目录
[2.1 任务背景](#2.1 任务背景)
[2.2 现有方法的局限](#2.2 现有方法的局限)
[2.3 ORCA 的核心思路](#2.3 ORCA 的核心思路)
[3. 相关工作](#3. 相关工作)
[3.1 文档理解中的 VLMs](#3.1 文档理解中的 VLMs)
[3.2 语言模型推理与验证](#3.2 语言模型推理与验证)
[3.3 多智能体框架](#3.3 多智能体框架)
[4. 方法](#4. 方法)
[4.1 ORCA 五阶段框架编辑](#4.1 ORCA 五阶段框架编辑)
[4.2.1 Agent Dock(智能体库)](#4.2.1 Agent Dock(智能体库))
[4.2.2 Router(路由)](#4.2.2 Router(路由))
[4.2.3 Orchestrator(编排)](#4.2.3 Orchestrator(编排))
[步骤 5:答案校准](#步骤 5:答案校准)
[5. 实验](#5. 实验)
1.摘要
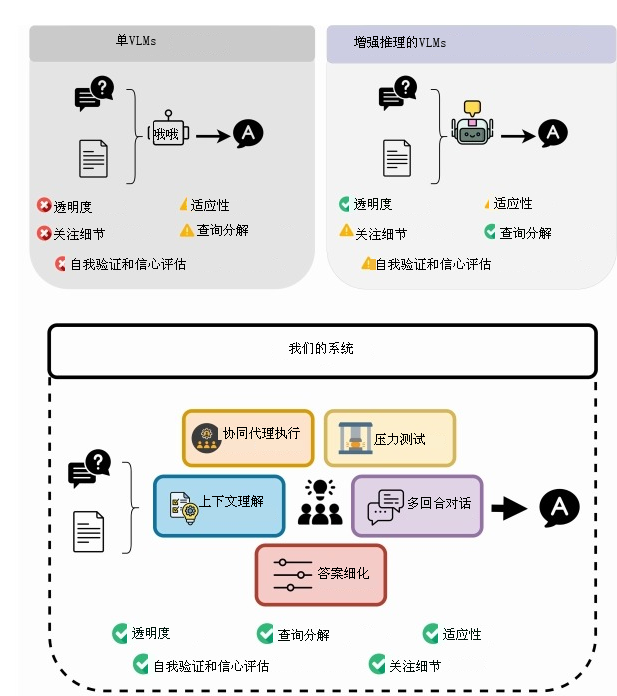
文档视觉问答(DocVQA)对现有的视觉-语言模型(VLM)而言仍具挑战性,尤其是在复杂推理和多步骤流程场景下。现有方法难以将复杂问题拆解为易处理的子任务,且往往无法针对不同文档元素采用专门的处理路径。我们提出了ORCA:面向文档视觉问答的协作智能体协同推理框架,这是一种全新的多智能体框架,通过智能体的战略协同与迭代优化来解决上述局限。ORCA首先由推理智能体将查询拆解为逻辑步骤,随后通过路由机制从专用智能体库中激活任务专属智能体。该框架依托一组专用人工智能智能体,每个智能体专注于不同的模态,实现对各类文档组件的细粒度理解与协同推理。为确保答案的可靠性,ORCA引入了包含压力测试的辩论机制,必要时还会采用正反论点裁决流程,之后再通过一致性校验器保证格式的统一。在三个基准数据集上的大量实验表明,我们的方法相比当前最优方法取得了显著提升,为视觉-语言推理领域的协同智能体系统构建了全新范式。
2.引言
2.1 任务背景
- DocVQA:基于单页文档图像 回答问题,内容包含文本、表格、图表、手写、表单。
- 难点:需要多步推理、跨元素整合、细节捕捉、结构化理解。
2.2 现有方法的局限
| 技术范式 | 核心局限 | 具体表现 |
|---|---|---|
| 单 VLMs | 能力与机制双重缺失 | • 无法拆解复杂推理 • 缺乏透明度、无法解释 • 对表格/图表/手写细节处理差 • 无法自我验证、评估置信度 |
| CoT / 增强推理模型 | 单体架构与认知偏差 | • 仍依赖单一模型 • 无内容专用路径 • 缺乏辩论/验证机制 • 易产生确认偏误 |
| 多智能体系统 | 流程僵化与效率瓶颈 | • 多为固定规则路由 • 缺乏推理引导 • 验证开销大 • 缺乏条件触发机制 |
2.3 ORCA 的核心思路
- 推理先行:先拆解问题,生成推理路径。
- 分工协作:9 类专用智能体,各司其职。
- 动态路由:按需激活智能体。
- 条件验证:分歧时才辩论,效率高。
- 全程透明、可解释、可验证。
3. 相关工作
3.1 文档理解中的 VLMs
- 早期:LayoutLM、TILT、Donut,侧重文本 + 布局。
- 近期:Qwen、InternVL、LLaVA 等 VLMs,直接处理文档图像。
- 局限:长推理弱、跨模态整合不足、细节丢失、表格 / 图表理解差。
3.2 语言模型推理与验证
- CoT:显式推理步骤,提升复杂任务。
- Self-Consistency:多路径采样。
- ReAct:结合工具使用。
- Reflexion:迭代反思。
- 辩论机制:多模型对抗验证,提升可靠性。
- 局限:单模型、无分工、验证成本高。
3.3 多智能体框架
- Visual ChatGPT、HuggingGPT:LLM 控制器 + 工具模块。
- 文档领域:表格 / OCR / 布局专用智能体。
- ORCA 区别:
- 推理引导路由,非手工规则;
- 推理路径掩码,避免确认偏误;
- 条件辩论,仅 8.3% 案例触发;
- 强协同、强验证、强解释。
4. 方法
问题定义:
给定单页文档 D + 问题 q ,输出准确答案 a;文档含文本、表格、图表、手写、表单等。
4.1 ORCA 五阶段框架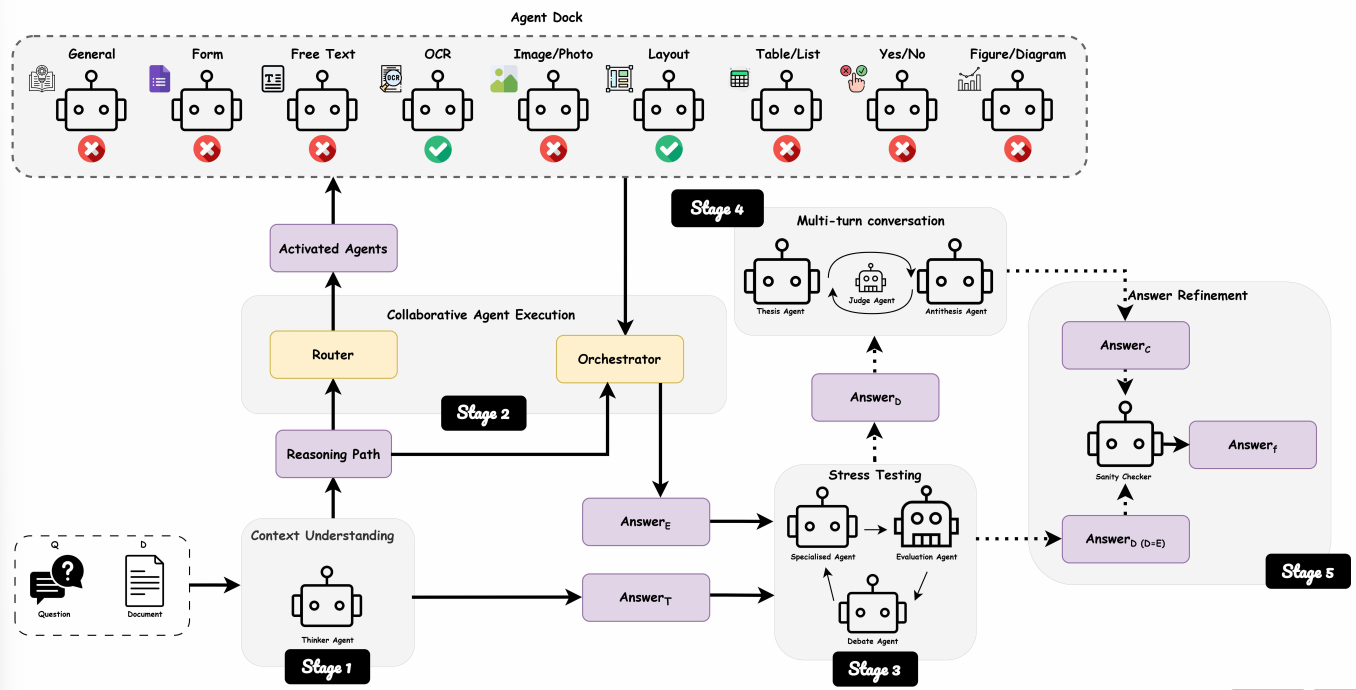
步骤1:上下文理解
- 智能:Thinker Agent(推理智能体,GLM-4.5V)。
- 输入:文档 D、问题 q。
- 输出:
- 结构化推理路径 R(拆解问题为步骤);
- 初始答案 a_T。
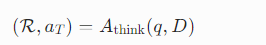
- 作用:规划推理、引导后续智能体。

步骤2:协作智能体执行
由 Agent Dock、Router、Orchestrator 三部分组成。
4.2.1 Agent Dock(智能体库)
共 9 类专用智能体(基于 Qwen3VL-8B 微调):
- General(通用)、Free Text(自由文本)、OCR(手写 / 难文本)、Image/Photo(图像)、Layout(布局)、Table/List(表格)、Figure/Diagram(图表)、Form(表单)、Yes/No(是非)。
4.2.2 Router(路由)
- 模型:Qwen2.5-VL-7B。
- 任务:多标签分类,选择需激活的智能体。
- 解码:Turbo DFS(非 sigmoid 阈值),输出激活向量 v。
- 特点:数据驱动、动态选择、可解释。

4.2.3 Orchestrator(编排)
- 输入:激活智能体、推理路径、问题、文档。
- 输出:执行顺序 σ。
- 关键:推理路径掩码 R *,隐藏初始答案,避免确认偏误。
- 执行:智能体串行运行 ,前一输出传给后一;最终输出专家答案 a_E。
步骤3:压力测试
- 触发条件:a_E ≠ a_T(仅 23.4% 案例)。
- 子智能
- Debate Agent(生成质疑)
- Specialized Agent(回应质疑)
- Evaluation Agent(判断回应质量)
- 流程:
- Debate Agent 生成质疑问题;
- 专业智能体回应并更新答案;
- Evaluation Agent 判一致性;
- 两轮不通过 → 进入辩论阶段。
- 输出:a_D 与 进入辩论标志。





步骤4:多轮辩论
- 触发:压力测试失败(仅 8.3% 案例)。
- 三方:Thesis(正方)、Antithesis(反方)、Judge(裁判)。
- 流程:3 轮结构化辩论,每轮含 参考、批评、结论;裁判总结、判断是否被说服。
- 输出:最终辩论答案 a_C。

步骤 5:答案校准
- 智能:Sanity Checker。
- 功能:格式修正、空格 / 标点对齐、与文档一致。
- 输出:最终答案 a_F。

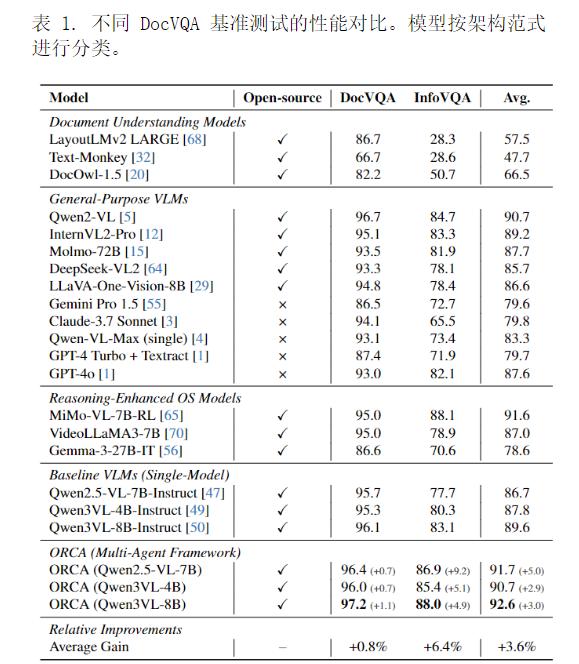
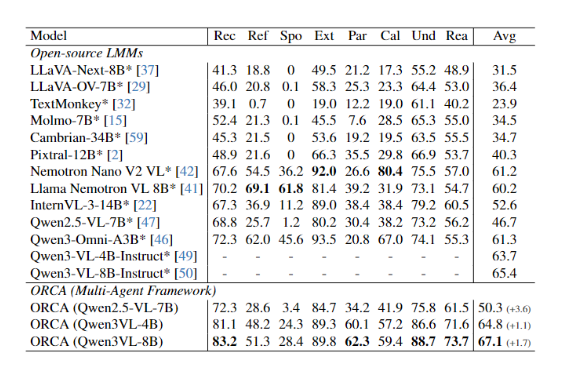
5. 实验
5.1.数据集
| 评估基准 | 核心任务 | 数据内容与特征 | 规模 | 难点/特点 | 评估指标 |
|---|---|---|---|---|---|
| Single-Page DocVQA | 单页文档图像问答 | 偏文本、含少量表格、布局多样 (票据、表单、书籍、报纸、扫描件、含文本/表格/图片) | 约 10k 问答对 | 基础文档理解与提取 | ANLS (平均归一化 Levenshtein 相似度) |
| InfographicsVQA (InfoVQA) | 信息图问答 | 高度视觉化、含图表/标注 (柱状图、饼图、折线、地图、统计、流程图、海报、标注文本) | 约 5k 问答对 | 需要视觉推理、数值比较、跨元素整合 | ANLS |
| OCRBench-v2 | 文档OCR+理解 (8个子任务综合) | 全要素覆盖 (文本、手写、表格、图表、布局) | - | 覆盖从感知到认知的全链路能力 | 8项任务平均分 |
5.2.评估指标