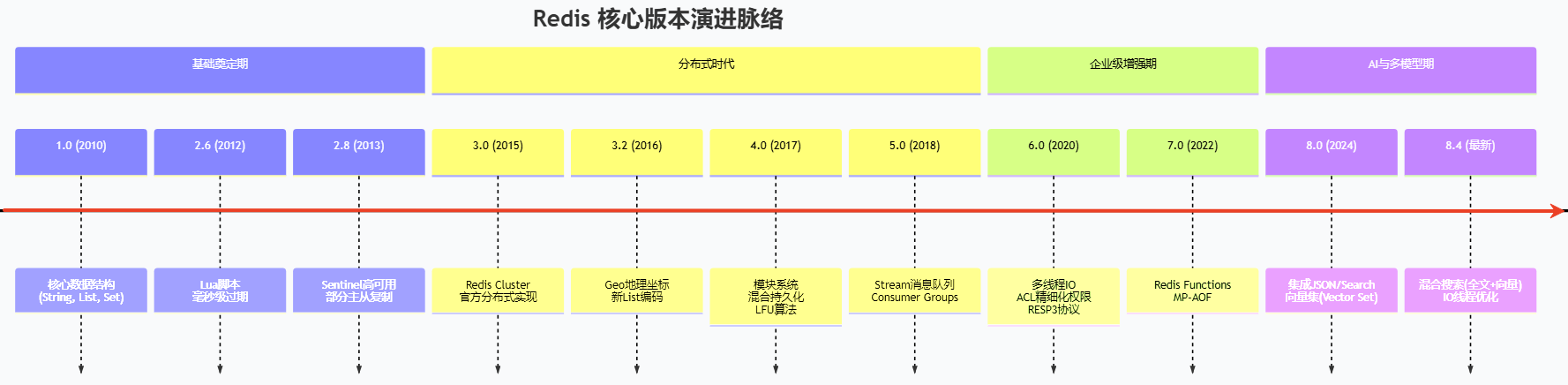
一、Redis 3.0(2015-03):分布式里程碑,原生集群 + 哨兵
核心定位
从单机走向原生分布式,解决水平扩展与高可用问题,是 Redis 发展史的分水岭。
1. Redis Sentinel(哨兵):高可用故障自动转移
原理
架构组成
- 主节点 (Master):负责写,同步数据到从
- 从节点 (Slave):只读,同步主节点数据
- 哨兵节点 (Sentinel):独立进程,监控 + 投票 + 自动选主
核心三大功能
- 监控:哨兵节点持续探测主、从节点存活状态
- 自动故障转移:主宕机 → 哨兵投票选最优从升级为主,其余从自动跟随新主
- 消息通知:节点异常通知客户端。
示例
bash
# 1. 哨兵配置文件(sentinel.conf)
sentinel monitor mymaster 127.0.0.1 6379 2 # 监控主节点,2个哨兵同意即判定宕机
sentinel down-after-milliseconds mymaster 3000 # 3秒无响应判定宕机
sentinel failover-timeout mymaster 10000 # 故障转移超时10秒
# 2. 启动哨兵
redis-sentinel sentinel.conf
# 3. 客户端通过哨兵获取主节点
redis-cli -h 127.0.0.1 -p 26379
127.0.0.1:26379> sentinel get-master-addr-by-name mymaster
# 输出:1) "127.0.0.1" 2) "6379"(主节点地址)场景
中小型项目、数据量不大
读多写少,依赖读写分离
只需要高可用,不需要分布式存储
2.原生 Redis Cluster(最重要)
原理
- 数据分片:共 16384 个哈希槽(hash slot) ,按
CRC16(key) % 16384计算key 落在哪个槽。 - 节点分工:每个主节点负责一部分槽位,从节点做备份,主宕机后从自动升级。
- 智能路由:客户端直接连接集群,自动跳转至键所在节点,无代理层。
示例
bash
# 1. 创建3主3从集群(6节点)
redis-cli --cluster create \
127.0.0.1:7000 127.0.0.1:7001 \
127.0.0.1:7002 127.0.0.1:7003 \
127.0.0.1:7004 127.0.0.1:7005 \
--cluster-replicas 1
# 2. 写入数据(自动路由到对应槽)
127.0.0.1:7001> set user:1001 "zhangsan"
# 输出:OK(自动路由到user:1001所属槽的节点)
# 3. 查询数据(任意节点均可访问)
127.0.0.1:7002> get user:1001
# 输出:"zhangsan"场景
- 大数据量存储、单机内存不够用
- 高并发写入业务
- 大型分布式项目、微服务架构
- 需要动态扩容业务
3. 部分重同步(PSYNC):主从复制优化
原理
旧版(2.x)网络中断后必须全量同步 (拷贝整个 RDB),3.0 引入复制偏移量 + 积压缓冲区,短中断后仅同步增量数据,大幅减少同步耗时与网络开销。
示例
bash
# 主节点(6379)
127.0.0.1:6379> info replication
# 输出:master_repl_offset:12345(复制偏移量)
# 从节点(6380)
127.0.0.1:6380> info replication
# 输出:slave_repl_offset:12345(与主一致,部分重同步生效)二、Redis 3.2(2016-08):安全增强 + 性能优化
1. 保护模式(Protected Mode):默认安全
原理
旧版默认无密码 + 外网可访问,极易被攻击。3.2 后默认启用保护模式:
- 无密码时,仅本地(127.0.0.1)可访问,外网连接直接拒绝。
- 提示配置密码或绑定外网 IP。
示例
bash
# 外网直接连接无密码Redis(默认保护模式)
redis-cli -h 192.168.1.100
# 输出:(error) DENIED Redis is running in protected mode...(拒绝连接)
# 关闭保护模式(不推荐,仅测试用)
127.0.0.1:6379> config set protected-mode no2. 客户端超时默认 0(永不超时)→ 300 秒
避免空闲客户端长期占用连接,导致连接数耗尽。
3. 优化 List 底层编码
小 List(长度≤512)默认用QuickList(链表 + 压缩列表混合),内存占用更低,读写更快。
4.GEO 地理位置存储 & 计算
bash
# 添加位置
GEOADD cities 116.397 39.908 "beijing" 121.473 31.230 "shanghai"
# 计算两地距离
GEODIST cities beijing shanghai km
# → "1067.8"三、Redis 4.0(2017-11):模块化 + 混合持久化 + LFU,从缓存到平台
核心定位
最大变革是模块系统,支持自定义数据类型与命令;持久化与淘汰策略全面升级。
1. 模块系统(Modules):功能无限扩展
原理
Redis 核心保留精简,通过动态库模块扩展功能,官方提供搜索、JSON、时序、布隆过滤器等模块,第三方可自定义开发。
示例(加载布隆过滤器模块)
# 1. 下载编译 rebloom 模块
git clone https://github.com/RedisBloom/RedisBloom.git
cd RedisBloom && make
# 2. 启动Redis时加载模块
redis-server --loadmodule ./rebloom.so
# 3. 使用布隆过滤器命令
127.0.0.1:6379> bf.add user_filter 1001
# 输出:1(添加成功)
127.0.0.1:6379> bf.exists user_filter 1001
# 输出:1(存在)2. 混合持久化(RDB+AOF):兼顾速度与数据安全
原理
- 旧版:RDB(快、数据可能丢)或 AOF(慢、数据安全)二选一。
- 4.0 混合:AOF 文件开头存 RDB 全量数据,后续追加 AOF 增量命令。
- 重启加载:先快速加载 RDB,再重放少量 AOF,速度接近 RDB,数据安全接近 AOF。
配置示例
Lua
# redis.conf
aof-use-rdb-preamble yes # 开启混合持久化
appendonly yes # 启用AOF
save 3600 1 # 每小时至少1个键变更时生成RDB3. LFU 缓存淘汰策略:比 LRU 更精准
原理
- LRU(旧):淘汰最久未访问的键,不关心访问频率(如热点键偶尔访问也可能被淘汰)。
- LFU(新):淘汰访问频率最低的键,频率高的热点键更难被淘汰,缓存命中率更高。
示例
bash
# 1. 配置LFU淘汰策略(内存满时触发)
127.0.0.1:6379> config set maxmemory 1gb
127.0.0.1:6379> config set maxmemory-policy allkeys-lfu
# 2. 写入大量数据,观察淘汰逻辑
# LFU会优先淘汰访问次数少的键,保护高频访问的热点数据4. 异步删除命令(UNLINK、FLUSHALL ASYNC):避免阻塞
原理
旧版 DEL、FLUSHALL 是同步阻塞,删除大键(如百万元素 List)会阻塞主线程,导致服务卡顿。4.0 新增异步命令,后台线程删除,不阻塞主线程。
示例
bash
# 1. 写入大List(100万元素)
127.0.0.1:6379> RPUSH big_list {1..1000000}
# 2. 同步删除(阻塞,卡顿)
127.0.0.1:6379> DEL big_list # 阻塞几秒,期间无法处理其他命令
# 3. 异步删除(非阻塞,推荐)
127.0.0.1:6379> UNLINK big_list # 立即返回,后台线程删除
# 4. 异步清空所有数据
127.0.0.1:6379> FLUSHALL ASYNC四、Redis 5.0(2018-10):Stream 流 + 集群管理优化,消息队列新选择
核心定位
最重磅:Stream 数据类型(消息队列);集群管理更易用,性能提升。
1. Stream 数据类型:原生消息队列,媲美 Kafka
原理
- 结构:类似日志文件,键 = 流名称 ,值 = 消息(消息 ID + 字段 - 值对),消息 ID 默认
时间戳-序列号。 - 核心能力:消费者组(Consumer Group)、消息确认(ACK)、消息回溯、阻塞读取,支持多消费组、多消费者,消息不丢、不重复。
示例(Stream 基础操作 + 消费者组)
bash
# 1. 创建流(自动创建,无需手动初始化)
# 2. 写入消息(自动生成消息ID:1620000000000-0)
127.0.0.1:6379> XADD order_stream * user_id 1001 amount 99.9
# 输出:1620000000000-0
# 3. 创建消费者组(消费组g1,从第一条消息开始消费)
127.0.0.1:6379> XGROUP CREATE order_stream g1 0
# 输出:OK
# 4. 消费者c1读取消息(阻塞10秒,无消息等待)
127.0.0.1:6379> XREADGROUP GROUP g1 c1 BLOCK 10000 STREAMS order_stream >
# 输出:1) 1) "order_stream"
# 2) 1) 1) "1620000000000-0"
# 2) 1) "user_id" 2) "1001" 3) "amount" 4) "99.9"
# 5. 消息确认(ACK,标记已处理,避免重复消费)
127.0.0.1:6379> XACK order_stream g1 1620000000000-0
# 输出:1场景
- 实时消息队列(订单、日志、事件推送)
- 数据同步(多服务间数据传递)
- 流处理(实时计算、风控)
2. 集群管理命令优化
新增 CLUSTER SLOTS、CLUSTER NODES 等命令,集群状态查询更清晰;新增手动槽位迁移命令,集群扩容缩容更灵活。
3. 性能提升
- 主从复制速度提升 50%
- 内存占用降低 10%-30%(优化数据结构编码)
五、Redis 6.0(2020-04):多线程 IO+ACL+SSL,企业级安全与性能
核心定位
IO 多线程 (性能飞跃)、ACL 权限控制 (精细化安全)、SSL 加密(传输安全),全面满足企业级需求。
1. IO 多线程:性能翻倍,吞吐量提升
原理
旧版 Redis 是单线程 (仅命令执行单线程,IO 读写单线程),瓶颈在网络 IO。6.0 引入IO 多线程:
- 命令执行:保持单线程(无并发问题,安全)
- 网络 IO:多线程处理(读请求、写响应),充分利用多核 CPU,吞吐量提升 1 倍 +。
配置示例
bash
# redis.conf
io-threads 4 # IO线程数(建议=CPU核心数,最多12)
io-threads-do-reads yes # 开启多线程读(默认开启)性能对比
- 单线程:10 万 QPS
- 4 核 IO 多线程:25 万 + QPS
2. ACL 权限控制:精细化权限,替代密码
原理
旧版仅全局密码 ,无法细分用户权限。6.0 引入用户 - 权限模型:
- 支持多用户,每个用户可配置读写权限、命令权限、键权限 (如用户 A 仅能读
user:*键,不能写)。 - 权限粒度:按键、按命令、按访问类型(读 / 写 / 管理)。
示例
bash
# 1. 创建管理员用户(所有权限)
127.0.0.1:6379> ACL SETUSER admin on >123456 ~* +@all
# 解释:on=启用,>123456=密码,~*=所有键,+@all=所有命令
# 2. 创建只读用户(仅读user:开头的键)
127.0.0.1:6379> ACL SETUSER reader on >654321 ~user:* +@read
# 解释:+@read=仅读命令,禁止写/管理命令
# 3. 登录验证
redis-cli -u redis://reader:654321@127.0.0.1:6379
127.0.0.1:6379> get user:1001 # 允许
127.0.0.1:6379> set user:1002 "lisi" # 拒绝(无写权限)3. SSL/TLS 加密:传输加密,防窃听篡改
原理
旧版网络传输明文,易被抓包篡改。6.0 支持 SSL/TLS 加密,客户端与服务端、主从复制、集群通信均加密,保障传输安全。
配置示例
bash
# redis.conf
tls-port 6380 # SSL端口
tls-cert-file ./redis.crt # 证书文件
tls-key-file ./redis.key # 私钥文件
tls-cluster yes # 集群通信加密4. 客户端缓存(Client Side Caching):减少网络交互
客户端本地缓存热点键,无需每次请求 Redis,减少网络 IO,进一步提升性能。
六、Redis 7.0(2022-04):Redis Functions + 分片 RDB + 性能巅峰
核心定位
里程碑级大版本 :回归开源(SSPL→RSALv2/SSPLv1/AGPLv3 三选一)、原生向量数据库 (AI 检索)、多模型数据结构 (JSON / 时序 / 概率)、性能提升 87%。
1.Redis Functions(比 Lua 脚本更好管理)
Lua
# 注册函数
FUNCTION LOAD "#!lua name=mylib\n
redis.register_function('myecho', function(keys, args)
return args[1]
end)"
bash
# 调用函数
FCALL myecho hello
# → "hello"2.Vector Set(向量集合):原生向量数据库,AI 检索首选
原理
新增向量数据类型 ,支持高维向量存储 + 相似度检索(余弦、欧氏距离),十亿级向量实时索引,查询延迟毫秒级,替代专用向量数据库(如 Pinecone)。
示例
bash
# 1. 创建向量集合(768维向量,余弦相似度)
127.0.0.1:6379> VECTOR CREATE doc_vectors DIM 768 TYPE FLOAT32 DISTANCE COSINE
# 输出:OK
# 2. 写入向量(文档ID+向量数据)
127.0.0.1:6379> VECTOR ADD doc_vectors doc1 [0.1,0.2,...,0.768]
127.0.0.1:6379> VECTOR ADD doc_vectors doc2 [0.3,0.4,...,0.768]
# 3. 相似度检索(查询与doc1最相似的前2个向量)
127.0.0.1:6379> VECTOR SEARCH doc_vectors [0.11,0.21,...,0.7681] LIMIT 2
# 输出:1) "doc1" 2) 0.98(相似度) 3) "doc2" 4) 0.85场景
- AI 语义检索(文本、图片、音频向量存储与查询)
- 推荐系统(用户 / 物品向量相似度匹配)
- 大模型 RAG(检索增强生成)知识库
3. 原生 JSON 支持:无需模块,直接操作 JSON
原理
旧版 JSON 需依赖 ReJSON 模块,8.0 内置 JSON 类型,支持JSON 路径查询、修改、嵌套结构 ,性能提升 50% ,内存占用降低 91%(同质数组优化)。
示例
bash
# 1. 写入JSON数据
127.0.0.1:6379> JSONSET user:1001 $ '{"name":"zhangsan","age":25,"tags":["dev","redis"]}'
# 输出:OK
# 2. JSON路径查询(查name字段)
127.0.0.1:6379> JSONGET user:1001 $.name
# 输出:"zhangsan"
# 3. 修改嵌套数组(添加tag)
127.0.0.1:6379> JSONARRAPPEND user:1001 $.tags "ai"
# 输出:3
# 4. 查询完整JSON
127.0.0.1:6379> JSONGET user:1001
# 输出:{"name":"zhangsan","age":25,"tags":["dev","redis","ai"]}4. 五种概率数据结构:原生支持,高效去重 / 统计
内置布隆过滤器、布谷鸟过滤器、Count-Min Sketch、Top-K、T-Digest,无需模块,内存极低,适合大数据量去重、频率统计、分位数计算。
示例(布隆过滤器)
bash
# 1. 布隆过滤器添加元素
127.0.0.1:6379> BFADD user_filter 1001 1002 1003
# 输出:1 1 1
# 2. 判断元素是否存在
127.0.0.1:6379> BFEXISTS user_filter 1001
# 输出:1(存在)
127.0.0.1:6379> BFEXISTS user_filter 9999
# 输出:0(不存在)5. 性能爆炸:吞吐量翻倍,命令速度提升 87%
- GET 性能提升 90% ,SET 提升 10%
- 分布式查询吞吐量提升 4.7 倍
- 主从复制时间减少 18%
- IO 线程模型重构,吞吐量翻倍
6. 许可证变更:回归开源,友好商用
从 SSPL(商业限制)改为 RSALv2/SSPLv1/AGPLv3 三选一,商用更友好,无版权风险。
八、Redis 8.2(2025-11):向量增强 + 性能优化 + 稳定性提升
1. 向量检索优化
- 支持向量索引压缩 ,内存占用降低 50%
- 相似度检索速度提升 30%,支持更大规模向量数据
2. 命令性能优化
- 字符串、哈希、Stream 命令速度提升 10%-20%
- 减少内存拷贝,降低 CPU 占用
3. 集群稳定性增强
- 修复槽位迁移 Bug,集群扩容缩容更稳定
- 优化主从复制断线重连逻辑,减少数据丢失风险
九、Redis 8.4(2026-03):原子槽迁移 + 字符串增强 + AOF 自动修复
1. CLUSTER MIGRATION:原子槽位迁移,零停机
原理
旧版槽位迁移:分多步执行,迁移期间槽位短暂不可用。8.4 新增 CLUSTER MIGRATION 命令,单步原子迁移槽位 + 数据,零停机,无数据不可用窗口Redis。
示例
bash
# 原子迁移槽位 0-100 从节点7001到7002
127.0.0.1:7001> CLUSTER MIGRATION 127.0.0.1 7002 0 100
# 输出:OK(原子完成,无停机)2. 字符串命令增强:DELEX(条件删除)
原理
新增 DELEX key value:仅当键值匹配时删除,原子操作,替代 "GET + 判断 + DEL" 三步,避免并发问题Redis。
示例
bash
# 1. 写入键值
127.0.0.1:6379> set lock "123"
# 输出:OK
# 2. 条件删除(值匹配则删除)
127.0.0.1:6379> DELEX lock "123"
# 输出:1(删除成功)
# 3. 条件删除(值不匹配,删除失败)
127.0.0.1:6379> set lock "456"
127.0.0.1:6379> DELEX lock "123"
# 输出:0(删除失败)3. AOF 自动修复:启动时自动修复损坏 AOF
新增 aof-load-corrupt-tail-max-size 配置,启动时自动修复轻微损坏的 AOF 尾部,无需手动修复,提升系统韧性Redis。
4. Stream 增强:XREADGROUP 支持 min-idle-time
消费者组读取时,可指定最小空闲时间,仅读取空闲超时的消息,优化消息重试逻辑,避免重复消费。
5.语义缓存(Semantic Cache)
Spring AI 已提供开箱即用的支持:
java
@Service
public class SemanticCacheService {
public String query(String userQuestion) {
// 1. 先搜索语义相似的历史问答
List<Document> cached = vectorStore.similaritySearch(
SearchRequest.builder()
.query(userQuestion)
.topK(1)
.similarityThreshold(0.92) // 相似度阈值
.build()
);
if (!cached.isEmpty()) {
return cached.get(0).getMetadata().get("answer");
}
// 2. Cache Miss -> 调用 LLM
String answer = chatClient.prompt(userQuestion).call().content();
// 3. 写入语义缓存
vectorStore.add(List.of(new Document(userQuestion,
Map.of("answer", answer))));
return answer;
}
}效果数据 :可减少 70% 的 LLM API 调用,延迟从秒级降到毫秒级
十、版本演进总结
- V3.0 :分布式基础(集群 + 哨兵)→ 解决水平扩展 + 高可用
- V4.0 :模块化 + 持久化 + 淘汰策略 → 从缓存 到多功能平台
- V5.0 :Stream 流 → 原生消息队列,适配实时场景
- V6.0 :多线程 IO+ACL+SSL → 企业级安全 + 性能,支撑高并发
- V7.0 :Functions + 分片 RDB + 多部分 AOF → 稳定性 + 易用性巅峰
- V8.0+ :向量 + 多模型 + AI → 从数据库 到AI 原生多模型数据库