EACL 2026 (CCF B类 / 顶级国际NLP会议)
链接:https://aclanthology.org/2026.eacl-long.253.pdf
github:https://github.com/nsivaku/dart

目录
摘要
专业视觉工具可为大语言模型或视觉语言模型补充专家知识(如定位、空间推理、医学知识等),但确定要调用哪些工具以及何时调用它们颇具挑战。我们提出了DART,这是一个多智能体框架,它利用多个辩论型视觉智能体之间的分歧来识别有用的视觉工具(如目标检测、光学字符识别、空间推理等),这些工具能够解决智能体之间的分歧。这些工具通过引入新信息,并提供与工具对齐的一致性评分来凸显与专家工具观点一致的智能体,从而促成富有成效的多智能体讨论。我们借助聚合智能体,通过提供智能体输出结果和工具信息来选出最佳答案。我们在四个不同的基准测试上对DART进行了验证,结果表明,我们的方法相较于多智能体辩论框架以及单智能体工具调用框架均有改进,在A-OKVQA和MMMU数据集上分别比次优基线(带评判模型的多智能体辩论框架)提升了3.4%和2.4%。我们还发现,DART能很好地适配应用领域中的新工具,在M3D医疗数据集上,相较于其他性能优异的工具调用、单智能体和多智能体基线,性能提升了1.3%。此外,我们通过计算各轮次的文本重叠度,凸显出DART相较于现有多智能体方法拥有更丰富的讨论内容。最后,我们分析了工具调用的分布情况,发现各类工具的使用呈现出多样化特征。
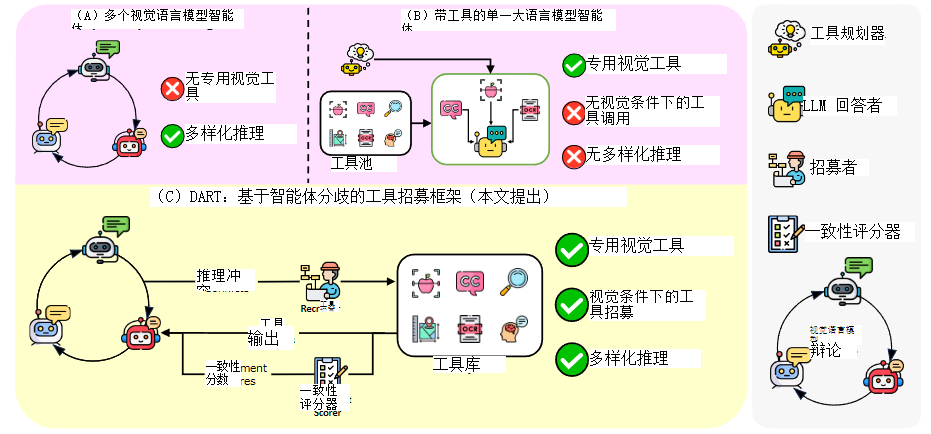
1.Introduction(引言)
1.1.研究背景
- 多模态模型(VLMs)强于通用推理,但细粒度感知弱 (定位、OCR、空间、属性),常落后于专业模型。
- 现有范式三类:
- 单智能体工具调用 (ViperGPT、Chameleon):LLM 自上而下规划工具,不看图像、不利用分歧、推理单一。
- 多智能体辩论 :文本有效,多模态易循环、缺新信息、分歧难消解。
- 专家模型单独使用:感知强、推理弱、难以整合。
1.2.研究动机
- 痛点:多模态辩论缺信息、工具调用缺图像反馈、两者割裂。
- 核心洞察:分歧本身就是选工具的信号 → 哪里吵,哪里用专家工具。
1.3.核心贡献
- DART = 多智能体辩论 + 分歧驱动工具调用 + 工具对齐打分。
- 三大创新:
- 分歧触发式工具调用:不预规划,辩论后用工具解决真实分歧。
- 工具对齐可信度:与专家输出越一致,智能体越可信。
- 闭环流程:生成→分歧→工具→打分→讨论→聚合。
1.4.论文目标
- 统一 VLMs、多智能体、专家工具,提升多模态 VQA 的感知精度 + 推理质量 + 讨论多样性。
2.Method(方法)
整体流程:5 步闭环,输入(图像 + 问题)→输出(最终答案)
2.1.初始答案生成
- 多个不同 VLM(如 QwenVL、MiniCPM-o、Ovis2)独立生成:答案、推理、自报置信度。
- 输出分组:把相同答案合并,标注答案、支持人数、推理。
给定:
- 图像 I
- 问题 Q
- n 个回答智能体:
每个
独立生成:
- 候选答案:
- 推理链:
- 自报告置信度:
输出分组
把相同答案合并,形成结构化分组:
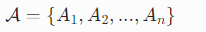
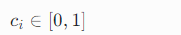
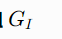
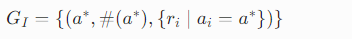

2.2.分歧驱动工具调用
哪里吵、哪里用工具:用分歧精准触发专家工具,而不是预规划。
- 分歧检测 :Recruiter(LLM)分析分组结果,定位感知 / 结论冲突点。
- 工具选择 :Recruiter 按分歧选最小必要工具集,生成参数。
- 工具池:Grounder、Object Detection、OCR、Spatial、Caption、Attribute、Reasoning。
- 工具执行 :专家模型输出;非文本结果(框、坐标)转自然语言供 LLM 理解。
招募智能体 Recruiter(LLM)输入
****,识别冲突点:
- 感知冲突:物体是否存在、颜色、位置、文字
- 结论冲突:答案不同
- 推理冲突:逻辑链不一致

2.3.工具对齐打分
- 假设:专家工具更准,对齐专家 = 更可信。
- 打分器(LLM):每个智能体输出 vs 每个工具输出 → 0/1 对齐分。
- 智能体最终分数:所有工具对齐分均值 Sᵢ ∈ 0,1,作为可信度权重。
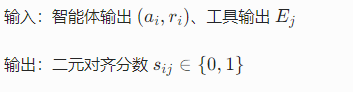

2.4.多智能体讨论
- 输入:分组答案、工具输出、对齐分数。
- 规则:专家输出 > 其他智能体观点 ;结合自报置信度 + 对齐分数更新答案与推理。
- 输出:更新分组、更新对齐分数。



2.5.结果聚合
Aggregator(独立 VLM)综合所有智能体答案、推理、工具输出、对齐分数 ,用 CoT 选出最优最终答案。

举个例子说明:
一、场景设定(例子背景)
图像 :一张停车收费表照片问题:停车收费员周末休息吗?(即工作日:周一--周五)
三个回答智能体(Q/M/O)
Q(QwenVL):周末休息,推理:收费表写 M--F
M(MiniCPM-o):周末不休息,推理:只看到 "9am--6pm"
O(Ovis2):周末休息,推理:收费表写 Mon--Fri
初始分组 G_I
答案:周末休息 → Q、O(2人) 答案:周末不休息 → M(1人)分歧点:收费表上有没有写 M--F/Mon--Fri
二、步骤 2:分歧驱动工具调用(选 OCR 工具)
** 招募智能体(Recruiter)** 识别分歧:文字识别不一致调用 OCR 工具,输出专家结果 E(文本):
E(OCR):METER ENFORCEMENT 9am--6pm M--F工具输出集合:E = {E_ocr},数量 |E| = 1
三、步骤 3:工具对齐打分(公式直接用)
1)逐对二元打分 s_ij ∈ {0,1}
打分器对比:智能体输出 vs E_ocr
Q:"周末休息(M--F)" → 和 E 一致 → s_Q=1
M:"周末不休息" → 和 E 矛盾 → s_M=0
O:"周末休息(Mon--Fri)" → 和 E 一致 → s_O=1
2)计算对齐分数 S_i(核心公式)
结果含义
Q、O:1.0,完全对齐专家,可信度最高
M:0.0,完全冲突,可信度最低
四、步骤 4:多智能体讨论(用 S_i 修正答案)
输入
旧分组 G_I、工具输出 E、对齐分数 S=1.0,0.0,1.0
规则:专家 E 优先级最高;结合 S_i + 自置信 c_i 修正
1)各智能体修正(带公式影响)
智能体 Q(S=1.0,原置信 70%)
对齐分满分 → 采信 E,维持原答案
新推理:OCR 确认 M--F,周末休息
新置信:0.9(S=1.0 提升)
智能体 M(S=0.0,原置信 85%)
对齐分 0 → 否定自己,改答案为周末休息
新推理:OCR 显示 M--F,推翻原判断
新置信:0.6(S=0.0 拉低)
智能体 O(S=1.0,原置信 90%)
对齐分满分 → 采信 E,维持原答案
新推理:OCR 验证 Mon--Fri,周末休息
新置信:0.95(S=1.0 提升)
2)讨论后分组 G_F
答案:周末休息 → Q、M、O(3人,全一致)3)重算对齐分数 S_F(公式复用)
还是 E={E_ocr},s 均为 1:
五、步骤 5:聚合(最终答案)
聚合器综合 G_F、E、S_F,输出:
最终答案:周末休息
置信:100%
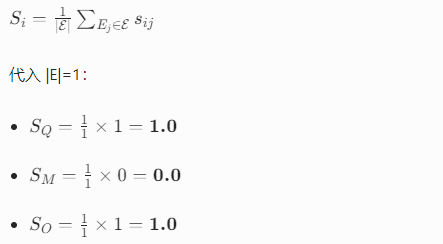
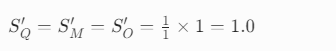
3.Experiments(实验)
3.1.数据集
数据集(4 个,通用 + 医疗)
- A-OKVQA:常识 + 世界知识 VQA。
- MMMU:多学科多模态理解。
- NaturalBench:对抗 VQA(人类易、VLMs 难)。
- M3D-VQA:3D 医疗影像,测领域适配。
- 回答智能体:Qwen2.5-VL、MiniCPM-o、Ovis2、LLaVA-1.6。
- 专家工具:GroundingDINO、YOLOv11、SpaceLLaVA、OCR-Qwen、InternVL2.5、MedGemma(医疗)。
- 辅助智能体:Qwen2.5(Recruiter/Scorer)、Ovis2(Aggregator)。
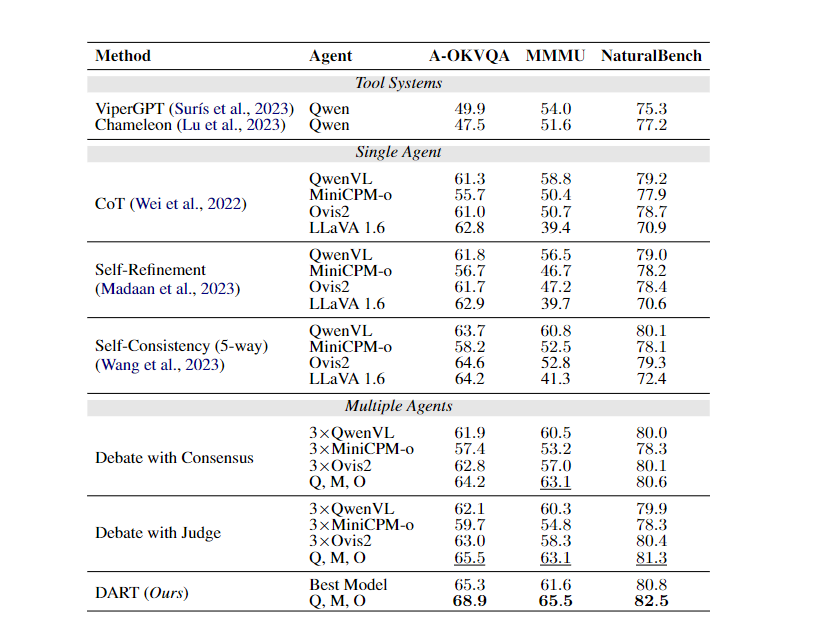
3.2.基线
- 工具系统:ViperGPT、Chameleon。
- 单智能体:CoT、Self-Refinement、Self-Consistency。
- 多智能体:共识辩论、裁判辩论。
4.提示词
4.1.初始答案生成
python
<问题>
1.用一个单词或短语回答问题,
2.然后为答案提供逐步推理。
3.最后,提供0-1的置信度评分
你的答案(0表示完全不自信,1表示完全自信):
您必须以以下格式输出:
答:[答]
推理:[推理]
信心:[信心]4.2.分歧解决智能体
python
这是初始提示:<完整的初始答案生成提示>
仔细查看其他智能体针对所提供问题的以下解决方案。
现在,分析一下双方之间发生了什么分歧不同的智能体。
<分组解决方案>
你可以召集不同的专家,每个专家都有自己的专业能力。根据你观察到的分歧,挑选出一组最有能力解决所有分歧的专家(可能只是其中之一)。以下是所有专家、他们的意见和他们的能力/用法:
"空间"(输入:list。混淆了空间关系的对象)-对对象之间的空间关系有完美的理解。当代理使用此功能时
不确定项目在场景中的位置。
"ocr"(输入:无)-可以正确读取图像中的所有文本。当代理具有不同的对图像中文本内容的看法。"grounder"(输入:list.objects)-如果是图像,它将找到任何对象,否则它将不归还任何东西。当代理对图像中的内容不一致时,请使用此选项。
"检测器"(输入:无)-将提供对象列表图像、计数和边界框。仅当代理在图像中的对象计数不同时才使用此选项。
"字幕"(输入:列表。你想要标题的对象)-可以详细描述图像中与问题相关的内容。当代理使用此功能时
可能需要更好地了解一般场景或特定对象的描述。
"attribute"(输入:list.objects你想要属性)-将给出图像中对象的不同特征的信息,包括颜色、属性、类别等。当代理对以下内容感到困惑时使用此选项相关对象的特征,需要许多表面级特征。
"推理"(输入:list。你想要推理的对象)-有更好的世界关于图像中可能发生的事情的知识和高级推理能力。
当智能体在其输入中感到困惑或冲突时,请使用此选项-关于场景的引用。这本质上是一个元推理代理,当模型基于相同的假设得出不同的结论时,它会进行干预。输出您需要解决分歧的专家来回答原始问题:。这应该是一个JSON,格式如下。
你可以根据需要,呼叫更多或更少的专家:
{
"专家":["grounder"、"attribute"、"ocr"],
"输入":{
"接地器":{
"不同意":"特工1提到有一只猫,但特工2说没有猫,而是说它是一只狗。",
"理由":"理由将有助于解决关于图像中猫或狗存在的分歧。",
"论点":["猫","狗"]
},
"属性":{
"不同意":"特工1说这朵花是红色的,特工2说是橙色的,特工3没有具体提到这朵花。
关于汽车的细节也存在混淆。",
"理由":"属性专家将帮助解决关于花朵颜色的分歧,并提供有关汽车的详细信息。",
"论点":["花"、"车"]
},
"ocr":{
"分歧":"智能体在图像中看到的文本上存在冲突。",
"理由":"OCR专家将看到图像中的文本并解决分歧。",
"论点":[]
}
}
}
现在,以给定的格式为前面的智能体解决方案和上面提供的问题提供专家输出。不要在分歧上显得多余
除非专家正在添加更好地解决分歧的新信息。除非绝对必要,否则不要添加专家。
提醒一下,问题是:<question>4.3.工具对齐智能体
python
你是一名协调智能体人。这意味着您可以确定两个不同的输出是未对齐(0)还是对齐(1)。专家的成果对多个不同智能体之间的分歧做出了回应。
您的任务是确定专家输出是否与单个智能体的输出对齐的原因。然后,如果智能体输出与专家的输出,如果对齐,则为1。
输出格式:
{
"推理":"您对智能体输出与专家输出对齐的推理。",
"alignment":"如果智能体输出与专家输出不一致,则为0,如果已对齐,则为1。"
}
分歧观点:<分歧>
专家输出:<Expert_Output>
智能体输出:<Agent_Output>4.4.讨论智能体
python
仔细审查以下来自其他智能体的解决方案作为附加信息,并提供你自己的答案和逐步推理过程问题。然后,请给出你对新答案的信心程度。
明确表明你同意或不同意哪个观点,并说明原因。
<grouped_solutions>
以下是专家对图像的信息。除非你确实发现了错误,否则应将此处提供的任何信息视为事实
附上专家信息(并确保注明这一点)。
<tool_outputs>
按照以下格式输出你的响应:
推理:[根据其他智能体的回答,对原始问题的答案进行推理]
答案:[新答案]
置信度:[confidence]
一些示例输出:
推理:我同意智能体1的推理,认为答案是A,因为它与医学专家对CT扫描的分析相一致。医学专家
已确认问题中描述的情况与图像中的发现一致。
答案:选项A
置信度:0.65
推理:我不同意智能体2的推理,即答案是B。医学专家的分析表明,这种情况更可能是A,因为
与问题中描述的症状和图像中的发现相匹配。
答案:选项A
置信度:0.95
推理:我同意智能体1和3的推理,认为答案是C。医学专家的分析支持这一结论,因为它与
图像中的发现和问题中描述的症状。
答案:选项C
置信度:0.30
无论如何,你必须遵循提供的格式。这条规则是不可违反的。4.5.聚合智能体
python
你是一个聚合器模型,将获得一张图片、一个问题以及一组答案选项。
你的任务是为问题选择最佳最终答案。
您还将获得各种信息来源,以帮助您做出明智的决策。每个答案都是由不同的智能体生成的,这些智能体会提供它们给出答案的理由。
您还将获得来自专家模型的工具输出,这些输出与问题直接相关,并用于解决回答智能体之间的分歧。
如果这些答案与工具提供的信息相矛盾,请随时参考这些专家工具的输出。
问题:<question>
以下是不同的智能体答案:<grouped_output>
以下是工具输出:<tool_outputs>
现在,根据所提供的信息,请逐步阐述您如何选择最佳、最正确的答案。
然后,请给出您对所选答案的信心程度。
输出格式如下:
推理:[推理]
答案:[答案]
置信度:[置信度]