原文:https://www.bzarg.com/p/how-a-kalman-filter-works-in-pictures/
卡尔曼滤波器能做什么?
让我们用一个玩具做示例:你制造了一个可以在树林里漫步的小机器人,机器人需要精确知道它的位置以便导航。

我们假设机器人有一个状态 x k ⃗ \vec{x_k} xk ,包含位置和速度:
x k ⃗ = ( p ⃗ , v ⃗ ) (1) \vec{x_k} = (\vec{p}, \vec{v}) \tag{1} xk =(p ,v )(1)
请注意,状态只是关于系统底层配置的一列数字;它可以是任何东西。在我们的例子里是位置和速度,但它可以是关于油箱中的液体量、汽车引擎的温度、用户在触摸板上手指的位置或任何你需要跟踪的东西的数据。
我们的机器人还有一个GPS传感器,精度大约10米,这很好,但它需要比10米更精确的位置信息。树林里有很多沟壑和悬崖,如果机器人误差超过几英尺,就可能掉下悬崖。所以单独的GPS是不够的。
我们也可能知道一些关于机器人如何移动的信息:它知道发送给轮马达的命令,它知道如果它朝一个方向前进且没有干扰,下一瞬间它很可能沿同一方向继续前进。但当然它并不了解自己运动的全部情况:它可能受到风的冲击,轮子可能会轻微打滑,或者在崎岖的地形上滚动;所以轮子转动的量可能并不完全代表机器人实际行驶的距离,预测也不会完美。
GPS传感器 告诉我们一些关于状态的信息,但只是间接的,并且有一些不确定性或误差。我们的预测告诉我们一些关于机器人如何移动的信息,但也只是间接的,并且有一些不确定性或误差。
但是如果我们使用所有可用的信息,我们能否得到比任何一个单独的估计更好的答案?当然答案是肯定的,这就是卡尔曼滤波器的用途。
卡尔曼滤波器如何看待你的问题
让我们看看我们试图解释的图景。我们将继续使用只有位置和速度的简单状态。
x ⃗ = p v (2) \vec{x} = \begin{bmatrix} p\\ v \end{bmatrix} \tag{2} x =pv(2)
我们不知道实际的位置和速度是多少;可能的位置和速度的组合可能有一整系列,但其中某一些比其他的更可能发生:
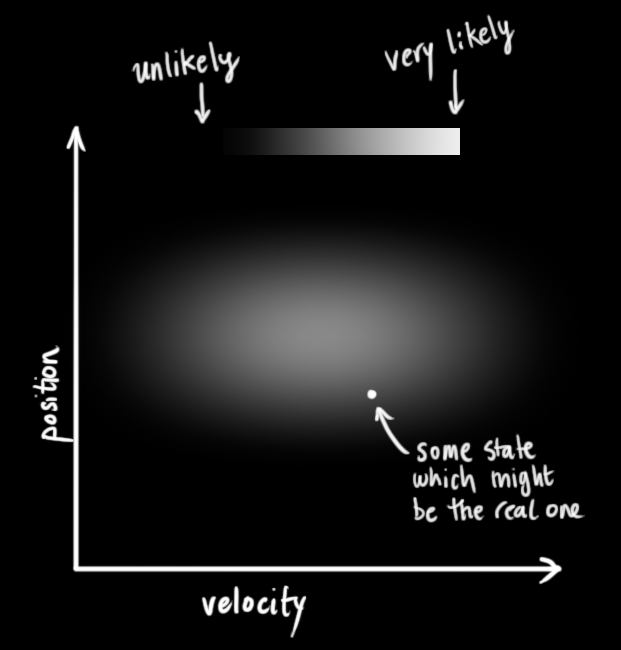
卡尔曼滤波器假设两个变量(在我们的例子中是位置和速度)都是随机的并且服从高斯分布 。每个变量有一个均值 μ \mu μ,它是随机分布的中心(也是最可能的状态),也是一个方差 σ 2 \sigma^2 σ2,即不确定性:
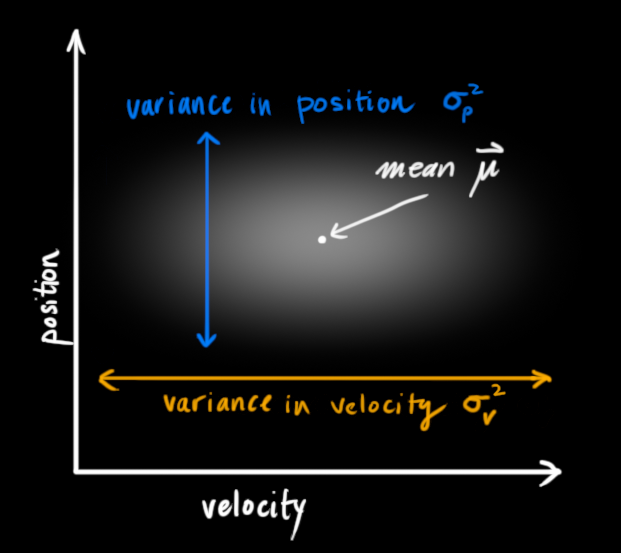
在上图中,位置和速度是不相关的,这意味着一个变量的状态不会告诉你另一个变量可能是什么。
下面的例子显示了更有趣的事情:位置和速度是相关的。观察特定位置的似然取决于你拥有的速度:
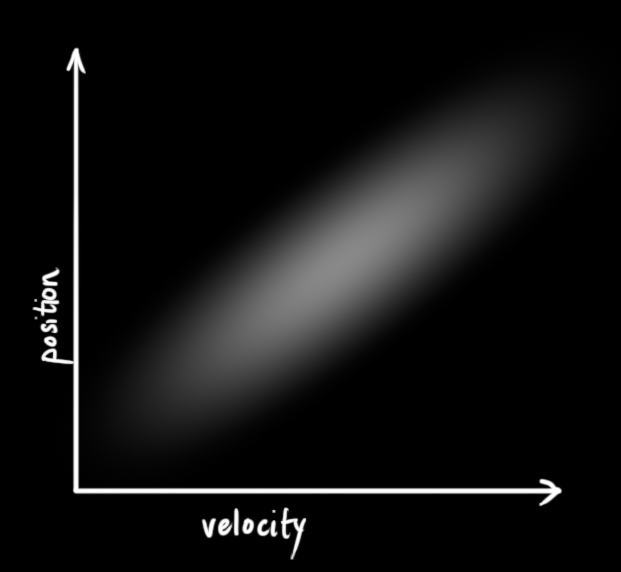
这种情况可能发生在,例如,我们基于旧位置估算新位置时。如果我们的速度很高,我们可能移动得更远,所以我们的位置会更远。如果我们移动缓慢,我们就不会走得那么远。
这种关系真的很重要,需要持续跟踪,因为它给了我们更多信息:一次测量告诉我们一些关于其他可能是什么的信息。这就是卡尔曼滤波器的目标,我们希望从我们的不确定测量中尽可能多地榨取信息!
这种相关性通过一个叫做协方差矩阵 的东西来捕捉。简而言之,矩阵 Σ i j \Sigma_{ij} Σij 的每个元素是第i个 状态变量和第j个 状态变量之间的相关程度。(你可能可以猜到协方差矩阵是对称的,这意味着交换i 和j 无所谓)。协方差矩阵经常被标记为" Σ \mathbf{\Sigma} Σ",所以我们称其元素为" Σ i j \Sigma_{ij} Σij"。
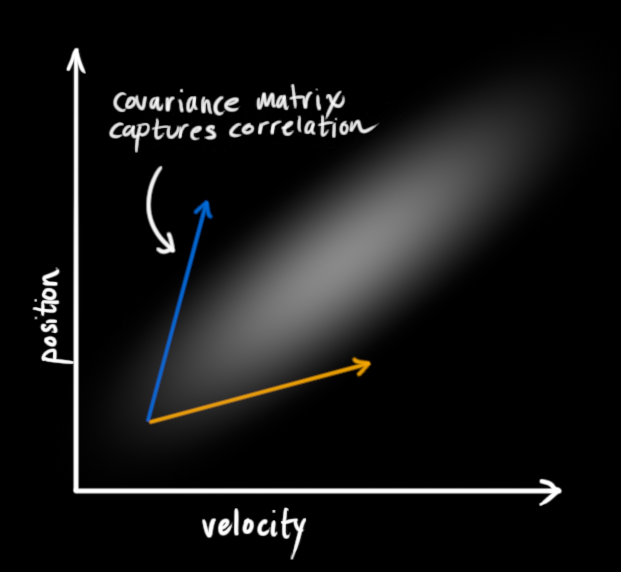
用矩阵描述问题
我们正在将关于状态的知识建模为一个高斯分布,所以我们在时间 k k k 需要两条信息:我们将称我们的最佳估计为 x ^ k \mathbf{\hat{x}_k} x^k(均值,其他地方称为 μ \mu μ),及其协方差矩阵 P k \mathbf{P_k} Pk。
x ^ k = position velocity P k = Σ p p Σ p v Σ v p Σ v v (3) \begin{equation} \begin{aligned} \mathbf{\hat{x}}k &= \begin{bmatrix} \text{position}\\ \text{velocity} \end{bmatrix}\\ \mathbf{P}k &= \begin{bmatrix} \Sigma{pp} & \Sigma{pv} \\ \Sigma_{vp} & \Sigma_{vv} \\ \end{bmatrix} \end{aligned} \end{equation} \tag{3} x^kPk=positionvelocity=ΣppΣvpΣpvΣvv(3)
(当然我们在这里只使用位置和速度,但值得记住的是状态可以包含任意数量的变量,可以代表任何你想要的东西)。
接下来,我们需要一种方法来查看当前状态 (在时间k-1 )并预测 下一个状态 在时间k 。记住,我们不知道哪个状态是"真实的",但我们的预测函数不在乎。它只是对所有状态操作,并给我们一个新的分布:
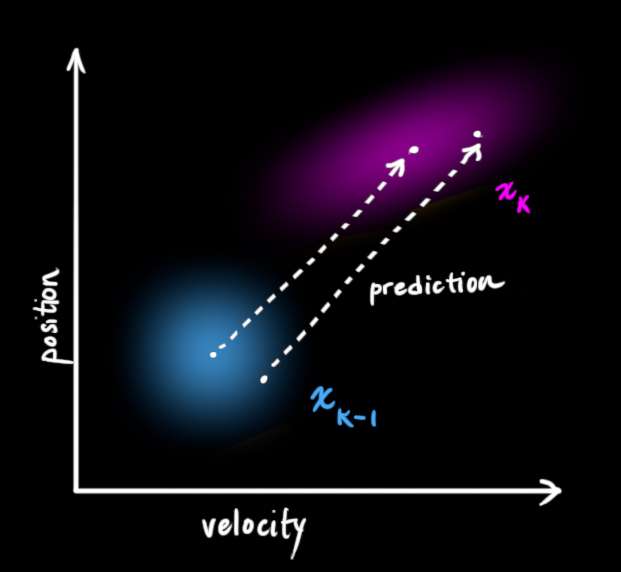
我们可以用一个矩阵 F k \mathbf{F_k} Fk 来表示这个预测步骤:
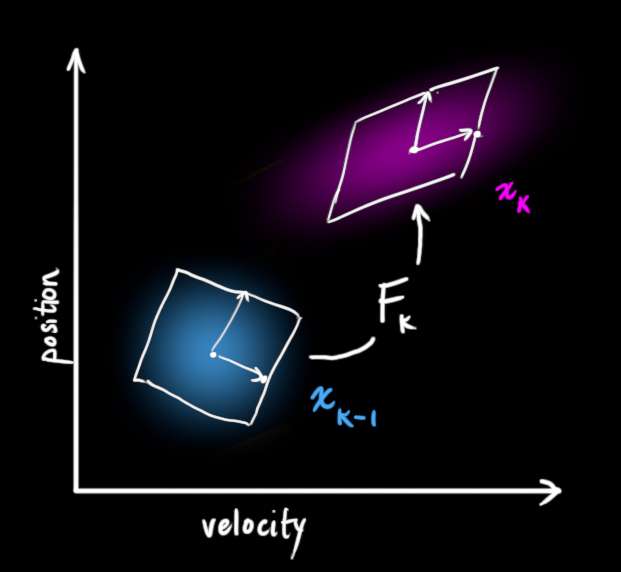
它获取原始估计中的每个点并将其移动到新的预测位置,这就是如果原始估计是正确的,系统将移动到的位置。
让我们应用它。我们将如何使用矩阵来预测未来下一时刻的位置和速度?我们将使用一个非常基本的运动学公式:
p k = p k − 1 + Δ t v k − 1 v k = v k − 1 (4) \begin{align} \color{deeppink}{p_k} &= \color{royalblue}{p_{k-1}} + \Delta t &\color{royalblue}{v_{k-1}} \\ \color{deeppink}{v_k} &= &\color{royalblue}{v_{k-1}} \end{align} \tag{4} pkvk=pk−1+Δt=vk−1vk−1(4)
换句话说:
x ^ k = 1 Δ t 0 1 x ^ k − 1 = F k x ^ k − 1 (5) \begin{align} \color{deeppink}{\mathbf{\hat{x}}k} &= \begin{bmatrix} 1 & \Delta t \\ 0 & 1 \end{bmatrix} \color{royalblue}{\mathbf{\hat{x}}{k-1}} \\ &= \mathbf{F}k \color{royalblue}{\mathbf{\hat{x}}{k-1}} \end{align}\tag{5} x^k=10Δt1x^k−1=Fkx^k−1(5)
我们现在有一个给出下一个状态的预测矩阵,但我们仍然不知道如何更新协方差矩阵。
这就是我们需要另一个公式的地方。如果我们将分布中的每个点乘以一个矩阵 A \color{firebrick}{\mathbf{A}} A,那么它的协方差矩阵 Σ \Sigma Σ 会发生什么?
嗯,很简单。我就直接给你这个恒等式:
C o v ( x ) = Σ C o v ( A x ) = A Σ A T (6) \begin{equation} \begin{split} Cov(x) &= \Sigma\\ Cov(\color{firebrick}{\mathbf{A}}x) &= \color{firebrick}{\mathbf{A}} \Sigma \color{firebrick}{\mathbf{A}}^T \end{split} \end{equation} \tag{6} Cov(x)Cov(Ax)=Σ=AΣAT(6)
因此将 (6) 与方程 (5) 结合起来:
x ^ k = F k x ^ k − 1 P k = F k P k − 1 F k T (7) \begin{equation} \begin{split} \color{deeppink}{\mathbf{\hat{x}}_k} &= \mathbf{F}k \color{royalblue}{\mathbf{\hat{x}}{k-1}} \\ \color{deeppink}{\mathbf{P}k} &= \mathbf{F_k} \color{royalblue}{\mathbf{P}{k-1}} \mathbf{F}_k^T \end{split} \end{equation} \tag{7} x^kPk=Fkx^k−1=FkPk−1FkT(7)
外部影响
不过我们还没有捕捉到一切。可能有一些与状态本身无关的变化------外部世界可能正在影响系统。
例如,如果状态模拟火车的运动,火车操作员可能推动油门,导致火车加速。类似地,在我们的机器人示例中,导航软件可能发出命令来转动轮子或停止。如果我们知道关于世界上正在发生的事情的这些额外信息,我们可以将其放入一个叫做 u k ⃗ \color{darkorange}{\vec{\mathbf{u}_k}} uk 的向量中,对其进行一些操作,并将其作为校正添加到我们的预测中。
假设我们知道由于油门设置或控制命令导致的预期加速度 a \color{darkorange}{a} a。从基本运动学得到:
p k = p k − 1 + Δ t v k − 1 + 1 2 a Δ t 2 v k = v k − 1 + a Δ t (8) \begin{align} \color{deeppink}{p_k} &= \color{royalblue}{p_{k-1}} + {\Delta t} &\color{royalblue}{v_{k-1}} + &\frac{1}{2} \color{darkorange}{a} {\Delta t}^2 \\ \color{deeppink}{v_k} &= &\color{royalblue}{v_{k-1}} + & \color{darkorange}{a} {\Delta t} \end{align} \tag{8} pkvk=pk−1+Δt=vk−1+vk−1+21aΔt2aΔt(8)
以矩阵形式:
x ^ k = F k x ^ k − 1 + Δ t 2 2 Δ t a = F k x ^ k − 1 + B k u k ⃗ (9) \begin{equation} \begin{split} \color{deeppink}{\mathbf{\hat{x}}_k} &= \mathbf{F}k \color{royalblue}{\mathbf{\hat{x}}{k-1}} + \begin{bmatrix} \frac{\Delta t^2}{2} \\ \Delta t \end{bmatrix} \color{darkorange}{a} \\ &= \mathbf{F}k \color{royalblue}{\mathbf{\hat{x}}{k-1}} + \mathbf{B}_k \color{darkorange}{\vec{\mathbf{u}_k}} \end{split} \end{equation} \tag{9} x^k=Fkx^k−1+2Δt2Δta=Fkx^k−1+Bkuk (9)
B k \mathbf{B}_k Bk 被称为控制矩阵 , u k ⃗ \color{darkorange}{\vec{\mathbf{u}_k}} uk 是控制向量。(对于非常简单的系统没有外部影响,你可以省略这些)。
让我们再添加一个细节。如果我们的预测不是对实际发生的事情的100%准确模型,会怎样?
外部不确定性
如果状态根据其自身属性演变,一切都没问题。如果状态根据外部力演变,只要我们知道那些外部力是什么,一切也仍然没问题。
但是关于我们不知道的力呢?例如,如果我们跟踪一架四旋翼飞行器,它可能被风冲击。如果我们跟踪一个轮式机器人,轮子可能打滑,或者地面上的凸起可能使其减速。我们无法跟踪这些事情,如果其中任何一件事发生,我们的预测可能会偏离,因为我们没有考虑那些额外的力。
我们可以通过在每个预测步骤之后添加一些新的不确定性来建模与"世界"(即我们没有跟踪的事物)相关的不确定性:
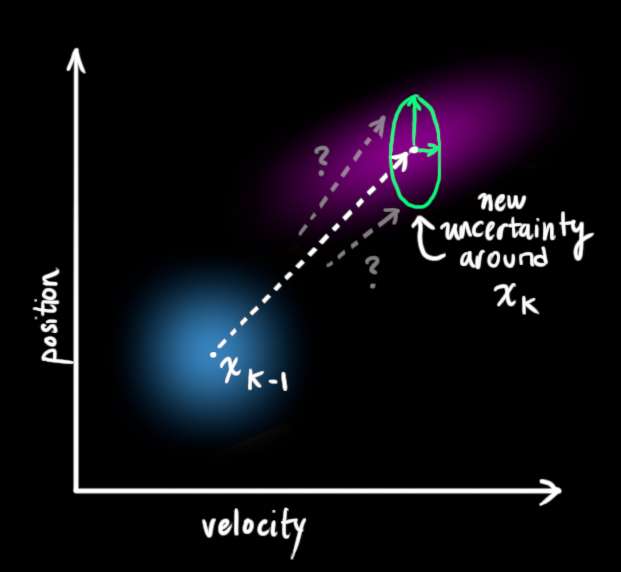
我们原始估计中的每个状态都可能移动到一系列状态。因为我们非常喜欢高斯分布,我们将说 x ^ k − 1 \color{royalblue}{\mathbf{\hat{x}}_{k-1}} x^k−1 中的每个点都被移动到协方差为 Q k \color{mediumaquamarine}{\mathbf{Q}_k} Qk 的高斯分布内的某个地方。另一种说法是,我们将未跟踪的影响视为协方差为 Q k \color{mediumaquamarine}{\mathbf{Q}_k} Qk 的噪声。
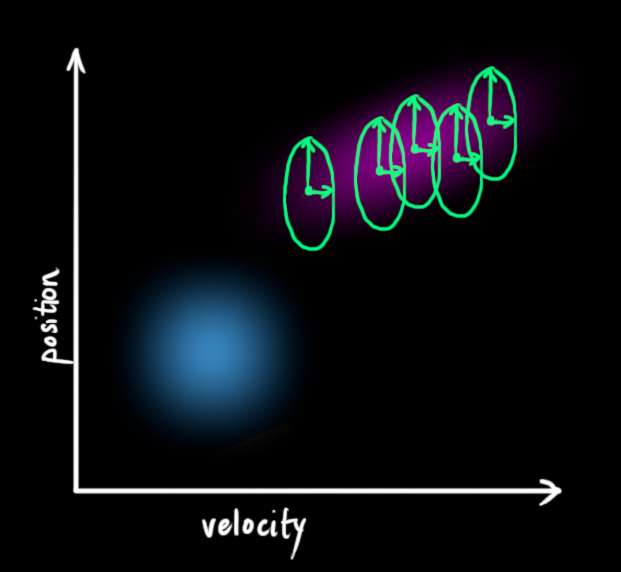
这产生了一个新的高斯分布,具有不同的协方差(但均值相同):
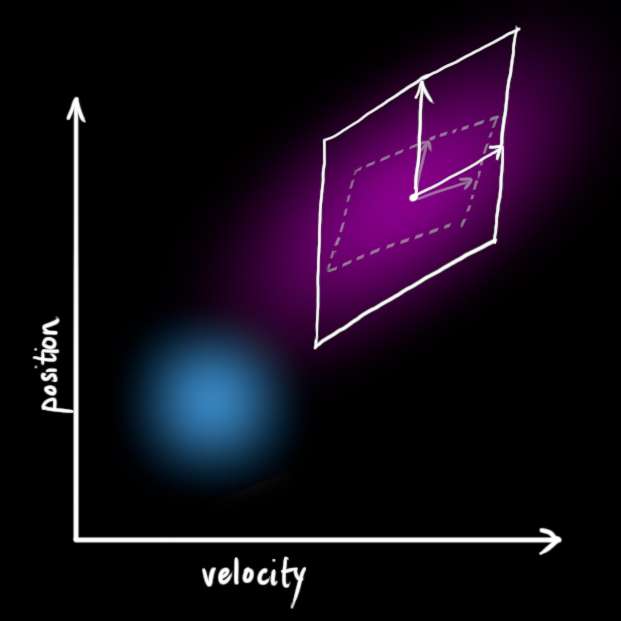
我们通过简单地加上 Q k {\color{mediumaquamarine}{\mathbf{Q}_k}} Qk 得到扩展协方差,给出我们预测步骤的完整表达式:
x ^ k = F k x ^ k − 1 + B k u k ⃗ P k = F k P k − 1 F k T + Q k (10) \begin{equation} \begin{split} \color{deeppink}{\mathbf{\hat{x}}_k} &= \mathbf{F}k \color{royalblue}{\mathbf{\hat{x}}{k-1}} + \mathbf{B}_k \color{darkorange}{\vec{\mathbf{u}_k}} \\ \color{deeppink}{\mathbf{P}k} &= \mathbf{F_k} \color{royalblue}{\mathbf{P}{k-1}} \mathbf{F}_k^T + \color{mediumaquamarine}{\mathbf{Q}_k} \end{split} \end{equation} \tag{10} x^kPk=Fkx^k−1+Bkuk =FkPk−1FkT+Qk(10)
换句话说,新的最佳估计 是根据之前的最佳估计 做出的预测 ,加上对已知外部影响 的校正。
而新的不确定性 是根据旧的不确定性 预测 的,并带有一些来自环境的额外不确定性。
好的,这很简单。我们有一个关于我们系统可能在的位置的模糊估计,由 x ^ k \color{deeppink}{\mathbf{\hat{x}}_k} x^k 和 P k \color{deeppink}{\mathbf{P}_k} Pk 给出。当我们从传感器获得一些数据时会发生什么?
用测量改善估计
我们可能有几个传感器向我们提供关于系统状态的信息。目前它们测量什么并不重要;也许一个读取位置,另一个读取速度。每个传感器告诉我们一些关于状态的间接 信息------换句话说,传感器操作状态并产生一组读数。
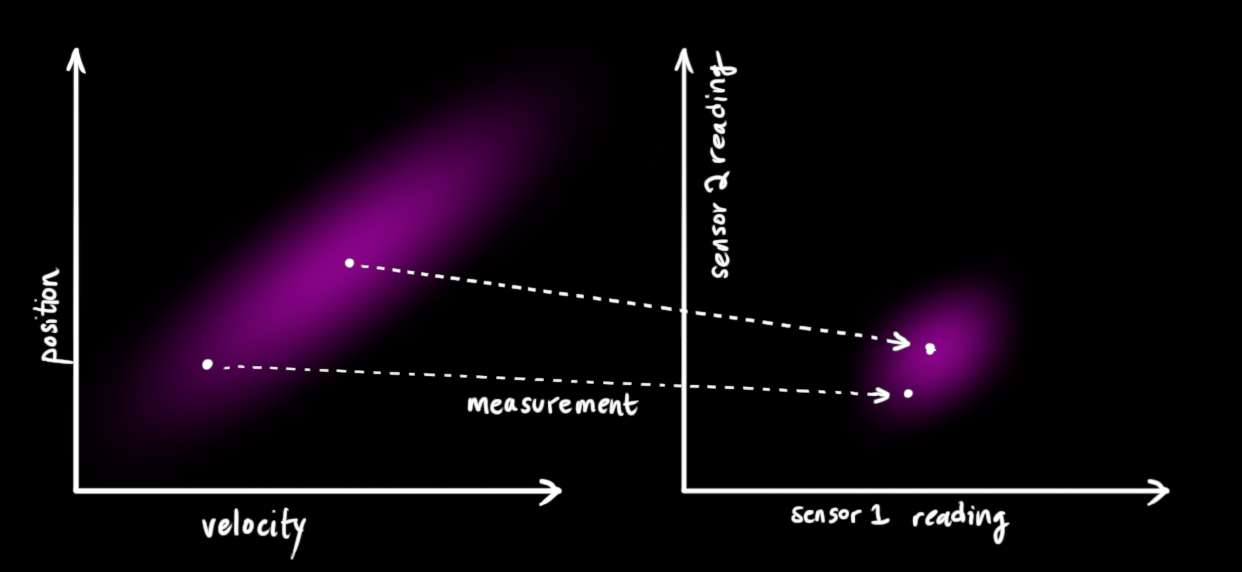
请注意,读数的单位和比例可能与我们跟踪的状态的单位和比例不相同。你可能能猜到这是要往哪里走:我们将用矩阵 H k \mathbf{H}_k Hk 对传感器进行建模。
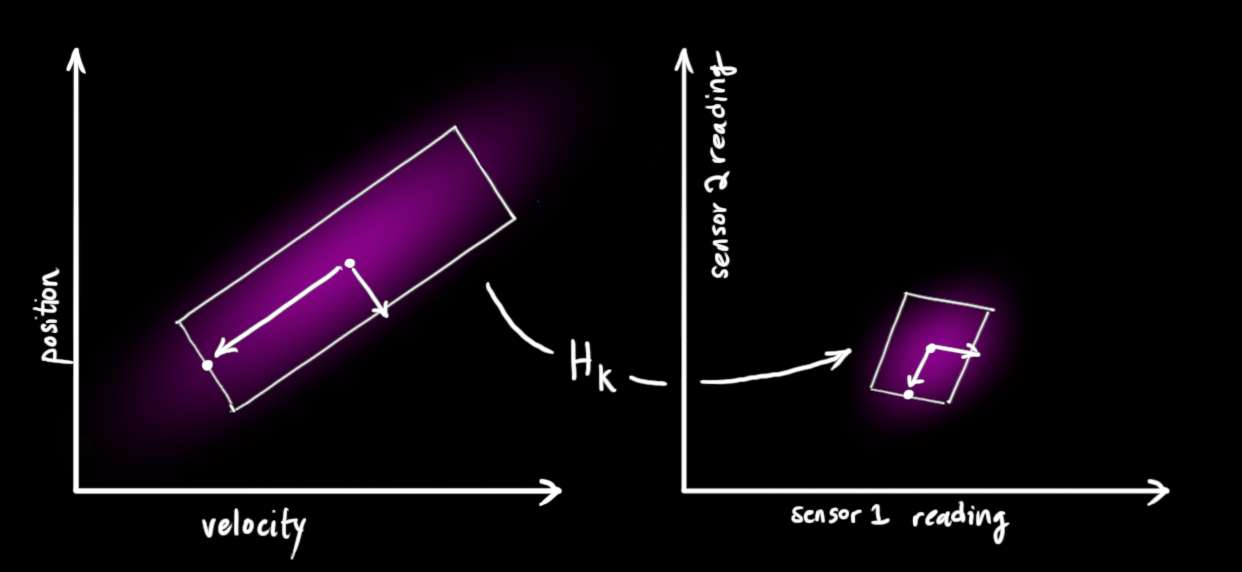
我们可以用通常的方法找出我们期望看到的传感器读数分布:
μ ⃗ expected = H k x ^ k Σ expected = H k P k H k T (11) \begin{equation} \begin{aligned} \vec{\mu}_{\text{expected}} &= \mathbf{H}_k \color{deeppink}{\mathbf{\hat{x}}k} \\ \mathbf{\Sigma}{\text{expected}} &= \mathbf{H}_k \color{deeppink}{\mathbf{P}_k} \mathbf{H}_k^T \end{aligned} \end{equation} \tag{11} μ expectedΣexpected=Hkx^k=HkPkHkT(11)
卡尔曼滤波器非常擅长处理传感器噪声。换句话说,我们的传感器至少有些不可靠,原始估计中的每个状态可能导致一系列传感器读数。
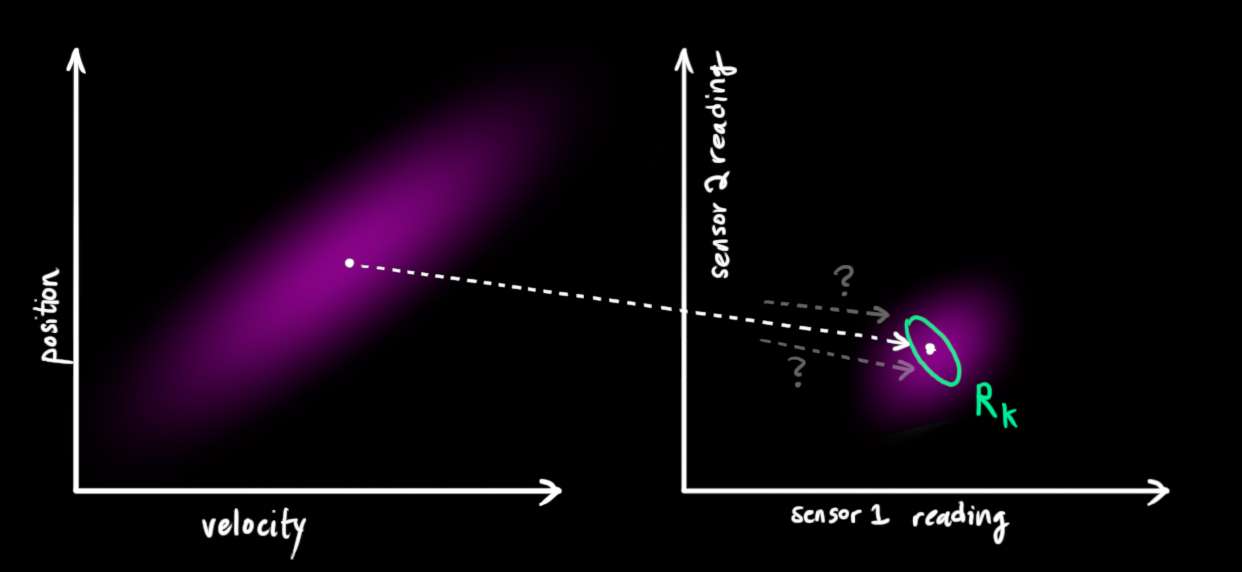
从我们观察到的每个读数,我们可能猜测我们的系统处于特定状态。但因为存在不确定性,某些状态比其他状态更可能产生我们看到的读数:
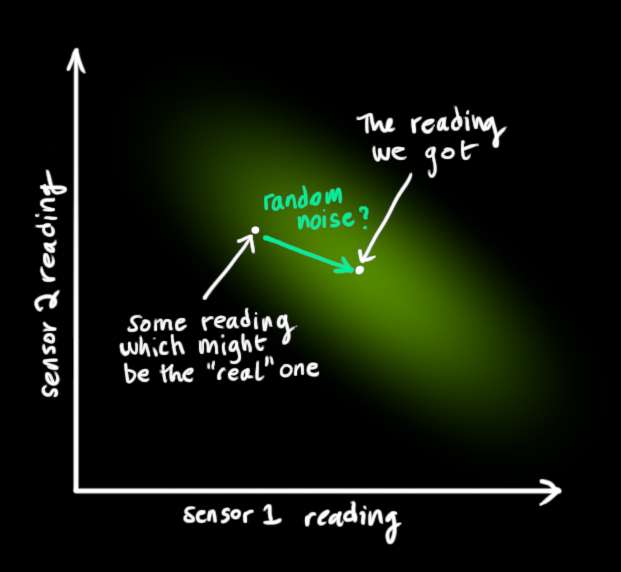
我们将称这个不确定性的协方差 (即传感器噪声)为 R k \color{mediumaquamarine}{\mathbf{R}_k} Rk。该分布有一个均值 等于我们观察到的读数,我们称其为 z k ⃗ \color{yellowgreen}{\vec{\mathbf{z}_k}} zk 。
所以现在我们有两个高斯分布:一个围绕我们转换预测的均值 μ ⃗ expected \vec{\mu}_{\text{expected}} μ expected,另一个围绕我们实际得到的传感器读数 z k ⃗ \color{yellowgreen}{\vec{\mathbf{z}_k}} zk 。
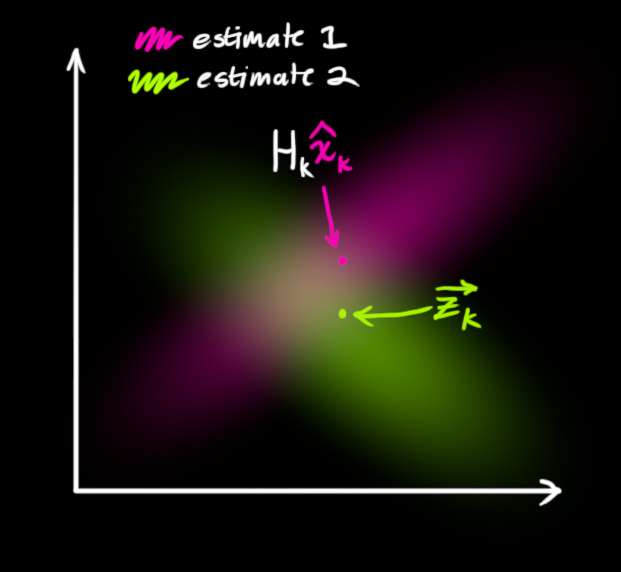
我们必须尝试协调我们基于预测状态 (粉色 )对读数的猜测,与基于我们实际观察到的传感器读数 (绿色)的不同猜测。
那么我们新的最可能状态是什么?对于任何可能的读数 ( z 1 , z 2 ) (z_1,z_2) (z1,z2),我们有两个相关概率:(1) 我们的传感器读数 z k ⃗ \color{yellowgreen}{\vec{\mathbf{z}_k}} zk 是对 ( z 1 , z 2 ) (z_1,z_2) (z1,z2) 的(错误)测量的概率,以及 (2) 我们的先前估计认为 ( z 1 , z 2 ) (z_1,z_2) (z1,z2) 是我们应该看到的读数的概率。
如果我们有两个概率,我们想知道两者都为真的机会,我们只需将它们相乘。所以,我们取两个高斯分布并将它们相乘:
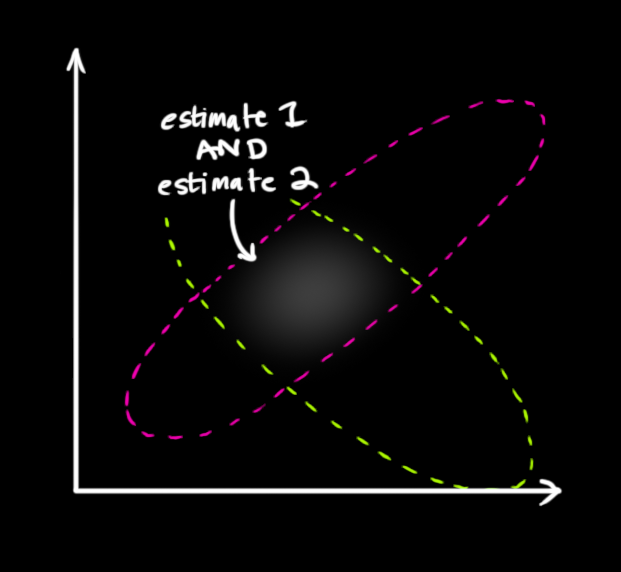
我们剩下的就是重叠 区域,这是两个 分布都明亮/可能的区域。它比我们之前的任何一个估计都精确得多。这个分布的均值是两个估计都最可能的配置,因此是给定我们拥有的所有信息对真实配置的最新猜测。
嗯。这看起来像另一个高斯分布。
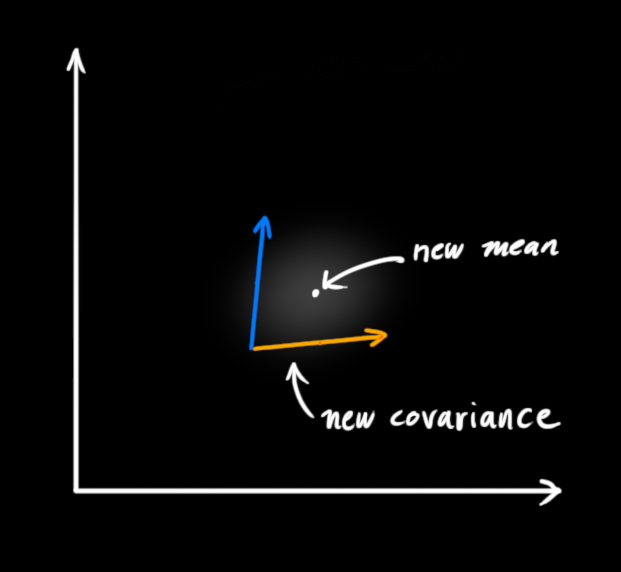
事实证明,当你将两个具有独立均值和协方差矩阵的高斯分布相乘时,你会得到一个具有自己的 均值和协方差矩阵的新高斯分布!你可能能看到这将走向何方:必定有一个公式从旧参数得到新参数!
合并高斯分布
让我们找到那个公式。它最容易首先在一维 中查看。方差为 σ 2 \sigma^2 σ2 和均值为 μ \mu μ 的一维高斯钟形曲线定义为:
N ( x , μ , σ ) = 1 σ 2 π e − ( x − μ ) 2 2 σ 2 (12) \begin{equation} \mathcal{N}(x, \mu,\sigma) = \frac{1}{ \sigma \sqrt{ 2\pi } } e^{ -\frac{ (x - \mu)^2 }{ 2\sigma^2 } } \end{equation} \tag{12} N(x,μ,σ)=σ2π 1e−2σ2(x−μ)2(12)
我们想知道当你将两个高斯曲线相乘时会发生什么。下面的蓝色曲线代表两个高斯总体的(未归一化的)交集:
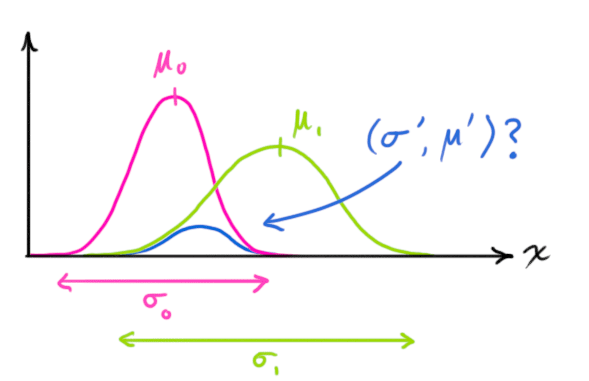
N ( x , μ 0 , σ 0 ) ⋅ N ( x , μ 1 , σ 1 ) = ? N ( x , μ ′ , σ ′ ) (13) \begin{equation} \mathcal{N}(x, \color{fuchsia}{\mu_0}, \color{deeppink}{\sigma_0}) \cdot \mathcal{N}(x, \color{yellowgreen}{\mu_1}, \color{mediumaquamarine}{\sigma_1}) \stackrel{?}{=} \mathcal{N}(x, \color{royalblue}{\mu'}, \color{mediumblue}{\sigma'}) \end{equation} \tag{13} N(x,μ0,σ0)⋅N(x,μ1,σ1)=?N(x,μ′,σ′)(13)
你可以将方程 (12) 代入方程 (13)。笔者注:两侧都是高斯分布,我们可以采用讨巧的方法,可以只比较指数部分 ,无须理会前面因子部分。
− ( x − μ 0 ) 2 2 σ 0 2 − ( x − μ 1 ) 2 2 σ 1 2 = − ( x − μ ′ ) 2 2 σ ′ 2 (14) \begin{equation} -\frac{ (x - \mu_0)^2 }{ 2\sigma_0^2 } - \frac{ (x - \mu_1)^2 }{ 2\sigma_1^2 } = -\frac{ (x - \mu')^2 }{ 2\sigma'^2 } \end{equation} \tag{14} −2σ02(x−μ0)2−2σ12(x−μ1)2=−2σ′2(x−μ′)2(14)
求方差 σ ′ \sigma' σ′
对于求解 σ ′ \sigma' σ′,我们可以比较公式(14)的 x 2 x^2 x2 系数部分。
− x 2 2 σ ′ 2 = − x 2 2 σ 0 2 − x 2 2 σ 1 2 σ ′ 2 = σ 0 2 σ 1 2 σ 0 2 + σ 1 2 σ ′ 2 = σ 0 2 σ 1 2 + σ 0 2 σ 0 2 − σ 0 4 σ 0 2 + σ 1 2 = σ 0 2 − σ 0 4 σ 0 2 + σ 1 2 (15) \begin{equation} \begin{gathered} -\frac{ x ^2 }{ 2\sigma'^2 } = - \frac{ x ^2 }{ 2\sigma_0^2 } - \frac{ x ^2 }{ 2\sigma_1^2 } \\ \sigma'^2 = \frac{ \sigma_0^2 \sigma_1^2 }{\sigma_0^2 + \sigma_1^2 } \\ \sigma'^2 = \frac{ \sigma_0^2 \sigma_1^2 + \sigma_0^2 \sigma_0^2 - \sigma_0^4 }{\sigma_0^2 + \sigma_1^2 } = \sigma_0^2 - \frac{ \sigma_0^4 }{\sigma_0^2 + \sigma_1^2 } \end{gathered} \end{equation} \tag{15} −2σ′2x2=−2σ02x2−2σ12x2σ′2=σ02+σ12σ02σ12σ′2=σ02+σ12σ02σ12+σ02σ02−σ04=σ02−σ02+σ12σ04(15)
求均值 μ ′ \mu' μ′
对于求解 μ ′ \mu' μ′,我们可以比较公式(14)的 x x x 系数部分。
− − 2 x μ ′ 2 σ ′ 2 = − − 2 x μ 0 2 σ 0 2 − − 2 x μ 1 2 σ 1 2 μ ′ σ ′ 2 = μ 0 σ 0 2 + μ 1 σ 1 2 μ ′ = ( μ 0 σ 0 2 + μ 1 σ 1 2 ) σ ′ μ ′ = ( μ 0 σ 1 2 + μ 1 σ 0 2 σ 1 2 σ 0 2 ) ( σ 0 2 σ 1 2 σ 0 2 + σ 1 2 ) = μ 0 σ 1 2 + μ 1 σ 0 2 σ 0 2 + σ 1 2 μ ′ = μ 0 σ 1 2 + μ 0 σ 0 2 − μ 0 σ 0 2 + μ 1 σ 0 2 σ 0 2 + σ 1 2 = μ 0 + σ 0 2 ( μ 1 − μ 0 ) σ 0 2 + σ 1 2 (16) \begin{equation} \begin{gathered} -\frac{ - 2 x \mu' }{ 2\sigma'^2 } = -\frac{ - 2 x \mu_0 }{ 2\sigma_0^2 } - \frac{ - 2 x \mu_1 }{ 2\sigma_1^2 } \\ \frac{ \mu' }{ \sigma'^2 } = \frac{ \mu_0 }{ \sigma_0^2 } + \frac{\mu_1 }{ \sigma_1^2 } \\ \mu' = ( \frac{ \mu_0 }{ \sigma_0^2 } + \frac{\mu_1 }{ \sigma_1^2 } ) \sigma' \\ \mu' = ( \frac{ \mu_0 \sigma_1^2 + \mu_1 \sigma_0^2 }{ \sigma_1^2 \sigma_0^2 })(\frac{ \sigma_0^2 \sigma_1^2 }{\sigma_0^2 + \sigma_1^2 }) = \frac{ \mu_0 \sigma_1^2 + \mu_1 \sigma_0^2 }{\sigma_0^2 + \sigma_1^2 } \\ \mu' = \frac{ \mu_0 \sigma_1^2 + \mu_0 \sigma_0^2 - \mu_0 \sigma_0^2 + \mu_1 \sigma_0^2 }{\sigma_0^2 + \sigma_1^2 } = \mu_0 + \frac{ \sigma_0^2 ( \mu_1 - \mu_0 ) }{\sigma_0^2 + \sigma_1^2 }\\ \end{gathered} \end{equation} \tag{16} −2σ′2−2xμ′=−2σ02−2xμ0−2σ12−2xμ1σ′2μ′=σ02μ0+σ12μ1μ′=(σ02μ0+σ12μ1)σ′μ′=(σ12σ02μ0σ12+μ1σ02)(σ02+σ12σ02σ12)=σ02+σ12μ0σ12+μ1σ02μ′=σ02+σ12μ0σ12+μ0σ02−μ0σ02+μ1σ02=μ0+σ02+σ12σ02(μ1−μ0)(16)
最终得到
μ ′ = μ 0 + σ 0 2 ( μ 1 − μ 0 ) σ 0 2 + σ 1 2 σ ′ 2 = σ 0 2 − σ 0 4 σ 0 2 + σ 1 2 (17) \begin{equation} \begin{aligned} \color{royalblue}{\mu'} &= \mu_0 + \frac{\sigma_0^2 (\mu_1 - \mu_0)} {\sigma_0^2 + \sigma_1^2}\\ \color{mediumblue}{\sigma'}^2 &= \sigma_0^2 - \frac{\sigma_0^4} {\sigma_0^2 + \sigma_1^2} \end{aligned} \end{equation} \tag{17} μ′σ′2=μ0+σ02+σ12σ02(μ1−μ0)=σ02−σ02+σ12σ04(17)
我们可以通过提取一小部分并称之为 k \color{purple}{\mathbf{k}} k 来简化:
k = σ 0 2 σ 0 2 + σ 1 2 (18) \begin{equation} \color{purple}{\mathbf{k}} = \frac{\sigma_0^2}{\sigma_0^2 + \sigma_1^2} \end{equation} \tag{18} k=σ02+σ12σ02(18)
μ ′ = μ 0 + k ( μ 1 − μ 0 ) σ ′ 2 = σ 0 2 − k σ 0 2 (19) \begin{equation} \begin{split} \color{royalblue}{\mu'} &= \mu_0 + \color{purple}{\mathbf{k}} (\mu_1 - \mu_0)\\ \color{mediumblue}{\sigma'}^2 &= \sigma_0^2 - \color{purple}{\mathbf{k}} \sigma_0^2 \end{split} \end{equation} \tag{19} μ′σ′2=μ0+k(μ1−μ0)=σ02−kσ02(19)
请注意你可以如何获取你之前的估计并添加一些东西来做出新的估计。而且看看这个公式多么简单!
但矩阵版本呢?好吧,让我们将方程 (18) 和 (19) 以矩阵形式重写。如果 Σ \Sigma Σ 是高斯分布的协方差矩阵, μ ⃗ \vec{\mu} μ 是沿每个轴的均值,那么:
K = Σ 0 ( Σ 0 + Σ 1 ) − 1 (20) \begin{equation} \color{purple}{\mathbf{K}} = \Sigma_0 (\Sigma_0 + \Sigma_1)^{-1} \end{equation} \tag{20} K=Σ0(Σ0+Σ1)−1(20)
μ ⃗ ′ = μ 0 ⃗ + K ( μ 1 ⃗ − μ 0 ⃗ ) Σ ′ = Σ 0 − K Σ 0 (21) \begin{equation} \begin{split} \color{royalblue}{\vec{\mu}'} &= \vec{\mu_0} + \color{purple}{\mathbf{K}} (\vec{\mu_1} - \vec{\mu_0})\\ \color{mediumblue}{\Sigma'} &= \Sigma_0 - \color{purple}{\mathbf{K}} \Sigma_0 \end{split} \end{equation} \tag{21} μ ′Σ′=μ0 +K(μ1 −μ0 )=Σ0−KΣ0(21)
K \color{purple}{\mathbf{K}} K 是一个叫做卡尔曼增益 的矩阵,我们马上就会用到它。从上面的公式
可以看出来卡尔曼滤波就是根据协方差来计算权重,融合预测值和测量值。
太棒了!我们快要完成了!
把一切整合起来
我们有两个分布:预测的测量值 ( μ 0 , Σ 0 ) = ( H k x ^ k , H k P k H k T ) (\color{fuchsia}{\mu_0}, \color{deeppink}{\Sigma_0}) = (\color{fuchsia}{\mathbf{H}_k \mathbf{\hat{x}}_k}, \color{deeppink}{\mathbf{H}_k \mathbf{P}_k \mathbf{H}_k^T}) (μ0,Σ0)=(Hkx^k,HkPkHkT),和观察到的测量值 ( μ 1 , Σ 1 ) = ( z k ⃗ , R k ) (\color{yellowgreen}{\mu_1}, \color{mediumaquamarine}{\Sigma_1}) = (\color{yellowgreen}{\vec{\mathbf{z}_k}}, \color{mediumaquamarine}{\mathbf{R}_k}) (μ1,Σ1)=(zk ,Rk)。我们可以将它们代入方程 (21) 找到它们的重叠:
H k x ^ k ′ = H k x ^ k + K ( z k ⃗ − H k x ^ k ) H k P k ′ H k T = H k P k H k T − K H k P k H k T (22) \begin{equation} \begin{aligned} \mathbf{H}_k \color{royalblue}{\mathbf{\hat{x}}_k'} &= \color{fuchsia}{\mathbf{H}_k \mathbf{\hat{x}}_k} & + & \color{purple}{\mathbf{K}} ( \color{yellowgreen}{\vec{\mathbf{z}_k}} - \color{fuchsia}{\mathbf{H}_k \mathbf{\hat{x}}_k} ) \\ \mathbf{H}_k \color{royalblue}{\mathbf{P}_k'} \mathbf{H}_k^T &= \color{deeppink}{\mathbf{H}_k \mathbf{P}_k \mathbf{H}_k^T} & - & \color{purple}{\mathbf{K}} \color{deeppink}{\mathbf{H}_k \mathbf{P}_k \mathbf{H}_k^T} \end{aligned} \end{equation} \tag{22} Hkx^k′HkPk′HkT=Hkx^k=HkPkHkT+−K(zk −Hkx^k)KHkPkHkT(22)
并且从 (20),卡尔曼增益是:
K = H k P k H k T ( H k P k H k T + R k ) − 1 (23) \begin{equation} \color{purple}{\mathbf{K}} = \color{deeppink}{\mathbf{H}_k \mathbf{P}_k \mathbf{H}_k^T} ( \color{deeppink}{\mathbf{H}_k \mathbf{P}_k \mathbf{H}_k^T} + \color{mediumaquamarine}{\mathbf{R}_k})^{-1} \end{equation} \tag{23} K=HkPkHkT(HkPkHkT+Rk)−1(23)
我们可以从 (22) 和 (23) 的每个项前面去掉一个 H k \mathbf{H}_k Hk(注意有一个藏在 K \color{purple}{\mathbf{K}} K 里面),并从 P k ′ \color{royalblue}{\mathbf{P}_k'} Pk′ 的方程中所有项的末尾去掉一个 H k T \mathbf{H}_k^T HkT。
x ^ k ′ = x ^ k + K ′ ( z k ⃗ − H k x ^ k ) P k ′ = P k − K ′ H k P k (24) \begin{equation} \begin{align} \color{royalblue}{\mathbf{\hat{x}}_k'} &= \color{fuchsia}{\mathbf{\hat{x}}_k} & + & \color{purple}{\mathbf{K}'} ( \color{yellowgreen}{\vec{\mathbf{z}_k}} - \color{fuchsia}{\mathbf{H}_k \mathbf{\hat{x}}_k} ) \\ \color{royalblue}{\mathbf{P}_k'} &= \color{deeppink}{\mathbf{P}_k} & - & \color{purple}{\mathbf{K}'} \color{deeppink}{\mathbf{H}_k \mathbf{P}_k} \end{align} \end{equation} \tag{24} x^k′Pk′=x^k=Pk+−K′(zk −Hkx^k)K′HkPk(24)
K ′ = P k H k T ( H k P k H k T + R k ) − 1 (25) \begin{equation} \color{purple}{\mathbf{K}'} = \color{deeppink}{\mathbf{P}_k \mathbf{H}_k^T} ( \color{deeppink}{\mathbf{H}_k \mathbf{P}_k \mathbf{H}_k^T} + \color{mediumaquamarine}{\mathbf{R}_k})^{-1} \end{equation} \tag{25} K′=PkHkT(HkPkHkT+Rk)−1(25)
从而得到更新步骤的完整方程。
就是这样! x ^ k ′ \color{royalblue}{\mathbf{\hat{x}}_k'} x^k′ 是我们的新最佳估计,我们可以继续将其(连同 P k ′ \color{royalblue}{\mathbf{P}_k'} Pk′ )反馈到另一轮预测 或更新中,想做多少次就做多少次。