特征选择虽能提升脑影像机器学习模型的预测性能,但被剔除的弱连接特征同样蕴含显著预测能力。《Nature Human Behaviour》刊发的这项研究通过四个大规模数据集(超1.2万人)验证:依据关联强度将脑连接特征划分为互不重叠的十分位组后,排名靠后的特征组在认知、发育及精神疾病表型预测中的表现与高排名组相当,且能成功泛化至外部队列。同时研究警示,过度依赖特征选择可能会歪曲对神经生物学机制的解释,强调全脑广泛分布的微弱信号不容忽视,这对提升模型可解释性与可重复性具有重要启示。
摘要
人类神经影像学的核心目标之一是揭示认知与心理健康背后的神经生物学机制。与传统 MRI 研究相比,基于神经影像数据训练的机器学习模型正越来越多地被用于预测行为表型、提升精准医疗水平并改善模型的泛化能力。 然而,脑连接数据的高维特性使得模型解释面临着巨大挑战。当前的主流方法依赖于特征选择,并隐含地将所选特征网络视为特定表型的独特标志,而忽略了其他特征网络。 尽管特征选择应用广泛,但其如何在简化模型与避免因过度简化而扭曲真实神经生物学机制之间取得平衡,仍未得到充分研究。为此,本研究利用四个大规模神经影像数据集(涵盖超过12000名参与者和13种结局变量)来证明被特征选择所剔除的连接边仍能实现显著的预测精度,同时会产生迥异的神经生物学解释。这一结果在认知、发育和精神疾病表型中均得到验证,不管是功能连接组(fMRI)还是结构连接组(DTI),甚至在外部队列验证中依然显著。这表明,仅关注排名靠前的特征可能简化了脑与行为关联的神经生物学基础。当某些被忽视的特征可能同样具有意义时,那么这些解释所呈现的仅为冰山一角,这可能加剧该领域内长期存在的可重复性问题。 总的来说,本研究结果强调,那些分布在全脑、看起来不起眼的微弱信号不应被忽视。
引言
人类神经影像学的一个核心目标是揭示认知与心理健康的神经生物学基础。与此目标一致,新兴的机器学习方法利用大脑结构和功能数据来预测行为表型中的个体差异。相较于传统的 MRI **研究,这些脑与行为预测模型通过将数据集划分为训练样本和测试样本,减少了过拟合现象,并提供了更为稳健的关联性评估。**同时,它们还为推进精准医疗策略提供了契机,涵盖从疾病亚型划分到个体治疗反应预测等多个方面。因此,大量研究工作致力于提高模型的准确性、可信度、公平性、可重复性以及泛化能力。
神经生物学可解释性,即模型结果能够映射至已知神经环路与生理过程的程度,是衡量模型效用的另一关键指标。 一个易于解释的模型,即便预测性能平平,也能揭示负责特定行为的神经环路。然而,对基于神经影像数据的机器学习模型进行解释仍面临诸多挑战。为获得对高维数据更易于处理的特征表达,该领域普遍采用单变量特征选择方法,即逐一评估脑特征与目标表型之间的关联,并筛选出单变量效应量最强的特征用于建模,其余特征则被丢弃。尽管特征选择可以缩短训练时间、提升预测性能并简化模型可解释性,但它可能会忽略那些信号较弱但在神经生物学层面具有意义的特征。
传统上,被选中的特征被解释为所预测表型个体差异背后的神经生物学基础。例如,模型通常以其预测的表型来命名。通过将选中的特征视为确定性依据,这些做法给人留下一种印象,即该模型唯一地表征了该表型的神经相关物。未被选中的特征则被视为对模型性能及神经生物学意义贡献甚微,甚至在某些情况下是无关紧要的。
因此,特征选择可能存在着歪曲行为个体差异背后神经生物学机制的风险。 大脑与真实世界表型之间的关联,很可能最佳地由具有微小效应量的广泛分布神经环路来表征。传统的单变量方法,包括单变量特征选择,可能仅允许最稳健、最直接的关联得以保留。然而,近期研究表明,单变量效应量较弱的特征往往可以组合起来,产生与强关联特征相当的预测精度。这表明,特征选择可能过度简化了支撑行为的复杂神经生物学机制。**如果在选择过程中被丢弃的特征确实承载着有意义的预测信息,那么将结果解释局限于排名靠前的特征,便人为截断了神经生物学的复杂性。**尽管单变量特征选择应用广泛,但其如何在简化模型与因过度简化而歪曲真实神经生物学机制之间取得平衡,这一问题仍未得到充分研究。
在这里,本研究检验了未被特征选择所保留的特征是否对预测及神经生物学解释具有实际意义。分析涵盖了四个大规模神经影像数据集中的 12200 名参与者,涉及功能连接和结构连接两种模态,以及包括年龄、性别、认知能力、发育指标和精神疾病表型在内的 13 **种结局变量。**本研究采用一种原创的预测范式,根据连接组特征与目标表型之间的关联程度,将其划分为互不重叠的子集。结果发现,多个被特征选择所忽略的子集能够产生显著的预测精度,但却带来迥异的生物学解释。这些结果表明,仅关注排名靠前的特征可能会描绘出一幅不完整的神经生物学图景,并进一步强调了分布于全脑的微弱信号不应被忽视。此外,针对同一表型可能存在多种神经生物学层面截然不同的模型,这一发现对识别临床或研究人群中有意义的亚型具有重要启示。
方法
数据集
费城神经发育队列 **(PNC)**的参与者招募自宾夕法尼亚州大费城地区的1291名年龄在8至21岁之间的个体。所有影像数据采集均在宾夕法尼亚大学医院的同一台扫描仪上完成。参与者完成了静息态、情绪任务及N-back任务的fMRI扫描。语言能力测量采用了宾夕法尼亚大学计算机化神经认知成套测验中的宾夕法尼亚言语推理任务,以及广泛性成就测验阅读分量表的标准总分。执行功能测量则采用了计算机化神经认知成套测验中的字母N-back任务、条件排除任务及持续表现任务。
健康脑网络队列 **(HBN)**的参与者招募自纽约州纽约市地区的1110名年龄在6至17岁之间的个体。这项多中心研究的影像数据采集分别于斯塔滕岛、罗格斯大学脑成像中心、花旗康奈尔脑成像中心以及纽约市立大学高等科学研究中心的移动MRI扫描仪上完成。参与者完成了两次静息态fMRI扫描,以及观看电影《Despicable Me》和《The Present》时的扫描任务。语言能力测量采用了语音加工综合测验中的音素省略、词语混合、假词复述、快速数字命名及快速字母命名的量表分数,以及单词阅读效率测验中的音位解码效率、常见词阅读效率及总单词阅读效率的量表分数。执行功能测量采用了美国国立卫生研究院(NIH)工具箱中的侧抑制任务、列表排序工作记忆任务、模式比较加工速度任务以及维度变化卡片分类任务的年龄校正标准分。
为筛选出具有显著效应量的发育及精神疾病表型,本研究首先使用原始的连接组预测模型框架进行预测。通过对575名拥有全部71个测量指标完整数据的HBN参与者进行预测测试,本研究识别出了预测性能r>0.10的量表及分量表。此过程共筛选出13个量表及分量表。随后使用拥有全部13个量表数据的747名参与者重复了预测。其中,6个量表达到了r≥0.15的预测性能,并被用于基于十分位数的预测范式,这6个量表分别为:社交沟通问卷评分、长处与困难问卷中的多动量表评分、焦虑相关障碍筛查量表中的分离焦虑评分、康纳斯自我报告量表第三版中的学习问题评分,以及网络成瘾测验与亲子网络成瘾测验评分。
人类连接组计划发育队列 **(HCPD)**的参与者招募自密苏里州圣路易斯、明尼苏达州双城、马萨诸塞州波士顿以及加利福尼亚州洛杉矶的428名个体,年龄范围为8至22岁。这项多中心研究的影像数据采集分别在明尼苏达大学、圣路易斯华盛顿大学、哈佛大学以及加州大学洛杉矶分校完成。参与者完成了静息态fMRI扫描。语言能力测量采用了NIH工具箱中的图片词汇及口语阅读识别的年龄校正标准分。执行功能测量采用了该工具箱中的侧抑制任务、列表排序工作记忆任务、模式比较加工速度任务、维度变化卡片分类任务及图片序列记忆任务的年龄校正标准分。
青少年脑与认知发育研究队列 **(ABCD)**的参与者招募自美国21个研究站点的9371名年龄在9至10岁之间的个体。这些站点包括:洛杉矶儿童医院、佛罗里达国际大学、劳瑞特脑研究所、南卡罗来纳医科大学、俄勒冈健康与科学大学、斯坦福国际研究院、加州大学圣地亚哥分校、加州大学洛杉矶分校、科罗拉多大学博尔德分校、佛罗里达大学、马里兰大学巴尔的摩分校、密歇根大学、明尼苏达大学、匹兹堡大学、罗切斯特大学、犹他大学、佛蒙特大学、威斯康星大学密尔沃基分校、弗吉尼亚联邦大学、圣路易斯华盛顿大学以及耶鲁大学。认知测量采用了NIH工具箱中的流体智力、晶体智力及综合智力的年龄校正分数。
fMRI数据预处理
所有数据集中的数据均进行了头动校正。额外的预处理步骤使用BioImage Suite软件执行,包括从功能数据中回归掉不感兴趣的协变量,如线性漂移和二次漂移、平均脑脊液信号、平均白质信号以及平均全脑信号。通过回归一个包含24个参数的头动模型来进一步控制头动,该模型包含六个刚体头动参数、六个时间导数以及这些项的平方。随后,使用高斯滤波器进行时间平滑,并参照标准空间进行灰质掩膜处理。然后应用Shen 268节点图谱将降噪后的数据分割为268个节点。最后,通过计算每对节点时间序列数据之间的相关性并应用Fisher变换,生成功能连接矩阵。
数据剔除基于以下任一标准:数据质量不佳、全脑覆盖不全所致节点缺失、头动幅度过大 ( > 0.2mm) **,以及行为或表型数据缺失。**每个参与者的连接组均包含其全部可用的、符合低头动标准(<0.2mm)的静息态与任务态fMRI数据。针对单个条件创建独立的连接组,然后进行平均。通过合并不同fMRI数据来源的连接组,可有效提升信度与预测效力。任何不具备至少一次符合低头动要求的fMRI扫描的参与者均被剔除。具体而言,在PNC中,共有246名参与者因图像质量或头动问题被剔除,61名因表型数据不完整被剔除;HBN中,1387名因图像质量或头动问题被剔除,829名因表型数据不完整被剔除;HCPD中,57名因图像质量或头动问题被剔除,167名因表型数据不完整被剔除;ABCD中,342名因表型数据不完整被剔除。
ABCD弥散张量数据预处理
FIB文件下载自https://brain.labsolver.org。依据该网站说明,成像采用多壳层弥散方案,b值分别设为500、1000、2000及3000s/mm²,弥散采样方向数分别为6、15、15及60个。平面内分辨率为1.7mm,层厚为1.7mm。弥散磁共振成像数据经旋转以对齐前后联合连线,各向同性分辨率为1.7mm。受限弥散程度采用受限弥散成像进行量化。弥散数据使用广义q空间采样成像进行重建,弥散采样长度比率设为1.25。张量指标基于b值低于1750s/mm²的弥散加权图像进行计算。
全脑纤维追踪使用DSI-Studio完成,并以定量各向异性值(QA)作为终止阈值。首先在每位受试者个体空间内逐体素计算QA值,随后采用统计参数映射非线性配准算法,基于该值将大脑图像配准至蒙特利尔神经学研究所(MNI)标准空间模板。然后,再次以每体素三个纤维方向、平均弥散距离1.25mm的参数重建自旋密度函数。纤维追踪在DSI-Studio中执行,参数设置如下:角度截止60°、步长1.0mm、最短长度30mm、自旋密度函数平滑0.0、最长长度300mm,以及由弥散加权成像信号确定的QA值。采用改进的FACT算法进行确定性纤维追踪,直至为每个个体重建出一千万条流线。个体结构连接组基于MNI空间中的Shen图谱(含268个节点)构建:两两节点之间的连接强度定义为连接每条纤维两个端区的平均QA值,并以0.001作为阈值,最终为每位参与者生成一个268×268的邻接矩阵。
创建语言能力与执行功能的潜在因子
无论机器学习模型是用于现实世界预测还是深化我们对神经生物学的理解,克服数据集特有的异质性都是至关重要的。PNC、HCPD及HBN分别采用不同的测量工具来评估执行功能与语言能力。为协调这些测量指标并实现跨数据集的直接比较,本研究使用主成分分析(PCA)在各数据集内部推导出执行功能和语言能力的潜在因子。简言之,对行为测量指标应用PCA以降低测量噪声,并为每个认知领域提取单一复合因子。拥有影像数据的参与者的行为指标随后被投影至第一主成分上。在 PNC 、 HBN 和 HCPD 中,第一主成分分别解释了语言测量指标方差的 70% 、 55% 与 77% ,以及执行功能测量指标方差的 53% 、 48% 与 40% 。
基于十分位数的连接组预测模型(CPM)
本研究对原有的连接组预测模型 (CPM) **框架进行了改进,以评估不同关联强度水平下的连接特征对目标表型的预测效能。**对于数据集内预测,共执行了100次十折交叉验证迭代。在每一折中,模型于约90%的数据上进行训练,并在剩余的10%数据上进行测试。对于每个目标表型,在每一折内,首先计算训练子集中所有参与者每条连接边与目标表型之间的Pearson相关系数。该单变量分析为每一特征提供了关联强度的度量。随后,特征依据其相关系数绝对值降序排列,以确保在排序过程中正负关联得到同等考虑。排序完成后,全部连接特征被划分为十个互不重叠的十分位组,每个十分位组包含总特征数的10%。其中,十分位组1由与目标表型关联最强的前10%特征构成,而十分位组10则由关联最弱的后10%特征构成。模型分别利用每个十分位组进行预测,并在该折的测试集上进行验证。对于敏感性分析,本研究在建立脑连接边与各表型之间关联的步骤中,进一步采用偏相关方法对非关注变量加以控制,从而构建独立的预测模型。
岭回归连接组预测模型
为更好地适应连接数据的高维特性,本研究使用岭回归连接组预测模型重复了上述分析。具体而言,由于功能连接矩阵具有半正定性质,各连接边之间并非相互独立,在此情形下,岭回归相较于普通最小二乘法表现出更强的稳健性。不同于对选定边进行求和并拟合一维普通最小二乘模型的做法,本研究直接利用全部任务中选定的连接边,在训练个体上拟合岭回归模型,并在交叉验证框架下将该模型应用于测试个体。L2正则化参数λ通过每一折训练数据上的贝叶斯优化进行选择。具体来说,调用MATLAB的fitrlinear函数并启用自动超参数优化,以选取能使训练集交叉验证均方误差最小化的λ值。所有超参数调优均严格限定于训练数据内部完成,以避免信息泄露。
十分位特征比较
为量化不同特征十分位组之间模型权重的共享方差,本研究计算了不同十分位组模型之间的r2值。对于节点层面的比较,将岭回归模型的连接边权重于Shen图谱定义的268个脑区内分别求和,为每个模型生成一个268维的节点重要性向量。这些向量之间的r2值反映了不同十分位组模型在节点层面权重分布上所共享的方差比例。对于网络层面的比较,将每条边的权重于55个经典功能网络内取均值,为每个模型生成一个网络层面的权重向量,随后计算不同十分位组之间这些向量的r2值,以反映特征权重在网络层面分布的相似程度。
对于连接组预测模型,分析方法与此类似,不同之处在于使用二值化选择掩膜代替连续权重。通过将每个节点的二值化边选择结果求和来创建节点重要性向量,并通过在每个网络内对二值化选择结果取平均来生成网络层面向量。随后计算不同十分位组之间这些二值化向量的r2值,以评估特征间的相似性。
代码可用性
分析使用MATLAB v.R2024a版本完成。代码可通过GitHub获取(https://github.com/brendan-adkinson/overlooked-features)。预处理采用Bioimage Suite v.3.01执行,该软件可免费获取(https://medicine.yale.edu/bioimaging/suite/)。额外预处理步骤采用人类连接组计划最小预处理流程v.3.4.0版本(https://github.com/Washington-University/HCPpipelines/releases)执行。
结果
本研究对连接组预测模型进行了改进,依据连接组特征与目标表型之间的关联强度,将特征划分为十个互不重叠的十分位组(图1a)。具体而言,为防止数据泄露,在训练集中计算每条连接边与目标表型之间的Pearson相关系数。随后,特征依据其相关系数绝对值降序排列。排序完成后,全部连接特征被划分为十个互不重叠的十分位组,其中第一个十分位组包含关联最强的前10%特征,而最后一个十分位组则包含后10%的特征。随后,每个十分位组分别用于在相应测试集中对感兴趣表型进行预测。模型采用100次十折交叉验证进行训练。模型性能通过Pearson相关系数、交叉验证决定系数以及均方误差进行评估,其中Pearson相关系数代表预测行为分数与实际行为分数之间的一致性。显著性通过1000次随机打乱行为数据标签的置换检验进行评估。与先前工作一致,本研究未对连接组预测模型应用Haufe变换。
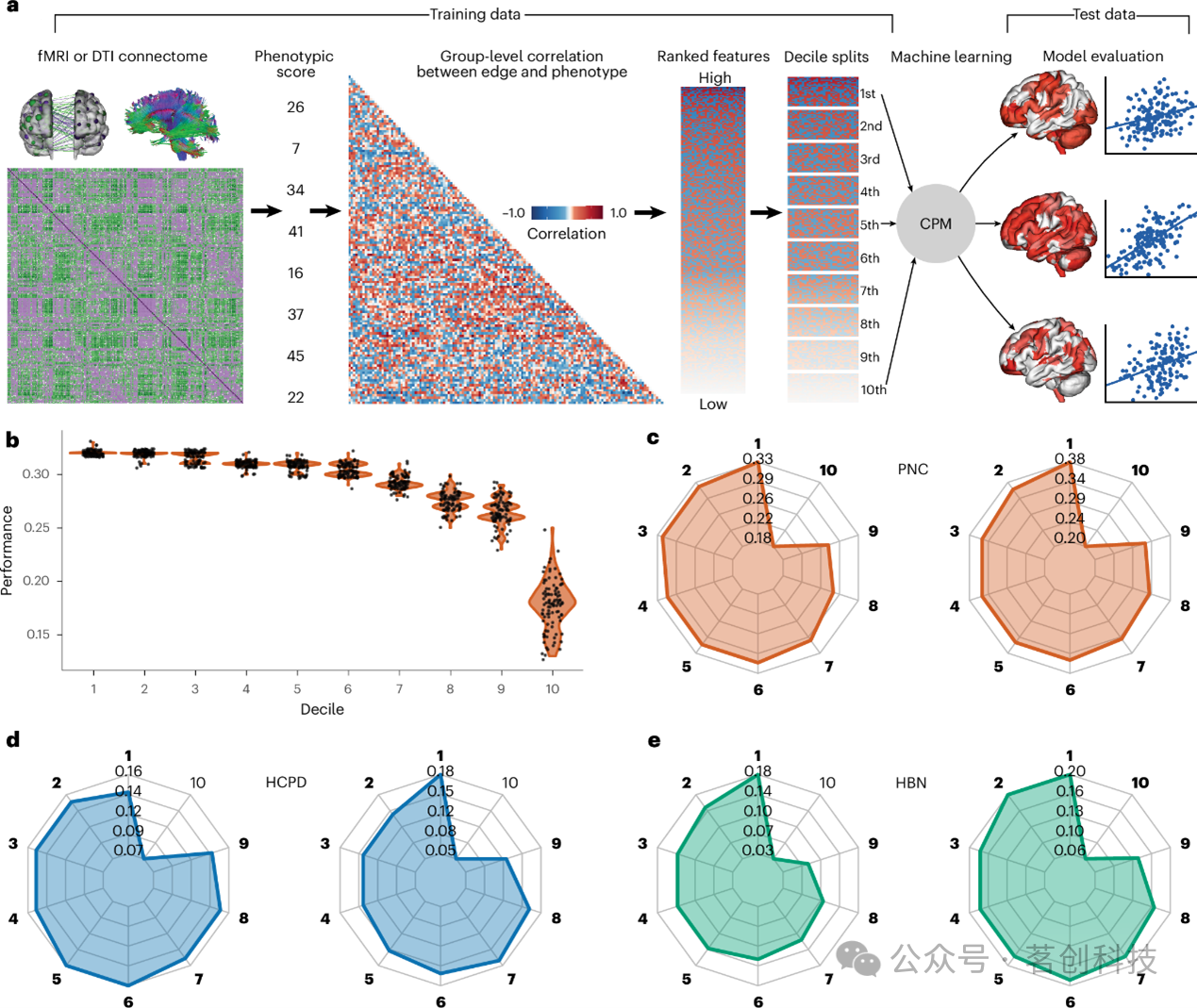
图1.跨互不重叠的十分位组排序脑连接特征的连接组预测模型。
预测精度并非排名靠前特征所独有
本研究使用改进后的连接组预测模型范式,在PNC、HBN和HCPD数据集中分别构建了语言能力与执行功能的预测模型。与先前工作一致,本研究采用PCA将单项认知测量指标整合为执行功能和语言能力的潜在变量。在PNC、HBN以及HCPD中,由第一至第九特征十分位组构建的模型均成功预测了执行功能和语言能力(图1)。在模型构建过程中通常被忽视的排名较低的特征,仍表现出显著的预测性能。例如,对于PNC的执行功能,第一个十分位组达到了r=0.33的预测性能(P=0.001),而第二(r=0.32, P=0.001)至第六(r=0.31, P=0.001)个十分位组亦实现了显著的预测。值得注意的是,尽管这些模型性能相近,但其底层连接边特征互不重叠,即任一给定边仅能归属于一个十分位组。此外,第一个十分位组并非始终呈现最优预测性能。就HCPD的执行功能而言,第五个十分位组(r=0.16, P=0.001)在数值上优于那些包含排名更靠前特征的十分位组。总的来说,第一个十分位组与第二(P=0.107)、五(P=0.067)、六(P=0.110)和七(P=0.408)个十分位组在预测性能上无显著差异。
被忽视的特征集同样能够通过外部验证
鉴于外部验证是模型评估的金标准,本研究将基于十分位组的模型应用于三个独立数据集。尽管各十分位组之间不存在重叠特征,但在全部十二个跨数据集预测场景中,除第一个十分位组之外的其他十分位组在执行功能与语言能力上均展现出了成功的外部验证(图2)。例如,在HCPD中测试的PNC执行功能模型,其第一至第九个十分位组的外部验证结果之间无显著差异。换言之,基于PNC执行功能第九个十分位组(P=0.004)所构建的模型,其向HCPD的泛化效果与基于第一个十分位组(P=0.002)所构建的模型同样出色。其他模型亦呈现出类似趋势。在PNC与HCPD中测试的模型,其表现优于在HBN中测试的模型。
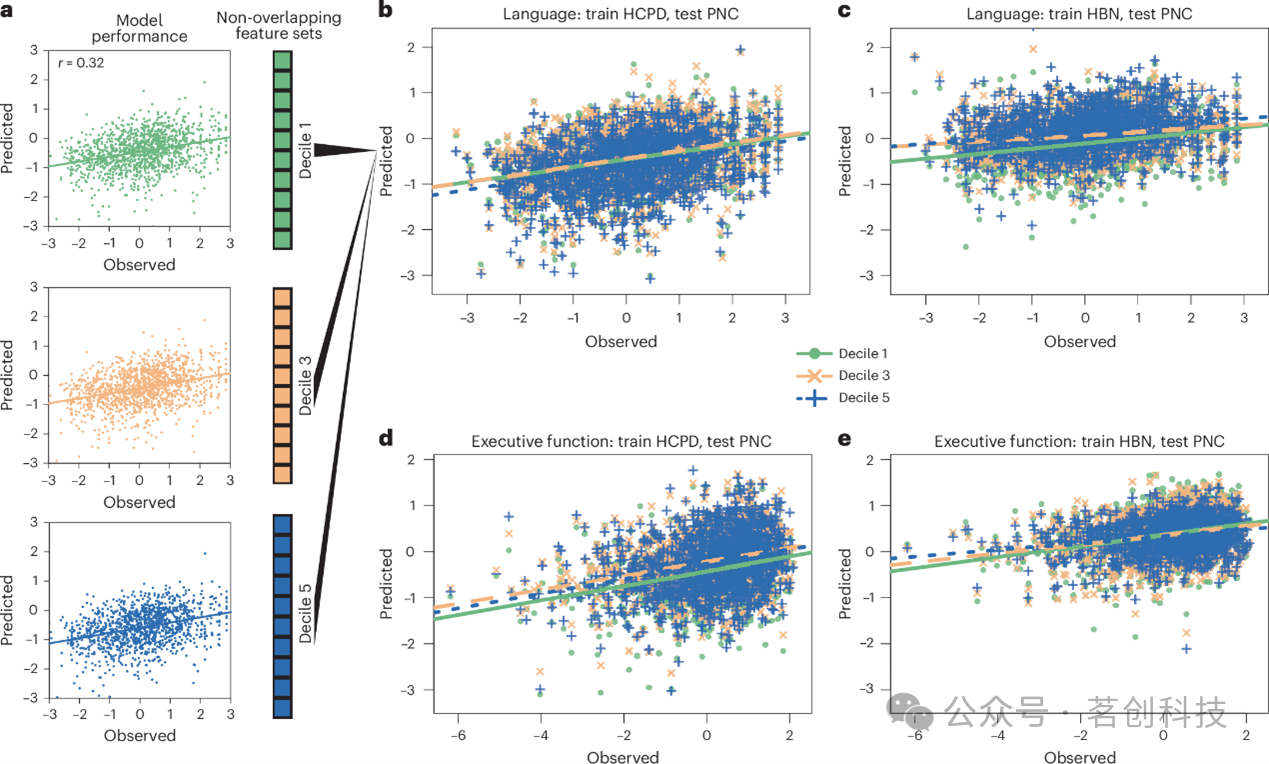
图2.多个互不重叠的特征集可泛化至外部数据集。
被忽视的特征产生迥异的神经生物学解释
鉴于模型在互不重叠特征子集上的表现相似,本研究试图通过比较网络内部及网络之间的功能连接,以确定每个基于十分位数的模型是否涉及相似的脑区特征。对于执行功能与语言能力而言,不同十分位组模型所依赖的经典功能网络各不相同(图3)。例如,在PNC的执行功能模型中,视觉联合网络与额顶网络之间的连接在第一个十分位组中较为突出,而在第二至第五个十分位组中则信息量较低(图3b)。来自不同十分位组的网络特征所解释的方差程度介于弱至中等水平(平均为13%),仅有一对网络组合的解释方差超过50%。相邻十分位组网络之间的解释方差高于非相邻十分位组网络之间的解释方差。具体而言,在PNC的执行功能模型中,第一个与第三个十分位组网络间的解释方差为0.5%,第一个与第四分十分位组之间为3%,第一个与第五个十分位组之间为4.5%。随着十分位组间距的增大,网络相似性逐渐降低,这一趋势在不同数据集与表型中均保持一致。当分析从网络层面比较转向节点层面比较------即基于Shen图谱268个节点各自的模型贡献总和来评估特征时,亦观察到类似的趋势(图3c)。
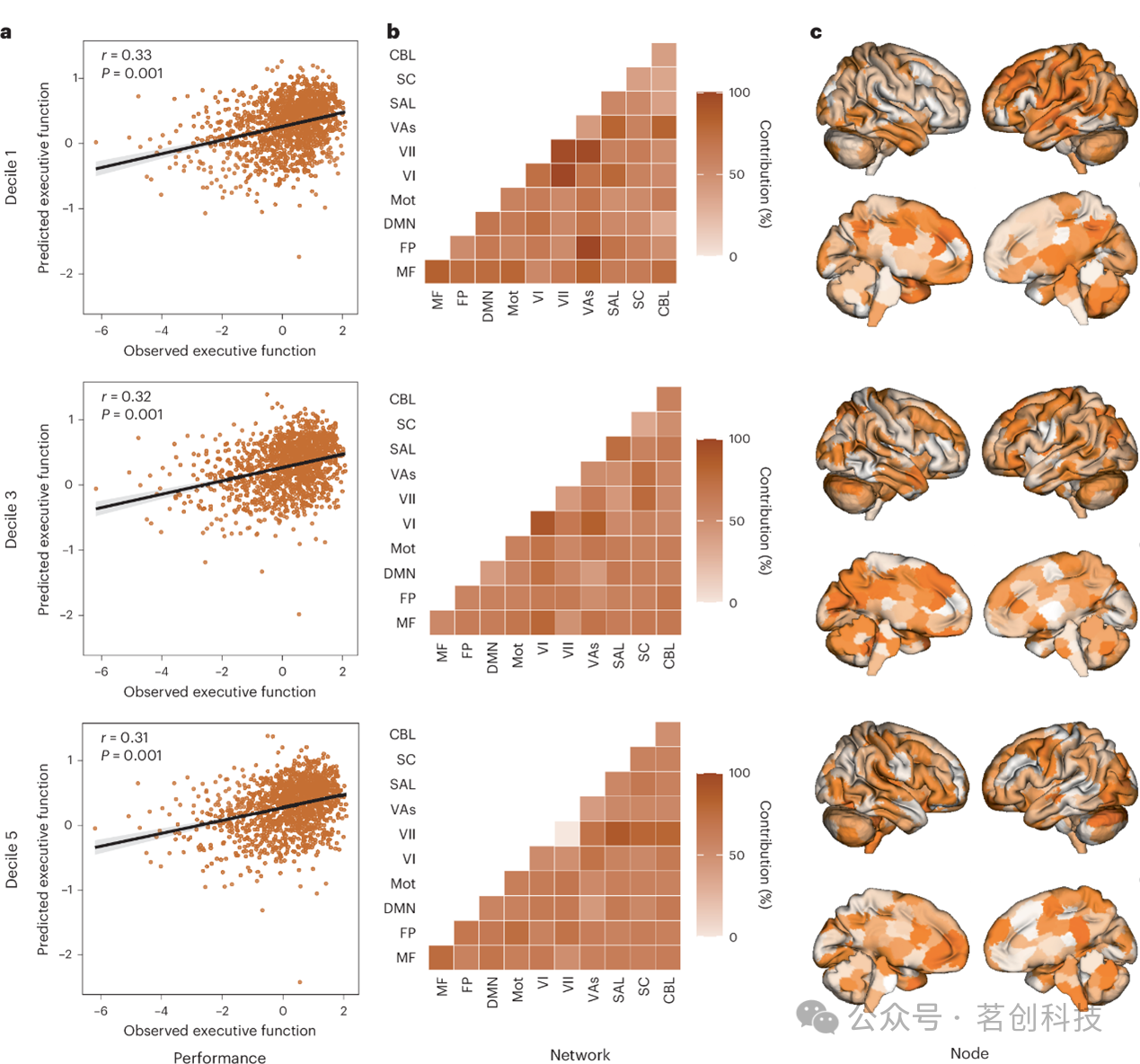
图3.被忽视的特征集提供相似的预测性能,但具有独特的神经解剖学贡献。
被忽视特征的效用可推广至精神疾病、发育及人口统计学表型领域
本研究进一步检验了被忽视特征在语言与执行功能之外的领域是否同样具有意义。首先,在HBN数据集中对一系列选定的发育及精神疾病表型进行预测。结果显示,对于每一个表型,除第一个十分位组之外的其他十分位组均具有预测效用(图4a)。值得注意的是,对于社交沟通问卷评分而言,第二至第七个十分位组的预测性能优于第一个十分位组。鉴于认知、发育及精神疾病表型的预测模型通常表现出较低的效应量,本研究还通过预测PNC、HCPD和HBN中的年龄与性别效应,检验了上述发现能否推广到具有更大效应量表型的预测。结果再次表明,在所有三个数据集中,传统上被忽视的特征集对性别与年龄均具有显著的预测能力(图4b、c)。
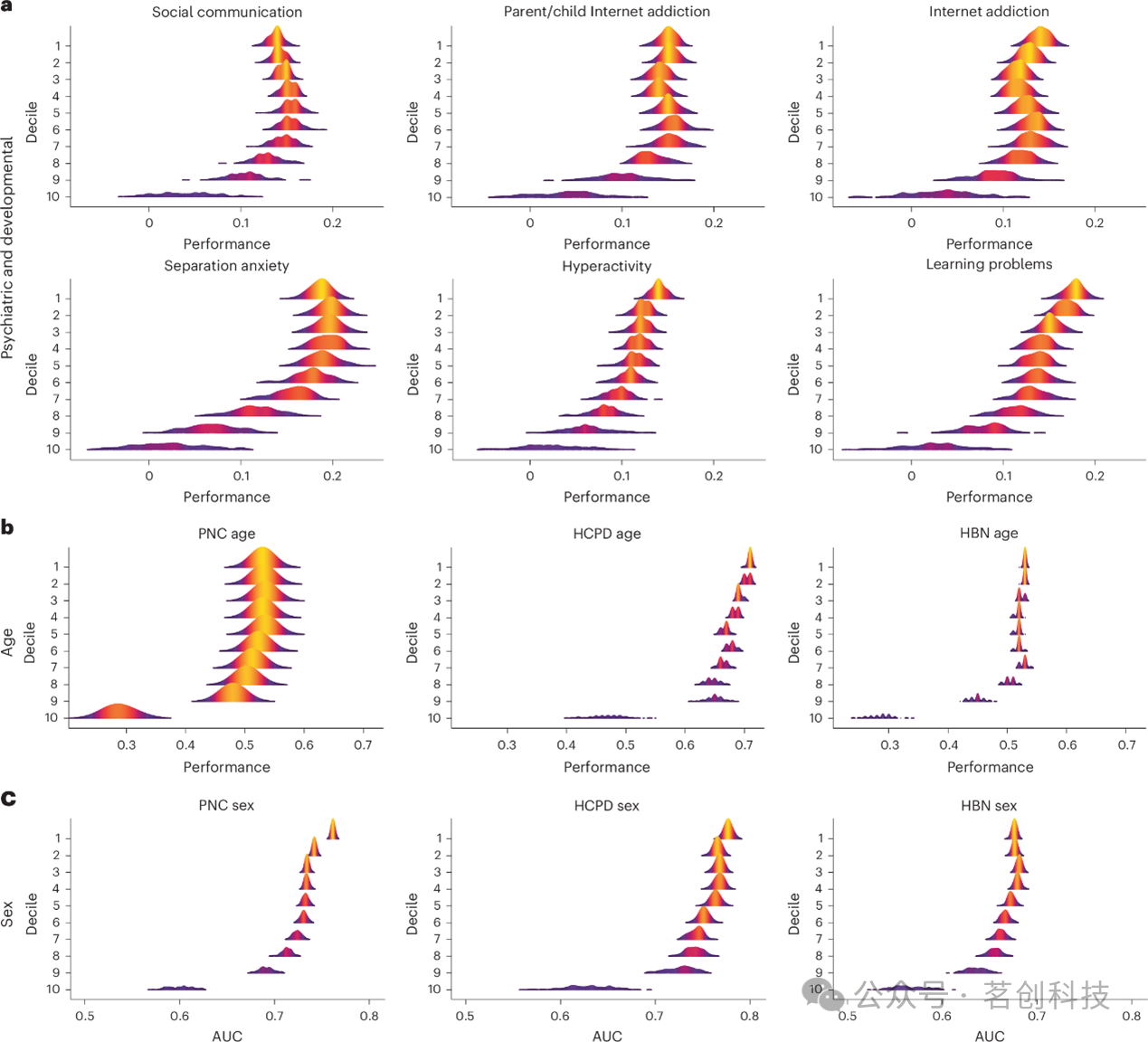
图4.基于十分位数的预测模型在HBN中的性能表现。
岭回归中被忽视的特征
随后,本研究采用岭回归重复了部分分析。岭回归无需特征选择即可处理高维数据,尽管在实际应用中特征选择仍常与之结合使用。岭回归分别在未进行特征选择以及采用与上述类似的基于十分位组的特征选择方法两种情况下执行。为更好地进行生物学解释,对模型权重应用了Haufe变换。
特征选择提升了岭回归的预测性能并缩短了训练时间。未进行特征选择的岭回归模型,其表现显著逊于第一个十分位组模型,而与第二及第三个十分位组模型相近。其余十分位组模型的表现则更差。这些结果凸显了特征选择的益处,即便在分析方法本身并不明确依赖特征选择的情况下亦是如此。
与连接组预测模型相似,第一个十分位组之外的模型亦展现出显著的预测能力(图5a)。然而,与连接组预测模型不同的是,后续十分位组的预测性能均逊于前一个十分位组。例如,第一个十分位组模型的表现优于第二个十分位组模型(P=0.048)。基于互不重叠十分位组构建的模型,彼此之间以及与未进行特征选择的模型之间,均呈现出互补的连接模式。基于十分位组的模型通常解释了未进行特征选择模型方差的不及40%(网络层面)与43%(节点层面)(图5b、c)。仅有三个基于十分位组的模型解释了未进行特征选择模型方差的50%以上。在三分之二的比较中,与未进行特征选择模型最相似者并非来自排名最高的十分位组模型。也就是说,构建于全部特征之上的模型,平均而言与排名较低的十分位组模型更为相似。
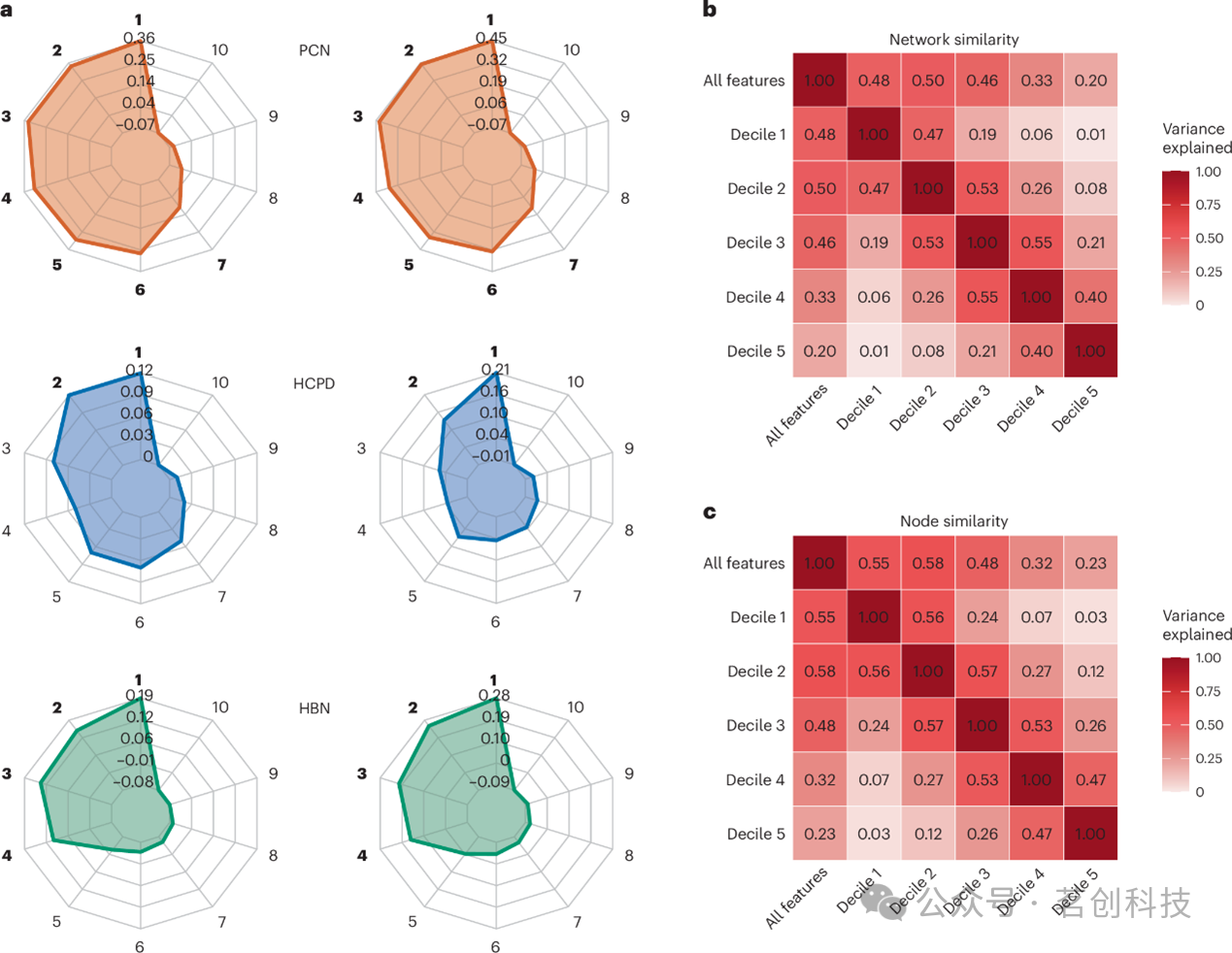
图5.基于十分位组的岭回归模型性能。
使用偏相关的重复验证
已知fMRI特征具有高度的空间与时间自相关性。为了通过去除节点间共享方差来分离直接连接,本研究在PNC数据集中,使用基于偏相关而非Pearson相关所生成的功能连接矩阵重复了上述分析。基于偏相关连接组的结果与基于弥散成像连接组所得结果相似,其预测性能相较于标准的PNC功能连接组呈现出更单调的衰减趋势。
被忽视的特征在其他成像模态中同样具有效用
本研究使用ABCD队列的弥散加权成像数据来检验较低十分位组的预测效用是否在不同成像模态中得以保持。结构连接组基于连接每条纤维两个端区的平均定量各向异性值构建。针对同时具备fMRI与弥散数据的6271名ABCD队列参与者,分别创建功能与结构预测模型,以预测NIH工具箱中经年龄校正的流体智力、晶体智力及综合智力分数。
与功能模型相似,结构模型在排名较低的十分位组特征集中仍保留了相当的预测能力(图6)。基于弥散的模型在不同十分位组之间呈现出稳定且线性的预测性能下降趋势,每个十分位组的表现均略逊于前一个。这与功能数据的结果模式有所不同,后者在大多数十分位组中保持相对稳定的性能,仅在最低十分位组中出现急剧下降。就整体而言,对于跨十分位组的每个表型,功能连接组的预测性能通常高于结构模型。上述基于弥散张量成像的结果在使用全部ABCD样本时,以及在HBN队列中对一效应量较高的表型进行预测时均得到了重复验证。
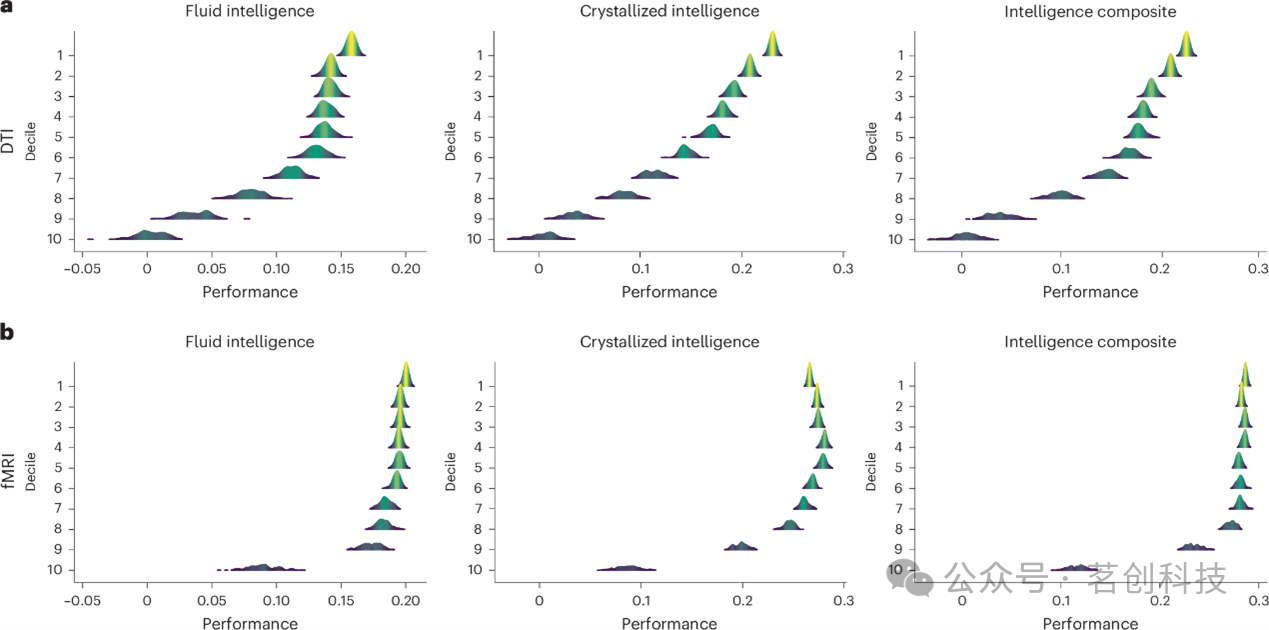
图6.ABCD队列中基于弥散张量成像与fMRI数据的十分位组预测模型性能。
敏感性及探索性分析
为进一步评估结果的稳健性,本研究采用替代性特征选择及建模方法执行了一系列敏感性分析。首先,检验了在替代性特征分组方式下所观察到的预测性能是否依然存续。不同于将特征划分为十个十分位组,本研究依据特征与目标表型的相关性,分别将特征划分为百分位组、二十分位组及五分位组。此外,还检验了基于替代性统计指标进行特征划分对结果的影响。具体而言,依据特征与目标表型的显著性或效应量,将特征划分到互不重叠的组别。随后,在控制非关注变量(年龄、性别、种族/族裔少数群体代表性、社会经济地位及头动)的影响后,对预测性能进行评估。为检验将任务态fMRI数据纳入平均连接组对模型性能的影响,本研究仅使用静息态连接组重复了PNC队列的分析。在上述每一种情景中,除排名最高的特征子集之外的其他特征子集均展现出显著的预测能力。初步结果亦表明,对于特定的个体亚组,排名最高的十分位组并非总是拟合最优的模型。
结论
本研究评估了未被选中的特征是否能够对神经影像预测模型的构建与解释产生有意义的贡献。通过使用基于十分位数的特征排序范式,本研究证明了显著的预测能力并非排名靠前的连接特征所独有。 在功能与结构连接数据以及广泛的表型和数据集范围内,排名较低、未被选中的特征也达到了显著的预测精度,且其精度通常与被选中的特征相当。更重要的是,这些排名较低的特征揭示了与核心特征互为补充的连接模式,并提供了独特的神经解剖学贡献。因此,若仅依赖某一种特定的特征集,我们对于脑-行为关联的神经生物学解读可能会大相径庭,甚至产生偏颇。尽管特征选择能够改善模型的性能,但若某些被忽略的特征同样承载着重要信息,那么基于简化特征集得出的结论,便可能只触及了脑 - **行为复杂关系的冰山一角。**此外,本研究结果进一步表明,那些常被忽视的特征可能蕴含着不容忽视的预测价值与生物学意义。这从侧面印证了脑网络具有广泛分布的特性,而非仅由少数局部或精简的环路主导。研究还提示了脑连接数据中可能存在潜在的亚型结构------即针对不同的个体亚群,最理想的预测模型可能是由完全不同的特征组合构成的。综上所述,深入理解与表征这些长期被忽视的脑连接特征,将是提升未来预测模型泛化能力与普适性的关键一步。
参考文献:Adkinson, B.D., Rosenblatt, M., Sun, H. et al. Feature selection leads to divergent neurobiological interpretations of brain-based machine learning biomarkers. Nat Hum Behav (2026). https://doi.org/10.1038/s41562-026-02447-y