概述
随着大语言模型(LLM)能力的飞速跃升,AI Agent(智能体)已成为企业智能化转型的核心基础设施。相比于简单的问答交互,Agent 能够自主规划任务、调用多样化工具、感知环境变化并持续优化执行策略,真正实现"说一句需求,AI 全程搞定"的业务自动化体验。
在 Java 企业级生态中引入 Agent 架构,不仅是技术选型上的顺势而为,更是工程可靠性的必然选择。Spring Boot 的依赖注入与生命周期管理、成熟的并发编程模型、丰富的生态系统(JDBC、HTTP Client、消息队列),以及稳定可靠的生产级运行时,都为构建企业级 Agent 系统提供了坚实基座。
本文从 Agent 的核心概念出发,深入剖析其工作原理,完整讲解 Java 技术栈下的 Agent 工作流设计与实现,涵盖任务规划、工具调用、状态管理、多步骤编排等关键环节,并通过一个企业级实战案例------智能数据报表分析 Agent------完整呈现从设计到落地的全流程。通过本文,你将掌握构建生产级 Java Agent 系统的核心能力。
一、Agent 核心概念解析
1.1 什么是 Agent
Agent(智能体)是一种能够自主感知环境、做出决策并执行动作的智能系统。如果用一句话概括 Agent 与普通程序的区别,那就是:普通程序执行预定义的固定逻辑,Agent 则根据目标自行决定下一步做什么 。
一个完整的 Agent 通常由以下四大组件构成:
感知(Perception) ------Agent 通过输入理解当前状态。对于基于 LLM 的软件 Agent 而言,"感知"就是将用户的自然语言指令、当前系统状态、外部数据反馈等信息转化为 Agent 能够理解的内部表示。这一步通常依赖 LLM 的语义理解能力来完成意图识别(Intent Detection)和实体抽取(Entity Extraction)。
规划(Planning) ------这是 Agent 最核心的能力。面对一个复杂任务,Agent 需要将其分解为若干子任务,确定执行顺序,处理子任务之间的依赖关系,并根据执行结果动态调整后续计划。常见的规划策略包括 Chain-of-Thought(CoT,逐步思考)、ReAct(Reason + Act,交替推理与行动)等。
行动(Action) ------Agent 通过调用外部工具来完成任务。工具(Tool)是 Agent 与外部世界交互的桥梁,可以是简单的计算器、搜索引擎,也可以是复杂的 ERP 系统、数据库或第三方 API。一个 Agent 的能力边界很大程度上由其可调用的工具集决定。
反馈(Feedback) ------行动产生结果后,Agent 需要评估结果是否达到目标。如果任务失败或部分完成,Agent 会分析原因并调整计划,形成"规划---行动---评估---再规划"的循环,直到任务完成或明确无法完成。
1.2 Agent 与传统 RPA 的本质区别
很多人在初次接触 Agent 时容易将其与 RPA(Robotic Process Automation,机器人流程自动化)混为一谈。两者虽然都追求业务流程的自动化,但在本质上有着显著差异。
RPA 本质上是一种"像素级录制回放"技术------它忠实地复现人类在图形界面上的每一次点击和输入。RPA 的优点是实施周期短、对现有系统零改造,缺点则是极度脆弱------一旦界面布局变化,RPA 流程就会失效,且无法处理任何未曾"录制"过的异常情况。
Agent 则截然不同。Agent 不关心界面细节,它通过 API 或自然语言接口与系统交互,以业务语义为单位执行操作。Agent 能够理解"查询本月销售额排名前五的客户"这样的高层语义指令,并自主拆解为调用 CRM 系统、SQL 查询、数据排序、格式化输出等一系列操作。Agent 具备推理能力,能够处理未曾预设过的分支情况,具备真正的业务理解力。
从技术架构上看,RPA 是面向过程的、硬编码的;Agent 则是面向目标的、自驱动的。这决定了 Agent 能够处理更复杂、更动态、更长尾的业务场景。
1.3 Agent 的技术架构分层
从工程实现角度,Agent 系统通常分为以下几层:
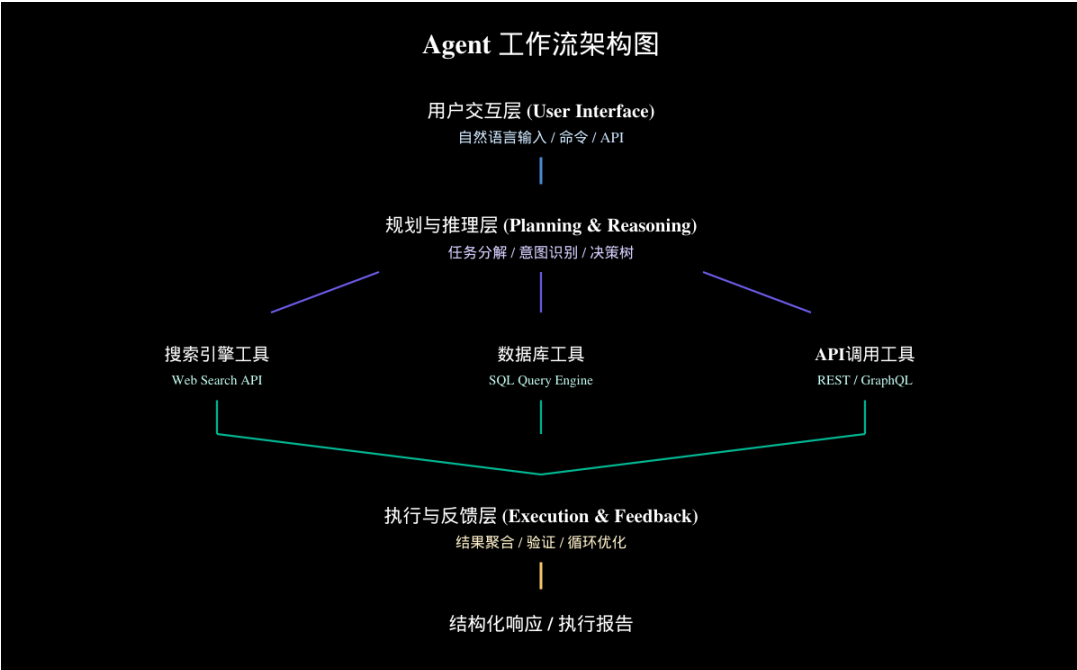
用户交互层(User Interface Layer) 负责接收用户请求、呈现执行结果。这一层可以是 REST API、Web 界面,甚至是钉钉/飞书机器人。Spring Boot 的 @RestController 是这一层的天然载体。
任务规划层(Planning Layer) 是 Agent 的大脑,基于 LLM 的推理能力完成意图识别、任务分解和执行规划。在 Java 实现中,这一层通常由一个专门的 AgentPlanner 组件封装,它将 LLM 的自然语言推理能力转化为可执行的任务图(Task Graph)。
工具层(Tool Layer) 管理所有可调用的外部工具。每个工具被抽象为一个 Tool 接口的实现,通过 ToolRegistry 统一注册和管理。工具执行由 ToolExecutor 统一调度,支持超时控制、重试策略和结果校验。
执行层(Execution Layer) 负责具体任务步骤的执行,包括并发执行、顺序编排、结果聚合等。对于 Java 而言,CompletableFuture 和 Spring 的 @Async 是这一层的核心支撑。
记忆层(Memory Layer) 存储 Agent 的短期记忆(当前任务上下文)和长期记忆(历史经验知识)。短期记忆通常使用堆内数据结构实现;长期记忆则可借助向量数据库(如 Milvus、Pinecone)或传统知识图谱实现。
二、Java Agent 工作流设计
2.1 整体架构设计
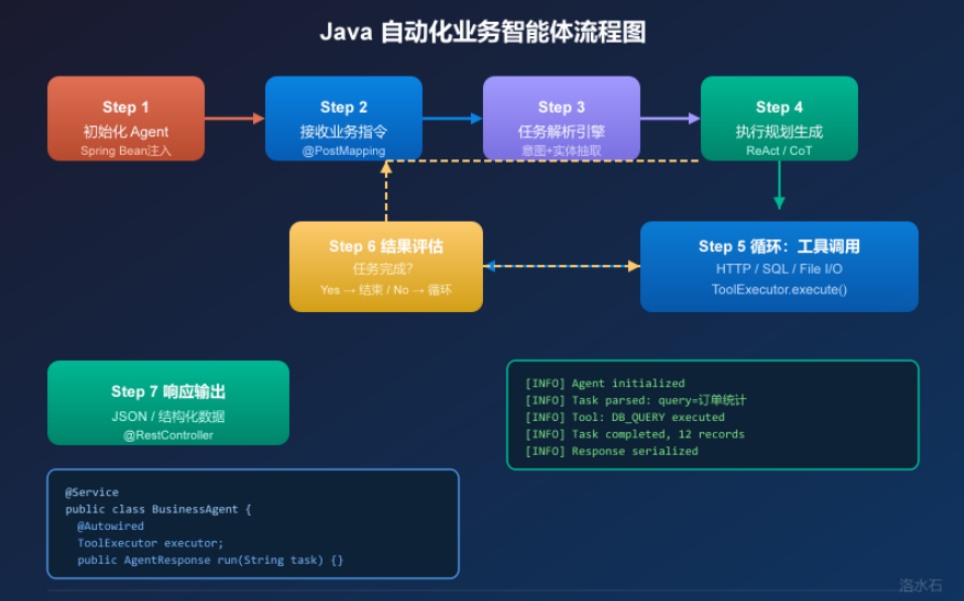
一个生产级的 Java Agent 系统,其架构设计需要兼顾灵活性、可扩展性和工程可靠性。以下是推荐的整体架构:
``_INLINE
用户请求 → REST API (Spring Boot)
↓
Agent Core (核心调度器)
↓
Task Planner (任务规划器,调用 LLM)
↓
Task Graph (有向无环任务图)
↓
Tool Registry (工具注册中心)
↓
Tool Executor (工具执行器,并发/顺序执行)
↓
Result Aggregator (结果聚合器)
↓
Response Serializer (响应序列化)
↓
返回给用户
__`_INLINE
核心设计原则包括:
单一职责原则 ------每个组件只负责一件事。Planner 负责规划,Executor 负责执行,Registry 负责管理。组件之间通过明确定义的接口通信,便于独立测试和替换。
依赖倒置原则 ------核心 Agent 类不直接依赖具体的工具实现,而是通过 _Tool__INLINE 接口与工具交互。这使得新增或替换工具时无需修改核心逻辑,符合开闭原则。
可观测性原则 ------每个任务步骤的执行状态、执行时间、返回结果都应被完整记录。引入 SLF4J + Logback 的日志体系,并考虑集成 Micrometer + Prometheus 实现指标监控。
2.2 核心接口定义
在 Java 中,Agent 的核心接口设计如下:
__`__INLINE_java
// 工具接口,所有外部能力都实现此接口
public interface Tool {
String name(); // 工具唯一标识
String description(); // 工具功能描述,用于 LLM 理解何时调用
ToolSchema inputSchema(); // 输入参数模式(JSON Schema)
ToolResult execute(Map<String, Object> params); // 执行工具
}
// 工具执行结果
public record ToolResult(
boolean success,
String output,
String error,
Map<String, Object> metadata
) {}
// 任务节点
public record Task(
String id,
String description,
Tool tool,
Map<String, Object> params,
TaskStatus status,
Object result
) {}
// Agent 核心接口
public interface BusinessAgent {
AgentResponse execute(AgentRequest request);
void registerTool(Tool tool);
void deregisterTool(String toolName);
List<Tool> getRegisteredTools();
}
__`_INLINE
这套接口设计的核心理念是工具作为一等公民 。每个工具不仅有执行逻辑,还自带元数据描述(名称、描述、输入模式),这些元数据会被传递给 LLM,使其能够准确判断在何种场景下调用哪个工具。
2.3 任务规划器的实现
任务规划器(Task Planner)是 Agent 系统的"智力中枢"。它的职责是将用户的高层语义指令转化为可执行的任务图。
规划过程通常分为两步:
第一步:意图识别 。收到用户请求后,首先判断用户的真实意图是简单问答、单步任务还是复杂多步骤任务。对于简单任务(如"今天天气如何"),无需复杂的任务分解;对于复杂任务(如"帮我分析本季度销售数据,生成对比报告"),则需要进一步拆解。
第二步:任务分解 。使用 ReAct 或 CoT 模式,将复杂任务拆解为有序的子任务序列。每个子任务明确其依赖的前置任务、使用的工具和期望的输出格式。
以下是一个基于 ReAct 模式的 Planner 实现框架:
__`__INLINE_java
@Service
@Slf4j
public class ReActPlanner implements TaskPlanner {
@Autowired
private LlmClient llmClient; // LLM 调用客户端
@Autowired
private ToolRegistry toolRegistry;
@Override
public TaskGraph plan(String userInstruction, List<Tool> availableTools) {
// 构建 Prompt,包含工具描述和用户指令
String prompt = buildReActPrompt(userInstruction, availableTools);
// 调用 LLM 获取推理过程
LlmResponse response = llmClient.complete(prompt);
// 解析 LLM 输出,构建任务图
return parseToTaskGraph(response.getContent());
}
private String buildReActPrompt(String instruction, List<Tool> tools) {
StringBuilder sb = new StringBuilder();
sb.append("你是一个专业的任务规划助手。面对用户指令,你需要按照以下格式逐步推理:\n\n");
sb.append("可用工具:\n");
for (Tool tool : tools) {
sb.append(String.format("- %s: %s (输入: %s)\n",
tool.name(), tool.description(), tool.inputSchema()));
}
sb.append("\n用户指令:").append(instruction).append("\n\n");
sb.append("请按以下格式输出任务规划:\n");
sb.append("思考1: ...\n");
sb.append("动作1: 工具名称\n");
sb.append("观察1: 工具返回结果\n");
sb.append("思考2: ...\n");
sb.append("动作2: 工具名称\n");
sb.append("...");
return sb.toString();
}
}
__`_INLINE
在实际生产中,规划器的 Prompt 工程(Prompt Engineering)是决定 Agent 效果的关键环节。好的 Prompt 需要清晰地描述任务目标、可用的工具能力、输出格式要求,并适当给出示例(Few-shot Learning)来引导 LLM 给出更准确的规划。
2.4 工具注册与执行机制
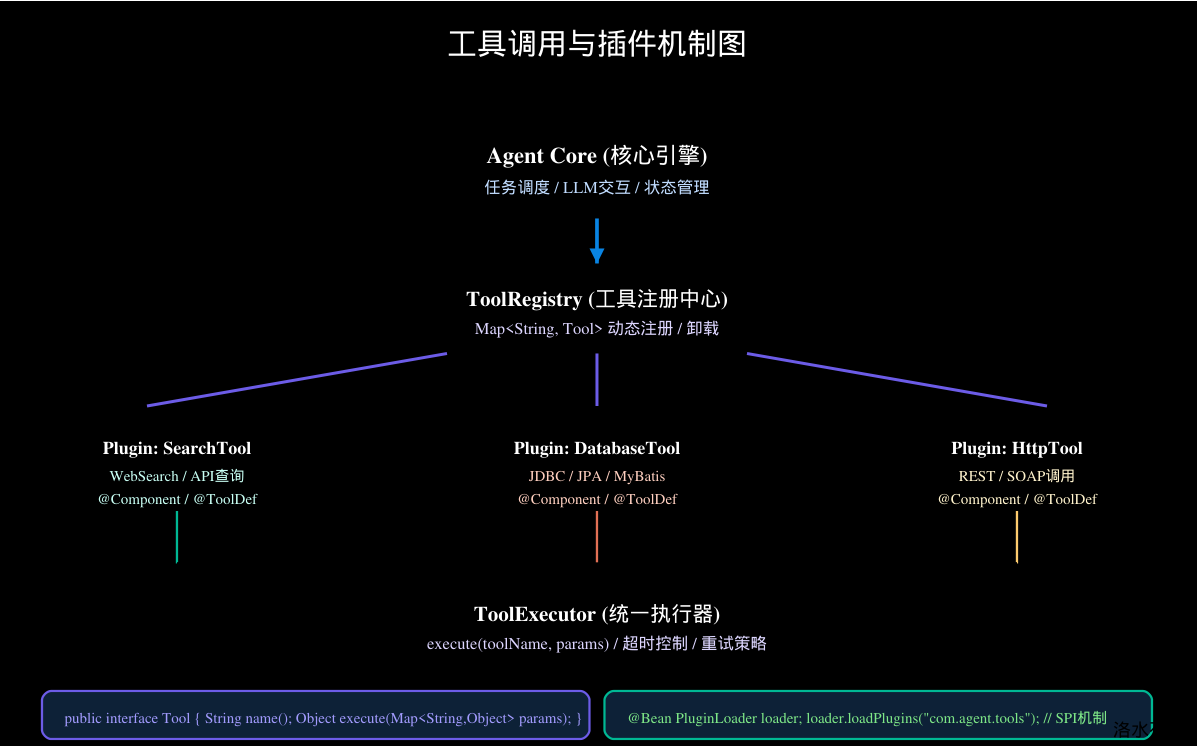
工具注册中心(Tool Registry)是 Agent 系统的"瑞士军刀"------它管理着所有可用工具的元数据,并提供查找能力供 Planner 使用。
__`__INLINE_java
@Service
@Slf4j
public class ToolRegistryImpl implements ToolRegistry {
private final Map<String, Tool> tools = new ConcurrentHashMap<>();
@Override
public void register(Tool tool) {
if (tools.containsKey(tool.name())) {
throw new IllegalStateException("Tool already registered: " + tool.name());
}
log.info("Registering tool: {}", tool.name());
tools.put(tool.name(), tool);
}
@Override
public void deregister(String name) {
log.info("Deregistering tool: {}", name);
tools.remove(name);
}
@Override
public Optional<Tool> get(String name) {
return Optional.ofNullable(tools.get(name));
}
@Override
public List<Tool> getAll() {
return new ArrayList<>(tools.values());
}
@Override
public ToolResult execute(String toolName, Map<String, Object> params) {
Tool tool = tools.get(toolName);
if (tool == null) {
return ToolResult.failure("Tool not found: " + toolName, Map.of());
}
try {
long start = System.currentTimeMillis();
ToolResult result = tool.execute(params);
long duration = System.currentTimeMillis() - start;
log.info("Tool {} executed in {}ms, success: {}", toolName, duration, result.success());
return result.withMetadata("duration_ms", duration);
} catch (Exception e) {
log.error("Tool {} execution failed", toolName, e);
return ToolResult.failure(e.getMessage(), Map.of());
}
}
}
__`_INLINE
工具执行器(Tool Executor)在 Registry 基础上增加了超时控制、重试策略和并发执行能力:
__`__INLINE_java
@Service
@Slf4j
public class ToolExecutorImpl implements ToolExecutor {
@Autowired
private ToolRegistry registry;
private final ExecutorService executor = Executors.newFixedThreadPool(10);
@Override
public ToolResult execute(String toolName, Map<String, Object> params, ExecuteOptions options) {
int maxRetries = options != null ? options.maxRetries() : 0;
int retryCount = 0;
Exception lastException = null;
while (retryCount <= maxRetries) {
try {
return executeWithTimeout(toolName, params, options);
} catch (Exception e) {
lastException = e;
retryCount++;
if (retryCount <= maxRetries) {
log.warn("Tool {} failed, retrying ({}/{})",
toolName, retryCount, maxRetries);
}
}
}
return ToolResult.failure(lastException.getMessage(), Map.of());
}
@Override
public List<ToolResult> executeParallel(List<ToolCall> calls) {
List<CompletableFuture<ToolResult>> futures = calls.stream()
.map(call -> CompletableFuture.supplyAsync(
() -> registry.execute(call.toolName(), call.params()),
executor))
.toList();
return futures.stream()
.map(CompletableFuture::join)
.toList();
}
}
__`_INLINE
三、多步骤任务编排
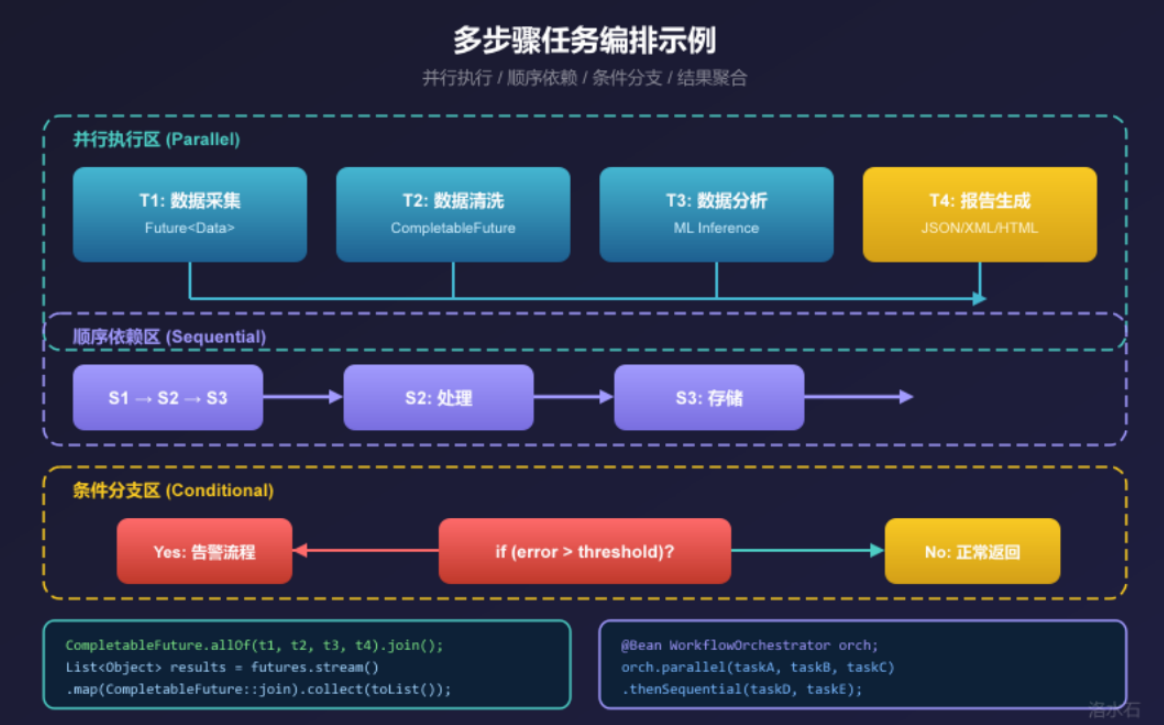
3.1 任务图的构建与执行
对于复杂业务场景,单步工具调用往往无法完成任务,需要将多个步骤按照一定逻辑编排执行。这就引出了"任务编排"(Task Orchestration)的概念。
任务编排的核心是任务图(Task Graph) ------一个有向无环图(DAG),节点是具体任务步骤,边代表执行顺序和依赖关系。每个节点包含任务描述、执行工具、输入参数,以及依赖于哪些前置节点的输出。
__`__INLINE_java
public record TaskGraph(
List<TaskNode> nodes,
List<TaskEdge> edges
) {
public List<TaskNode> getRoots() {
// 返回没有前置依赖的起始节点
Set<String> hasParent = edges.stream()
.map(TaskEdge::targetId)
.collect(Collectors.toSet());
return nodes.stream()
.filter(n -> !hasParent.contains(n.id()))
.toList();
}
public List<TaskNode> getDependents(String nodeId) {
// 返回直接依赖某节点的所有后续节点
return edges.stream()
.filter(e -> e.sourceId().equals(nodeId))
.map(e -> nodes.stream()
.filter(n -> n.id().equals(e.targetId()))
.findFirst().orElseThrow())
.toList();
}
}
__`_INLINE
任务图的执行引擎负责按照依赖关系调度任务。对于没有依赖的节点(根节点),可以并行执行;对于有依赖的节点,必须等待所有前置节点完成后才能开始。
3.2 并行执行与顺序依赖
实际业务中,我们经常需要混合使用并行和顺序两种编排模式。例如,数据采集步骤可以从多个数据源并行拉取数据(提速),但数据融合步骤必须等待所有采集任务完成(顺序依赖)。
__`__INLINE_java
@Service
@Slf4j
public class WorkflowOrchestrator {
@Autowired
private ToolExecutor toolExecutor;
/**
* 执行任务图,返回聚合结果
*/
public WorkflowResult execute(TaskGraph graph, Map<String, Object> context) {
Map<String, Object> results = new ConcurrentHashMap<>();
Map<String, TaskStatus> statuses = new ConcurrentHashMap<>();
AtomicInteger completedCount = new AtomicInteger(0);
// 找出所有根节点(无前置依赖的节点)
List<TaskNode> roots = graph.getRoots();
// 并行执行根节点
List<CompletableFuture<Void>> rootFutures = roots.stream()
.map(node -> CompletableFuture.runAsync(() -> {
executeNode(node, context, results, statuses);
completedCount.incrementAndGet();
// 触发后续节点检查
triggerDependents(node.id(), graph, context, results, statuses, completedCount);
}))
.toList();
// 等待所有任务完成
CompletableFuture.allOf(rootFutures.toArray(new CompletableFuture0)).join();
return new WorkflowResult(results, statuses);
}
private void triggerDependents(String nodeId, TaskGraph graph,
Map<String, Object> context, Map<String, Object> results,
Map<String, TaskStatus> statuses, AtomicInteger completedCount) {
List<TaskNode> dependents = graph.getDependents(nodeId);
for (TaskNode dependent : dependents) {
// 检查该节点的所有前置依赖是否都已完成
boolean allDependenciesMet = graph.getDependencies(dependent.id()).stream()
.allMatch(depId -> statuses.get(depId) == TaskStatus.COMPLETED);
if (allDependenciesMet) {
// 构建当前节点的输入参数(从前置节点结果中提取)
Map<String, Object> params = buildParams(dependent, results, context);
CompletableFuture.runAsync(() -> {
executeNode(dependent, params, results, statuses);
completedCount.incrementAndGet();
triggerDependents(dependent.id(), graph, context, results, statuses, completedCount);
});
}
}
}
private void executeNode(TaskNode node, Map<String, Object> params,
Map<String, Object> results, Map<String, TaskStatus> statuses) {
statuses.put(node.id(), TaskStatus.RUNNING);
try {
log.info("Executing node: {}", node.id());
ToolResult result = toolExecutor.execute(node.toolName(), params, node.options());
results.put(node.id(), result);
statuses.put(node.id(), result.success() ? TaskStatus.COMPLETED : TaskStatus.FAILED);
} catch (Exception e) {
log.error("Node {} execution failed", node.id(), e);
statuses.put(node.id(), TaskStatus.FAILED);
}
}
}
__`_INLINE
3.3 条件分支与循环控制
在真实业务场景中,往往需要根据中间结果动态决定后续分支。例如,数据库连接失败时走告警流程而非继续查询;订单金额超过限额时需要人工审批。这些条件分支逻辑可以通过在任务图中引入"条件节点"来实现。
__`__INLINE_java
public interface TaskCondition {
boolean evaluate(Map<String, Object> context, Map<String, Object> results);
}
// 示例:判断是否有错误
public class ErrorThresholdCondition implements TaskCondition {
private final double threshold;
@Override
public boolean evaluate(Map<String, Object> context, Map<String, Object> results) {
Object errorCount = results.get("error_count");
if (errorCount instanceof Number n) {
return n.doubleValue() > threshold;
}
return false;
}
}
__`_INLINE
循环控制则通过在 Planner 层面实现"重规划"来实现。当某个任务执行失败或结果不满足预期时,将结果反馈给 LLM 进行二次规划,形成 Agent-Executor 的反馈循环。这种机制使得 Agent 能够处理需要多轮交互的复杂业务流程。
四、企业级实战:智能数据报表分析 Agent
4.1 业务场景与需求分析
让我们以一个真实的企业级场景------智能数据报表分析 Agent ------来完整展示 Java Agent 系统的设计与实现全过程。
业务背景:某电商公司数据团队每天需要花费大量时间手动从多个数据源(订单系统、CRM 系统、财务系统)拉取数据,进行汇总计算,生成日报、周报、月报。报表格式相对固定,但数据来源多、计算逻辑复杂、且经常需要根据管理层的新需求临时调整。
我们的目标:构建一个智能数据分析 Agent,用户只需说"帮我生成上个月各区域销售冠军及其同比增长率",Agent 自动完成数据获取、计算、格式化全过程,并返回可直接使用的分析结论。
4.2 系统设计
整体架构分为以下几个模块:
数据采集层(Data Acquisition Layer) :通过 _DatabaseTool 连接数据仓库,通过 HttpTool 调用各业务系统的 RESTful API,通过 FileTool__INLINE 读取本地 CSV/Excel 文件。
数据处理层(Data Processing Layer) :对原始数据进行清洗、转换、聚合计算。使用 _CalculationTool 执行复杂数学运算,使用 GroupingTool__INLINE 执行多维度分组汇总。
分析推理层(Analysis Layer) :基于 LLM 的分析能力,对计算结果进行业务层面的解读,生成文字结论和洞察建议。
报告生成层(Reporting Layer) :将分析结果渲染为指定格式(JSON、HTML、Markdown),支持多种图表类型的嵌入。
4.3 核心工具实现
DatabaseTool 是整个系统的数据中枢。以下是一个生产级的实现:
__`__INLINE_java
@Component
@ToolDef(name = "db_query", description = "执行SQL查询从数据仓库获取数据",
inputSchema = """
{
"type": "object",
"properties": {
"sql": {"type": "string", "description": "待执行的SQL语句"},
"timeout": {"type": "integer", "description": "超时时间(秒)", "default": 30}
},
"required": "sql"
}
""")
@Slf4j
public class DatabaseTool implements Tool {
@Autowired
private DataSource dataSource; // 配置好的数据源
@Override
public String name() {
return "db_query";
}
@Override
public String description() {
return "从企业数据仓库执行SQL查询,返回结构化数据结果集";
}
@Override
public ToolSchema inputSchema() {
return ToolSchema.builder()
.addProperty("sql", "string", "待执行的SELECT查询语句")
.addProperty("timeout", "integer", "查询超时时间(秒)", false, 30)
.required("sql")
.build();
}
@Override
public ToolResult execute(Map<String, Object> params) {
String sql = (String) params.get("sql");
int timeout = params.get("timeout") != null
? ((Number) params.get("timeout")).intValue()
: 30;
// SQL 安全校验:仅允许 SELECT 语句
if (!isSelectStatement(sql)) {
return ToolResult.failure("Only SELECT statements are allowed", Map.of());
}
try (Connection conn = dataSource.getConnection();
Statement stmt = conn.createStatement()) {
stmt.setQueryTimeout(timeout);
long start = System.currentTimeMillis();
ResultSet rs = stmt.executeQuery(sql);
List<Map<String, Object>> rows = resultSetToList(rs);
long duration = System.currentTimeMillis() - start;
return ToolResult.success(
JSON.toJSONString(rows),
Map.of("row_count", rows.size(), "duration_ms", duration)
);
} catch (SQLException e) {
log.error("Database query failed", e);
return ToolResult.failure("Query failed: " + e.getMessage(),
Map.of("sql_state", e.getSQLState()));
}
}
private boolean isSelectStatement(String sql) {
String trimmed = sql.trim().toLowerCase();
return trimmed.startsWith("select") && !trimmed.contains("drop")
&& !trimmed.contains("delete") && !trimmed.contains("insert")
&& !trimmed.contains("update") && !trimmed.contains("truncate");
}
}
__`_INLINE
HttpTool 用于调用第三方业务系统的 API:
__`__INLINE_java
@Component
@ToolDef(name = "http_call", description = "发起HTTP请求调用外部REST API",
inputSchema = """
{
"type": "object",
"properties": {
"url": {"type": "string"},
"method": {"type": "string", "enum": "GET", "POST", "PUT", "DELETE"},
"headers": {"type": "object"},
"body": {"type": "object"}
},
"required": "url", "method"
}
""")
@Slf4j
public class HttpTool implements Tool {
private final RestTemplate restTemplate;
public HttpTool(RestTemplateBuilder builder) {
this.restTemplate = builder
.setConnectTimeout(Duration.ofSeconds(10))
.setReadTimeout(Duration.ofSeconds(30))
.build();
}
@Override
public String name() {
return "http_call";
}
@Override
public ToolResult execute(Map<String, Object> params) {
String url = (String) params.get("url");
String method = (String) params.get("method");
Map<String, Object> headers = params.get("headers") != null
? (Map<String, Object>) params.get("headers") : Map.of();
Object body = params.get("body");
HttpHeaders httpHeaders = new HttpHeaders();
headers.forEach((k, v) -> httpHeaders.set(k, String.valueOf(v)));
httpHeaders.setContentType(MediaType.APPLICATION_JSON);
HttpEntity<Object> entity = new HttpEntity<>(body, httpHeaders);
try {
long start = System.currentTimeMillis();
ResponseEntity<String> response = restTemplate.exchange(
url, HttpMethod.valueOf(method), entity, String.class);
long duration = System.currentTimeMillis() - start;
return ToolResult.success(
response.getBody(),
Map.of("status", response.getStatusCode().value(),
"duration_ms", duration)
);
} catch (HttpClientErrorException e) {
return ToolResult.failure("HTTP " + e.getStatusCode() + ": " + e.getMessage(),
Map.of("status", e.getStatusCode().value()));
} catch (Exception e) {
return ToolResult.failure("HTTP request failed: " + e.getMessage(), Map.of());
}
}
}
__`_INLINE
4.4 Agent 核心服务实现
将所有组件整合起来,构建完整的 _IntelligentReportAgent__INLINE:
__`__INLINE_java
@Service
@Slf4j
public class IntelligentReportAgent implements BusinessAgent {
@Autowired
private ToolRegistry toolRegistry;
@Autowired
private TaskPlanner planner;
@Autowired
private WorkflowOrchestrator orchestrator;
@Autowired
private LlmClient llmClient;
@Override
public AgentResponse execute(AgentRequest request) {
log.info("Received request: {}", request.instruction());
long start = System.currentTimeMillis();
try {
// Step 1: 获取所有可用工具
List<Tool> availableTools = toolRegistry.getAll();
// Step 2: 任务规划 - 将自然语言指令转化为任务图
TaskGraph graph = planner.plan(request.instruction(), availableTools);
log.info("Task graph created with {} nodes", graph.nodes().size());
// Step 3: 执行任务图
WorkflowResult result = orchestrator.execute(graph, Map.of(
"user_id", request.userId(),
"org_id", request.orgId(),
"instruction", request.instruction()
));
// Step 4: 结果分析与自然语言生成
String conclusion = generateConclusion(request.instruction(), result);
long duration = System.currentTimeMillis() - start;
log.info("Request completed in {}ms", duration);
return AgentResponse.success(
conclusion,
result.rawResults(),
Map.of("duration_ms", duration, "steps_executed", graph.nodes().size())
);
} catch (Exception e) {
log.error("Agent execution failed", e);
return AgentResponse.failure("处理失败: " + e.getMessage());
}
}
private String generateConclusion(String instruction, WorkflowResult result) {
// 将结构化数据结果交给 LLM 生成自然语言分析结论
String prompt = String.format("""
基于以下原始数据,给出针对用户问题的分析结论。
用户问题:%s
数据结果:
%s
请用专业的数据分析师口吻,给出简洁明了的分析结论,包含关键数字和同比/环比变化。
""", instruction, JSON.toJSONString(result.rawResults()));
return llmClient.complete(prompt).getContent();
}
}
__`_INLINE
4.5 Spring Boot 启动配置
为了让 Agent 系统在 Spring Boot 环境中正确启动,需要进行以下配置:
__`__INLINE_java
@Configuration
public class AgentConfiguration {
@Bean
public ToolRegistry toolRegistry() {
return new ToolRegistryImpl();
}
@Bean
public ToolExecutor toolExecutor(ToolRegistry registry) {
return new ToolExecutorImpl(registry);
}
@Bean
public WorkflowOrchestrator workflowOrchestrator(ToolExecutor toolExecutor) {
return new WorkflowOrchestrator(toolExecutor);
}
@Bean
public RestTemplate restTemplate(RestTemplateBuilder builder) {
return builder.build();
}
// 工具自动注册
@Autowired
private void registerTools(ApplicationContext ctx, ToolRegistry registry) {
Map<String, Tool> tools = ctx.getBeansOfType(Tool.class);
tools.values().forEach(registry::register);
log.info("Registered {} tools", tools.size());
}
}
__`_INLINE
4.6 RESTful API 接口
将 Agent 暴露为 HTTP 接口,供前端或第三方系统调用:
__`__INLINE_java
@RestController
@RequestMapping("/api/v1/agent")
@Slf4j
public class AgentController {
@Autowired
private BusinessAgent reportAgent;
@PostMapping("/report")
public ResponseEntity<AgentResponse> generateReport(
@RequestBody AgentRequest request,
@RequestHeader(value = "X-User-Id", required = false) String userId) {
if (userId != null) {
request = new AgentRequest(request.instruction(), userId, request.orgId());
}
return ResponseEntity.ok(reportAgent.execute(request));
}
@GetMapping("/tools")
public ResponseEntity<List<ToolInfo>> listTools() {
return ResponseEntity.ok(reportAgent.getRegisteredTools().stream()
.map(t -> new ToolInfo(t.name(), t.description(), t.inputSchema()))
.toList());
}
}
__`_INLINE
五、生产级工程实践
5.1 异常处理与容错机制
生产环境中的 Agent 系统面临诸多不确定性:LLM 服务不可用、网络超时、数据库连接池耗尽、工具返回异常数据等。完善的异常处理和容错机制是系统可靠运行的关键。
分层异常处理策略 :
第一层是工具级容错------每个工具执行时都包装在 try-catch 中,单个工具失败不影响其他工具和整体流程。工具返回 __ToolResult.failure(...)_INLINE 而非抛出异常,使执行引擎能够继续调度后续步骤。
第二层是执行引擎级容错------通过重试机制(_ToolExecutor 的 maxRetries__INLINE 配置)和熔断器模式,防止单个工具的持续失败拖垮整个系统。
第三层是 Agent 级容错------当所有执行路径都失败时,Agent 返回明确的错误信息和部分结果(能返回多少返回多少),而非直接崩溃。
__`__INLINE_java
// 熔断器实现
@Service
@Slf4j
public class CircuitBreakerTool implements Tool {
private final Tool delegate;
private final AtomicInteger failureCount = new AtomicInteger(0);
private final AtomicReference<Long> lastFailureTime = new AtomicReference<>(0L);
private final int failureThreshold;
private final long resetTimeoutMs;
public CircuitBreakerTool(Tool delegate, int failureThreshold, long resetTimeoutMs) {
this.delegate = delegate;
this.failureThreshold = failureThreshold;
this.resetTimeoutMs = resetTimeoutMs;
}
@Override
public ToolResult execute(Map<String, Object> params) {
if (isOpen()) {
return ToolResult.failure("Circuit breaker is open for: " + delegate.name(), Map.of());
}
try {
ToolResult result = delegate.execute(params);
if (!result.success()) {
recordFailure();
} else {
reset();
}
return result;
} catch (Exception e) {
recordFailure();
throw e;
}
}
private boolean isOpen() {
if (failureCount.get() < failureThreshold) return false;
long elapsed = System.currentTimeMillis() - lastFailureTime.get();
if (elapsed > resetTimeoutMs) {
reset();
return false;
}
return true;
}
private void recordFailure() {
failureCount.incrementAndGet();
lastFailureTime.set(System.currentTimeMillis());
}
private void reset() {
failureCount.set(0);
}
}
__`_INLINE
5.2 安全防护
Agent 系统涉及对数据库、文件系统、外部 API 的操作,安全问题尤为重要。
SQL 注入防护 :所有数据库操作必须通过参数化查询,不允许动态拼接用户输入到 SQL 语句中。__DatabaseTool 中的 isSelectStatement()_INLINE 校验仅是第一道防线,真正的安全来自参数化查询。
输入校验 :使用 Spring Validation 对用户输入进行严格校验。使用 JSON Schema(__inputSchema()_INLINE 方法)对工具参数进行模式校验,防止畸形输入导致系统行为异常。
权限控制 :不同用户角色可调用的工具集合不同。引入 _ToolPermissionService__INLINE,在执行工具前检查当前用户权限。
__`__INLINE_java
@Component
@Slf4j
public class SecureToolExecutor implements ToolExecutor {
@Autowired
private ToolExecutor delegate;
@Autowired
private ToolPermissionService permissionService;
@Override
public ToolResult execute(String toolName, Map<String, Object> params, ExecuteOptions options) {
if (!permissionService.hasPermission(getCurrentUser(), toolName)) {
log.warn("User {} attempted to access tool {} without permission",
getCurrentUser(), toolName);
return ToolResult.failure("Permission denied for tool: " + toolName, Map.of());
}
return delegate.execute(toolName, params, options);
}
private String getCurrentUser() {
// 从 Security Context 获取当前用户
Authentication auth = SecurityContextHolder.getContext().getAuthentication();
return auth != null ? auth.getName() : "anonymous";
}
}
__`_INLINE
5.3 性能优化
Agent 系统的性能瓶颈主要在 LLM 调用和数据获取两个环节。
LLM 调用的优化策略 包括:使用支持流式输出的 API 减少等待感;对频繁请求的相同上下文进行缓存(如通过 Redis 缓存 Planner 的中间结果);对实时性要求不高的场景使用异步非阻塞调用。
数据获取的优化 核心是并行拉取 ------当任务图中多个节点之间无依赖时,利用 _CompletableFuture.allOf() 并行执行,大幅缩短总执行时间。在 IntelligentReportAgent__INLINE 的案例中,数据仓库查询、第三方 API 调用、本地文件读取可以并行进行,这往往能将整体耗时从"三步串行"变为"一步并行"。
__`__INLINE_java
// 并行拉取优化示例
private Map<String, Object> fetchAllDataInParallel(List<DataSource> sources) {
List<CompletableFuture<Map.Entry<String, Object>>> futures = sources.stream()
.map(source -> CompletableFuture.supplyAsync(() -> {
Object data = fetchFromSource(source);
return Map.entry(source.getName(), data);
}, dataFetchExecutor))
.toList();
return CompletableFuture.allOf(futures.toArray(new CompletableFuture0))
.thenApply(v -> futures.stream()
.map(CompletableFuture::join)
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue)))
.join();
}
__`_INLINE
资源池化 :数据库连接池(HikariCP)、HTTP 连接池(Apache HttpClient 或 OkHttp 的连接池复用)、线程池(_Executors.newFixedThreadPool__INLINE)都是减少资源创建开销的标准手段。
5.4 可观测性与监控
Agent 系统的可观测性建设包括日志、指标和追踪三个方面。
结构化日志 :使用 SLF4J + Logback 的 JSON 格式输出,包含 traceId(请求链路追踪)、taskId(任务 ID)、toolName(工具名称)、duration(执行时长)等字段,便于在 ELK/Graylog 等日志系统中检索和分析。
关键指标 :通过 Micrometer + Prometheus 暴露以下核心指标:
-
_agent.requests.total__INLINE:Agent 请求总数(计数器)
-
_agent.request.duration__INLINE:请求处理耗时(histogram)
-
_agent.tool.executions.total__INLINE:各工具调用次数(带 toolName 标签)
-
_agent.tool.execution.duration__INLINE:各工具执行耗时(带 toolName 标签)
-
_agent.task.completion.rate__INLINE:任务完成率(成功/总数)
__`__INLINE_java
@Timed(value = "agent.tool.execution", extraTags = {"tool", "db_query"})
@Override
public ToolResult execute(String toolName, Map<String, Object> params, ExecuteOptions options) {
return delegate.execute(toolName, params, options);
}
__``
六、总结与展望
本文系统讲解了 Java 技术栈下 Agent 工作流的完整实现方案。从 Agent 的核心概念出发,我们深入剖析了任务规划、工具注册、任务编排等关键环节的设计思路与代码实现,并通过一个企业级实战案例------智能数据报表分析 Agent------展示了从架构设计到生产落地的全流程。
核心要点总结:
Agent 本质是"目标驱动的自主执行系统" ,与传统 RPA 的根本区别在于理解业务语义而非操作界面像素。Java 凭借其企业级生态(Spring Boot、依赖注入、并发框架、成熟的工具链),是构建生产级 Agent 系统的优选语言。
工具接口(Tool Interface)是 Agent 系统的设计核心 。将所有外部能力抽象为统一接口,使系统具备高度的可扩展性和可测试性。工具注册中心(ToolRegistry)负责管理工具的元数据和生命周期,工具执行器(ToolExecutor)提供超时控制、重试策略和并发执行能力。
任务编排是复杂业务场景的关键 。通过构建有向无环任务图(DAG),配合并行执行和顺序依赖的混合编排策略,可以高效处理多数据源、多步骤的企业级业务流程。
生产级工程实践不可忽视 。分层异常处理、熔断器、安全防护(SQL 注入防护、权限控制)、性能优化(并行拉取、资源池化)以及完善的可观测性建设,是 Agent 系统能够稳定可靠运行于生产环境的必要条件。
展望未来,Java Agent 技术将在以下几个方向持续演进:
一是多模态 Agent ------除文本外,Agent 将逐步支持图像、音频、视频等多种模态的输入输出,实现真正的多模态业务自动化。
二是多 Agent 协作 ------多个专业 Agent 通过消息传递和任务协作,形成 Agent 团队(Multi-Agent System),处理更复杂的跨领域问题。
三是长期记忆与持续学习 ------通过向量数据库和知识图谱技术,赋予 Agent 持久化记忆和从历史经验中持续优化的能力,使 Agent 在企业业务中越用越智能。
四是标准化协议 ------随着 Agent 技术的普及,跨框架、跨平台的 Agent 互操作协议(如 Anthropic 的 MCP、OpenAI 的 Plugins)将推动 Agent 生态走向开放和标准化。
Java 作为企业级后端开发的主导语言,在 Agent 时代将继续发挥其核心价值。掌握 Agent 工作流的 Java 实现,不仅是跟上技术趋势的必需,更是构建下一代智能化企业应用的能力基础。
作者:洛水石