论文信息
- 标题:FDA: Fourier Domain Adaptation for Semantic Segmentation
- 会议:arXiv 2020
- 单位:UCLA Vision Lab
- 代码:https://github.com/YanchaoYang/FDA
- 论文:https://arxiv.org/pdf/2004.05498v1
一、引言:当游戏里的"老司机"到了现实就翻车
做语义分割的同学肯定都有过这样的痛苦经历:标注一张像素级的城市道路图要花好几个小时,人工标注成本高到离谱。于是大家想到了一个好办法------用游戏里的合成数据!比如GTA5里随便跑一跑就能得到几十万张带完美标注的图像,简直是标注自由的天堂。
但问题来了:在GTA5里训练出来的分割模型,拿到现实世界的Cityscapes数据集上一测,性能直接腰斩。这就是域偏移(Domain Shift):合成数据和真实数据的像素统计特性(光照、颜色、对比度)不一样,但高层次的语义内容(车、人、路)是一样的。就像你用美颜相机拍的照片训练了一个人脸识别模型,拿到原相机面前就认不出人了------脸还是那张脸,但低层次的"风格"变了。
之前解决这个问题的主流方法是对抗学习:训练一个生成器把合成图转成真实图的风格,再训练一个判别器来区分真假图。但对抗学习有多难调,懂的都懂:模式崩溃、训练不稳定、超参数多到爆炸,经常是调了一个月还不如 baseline。
而今天这篇论文给了我们一个惊掉下巴的解决方案:不需要训练任何额外网络,只需要做一次傅里叶变换,把源域图的低频振幅换成目标域的,就能搞定域适配。简单到离谱,效果却吊打当时所有的SOTA对抗学习方法。
二、核心思想:频率里藏着域偏移的秘密
2.1 傅里叶变换:把图像拆成"音符"
首先我们需要一个基础的信号处理知识:任何图像都可以表示为无数个不同频率的正弦波的叠加。
- 低频分量:决定图像的整体亮度、颜色、全局风格,对应图像里"大块"的区域
- 高频分量:决定图像的边缘、细节、纹理,对应图像里"尖锐"的部分
更重要的是:图像的语义内容几乎完全由相位分量决定,振幅分量主要决定风格。如果你把A图的振幅和B图的相位组合起来,得到的图像会几乎和B图一模一样,只是颜色和亮度有点像A图。
这就是FDA方法的核心洞察:既然域偏移主要体现在低层次的风格差异上,那我们直接把源域图的低频振幅换成目标域的,不就可以在不改变语义的前提下,把源域图"变成"目标域的风格了吗?
2.2 FDA的完整流程
图1展示了FDA的完整流程,简单到三步就能搞定:
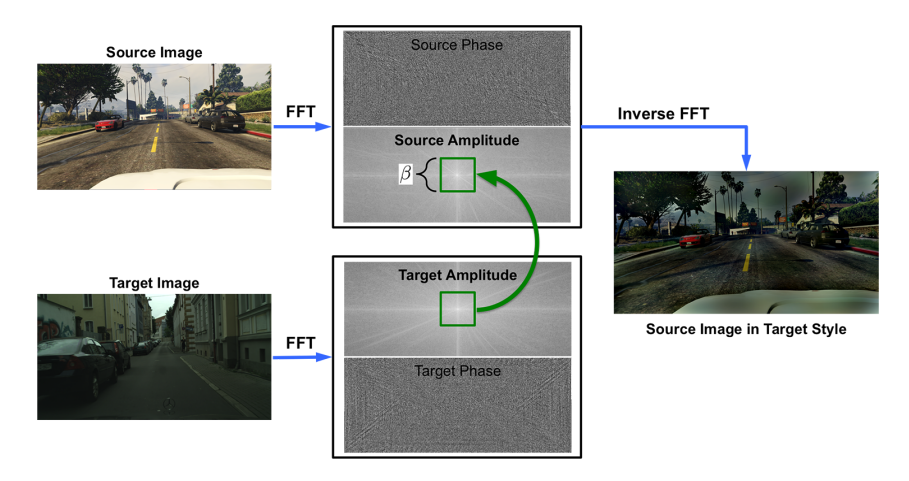
图1 频谱迁移示意图(出自原论文Figure 1)
- 对源图像和随机采样的目标图像分别做快速傅里叶变换(FFT),分离出振幅和相位分量
- 用一个中心掩码把源图像的低频振幅替换成目标图像的低频振幅,高频振幅和源图像的相位保持不变
- 对组合后的频谱做逆傅里叶变换(iFFT),得到风格为目标域、语义为源域的新图像
就是这么简单!没有生成器,没有判别器,没有对抗训练,只有两次FFT和一次元素相乘。
三、方法详解:公式与代码实现
3.1 傅里叶变换与逆变换
首先是二维傅里叶变换的公式,它把图像从像素空间转换到频率空间:
F(x)(m,n)=∑h,wx(h,w)e−j2π(hHm+wWn),j2=−1\mathcal{F}(x)(m, n)=\sum_{h, w} x(h, w) e^{-j 2 \pi\left(\frac{h}{H} m+\frac{w}{W} n\right)}, j^{2}=-1F(x)(m,n)=h,w∑x(h,w)e−j2π(Hhm+Wwn),j2=−1
- F(x)\mathcal{F}(x)F(x):图像xxx的二维傅里叶变换结果
- x(h,w)x(h, w)x(h,w):原始图像在坐标(h,w)(h, w)(h,w)处的像素值
- H,WH, WH,W:图像的高度和宽度
- m,nm, nm,n:频率域的坐标,对应不同的频率分量
- jjj:虚数单位,满足j2=−1j^2=-1j2=−1
通俗解释:这个公式就像把一首曲子从波形图转换成五线谱,每个"音符"对应一个频率分量,告诉你这个频率的正弦波在图像里有多大的"音量"(振幅)和"相位"。
3.2 频率掩码与FDA核心公式
我们用一个中心掩码来控制要交换的低频区域大小:
Mβ(h,w)=1(h,w)∈−βH:βH,−βW:βWM_{\beta}(h, w)=\mathbb{1}_{(h, w) \in-\\beta H: \\beta H,-\\beta W: \\beta W}Mβ(h,w)=1(h,w)∈−βH:βH,−βW:βW
- MβM_\betaMβ:频率域的中心掩码,只保留中心β\betaβ比例的区域
- β\betaβ:控制交换低频区域大小的超参数,取值在(0,1)(0,1)(0,1)之间,和图像分辨率无关
- 1\mathbb{1}1:指示函数,满足条件时为1,否则为0
通俗解释 :这个掩码就像一个正方形的"滤镜",只让频率域中心的低频分量通过。β\betaβ越大,滤镜越大,交换的低频信息越多。
然后是FDA的核心转换公式:
xs→t=F−1(Mβ∘FA(xt)+(1−Mβ)∘FA(xs),FP(xs))x^{s \to t}=\mathcal{F}^{-1}\left(\leftM_{\\beta} \\circ \\mathcal{F}\^{A}\\left(x\^{t}\\right)+\\left(1-M_{\\beta}\\right) \\circ \\mathcal{F}\^{A}\\left(x\^{s}\\right), \\mathcal{F}\^{P}\\left(x\^{s}\\right)\\right\right)xs→t=F−1(Mβ∘FA(xt)+(1−Mβ)∘FA(xs),FP(xs))
- xs→tx^{s \to t}xs→t:经过FDA转换后,风格为目标域、语义为源域的图像
- F−1\mathcal{F}^{-1}F−1:逆傅里叶变换,把频率域信号转回像素空间
- ∘\circ∘:哈达玛积,即两个矩阵对应元素相乘
- FA(x)\mathcal{F}^{A}(x)FA(x):图像xxx傅里叶变换后的振幅分量
- FP(x)\mathcal{F}^{P}(x)FP(x):图像xxx傅里叶变换后的相位分量
- xsx^sxs:源域图像(带标注的合成图像)
- xtx^txt:目标域图像(无标注的真实图像)
通俗解释:这个公式做了三件事:
- 把源图和目标图都转成频率域,分开振幅和相位
- 用掩码把源图的低频振幅换成目标图的,高频振幅保留源图的
- 保留源图的所有相位信息(因为相位决定语义),然后一起转回像素空间
3.3 超参数β\betaβ的选择
β\betaβ是FDA唯一的超参数,它的选择直接影响转换效果。图2展示了不同β\betaβ值的转换结果:

图2 不同β\betaβ值的转换效果(出自原论文Figure 2)
可以看到:
- β=0\beta=0β=0:转换后的图像和原图完全一样
- β\betaβ增大:图像越来越像目标域的风格
- β\betaβ过大:会引入明显的伪影(比如图中放大的区域有奇怪的纹理)
论文通过实验发现,β≤0.15\beta \leq 0.15β≤0.15时效果最好,既能有效缩小域差距,又不会引入过多伪影。
有趣案例 :β\betaβ就像你调美颜的程度,调小了没效果,调大了脸都变形了,得找个合适的度。论文里用了β=0.01,0.05,0.09\beta=0.01, 0.05, 0.09β=0.01,0.05,0.09三个值,效果都很好。
3.4 核心代码实现
下面是用PyTorch实现的FDA转换函数,完全对应论文中的公式,核心代码只有几十行:
python
import torch
import torch.fft as fft
def fda_transform(source_img, target_img, beta=0.09):
"""
傅里叶域自适应(FDA)转换函数
Args:
source_img: 源域图像,shape: [B, C, H, W],像素值范围[0, 255]
注意:论文要求在[0,255]范围做FFT,不要先做均值减法
target_img: 目标域图像,shape: [B, C, H, W],像素值范围[0, 255]
beta: 控制交换低频区域大小的超参数,建议≤0.15
Returns:
adapted_img: 转换后的源域图像,shape: [B, C, H, W]
"""
# 1. 二维快速傅里叶变换,并将零频率分量移到频谱中心
fft_source = fft.fftshift(fft.fft2(source_img, dim=(-2, -1)), dim=(-2, -1))
fft_target = fft.fftshift(fft.fft2(target_img, dim=(-2, -1)), dim=(-2, -1))
# 2. 分离振幅和相位分量
amp_source = torch.abs(fft_source)
phase_source = torch.angle(fft_source)
amp_target = torch.abs(fft_target)
# 3. 创建中心掩码
B, C, H, W = source_img.shape
h_mask = int(beta * H / 2) # 掩码半高
w_mask = int(beta * W / 2) # 掩码半宽
mask = torch.ones((H, W), device=source_img.device)
# 中心区域设为0(需要替换为目标域振幅的部分)
mask[H//2 - h_mask : H//2 + h_mask, W//2 - w_mask : W//2 + w_mask] = 0
# 4. 交换低频振幅:源域高频 + 目标域低频
amp_adapted = amp_source * mask + amp_target * (1 - mask)
# 5. 组合振幅和相位,逆FFT转回像素空间
fft_adapted = amp_adapted * torch.exp(1j * phase_source)
adapted_img = torch.real(fft.ifft2(fft.ifftshift(fft_adapted, dim=(-2, -1)), dim=(-2, -1)))
# 6. 裁剪到[0, 255]范围,避免数值溢出
adapted_img = torch.clamp(adapted_img, 0, 255)
return adapted_img3.5 训练损失函数
经过FDA转换后,我们就可以用转换后的源域图像和原来的标注来训练分割网络了。为了进一步提升性能,论文还加入了熵正则化和多带迁移自监督训练。
3.5.1 基础交叉熵损失
这是语义分割最基础的损失函数,让网络在转换后的源域图像上学习分割:
Lce(ϕw;Ds→t)=−∑i⟨yis,log(ϕw(xis→t))⟩\mathcal{L}{c e}\left(\phi^{w} ; D^{s \to t}\right)=-\sum{i}\left\langle y_{i}^{s}, log \left(\phi^{w}\left(x_{i}^{s \to t}\right)\right)\right\rangleLce(ϕw;Ds→t)=−i∑⟨yis,log(ϕw(xis→t))⟩
- Lce\mathcal{L}_{ce}Lce:交叉熵损失函数
- ϕw\phi^wϕw:参数为www的语义分割网络
- Ds→tD^{s \to t}Ds→t:经过FDA转换后的源域数据集
- yisy_i^syis:源域图像xisx_i^sxis对应的语义标注
- ⟨⋅,⋅⟩\langle \cdot, \cdot \rangle⟨⋅,⋅⟩:向量内积
3.5.2 鲁棒熵正则化损失
为了让网络在目标域图像上的预测更自信,我们加入熵正则化损失。论文使用了Charbonnier惩罚函数来替代普通的L1/L2惩罚,它会更严厉地惩罚高熵预测:
Lent(ϕw;Dt)=∑iρ(−⟨ϕw(xit),log(ϕw(xit))⟩)\mathcal{L}{ent }\left(\phi^{w} ; D^{t}\right)=\sum{i} \rho\left(-\left\langle\phi^{w}\left(x_{i}^{t}\right), log \left(\phi^{w}\left(x_{i}^{t}\right)\right)\right\rangle\right)Lent(ϕw;Dt)=i∑ρ(−⟨ϕw(xit),log(ϕw(xit))⟩)
其中Charbonnier惩罚函数为:
ρ(x)=(x2+0.0012)η\rho(x)=(x^{2}+0.001^{2})^{\eta}ρ(x)=(x2+0.0012)η
- Lent\mathcal{L}_{ent}Lent:熵正则化损失
- DtD^tDt:目标域数据集(无标注)
- ρ(x)\rho(x)ρ(x):Charbonnier惩罚函数
- η\etaη:控制惩罚强度的参数,论文中使用η=2.0\eta=2.0η=2.0
图3展示了不同η\etaη值的Charbonnier惩罚函数曲线:
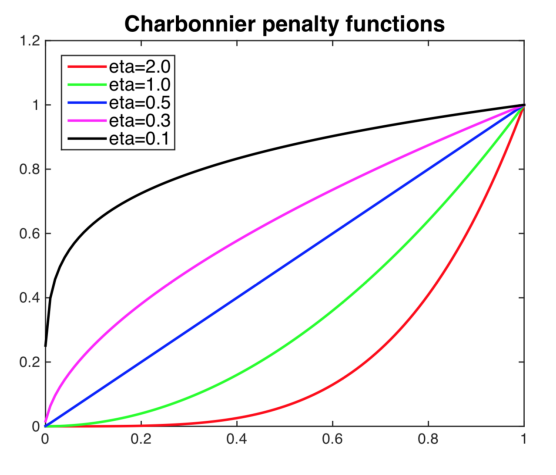
图3 Charbonnier惩罚函数(出自原论文Figure 3)
通俗解释:这个损失就像老师改作业,错得越离谱(预测熵越高),扣的分越多。普通的熵最小化对"差不多对"的预测惩罚太轻,而Charbonnier惩罚能让网络更果断。
3.5.3 总损失函数
基础训练阶段的总损失是交叉熵损失和熵正则化损失的加权和:
L(ϕw;Ds→t,Dt)=Lce(ϕw;Ds→t)+λentLent(ϕw;Dt)\mathcal{L}\left(\phi^{w} ; D^{s \to t}, D^{t}\right)=\mathcal{L}{c e}\left(\phi^{w} ; D^{s \to t}\right)+\lambda{ent } \mathcal{L}_{ent }\left(\phi^{w} ; D^{t}\right)L(ϕw;Ds→t,Dt)=Lce(ϕw;Ds→t)+λentLent(ϕw;Dt)
- λent\lambda_{ent}λent:熵损失的权重,论文中使用λent=0.005\lambda_{ent}=0.005λent=0.005
3.6 多带迁移(MBT)与自监督训练
论文发现,不同β\betaβ训练的模型在不同类别上表现最好。比如β=0.09\beta=0.09β=0.09的模型在道路上表现好,β=0.01\beta=0.01β=0.01的模型在行人上表现好。于是论文提出了多带迁移 (Multi-band Transfer):训练多个不同β\betaβ的模型,用它们的平均预测作为伪标签,再进行自监督训练。
多模型平均预测公式:
y^it=argmaxk1M∑mϕβmw(xit)\hat{y}{i}^{t}=arg max {k} \frac{1}{M} \sum{m} \phi{\beta_{m}}^{w}\left(x_{i}^{t}\right)y^it=argmaxkM1m∑ϕβmw(xit)
- y^it\hat{y}_i^ty^it:目标域图像xitx_i^txit的伪标签
- MMM:不同β\betaβ训练的模型数量,论文中使用3个(β=0.01,0.05,0.09\beta=0.01, 0.05, 0.09β=0.01,0.05,0.09)
- ϕβmw\phi_{\beta_m}^wϕβmw:第mmm个用βm\beta_mβm训练的分割网络
通俗解释:就像三个专家一起投票,每个专家擅长不同的领域,投票结果比单个专家更准确。
自监督训练阶段的总损失在基础损失上增加了伪标签的交叉熵损失:
Lsst(ϕw;Ds→t,D^t)=Lce(ϕw;Ds→t)+λentLent(ϕw;Dt)+Lce(ϕw;D^t)\begin{aligned} \mathcal{L}{s s t}\left(\phi^{w} ; D^{s \to t}, \hat{D}^{t}\right) & =\mathcal{L}{c e}\left(\phi^{w} ; D^{s \to t}\right) \\ +\lambda_{ent } \mathcal{L}{ent }\left(\phi^{w} ; D^{t}\right)+\mathcal{L}{c e}\left(\phi^{w} ; \hat{D}^{t}\right) \end{aligned}Lsst(ϕw;Ds→t,D^t)+λentLent(ϕw;Dt)+Lce(ϕw;D^t)=Lce(ϕw;Ds→t)
- D^t\hat{D}^tD^t:添加了伪标签的目标域数据集
完整的训练流程是:
- 用基础损失训练3个不同β\betaβ的分割模型
- 用这3个模型的平均预测生成目标域的伪标签
- 用自监督损失再训练这3个模型,重复两轮
四、实验结果:简单方法吊打复杂对抗学习
4.1 实验设置
论文在两个标准的合成到真实的无监督域适配任务上进行了评估:
- GTA5→Cityscapes:源域是GTA5合成数据集(24966张图像),目标域是Cityscapes真实数据集(2975张训练,500张验证)
- SYNTHIA→Cityscapes:源域是SYNTHIA合成数据集(9400张图像),目标域同上
使用了两个主流的语义分割网络作为backbone:
- DeepLabV2 + ResNet101
- FCN-8s + VGG16
4.2 消融实验
表1展示了GTA5→Cityscapes任务的消融实验结果:
表1 GTA5→Cityscapes任务的消融实验(出自原论文Table 1)
| 实验设置 | mIoU |
|---|---|
| β=0.01 (T=0) | 44.61 |
| β=0.05 (T=0) | 44.60 |
| β=0.09 (T=0) | 45.01 |
| Cycada19 (对抗学习SOTA) | 42.70 |
| β=0.09 (λ_ent=0) | 44.64 |
| β=0.09 (单模型自训练) | 45.42 |
| MBT (T=0, 多模型平均) | 46.77 |
| MBT (T=2, 两轮自训练) | 50.45 |
关键发现:
- FDA对β的选择非常鲁棒:不同β的单模型性能几乎一样
- 零正则化也能吊打对抗学习:即使不用熵正则化(λ_ent=0),FDA也比当时的SOTA对抗学习方法Cycada高1.94%mIoU
- 多模型平均提升巨大:单模型自训练只提升了0.41%,而多模型平均直接提升了1.76%
- 最终效果惊人:经过两轮自训练的MBT达到了50.45%mIoU,远超所有对抗学习方法
4.3 基准对比
表2和表3分别展示了在两个任务上和其他SOTA方法的定量对比:
表2 GTA5→Cityscapes任务的定量对比(出自原论文Table 2)
| Backbone | 方法 | mIoU |
|---|---|---|
| ResNet101 | Cycada19 | 42.7 |
| CLAN29 | 43.2 | |
| DLOW17 | 42.3 | |
| AdvEnt45 | 45.5 | |
| BDL23 (之前SOTA) | 48.5 | |
| FDA (单尺度) | 44.6 | |
| FDA-ENT (单尺度+熵正则) | 45.0 | |
| FDA-MBT (多尺度+自训练) | 50.45 | |
| VGG16 | BDL23 | 41.3 |
| FDA-MBT | 42.2 |
表3 SYNTHIA→Cityscapes任务的定量对比(出自原论文Table 3)
| Backbone | 方法 | mIoU (13类) |
|---|---|---|
| ResNet101 | BDL23 | 51.4 |
| FDA-MBT | 52.5 | |
| VGG16 | BDL23 | 39.0 |
| FDA-MBT | 40.5 |
结论:
- 单尺度FDA已经超过了大部分对抗学习方法
- 加上熵正则化的FDA-ENT和当时最先进的AdvEnt、ABStruct等方法相当
- FDA-MBT在两个任务上都达到了SOTA,在GTA5→Cityscapes上比BDL高1.95%,在SYNTHIA→Cityscapes上比BDL高1.1%(ResNet101)和1.5%(VGG16)
- FDA在不同backbone上都表现出色,证明了方法的通用性
4.4 定性结果
图5展示了和BDL方法的定性对比:

图5 定性结果对比(出自原论文Figure 5)
从左到右依次是:输入图像、真实标注、BDL预测、FDA-MBT预测。可以看到:
- FDA-MBT的预测更平滑,比如第一行和第四行的道路,第三行的墙壁
- FDA-MBT能更好地保留精细结构,比如第五行的电线杆
- FDA-MBT对稀有类别的识别更好,比如第二行的卡车,第三、四行的自行车
五、讨论与启示
这篇论文最震撼的地方在于:用一个零训练成本的简单操作,解决了一个被认为需要复杂对抗学习才能解决的问题。它给我们带来了几个重要的启示:
-
不要盲目追求复杂模型:很多时候,从数据本身入手,用基础的信号处理方法就能得到意想不到的效果。傅里叶变换已经发明了200多年,没想到在2020年还能在深度学习领域搞出大新闻。
-
低层次统计差异是域偏移的主要原因:深度学习模型其实很"笨",它们很容易被低层次的像素统计变化干扰,而对高层次的语义变化不敏感。FDA直接在数据层面消除了低层次差异,比让模型自己学习要高效得多。
-
已知的干扰因素不需要学习:我们知道光照、颜色这些因素不会影响语义,那为什么还要让模型花大力气去学习它们呢?直接在预处理阶段消除掉不好吗?FDA就是这个思路的完美体现。
当然,FDA也不是万能的。它主要针对低层次的域偏移,对于高层次的语义偏移(比如不同场景下物体的分布差异)效果有限。但它为无监督域适配领域打开了一扇新的大门,后续有很多工作都基于FDA进行了扩展。
六、总结
FDA是一个极具创新性的无监督域适配方法,它的核心思想是利用傅里叶变换分离图像的语义和风格,通过交换低频振幅来实现域对齐。它具有以下优势:
- 零训练成本:不需要训练任何额外网络,只需要FFT和逆FFT
- 简单易实现:核心代码只有几十行,没有复杂的超参数
- 性能SOTA:超过了当时所有的对抗学习方法
- 通用性强:可以和任何语义分割网络结合,也可以扩展到其他视觉任务
这篇论文告诉我们:有时候,最简单的方法反而是最有效的。在深度学习的浪潮中,我们不要忘记那些经典的信号处理和数学工具,它们可能会给我们带来意想不到的惊喜。