目录
一、环境信息
|------|--------------------------------------|
| 名称 | 值 |
| CPU | 12th Gen Intel(R) Core(TM) i7-12700H |
| 操作系统 | CentOS Linux release 7.9.2009 (Core) |
| 内存 | 7G |
| 逻辑核数 | 8 |
| DM版本 | 8.1.4.170 |
二、说点什么
达梦闭源,堆栈中的函数我们多记录一次,就多一次解决问题的可能。
三、函数栈截图
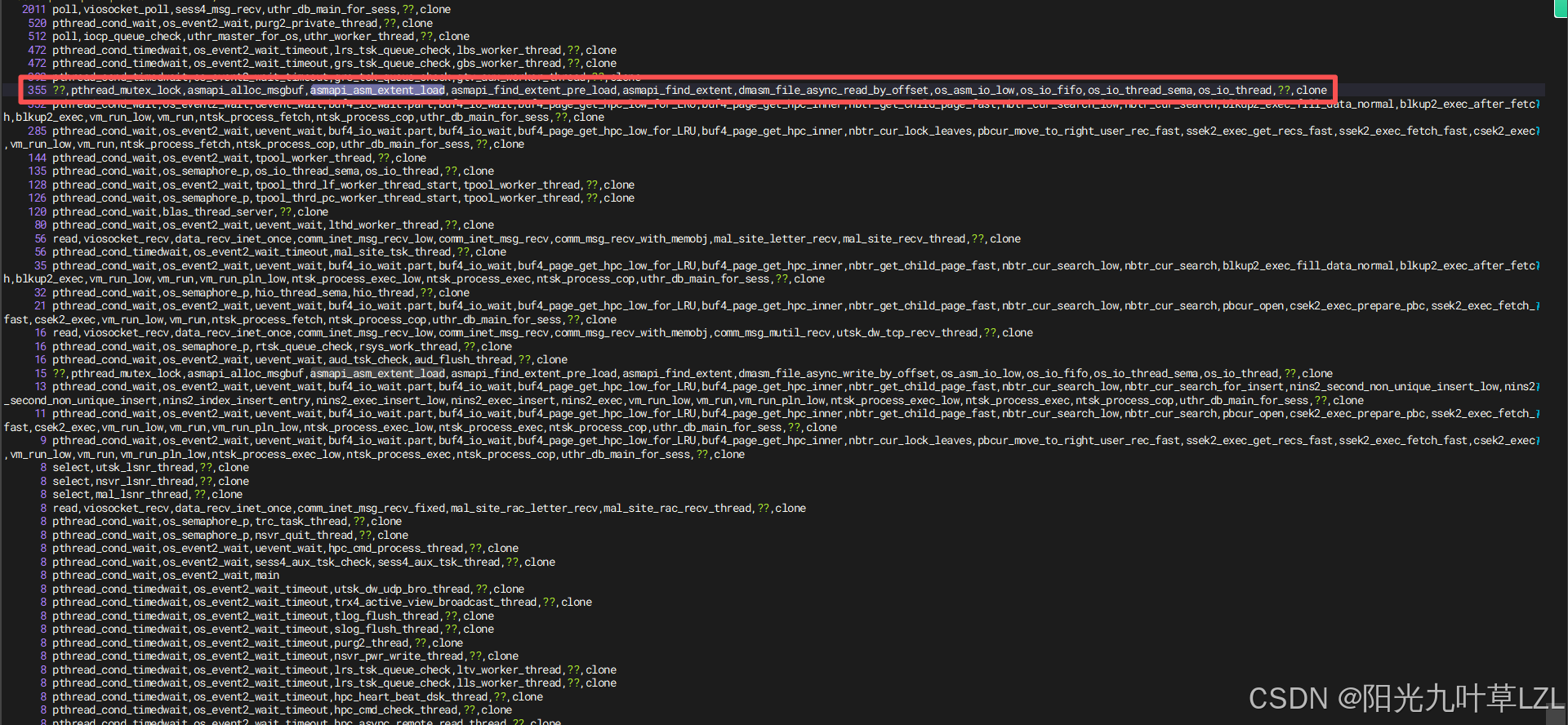
这一层函数栈执行了355次,说明达梦asm共享内存紧张,频繁的申请内存。
四、解决方法
|---------------------|------|---------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------|-------------------------------------|
| 参数名 | 修改值 | 描述 | 配置文件 | 备注 |
| DCR_EP_SHM_SIZE | 1024 | 共享内存大小,单位 MB,取值范围 10~40000。每 10M 共享内存大小能管理的磁盘大小,每个簇描述项大概占用 64byte 内存空间,每个簇描述项对应 4MB 磁盘空间,共享内存还有部分内存用来保 持必要的控制信息。440GB 左右的磁盘,需要 10MB 大小的共享内存能保证使用过程中簇描述项不被淘汰。 | DMDCR_CFG.INI | |
| DMDCR_NEED_PRE_LOAD | 1 | 非镜像环境下,指定 DMASMSVR 启动时是否预加载文件EXTENT;镜像环境下,指定 DMASMSVRM 启动时是否预加载文件 AU。0:否;1:是。预加载操作可以提升 DMSERVER 或DMASMSVRM 运行时的性能,但是数据量非常大时,预加载操作比较耗时。缺省为 0 | DMDCR.INI | 数据量较大时,启动较慢,可以不配置,5T数据启动一分钟左右,仅供参考。 |