想象一个机器人去货架上拿瓶子:先要从初始位姿划过半米的空气,再用末端去精确卡住瓶颈。前半段在自由空间里几乎"用脚指头都能开",后半段却需要毫米级的精修。可是在主流的模仿学习里,这两段是被一视同仁地对待的------每一个控制周期都跑一次策略网络、预测一次动作、走一步、再来一次。看起来朴素稳健,实则极度浪费:在自由空间里一遍遍重复"差不多的预测",反而让误差有机会在中途积累;在接触阶段又因为同样的预测频率不够密集,错过对齐细节。
最近放出的 SkiP(Skip Policy)给出了一个非常"反套路"的答案:不动模型架构,不加额外规划器,也不引入层次化结构,只改训练目标------让策略在自由空间一次跨过几十步,到了关键阶段再切回密集精修。最终在 72 个仿真任务和 3 个真机任务上,执行步数减少 15-40% 的同时成功率没掉,甚至往往更高。在 RLBench-10 上,平均成功率从 0.70 直接拉到 0.85,平均执行步数从 127.5 砍到 72.9。
这篇文章会拆解 SkiP 的两个关键技术------动作重标记(Action Relabeling)和运动频谱键控(MSK),看看它为什么"轻而易举"地做到了又快又准。
背景与动机:均匀预测是模仿学习的隐性瓶颈
行为克隆(Behavior Cloning, BC)的范式简单到几乎像是默认设置:每一步看一帧观测,输出下一步动作。Action Chunking with Transformers (ACT)、Diffusion Policy、3D Diffuser Actor 这些近年的明星工作都在动作生成器上做文章------更强的解码、更大的窗口、更聪明的视觉编码------但都没有改训练监督本身 。结果就是:策略在执行时仍然以均匀的时间分辨率推进,每一个时间步拿到的"待遇"都一样,不管这一步重不重要。
这种均匀分配在两端都不划算。一端是自由空间:轨迹本身高度可预测,每多查询一次策略就是多积累一次预测误差,而误差是会沿着 rollout 累积的(这是 DAgger 和 imitation learning 误差扩散经典结论的根源);另一端是接触阶段:抓握、对齐、插孔这些动作要求毫米级精度,反而要密集纠错。"该快的快不起来,该慢的慢得不够",是模仿学习长期被低估的一个结构性问题。
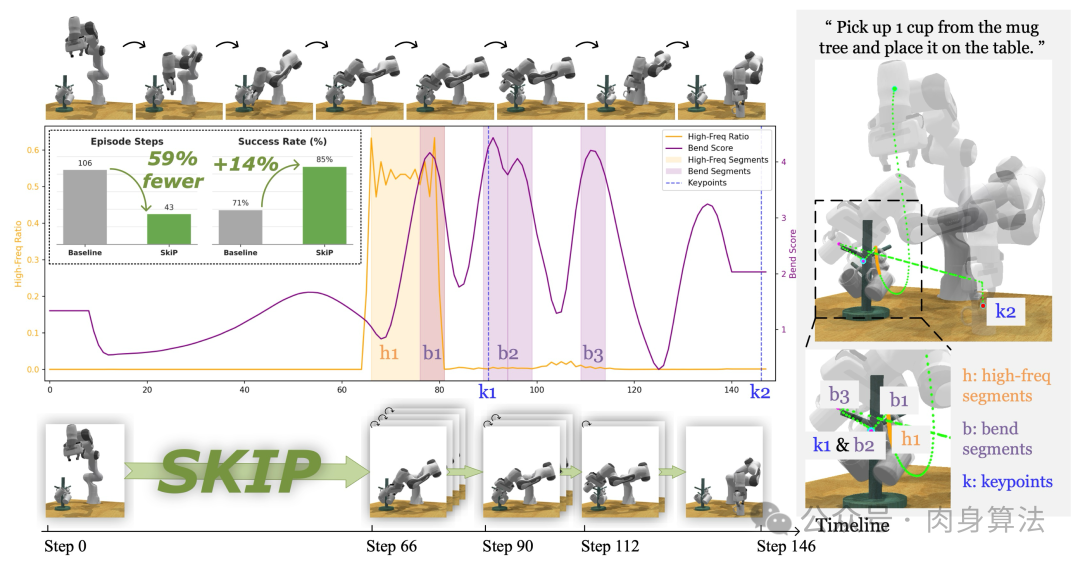
SkiP 用上图很直观地展示了这个问题和它的解法。任务是"从马克杯架上取一个杯子放到桌上"。中间的曲线图里,橙色是高频能量比率 ,紫色是 bend score ------它们标出了演示轨迹里真正信息密集的瞬间(黄色 h、紫色 b、灰色 k 阴影区)。下方的轨迹条说明 SkiP 学到了一个鲜明的"快进+精修"模式:从 step 0 一口气跳到 step 66 进入接触阶段,再在 step 66 之后密集精修。Episode steps 从 100 降到 41,下降 59% ;同任务 SR 从 71% 升到 85%,反而提升 14 个百分点。
核心方法
SkiP 把整套方法拆成两件事,逻辑很对称:
-
MSK(Motion Spectrum Keying) 负责回答"哪些时刻是关键时刻"------这是标签的生成;
-
Action Relabeling 负责回答"知道关键时刻之后,怎么改写监督信号"------这是目标的改写。
值得强调的是:SkiP 没有改任何模型结构。无论底层用的是 Transformer(CoA 风格)、UNet 扩散策略(Diffusion Policy)、3D 扩散策略(DP3)还是预训练 VLA(π₀.₅),换上 SkiP 的训练目标,效果都能复现。这一点对工程落地很重要------它意味着已有的策略仓库不需要重写,只要把 dataloader 里的目标动作做一次重标记即可。
1. Motion Spectrum Keying:用 DCT 自动找出"关键瞬间"
传统的关键帧抽取方法(如 James 和 Abbeel 提出的方案)依赖启发式信号:夹爪状态变化、末端速度过零点。这套规则对"拿起-放下"型任务够用,但对持续高精度运动(比如擦拭、拖拽)就抓不住。MSK 的想法很直接:关键时刻往往伴随更高的局部运动复杂度------也就是动作信号里出现了更多高频成分。
具体步骤如下:
第 1 步:速度信号与短时 DCT。 对动作序列 {a_t}*{t=1}\^T,先逐步求差得到速度v_t = a_t - a*{t-1}。然后以每个时间步t为中心,取长度W的窗口(论文里W=16,对称为\[t-8, t+7\]),沿时间轴做离散余弦变换:
其中 是 DCT 的标准归一化系数。
第 2 步:高频能量比率。 求频谱能量 后,提取上半频段()的能量占比:
越大意味着这一段动作的局部变化越剧烈------通常对应着接触发生、姿态修正这些"非平滑"事件。
第 3 步:阈值化。 对每一回合(per-episode)按分位数 切分------超过分位数的连续时间步合并成一个关键段。论文默认 (也就是取每回合 排序前 25% 的部分),并通过消融实验确认 在成功率上达到峰值。
第 4 步:bend score 几何补强。 单纯的高频信号会漏掉缓慢但路径弯曲的精修动作(比如沿曲线擦拭)。SkiP 用 bend score 补一道:
其中 是窗口首尾两个末端坐标之间的线性插值参考线, 是窗口内的平均步长(保证尺度不变)。 高的时间步表示末端轨迹明显偏离了直线,意味着这一段是有结构的几何修正。
第 5 步:并集分割。 最终的关键段是三类的并集------高频段、bend 段,加上启发式关键帧(夹爪状态变化和速度过零点)前后 ±5 步的小邻域。剩下的全部归为跳跃段。短于 3 步的片段当噪声丢掉,每回合前 20% 也被跳过(避免把初始化复位运动误判为关键运动)。

整套 MSK 没有任何可学习参数,运行起来非常快------这是相对一些"用 VLM 标关键段"方案的显著优势。论文里专门做了对比:用 Gemini-2.5-Pro 替换 MSK 来分段(标记为 SkiP†),在 RoboMimic 上甚至会出现灾难性下跌(SR 0.123 vs MSK 的 0.772),原因是 VLM 不一定能准确捕捉到机器人动作信号里的"接触瞬间"。简单的频谱启发式反而更贴合任务本质。
2. Action Relabeling:把训练目标"挪到下一个关键点"
有了关键段标注 (关键段=1,跳跃段=0)之后,重标记本身是一个非常清爽的几行代码改动。
定义"下一个关键段的入口时间":
然后重新选择目标动作块的起点:
且存在
接下来构造长度为 的目标动作块 :
注意这里 是 padding mask:因为重标记后目标可能"跳出"演示尾部,超出 的部分要被屏蔽掉。
最终的损失就是一个带掩码的模仿损失:
是 backbone 自带的损失(Transformer 用 L1,扩散策略用去噪损失,VLA 用 flow matching loss),SkiP 不引入任何额外的 loss 项。
直觉上,这个机制把策略训练成了两种行为模式的混合:
-
在关键段里 ():目标还是"下一步",本质就是密集 next-step prediction,学到对接触和修正的高分辨率响应;
-
在跳跃段里 ():目标被改写成"下一个关键段入口的动作",等于告诉策略"你不用一步步走,直接把末端跳到下一个关键瞬间该有的位置"。
3. 推理时的执行:把整段 chunk 一次性吃光
模仿学习里很多方法(包括 ACT)会用 temporal ensembling 在重叠的预测块之间做加权融合,以减少抖动。SkiP 直接禁用了 temporal ensembling------每次策略查询输出长度为 的动作块,环境把整块执行完,再去查下一次。这就是为什么"执行步数"会大幅下降:跳跃段的目标已经被训成"跳到下一个关键点",于是单次查询就能跨过几十步的自由空间。
论文里有个相当漂亮的分析(Figure 6):他们测量每次策略调用的"跳跃距离" ,发现 SkiP 的调用呈双峰分布------跳跃模式的距离在 0.1-0.7m,关键模式则聚集在零附近;而基线 CoA-rev 集中在零附近、CoA-fwd 是中等单峰分布。这强证了一件事:重标记真的教出了两种不同的输出模式,不是一个被平均掉的"中庸"行为。
实验与结果
实验规模可以说相当扎实:72 个仿真任务 + 3 个真机任务,覆盖 RLBench-10/60、RoboMimic(含 lift/can/square/transport)、RoboTwin(8 个双臂任务)、RLBench-18(VLA 微调)、以及 π₀.₅ 真机微调。
仿真主结果
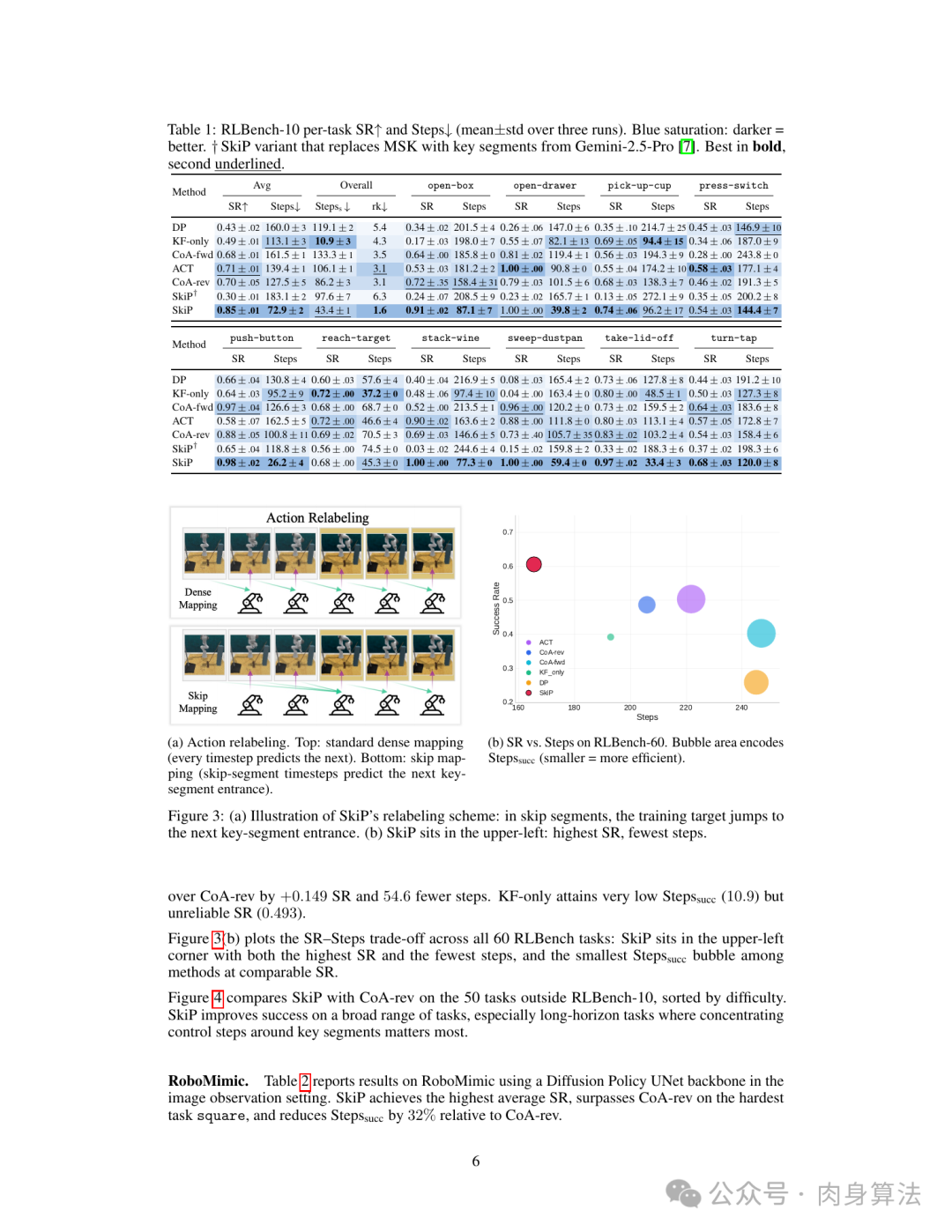
RLBench-10(Transformer 骨干):SkiP 平均成功率 0.85,平均执行步数 72.9。横向对比:
| 方法 | 平均 SR ↑ | 平均执行步数 ↓ |
|---|---|---|
| Diffusion Policy | 0.43 | 119.1 |
| KF-only(仅关键帧预测) | 0.49 | 10.9(不可靠) |
| ACT | 0.71 | 106.1 |
| CoA-fwd | 0.68 | 133.3 |
| CoA-rev | 0.70 | 86.2 |
| SkiP | 0.85 | 43.4 |
比次优的 CoA-rev 高 +14.9 个百分点,同时减少 54.6 步。
RoboMimic(Diffusion Policy UNet) :SkiP 0.772 SR / 144.1 steps,相较 CoA-rev 的 0.723 SR / 211.8 steps,Steps_succ 减少 32%。值得注意的是用 Gemini-2.5-Pro 分段的 SkiP† 暴跌到 0.123------这反过来印证了 MSK 这种轻量频谱方法在动作信号里更可靠。
RoboTwin(DP3 双臂 + 点云):SkiP 0.773 SR / 126.6 steps,相比 DP3 baseline(0.614 / 268.7)成功率提升 +0.159、步数减少 53%。
真机三任务(基于 π₀.₅ 微调)
| 任务 | 指标 | π₀.₅ Base | KF-only | CoA | SkiP |
|---|---|---|---|---|---|
| pour-water | SR | 40.0% | 6.7% | 33.3% | 46.7% |
| 步数 | 290.4 | 309.6 | 281.9 | 265.4 | |
| 时间 | 3:44 | 4:01 | 3:39 | 3:28 | |
| stack-bowls | SR | 33.3% | 6.7% | 26.7% | 53.3% |
| 步数 | 246.3 | 271.4 | 226.8 | 204.5 | |
| 时间 | 2:41 | 2:59 | 2:29 | 2:16 | |
| tidy-up-desk | SR | 66.7% | 13.3% | 40.0% | 73.3% |
| 步数 | 250.7 | 286.8 | 232.4 | 207.4 | |
| 时间 | 2:20 | 2:43 | 2:12 | 2:00 |
每个任务 15 次 rollout。三个任务上 SkiP 都是最高 SR + 最少步数 + 最短墙钟时间。stack-bowls 上从 33.3% 飙到 53.3%,绝对增益 +20 个百分点 ------而骨干网络完全没变,只换了训练目标。这有力地证明了 action relabeling 与大规模预训练是互补的:预训练权重提供通用的运动能力,重标记教会策略"该把决策预算花在哪里"。
消融实验
分位数阈值 q:SR 在 q=0.75 达到峰值,q≥0.80 时跳过得太激进、SR 显著下跌;Steps_succ 随 q 单调下降。q=0.75 是 SR 和效率的最佳平衡点。
ST-DCT 窗口大小 W(RLBench-60):
| W | SR ↑ | Steps ↓ | Steps_succ ↓ |
|---|---|---|---|
| 4 | 0.529 | 178.4 | 50.6 |
| 8 | 0.547 | 175.6 | 57.2 |
| 16(默认) | 0.606 | 165.5 | 64.1 |
| 32 | 0.514 | 176.7 | 47.2 |
太小的窗口丢失时序上下文,太大的窗口又过于选择性、漏掉一些纠正动作。
组件消融:
| 配置 | SR ↑ | Steps ↓ |
|---|---|---|
| 仅 DCT(去掉 union 和 bend) | 0.530 | 176.3 |
| 去掉 union(保留 DCT+bend) | 0.574 | 168.8 |
| 去掉 bend(保留 DCT+union) | 0.574 | 163.0 |
| 完整 SkiP | 0.606 | 165.5 |
最有信息量的一行是"仅 DCT":去掉所有补强组件后 SR 还有 0.530,仍然高于 CoA-rev 在同套 RLBench-60 上的 0.490 。也就是说性能增益主要来自 action relabeling 本身,标签的工艺只是锦上添花。
讨论与思考
读完整篇论文我觉得最值得拎出来讲三点。
1. 把"做什么"和"什么时候做"解耦的训练范式
过去几年里模仿学习里大部分的"进步",无论是 Diffusion Policy 还是 Action Chunking,本质都是在改"动作生成器"------用更强的解码器去拟合人类演示。SkiP 走了完全不同的方向:它改的不是模型,是监督信号本身。这一手在我看来挺像 NLP 里 next-token prediction → masked language modeling → instruction tuning 的演化思路------同一套架构在不同的目标下能学到完全不同的能力。
模仿学习的"目标改写"维度长期被忽视,SkiP 是第一个把这件事做得这么干净的工作。我猜接下来一两年会有不少跟进------比如把目标从"下一个关键段入口"再往后推(多级跳跃)、或者把跳跃距离也作为预测对象(learned skip planner,不过 SkiP 已经证明了不需要也行)。
2. 频谱方法对 VLM 的胜利
SkiP† 用 Gemini-2.5-Pro 替换 MSK 的对比相当意味深长。一个被普遍认为更"聪明"的多模态大模型在这里不仅没赢,反而严重输给了一个完全没有可学习参数、纯靠 DCT 的启发式方法。
这背后的逻辑其实很 fundamental:机器人动作信号里的"关键瞬间"是一个高度任务无关的物理概念------动力学上的接触、几何上的转折------这些信息在动作信号的频谱里直接可读 ,反而是 VLM 在没有动作信号、只看图像和文字时很难精确定位的。这给一个启发:在具身智能这条路上,不要无脑用大模型替代经典信号处理,很多时候"该用 DSP 就用 DSP"。
3. 跳跃为什么会让成功率反而更高?
直觉上"跳过中间预测"应该是用准确度换效率,但 SkiP 的数据里我们看到的是"准确度 + 效率"双赢。论文给出的解释很关键:每一次策略查询都是一次潜在的误差累积机会。在自由空间里,本来这些预测就高度可预测且接近确定性,每多预测一次只是多积累一次扰动;把整段坍塌成一个决策,反而把这些误差"挤掉"了。这是个相当反直觉但又很合理的发现------它把模仿学习里被普遍接受的"高频预测 = 更稳定"这条直觉给反转了。
这一点对工程落地有非常直接的启示:在自由空间高频查询策略不仅浪费,还会降低任务成功率。
局限性
诚实地说几点:
-
SkiP 的 MSK 依赖动作信号的高频结构,对真正连续平滑但需要高精度的任务(比如沿曲面缓慢拖拽)可能会过度倾向 bend score,需要任务特定调参;
-
真机实验里 SkiP 提升的是 π₀.₅ 已经具备部分能力的任务,对从 0% SR 起步的任务并没有改善------也就是说重标记是个 "amplifier",本身不能从零教会策略一个新技能;
-
论文里 H(chunk 长度)的选择和跳跃距离之间的关系还可以更系统地刻画------目前看起来是经验性的。
但这些都不影响 SkiP 是一个非常优雅的工作。我相当看好这套思路在 VLA、长程任务和真机部署里被广泛复用。
总结
-
核心观点:模仿学习的低效不在模型,而在监督------所有时间步用同一种 next-step prediction 训练是浪费的。
-
关键贡献 1(MSK):用短时 DCT 和 bend score 在动作信号本身上做关键段分割,无需学习、无需任何人工标注。
-
关键贡献 2(Action Relabeling):在跳跃段把训练目标改写为"下一个关键段入口"的动作,让策略学会"快进",损失公式只是一行 mask。
-
效果:72 仿真 + 3 真机任务上,执行步数 -15% 至 -40%,成功率持平或更高;RLBench-10 平均 SR 从 0.70 → 0.85,平均步数 127.5 → 72.9。
-
意义:把"目标改写"作为一个独立的研究维度凸显出来,可能比"换更强的动作生成器"是更高 ROI 的路径。
本文基于 SkiP: When to Skip and When to Refine for Efficient Robot Manipulation1 解读。项目主页:pgq18.github.io/SkiP-page2,代码:github.com/CCCalcifer/Skip-Policy3。
引用链接
1SkiP: When to Skip and When to Refine for Efficient Robot Manipulation: https://arxiv.org/abs/2605.15536
2pgq18.github.io/SkiP-page: https://pgq18.github.io/SkiP-page/
3github.com/CCCalcifer/Skip-Policy: https://github.com/CCCalcifer/Skip-Policy