一、收银变慢,监控却说一切正常
月初收到门店反馈:下午高峰期收银结账变慢,偶尔要等5-6秒才出结果。
值班同事第一反应看服务器监控------CPU 35%、内存占用60%、磁盘IO正常、网络延迟2ms。全绿。
接着查应用日志,没有报错。查Nginx access log,发现 /api/checkout 接口P99响应时间从正常的200ms飙到了6200ms,但只在14:00-16:00出现。
最后定位到原因:有一条统计查询没加索引,随着订单表数据增长到300万行,全表扫描耗时从1秒涨到8秒,恰好在高峰期被频繁触发。
问题本身不复杂------加个索引就解决了。但暴露的链路断点很致命:
slow_log其实已经记录了这条SQL整整两周,但没有任何机制把它变成一个告警或一个待处理事项。
这不是个例。大部分多门店系统的慢查询管理现状:
| 环节 | 现状 | 问题 |
|---|---|---|
| slow_log | 开了 | 日志文件越来越大,没人看 |
| 分析 | 偶尔手动看 | 没有定期解析和聚合 |
| 告警 | 无 | 慢查询不在告警体系内 |
| 定位 | 靠人肉grep | 不知道哪条SQL影响最大 |
| 优化 | 等出问题再查 | 被动,无法提前发现退化 |
| 工单联动 | 无 | 发现了慢SQL也没有派单和跟进闭环 |
理想状态是:慢查询一旦触发告警,自动生成一张带SQL指纹和所属数据库的工单,DBA直接从工单拿上下文开始优化,优化完关单,月底统计哪个库的慢查询工单最多------这才是"监控→告警→处置→闭环"的完整链路。
下面给出一套从采集到告警的完整链路。
二、慢查询监控的完整链路
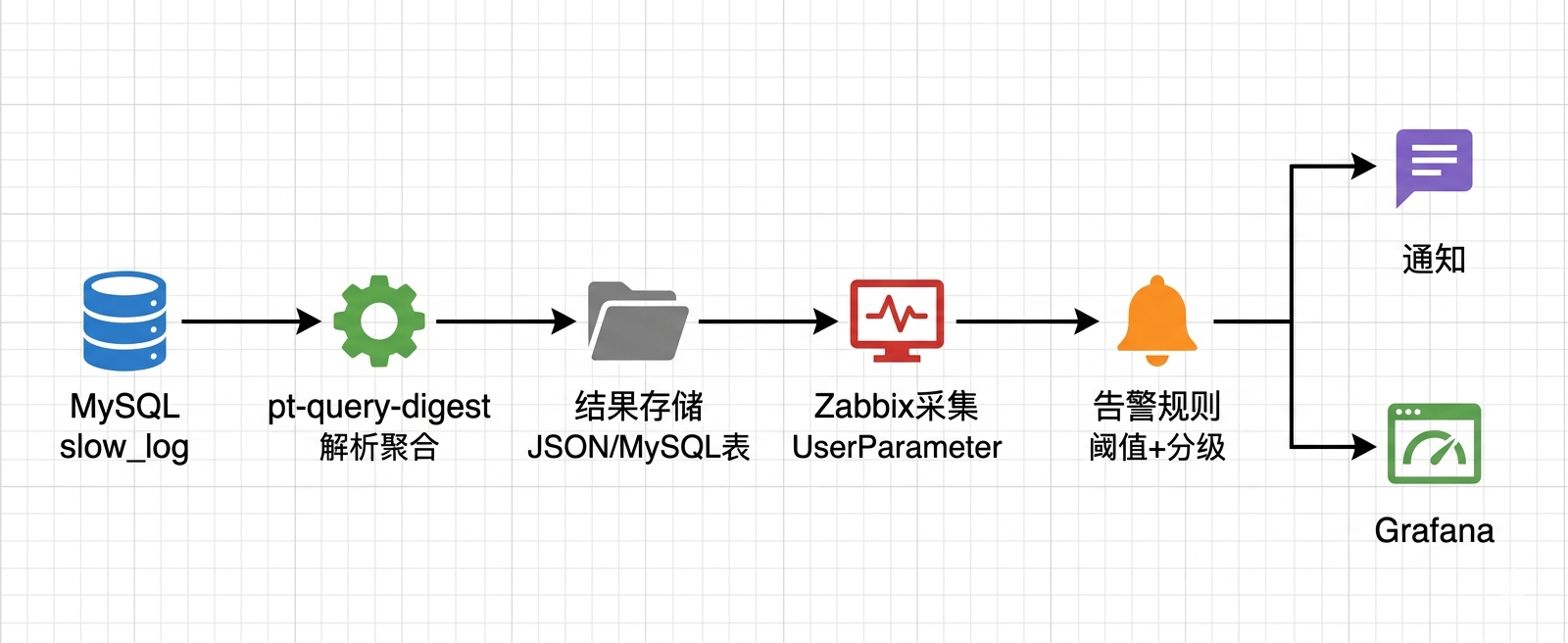
整条链路分6步:
MySQL slow_log → pt-query-digest 定期解析 → 结果入库/文件 → Zabbix 自定义采集 → 告警规则判断 → 通知 + Grafana可视化每一步的核心任务:
| 步骤 | 工具 | 核心产出 |
|---|---|---|
| 1. 采集 | MySQL原生slow_log | 原始慢查询记录 |
| 2. 解析 | pt-query-digest | SQL指纹聚合 + 统计摘要 |
| 3. 存储 | JSON文件 / MySQL表 | 可查询的结构化数据 |
| 4. 监控 | Zabbix UserParameter | 指标采集(数量/最大耗时/Top SQL) |
| 5. 告警 | Zabbix Trigger | 分级告警(P1/P2/P3) |
| 6. 展示 | Grafana | 趋势 + Top SQL + 分布分析 |
三、Step 1-2:slow_log配置 + pt-query-digest定期解析
3.1 MySQL slow_log 配置
sql
-- 查看当前慢查询配置
SHOW VARIABLES LIKE 'slow_query%';
SHOW VARIABLES LIKE 'long_query_time';
-- 开启慢查询日志(动态生效,无需重启)
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 1; -- 超过1秒记录
SET GLOBAL log_queries_not_using_indexes = ON; -- 未使用索引的也记录
SET GLOBAL min_examined_row_limit = 1000; -- 扫描行数>1000才记录(过滤小表全扫)
-- 持久化配置(写入 my.cnf)
-- [mysqld]
-- slow_query_log = 1
-- slow_query_log_file = /var/log/mysql/slow.log
-- long_query_time = 1
-- log_queries_not_using_indexes = 1
-- min_examined_row_limit = 1000关键参数选择建议:
| 参数 | 建议值 | 理由 |
|---|---|---|
| long_query_time | 1秒(业务系统) / 0.5秒(核心交易) | 太短日志量爆炸,太长漏掉退化趋势 |
| log_queries_not_using_indexes | ON | 提前发现缺索引SQL |
| min_examined_row_limit | 1000 | 避免小表全扫干扰 |
3.2 pt-query-digest 定期解析
安装 Percona Toolkit:
bash
# CentOS/RHEL
yum install -y percona-toolkit
# Ubuntu/Debian
apt-get install -y percona-toolkit
# 验证安装
pt-query-digest --version定时解析脚本 /opt/scripts/slow_query_analyze.sh:
bash
#!/bin/bash
# 慢查询定期解析脚本
# 每10分钟执行一次,解析增量日志并输出JSON格式结果
SLOW_LOG="/var/log/mysql/slow.log"
OUTPUT_DIR="/opt/slow_query_reports"
TIMESTAMP=$(date +%Y%m%d_%H%M)
LAST_POS_FILE="/tmp/slow_log_last_pos"
mkdir -p "$OUTPUT_DIR"
# 获取上次读取位置(增量解析)
if [ -f "$LAST_POS_FILE" ]; then
LAST_POS=$(cat "$LAST_POS_FILE")
else
LAST_POS=0
fi
# 当前文件大小
CURRENT_SIZE=$(stat -c%s "$SLOW_LOG" 2>/dev/null || stat -f%z "$SLOW_LOG")
# 如果日志被轮转(当前大小小于上次位置),重置
if [ "$CURRENT_SIZE" -lt "$LAST_POS" ]; then
LAST_POS=0
fi
# 增量读取并解析
tail -c +$((LAST_POS + 1)) "$SLOW_LOG" | pt-query-digest \
--output json \
--limit 20 \
--order-by Query_time:sum \
> "$OUTPUT_DIR/report_${TIMESTAMP}.json" 2>/dev/null
# 同时输出简要摘要供Zabbix采集
tail -c +$((LAST_POS + 1)) "$SLOW_LOG" | pt-query-digest \
--output json \
--limit 5 \
> "$OUTPUT_DIR/latest_summary.json" 2>/dev/null
# 记录当前位置
echo "$CURRENT_SIZE" > "$LAST_POS_FILE"
# 提取关键指标供监控采集
TOTAL_QUERIES=$(cat "$OUTPUT_DIR/latest_summary.json" | python3 -c "
import sys, json
try:
data = json.load(sys.stdin)
print(len(data.get('classes', [])))
except:
print(0)
")
MAX_TIME=$(cat "$OUTPUT_DIR/latest_summary.json" | python3 -c "
import sys, json
try:
data = json.load(sys.stdin)
classes = data.get('classes', [])
if classes:
print(max(c.get('metrics', {}).get('Query_time', {}).get('max', 0) for c in classes))
else:
print(0)
except:
print(0)
")
# 写入Zabbix可读的指标文件
echo "$TOTAL_QUERIES" > /tmp/slow_query_count
echo "$MAX_TIME" > /tmp/slow_query_max_time配置 crontab:
bash
# 每10分钟执行一次慢查询解析
*/10 * * * * /opt/scripts/slow_query_analyze.sh >> /var/log/slow_query_analyze.log 2>&1四、Step 3-5:Zabbix自定义采集 + 分级告警
4.1 Zabbix UserParameter 配置
在被监控主机的 Zabbix Agent 配置中添加自定义监控项:
ini
# /etc/zabbix/zabbix_agentd.d/mysql_slow_query.conf
# 慢查询数量(10分钟内新增的不同SQL指纹数)
UserParameter=mysql.slow_query.count,cat /tmp/slow_query_count 2>/dev/null || echo 0
# 最大查询耗时(秒)
UserParameter=mysql.slow_query.max_time,cat /tmp/slow_query_max_time 2>/dev/null || echo 0
# 当前slow_log文件大小(MB)
UserParameter=mysql.slow_query.log_size,echo "scale=2; $(stat -c%s /var/log/mysql/slow.log 2>/dev/null || echo 0) / 1048576" | bc
# 累计慢查询总数(从MySQL状态变量获取)
UserParameter=mysql.slow_query.total,mysqladmin -u zabbix_monitor -p'MonitorPass123' extended-status 2>/dev/null | grep -w Slow_queries | awk '{print $4}'重启 Zabbix Agent:
bash
systemctl restart zabbix-agent
# 验证
zabbix_agentd -t mysql.slow_query.count
zabbix_agentd -t mysql.slow_query.max_time4.2 Zabbix 告警规则(Trigger)
yaml
# 告警分级设计
triggers:
# P1 - 严重:存在超过10秒的慢查询(可能阻塞业务)
- name: "MySQL慢查询严重:存在超10秒SQL [P1]"
expression: "last(/MySQL Slow Query/mysql.slow_query.max_time)>10"
severity: High
description: "最大查询耗时超过10秒,可能阻塞业务事务,需立即排查"
# P2 - 警告:10分钟内新增5种以上慢SQL指纹
- name: "MySQL慢查询增多:10分钟新增{ITEM.LASTVALUE}种慢SQL [P2]"
expression: "last(/MySQL Slow Query/mysql.slow_query.count)>5"
severity: Warning
description: "短时间内出现大量不同的慢SQL,可能存在批量索引缺失或数据量突增"
# P3 - 信息:存在超过3秒的慢查询
- name: "MySQL慢查询注意:存在超3秒SQL [P3]"
expression: "last(/MySQL Slow Query/mysql.slow_query.max_time)>3 and last(/MySQL Slow Query/mysql.slow_query.max_time)<=10"
severity: Information
description: "存在3-10秒慢查询,建议排查是否需要索引优化"
# 趋势告警:慢查询数量持续增长(退化预警)
- name: "MySQL慢查询趋势恶化:连续3个周期递增"
expression: "last(/MySQL Slow Query/mysql.slow_query.count)>avg(/MySQL Slow Query/mysql.slow_query.count,1h)*2 and last(/MySQL Slow Query/mysql.slow_query.count)>3"
severity: Warning
description: "慢查询数量持续增长,可能存在数据量增长导致的性能退化"4.3 告警通知模板(企业微信 Webhook)
python
#!/usr/bin/env python3
# /opt/scripts/slow_query_alert_wechat.py
# Zabbix 动作调用,发送告警到企业微信
import sys
import json
import requests
import os
WEBHOOK_URL = os.environ.get('WECHAT_WEBHOOK', 'https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=YOUR_KEY')
def send_alert(subject, message):
# 解析告警信息
content = f"""**{subject}**
{message}
---
> 处理建议:
> 1. 登录对应服务器查看 /opt/slow_query_reports/latest_summary.json
> 2. 找到最慢的SQL指纹,确认是否缺索引
> 3. 如为核心交易SQL,优先评估索引优化方案"""
payload = {
"msgtype": "markdown",
"markdown": {"content": content}
}
resp = requests.post(WEBHOOK_URL, json=payload, timeout=10)
return resp.status_code == 200
if __name__ == '__main__':
subject = sys.argv[1] if len(sys.argv) > 1 else "MySQL慢查询告警"
message = sys.argv[2] if len(sys.argv) > 2 else ""
send_alert(subject, message)五、Step 6:Grafana慢查询分析看板
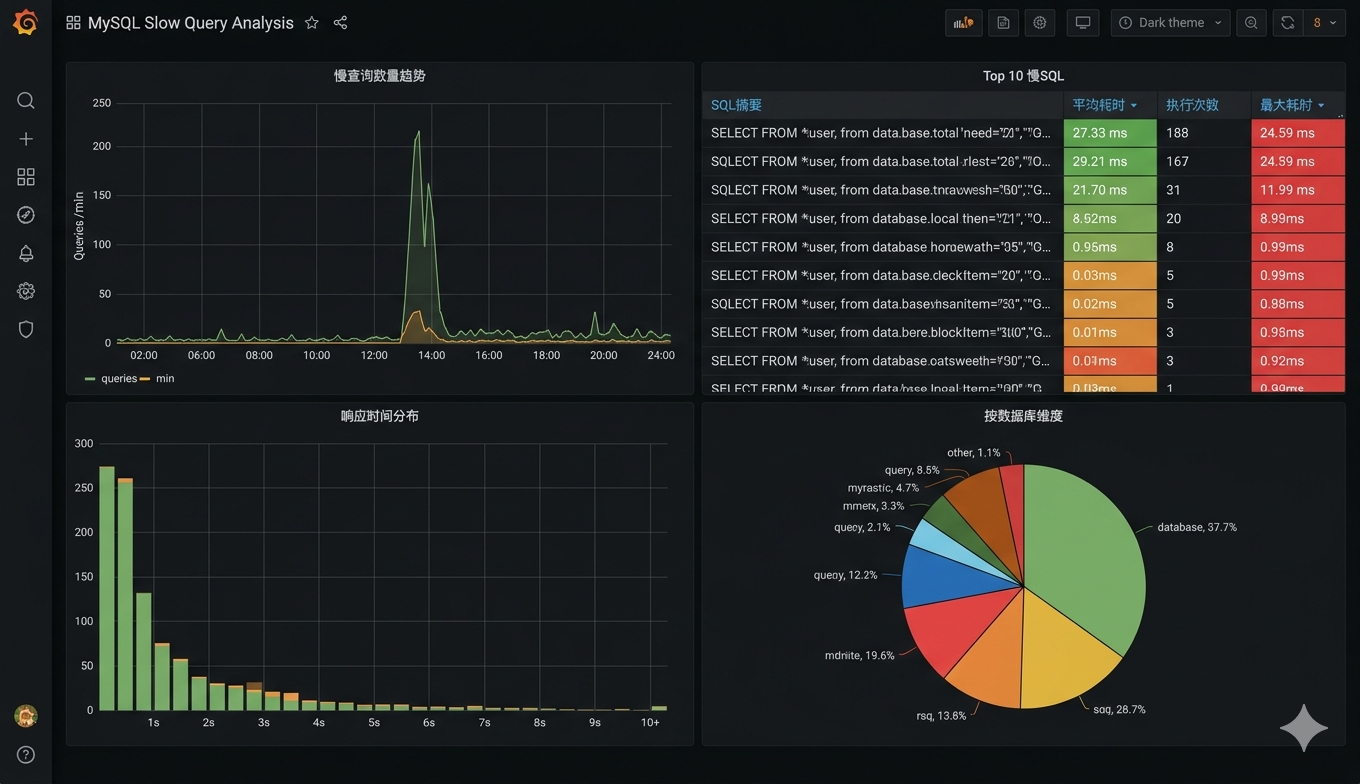
看板包含4个核心面板,数据源为 Zabbix(通过 Zabbix-Grafana 插件)或直接查询存储慢查询统计的MySQL表。
面板1:慢查询数量趋势(Time Series)
sql
-- 数据源:Zabbix history 或直接查询统计表
SELECT
FROM_UNIXTIME(clock) AS time,
value AS slow_query_count
FROM history
WHERE itemid = {SLOW_QUERY_COUNT_ITEMID}
AND clock > UNIX_TIMESTAMP(NOW() - INTERVAL 24 HOUR)
ORDER BY clock;面板2:Top 10 慢SQL排行(Table)
sql
-- 如果使用pt-query-digest --review模式写入数据库
SELECT
SUBSTR(fingerprint, 1, 80) AS 'SQL摘要',
ROUND(avg_query_time, 2) AS '平均耗时(s)',
exec_count AS '执行次数',
ROUND(max_query_time, 2) AS '最大耗时(s)',
ROUND(avg_query_time * exec_count, 1) AS '总耗时(s)',
db_name AS '数据库',
last_seen AS '最后出现'
FROM slow_query_review
WHERE last_seen > NOW() - INTERVAL 24 HOUR
ORDER BY avg_query_time * exec_count DESC
LIMIT 10;面板3:响应时间分布(Histogram)
sql
SELECT
CASE
WHEN query_time < 1 THEN '0-1s'
WHEN query_time < 3 THEN '1-3s'
WHEN query_time < 5 THEN '3-5s'
WHEN query_time < 10 THEN '5-10s'
ELSE '10s+'
END AS time_bucket,
COUNT(*) AS count
FROM slow_query_log_parsed
WHERE timestamp > NOW() - INTERVAL 24 HOUR
GROUP BY time_bucket
ORDER BY FIELD(time_bucket, '0-1s', '1-3s', '3-5s', '5-10s', '10s+');面板4:按数据库维度聚合(Pie Chart)
sql
SELECT
db_name AS '数据库',
COUNT(*) AS '慢查询数'
FROM slow_query_log_parsed
WHERE timestamp > NOW() - INTERVAL 24 HOUR
GROUP BY db_name
ORDER BY COUNT(*) DESC;六、落地效果与避坑清单
这套链路在我们的环境跑了4个月,核心数据变化:
| 指标 | 之前 | 之后 |
|---|---|---|
| 慢查询发现到处理平均时间 | 3-7天(等用户投诉) | 10分钟内告警 |
| 累计慢SQL指纹数 | 不知道 | 每日可追踪 |
| 因慢SQL导致的业务投诉 | 月均4-5次 | 月均0-1次 |
| 索引优化响应周期 | 被动、无优先级 | P1当天处理、P2 3天内 |
避坑清单
| 坑 | 现象 | 解决 |
|---|---|---|
| slow_log 文件暴增 | 几天就几个G | 配合 logrotate 按天轮转,保留7天 |
| pt-query-digest 解析慢 | 大文件解析要几分钟 | 用增量解析(记录offset),每次只处理新增部分 |
| long_query_time 设太短 | 大量无意义记录 | 配合 min_examined_row_limit 过滤小查询 |
| 监控只看"有没有"不看"变化趋势" | 慢SQL一直有3条没人管 | 加趋势告警:数量持续递增才报 |
| 告警后不知道查哪条SQL | 只知道"有慢查询"但不知道是哪条 | 告警通知里带Top 1 SQL指纹摘要 |
logrotate 配置参考
bash
# /etc/logrotate.d/mysql-slow-log
/var/log/mysql/slow.log {
daily
rotate 7
compress
delaycompress
missingok
notifempty
create 640 mysql mysql
postrotate
/usr/bin/mysqladmin flush-logs
endscript
}七、和运维体系结合
慢查询监控不是孤立的------它是整个数据库运维可观测性的一环。前面第一节提到的"理想状态",在我们的环境里已经跑通了。
Zabbix采集到的慢查询告警通过Webhook推送到工单系统,自动创建一张P2/P3工单。工单里带着慢SQL指纹摘要、所属数据库和触发时段,DBA直接从工单拿上下文开始排查,不需要再登服务器翻日志。我们用的是冠服云EMS平台做这层告警→工单的自动联动------告警事件进来后按规则匹配到对应数据库的资产记录,工单自动挂到那条资产下面。这样做有一个额外好处:月底拉一下资产维度的工单统计,"哪个库的慢查询工单最多、处理周期多长"一目了然,能帮团队决定下一步索引优化的优先级。
另外一个实际验证的经验:告警创建工单时,我们让工单标题自动带上Top 1慢SQL的指纹摘要(前60个字符),这样运维主管在工单列表里扫一眼就能判断优先级,不需要点进去看详情。这个小细节把慢查询工单的平均响应时间从4小时压到了40分钟。
这套链路的关键不是工具选什么,而是两点:第一,慢查询必须进入你的告警体系------不被告警覆盖的问题,就是不存在的问题;第二,告警必须能自动变成可追踪的工单------否则告警看了、没人跟、下次还来。
八、落地Checklist
- MySQL slow_log 开启并配置合理阈值(建议1秒)
- logrotate 配置慢查询日志轮转(日切,保留7天)
- 安装 Percona Toolkit,验证 pt-query-digest 可用
- 部署增量解析脚本,crontab 每10分钟执行
- Zabbix 配置 UserParameter,验证指标可采集
- 配置三级告警规则(P1 >10s / P2 >5种指纹 / P3 >3s)
- 告警通知模板包含SQL摘要信息
- Grafana 看板部署(趋势+Top SQL+分布+维度)
- 验证端到端:手动执行一条
SELECT SLEEP(5)确认告警触发
本文基于 MySQL 5.7/8.0 + Zabbix 6.x + Grafana 9.x 环境验证。核心思路适用于 MariaDB 和 PostgreSQL(pg_stat_statements 替代 slow_log)。