快速了解部分
基础信息(英文):
1.题目: Yell At Your Robot: Improving On-the-Fly from Language Corrections
2.时间: 2024.03
3.机构: Stanford University, UC Berkeley
4.3个英文关键词: Language Corrections, Hierarchical Policies, Continuous Improvement
1句话通俗总结本文干了什么事情
让机器人通过听懂人类的语言来实时调整动作,并利用这些反馈数据自我迭代升级,从而在不增加昂贵遥操作成本的情况下,搞定复杂的长程双手机械臂任务。
研究痛点:现有研究不足 / 要解决的具体问题
- 长程任务容错率低:任务步骤越长,出错概率指数级上升,低级策略(Low-level Policy)容易出错,而训练能容错的高级策略(High-level Policy)需要大量涵盖各种错误场景的演示数据,收集成本极高。
- 现有方法的局限:直接模仿学习(如DAgger)需要人类亲自上手遥操作纠正,太累人;利用大模型(LLM/VLM)做规划虽然不用演示,但缺乏物理 grounding,容易给出不切实际的指令(比如让机器人"把已经在袋子里的海绵放进去")。
核心方法:关键技术、模型或研究设计(简要)
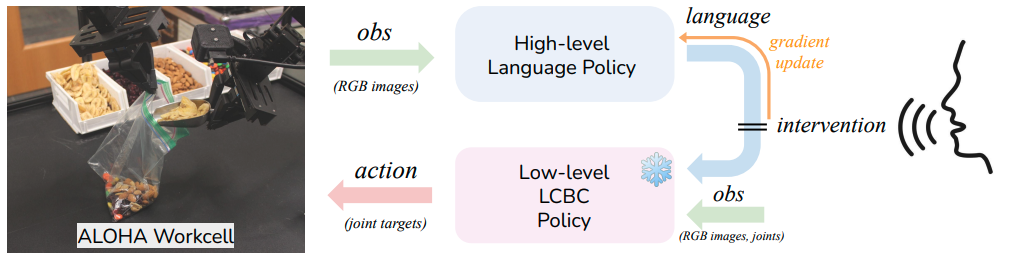
YAY Robot:一个分层系统。
- 底层:用ACT模型训练一个能听懂各种复杂语言指令(包括纠错指令)的策略。
- 上层:训练一个能输出语言指令的高级策略。当人类觉得机器人做错了,直接用嘴喊停并给出语言修正,系统记录下来,用来微调这个高级策略。
深入了解部分
作者想要表达什么
作者想证明:自然语言是连接人类直觉与机器人底层物理控制的最佳桥梁。
不需要昂贵的全任务演示,也不需要完全依赖虚幻的大模型,只要让普通人能"骂"机器人,机器人就能利用这些"骂声"学会如何处理复杂任务中的各种幺蛾子。
相比前人创新在哪里
- 反馈形式的创新:不同于传统的DAgger需要人类提供"低级动作"纠正,YAY Robot只需要人类提供"高级语言"纠正。
- 分层架构的解耦:将"技能执行"(底层)和"决策规划"(上层)解耦。底层学得宽泛(包含各种纠错技能),上层通过语言反馈不断进化。
- 低成本迭代:实现了真正的"边做边学"(On-the-fly),人类不需要专门去实验室录数据,只需要在日常使用中随口指导即可。
解决方法/算法的通俗解释
想象你在教一个聋哑但手很巧的徒弟(机器人)干活。
- 以前的方法:你要么得手把手帮他做一遍(遥操作),要么得自己写一本《遇到xx情况该怎么做》的说明书(大模型提示工程)。
- YAY Robot的方法:你只需要在他做错时大喊一句"往左一点!"或者"换个姿势!"。他听了之后,先照做(实时调整),然后默默记住"下次遇到这种情况,我应该用这个动作"(策略微调)。久而久之,他就学会了自己判断什么时候该做什么。
解决方法的具体做法
- 数据收集:先收集一堆带语音解说的操作录像(Live Narration),把语音转成文字,训练一个底层策略(LCBC),让它能听懂各种指令。
- 部署与干预:让机器人自己干活。人类在旁边看着,如果觉得它要错了,就喊一句指令(比如"别倒了,换个角度")。
- 实时覆盖:机器人的耳朵(麦克风)听到这句话,直接覆盖掉大脑(上层策略)原本想做的动作,执行新指令。
- 迭代学习:把人类刚才喊的那句话和当时看到的画面存下来,回头用来"补课"(Fine-tune)机器人的大脑,让它下次自己就能想到这个好办法。
基于前人的哪些方法
- ACT (Action Chunking with Transformers):用于底层策略,这是目前模仿学习里的SOTA模型,擅长处理高维动作。
- DAgger (Dataset Aggregation):核心的模仿学习算法,YAY Robot本质上是把DAgger搬到了语言空间(Language Space)上,而不是动作空间上。
- CLIP / ViT:用于视觉和语言的编码,让机器人能看懂画面并理解语言指令的语义。
实验设置、数据、评估方式、结论
- 硬件:ALOHA双手机械臂。
- 任务:三个超难的长程任务------装袋(Bag Packing)、做什锦果仁(Trail Mix)、洗盘子(Plate Cleaning)。这些任务涉及透明物体、软体操作,非常容易失败。
- 对比 :
- Base Policy(基础策略):成功率很低(约15%)。
- YAY Robot + 人工喊话:成功率飙升到50%左右,证明语言反馈能救命。
- YAY Robot(微调后):成功率提升到45%左右,证明机器人真的学会了,不需要人类一直盯着喊了。
- 结论:这种方法能把成功率提升3倍以上,且显著优于纯脚本(Scripted)或纯GPT-4V控制的方案。
提到的同类工作
- RT-1 / RT-2:谷歌的机器人Transformer模型,强调大规模数据和语义理解。
- DAgger / HG-DAgger:经典的模仿学习算法,需要低级动作纠正。
- GPT-4V / VLMs:大型视觉语言模型,被用作对比基准,证明纯大模型在物理世界规划的不足。
和本文相关性最高的3个文献
- RT-1 : 这是本文底层技术的重要基石,本文沿用了其将语言作为策略输入的思想,但解决了RT-1在长程任务中缺乏纠错能力的问题。
- DAgger : 本文核心算法逻辑的来源,作者明确表示YAY Robot是DAgger在语言空间上的变体。
- ALOHA : 本文实验所用的硬件平台及相关数据收集方法,是本文得以在低成本下进行双手机械臂研究的前提。
我的
分为高低两层。高层策略用于输出语言。底层策略用于输出action。
主要实现的功能是机器人在推理时可以语言介入,然后底层策略会按照语言指示运行,完成任务。这个介入的语言会存下来用来训高层策略,在下次遇到相同情况的时候就能发出同样的介入语言了。
问题在于如何让底层策略能够按照语言指示运行?文章方法是采集员在采集时就说出对应操作,把话也录进去了,而且还针对机器人做不好的地方去录制纠正指令。