1. 回顾:基础排序的局限
在上一篇中,我们学习了冒泡排序、选择排序和插入排序。它们的时间复杂度都是 O(n^2),当数据量较大时(n > 10^4),性能会急剧下降。
关键问题:如何突破 O(n^2) 的瓶颈,实现更高效排序?
本文将介绍三种高级排序算法,它们的核心思想各不相同,但都能将时间复杂度降低到 O(n log n) 级别:
| 算法 | 核心思想 | 时间复杂度 |
|---|---|---|
| 希尔排序 | 分组插入排序,增量递减 | O(n^1.3) ~ O(n^2) |
| 快速排序 | 分治 + 基准划分 | 平均 O(n log n) |
| 归并排序 | 分治 + 有序合并 | O(n log n) |
2. 希尔排序(Shell Sort)
2.1 算法思想
希尔排序是插入排序的升级版,由 Donald Shell 于 1959 年提出。它的核心思想是:
先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录"基本有序"时,再对全体记录进行一次直接插入排序。
为什么这样更快?
- 插入排序在数据基本有序时效率极高(O(n))
- 希尔排序通过增量分组,让元素大步长移动,快速接近最终位置
- 最后当增量为 1 时,数组已经接近有序,此时插入排序只需少量调整
2.2 算法步骤详解
初始数组:81, 94, 11, 96, 12, 35, 17, 95, 28, 58, 41, 75, 15
增量序列(Shell 原始):n/2, n/4, ..., 1
即:6, 3, 1
第1轮(增量 gap=6):将数组分成 6 组,每组内部进行插入排序
组1(下标0,6):81, 17 -> 17, 81
组2(下标1,7):94, 95 -> 94, 95(已有序)
组3(下标2,8):11, 28 -> 11, 28(已有序)
组4(下标3,9):96, 58 -> 58, 96
组5(下标4,10):12, 41 -> 12, 41(已有序)
组6(下标5,11):35, 75 -> 35, 75(已有序)
结果:17, 94, 11, 58, 12, 35, 81, 95, 28, 96, 41, 75, 15
第2轮(增量 gap=3):将数组分成 3 组
组1(下标0,3,6,9,12):17, 58, 81, 96, 15 -> 15, 17, 58, 81, 96
组2(下标1,4,7,10):94, 12, 95, 41 -> 12, 41, 94, 95
组3(下标2,5,8,11):11, 35, 28, 75 -> 11, 28, 35, 75
结果:15, 12, 11, 17, 41, 28, 58, 94, 35, 81, 95, 75, 96
第3轮(增量 gap=1):标准插入排序
此时数组已基本有序,只需少量调整
结果:11, 12, 15, 17, 28, 35, 41, 58, 75, 81, 94, 95, 96
2.3 可视化图示
希尔排序增量分组过程:
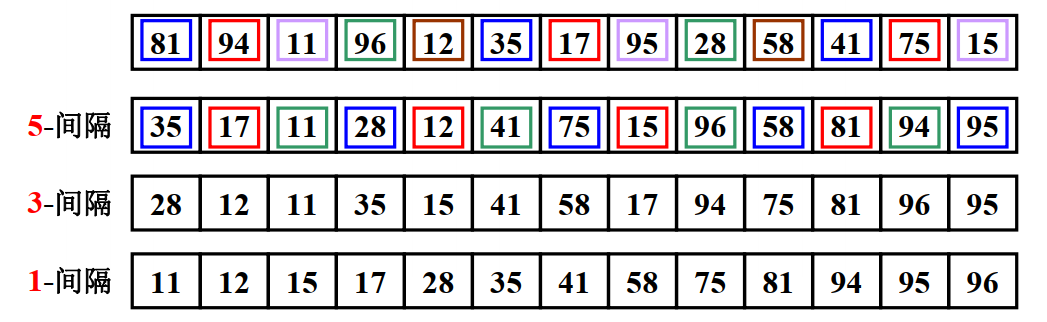
上图展示了希尔排序的核心过程:
- 5-间隔:按间隔 5 分组,每组内部排序
- 3-间隔:缩小间隔为 3,再次分组排序
- 1-间隔:最后间隔为 1,即标准插入排序
- 可以看到,随着增量减小,数组越来越接近有序
希尔排序分组示意:
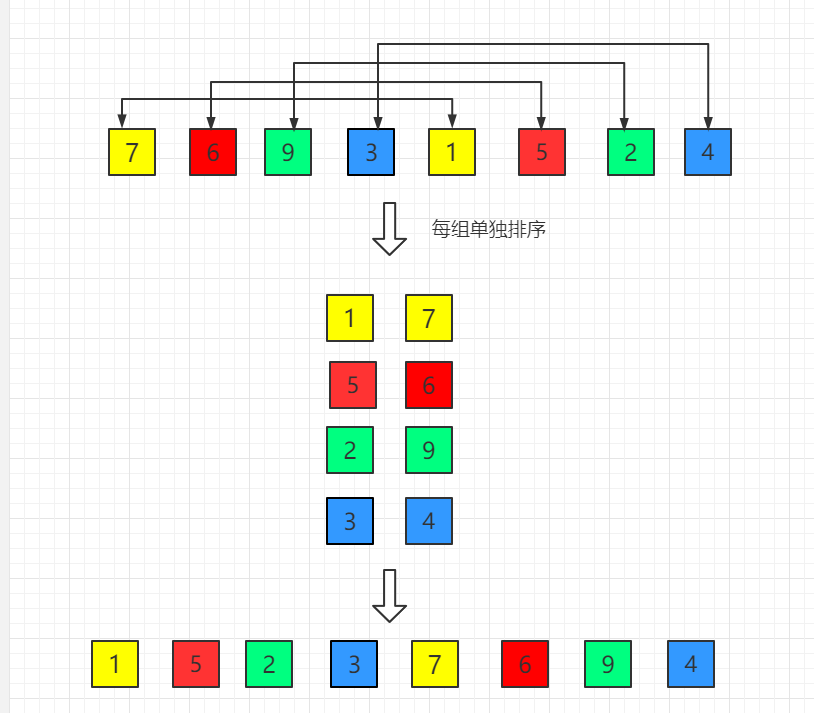
上图展示了 gap=4 时的分组方式:
- 相同颜色的元素属于同一组
- 每组单独进行插入排序
- 排序后相同颜色组内的元素有序
2.4 完整代码实现
python
def shell_sort(arr: list) -> list:
n = len(arr)
gap = n // 2
while gap > 0:
for i in range(gap, n):
current = arr[i]
j = i
while j >= gap and arr[j - gap] > current:
arr[j] = arr[j - gap]
j -= gap
arr[j] = current
gap //= 2
return arr
def shell_sort_knuth(arr: list) -> list:
n = len(arr)
gap = 1
while gap < n // 3:
gap = gap * 3 + 1
while gap > 0:
for i in range(gap, n):
current = arr[i]
j = i
while j >= gap and arr[j - gap] > current:
arr[j] = arr[j - gap]
j -= gap
arr[j] = current
gap //= 3
return arr
if __name__ == "__main__":
test_data = [81, 94, 11, 96, 12, 35, 17, 95, 28, 58, 41, 75, 15]
print(f"原始数组: {test_data}")
sorted_data = shell_sort(test_data.copy())
print(f"排序结果: {sorted_data}")
assert sorted_data == sorted(test_data)
print("验证通过!")2.5 复杂度分析
| 指标 | 复杂度 | 说明 |
|---|---|---|
| 最好时间 | O(n log n) | 取决于增量序列 |
| 最坏时间 | O(n^2) | Shell原始增量(n/2, n/4...) |
| 平均时间 | O(n^1.3 ~ n^1.5) | Knuth/Hibbard增量序列 |
| 空间复杂度 | O(1) | 原地排序 |
| 稳定性 | 不稳定 | 分组插入可能跨越多个元素 |
常见增量序列对比:
| 增量序列 | 公式 | 时间复杂度 |
|---|---|---|
| Shell原始 | n/2, n/4, ..., 1 | O(n^2) |
| Knuth | 3k+1 | O(n^1.5) |
| Hibbard | 2^k-1 | O(n^1.5) |
| Sedgewick | 94^k - 92^k + 1 | O(n^1.3) |
2.6 希尔排序的优势
python
def compare_sorts():
import random
import time
n = 50000
arr = [random.randint(1, 100000) for _ in range(n)]
start = time.time()
insertion_sort(arr.copy())
insert_time = time.time() - start
start = time.time()
shell_sort(arr.copy())
shell_time = time.time() - start
print(f"插入排序: {insert_time:.3f}s")
print(f"希尔排序: {shell_time:.3f}s")
print(f"加速比: {insert_time/shell_time:.1f}x")3. 快速排序(Quick Sort)
3.1 算法思想
快速排序由 Tony Hoare 于 1960 年提出,是实际应用中最广泛 的排序算法。它的核心思想是分治法(Divide and Conquer):
1. 分解 :选择一个基准值(pivot),将数组划分为两部分------左边都小于等于 pivot,右边都大于 pivot
2. 解决 :递归地对左右两部分进行快速排序
3. 合并:无需额外合并,原地即有序
3.2 算法步骤详解
初始数组:3, 5, 8, 1, 2, 9, 4, 7, 6
第1层递归:选择基准值 pivot = 3(最左边元素)
目标:将数组划分为 \<=3 3 \>3
遍历过程(双指针法):
idx=1: a1=5 > 3,不交换
idx=2: a2=8 > 3,不交换
idx=3: a3=1 <= 3,交换 a1和a3 -> 3, 1, 8, 5, 2, 9, 4, 7, 6, idx=2
idx=4: a4=2 <= 3,交换 a2和a4 -> 3, 1, 2, 5, 8, 9, 4, 7, 6, idx=3
idx=5: a5=9 > 3,不交换
idx=6: a6=4 > 3,不交换
idx=7: a7=7 > 3,不交换
idx=8: a8=6 > 3,不交换
最后将 pivot 放到正确位置:交换 a0和a2
结果:2, 1, 3, 5, 8, 9, 4, 7, 6
左子数组 2, 1(下标0-1)
右子数组 5, 8, 9, 4, 7, 6(下标3-8)
第2层递归(左):2, 1,pivot=2
-> 1, 2
第2层递归(右):5, 8, 9, 4, 7, 6,pivot=5
-> 4, 5, 8, 9, 7, 6 -> 左4, 右8, 9, 7, 6
...
最终结果:1, 2, 3, 4, 5, 6, 7, 8, 9
3.3 可视化图示
分治思想示意图:
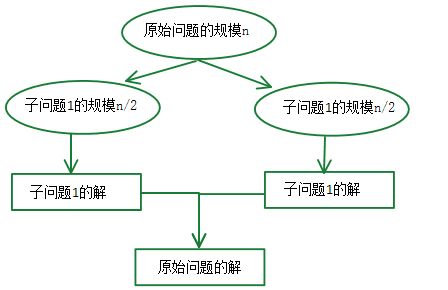
上图展示了分治的核心思想:
- 将规模为 n 的问题分解为两个规模为 n/2 的子问题
- 递归求解子问题
- 合并子问题的解得到原问题的解
快速排序递归树:
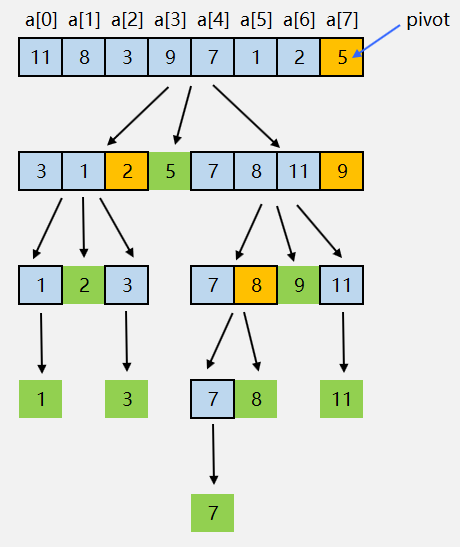
上图展示了快速排序的递归过程:
- 黄色:当前选中的基准值(pivot)
- 绿色:基准值的最终位置
- 蓝色:当前正在处理的子数组
- 每次递归都将问题规模大致减半
3.4 完整代码实现
python
def quick_sort(arr: list) -> list:
_quick_sort_helper(arr, 0, len(arr) - 1)
return arr
def _quick_sort_helper(arr: list, left: int, right: int):
if left < right:
pivot_idx = _partition(arr, left, right)
_quick_sort_helper(arr, left, pivot_idx - 1)
_quick_sort_helper(arr, pivot_idx + 1, right)
def _partition(arr: list, left: int, right: int) -> int:
pivot = arr[left]
idx = left + 1
for i in range(left + 1, right + 1):
if arr[i] <= pivot:
arr[idx], arr[i] = arr[i], arr[idx]
idx += 1
arr[left], arr[idx - 1] = arr[idx - 1], arr[left]
return idx - 1
# 优化版本:三数取中法 + 小数组切换插入排序
def quick_sort_optimized(arr: list) -> list:
_quick_sort_opt_helper(arr, 0, len(arr) - 1)
return arr
def _quick_sort_opt_helper(arr: list, left: int, right: int):
if right - left + 1 <= 10:
_insertion_sort_range(arr, left, right)
return
if left < right:
pivot_idx = _partition_median_of_three(arr, left, right)
_quick_sort_opt_helper(arr, left, pivot_idx - 1)
_quick_sort_opt_helper(arr, pivot_idx + 1, right)
def _partition_median_of_three(arr: list, left: int, right: int) -> int:
mid = (left + right) // 2
if arr[left] > arr[mid]:
arr[left], arr[mid] = arr[mid], arr[left]
if arr[left] > arr[right]:
arr[left], arr[right] = arr[right], arr[left]
if arr[mid] > arr[right]:
arr[mid], arr[right] = arr[right], arr[mid]
arr[mid], arr[right - 1] = arr[right - 1], arr[mid]
pivot = arr[right - 1]
idx = left
for i in range(left, right - 1):
if arr[i] <= pivot:
arr[idx], arr[i] = arr[i], arr[idx]
idx += 1
arr[idx], arr[right - 1] = arr[right - 1], arr[idx]
return idx
def _insertion_sort_range(arr: list, left: int, right: int):
for i in range(left + 1, right + 1):
current = arr[i]
j = i - 1
while j >= left and arr[j] > current:
arr[j + 1] = arr[j]
j -= 1
arr[j + 1] = current
# 简洁版(Pythonic)
def quick_sort_concise(arr: list) -> list:
if len(arr) <= 1:
return arr
pivot = arr[0]
left = [x for x in arr[1:] if x <= pivot]
right = [x for x in arr[1:] if x > pivot]
return quick_sort_concise(left) + [pivot] + quick_sort_concise(right)
if __name__ == "__main__":
test_data = [3, 5, 8, 1, 2, 9, 4, 7, 6]
print(f"原始数组: {test_data}")
sorted_data = quick_sort(test_data.copy())
print(f"排序结果: {sorted_data}")
assert sorted_data == sorted(test_data)
print("验证通过!")3.5 复杂度分析
| 指标 | 复杂度 | 说明 |
|---|---|---|
| 最好时间 | O(n log n) | 每次划分平衡,树高 log n |
| 最坏时间 | O(n^2) | 数组已有序/逆序,树高 n |
| 平均时间 | O(n log n) | 随机数据,期望树高 log n |
| 空间复杂度 | O(log n) | 递归栈深度 |
| 稳定性 | 不稳定 | 交换可能跨越多个元素 |
为什么快速排序比归并排序更常用?
| 特性 | 快速排序 | 归并排序 |
|---|---|---|
| 空间复杂度 | O(log n)(栈空间) | O(n)(额外数组) |
| 常数因子 | 较小 | 较大 |
| 缓存友好性 | 原地操作,缓存命中率高 | 需要额外数组,缓存不友好 |
| 稳定性 | 不稳定 | 稳定 |
| 最坏情况 | O(n^2)(可避免) | 稳定 O(n log n) |
核心原因:快速排序是原地排序,空间复杂度更低,缓存局部性更好,实际运行效率通常优于归并排序。
3.6 快速排序的优化策略
| 优化策略 | 作用 | 实现方式 |
|---|---|---|
| 三数取中法 | 避免最坏情况 | 选择 left/mid/right 的中位数作为 pivot |
| 随机化 pivot | 避免最坏情况 | 随机选择 pivot 元素 |
| 小数组切换插入排序 | 减少递归开销 | 长度 < 10 时切换 |
| 三路划分 | 处理大量重复元素 | 将数组分为 <, =, > 三部分 |
4. 归并排序(Merge Sort)
4.1 算法思想
归并排序是分治思想的经典应用,由 John von Neumann 于 1945 年提出。核心思想:
1. 分解 :将数组从中间分成两半,递归地对每一半进行归并排序
2. 解决 :当子数组长度为 1 时,自然有序(递归终止条件)
3. 合并:将两个有序子数组合并成一个有序数组
4.2 算法步骤详解
初始数组:11, 8, 3, 9, 7, 1, 2, 5
分解阶段:
11, 8, 3, 9, 7, 1, 2, 5
/
11, 8, 3, 9\] \[7, 1, 2, 5
/
11, 8\] \[3, 9
/
11\] \[8\] \[3\] \[9\] \[7\] \[1\] \[2\] \[5
合并阶段(自底向上):
11\] \[8\] -\> \[8, 11
3\] \[9\] -\> \[3, 9
7\] \[1\] -\> \[1, 7
2\] \[5\] -\> \[2, 5
8, 11\] \[3, 9\] -\> \[3, 8, 9, 11
1, 7\] \[2, 5\] -\> \[1, 2, 5, 7
3, 8, 9, 11\] \[1, 2, 5, 7\] -\> \[1, 2, 3, 5, 7, 8, 9, 11
4.3 可视化图示
归并排序分解与合并过程:
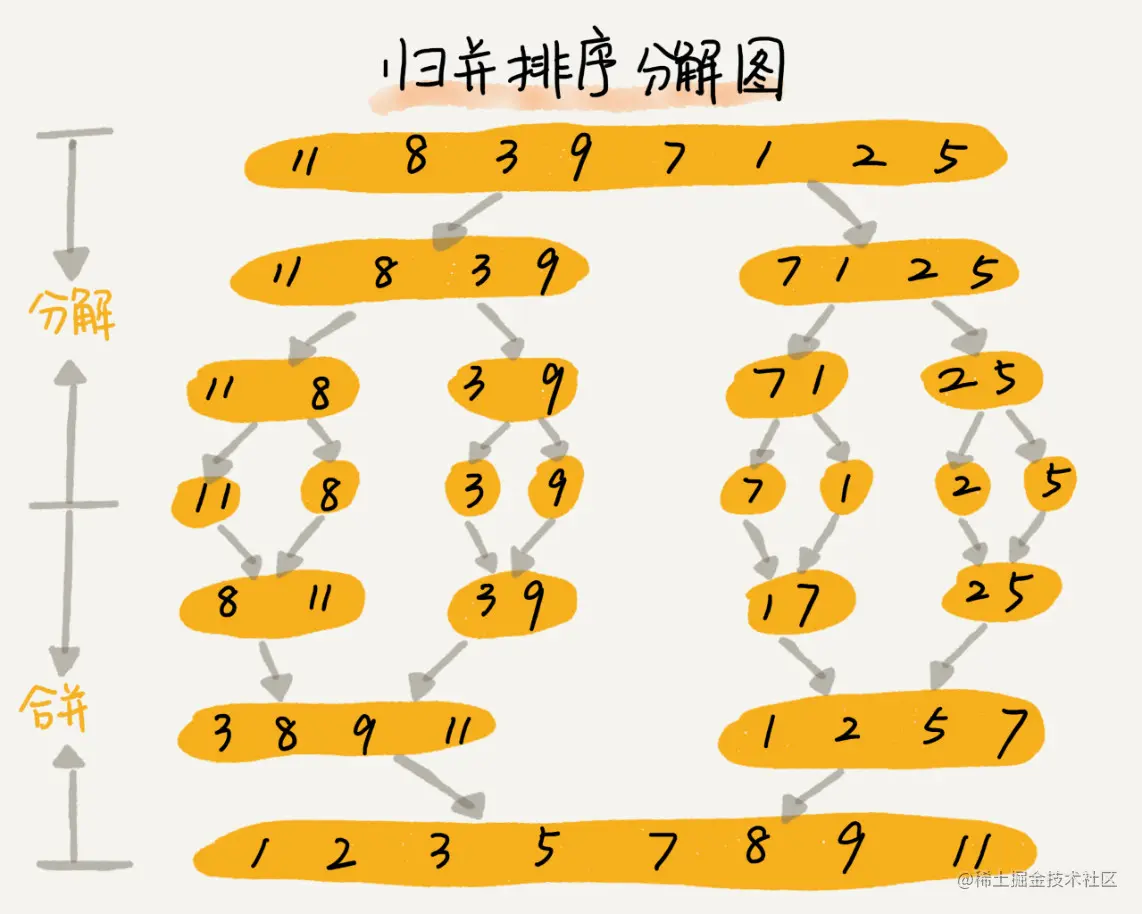
上图展示了归并排序的完整过程:
- 分解(向下箭头):不断将数组二分,直到子数组长度为 1
- 合并(向上箭头):将两个有序子数组合并
- 整个过程形成一棵递归树
归并排序递归树:
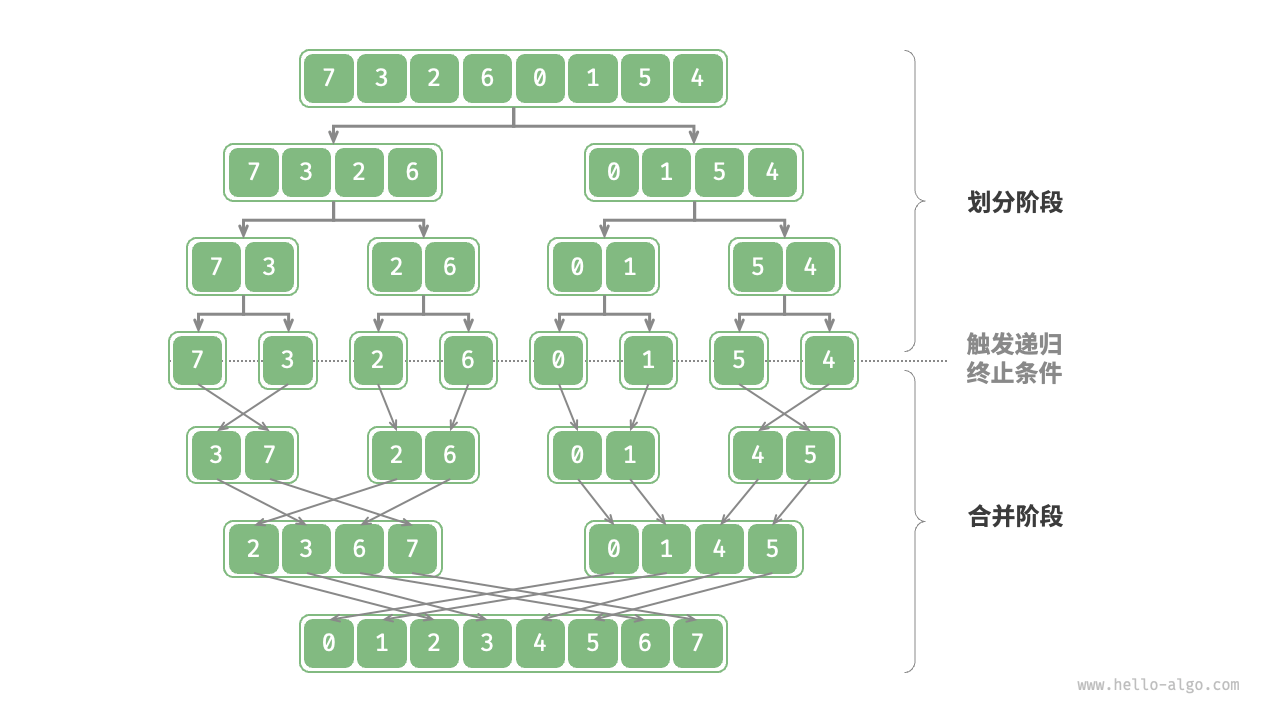
上图更清晰地展示了:
- 划分阶段:递归二分,直到触发终止条件(长度为1)
- 合并阶段:自底向上合并两个有序子数组
- 树高为 log n,每层合并操作总时间为 O(n)
两个有序数组合并过程:
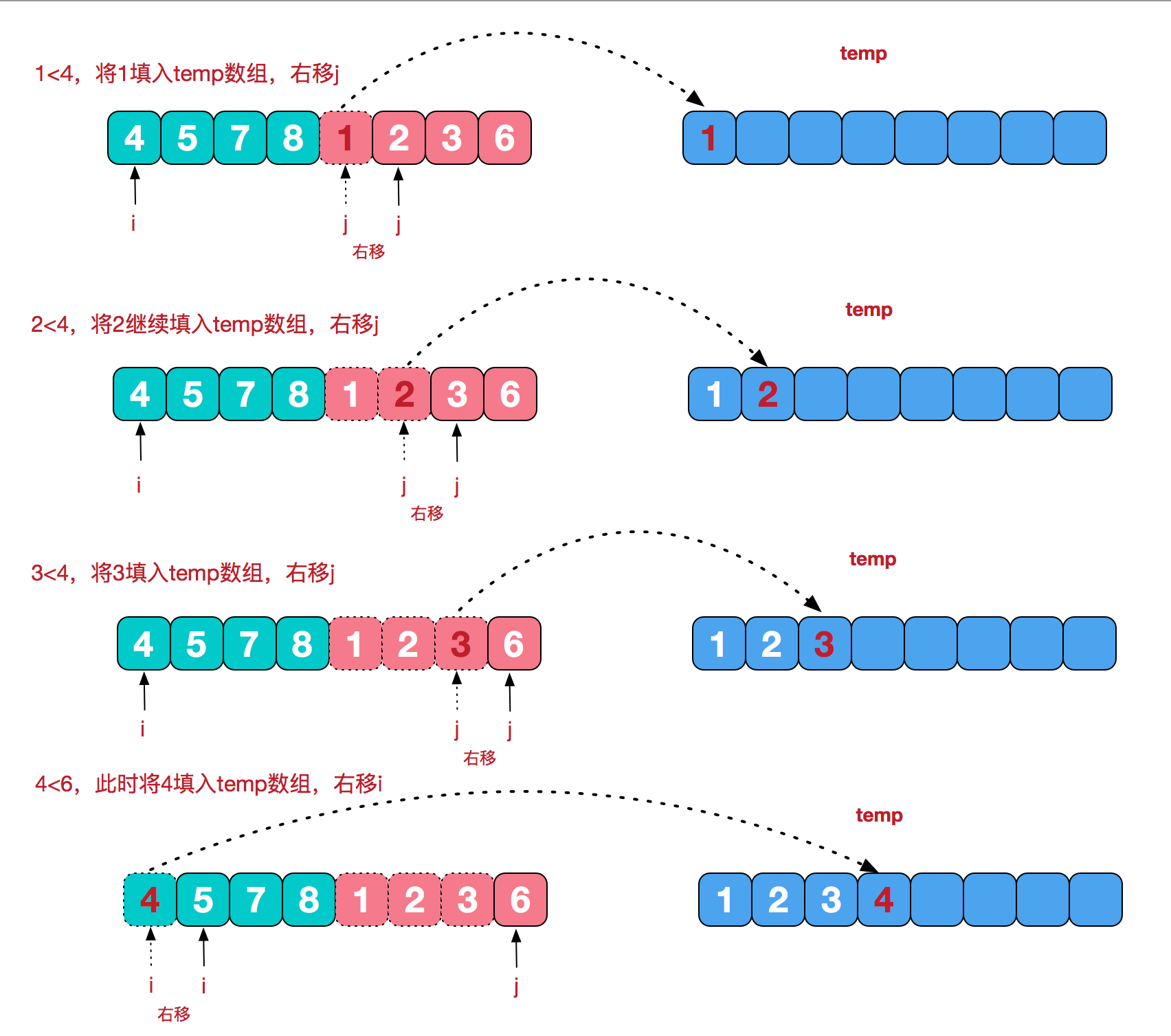
上图展示了合并两个有序数组 4,5,7,8 和 1,2,3,6 的过程:
- 使用双指针 i 和 j 分别指向两个数组的开头
- 每次比较 Ai 和 Bj,将较小的元素放入结果数组
- 最后将剩余元素追加到结果末尾
4.4 完整代码实现
python
def merge_sort(arr: list) -> list:
if len(arr) < 2:
return arr[:]
mid = len(arr) // 2
left = merge_sort(arr[:mid])
right = merge_sort(arr[mid:])
return _merge(left, right)
def _merge(left: list, right: list) -> list:
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
# 原地归并排序(优化空间)
def merge_sort_inplace(arr: list) -> list:
n = len(arr)
if n < 2:
return arr
temp = [0] * n
_merge_sort_helper(arr, temp, 0, n - 1)
return arr
def _merge_sort_helper(arr: list, temp: list, left: int, right: int):
if left < right:
mid = (left + right) // 2
_merge_sort_helper(arr, temp, left, mid)
_merge_sort_helper(arr, temp, mid + 1, right)
_merge_inplace(arr, temp, left, mid, right)
def _merge_inplace(arr: list, temp: list, left: int, mid: int, right: int):
for i in range(left, right + 1):
temp[i] = arr[i]
i = left
j = mid + 1
k = left
while i <= mid and j <= right:
if temp[i] <= temp[j]:
arr[k] = temp[i]
i += 1
else:
arr[k] = temp[j]
j += 1
k += 1
while i <= mid:
arr[k] = temp[i]
i += 1
k += 1
while j <= right:
arr[k] = temp[j]
j += 1
k += 1
if __name__ == "__main__":
test_data = [11, 8, 3, 9, 7, 1, 2, 5]
print(f"原始数组: {test_data}")
sorted_data = merge_sort(test_data.copy())
print(f"排序结果: {sorted_data}")
assert sorted_data == sorted(test_data)
print("验证通过!")4.5 复杂度分析
| 指标 | 复杂度 | 说明 |
|---|---|---|
| 最好时间 | O(n log n) | 树高 log n,每层 O(n) |
| 最坏时间 | O(n log n) | 同上,不受数据分布影响 |
| 平均时间 | O(n log n) | 同上 |
| 空间复杂度 | O(n) | 需要额外数组进行合并 |
| 稳定性 | 稳定 | 合并时相等元素保持原有顺序 |
4.6 归并排序的应用场景
归并排序的典型应用:
- 链表排序:不需要随机访问,空间复杂度可优化到 O(1)
- 逆序对统计:合并过程中自然统计
- 外排序:处理海量数据的标准方法
- 求数组第 k 大元素:结合二分思想
5. 三大高级排序算法对比总结
5.1 核心特性对比表
| 特性 | 希尔排序 | 快速排序 | 归并排序 |
|---|---|---|---|
| 核心思想 | 分组插入排序 | 分治 + 基准划分 | 分治 + 有序合并 |
| 最好时间 | O(n log n) | O(n log n) | O(n log n) |
| 最坏时间 | O(n^2) | O(n^2) | O(n log n) |
| 平均时间 | O(n^1.3) | O(n log n) | O(n log n) |
| 空间复杂度 | O(1) | O(log n) | O(n) |
| 稳定性 | 不稳定 | 不稳定 | 稳定 |
| 是否原地 | 是 | 是 | 否 |
| 适用场景 | 中等规模 | 通用场景 | 需要稳定性/链表/外排序 |
5.2 算法选择决策树
数据规模?
├── 小规模(n < 100)-> 插入排序
├── 中等规模(n < 10000)-> 希尔排序
└── 大规模(n >= 10000)
├── 需要稳定性?
│ ├── 是 -> 归并排序
│ └── 否 -> 快速排序
├── 内存受限?
│ ├── 是 -> 快速排序(原地)/ 希尔排序
│ └── 否 -> 快速排序 / 归并排序
└── 数据基本有序?
├── 是 -> 插入排序 / 希尔排序
└── 否 -> 快速排序5.3 排序算法全家福
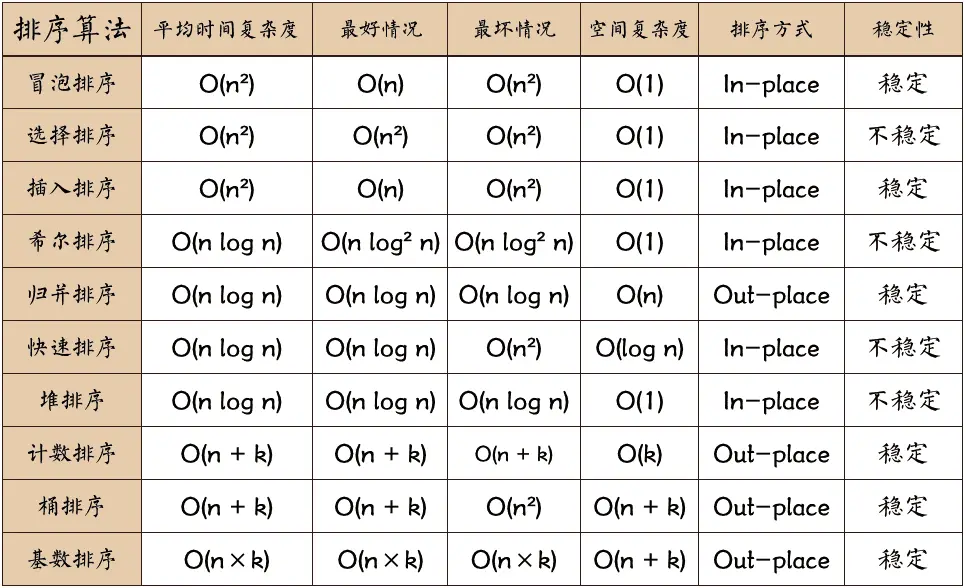
十大经典排序算法复杂度对比:
6. 实战练习:蓝桥云课 LQ3226 宝藏排序II
6.1 题目描述
在一个神秘的岛屿上,有一支探险队发现了一批宝藏,这批宝藏是以整数数组的形式存在的。每个宝藏上都标有一个数字,代表了其珍贵程度。然而,由于某种神奇的力量,这批宝藏的顺序被打乱了,探险队需要将宝藏按照珍贵程度进行排序,以便更好地研究和保护它们。作为探险队的一员,肖恩需要设计合适的排序算法来将宝藏按照珍贵程度进行从小到大排序。请你帮帮肖恩。
输入格式:
- 第一行:整数 n(宝藏数量,1 <= n <= 10^5)
- 第二行:n 个整数,表示每个宝藏的珍贵程度
输出格式:
- 一行,排序后的 n 个整数,空格分隔
样例:
输入:
9
3 5 8 1 2 9 4 7 6
输出:
1 2 3 4 5 6 7 8 96.2 三种算法 AC 代码
解法一:快速排序
python
# a[left,right] 按照小于等于基准值、基准值、大于基准值排列
def partition(a, left, right):
idx = left + 1
for i in range(left + 1, right + 1):
if a[i] <= a[left]:
a[idx], a[i] = a[i], a[idx]
idx += 1
a[left], a[idx - 1] = a[idx - 1], a[left]
return idx - 1
def quicksort(a, left, right):
if left < right:
mid = partition(a, left, right)
quicksort(a, left, mid - 1)
quicksort(a, mid + 1, right)
n = int(input())
a = list(map(int, input().split()))
quicksort(a, 0, n - 1)
print(' '.join(map(str, a)))解法二:归并排序
python
n = int(input())
a = list(map(int, input().split()))
def Merge(A, B):
result = []
while len(A) != 0 and len(B) != 0:
if A[0] <= B[0]:
result.append(A.pop(0))
else:
result.append(B.pop(0))
result.extend(A)
result.extend(B)
return result
def MergeSort(A):
if len(A) < 2:
return A
mid = len(A) // 2
left = MergeSort(A[:mid])
right = MergeSort(A[mid:])
return Merge(left, right)
print(' '.join(map(str, MergeSort(a))))解法三:Python 内置排序(推荐)
python
n = int(input())
a = list(map(int, input().split()))
# Python 内置 Timsort,基于归并排序和插入排序的混合算法
# 时间复杂度 O(n log n),空间复杂度 O(n)
# 实际竞赛中最推荐的写法
a.sort()
print(' '.join(map(str, a)))6.3 复杂度分析(针对本题)
| 算法 | 时间复杂度 | 空间复杂度 | 能否通过 | 说明 |
|---|---|---|---|---|
| 快速排序 | O(n log n) | O(log n) | 能 | 最坏 O(n^2),但实际很快 |
| 归并排序 | O(n log n) | O(n) | 能 | 稳定,但需要额外空间 |
| 希尔排序 | O(n^1.3) | O(1) | 能 | 原地排序,但常数较大 |
| a.sort() | O(n log n) | O(n) | 能 | 推荐,Python 内置 Timsort |
竞赛建议:n <= 10^5 时,快速排序和归并排序都能轻松通过。实际比赛中建议直接使用 a.sort() 或 sorted(a),它们底层是高度优化的 Timsort 算法。
结语
本文深入讲解了三种高级排序算法:
| 算法 | 核心突破 | 关键掌握点 |
|---|---|---|
| 希尔排序 | 突破 O(n^2) 的第一步 | 增量序列设计、分组插入思想 |
| 快速排序 | 分治 + 原地划分 | pivot 选择、划分函数、递归终止 |
| 归并排序 | 稳定 O(n log n) | 递归分解、双指针合并、稳定性保证 |
排序算法完整知识体系:
| 复杂度 | 算法 | 特点 |
|---|---|---|
| O(n^2) | 冒泡、选择、插入 | 基础,教学用 |
| O(n^1.3) | 希尔排序 | 插入排序升级版 |
| O(n log n) | 快速、归并、堆排序 | 实际应用主力 |
| O(n) | 计数、桶、基数排序 | 特定数据分布 |
思考题:计数排序的时间复杂度是 O(n+k),当 k 很大时(如 k = n^2),还能用计数排序吗?如果不能,有什么替代方案?下篇揭晓答案!
点赞 + 收藏 + 关注,算法学习不迷路!