一、卷积神经网络(CNN)
1. 图像基础概念
在正式聊CNN之前,先来看一眼我们处理的对象------图像。
图像是由密密麻麻的像素点 组成的,每个像素点的取值范围是 0, 255。像素值越接近0,颜色越暗(接近黑色);越接近255,颜色越亮(接近白色)。
在深度学习中,大多数图像都是彩色图 ,由 RGB 三个通道 组成,分别是红(Red)、绿(Green)、蓝(Blue)。所以彩色图的形状通常是 H, W, C,即高度、宽度、通道数。
简单理解:RGB三原色可以混合出世界上任意颜色,图像在计算机里就是三个通道的数值矩阵。
python
import numpy as np
import matplotlib.pyplot as plt
# 全0数组 → 黑色图像
img_black = np.zeros([200, 200, 3])
plt.imshow(img_black)
plt.show()
# 全255数组 → 白色图像
img_white = np.full([200, 200, 3], 255)
plt.imshow(img_white)
plt.show()2. CNN概述
卷积神经网络(Convolutional Neural Network, CNN) 是含有卷积层 的神经网络,卷积层的作用是自动学习、提取图像的特征。
CNN 网络主要由三部分构成:
| 层次 | 作用 |
|---|---|
| 卷积层(CONV) | 负责提取图像中的局部特征 |
| 池化层(POOL) | 大幅降低参数量级(降维) |
| 全连接层(FC) | 输出CNN模型的预测结果 |
CNN做的事情用一句话概括:给定一张图片,判断图片里是什么东西。最左边是数据输入层(去均值、归一化等预处理),中间经过卷积层+激活层+池化层的循环叠加,最右边全连接层输出结果。
3. 卷积层
3.1 卷积计算过程
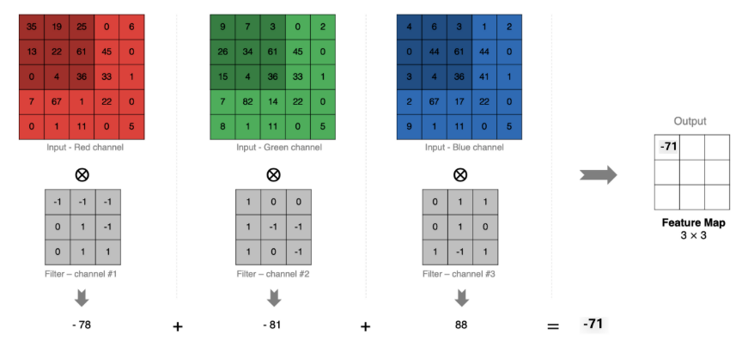
卷积运算是 CNN 的核心,本质上就是卷积核和输入数据的局部区域做点积(线性乘积求和) 。
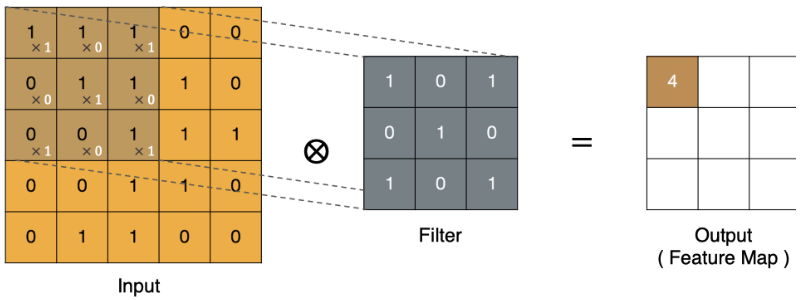
-
input:输入图像
-
filter:卷积核(也叫滤波器、卷积矩阵)
-
output:特征图(feature map)
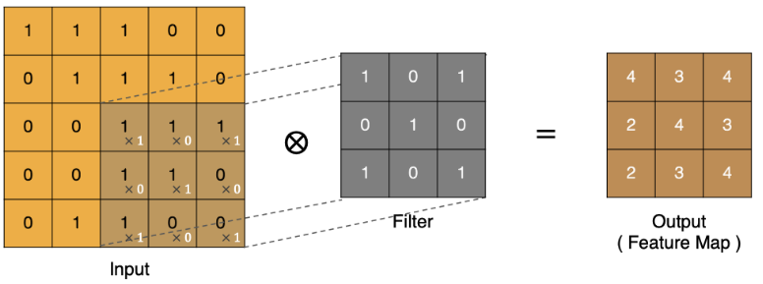
输入图像的局部区域 × 卷积核 → 特征图中的一个像素值
滑动卷积核遍历整张图像,就得到了完整的特征图。
3.2 Padding(填充)
如果不做任何处理,每经过一次卷积,特征图都会比原图小很多。Padding 就是在原图周围添加一圈额外的像素(通常是0),使得卷积后图像大小保持不变。
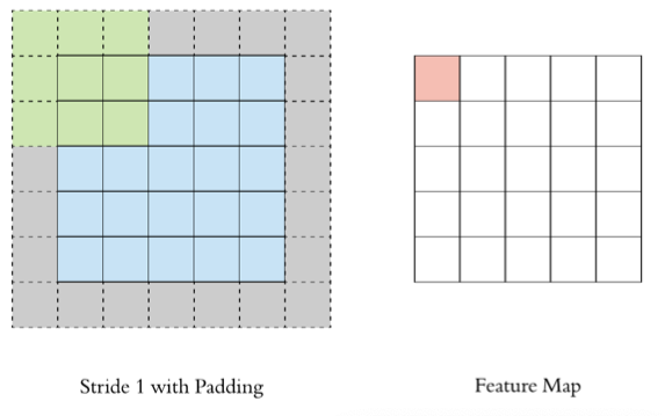
通俗理解:卷积会让图像"缩水",padding就是在边缘"垫一圈",让图像不缩水。
3.3 Stride(步长)
Stride 指的是卷积核在图像上滑动时的步伐大小。步长为1表示每次移动1个像素,步长为2表示每次跳过2个像素。
步长越大,特征图越小,计算量也越小,但可能丢失一些细节特征。

3.4 多通道与多卷积核
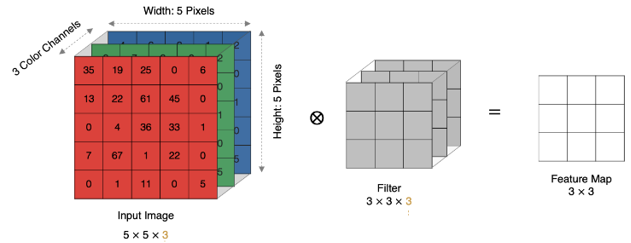
- 多通道卷积:彩色图有RGB三个通道,卷积时每个通道分别与对应的卷积核做点积,再相加得到一个输出通道。
- 多卷积核 :使用多个卷积核可以提取多种不同的特征,每个卷积核产生一张特征图。
3.5 特征图大小计算
输入图像大小 W×WW \times WW×W,卷积核大小 F×FF \times FF×F,步长为 SSS,填充为 PPP,输出大小为 N×NN \times NN×N:
N=W−F+2PS+1N = \frac{W - F + 2P}{S} + 1N=SW−F+2P+1
举例:图像 5×5,卷积核 3×3,Stride=1,Padding=1:
N=5−3+2×11+1=5N = \frac{5 - 3 + 2 \times 1}{1} + 1 = 5N=15−3+2×1+1=5
输出特征图仍为 5×5,大小不变 ✅
4. 池化层
池化层(Pooling) 位于卷积层之后,通过下采样 大幅降低数据维度,从而减少计算量和内存消耗,同时提高模型的鲁棒性。
池化操作有两种主要类型:
| 类型 | 计算方式 | 特点 |
|---|---|---|
| 最大池化(MaxPool) | 取区域最大值 | 保留显著特征 |
| 平均池化(AvgPool) | 取区域平均值 | 保留背景信息 |
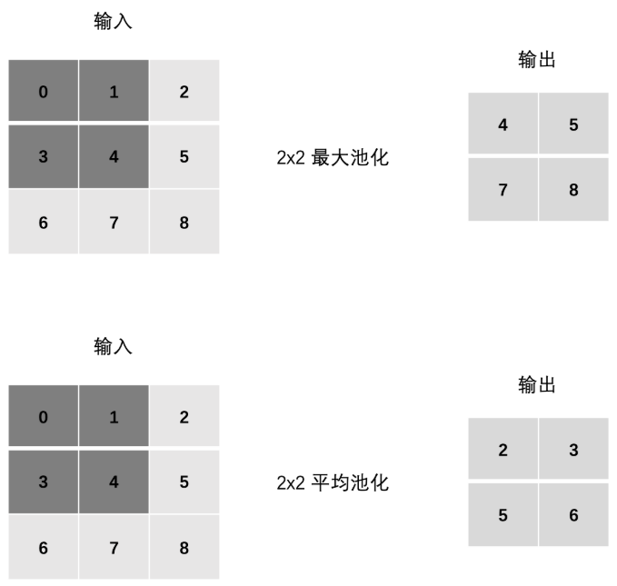
简单理解:最大池化就是"选最厉害的",平均池化就是"取平均值"。
多通道池化:池化层对每个输入通道分别独立池化,输出通道数 = 输入通道数。
python
import torch
import torch.nn as nn
# 单通道池化
inputs = torch.tensor([[[0., 1., 2.], [3., 4., 5.], [6., 7., 8.]]])
max_pool = nn.MaxPool2d(kernel_size=2, stride=1, padding=0)
avg_pool = nn.AvgPool2d(kernel_size=2, stride=1, padding=0)
print("最大池化:\n", max_pool(inputs))
print("平均池化:\n", avg_pool(inputs))
# 多通道池化
inputs_multi = torch.tensor([[[0., 1., 2.], [3., 4., 5.], [6., 7., 8.]],
[[10., 20., 30.], [40., 50., 60.], [70., 80., 90.]],
[[11., 22., 33.], [44., 55., 66.], [77., 88., 99.]]])
print("多通道最大池化:\n", max_pool(inputs_multi))二、循环神经网络(RNN)
1. RNN概述与序列数据
循环神经网络(Recurrent Neural Network, RNN) 是专门处理序列数据 的神经网络。与传统前馈神经网络不同,RNN具有"循环"结构,能够记住前面时间步的信息,适用于时间序列或有时序依赖的数据。
序列数据的核心特点:后面的数据跟前面的数据有关系。
举例来说,"我爱你"这三个词的顺序不能颠倒------"我"在"爱"前面,"爱"在"你"前面,顺序一变意思就完全变了。
RNN的典型应用场景:
| 应用领域 | 具体任务 |
|---|---|
| 自然语言处理(NLP) | 文本生成、机器翻译、情感分析 |
| 时间序列预测 | 股市预测、气象预测 |
| 语音识别 | 语音转文字 |
| 音乐生成 | 生成新乐曲 |
RNN的内部结构分为三层:词嵌入层 + RNN层 + 全连接层。
2. 词嵌入层
2.1 什么是词嵌入
自然语言是人类的语言,无法直接被神经网络处理。词嵌入层 的作用是把词(token)转换成向量 (即"词向量"),这个过程叫做向量化。
通俗比喻:词嵌入就像给每个词发一张"身份证",每张身份证上写着一串数字,这串数字代表了这个词的"特征"。
词嵌入层在RNN中的作用:
- 输入表示:将词转换为数值向量
- 降低维度:用低维向量表示高维稀疏信息
- 语义表示:相似词的词向量也相似
词嵌入矩阵的形状为:词表大小 × 词向量维度 ,例如100个词、每个词用128维向量表示,矩阵形状就是 100×128。
2.2 词嵌入的工作流程
文本 → 分词 → token序列 → 索引序列 → Embedding查表 → 词向量序列 → 输入模型2.3 PyTorch词嵌入API
在PyTorch中使用 nn.Embedding 实现词嵌入:
python
import torch
import torch.nn as nn
import jieba
if __name__ == '__main__':
# 文本数据
text = '北京冬奥的进度条已经过半,不少外国运动员在完成自己的比赛后踏上归途。'
# 1. 文本分词
words = jieba.lcut(text)
print('文本分词:', words)
# 2. 分词去重,获取词表
unique_words = list(set(words))
print('去重后词的个数:', len(unique_words))
# 3. 构建词嵌入层
# num_embeddings: 词的总数量
# embedding_dim: 词嵌入维度
embed = nn.Embedding(num_embeddings=len(unique_words), embedding_dim=4)
# 4. 词的词向量表示
for i, word in enumerate(unique_words):
word_vec = embed(torch.tensor(i))
print(f'{word:3s} -> {word_vec}')3. RNN网络结构
3.1 RNN的核心思想
RNN的"循环"体现在:每一时间步的输入不仅包含当前词的词向量,还包含上一时间步的隐藏状态(历史信息)。
- 输入 :当前时间步的输入值 xtx_txt(词向量)+ 上一时间步的隐藏状态 ht−1h_{t-1}ht−1
- 输出 :当前时间步的隐藏状态 hth_tht
- 隐藏状态:负责"记忆"序列数据中的历史信息,并在不同时间步之间传递
RNN的隐藏状态就像人的"短期记忆",它记录了到目前为止看到的所有词的信息。
3.2 RNN的计算过程
以用户意图识别任务为例,输入句子 "What time is it?":
- 将单词 "What" 输入RNN → 产生输出 O1O_1O1(隐层状态)
- 将单词 "time" 输入RNN → RNN不仅用"time",还结合上一步的隐层输出 O1O_1O1 → 产生 O2O_2O2
- 重复上述步骤,直到处理完所有单词
- 最后用最终的隐层输出 O5O_5O5 来判断用户意图
3.3 RNN的展开结构
RNN按时间步展开后,实际上是一系列权共享的神经网络,每一列代表一个时间步的循环单元。权共享是RNN节省参数的关键------不管句子有多长,用的是同一套权重。
4. RNN的PyTorch API
python
import torch
import torch.nn as nn
# RNN基本用法示例
rnn = nn.RNN(input_size=128, hidden_size=256, num_layers=2, batch_first=True)
# 输入: (batch, seq_len, input_size)
# 隐状态: (num_layers, batch, hidden_size)
inputs = torch.randn(32, 50, 128) # batch=32, 句子长度50, 词向量维度128
hidden = torch.zeros(2, 32, 256)
output, hidden = rnn(inputs, hidden)
print("输出形状:", output.shape) # (32, 50, 256)
print("隐状态形状:", hidden.shape) # (2, 32, 256)三、实操案例:CNN图像分类
池化后的图片有点渗人,就不在这展示了...
python
from matplotlib import pyplot as plt
import torch
# 读取图像
img = plt.imread("img.jpg")
plt.imshow(img)
plt.axis("off")
plt.show()
# 构建卷积层
torch.manual_seed(0)
conv = torch.nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3, stride=2, padding=1)
# 预处理:转换类型并归一化
img_tensor = torch.tensor(img, dtype=torch.float32) / 255.0
print(f"原始形状: {img_tensor.shape}")
# 调整维度:(H, W, C) -> (C, H, W)
img_tensor = img_tensor.permute(2, 0, 1)
print(f"调整后形状: {img_tensor.shape}")
# 添加 Batch 维度
img_tensor = img_tensor.unsqueeze(0)
print(f"升维后形状: {img_tensor.shape}")
# 通过卷积层
feature_map = conv(img_tensor)
print(f"特征图形状: {feature_map.shape}")
# 最大池化
max_pool = torch.nn.MaxPool2d(kernel_size=2, stride=2)
pooled = max_pool(feature_map)
print(f"池化后形状: {pooled.shape}")
# 可视化特征图
pooled_np = pooled.detach().squeeze().permute(1, 2, 0).numpy()
# 归一化到 [0, 1] 以便显示
pooled_np = (pooled_np - pooled_np.min()) / (pooled_np.max() - pooled_np.min() + 1e-8)
plt.imshow(pooled_np)
plt.axis("off")
plt.show()四、总结
核心对比
| 特性 | CNN(卷积神经网络) | RNN(循环神经网络) |
|---|---|---|
| 处理对象 | 图像(空间数据) | 序列数据(时间/文本) |
| 核心结构 | 卷积层 + 池化层 | 循环单元 + 隐藏状态 |
| 权值共享 | 卷积核在整个图像上共享 | 权重在不同时间步共享 |
| 记忆能力 | 无时间维记忆 | 有(通过隐藏状态传递) |
| 典型任务 | 图像分类、目标检测 | NLP、时间序列预测 |
| 改进版本 | ResNet、VGG、EfficientNet | LSTM、GRU |
核心知识点回顾
| 知识点 | 一句话总结 |
|---|---|
| 卷积运算 | 卷积核与图像局部区域做点积,提取特征 |
| Padding | 在图像边缘补0,防止卷积后图像缩小 |
| Stride | 卷积核滑动步长,影响特征图尺寸 |
| 池化层 | 下采样降维,保留显著特征 |
| 词嵌入 | 将词转换为固定维度的数值向量 |
| RNN隐藏状态 | 存储历史信息,在时间步之间传递 |
| 权值共享 | CNN和RNN都用同一套权重处理不同位置/时间步的数据,大幅减少参数量 |
CNN擅长处理"空间"信息,RNN擅长处理"时间/序列"信息。两者是深度学习在计算机视觉和自然语言处理领域的基石,后续的许多高级模型(如Transformer)都可以看作是它们的延伸和进化。