
◆ 博主名称: 晓此方-CSDN博客 大家好,欢迎来到晓此方的博客。
⭐️Linux系列个人专栏: 【主题曲】Linux
⭐️此方的GitHub: github_此方
⭐️ Re系列专栏:我们思考 (Rethink) · 我们重建 (Rebuild) · 我们记录 (Record)
文章目录
- 概要&序論
- 一、进程的概念
-
- 1.1进程的课本概念
- 1.2进程的实际概念
- 1.3初见系统调用与查看我们的进程
- 1.4进程父子关系
-
- 1.4.1进程树
- 1.4.2子进程的创建
- 1.4.3一个函数为什么可以有两个返回值
- [1.4.4 else 和 if else 为什么可以同时执行?](#1.4.4 else 和 if else 为什么可以同时执行?)
- [1.4.5 一个局部变量为什么可以同时等于 0 和大于 0?](#1.4.5 一个局部变量为什么可以同时等于 0 和大于 0?)
- 1.4.6补充一个有趣的进程------守护进程(了解)
概要&序論
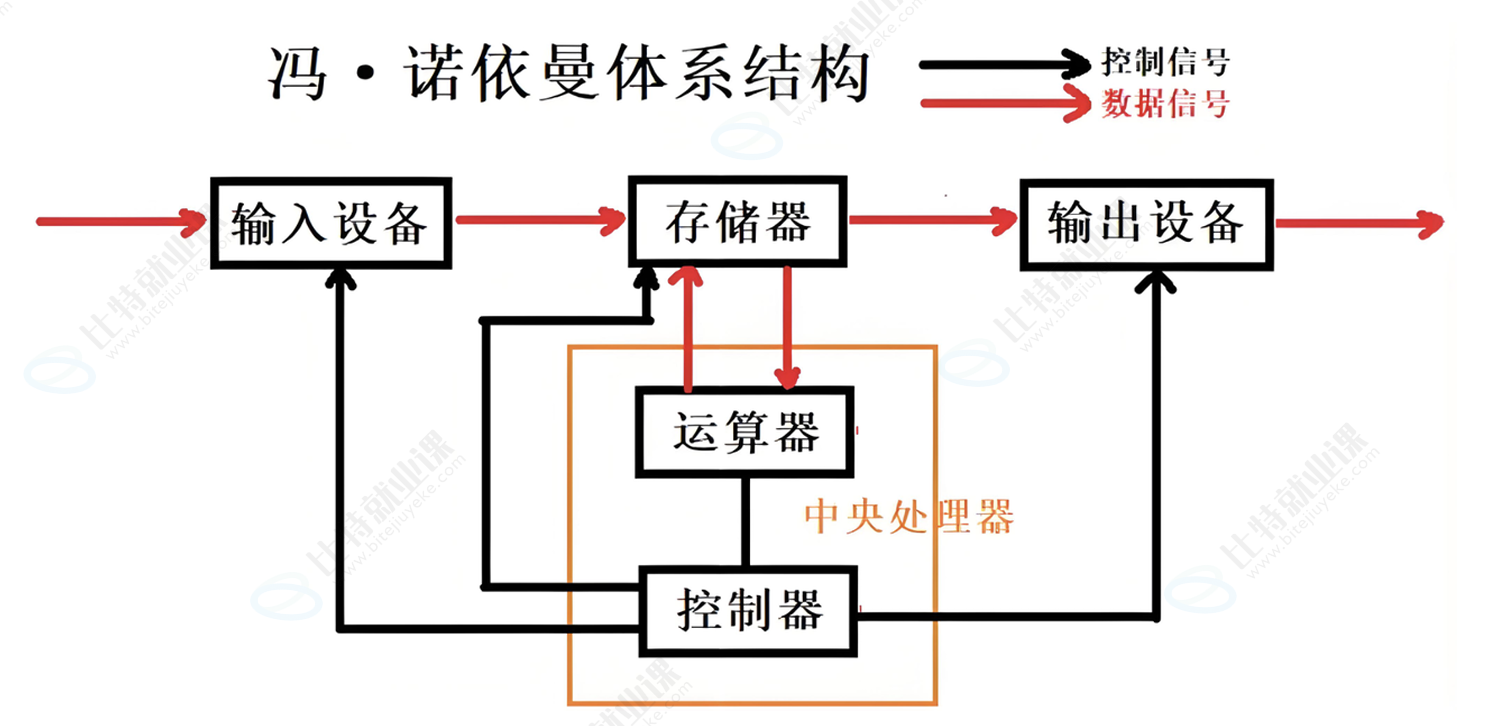
Hello大家好,我是此方 ,上文我们初步探讨了**进程** 这个话题,了解了冯诺依曼体系结构和软硬件体系的层状结构,最重要的还是一句话"先描述,再组织。 "今天将正式开始对进程概念的理解。好的,现在我们开始吧。
一、进程的概念
1.1进程的课本概念
- 课本概念: 程序的一个执行实例,正在执行的程序等。
- 内核观点: 担当分配系统资源(CPU时间,内存)的实体。
- 当前: 进程 = 内核数据结构(
task_struct) + 自己的程序代码和数据。
如果说进程的概念我就这么讲的话,未免也太不负责任了,以上的概念实际上是已经了解它的人提出的精辟的总结 ,不适合我们直接拿来讲。
那么,进程------到底是什么?
1.2进程的实际概念
1.2.1什么是PCB/task_struct
我们上一篇文章中了解到 :程序没有被运行起来的时候都是一个个在磁盘上的文件,在运行起来之后就要被加载进内存。
此时,操作系统(OS)必然要对多个被加载到内存中的程序进行管理。
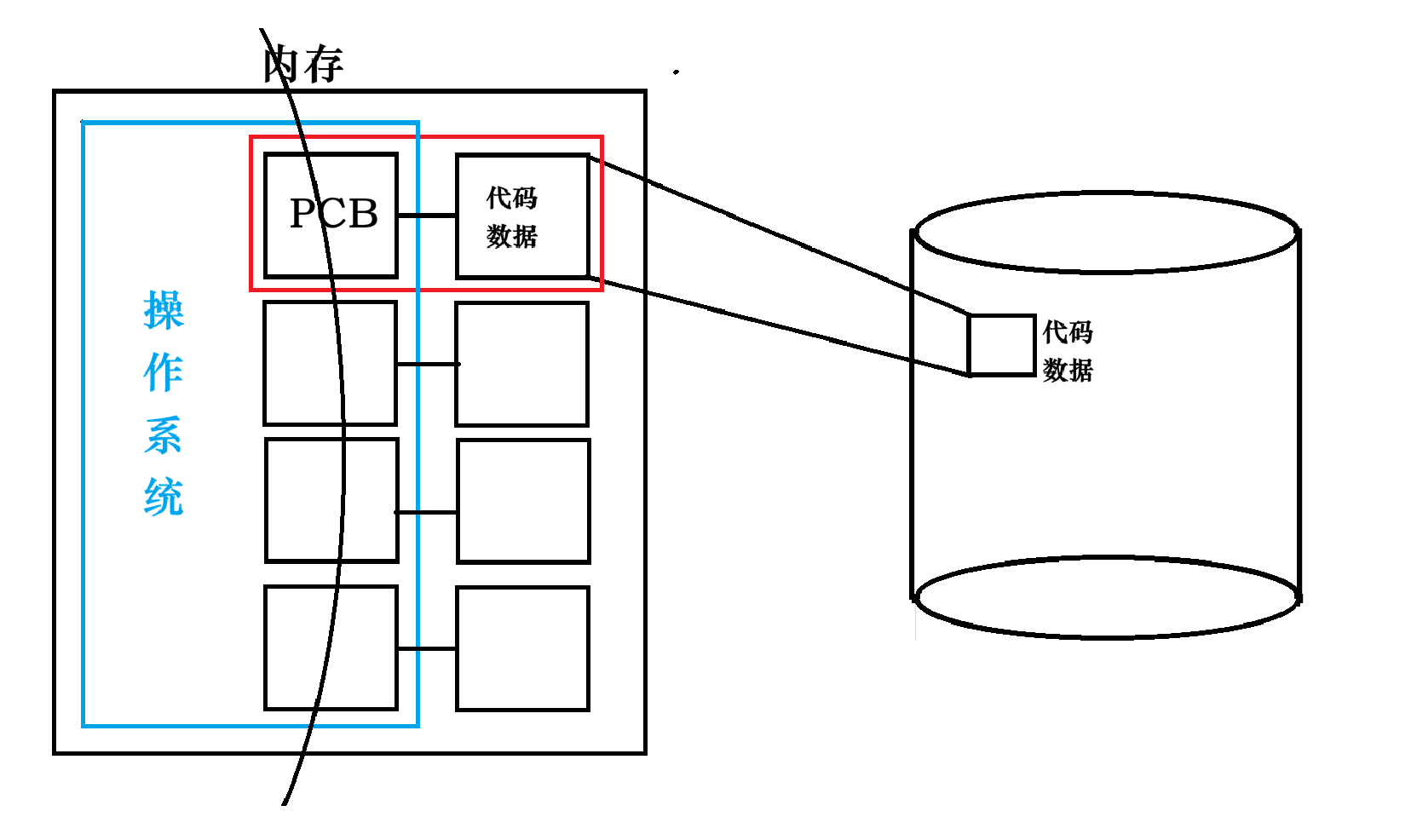
管理的核心逻辑是:先描述,再组织。
先描述,操作系统描述进程的各种数据,创建了一个PCB,PCB是什么?
PCB 全称是 Process Control Block ,即进程控制块。
PCB就可以理解为进程的一个"户口本"。
在 Linux 操作系统中,用于描述进程的结构体叫做 struct task_struct(PCB和task_struct是抽象和具体的关系 )。它包含了进程的所有属性 。我们举例几个(后面的文章中都会讲,实际上这里面有上百个描述信息 )
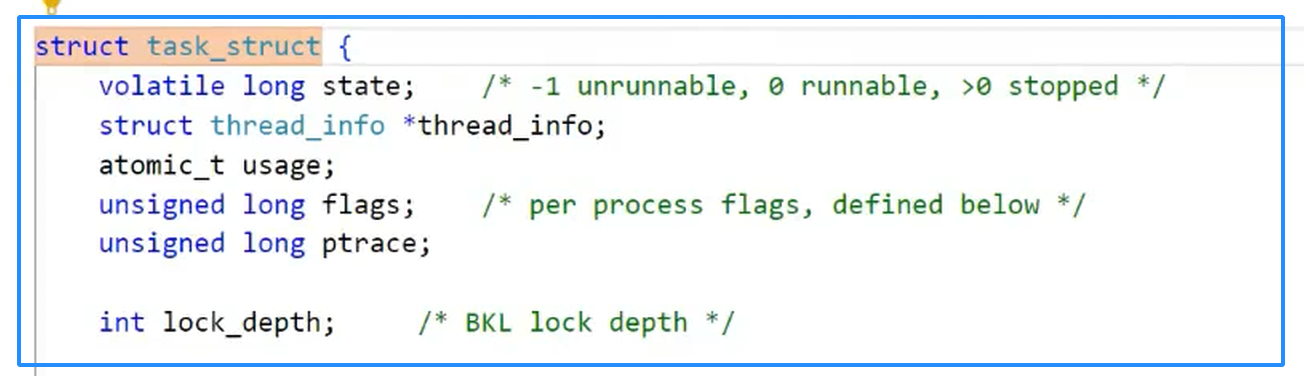
- 标示符:描述本进程的唯一标示符,用来区别其他进程。
- 状态:任务状态,退出代码,退出信号等。
- 优先级:相对于其他进程的优先级。
- 程序计数器:程序中即将被执行的下一条指令的地址。
- 内存指针:包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
- 上下文数据:进程执行时处理器的寄存器中的数据休学例子,要加图CPU,寄存器。
- I / O状态信息:包括显示的I/O请求,分配给进程的I / O设备和被进程使用的文件列表。
- 记账信息:可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
1.2.2操作系统内部组织的进程链表
再组织,操作系统再每一个task_struct里面都放了一个指针,于是每一个PCB连接在一起。形成了一个链表。
最终 :对进程的管理,最终就变成了对链表的增删查改。
- 增加:加入一个新的PCB,然后用它指向我们新的被加载进来的代码与数据
- 删除 :一个代码运行结束,将我们的一个对应的PCB删除(从链表中)
操作不是直接去操作我们的代码与数据,而是去找我们的PCB,用PCB去修改我们的代码与数据
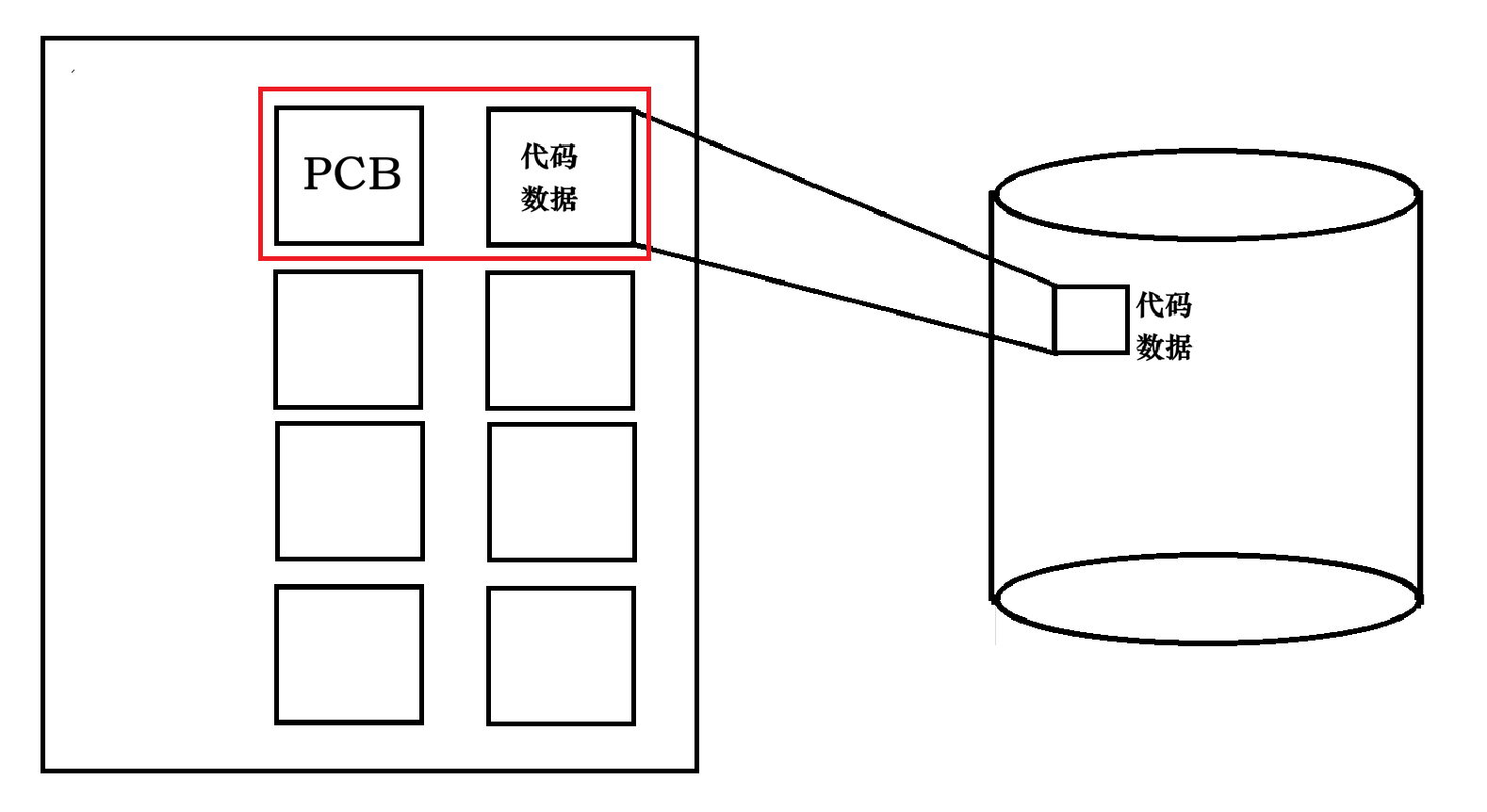
但是我们还是不是很清楚,进程的链表到底是什么?
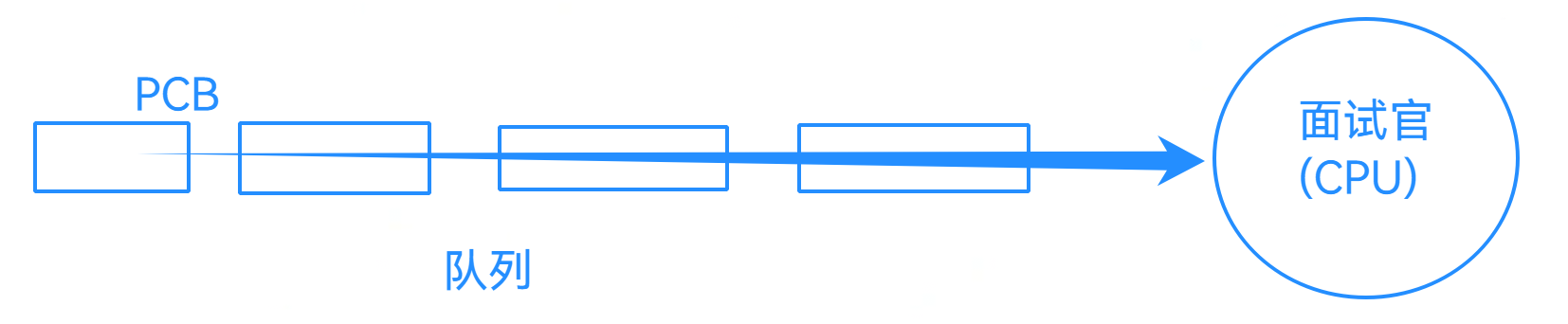
试想一个场景,我们在面试的时候,排成一个长队,然后一个一个找面试官。比喻面试官为CPU,那么我们就是PCB。
但是实际上这种模型不符合实际,准确的来说,不是我们的人在排队,而是我们的简历在排队------也即是:我们人是数据和代码,而简历就是对应我们人的PCB。于是,先描述再组织的结构就清晰了。
1.2.3输出两个结论
没错!关于进程我们首先要输出两个颠覆你想象的概念:
- 进程==PCB+加载到内存的代码和数据,而不是代码和数据。
- 操作系统对进程的管理==操作系统对链表的增删查改。这也是解耦。
1.3初见系统调用与查看我们的进程
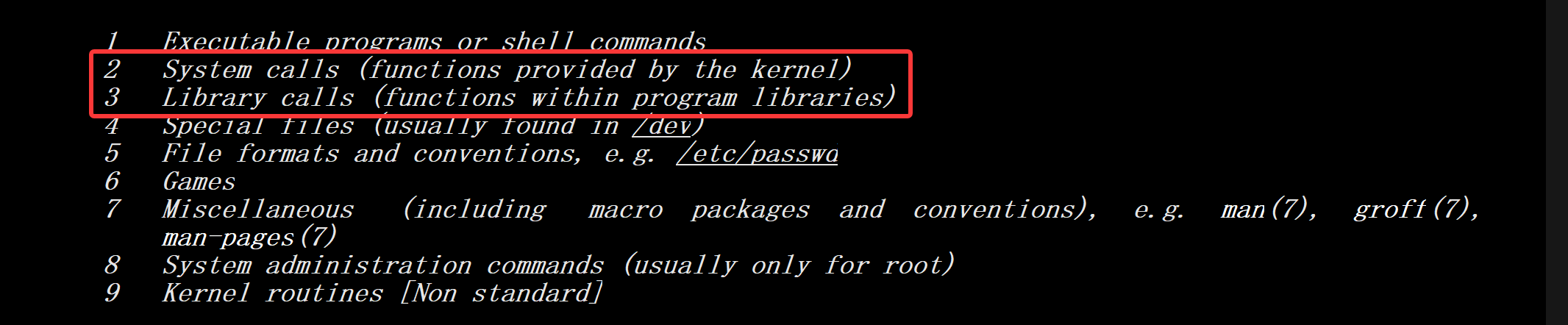
1.3.1系统调用存在哪里
看完上面的理论部分,这会是我们第一次触碰系统调用。首先得知道它在那里查找。 如下的man手册前者是系统调用,后者是库函数调用。
1.3.2第一个系统调用
cpp
1 #include <stdio.h>
2 #include <unistd.h>
3 #include <sys/types.h>
5 int main()
6 {
7 while(1)
8 {
9 sleep(1);
10 printf("我是一个进程!,我的pid: %d\n", getpid()); // 获取当前进程的pid
11 }
12 }-
unistd.h:包含了各种系统服务的函数原型,是访问系统调用(如getpid)的门户。 -
sys/types.h:提供了进程 ID 等数据类型的定义(如pid_t)。 -
sleep:让进程进入休眠状态。(后面进程状态回讲) -
getpid:通过系统调用直接向内核申请获取当前进程的唯一标识符(PID)。
那么除了getpid以外,我还要补充一个系统调用:getppid,获取父进程的pid。
cpp
1 #include <stdio.h>
2 #include <unistd.h>
3 #include <sys/types.h>
5 int main()
6 {
7 while(1)
8 {
9 sleep(1);
10 printf("我是一个进程!,我的pid: %d\n", getppid()); // 获取当前进程的父进程pid
11 }
12 }1.3.3查看一个进程
那么进程创建起来了,让他跑起来后如何查看它呢?我们可以使用 ps axj 命令。该命令会列出系统中所有进程的详细状态信息。
为了更高效地观察进程,我们通常会结合管道和脚本进行优化:
- 基础过滤 :使用
grep '文件名'筛选特定进程。 - 去除干扰 :加上
grep -v grep过滤掉过滤指令本身的进程。 - 保留标题栏 :使用
head -1显示ps输出的首行属性说明。 - 实时监控脚本 :
使用while循环构建一个简单的自动化脚本:
bash
while :; do ps axj | head -1 && ps axj | grep 'myprocess' | grep -v grep; sleep 1; done
pid不会一成不变,当我们ctrl +c杀死进程后,再次运行看到的pid就不一样了。补充,杀死进程的方法还有一个,通过信号杀死:kill -9 进程pid。
但是细心的你肯定发现了:有一个pid是始终不变的
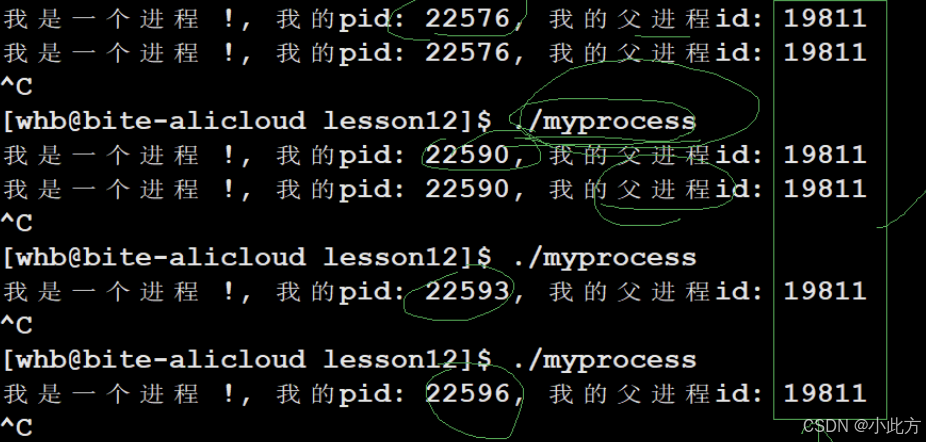
查看它,我们发现,它就是bash。所以说命令行解释器本质上也是一个进程,它是一个会在你的终端不断的打印一个譬如zbc@bite...$并且不断的阻塞等待你输入的一个进程。 操作系统对每一个用户都会创建一个bash。(bash前面的一横杠表示"远程登录")

除了上述的方式查看进程,还有一种方式:通过 /proc 目录查看进程,系统把你的一个一个进程都转化称为了文件。 进程结束,文件消失。
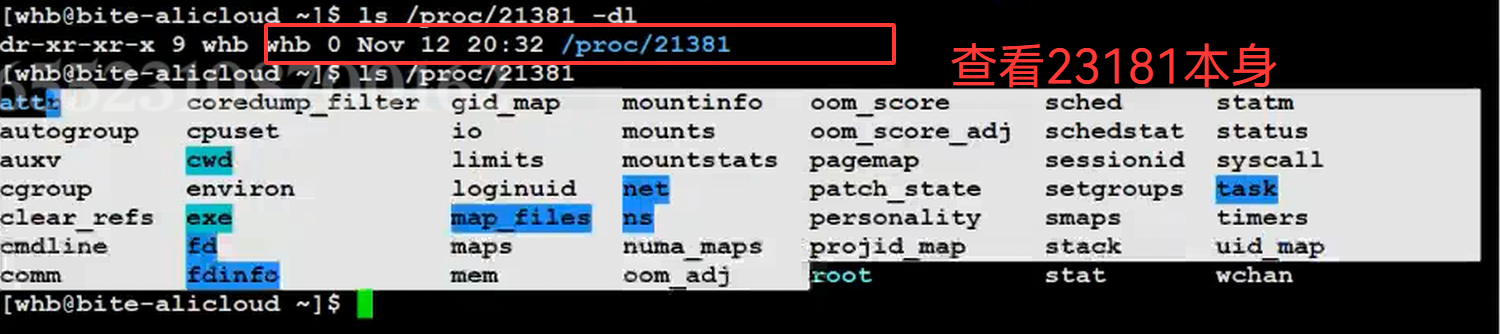
或者打开一个指定的进程的文件夹: /proc/21381, 好,我要补充两个小知识。
1.3.4进程与工作目录
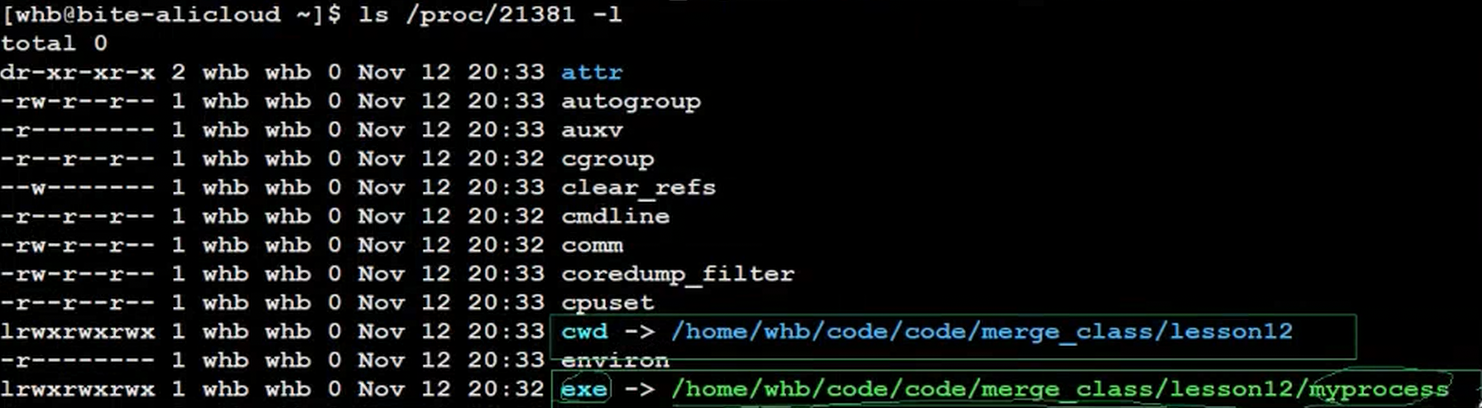
这两个是什么?
bash
exe -> /home/whb/code/code/merge_class/lesson12/myprocess
cwd -> /home/whb/code/code/merge_class/lesson12第一个是进程的路径,让进程知道自己是哪里来的。它的代码和数据在磁盘的什么位置,把它干掉不会影响进程的正常运行。(一般情况下,后面讲挂起的时候再讲这个地址的重要性 )当然你给他干掉了,它会跳红警告。
第二个是进程的当前工作目录 。文件拼接 :当我们在代码中使用相对路径打开文件(如 fopen("hello.txt", "w");)时,系统会自动将 cwd 的路径与文件名进行拼接,从而确定文件在磁盘上的位置。
这也是为什么新建文件默认会出现在可执行文件同级目录的原因------因为进程启动时的
cwd默认继承自父进程(通常是 shell)所在的路径。
动态修改:chdir 系统调用 : 进程可以通过调用 chdir 接口来动态改变自己的工作目录。
cpp
#include <unistd.h>
chdir("/home/whb"); // 将进程的工作目录切换到 /home/whb
fopen("hello.txt", "a"); // 此时文件将创建在 /home/whb 目录下有没有这么想过?其实shell也是一个进程,于是cd命令很可能内部就封装了一个chdir,事实确实如此。
1.4进程父子关系
1.4.1进程树
我们的进程是一个单亲繁殖系统,类似于B树(我们还没有学),一颗多叉树从根结点出发延伸出多个子进程。譬如我们一切的命令都有一个共同的父进程bash。
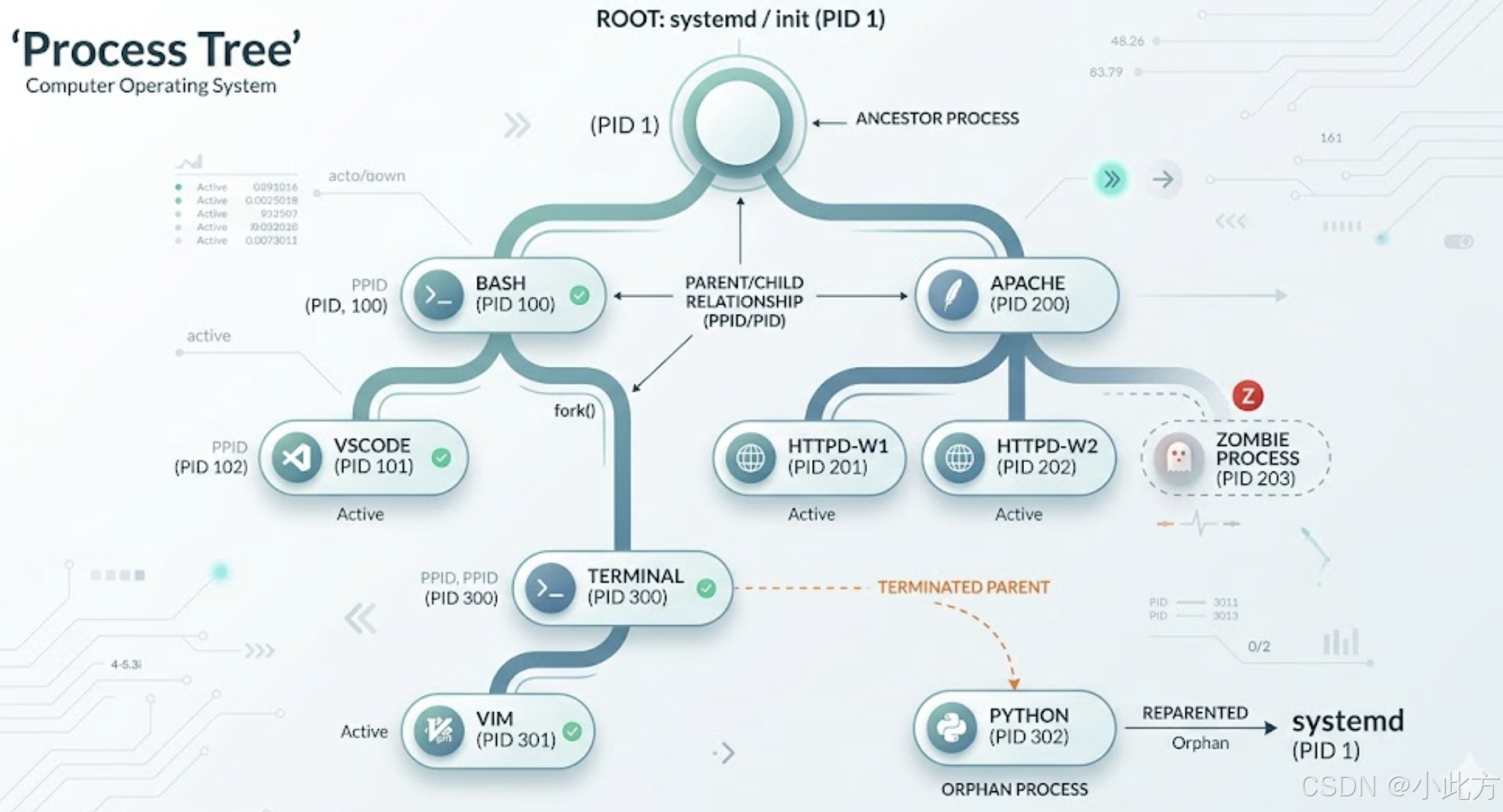
1.4.2子进程的创建
那么进程应该如何创建呢?我们先来介绍一个创建子进程的系统调用: fork()。
头文件:#include <unistd.h>
快速了解一下这个系统调用: 一句话核心:fork()就是进程的"分身术"------调用一次,原地复制出一个几乎一模一样的子进程,让程序实现真正的"分头行动"。
- 作用 :
* 创建分身 :产生子进程,继承父进程的代码和数据。
* 并发处理 :让父子进程同时运行,互不干扰地处理不同任务。
* 环境隔离:子进程在独立空间运行,崩溃不影响父进程。
我们写一个代码然后慢慢讲:
cpp
#include<iostream>
#include<unistd.h>
#include<string>
#include<sys/types.h>
using namespace std;
void Func_Test_Process()
{
pid_t _id = fork();
if(_id < 0)
{
string strerror("fork fail");
throw strerror;
}
else if(_id == 0)
{
while(1)
{
printf( "这是一个子进程,子进程的pid是: %d ,子进程的ppid是: %d .\n",getpid(),getppid());
sleep(1);
}
}
else if(_id > 0)
{
while(1)
{
printf( "这是一个父进程,父进程的pid是: %d ,父进程的ppid是: %d .\n",getpid(),getppid());
sleep(1);
}
}
}
int main()
{
try
{
Func_Test_Process();
}
catch(string&& str)
{
cout<<str<<endl;
}
}如上,父子进程都拿着各自的_id去执行对应的代码。
我们的父进程创建一个子进程,默认是将父进程的PCB中的数据拷贝一份给子进程,并修改一部分内容,比如pid和ppid。于是子进程自然而然地就会指向父进程的那段数据与代码 。于是自然而然地,子进程也会去执行父进程后面的那一段代码。相当于有两个进程同时执行代码。
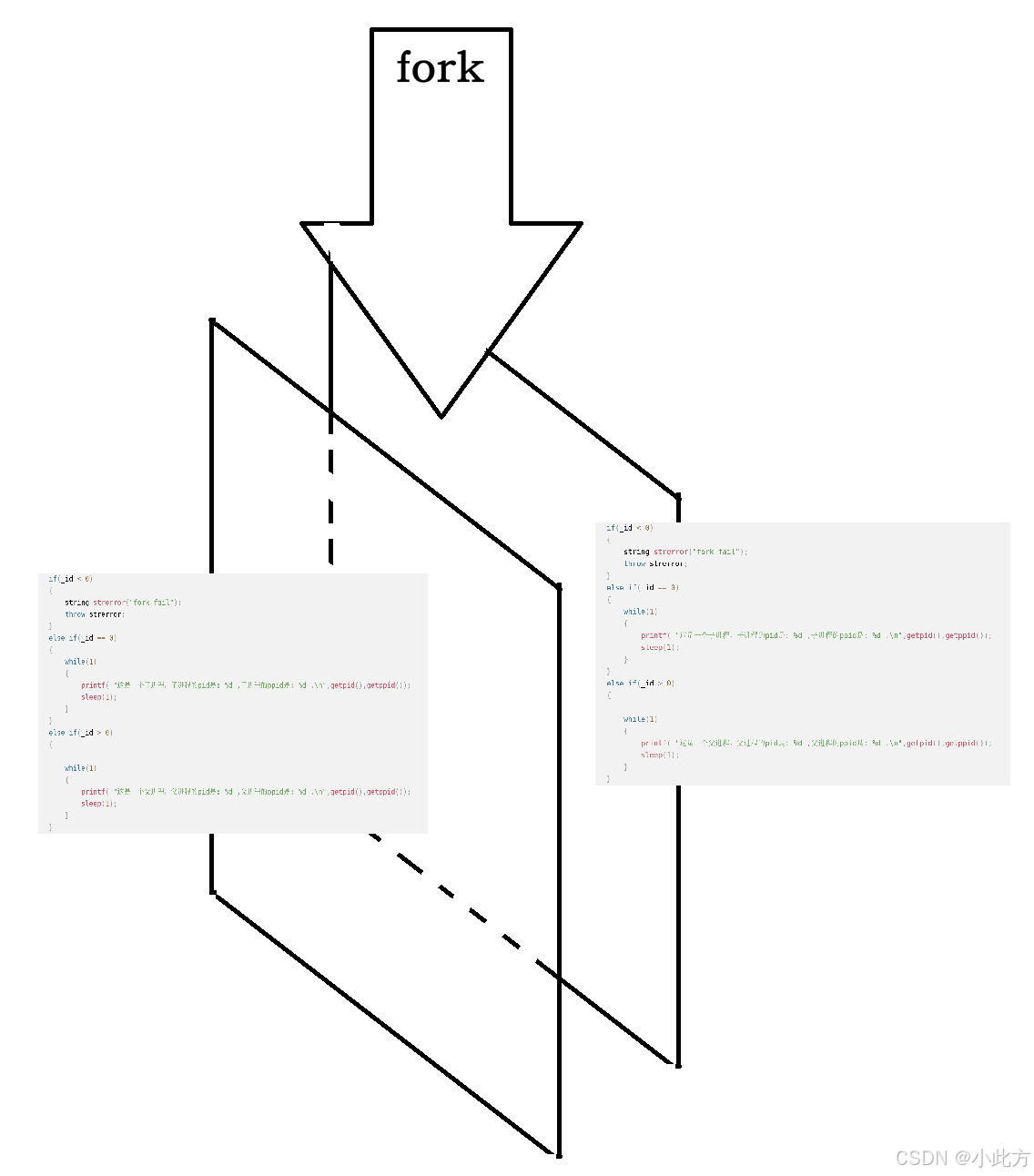
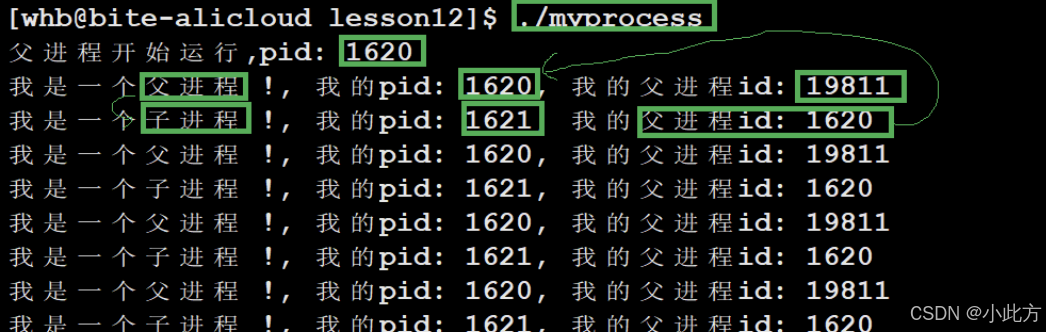
这里父进程获取到子进程的pid,并且子进程获取的id结果是0.为什么?
- 父进程必须获得每一个子进程的pid方便做管理
- 子进程不必获得父进程的pid,因为子进程可以用ppid
如果你看到这里,一定被很多问题困惑着,没错,它确实颠覆了你从C到C++到数据结构以来的代码经验。
于是我们有三个问题需要解决,这些问题看似都违反了C++的语言规则。
- else和ifelse为什么可以同时执行?
- 一个局部变量为什么可以同时=0和>0?
- 一个函数为什么可以有两个返回值?
1.4.3一个函数为什么可以有两个返回值
我们首先来解决第三个问题:一个函数为什么可以有两个返回值?为什么fork可以返回两个值?
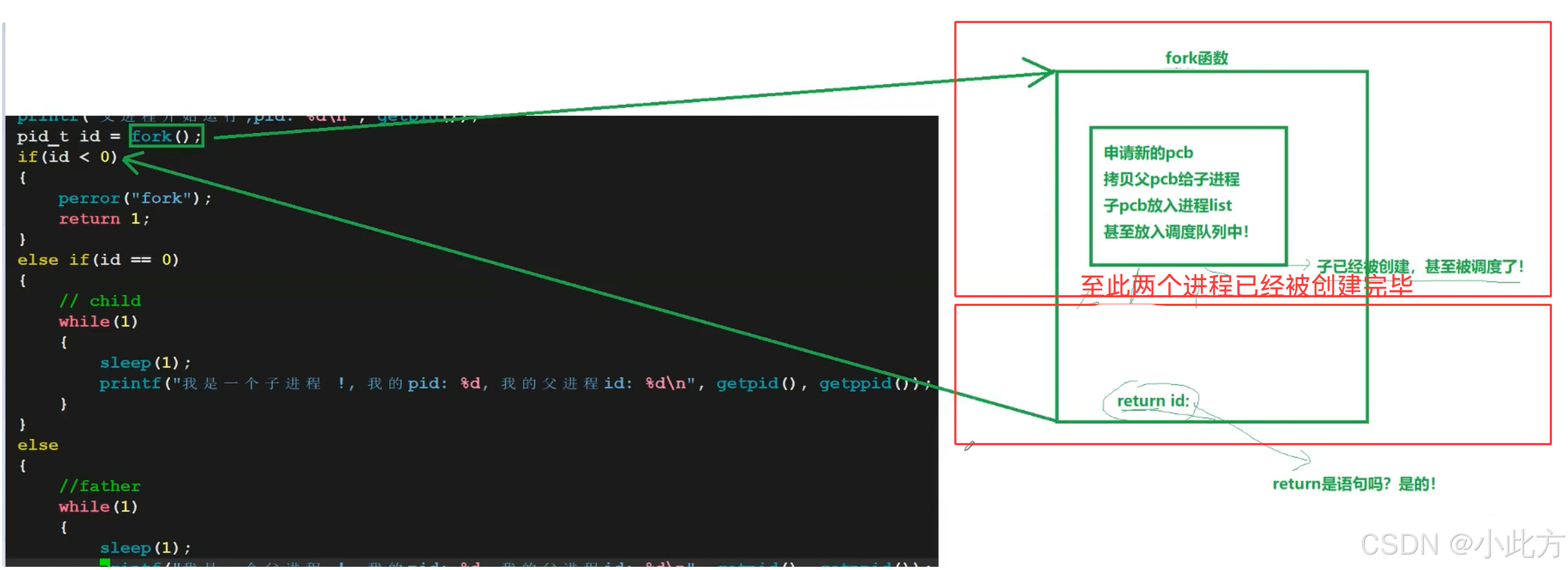
首先我想要问你一个问题:一个函数到达了return,它的核心功能做完了没有? 答案是做完了,fork内部也是如此,也就是说,fork在return之前就已经完成了
- 申请新的pcb
- 拷贝父pcb给子进程
- 子pcb放入进程list
- 甚至放入调度队列中!
那么精确到语句层面,子进程被创建的时间结点一定在return之前,于是fork内部必然会有两个进程返回两个值。
1.4.4 else 和 if else 为什么可以同时执行?
在之前的认知里,if else 和 else 永远互斥。但在 Linux 系统编程中,这个规则被"进程"这个维度打破了。
我们要明确一个概念:代码是共享的,但执行流是独立的。
正如前面所说,当 fork 函数核心逻辑执行完毕时,系统里已经存在两个独立的执行流(父进程和子进程)。
- 父进程 :拿着
fork返回的子进程 PID,继续向下执行。它遇到了if(_id > 0),逻辑判断为真,于是进入该分支。 - 子进程 :拿着
fork返回的 0,也继续向下执行。它遇到了if(_id == 0),逻辑判断为真,于是进入该分支。
所以,并不是"在一个进程里同时执行了两个分支",而是两个进程各自执行了属于自己的那个分支 。由于它们几乎同时在屏幕上打印,才给了你一种"代码逻辑被违背"的错觉。
我只能先讲到这里,这个问题还有疑点,我必须放在进程地址空间里面讲。
1.4.5 一个局部变量为什么可以同时等于 0 和大于 0?
这可能是最令你崩溃的地方:同一个变量 _id,怎么可能既是 0 又是进程号?
这里涉及到了 Linux 内存管理的核心技术------写时拷贝。
1. 初始状态 :fork 刚完成时,子进程的页表指向的物理内存和父进程是同一块 。也就是说,它们最初确实共享同一个 _id 的内存空间。
2. 发生写入 :当 fork 准备返回结果并写入 _id 变量时,操作系统发现有两个进程尝试操作这块内存。
3. 触发拷贝 :为了保证进程的独立性(互不干扰),操作系统会为子进程重新开辟一块物理空间,把父进程的内容拷贝过去,然后修改子进程页表的映射关系。
你在父进程里看 _id,它映射的是一块存着子进程 PID 的物理内存;你在子进程里看 _id,它映射的是另一块存着 0 的物理内存。
由上我们其实还能得出一个结论:进程具有独立性。 两个进程的PCB数据结构是独立的。代码不可修改(后面讲进程程序替换的时候说明这里其实说的不对)即使共享也不会影响,数据又有写时拷贝护着。
1.4.6补充一个有趣的进程------守护进程(了解)
采纳自Gemini:
守护进程 和精灵进程指的是同一种东西。
- 中文术语:守护进程。
- 英文术语:Daemon(原意为"精灵"、"守护神",故部分翻译称之为精灵进程)。
什么是守护进程?
守护进程是生存期长的一种进程。它们通常在系统引导装入时启动,在系统关闭时终止。
它的三个核心特征:
- 后台运行:它没有控制终端(TTY),你无法在屏幕上直接看到它的输入输出。
- 独立于终端:即使你关闭了当前登录的 Shell 窗口,它依然在运行,不受用户登录、注销的影响。
- 周期性/等待性:它通常在等待某个事件发生(比如 Web 服务器等待请求)或周期性执行任务(比如磁盘清理)。
好的本期内容就到这里,如果对你有帮助,还不要忘记点赞三联支持。我是此方,我们下期再见。bye!