目录
[8、perf trace追踪系统调用](#8、perf trace追踪系统调用)
一、环境信息
|------|-----------------|
| 名称 | 值 |
| CPU | 海光 |
| 操作系统 | Kylin10 |
| DM版本 | 8.1.4.80_pack34 |
二、说点什么
最近DSC集群上线后,业务老师反馈指标性能每日不同时间段会出现下降的现象,排查周期长,感谢原厂老师这段时间的协助和分析,这里做一个总结,希望对大家有参考价值。
注意只有DSC版本才适用。
单机、主备版本请见之前的博客:
达梦数据库-学习-30-读写数据页超时告警排查(pagex,x,xxxxxx disk write uses)-主备集群版
三、排查过程
1、告警与等待
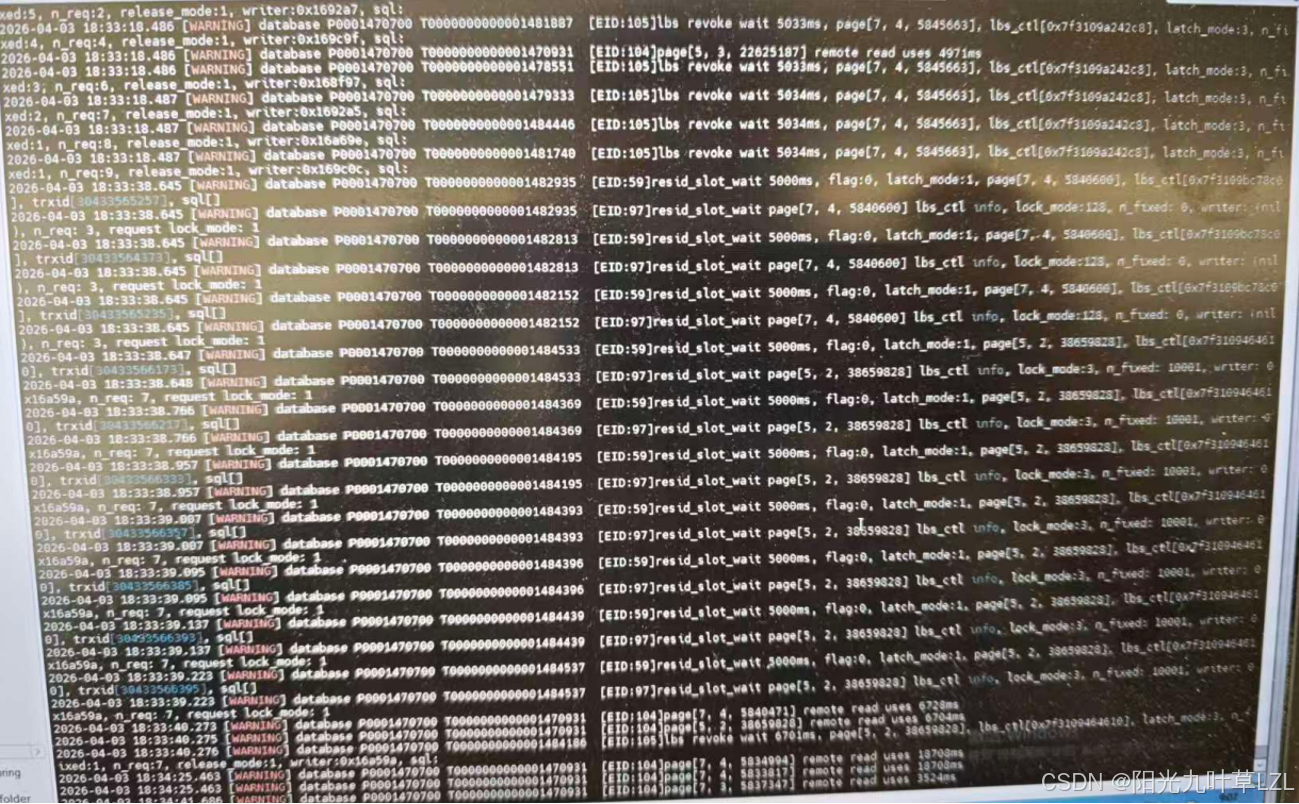
我们通过日志信息可以将告警信息分为两大类:
1、page remote read uses xxxx ms :最新的X表数据页在DSC节点A,B节点需读取X表数据,B通过网络读取A内存的最新数据页,时间超过3s出现告警。
2、lbs revoke wait xxxx ms : 本地缓冲栓回收A表权限等待超时。
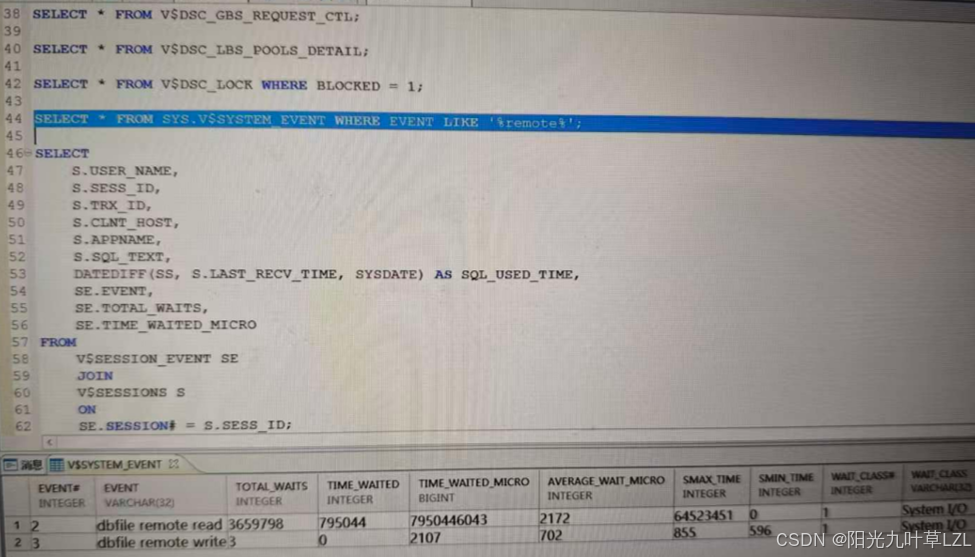
查看系统等待视图,发现数据库有较多的远程读写数据文件的等待事件,结合上面的日志告警说明应用侧在压多节点的场景下,缓存融合是影响数据库性能的因素之一,但缓存融合不应该这么效率低下,可能是网络层的影响,但我们先从数据库侧来避免缓存融合带来的影响,保证业务指标的正常执行。
网络层可以部署nmon进行监控。
nmon相关资料可以参考之前的博客:Linux-学习-04-nmon简记(持续更新)_linux debian nmon-CSDN博客
2、EP_SELECTOR参数调整

我们通过修改达梦参数配置,来减少缓存融合情况的发生,EP_SELECTOR改为1,手动指定节点。
3、dm_svc.conf配置示例
bash
# 以#开头的行表示是注释
# 全局配置区
TIME_ZONE=(+480)
LANGUAGE=(cn)
#集群配置举例
DSC=(xx.xx.xx.xx:5236,xx.xx.xx.xx:5236,xx.xx.xx.xx:5236)# 生产服务配置区
[DSC]
LOGIN_MODE=(1)
SWITCH_TIMES=(200)
SWITCH_INTERVAL=(300)
AUTO_RECONNECT=(1)
EP_SELECTOR=(1)配置文件修改完,重启应用,数据库层不再告警page remote read uses xxxx ms、lbs revoke wait xxxx ms等,应用指标压测性能进一步提升,但还没有满足业务老师性能需求,我们继续一层层排查。
4、高并发时日志告警
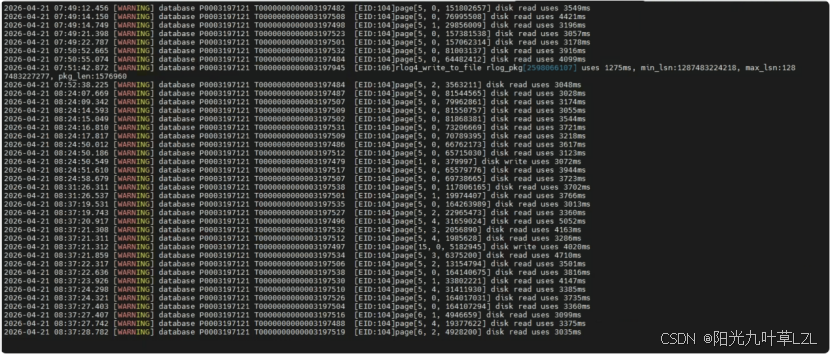
应用侧继续高并发压测,数据库层出现pagex,x,xxxxxx disk write/read uses xxxx ms,又是这个老朋友一般的告警了,第一反应是磁盘有问题,因为之前在主备集群版本的时候验证了,当然也是这个想法让我对此次排查遮上了一层迷雾。
5、磁盘性能观察

我们先查看虚拟设备映射关系,对应的多路径名是mpathe。
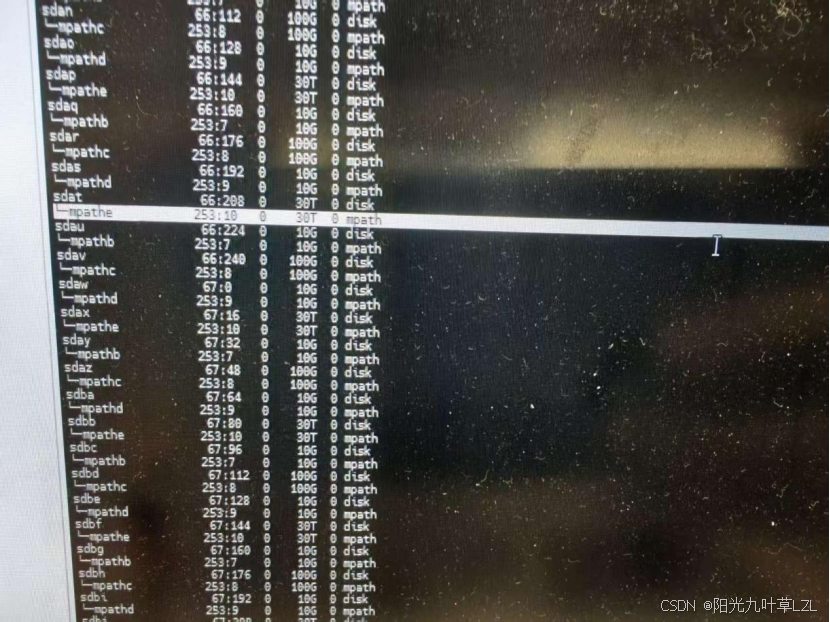
多路径mpathe正好对应的是30T的共享存储数据盘。

我们使用iostat命令监控dm-10的性能表现: %util 100%负载的情况下,每秒读写都在0左右,会过一段时间频繁的出现,这是闲时的表现。

在高负载的情况下,读100多 MB/s,写5 MB/s左右,%util负载已经到达60%,这是一块NVME SSD的盘。
后续咨询了麒麟原厂老师,才知道在多路径存储设备环境下,%util不能作为负载满的指标,学到老活到老压。
6、SQL执行情况
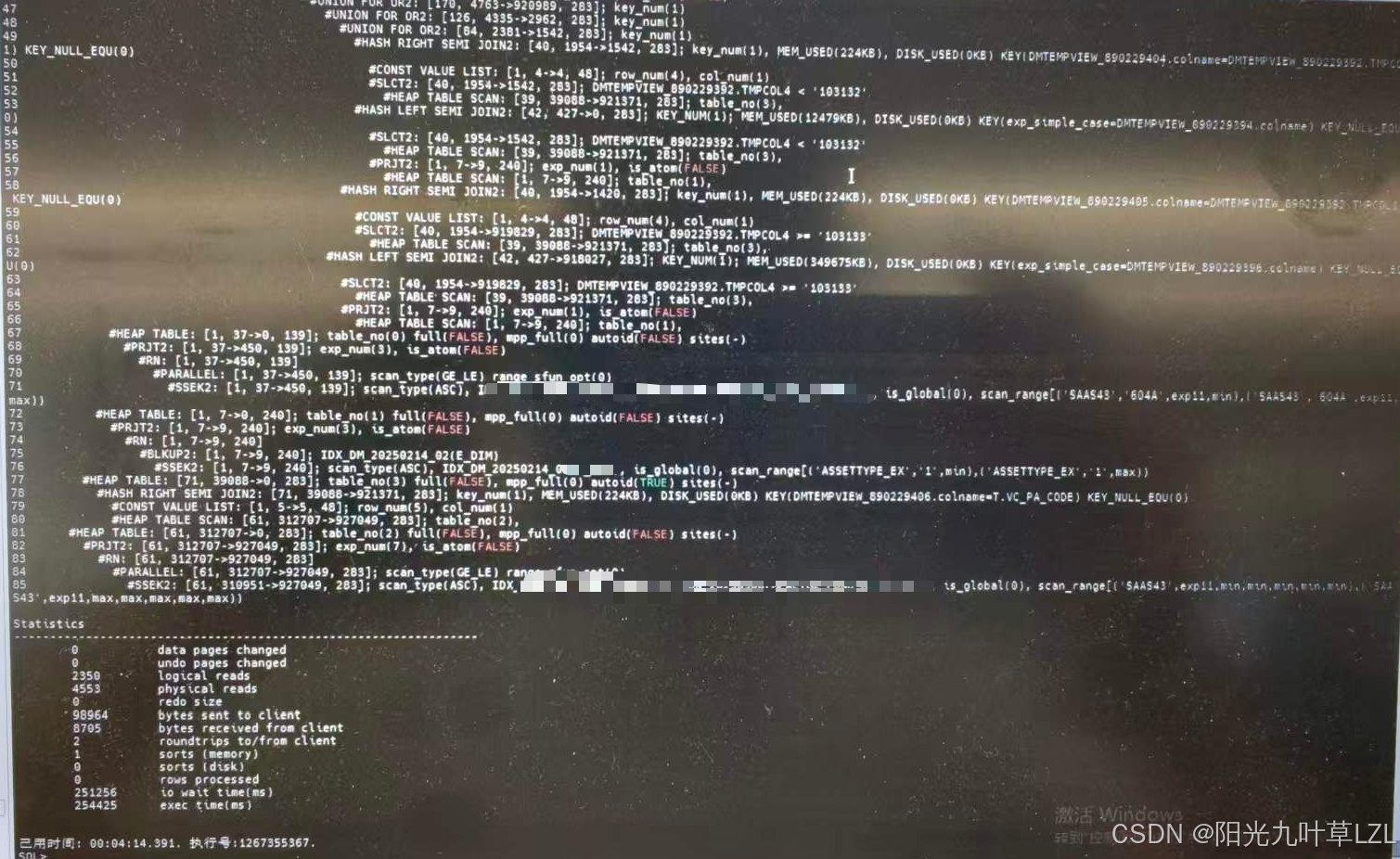
我们观察业务老师说的慢指标,autotrace显示SQL执行需254s,IO WAIT TIME 251s,物理读4553个数据块,说明SQL耗时主要集中在物理读的IO等待上,因为逻辑读是在内存中操作,不存在磁盘IO等待,这也能解释为什么业务老师表示某些指标跑的很慢,后续无论是应用再跑相同指标,还是数据库管理工具中再执行多次都能秒出的现象。也进一步加深了性能点都消耗在磁盘上的考虑。
7、堆栈分析
我们通过pstack打印dmserver进程的堆栈信息。
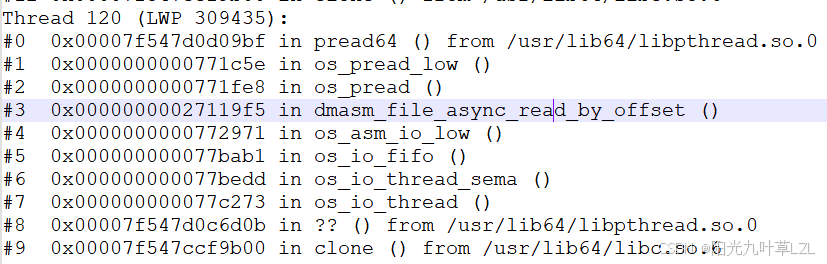
os_io_thread函数是达梦数据页落盘线程调用的,最上层的栈针指向系统调用pread64,说明读数据页用的是此方法。写一个数据页的方法是pwrite64,堆栈就不放上去了。
8、perf trace追踪系统调用
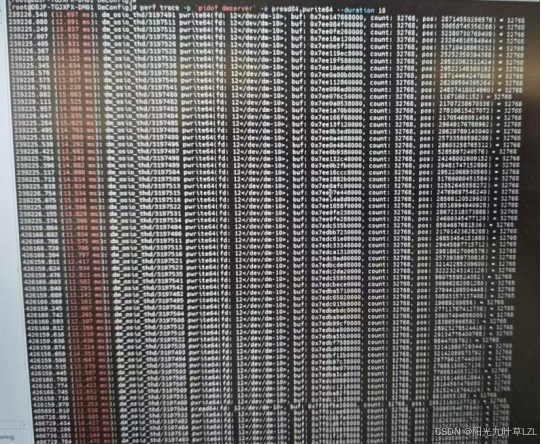
我们用perf trace来观察系统调用pread64、pwrite64的耗时情况。
从监控情况分析来看,读取一个32K数据页需10ms左右,看过我之前在主备环境分析读写页超时问题的小伙伴都知道,我们是实打实捕获到3s的,strace和perf不一样,第一反应是否定的,都是监控系统调用不可能差距这么大。
从之前的SQL我们知道IO WAIT TIME 251s,物理读4553个数据块,4553 * 10 ≈ 45s,251s - 45s还有很大空间,这是耗在哪里了呢,perf肯定不会错,那就是主备和DSC在读写数据页这一块的耗时计算的代码逻辑不一样了,我咨询了达梦原厂老师,提单子帮忙咨询了达梦内核研发老师,得到的反馈是不同架构之间,读写数据页耗时计算的代码逻辑是不一样的,这肯定了我们的猜想。
我们邀请两位达梦老师来帮助我们进一步分析耗时。
9、DCR_EP_SHM_SIZE参数调整
达梦原厂老师对于并发卡顿时打印了堆栈进行分析。
分析情况我做了笔记,大家可以参考一下:
达梦数据库-堆栈看问题-01-asmapi_asm_extent_load-CSDN博客
根据实际情况我们调整了DCR_EP_SHM_SIZE参数重启集群,数据库填充完ASM进程的共享内存中多层HASH MAP之后,数据库中不在提示读写页的超时告警,性能上也满足了业务老师的需求,但还不是我们高兴的时候,之前用perf trace来观察系统调用pread64、pwrite64的耗时情况,一次就需要10ms,4000个页,32K的块,125M的数据就需要40s,这也不正常,我们需要进一步分析底层调用的耗时情况。
10、blktrace排查
听取领导建议可以使用blktrace排查试试,我们邀请麒麟原厂老师帮忙用blktrace进行了进一步的验证。
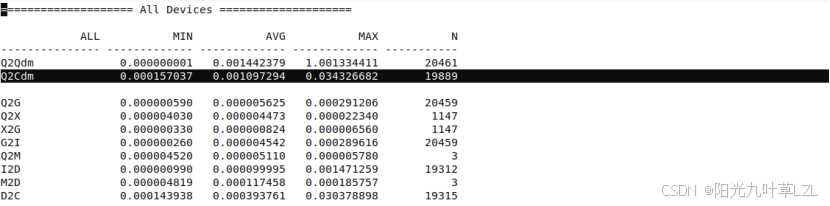
通过blktrace抓取数据,D2C即硬件到驱动层的平均耗时为0.39ms,但是存在MAX最慢出现过30ms的现象。
细化可以看到++++MAX的最大耗时出现在D2C的位置++++,已知D2C是块设备层将I/O请求发送给底层驱动,说明最高30ms的耗时主要在硬件完成I/O任务。
|---------|--------|-----------------------------------|
| D2C | 设备服务时间 | 请求下发到设备 → 设备完成I/O的时间(硬件真实耗时 ) |
这侧面说明慢操作原因可能是底层存储的基础性能带来的影响,这里就由专业的存储老师来进行进一步排查,术业有专攻。
11、备机任务积压
我们可以参考之前的笔记:达梦数据库-学习-56-备机任务积压分析-CSDN博客
当然除了上面的一系列影响,备机任务积压也是一个性能点,但这并不是影响性能的关键点,达梦的调整可以适当缓解症状。
四、总结
达梦数据库DSC集群上线后我们发现了各种各样的问题,有数据库参数配置、存储硬件性能、备机任务积压等情况发生,上线前还是要进行充分的验证,避免上线后影响业务、影响用户体验。
万事开头难,我们一起继续前进和探索。