进程控制
一、进程创建
1. 通过fork()函数创建新进程
在 linux 中 fork 函数是非常重要的函数,它从已存在进程中创建⼀个新进程。新进程为子进程,而原进程为父进程。
调用fork函数后,系统做的:
- 分配新的内存块 和内核数据结构给子进程
- 将父进程 部分数据结构内容拷贝至子进程
- 添加 子进程到系统进程列表当中
fork返回,开始调度器调度
2.fork的常见用法
- ⼀个父进程希望复制自己,使父子进程同时执行不同的代码段。例如,父进程等待客户端请求,生成子进程来处理请求。
- ⼀个进程要执行⼀个不同的程序。例如子进程从fork返回后,调用exec函数。
3.fork调用失败
- 系统中有太多的进程
- 实际用户的进程数超多了限制(少见)
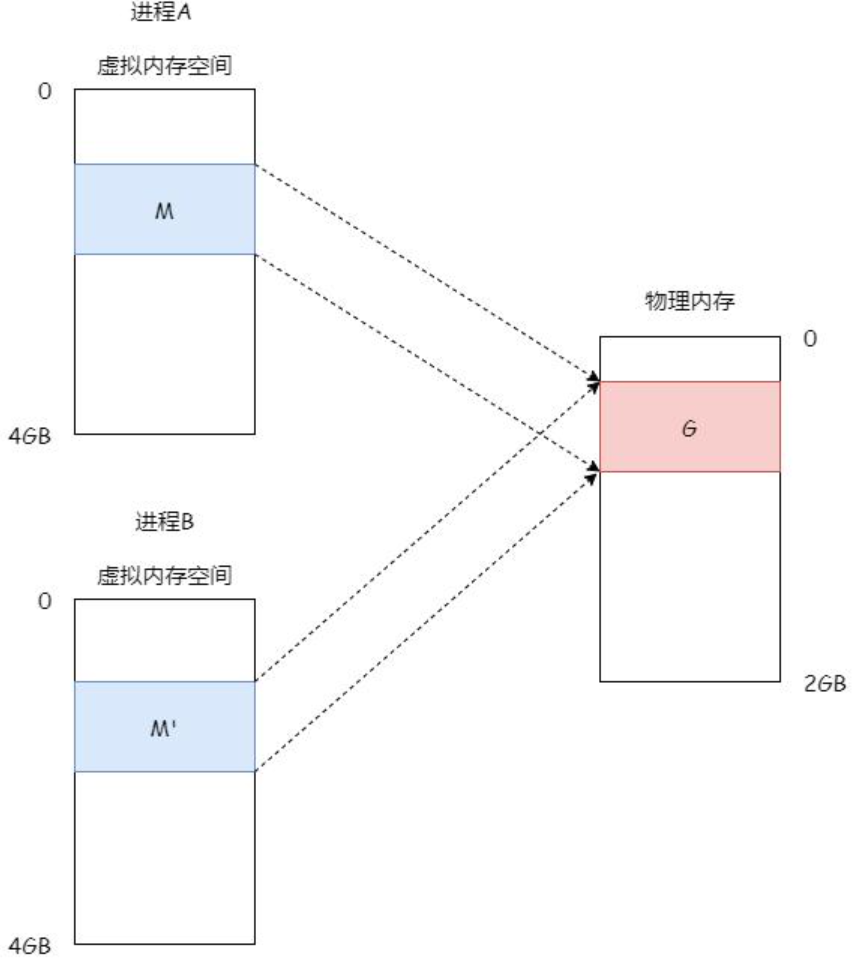
二、写实拷贝(Copy‑On‑Write,COW)
fork()时发生什么?
-
内核创建子进程:
-
新 task_struct(进程控制块)
-
新 mm_struct(虚拟地址空间)
-
复制父进程页表 ,但不复制物理内存
-
-
所有共享页的权限 设为只读
-
父子进程:
-
虚拟地址完全一样
-
物理地址完全共享
-
都只能读,不能写
-
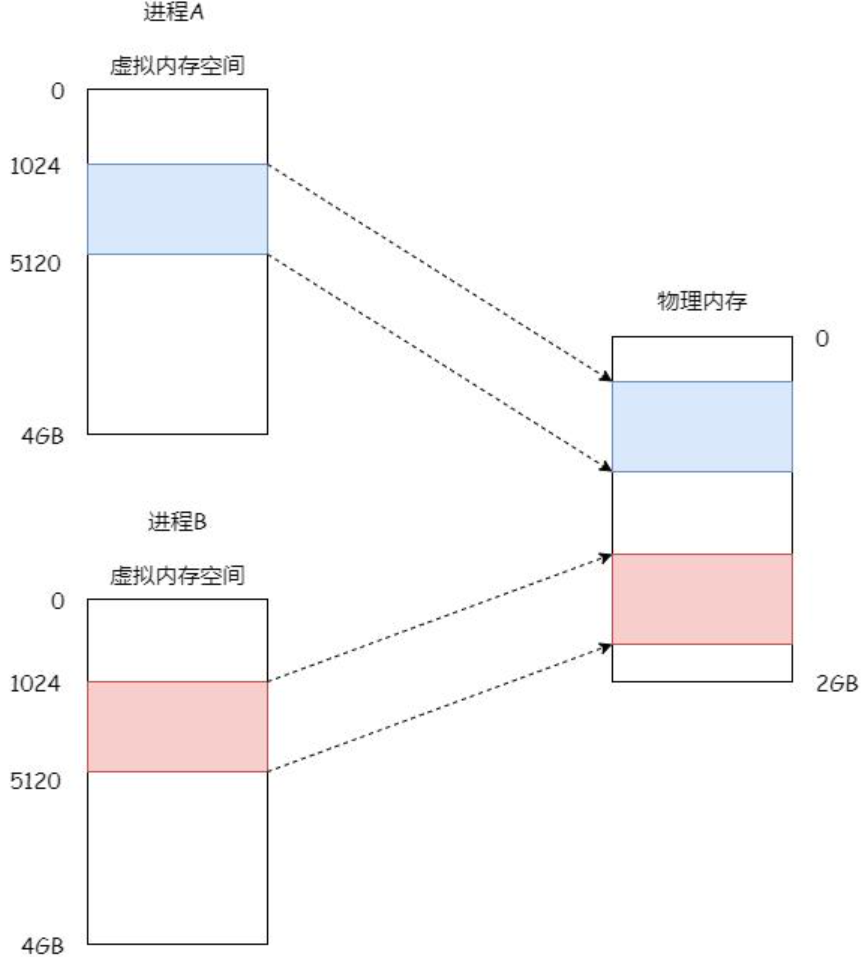
什么时候真正拷贝?(写触发)
只要任何一方(父 / 子)对共享页执行写操作:
- CPU 检测到页表标志位只读 → 触发缺页异常(Page Fault),写不进去
- 内核判断是 COW 场景:
- 分配新物理页
- 把旧页内容复制到新页
- 修改当前进程页表:指向新页 → 设为可写
- 另一进程继续共享原页
- 结果:只复制 "被写的那一页",不是全量拷贝
三、进程终止
三种结果
进程终止的本质是释放系统资源,就是释放进程申请的相关内核数据结构和对应的数据和代码。
进程终止有三种结果:
- 代码运行完毕,结果正确
- 代码运行完毕,结果不正确
- 代码异常终止
进程main函数返回的相当于一个进程退出码 ;在Linux中,可以通过命令echo $?将最近一次进程运行的退出码打印在屏幕上。
一个进程正常退出,就是main函数返回0 ;除了返回0和1,其他返回值都代表着不成功。1一般是程序员自己定义的通用错误。
错误码与退出码的区别
1. 退出码(进程退出状态码)
全称:进程退出码 exit code
- 作用:一个进程结束运行后,留给父进程看的运行结果
- 来源:
- 程序里
exit(数值) main函数return 数值- 被信号杀死由内核赋值
- 程序里
- 范围:0~255 ,只占低 8 位
2. 错误码(系统调用错误码 errno)
- 作用:调用 Linux 内核函数失败时,标记失败原因
- 来源:
open/read/write/fork/pipe等系统调用执行失败 - 本质:全局整型变量
int errno - 范围:几十~上百个宏值(EPERM、ENOENT、EINTR...)
- 头文件:
<errno.h> - 特点:只有调用失败才赋值,成功不清空
3.核心五大区别
-
所属主体不同
-
退出码:整个进程跑完后的最终结果
-
错误码:某一次系统调用失败的原因
-
-
使用时机不同
-
退出码:进程彻底结束之后使用
-
错误码:程序运行中途,调用函数出错立刻查看
-
-
取值范围不同
-
退出码:0~255
-
错误码:多枚举宏,数量极多
-
-
获取方式不同
-
退出码:父进程
wait读取子进程状态 -
错误码:程序内部直接读全局变量
errno
-
4.直观例子
例子 1:退出码
c
int main()
{
return 0; // 退出码 0 成功
}Shell 执行:echo $? 查看上一条命令退出码
例子 2:错误码
c
int fd = open("不存在的文件.txt", O_RDONLY);
if(fd < 0)
{
printf("%d\n", errno); // 打印错误码,代表文件不存在
}5.最容易混淆的点
-
退出码可以自己随便设,errno 是内核固定规定
-
一个进程只有一个最终退出码,但运行中能产生无数次 errno 错误码
-
$?拿到的是退出码 ,不是errno -
程序调用系统调用出错 → 产生
errno程序结束运行 → 给出
退出码
三种结果的表示
Linux中,进程终止有不同信号:
(1)代码跑完,结果正确
运行期间,没有收到信号 ;0 && return 0 -> signumber:0 && 退出码:0;
(2)代码跑完,结果错误
signumber:0 && 退出码 !0;
(3)代码没跑完,进程异常。
signumber:!0;
此时退出码已经没有意义了,此时关注的就是什么原因 导致的异常!Linux中就是被信号终止了
所以:
一个进程执行的结果状态,可以用两个数字表示:int sig、int exit_code。用户不需要维护这些,当一个进程结束时,OS会把进程退出的详细信息写入到进程的task_struct结构体中!!!那么 ,进程退出,需要僵尸维护自己的退出状态!
不考虑进程异常,如何退出进程
main函数return- 在任意地方
exit()
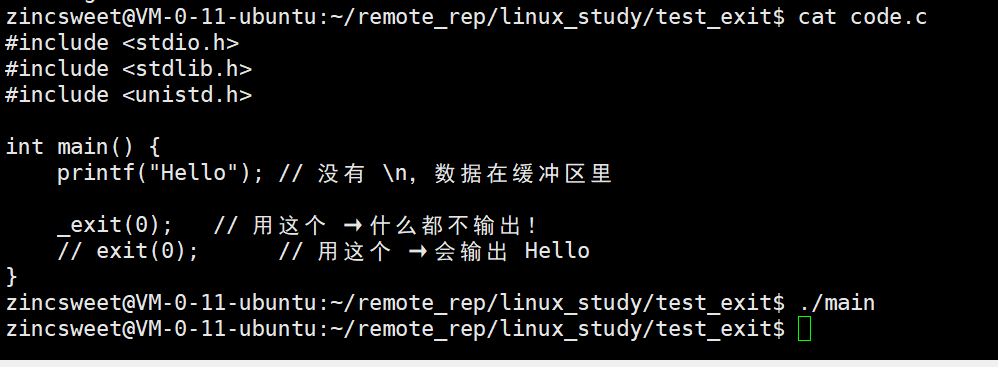
函数exit()与_exit()的区别
一、本质区别
exit()- 属于 C 标准库函数(封装了系统调用)
- 作用:正常、优雅地终止进程
- 会做大量清理工作
_exit()- 属于 Linux 系统调用
- 作用:立即、暴力终止进程
- 不做任何清理工作
c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main() {
printf("Hello"); // 没有 \n,数据在缓冲区里
// _exit(0); // 用这个 → 什么都不输出!
exit(0); // 用这个 → 会输出 Hello
}
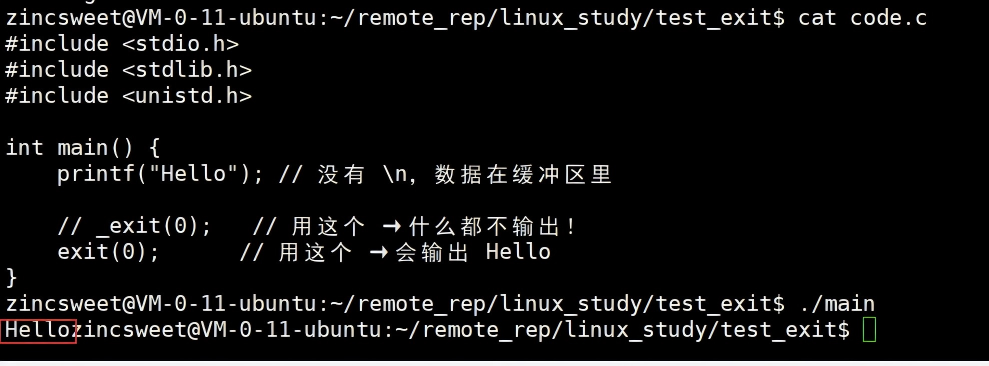
二、最关键的区别(3点)
-
是否刷新 I/O 缓冲区
-
exit ():会刷新
-
_exit ():不刷新
-
-
层级不同
-
exit () = 库函数(上层)
-
_exit () = 系统调用(底层)
-
-
使用场景
-
exit ():正常程序退出
-
_exit ():子进程在 fork 后 exec 前使用(防止缓冲区混乱)
-
四、进程等待
进程等待的必要性
- 回收子进程资源 :子进程退出后若父进程不等待,会变成僵尸进程,占用进程号等系统资源,造成资源泄漏。
- 获取子进程退出状态 :父进程可通过等待拿到子进程退出码 ,判断子进程是正常结束、异常终止还是被信号终止。
- 控制父子进程执行顺序 :让父进程阻塞等待子进程完成任务后再继续执行,实现业务逻辑先后次序。
- 避免孤儿进程 :防止父进程先退出,子进程被 init 进程接管,导致进程管理混乱。
- 保证数据交互完整性:确保子进程读写、运算等任务执行完毕,父进程再读取其运行结果。
等待方法
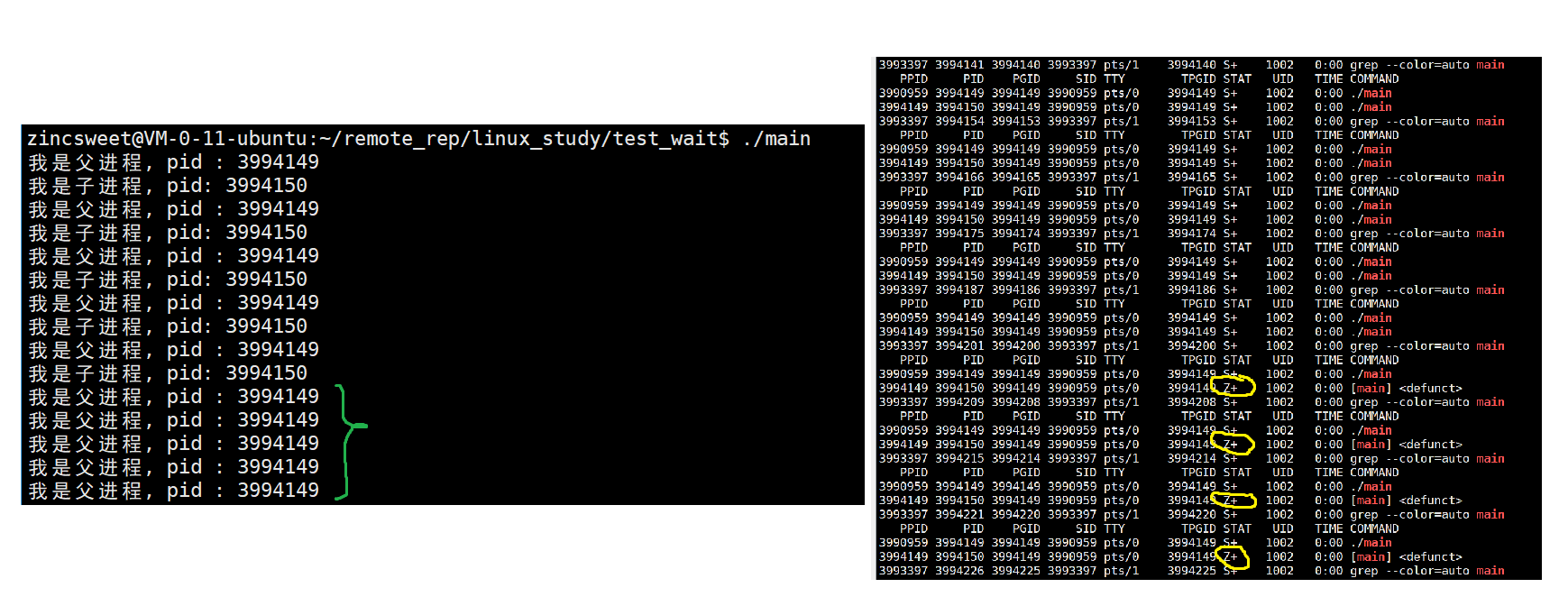
当父进程还在进行,而子进程结束时:
c
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#include<error.h>
#include<stdlib.h>
int main() {
pid_t id = fork();
if(id == 0) {
int cnt = 5;
while (cnt--) {
printf("我是子进程, pid: %d\n", getpid());
sleep(1);
}
exit(0);
}
else if (id > 0) {
while (1) {
printf("我是父进程, pid : %d\n", getpid());
sleep(1);
}
}
return 0;
}
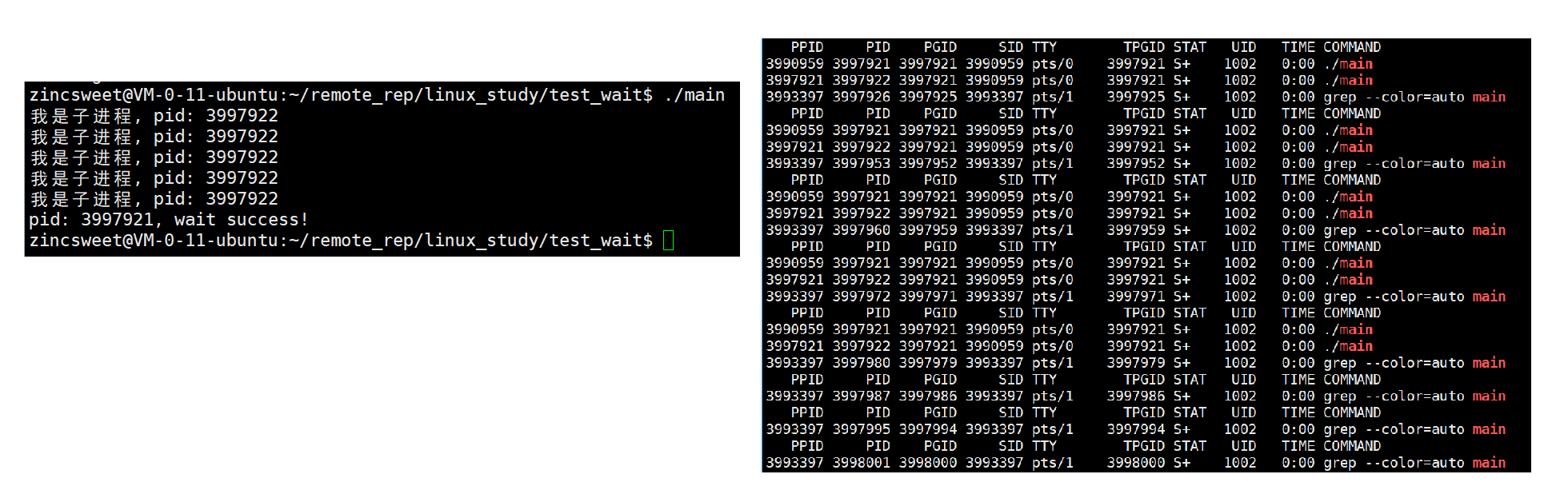
1.wait()函数
c
#include<sys/types.h>
#include<sys/wait.h>
pid_t wait(int* status);
// 返回值:成功返回被等待进程pid,失败返回-1。
// 参数:输出型参数,获取子进程退出状态,不关⼼则可以设置成为NULL通过在父进程中添加代码:
c
// 等待子进程
pid_t rid = wait(NULL);
if (rid == id) {
// 等待成功
printf("pid: %d, wait success!\n", getpid());
}
也就是说,当父进程wait子进程,但是子进程就是没有退出,则父进程会阻塞在wait函数中;
再利用sleep来直观的查看对僵尸进程的改善:
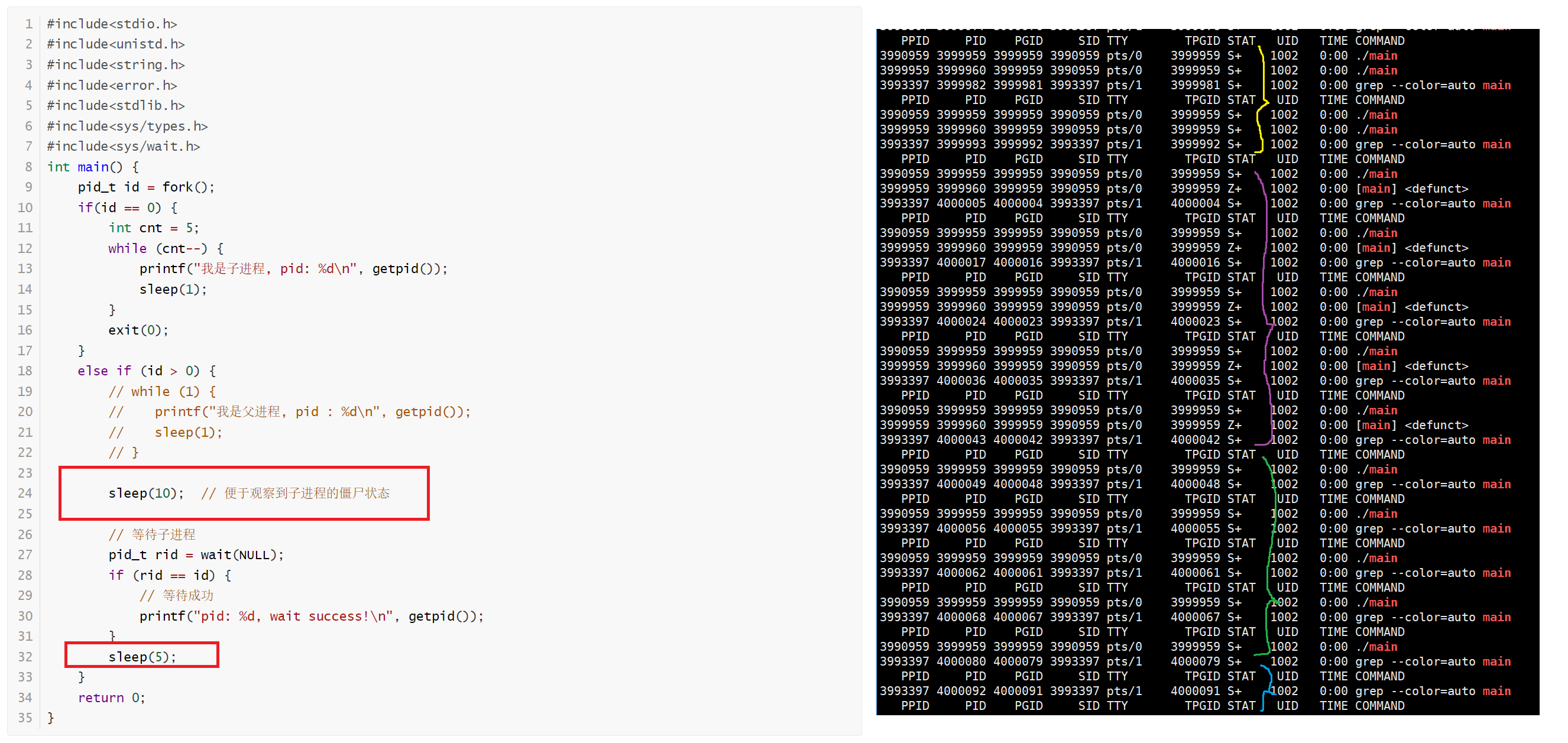
2.waitpid函数(更推荐)
c
#include <sys/types.h>
#include <sys/wait.h>
pid_ t waitpid(pid_t pid, int *wstatus, int options);
// 当pid=-1;options=0时,函数等同于wait()参数
-
pid
-
pid > 0:等待指定 pid子进程 -
pid = 0:等待同组任意子进程 -
pid = -1:等待任意子进程(等价 wait) -
pid < -1:等待指定进程组任意子进程
-
-
wstatus
传出参数,存子进程退出信息,传NULL表示不关心。
常用宏:
-
WIFEXITED(w):正常退出为真 -
WEXITSTATUS(w):获取退出码
-
options
-
0:阻塞等待(默认) -
WNOHANG:非阻塞,不等待,无子进程退出立即返回 0
-
返回值
>0:成功,返回退出子进程 pid0:非阻塞模式,子进程还没退出-1:出错
将wait函数换成waitpid后
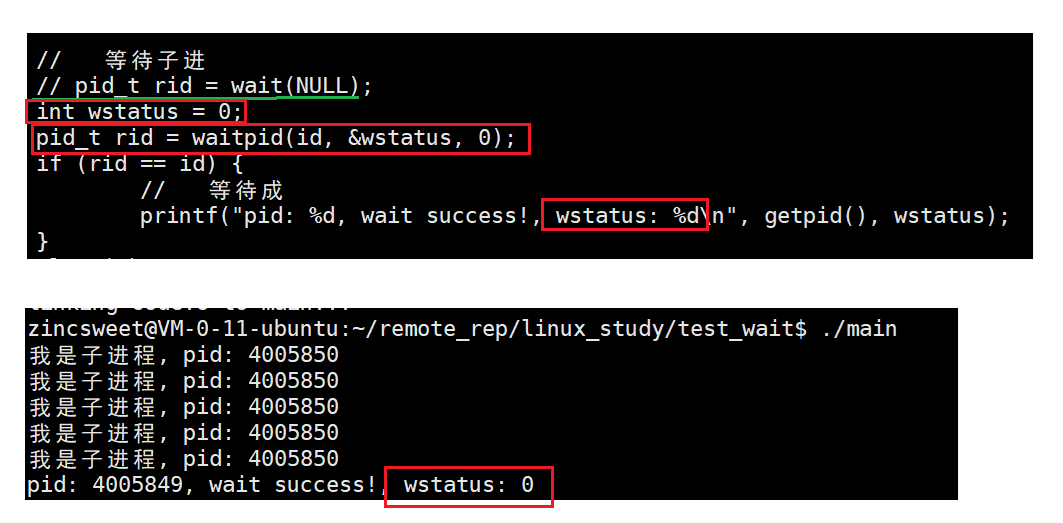
3.waitpid的返回参数wstatus
当我们将子进程的退出码设置为1:
c
if(id == 0) {
int cnt = 5;
while (cnt--) {
printf("我是子进程, pid: %d\n", getpid());
sleep(1);
}
exit(1); // 修改
}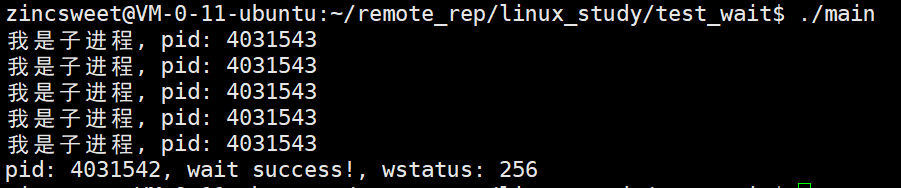
我们知道wstatus是获取子进程退出信息的!子进程退出有三种情况,三种情况与两个数字有关;
所以wstatus本质是得到进程退出的两个数字!!!
那一个wstatus怎么得到两个数字呢?其实wstatus是有32个比特位
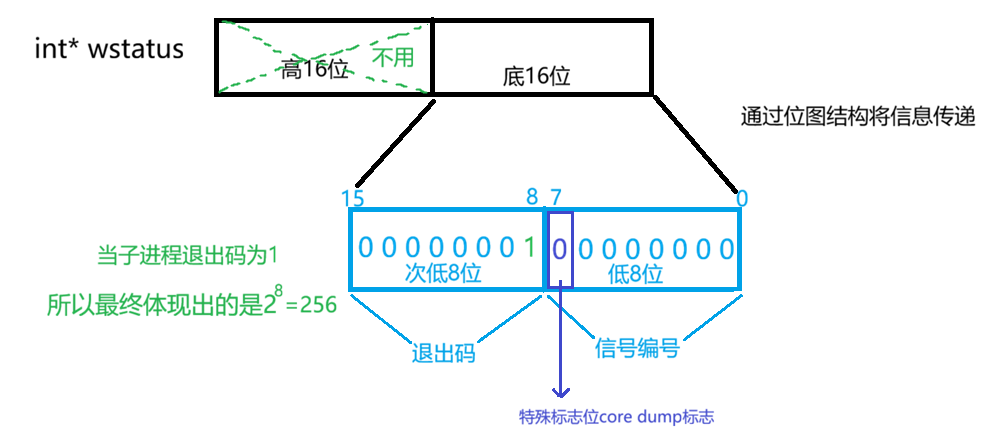
所以当我们需要拿到具体的退出码或者错误码时,底层用的是位移>>加 按位与& ;平常使用时就用定义好的宏;
c
int exit_code = ((wstatus >> 8)&0xff); // 1111 1111
int exit_sig = wstatus&0x7f; // 0111 1111
c
// 将子进程退出码改为123
exit(123);
那我们再试一试,将父子都设置成死循环,再通过kill -9杀死子进程,会发生什么

此时父进程立马回收,并显示子进程的退出信号9。
4.阻塞与非阻塞
第三个参数 options 决定阻塞 / 非阻塞
(1)阻塞模式(默认)
c
waitpid(pid, &status, 0);options=0= 阻塞等待- 逻辑:父进程卡死不动,一直等到指定子进程退出,函数才返回
- 特点:父进程暂停执行,专一等子进程结束
(2)非阻塞模式
c
waitpid(pid, &status, WNOHANG);options=WNOHANG= 非阻塞- 逻辑:不等!立刻返回
- 子进程已退出:返回子进程 PID
- 子进程还在运行:立刻返回 0,父进程继续往下跑代码
非阻塞的用法
如果只用一次非阻塞:子进程没结束就直接跳过回收 ,容易产生僵尸进程
正确用法:循环轮询
c
while(1)
{
// 非阻塞查看
pid_t ret = waitpid(-1, NULL, WNOHANG);
if(ret > 0)
printf("回收子进程\n");
else if(ret == 0)
{
// 子进程还在跑,父进程做别的事
printf("子进程运行中,父进程忙别的\n");
sleep(1);
}
else
break; // 没有子进程了
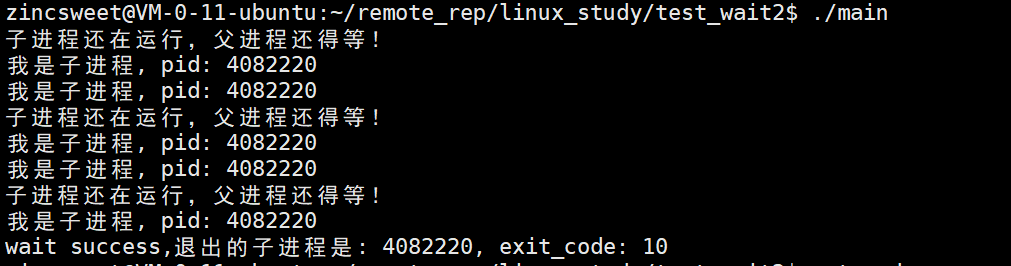
}完整的测试代码:
c
#include<stdio.h>
#include<unistd.h>
#include<string.h>
#include<error.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/wait.h>
int main() {
pid_t id = fork();
if(id == 0) {
int cnt = 5;
while (cnt--) {
printf("我是子进程, pid: %d\n", getpid());
sleep(1);
}
exit(10);
}
else {
while (1) {
int wstatus = 0;
pid_t rid = waitpid(id, &wstatus, WNOHANG);
if (rid > 0) {
printf("wait success,退出的子进程是: %d, exit_code: %d\n",rid, WEXITSTATUS(wstatus));
break;
}
else if (rid == 0) {
printf("子进程还在运行,父进程还得等!\n");
sleep(2);
}
else {
perror("waitpid\n");
break;
}
}
}
return 0;
}
五、进程程序替换
1.现象
C语言头文件<unistd.h>中有一系列程序替换的相关函数exec*:
c
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ...,char *const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execve(const char *path, char *const argv[], char *const envp[]);试试execl函数
c
#include<stdio.h>
#include<unistd.h>
int main() {
printf("我变成了一个进程:%d\n", getpid());
// 执行另一个程序
execl("/usr/bin/ls","-a","-l",NULL); // 程序替换函数
printf("我的代码运行中...");
printf("我的代码运行中...");
printf("我的代码运行中...");
printf("我的代码运行中...");
return 0;
}
我们发现,此时进程没有执行之后的代码,而是执行了ls -a -l!
2.原理
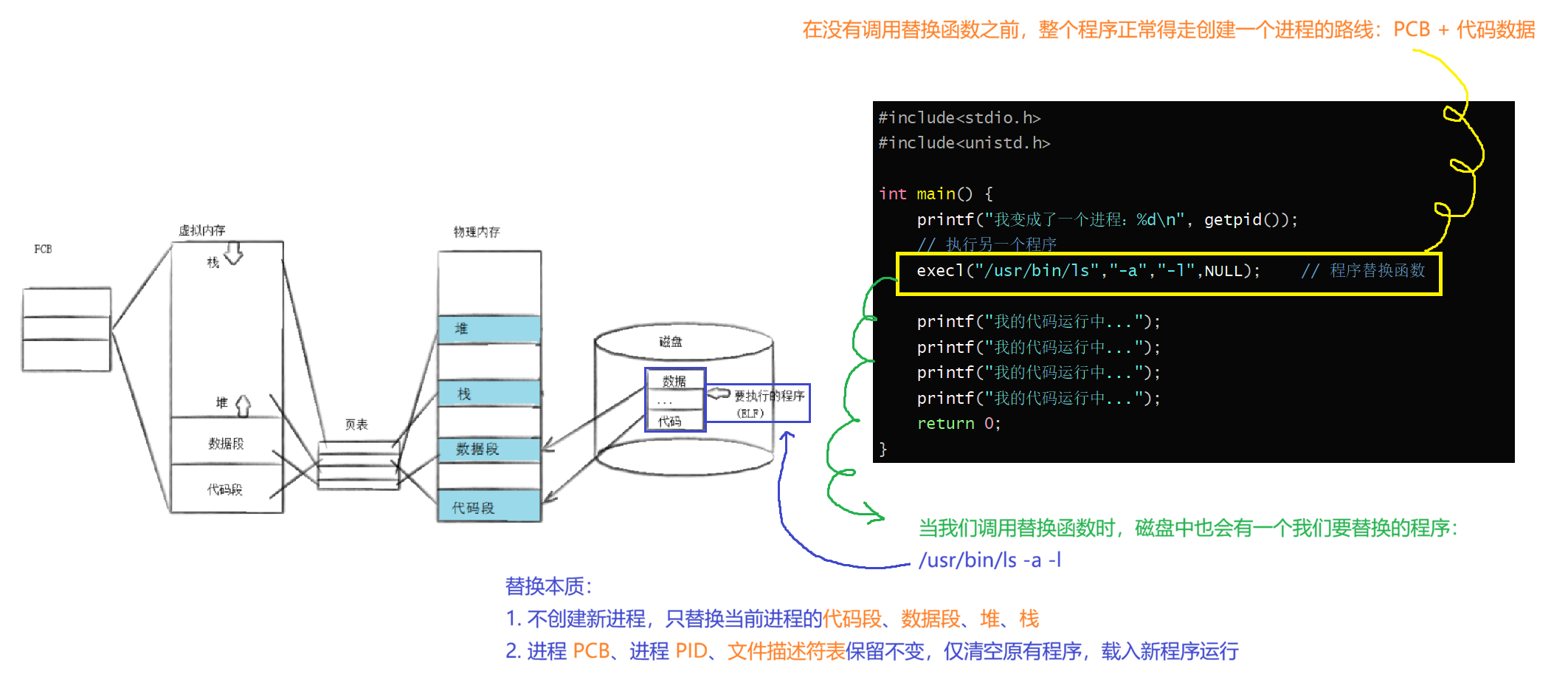
其中我们发现,在替换的过程中,有一个文件的IO过程,它是由OS来完成的。
(补充)在运行代码程序时,其实最开始运行的程序是一个加载器 ,加载器通过找到需要运行的目标程序,进行程序替换来运行那个目标程序。
而且一般我们用程序替换都是在子进程中替换 ;而且因为子进程需要替换,那么肯定就不能还和父进程共享数据了,此时就会发生写实拷贝;
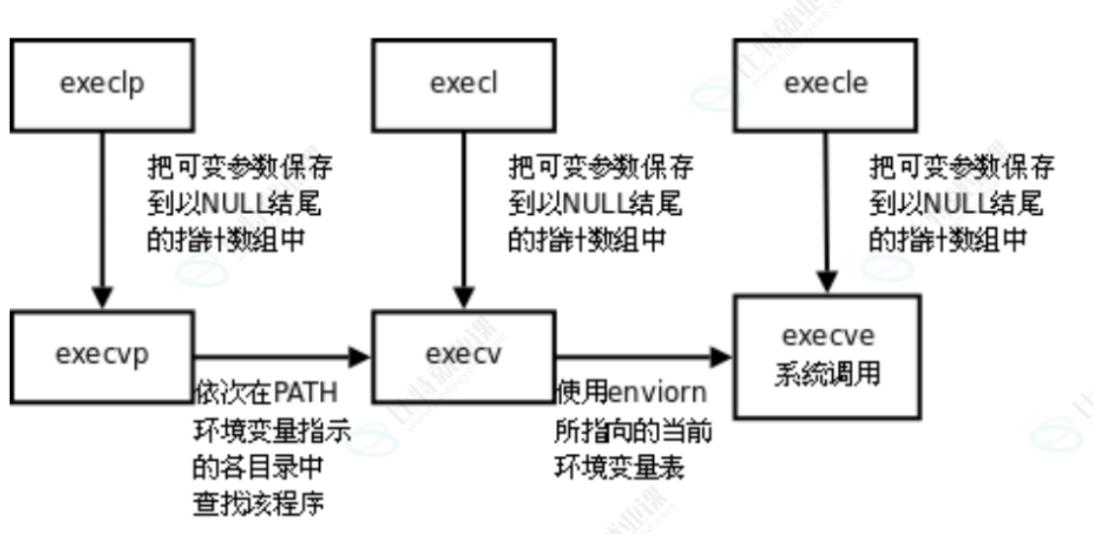
3.系列函数说明
execl、execlp、execle、execv、execvp、execve
l(list): 表示参数采用列表,那么实际传参里就要有NULLv(vector): 参数用数组,实际传参里可以没有NULLp(path): 有 p 自动搜索环境变量 PATHe(env): 表示自己维护环境变量,传入时用的就是自己的新的,系统的不参与
返回值规则相同
-
成功时:程序直接被新程序覆盖,原来代码全部没了 ,所以不会回到
exec*后面代码,无返回值 -
失败时:会 return -1,用来告诉程序:启动新程序失败了,继续往下跑原来代码。
传参规则
(1)execl
c
// 格式:execl(全路径, 程序名, 参数1, 参数2, ..., NULL);
execl("/bin/ps", "ps", "-ef", NULL);- 必须写绝对路径
- 挨个写参数,末尾补NULL
(2)execlp
c
// 格式:execlp(程序名, 程序名, 参数..., NULL);
execlp("ps", "ps", "-ef", NULL);- 不用全路径,自动搜 PATH
- 其余同 execl,逐个传参
(3)execle
c
char *const envp[] = {"PATH=/bin:/usr/bin", "TERM=console", NULL};
// 格式:execle(全路径, 程序名, 参数..., NULL, 自定义环境数组);
execle("/bin/ps", "ps", "-ef", NULL, envp);- 绝对路径 + 逐个传参
- 最后多传一层环境变量数组
(4)execv
c
char *const argv[] = {"ps", "-ef", NULL};
// 格式:execv(全路径, 参数字符串数组);
execv("/bin/ps", argv);绝对路径
- 所有参数提前放进char * 数组,数组尾存 NULL
(5)execvp
c
char *const argv[] = {"ps", "-ef", NULL};
// 格式:execvp(程序名, 参数字符串数组);
execvp("ps", argv);- 搜 PATH,不用全路径
- 参数放数组传入
(6)execve(原生系统调用)
c
char *const argv[] = {"ps", "-ef", NULL};
char *const envp[] = {"PATH=/bin:/usr/bin", "TERM=console", NULL};
// 格式:`execve(全路径, 参数数组, 环境变量数组);`
execve("/bin/ps", argv, envp);- 三个参数:路径、参数数组、环境数组
- 无可变参,纯数组传参
(7)传入环境变量注意
如果传入的是自己整的一个数组比如像:char *const envp[] = {"PATH=/bin:/usr/bin", "TERM=console", NULL};,函数用的时候就只会用到数组里面仅有的这些,进程不会用原有的系统环境变量;
当我们需要用到进程原有的系统环境变量 并且还要追加用自己的时,我们可以取到:
首先要将环境变量定义出来;再用函数putenv()追加自己的;
c
char* const argv[] = {"myexe", "-a", NULL};
extern char** environ;
putenv((char*)"myenv=abcd");
execve("./myexe", argv, environ);(补充)所以之前main函数的环境变量的参数,也是父进程通过程序替换时传入的参数。
f", NULL};
char *const envp\[\] = {"PATH=/bin:/usr/bin", "TERM=console", NULL};