比起君子讷于言而敏于行,我更喜欢君子善于言且敏于行。
目录
[1. "对象"的本质](#1. “对象”的本质)
[2. Service 对象的存在形式是什么?](#2. Service 对象的存在形式是什么?)
[3. 如何查看 Service](#3. 如何查看 Service)
[(2)Rancher UI 查看](#(2)Rancher UI 查看)
[1. hostNetwork 是什么](#1. hostNetwork 是什么)
[2. 典型应用场景](#2. 典型应用场景)
[3. hostNetwork 落地操作](#3. hostNetwork 落地操作)
[方法 1:在 Pod YAML 里指定](#方法 1:在 Pod YAML 里指定)
[方法 2:Deployment/DaemonSet](#方法 2:Deployment/DaemonSet)
[4. hostNetwork的注意事项:](#4. hostNetwork的注意事项:)
[1. ClusterIP](#1. ClusterIP)
[2. NodePort](#2. NodePort)
[3. LoadBalancer](#3. LoadBalancer)
[4. ExternalName](#4. ExternalName)
[5. Headless / ClusterIP: None](#5. Headless / ClusterIP: None)
前言
众所周知,最近在新增上海节点的master到k8s集群中并把之前的北京master丝滑移除。在此期间又会涉及到一些网络问题,包括但不限于域名解析、pod访问、ingress pod移除,等等。总而言之,一锅粥!趁热打铁,彻底捋清楚k8s集群所有的网络访问内容,清晰明了的应对工作。
Kubernetes 的网络(Pod、Service、NodePort、hostNetwork)属于网络层/传输层
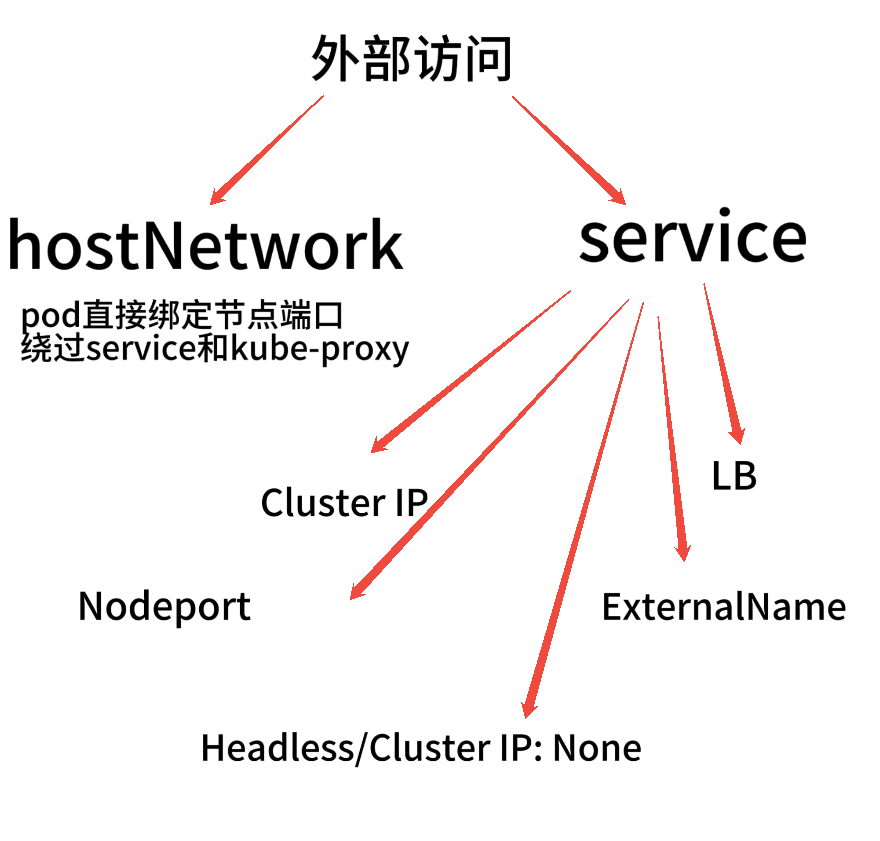
一、访问流程抓重点
化繁为简,我们最简单明了的去看访问的流程,可以发现,实际上k8s的网络访问核心内容就是service。觉得很杂乱只是因为service有不同的类型用在不同的场景下。抓住了本质,就很好往下梳理了。
1. "对象"的本质
在 Kubernetes 里,一切都是 对象 (Object) 。可以把它想成 系统里的条目或记录,有点像 Excel 里的行,也像数据库里的记录。
- 对象不是程序,也不会自己跑
- 它只是 告诉 Kubernetes:我要什么、怎么部署、需要哪些资源
- Kubernetes 会根据对象去 调度 Pod、分配 IP、配置网络、管理副本
2. Service 对象的存在形式是什么?
在 Kubernetes 里,Service 是一种 API 对象 (像 Pod、Deployment、ConfigMap 都是对象),它在 etcd 里存储,而不会自己跑成 Pod。
- 当你创建 Service 时,它会生成一个对象(对象 = 系统记录 + 期望状态),包含:
- 名字 :
metadata.name(比如my-service) - 类型 :
spec.type(ClusterIP / NodePort / LoadBalancer / ...) - 选择器 :
spec.selector(选择哪些 Pod) - 端口映射 :
spec.ports(Service port → Pod targetPort) - ClusterIP(Kubernetes 自动分配 VIP)
- 名字 :
- 它本身不占用 Pod,也不直接运行程序
- 实际转发流量靠 kube-proxy(iptables 或 IPVS)完成
- 你创建对象 = 你告诉 Kubernetes:我要这样一个东西,系统去实现它
- YAML 是对象的"身份证",里面有所有属性
把 Kubernetes 想成一个 公司:
Pod = 员工,在办公室工作(运行程序)
Deployment = HR 发的招聘单:我要 3 个前端开发员(创建 Pod)
Service = 前台接待员:谁来找你,应该把客户引到哪个员工(Pod)
ClusterIP = 内部 VIP,大家公司内部都能找前台接待
NodePort / LoadBalancer = 外部访问通道,客户从外部通过前台找到员工
hostNetwork:罗子君的妈妈 ------> 公司大门(Pod 直接绑定节点端口) ------>林凌(Pod)
注意:Service 这个"前台",自己不做工作,只是负责指引流量。
3. 如何查看 Service
(1)命令行
可以用 kubectl 查看 Service:
# 查看某个命名空间下所有 Service
kubectl get svc -n <namespace>
# 查看详细信息
kubectl describe svc my-service -n <namespace>
# 查看 YAML 原始定义
kubectl get svc my-service -n <namespace> -o yaml(2)Rancher UI 查看
在 Rancher 页面里:
1.进入 集群 → 选择命名空间(比如 cattle-system)------菜单选择 Workloads / Services------ 找到对应 Service(比如 rancher),可以看到:
- Type(ClusterIP / NodePort / LoadBalancer)
- Ports
- Selectors(对应 Pod 标签)
- Endpoints(Pod 列表 + IP)
Rancher 的 Service 界面就相当于 kubectl get svc -n <namespace> 的可视化版,而且还能直接看到 Service 关联的 Pod。
二、详细拆解------hostNetwork
我们先来把和service并列的hostNetwork搞清楚
1. hostNetwork 是什么
pod直接使用宿主机的网络栈,也就是pod网络接口直接挂在节点上
pod的容器IP=节点IP,Pod 内的端口就是节点上的端口
会绕过CNI(pod和pod直接访问会通过CNI插件,calico、flannel等)和 Service/kube-proxy,网络访问更直接。
用途类似端口直通,适合对延迟、端口固定、外部访问敏感的场景。
2. 典型应用场景
核心思想:任何必须直接占用节点端口或低延迟直通的服务,都可以考虑 hostNetwork
|--------------------------------------------|-------------------------------------|------------------------------------|
| 场景 | 说明 | 为什么用 hostNetwork |
| Ingress Controller(nginx-ingress, traefik) | 对外服务入口,需要固定端口 80/443 | 避免 NodePort 或 LB 映射复杂,Pod 直接监听节点端口 |
| 高性能网络服务 | 低延迟需求,如某些金融/视频流服务 | 绕过 kube-proxy 和 iptables,减少延迟 |
| 系统级服务 | DNS、CNI 插件、网络监控代理 | 必须直接访问宿主机网络,不能被 Service 隔离 |
| 调试/运维工具 | Prometheus Node Exporter、日志收集 Agent | 直接访问宿主机端口和接口,方便省事 |
3. hostNetwork 落地操作
方法 1:hostNetwork
hostNetwork 本身只是改变 Pod 的网络模式,让 Pod 直接使用节点 IP 和端口。
apiVersion: v1
kind: Pod
metadata:
name: hostnetwork-demo
spec:
hostNetwork: true # 开启 hostNetwork
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80 # 容器端口直接占用节点端口方法 2:Deployment/DaemonSet
DaemonSet 本身只是保证 Pod 在每个节点上都有一个副本。
很多 ingress-controller 和监控 Agent 通常更推荐用 DaemonSet 部署到每个节点:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: ingress-nginx
namespace: ingress-nginx
spec:
template:
spec:
hostNetwork: true
containers:
- name: controller
image: ingress-nginx/controller
ports:
- containerPort: 80
- containerPort: 443我们来拆解一下方法2的原理
|--------|-------------------------------|--------------------------------------------------------------------------------------------|
| | Deployment | DaemonSet |
| 概括 | 集群级副本控制 | 节点级副本控制 |
| 用途 | 管理一组相同的 Pod,保证副本数(replicas) | 在集群每个节点上都运行一份 Pod |
| Pod 分布 | Pod 可以分布在任意节点,由 scheduler 决定 | 每个节点都有一个 Pod,新节点加入时自动调度 Pod |
| 大白话 | 你想建 3 个咖啡馆,不管在哪个街区,只要总数是 3 就行 | 每个街区都必须建一个咖啡馆,保证每个街区都有覆盖 |
| 典型场景 | Web 应用、后端服务、不要求每个节点都有副本 | ingress-controller、日志收集 agent(fluentd)、监控 agent(node-exporter)、网络插件(calico、cilium、flannel) |
hostNetwork 单 Pod 模式下,pod直接绑定在节点端口上会出现一个问题,那就是:如果 Pod 只部署在一个节点上,其他节点访问同端口就访问不到 Pod。类似 单机服务,端口固定,但不高可用。
所以我理解为 DaemonSet + hostNetwork,相当于是hostnetwork的高可用模式
每个节点都部署一份 Pod ,每个 Pod 都用 hostNetwork 直接绑定节点端口。从而实现:访问任何节点的端口都能命中 Pod
**方法3:**hostNetwork + DaemonSet
hostNetwork + DaemonSet = 高可用 hostNetwork
应用场景:rancher.test.com访问。实际上访问任意节点ip:32443,都能访问到rancher。我需要让用户去访问域名,实际上是访问url:443,来访问rancher页面。
**基础方式,**我可以把rancher pod的端口号使用hostNetwork映射到节点端口,把url只挂给这一个节点,可以实现。缺点:一旦这个节点挂了,访问就会失败。事实上任意节点都可以访问的。单节点会不稳定
中阶方式, 可以使用nodeport的方式,NodePort 把节点上的高位32443端口映射到Pod的443端口。此时,用户访问url:32443就会访问到pod:443,访问通过。可是我们要实现的是用户访问url:443。也就意味着,需要在每一个节点上做一次网络转发,让443端口访问来的都去找32443端口。这么做也很麻烦,依旧需要手动执行每一台设备。当然,如果是云厂商服务器也可以直接使用LB,让外部通过标准端口访问,LB 转发到 NodePort,再到 Pod。相对来说比手动执行iptable或者firewalld或者nginx要省事儿。可惜,我这个是手搓的k8s集群,不能直接用LB。(备注:本文记录Kubernetes 的网络Pod、Service、NodePort、hostNetwork属于网络层/传输层。Ingress 本质上不是 Pod 网络本身,它是一层 HTTP/HTTPS 层面的路由器。所以这里不考虑使用Ingress解决"HTTP 请求路由到哪个 Pod/Service"的问题。后续会单独再出一篇关于ingress的内容。)
**进阶方式,**组合起来:hostNetwork → Pod 直接用节点 IP 和端口
DaemonSet → 每个节点都有这个 Pod
结果:无论访问哪台节点的 443,都会命中一个 Pod,不会因为单节点挂掉而访问失败
类比:就像每栋都配了前台,客户到哪栋楼都有人接待
核心意思就是:hostNetwork 保证 Pod 端口直接暴露,DaemonSet 保证每个节点都有 Pod →从而实现高可用。
4. hostNetwork的注意事项:
-
端口冲突:hostNetwork Pod 端口是节点端口,要保证不
-
安全性:Pod 有节点网络权限,安全隔离比普通 Pod 弱。
-
不适合大规模 Pod:hostNetwork 不能动态负载均衡到多个节点,需要配合 DNS 或外部 LB。
二、 service
我们按照:原理 → 应用场景 → 方案落地的方式,一个个的来梳理service的不同类型。
Kubernetes 官方 Service 类型 本质上只有 这五种:
- ClusterIP(默认)
- NodePort
- LoadBalancer
- ExternalName
- Headless / ClusterIP: None
所以严格来说,这就是"官方 Service 类型"的全集。但是在实际运维或文档里,大家经常会把 hostNetwork + DaemonSet + Ingress/Service 联合方式 也算作"Service 类型",所以会出现感觉"好像不止五种"的情况。
简单理解 :如果只看 Kubernetes API → 就是上面五种。如果看实际生产使用 → 会有组合方式(比如 hostNetwork pod + NodePort service + Ingress)来实现不同的访问策略。换句话说,官方文档中只有这五种,你平时看到的各种外网访问场景,其实都是这五种基础类型在组合使用。
1. ClusterIP
内部访问
Pod A ---> ClusterIP Service VIP ---> kube-proxy ---> Pod B targetPort
我把ClusterIP理解为实现了Pod 高可用。
ClusterIP 是 集群内部的虚拟 IP (VIP)
如果某个 Pod 挂掉了,VIP 会自动不再把流量发给它 → Pod 层面的高可用
原理 :
给一组 Pod 分配一个虚拟 IP(VIP)
集群内部流量访问该 VIP 时,kube-proxy 会把流量负载到所有匹配的 Pod 上
Pod 的 IP 是动态的,VIP 屏蔽了 Pod IP 的变化
应用场景:
集群内部服务发现、后端微服务之间调用、不需要直接暴露给外部
落地方式:
Pod 访问 创建的 my-service 即可,ClusterIP 自动负载均衡
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
type: ClusterIP
selector:
app: my-app
ports:
- port: 80
targetPort: 80802. NodePort
我把NodePort理解为实现了节点高可用 + 外部访问
外部请求 → 节点IP:nodePort → kube-proxy → Service → Pod
其中一个节点挂掉,流量需要打到其它节点的 NodePort → 实现节点 HA
NodePort 实际上是外部访问集群的统一入口,而 Pod HA 仍然靠 ClusterIP 分发
原理:
给 Service 分配一个固定端口(NodePort),通常在 30000~32767
NodePort 是 Node 级别端口映射,不关心 Pod 的具体 IP
NodePort 端口是固定在节点上的,只要 Pod 存在,节点任意 IP 都能通过这个端口访问对应 Service
应用场景:
小型集群或者本地测试、暴露服务给外部,不依赖云 LB、临时访问或者调试
落地方式:
访问方式:http://<NodeIP>:30080(这个ip可以自己去随意调整)
创建了一个my-service的对象,并注册到 kube-apiserver------ NodePort 会在 所有节点 开放这个端口(30080)------流量经过 kube-proxy 再转发到 Pod 的 targetPort(8080)
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
type: NodePort
selector:
app: my-app
ports:
- port: 80 # Service 端口
targetPort: 8080 # Pod 端口
nodePort: 30080 # 外部访问端口3. LoadBalancer
我把LoadBalancer****理解为实现了外网的访问
LoadBalancer → 云厂商 LB 前置,背后其实还是 NodePort
注意:只有云厂商是可以实现的,如果是自建的集群,不能自动生成外网IP,需要手搓,下面提供了两种常用方式。
- (开源 LB 控制器)
- 在裸机集群中实现
LoadBalancer类型 - 可以分配内网或公网 IP
- 支持 ARP/BGP 模式
- 在裸机集群中实现
- NodePort + 外部 LB
- 自己在机房的 LB(F5、Nginx、HAProxy 等)上做转发
- 指向集群所有节点的 NodePort
原理:
云厂商提供 LB(Load Balancer)服务,直接用 type: LoadBalancer
外部请求 → 云 LB → NodePort → Service → Pod
对外暴露固定 IP(LB IP),隐藏节点和 Pod 的实际 IP
应用场景:
公网访问服务、高可用集群,负载均衡流量、云环境(AWS ELB、阿里云 SLB、Azure LB)
落地方式:
创建后,云 LB 自动生成外网 IP
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
type: LoadBalancer
selector:
app: my-app
ports:
- port: 80
targetPort: 80804. ExternalName
我把ExternalName****理解为实现了DNS解析
原理:
不做流量转发,不经过kube-proxy规则
直接返回DNS的名称
Pod 内访问 my-service 时,DNS 解析到指定外部域名
应用场景:
集群内需要访问外部服务、想给外部服务起一个集群内别名
方案落地:
Pod 访问 external-api → DNS 解析到 api.example.com
apiVersion: v1
kind: Service
metadata:
name: external-api
spec:
type: ExternalName
externalName: api.example.com5. Headless / ClusterIP: None
我把Headless Service 理解为把 k8s的负载均衡功能关掉,自己拿 Pod IP 来做流量分配。
介于本人暂时没有遇到过这种使用场景,所以感觉很鸡肋(个人观点,勿喷!)
原理:
暴露 Pod 的真实 IP,客户端自己选择要访问哪个 Pod。
常用于有状态服务(StatefulSet)
不分配 VIP 给pod,Service 只做 DNS 解析,返回 Pod 的真实 IP 列表
网络需求:Pod 间的 CNI 网络必须可达,否则无法访问 Pod。
应用场景:
数据库集群(MySQL、Cassandra、Kafka)、StatefulSet,需要客户端知道每个 Pod IP
方案落地:
Pod 获取 Service DNS → 得到多个 Pod IP → 自己负载均衡apiVersion: v1
kind: Service
metadata:
name: headless-service
spec:
clusterIP: None
selector:
app: my-app
ports:
- port: 80
targetPort: 8080其实网络内容并不复杂,关键是要彻底的区分清楚它们的本质。如果不确定自己是否彻底区分清楚,那么用下面几个问题来考考自己叭~~~
Headless和hostNetwork的区别是什么呢?
五种service方式,哪些会使用到kube-proxy,哪些会使用到CNI呢?
聪明的你一定有答案了叭
总结
ClusterIP 是基础,NodePort/LoadBalancer 是对外暴露方式,ExternalName 是别名,Headless 是自管理 Pod IP 列表