgtC_{gt}Cgt
输出 :优化后的网络参数Θ\ThetaΘ
- 步骤 1:频率感知特征提取
- 初始化骨干特征F=∅F = \emptysetF=∅, x←Ix \leftarrow Ix←I
- for i∈{2,3,4,5}i \in \{2, 3, 4, 5\}i∈{2,3,4,5} do
- x←WTConv Blocki(x)x \leftarrow \text{WTConv Block}_i(x)x←WTConv Blocki(x) ▷ 提取多尺度特征
- F←F∪{Fi}F \leftarrow F \cup \{F_i\}F←F∪{Fi} ▷ 保存步长2i2^i2i处的特征图FiF_iFi
- end for
- 步骤 2:全局上下文增强
- F5′←SWSA-IFI(F5)F'_5 \leftarrow \text{SWSA-IFI}(F_5)F5′←SWSA-IFI(F5) ▷ 滑动窗口自注意力
- 步骤 3:跨尺度重校准与融合
- P5←RepNCSPELAN4(SBA(F5′))P_5 \leftarrow \text{RepNCSPELAN4}(\text{SBA}(F'_5))P5←RepNCSPELAN4(SBA(F5′))
- for i∈{4,3,2}i \in \{4, 3, 2\}i∈{4,3,2} do ▷ 自顶向下路径
- Faligned←SBA(Upsample(Pi+1),Fi)F_{aligned} \leftarrow \text{SBA}(\text{Upsample}(P_{i+1}), F_i)Faligned←SBA(Upsample(Pi+1),Fi) ▷ 选择性边界聚合
- Pi←RepNCSPELAN4(Faligned)P_i \leftarrow \text{RepNCSPELAN4}(F_{aligned})Pi←RepNCSPELAN4(Faligned) ▷ 高效特征处理
- end for
- 步骤 4:预测与混合优化
- Hfeat←TransformerDecoder({P2,...,P5})H_{feat} \leftarrow \text{TransformerDecoder}(\{P_2, \dots, P_5\})Hfeat←TransformerDecoder({P2,...,P5})
- Bpred,Cpred←DetectionHeads(Hfeat)B_{pred}, C_{pred} \leftarrow \text{DetectionHeads}(H_{feat})Bpred,Cpred←DetectionHeads(Hfeat)
- Lreg←α⋅InnerCIoU+(1−α)⋅NWDL_{reg} \leftarrow \alpha \cdot \text{InnerCIoU} + (1-\alpha) \cdot \text{NWD}Lreg←α⋅InnerCIoU+(1−α)⋅NWD ▷ 混合几何与分布损失
- 通过反向传播更新Θ\ThetaΘ:Lcls+LregL_{cls} + L_{reg}Lcls+Lreg
- return Θ\ThetaΘ
频率感知特征提取:过程始于使用由 WTConv Block 构建的骨干网络提取多尺度表示。这涉及将输入特征分解为频率子带以分别处理结构形状与高频细节。频率感知机制对于保留小型无人机的细粒度完整性同时有效抑制背景噪声干扰至关重要。
全局上下文增强:最深特征图随后由 SWSA-IFI 编码器处理以捕获长程依赖关系。这涉及将特征划分为窗口以聚合全局语义上下文。所提出的注意力机制对于丰富小目标的特征表示、促进其在复杂杂乱环境中的区分至关重要。
跨尺度重校准与融合:为缓解不同尺度间的语义差距,对提取的分层特征应用 ECFRFN。此过程结合用于精确特征对齐的 SBA 与用于轻量级处理的 RepNCSPELAN4。该配置允许有效特征校准,在不牺牲检测精度的情况下优化计算效率。
预测与混合优化:利用校准后的特征金字塔,采用 Transformer 解码器生成最终目标预测。此阶段引入结合 Inner-CIoU 与 NWD 的混合损失函数进行联合优化。混合策略对于确保对微小目标的敏感性及在训练过程中提供精确几何定位至关重要。
四、实验 (EXPERIMENTS)
4.1 数据集准备
近年来,为推进基于视觉的检测,已引入多个反无人机数据集,包括 DUT Anti-UAV 数据集9、TIB 数据集11、UAVSwarm 数据集39及 DroneMMset。然而,这些公开数据集通常强调特定且孤立的挑战。例如,UAVSwarm 数据集主要关注无人机群内的多目标跟踪,而 TIB 数据集专为极小空中目标定制。类似地,DUT 数据集强调多场景变化,而 DroneMMset 主要处理严重光照变化。虽然有价值,但仅依赖这些专用数据集可能无法完全反映真实反无人机操作的复合复杂性。

因此,为严格评估所提方法在复合环境挑战下的鲁棒性与通用性,我们构建了一个综合无人机检测数据集。如图 5 所示,该数据集涵盖广泛的环境可变性,包含多样背景杂乱(如城市天际线与植被)以及变化的光照、天气条件,以及具有剧烈尺度变化的单/多无人机场景。数据来源为现有开源档案与自采真实影像的混合集成。关键在于,为解决视频数据固有的高时间冗余问题(相邻帧呈现过度视觉相似性,消耗训练资源而无信息增益),我们实施了时间子采样策略。具体而言,对于每五个相邻帧序列,随机提取一帧代表性图像以保持特征多样性同时减少计算开销。经过严格清洗与子采样后,最终精选数据集共包含 14,713 张图像。最后,按照 7:2:1 比例将精选数据集随机划分为训练集、验证集与测试集,以确保公平全面的性能评估。
4.2 实现细节与实验设置
为确保公平一致的评估,所有实验在统一硬件与软件平台上进行。深度学习模型使用 PyTorch 框架实现,并在配备 NVIDIA RTX 3090 GPU 的高性能服务器上执行。具体硬件与软件配置详见表 1。
在模型选择方面,我们采用 11 个代表性最先进基线与所提 UAV-DETR 进行基准对比。根本上,我们的网络作为通用数据驱动检测框架运行,自主学习鲁棒目标特征,确保与通用检测器的直接性能对比具有高度相关性与方法学合理性。此外,为保证严格公平的定量评估,这些基线模型基于可比参数量与计算复杂度(FLOPs)精心选择。综合选择包括:
- 基于 CNN 的架构:经典两阶段 Faster R-CNN 与单阶段 SSD(均配备标准 ResNet-50 骨干),以及最先进的 YOLO 系列(YOLOv8m、YOLOv10m、YOLO11m、YOLO12m)与改进 YOLO 变体 Hyper-YOLOm。
- 基于 Transformer 的架构:标准 DETR 与 Deformable DETR(均使用 ResNet-50 骨干),配置轻量级 ResNet-18 骨干的基线 RT-DETR,以及近期 VRF-DETR。
所有模型训练 100 个周期以平衡收敛速度与计算资源利用。为严格评估架构本身的特征提取能力(而非从 COCO 等大规模数据集迁移学习的益处),主要实验协议涉及从头训练所有模型(即不加载预训练权重)。然而,经验观察表明某些早期架构(特别是 Faster R-CNN、SSD、DETR 与 Deformable DETR)在此特定数据集上从头训练时表现出显著收敛困难与次优性能。为解决此问题并建立竞争性基线,我们对这四个模型进行了使用预训练权重初始化的单独实验,以下标PT_{PT}PT表示(如 Faster R-CNNPT_{PT}PT、DETRPT_{PT}PT)。
4.3 评估指标
为对所提 UAV-DETR 进行全面定量分析,我们采用涵盖检测精度与计算效率的多维评估协议。为清晰标示各指标的优化方向,我们使用(↑)(\uparrow)(↑)表示越高越好,(↓)(\downarrow)(↓)表示越低越好。
检测性能指标 :遵循 COCO 与 PASCAL VOC 等标准基准,我们使用精确率(PPP, ↑\uparrow↑)、召回率(RRR, ↑\uparrow↑)与 F1 分数(F1F1F1, ↑\uparrow↑)评估基本分类与定位能力。定义如下:
P=TPTP+FP,R=TPTP+FN,F1=2×P×RP+R(14)P = \frac{TP}{TP + FP}, \quad R = \frac{TP}{TP + FN}, \quad F1 = \frac{2 \times P \times R}{P + R} \quad (14)P=TP+FPTP,R=TP+FNTP,F1=P+R2×P×R(14)
其中TPTPTP、FPFPFP与FNFNFN分别表示真正例、假正例与假反例。
为进一步评估检测器在不同重叠阈值下的鲁棒性,我们采用平均精度(mAP, ↑\uparrow↑),表示在所有类别上平均的精确率 - 召回率曲线下面积。我们报告三个特定 mAP 变体:
- mAP50 (↑)(\uparrow)(↑):在单一交并比(IoU)阈值 0.5 下计算的 mAP。该指标主要反映模型粗略定位目标的能力。
- mAP75 (↑)(\uparrow)(↑):在更严格 IoU 阈值 0.75 下的 mAP,要求更高定位精度。
- mAP50:95 (↑)(\uparrow)(↑):在 10 个从 0.5 到 0.95、步长 0.05 的 IoU 阈值上平均的 mAP。这是最严格的指标,对于小型无人机检测尤为关键,因为目标像素面积极小使得高 IoU 匹配极具挑战性。
计算效率指标:除检测精度外,鉴于在资源受限硬件(典型如边缘计算设备)上部署无人机检测器的约束,评估模型的轻量级特性至关重要。为此,我们纳入两个关键效率指标:
- 参数量 (Params, ↓\downarrow↓):以百万(M)为单位,量化模型的空间复杂度与存储需求。
- 浮点运算量 (FLOPs, ↓\downarrow↓):以千兆浮点运算(G)为单位,评估推理时的时间复杂度与计算成本。
最终,Params 与 FLOPs 的最小值(↓)(\downarrow)(↓)结合最大化的 mAP 分数(↑)(\uparrow)(↑),证明了所提方法在检测精度与部署效率之间实现最优权衡的优越性。
4.4 实验结果
为实证验证所提方法的有效性,我们在构建的无人机数据集上对 11 个最先进检测器进行了对比分析。所有模型均按照第 4.2 节描述的相同训练协议在测试集上评估。
4.4.1 定性分析
图 6 中 F1-置信度曲线与精确率 - 召回率曲线的视觉对比提供了模型鲁棒性的直观评估。如 F1-置信度指标所示,所提 UAV-DETR(粗红线表示)在宽置信度阈值范围内保持一致的高 F1 分数,相比 RT-DETR 与 YOLO12m 等竞争模型展现出更宽的平稳区域。值得注意的是,虽然严重依赖预训练权重的模型(如 DETRPT_{PT}PT与 Faster R-CNNPT_{PT}PT)在极高置信度水平下似乎保持更高 F1 分数,但此现象完全归因于从大规模预训练数据集获得的通用先验知识。关键在于,在更实用的广泛中等置信度范围内,UAV-DETR 显著优于这些预训练模型,展现出卓越鲁棒性。
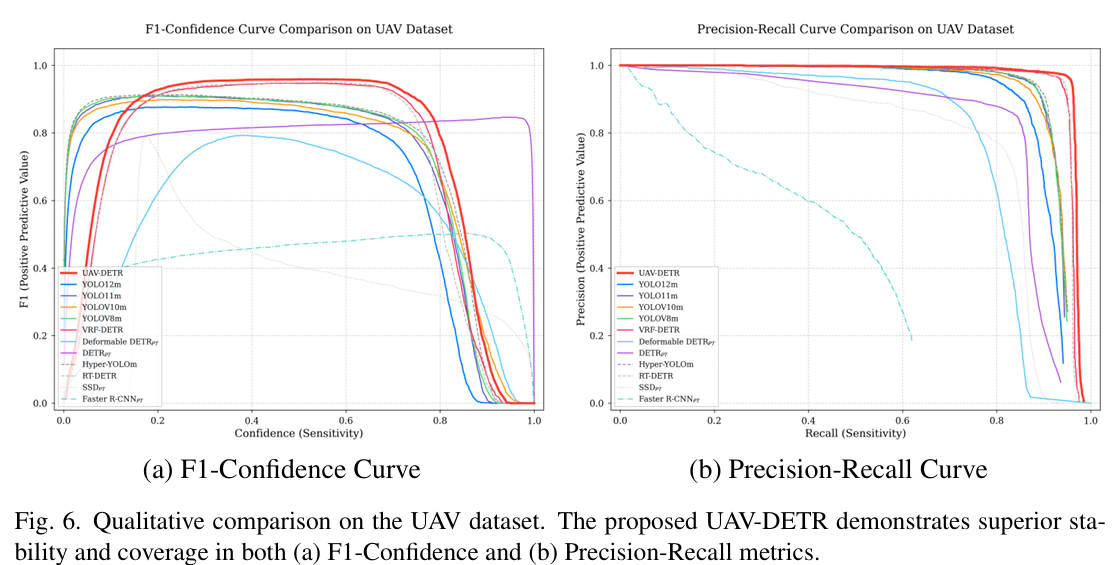
类似地,精确率 - 召回率曲线表明我们的方法涵盖最大曲线下面积。虽然带PT_{PT}PT下标的模型依赖预训练才能获得有意义的检测结果(且常在没有预训练时无法有效收敛),但 UAV-DETR 完全从头训练。尽管此严格且完全公平的设定,我们的模型不仅避免了标准 Transformer 检测器在没有先验权重时训练的典型收敛失败,还在高召回区域保持优越精度。在此区域,早期方法遭受严重召回截断,而现代检测器经历精度急剧下降。此特性表明,我们的频率感知骨干与混合损失策略有效抑制复杂背景中的误报。最终,这证明 UAV-DETR 的性能增益源于优越的架构设计与领域特定归纳偏置,而非依赖海量通用数据。
4.4.2 定量分析
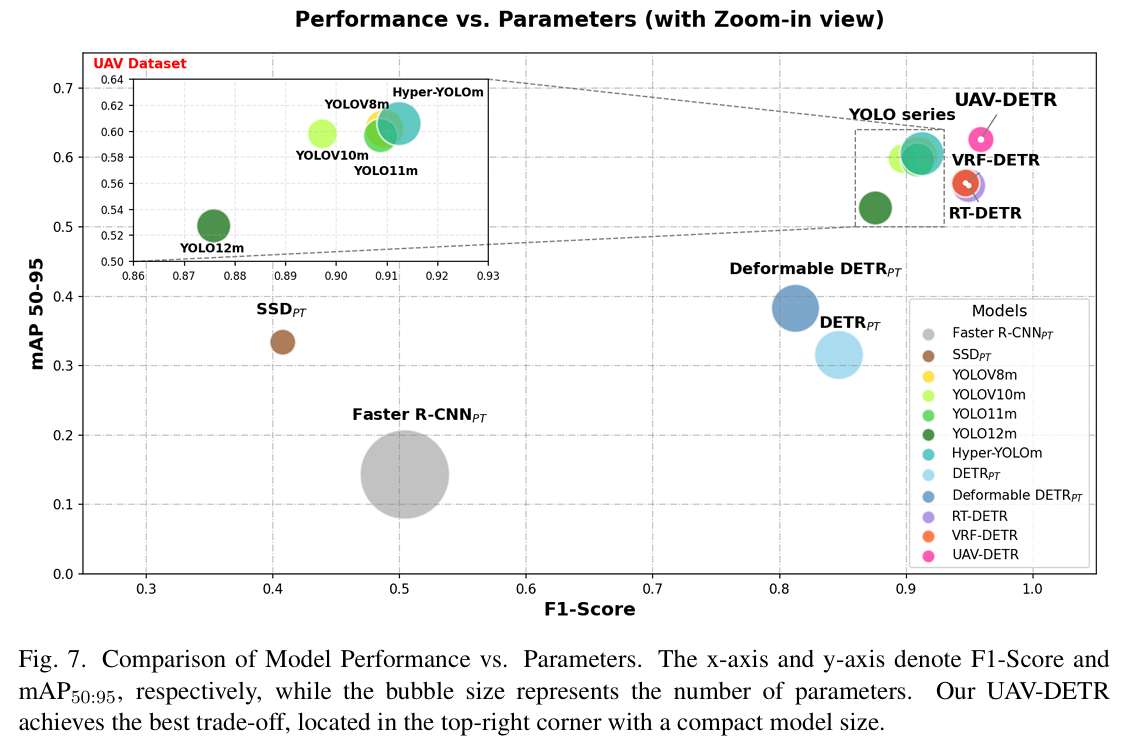
表 2 总结的详细数值对比表明,UAV-DETR 在检测精度与模型复杂度之间实现了卓越平衡。
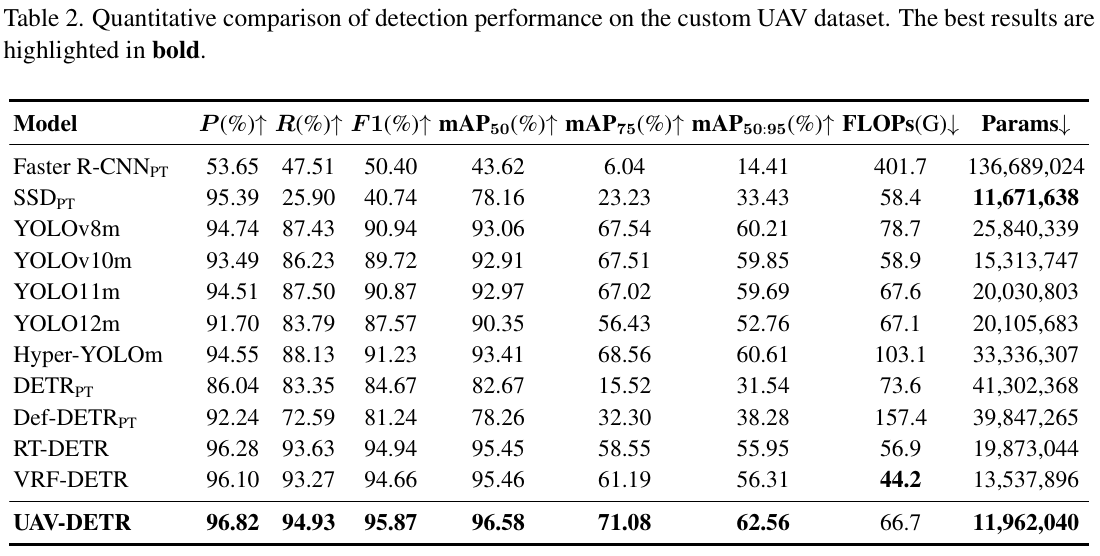
在检测精度方面,我们的方法在关键指标上优于所有竞争基线。具体而言,UAV-DETR 达到最高精确率96.82%96.82\%96.82%与召回率94.93%94.93\%94.93%,分别以0.54%0.54\%0.54%与1.30%1.30\%1.30%的幅度超越次优模型 RT-DETR。更关键的是,在严格的 mAP50:95 指标下,我们的模型达到62.56%62.56\%62.56%,显著优于先进无锚点模型如 YOLO12m(52.76%52.76\%52.76%)与 Hyper-YOLOm(60.61%60.61\%60.61%)。71.08%71.08\%71.08%的显著 mAP75 分数进一步证实,所提 ECFRFN 架构与融合 Inner-CIoU 和 NWD 的混合损失策略显著改善了微小目标的几何对齐与边界回归。关键在于,此优越性能并未以沉重计算开销为代价。
关于效率指标,传统模型如 Faster R-CNNPT_{PT}PT与 DETRPT_{PT}PT遭受过多 FLOPs 与超过 40M 的参数量。虽然 SSDPT_{PT}PT实现最低参数量11.6711.6711.67M,但其精度仍次优,mAP50 为78.16%78.16\%78.16%。相比之下,UAV-DETR 建立了最优权衡。仅11.9611.9611.96M 参数,我们的模型比 YOLOv8m 小约53%53\%53%,比 RT-DETR 小40%40\%40%,却提供显著更高精度。虽然 VRF-DETR 展现更低 FLOPs,但 UAV-DETR 在 mAP50:95 上以6.25%6.25\%6.25%优势超越它,同时保持更小整体占用。此最优权衡根本上由 WTConv 增强骨干驱动,其大幅减少参数冗余,结合 ECFRFN 与 SWSA-IFI 模块的高效特征处理。共同地,它们在高度紧凑预算内最大化小目标的表示能力。
4.4.3 可视化结果
图 8--10 可视化了多样反无人机场景下的定性检测结果。标准边界框与置信度分数代表模型的原始预测。为明确突出检测失败,我们在误报(假正例,FP)上叠加红框,并用紫框标示漏检目标(假反例,FN)。



4.4.4 关键组件特征可视化
可视化从 UAV-DETR 流水线顺序阶段提取的中间特征热力图,直观展示了内部机制与我们专门设计模块的有效性。图 11 以网格格式呈现这些可视化,说明五个不同复杂场景下的渐进重校准过程。布局严格遵循内部数据流:从左至右五列分别对应原始输入图像、主 ConvNormLayer 的初始低层特征、WTConv 增强骨干后的高频细节保留、SWSA-IFI 编码器的全局上下文聚焦,以及 ECFRFN 颈部在P3P_3P3分辨率级别的最终噪声过滤激活。
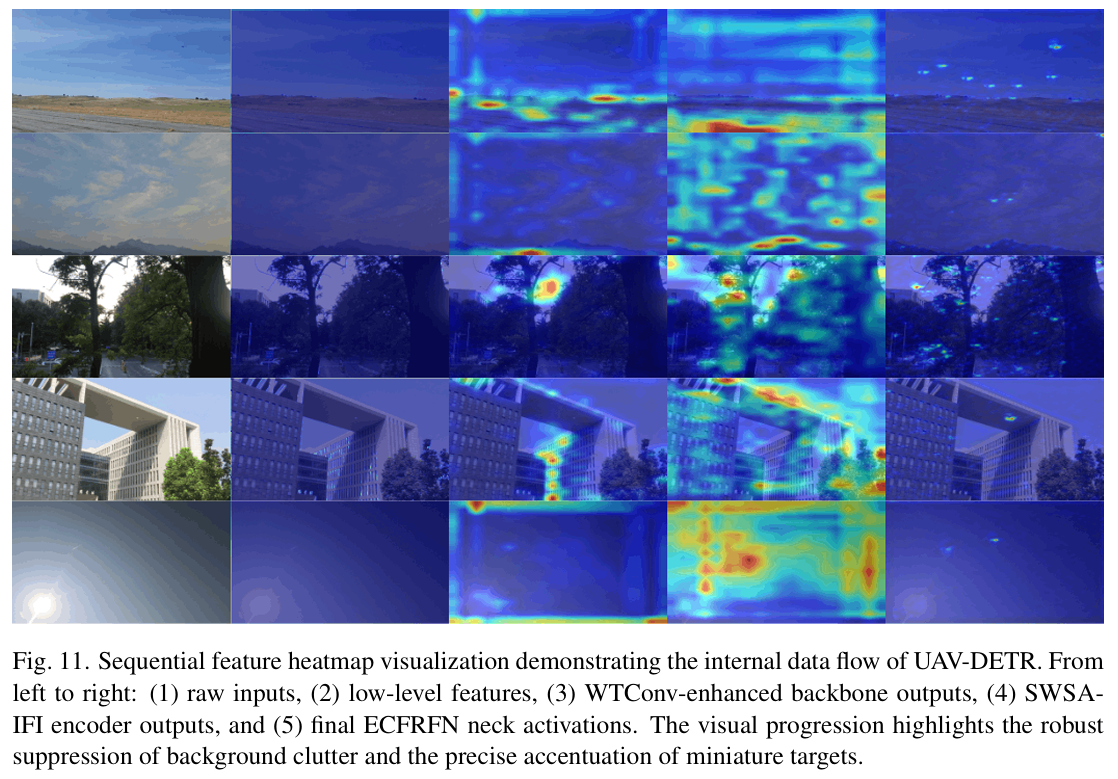
视觉进程揭示了噪声抑制与目标突出的清晰机制。最左列显示微型无人机位于极具挑战性的环境中。移至第二列,主 ConvNormLayer 仅执行低层像素变换,几乎无语义目标感知,导致均匀弱激活。随后,如图 3 所示,WTConv 增强骨干成功保留高频结构细节,防止标准下采样典型的严重信息损失。然而,大量背景杂乱(如树木枝叶与建筑边缘)也与目标一同被显著激活。SWSA-IFI 编码器通过建立全局上下文感知并主动将网络注意力转向显著区域来解决此干扰,如第四列所示。虽然此机制显著增强潜在目标的语义聚焦,但其宽感受野偶尔会突出显著背景干扰物。最后,第五列展示了特征精炼过程的最终成果。通过 ECFRFN 模块内的选择性边界聚合与跨尺度融合,剩余的结构背景噪声被完全过滤。最终热力图呈现高度局部化且强烈的激活,仅集中在真实无人机目标上,呈现为清晰锐利的光斑。此顺序可视化证实,每个提出的组件对于从严重环境干扰中隔离微小空中目标都不可或缺。
4.4.5 公开基准上的泛化验证
为促进可重复性与社区进一步研究,我们已完全开源源代码与构建的数据集,可通过摘要中提供的 GitHub 链接访问。为进一步严格验证所提方法在不同数据分布(超越自采样本)上的泛化能力,我们将评估扩展至公开的 DUT Anti-UAV 数据集。图 12 直观展示了此鲁棒泛化。如图所示,即使在此具有不同环境特征的外部基准上,UAV-DETR 仍保持相对于竞争方法的明显性能优势,验证我们的模型未过拟合自建数据集。
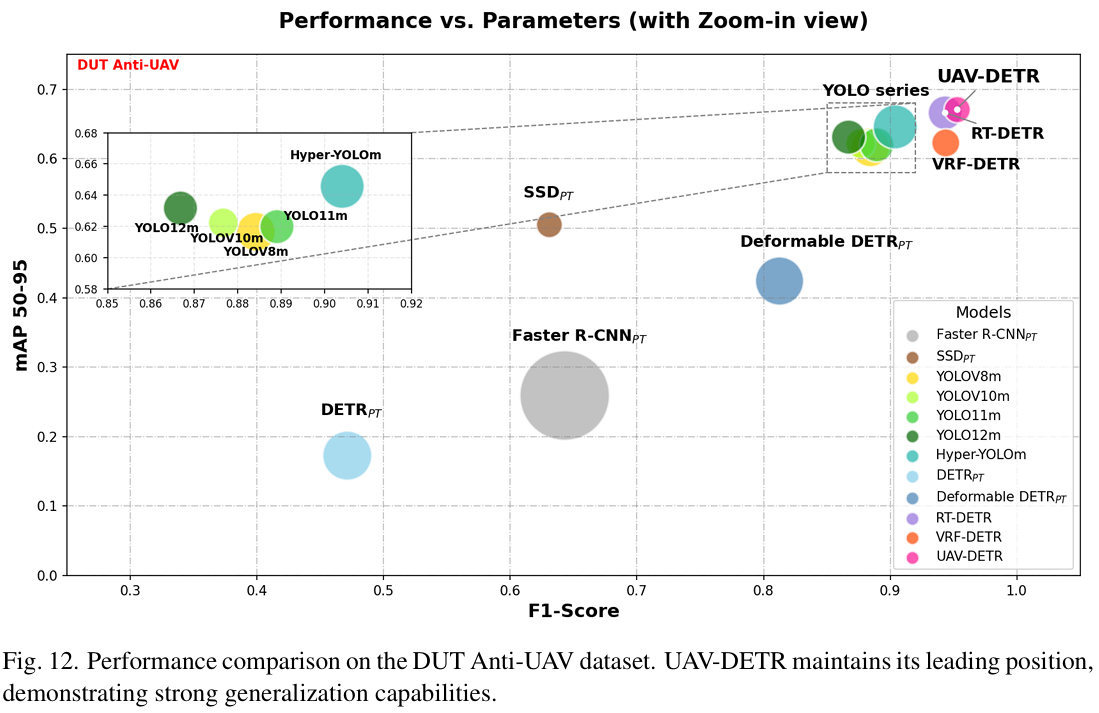
表 3 列出的详细数值结果进一步证实此优越性。始终如一地,UAV-DETR 在所有报告指标上实现最先进性能。值得注意的是,它达到67.15%67.15\%67.15%的 mAP50:95,超越高度竞争的 RT-DETR(66.67%66.67\%66.67%)与先进 YOLO12m(63.19%63.19\%63.19%)。精确率的显著领先(达到97.09%97.09\%97.09%)进一步表明,我们的频率感知设计在多样环境中有效区分无人机目标与复杂背景,最小化误报。
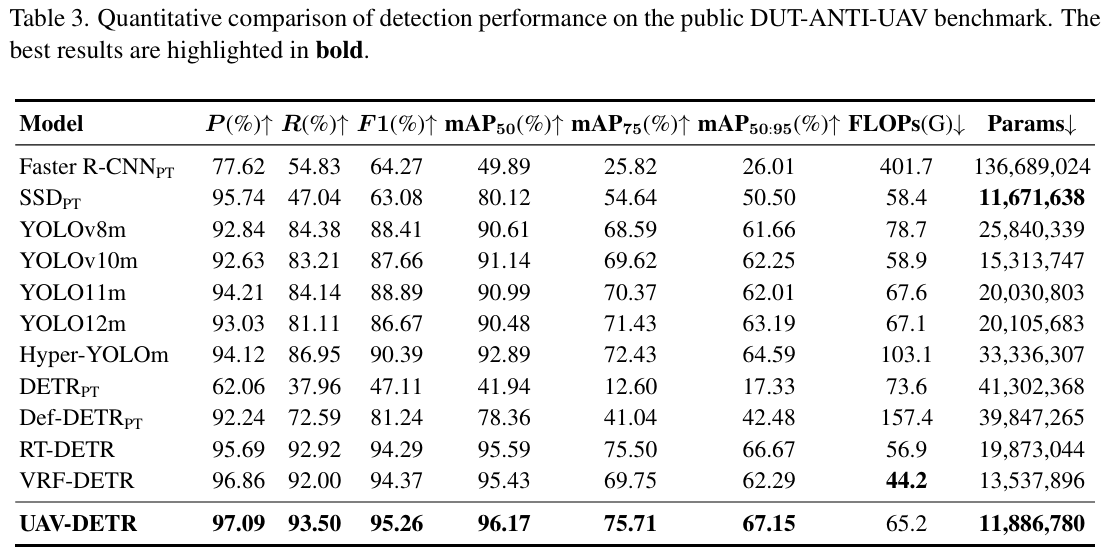
关于效率与精度的平衡,UAV-DETR 展现出实际部署的卓越适应性。如效率指标所示,我们的模型仅以11.811.811.8M 参数保持极轻量级占用。这与轻量级 SSDPT_{PT}PT的11.611.611.6M 参数相当,却提供精度的巨大提升,mAP50:95 提升约16.6%16.6\%16.6%。与纯关注低 FLOPs 的 VRF-DETR 相比,我们的方法提供更优权衡,以更小模型尺寸提供4.86%4.86\%4.86%更高的 mAP50:95,从而证明其适用于资源受限平台。
4.5 消融实验
为系统验证每个提出组件的有效性并解析其对整体性能的个体贡献,我们在自建无人机数据集上进行了全面消融实验。我们采用标准 RT-DETR 作为基线(记为模型 O),并渐进集成以下模块:
- A:混合损失策略(Inner-CIoU + NWD)
- B:高效跨尺度特征重校准融合网络(ECFRFN)
- C:频率感知骨干(WTConv Blocks)
- D:滑动窗口自注意力编码器(SWSA-IFI)
我们首先在图 13 中可视化模型性能与复杂度的演化。双轴图揭示清晰优化轨迹:虽然检测精度(柱状图表示)在初始步骤呈现稳定上升趋势,但在引入 WTConv 骨干(模型 O+A+B+C)时发生关键转变。此处,参数量(折线图表示)呈现急剧下降,表明模型冗余大幅减少。关键在于,最终配置(模型 O+A+B+C+D)在精度上达到明显峰值,同时占据参数幅度的最低谷,直观证实我们轻量级高性能设计策略的有效性。
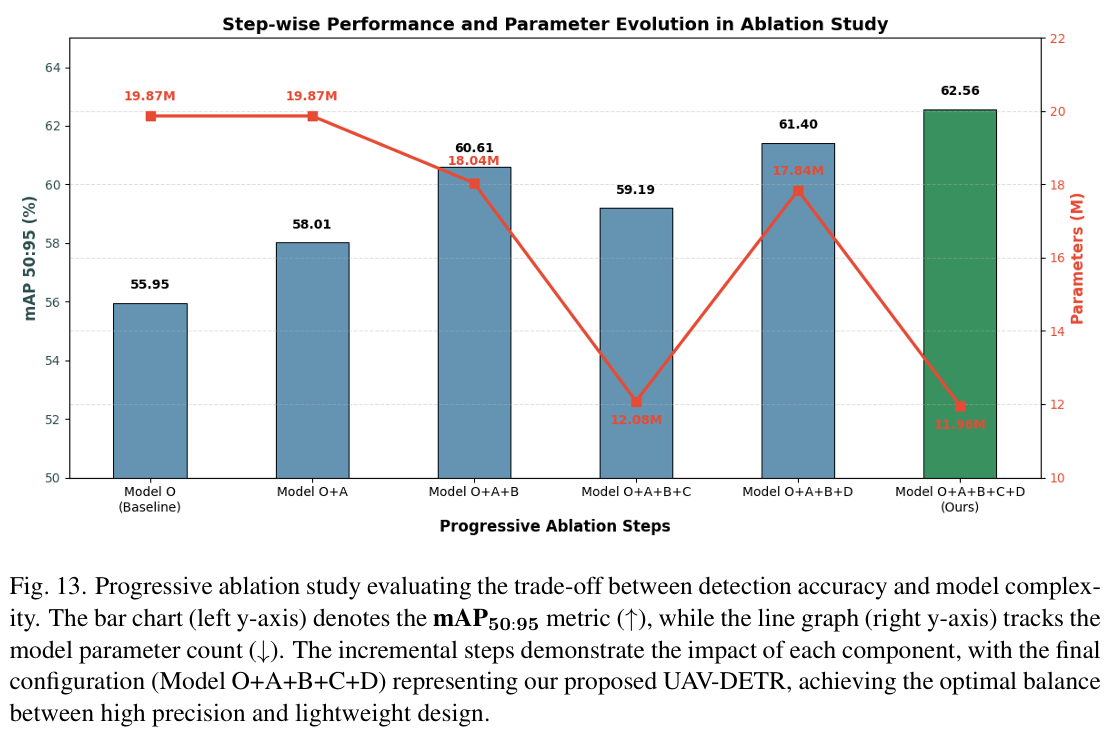
表 4 枚举了详细数值对比。初始阶段,用混合损失策略替换原始损失函数(模型 O+A)产生即时改进。如第 1 行至第 2 行所示,引入 Inner-CIoU 与 NWD 将 mAP50:95 从55.95%55.95\%55.95%提升至58.01%58.01\%58.01%。值得注意的是,mAP75 看到4.16%4.16\%4.16%的显著跃升,验证混合损失有效增强小目标的几何对齐精度。
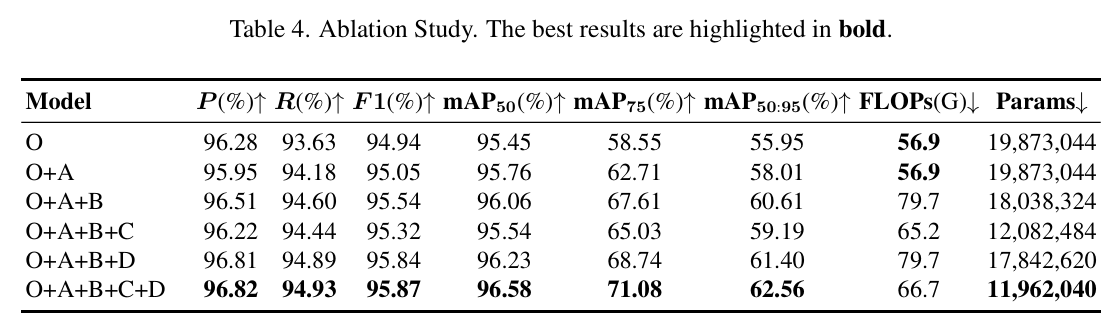
随后,集成 ECFRFN 模块(模型 O+A+B)替换标准颈部进一步提升 mAP50:95 至60.61%60.61\%60.61%,表明 SBA 机制在多尺度特征交互中成功过滤背景噪声。
为研究轻量级设计与语义表示之间的最优平衡,我们进一步分析了模块 C(频率感知骨干)与模块 D(全局注意力机制)的具体作用。用提出的 WTConv Blocks 重构骨干(模型 O+A+B+C)成功实现轻量级设计的主要目标,将参数量从18.0418.0418.04M 大幅减少至12.0812.0812.08M。然而,如第 4 行所示,此激进压缩导致 mAP50:95 轻微退化至59.19%59.19\%59.19%,表明显著减少通道冗余可能伴随语义信息的轻微损失。相反,仅添加注意力模块(模型 O+A+B+D)提升精度但保持17.8417.8417.84M 参数的较高计算负担。最关键的是,当两个模块集成时(模型 O+A+B+C+D),实现显著协同效应。如最后一行所示,模型以最低参数量11.9611.9611.96M 达到最高性能,mAP50:95 为62.56%62.56\%62.56%。这证实 SWSA-IFI 编码器捕获的鲁棒上下文特征有效补偿轻量级 WTConv Blocks 减少的语义容量,实现效率与精度的最优权衡。
4.6 算法失败与局限性的讨论
分析 UAV-DETR 的失败案例与固有局限性为未来优化提供关键见解,尽管其在各种场景中表现最先进。我们的实证研究揭示两种主要失败模式:形态干扰物诱导的误报(FP)与严重环境伪装导致的漏检(FN)。

图 14(a) 系统说明了飞行鸟类被误分类为无人机的典型 FP 实例。虽然 UAV-DETR 在标准环境中擅长区分生物干扰物,但当鸟类表现出与无人机极端形态相似性且位于真实目标附近空间时,偶尔误分类仍存在。此特定感知模糊在低分辨率条件下仍是挑战性瓶颈。相反,图 14(b) 突出显示了主要由严重视觉融合导致的漏检示例。在这些城市环境中,微型无人机常与高度复杂纹理的建筑背景视觉融合。相应缺乏明显对比阻碍模型提取判别性目标边界,最终导致漏检。
除环境脆弱性外,关键架构局限在于框架增加的计算开销。虽然 UAV-DETR 保持紧凑参数量并实现优越精度,但特征重校准与融合机制引入不可避免的计算需求。具体而言,整体计算量增加9.89.89.8GFLOPs,相对于基线 RT-DETR 代表17.2%17.2\%17.2%开销。因此,未来工作必须聚焦后续优化策略,如网络剪枝与权重量化,以满足超低功耗边缘设备上的严格硬件约束。
五、结论 (CONCLUSION)
本文提出 UAV-DETR,一种高效鲁棒的目标检测框架,专为应对反无人机场景中固有的极端尺度变化、微型目标尺寸与复杂背景干扰等关键挑战而设计。通过协同集成 WTConv 增强骨干、SWSA-IFI 编码器、ECFRFN 颈部架构与 InnerCIoU-NWD 混合损失函数,所提方法显著增强小型空中目标的多尺度特征表示与几何对齐。
在自建无人机数据集与公开 DUT-ANTI-UAV 基准上的综合评估验证了所提框架的有效性与泛化能力。UAV-DETR 始终优于 11 个最先进检测器,包括近期 YOLOv8m--YOLO12m 系列与先进 DETR 变体。具体而言,它在自建数据集上实现95.87%95.87\%95.87%的 F1 分数与62.56%62.56\%62.56%的 mAP50:95。此强劲性能良好迁移至 DUT-ANTI-UAV 数据集,产生95.26%95.26\%95.26%的 F1 分数与67.15%67.15\%67.15%的 mAP50:95,证明其在严重背景杂乱中抑制误检的鲁棒性。此外,详细消融实验证实了所提模块的个体贡献与协同效应。这些组件的渐进集成系统提升检测精度,将基线 mAP50:95 从55.95%55.95\%55.95%提升至62.56%62.56\%62.56%。同时,网络复杂度显著降低。UAV-DETR 保持高度紧凑的11.9611.9611.96M 参数占用(相对于19.8719.8719.87M 基线减少约40%40\%40%),从而在检测精度与模型轻量级之间建立最优权衡。
未来,虽然本研究主要在反无人机场景内验证 UAV-DETR,但我们的失败分析揭示极端形态干扰物与严重环境伪装仍构成感知挑战。此外,先进特征重校准不可避免地引入17.2%17.2\%17.2%计算开销增加。因此,我们正在进行的研究将沿两个主要方向展开。首先,为中和此计算负担并满足真实防御系统的严格低延迟约束,我们将探索硬件感知优化策略,如网络剪枝与权重量化,以促进在超低功耗边缘计算平台(如 RK3588)上的无缝部署。其次,基于此鲁棒基础,我们旨在集成先进目标跟踪算法以处理多目标无人机群的高度动态特性,标志着向开发能够实时作战意图识别的自主智能系统迈出关键一步40。
(注:参考文献1--40为英文标准学术引用格式,此处保留原文以便直接检索核对。如需逐条翻译可提供补充说明。)