先谈谈自己工作的经历吧,我原来在某企业管理风控系统,日常工作最多的就是业务接入,然后就是成批几百个统计类特征的开发工作,策略人员小手一滑啦,Excel中几个维度两两组合,就出现几百个特征需要开发。在此家之前另一家用的决策引擎是Drools, 这个估计很多中小企业都还在用,Drools规则引擎看似强大,实则风控研发的噩梦,一切依赖开发人员,策略长期与规则隔离,很容易出现跟孩子不熟的问题,就好比把大舅家孩子认成姑家的。 好了回归正题实时特征计算,网络很多文章都在说如何用flink,如何实时计算,文章读取,视频也看过。说实话,干货不多,不成体系,存在遮遮掩掩的情况,也大有吹牛皮的存在。 本文将从生产实践方面解读为何需要实时特征计算平台,注意是平台化解决思路。回到开篇场景,业务部门需要推广一项新业务,需要接入风控,然后策略给出一批几百个特征,如果让你开发,你需要多久?
在工作期间在特征这一块领域,我有自己的一套理解。因为我真实参与了累计10000+的统计类特征开发,从SQL统计到三方数据源解析。
先说传统的SQL统计实现模式:前端交互设计一套页面,选中数据源,然后脚本输入SQL语句,动态传入参数。然后直接调度使用。这套方案对某些实时性要求不高的场景(如信贷领域)影响不大,但是对支付风控存在致命的隐患,主要体现在2方面:部署效率和执行耗时;
一个新业务进来,需要开发500个特征,按SQL统计或者代码开发起码要耗时5天,业务验证还要花费更多耗时,策略部署需要等着特征开发完毕才能开始。这样悄悄的过去了半个月甚至一个月,在日益激烈的竞争下,公司业务能等一个月吗?特征的执行耗时严重影响决策的响应时间,当前决策响应耗时多少?工作期间经过重新设计决策引擎和特征计算,我们支付风控达到了200ms以内的决策耗时。
我的设计是拿实时特征计算代替所有的SQL统计,抛开所谓的实时数据和离线数据概念划分,单从支付领域来说,我理解支付交易需要的特征数据大概分为三类:
- 超高实时的,具体到包含当笔交易的那种;
- 允许轻微延迟的,比如延迟几秒的。
- 允许天级延迟的;
如果技术允许,我建议避免第三类的出现,因为支付交易的超高交易量问题,秒级的延迟也存在很高的风险。 我的整体设计思路就是实时计算代替全部的SQL统计,底层均采用增量式计算模式,技术框架采用redis, flink, kafka, hbase; 一类数据用自定义算法或redis自增; 二三类数据用flink; 为保障查询效率,计算结果均存储redis, 这样查询方面耗时控制在毫秒以内。但此方案存在短板,过度依赖redis , 假如redis不可用,所以需要hbase做个备份,一旦出现redis不可用,还可以从hbase查询。特征计算流程按照以下模式
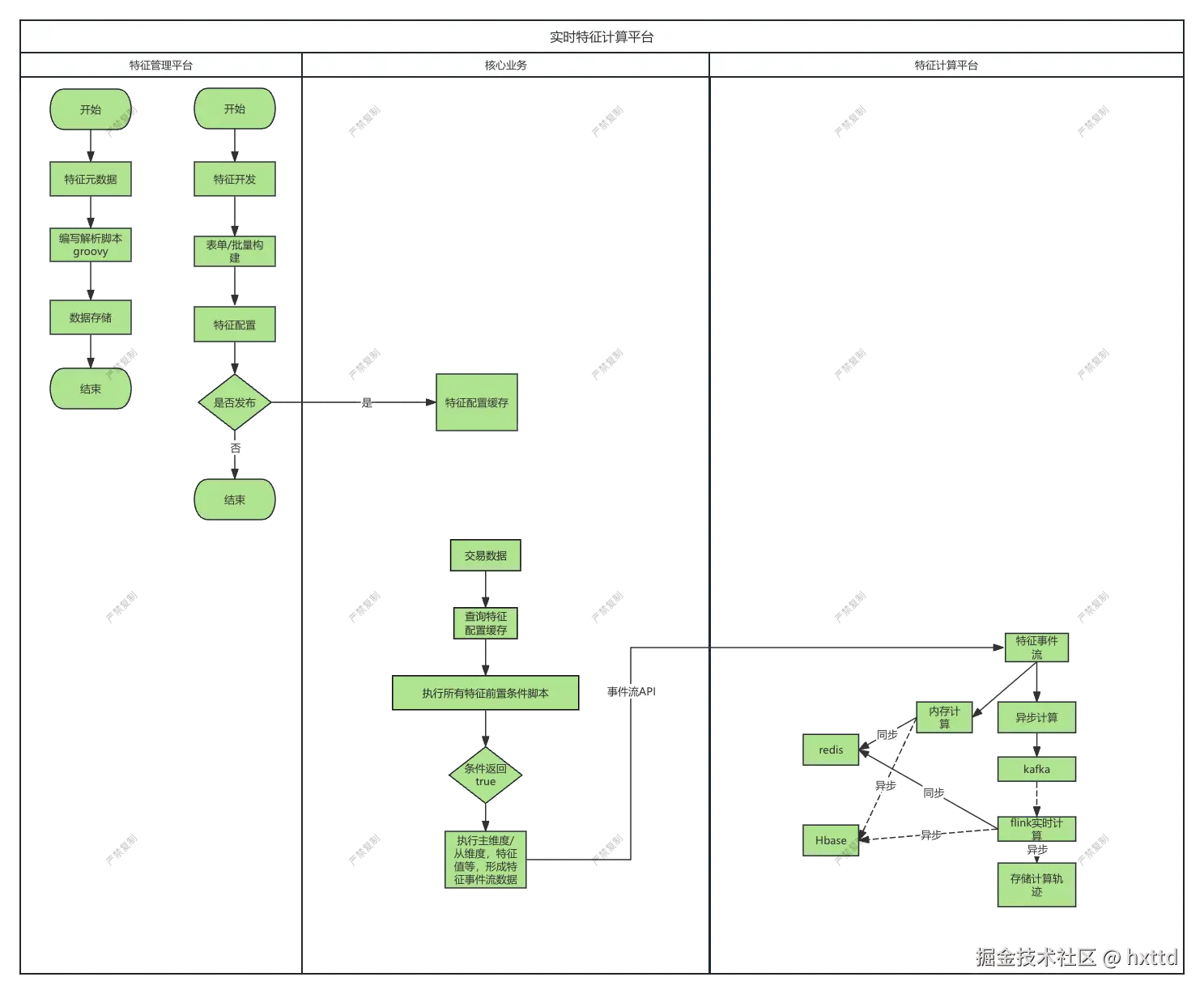
因为计算平台预定义存储是存放redis中,固查询是可以直接从redis获取结果数据,毫秒级响应。针对支付风控,尤其是涉及跨境支付时,因为部分地区存在数据出境安全要求的缘故,此处需要变更一下方案
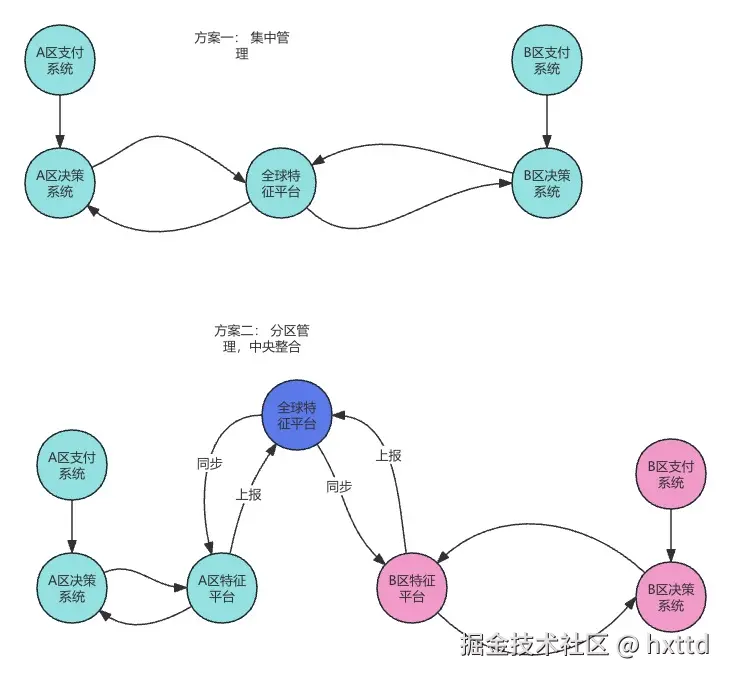
方案一:集中管理,初始化阶段,针对所有要求不允许出境的数据进行不可逆转化,如转Md5值,以达到合规要求。送往中央集群计算,各地区决策中心统一访问中央集群redis, 因为网络和机房原因,耗时较高;好处就是架构简单,容易维护。
方案二:分区计算存储,中央调配,各地区决策系统本地部署实施特征计算平台,然后同步中央集群,各地集群从中央同步增量;好处就是各地区独立,决策响应超快,缺点是结构复杂,部分增量存在秒级延迟。我倾向方案二
以上都是属于设计篇,下面直接送上具体细节设计
一、模块概述
1.1 模块定位
ttd-feature 是 TTD 智能决策引擎的特征累计模块,专门用于处理和计算业务场景中的特征值(Feature)。特征是指在特定时间窗口内,基于主维度和从维度对业务事件进行累计统计的特征值,广泛应用于风控、反欺诈、交易监控等场景。
1.2 核心能力
- 多维度累计:支持主维度(如用户ID)和从维度(如设备ID、商户ID)的二维累计
- 多时间窗口:支持 TTL(滑动窗口)、自然日、自然月、自然年、永久累计五种时间模式
- 多计算方式:支持求和(SUM)、计数(COUNT)、平均值(AVG)、最小值(MIN)、最大值(MAX)
- 高性能存储:基于 Redis 的高速缓存,支持毫秒级读写
- 异步处理:采用线程池异步处理,提升系统吞吐量
- 幂等控制:基于 Redis 的幂等判断,防止重复累计
- 监控追溯:完整的监控数据落库,支持数据审计和问题排查
二、核心概念
2.1 特征(Feature)
特征是一种特殊的业务特征,用于统计某个主体在特定时间范围内的行为频率或累计值。
示例场景:
- 用户在过去 24 小时内的登录次数
- 用户在近 7 天的交易总金额
- 同一设备在今日的下单次数
- 商户在本月的退款总金额
2.2 核心概念定义
| 概念 | 说明 | 示例 |
|---|---|---|
| 特征编码(featureCode) | 特征的唯一标识 | user_login_count_24h |
| 主维度(masterValue) | 累计的主要维度 | 用户ID:user_12345 |
| 从维度(slaveValue) | 累计的次要维度(可选) | 设备ID:device_abc |
| 特征值(featureValue) | 每次累计的值 | 1(计数)、100.50(金额) |
| 累计方式(cumType) | 时间窗口模式 | TTL、CD(自然日)、CM(自然月)等 |
| 计算方式(calateType) | 聚合计算方式 | SUM、COUNT、AVG、MIN、MAX |
2.3 累计方式枚举(FeatureCumTypeEnum)
| 枚举值 | 类型代码 | 说明 | 应用场景 |
|---|---|---|---|
| TTL | ttl |
滑动时间窗口 | 过去24小时、过去7天 |
| CURRENT_DAY | cd |
自然日 | 今日累计、昨日清零 |
| CURRENT_MONTH | cm |
自然月 | 本月累计、月初清零 |
| CURRENT_YEAR | cy |
自然年 | 今年累计、年初清零 |
| FOREVER | fvr |
永久累计 | 历史总累计、不清零 |
三、架构设计
3.1 整体架构图
yaml
┌─────────────────────────────────────────────────────────────┐
│ 业务系统(调用方) │
└──────────────────┬──────────────────────────────────────────┘
│ writeFeature(TxnFeatureRequest)
▼
┌─────────────────────────────────────────────────────────────┐
│ TxnFeatureService(服务接口) │
│ TxnFeatureServiceImpl │
└──────────────────┬──────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ FeatureDataSunkTask(数据处理任务) │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ 1. 幂等判断(Redis) │ │
│ │ 2. 异步并发处理(ThreadPoolExecutor) │ │
│ │ 3. 路由到具体累计服务(FeatureDataSunkFactory) │ │
│ │ 4. Redis 缓存更新 │ │
│ │ 5. 监控数据落库 │ │
│ └──────────────────────────────────────────────────────┘ │
└──────────────────┬──────────────────────────────────────────┘
│
┌──────────┴──────────┐
▼ ▼
┌───────────────┐ ┌──────────────────┐
│ FeatureData │ │ 监控数据落库服务 │
│ SunkFactory │ │FeatureMonitor │
│ (策略工厂) │ │ SinkService │
└───────┬───────┘ └────────┬─────────┘
│ │
▼ ▼
┌──────────────────┐ ┌──────────────────────────────────┐
│ 累计策略实现类 │ │ 监控数据存储 │
│ │ │ ├─ 事件流数据(FeatureEventData) │
│ ├─ TTL模式 │ │ ├─ 主维度值记录 │
│ ├─ 自然日模式 │ │ ├─ 历史快照数据 │
│ ├─ 自然月模式 │ │ ├─ 查询快照数据 │
│ ├─ 自然年模式 │ │ └─ 日监控数据 │
│ └─ 永久累计模式 │ └──────────────────────────────────┘
└──────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ Redis(高速缓存层) │
│ ┌─────────────────────────────────────────────┐ │
│ │ Key: feature:{featureCode}:{masterValue} │ │
│ │ Value: Map<slaveValue, List<ValueItem>> │ │
│ │ TTL: 动态过期时间 │ │
│ └─────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘3.2 核心组件说明
3.2.1 服务层
TxnFeatureService(特征累计服务接口)
提供特征累计的统一入口方法 writeFeature(TxnFeatureRequest request),接收业务请求后触发异步处理流程。
TxnFeatureRequest(请求对象)
包含以下核心字段:
- txnId:交易流水号(必填)
- txnTime:交易时间(可选)
- eventDataList:事件数据列表(必填),包含多个 FeatureEventDataDto 对象
3.2.2 数据处理层
FeatureDataSunkTask(数据处理任务)
核心处理流程分为以下步骤:
- 校验事件数据:检查事件数据列表是否为空,为空则抛出异常
- 保存事件流数据:将原始事件数据异步保存到监控存储,用于数据追溯
- 并发处理事件 :遍历事件列表,对每个事件执行以下操作:
- 幂等判断:基于 Redis 检查该交易是否已处理(Key 格式:
pay:rcs:feature:handle:{txnId}:{featureCode}),已处理则跳过 - 异步处理:提交任务到线程池(payRcsFeatureSunkTp),使用 CompletableFuture 实现并发
- 策略路由:通过 FeatureDataSunkFactory 根据 cumType 获取对应的累计策略服务
- 执行算法:调用策略服务的 getFeatureData 方法计算累计值
- 写入缓存:构建 Redis Key 和过期时间,将处理后数据写入 Redis
- 保存监控:记录主维度值和历史快照数据
- 设置幂等标记:在 Redis 中设置处理标记,5 分钟过期
- 幂等判断:基于 Redis 检查该交易是否已处理(Key 格式:
- 等待完成:使用 CompletableFuture.allOf().join() 等待所有异步任务完成
3.2.3 策略模式层
AbstractFeatureDataSunkService(抽象策略基类)
定义策略接口和公共方法:
- getCumType():返回累计类型标识(策略路由键)
- getFeatureData(dto):抽象方法,由子类实现具体的累计算法
- getCacheItemFromRedis(redisKey):公共方法,从 Redis 读取并反序列化缓存数据
FeatureDataSunkFactory(策略工厂)
采用 Spring 自动注册机制:
- 使用 @PostConstruct 在启动时扫描所有 AbstractFeatureDataSunkService 类型的 Bean
- 将每个策略实例以其 getCumType() 返回值作为 Key 存入 serviceMap
- 提供静态方法 getService(cumType) 根据累计类型获取对应策略
设计优势:
- ✅ 开闭原则:新增累计方式只需添加新策略类,无需修改现有代码
- ✅ 自动注册:基于 Spring 的自动发现机制,零配置
- ✅ 策略路由:根据 cumType 动态路由到对应实现
3.2.4 策略实现类
五种累计策略实现:
| 策略类 | 累计类型 | 核心逻辑 |
|---|---|---|
| FeatureDataSunkByTTLService | TTL | 基于滑动时间窗口,过滤过期数据 |
| FeatureDataSunkByCalendarDayService | 自然日 | 按自然日累计,每日清零 |
| FeatureDataSunkByCalendarMonthService | 自然月 | 按自然月累计,每月清零 |
| FeatureDataSunkByCalendarYearService | 自然年 | 按自然年累计,每年清零 |
| FeatureDataSunkByPersistService | 永久累计 | 永久累计,不清零 |
TTL 策略实现示例(FeatureDataSunkByTTLService)
核心算法流程:
- 从 Redis 读取缓存数据(Map<从维度, 值项列表>)
- 计算时间窗口边界:windowMinTime = txnTime - timeWindow
- 过滤过期数据:移除时间戳小于窗口边界的记录
- 清理空值:移除累计值为空的从维度
- 保存处理前数据快照(用于监控对比)
- 追加新数据:在对应从维度下添加新的值项(包含 txnId、时间戳、值)
- 首次创建:若缓存不存在,则创建新的数据结构
- 返回 FeatureWindowDataDto,包含处理前后的数据快照
3.2.5 辅助工具类
FeatureRedisKeyBuilder(Redis Key 构建器)
构建特征数据项 Key,格式为 feature:{featureCode}:{masterValue},例如 feature:user_login_count_24h:user_12345。
FeatureTimeOutBuilder(过期时间构建器)
提供三个核心方法:
- getCacheTime(dto):根据 cumType 和 expireNum/expireType 计算缓存过期时间(秒)
- getWindowMinTime(dto):计算时间窗口最小时间戳
- getWindowExpireTime(dto):计算窗口过期时间
3.2.6 监控层
FeatureMonitorSinkService(监控数据落库服务)
监控数据类型:
| 监控数据 | DTO 类 | 用途 |
|---|---|---|
| 事件流数据 | FeatureEventDataDto | 记录原始事件,用于数据追溯 |
| 主维度值记录 | FeatureMasterValueRecord | 记录主维度的缓存大小和字节数 |
| 历史快照数据 | FeatureHistorySnapshotDto | 记录写入前后的数据快照 |
| 查询快照数据 | FeatureReadSnapshotDto | 记录查询时的数据快照 |
| 日监控数据 | FeatureDailyMonitorDto | 每日统计汇总 |
监控数据流转:
vbnet
事件写入
↓
保存事件流数据(FeatureEventData)
↓
计算累计值
↓
保存主维度值记录(FeatureMasterValueRecord)
├─ Redis Key
├─ 缓存大小(条目数)
└─ 缓存字节数
↓
保存历史快照数据(FeatureHistorySnapshotDto)
├─ 写入前数据(beforeData)
└─ 写入后数据(afterData)
↓
异步落库(Kafka / 数据库)四、数据模型
4.1 核心数据对象
FeatureEventDataDto(事件流数据)
| 字段 | 类型 | 说明 |
|---|---|---|
| txnId | String | 交易流水号 |
| txnTime | Date | 交易时间 |
| featureCode | String | 特征编码 |
| masterValue | String | 主维度值 |
| slaveValue | String | 从维度值 |
| featureValue | BigDecimal | 特征值 |
| cumType | String | 累计方式 |
| calateType | String | 计算方式 |
| expireNum | Integer | 过期时间数 |
| expireType | String | 过期时间单位 |
| expireTime | Date | 过期时间 |
FeatureWindowDataDto(窗口数据)
| 字段 | 类型 | 说明 |
|---|---|---|
| featureCode | String | 特征编码 |
| masterValue | String | 主维度值 |
| txnId | String | 交易流水号 |
| redisKey | String | Redis Key |
| beforeData | Map<String, List<FeatureValueItem>> | 处理前数据 |
| afterData | Map<String, List<FeatureValueItem>> | 处理后数据 |
| expireTime | Date | 过期时间 |
FeatureValueItem(值项)
| 字段 | 类型 | 说明 |
|---|---|---|
| txnId | String | 交易流水号 |
| ts | Long | 时间戳 |
| value | BigDecimal | 值 |
4.2 Redis 数据结构
Key 格式:
css
feature:{featureCode}:{masterValue}示例:
makefile
feature:user_login_count_24h:user_12345Value 结构(JSON):
json
{
"device_001": [
{"txnId": "txn001", "ts": 1716000000000, "value": 1},
{"txnId": "txn002", "ts": 1716003600000, "value": 1}
],
"device_002": [
{"txnId": "txn003", "ts": 1716007200000, "value": 1}
]
}说明:
- Key:从维度值(如设备ID)
- Value:值项列表(包含交易ID、时间戳、值)
五、核心流程
5.1 速率累计流程
markdown
1. 业务系统调用 writeFeature(TxnFeatureRequest)
↓
2. TxnFeatureServiceImpl 接收请求
↓
3. FeatureDataSunkTask.execute() 执行处理
↓
4. 校验事件数据列表非空
↓
5. 异步保存事件流数据到监控存储
↓
6. 遍历事件列表,对每个事件:
├─ 6.1 幂等判断(Redis)
│ └─ 已处理 → 跳过
│ └─ 未处理 → 继续
├─ 6.2 提交异步任务到线程池
│ ├─ 获取累计策略服务(FeatureDataSunkFactory)
│ ├─ 执行策略算法(getFeatureData)
│ │ ├─ 从 Redis 读取缓存数据
│ │ ├─ 过滤过期数据
│ │ ├─ 追加新数据
│ │ └─ 返回前后数据快照
│ ├─ 写入 Redis(带过期时间)
│ ├─ 保存主维度值监控记录
│ ├─ 保存历史快照数据
│ └─ 设置幂等标记(5分钟)
│
7. 等待所有异步任务完成(CompletableFuture.allOf)
↓
8. 返回(异步处理,立即返回)
## 六、设计模式
### 6.1 策略模式(Strategy Pattern)
**应用场景:** 不同累计方式的算法实现AbstractFeatureDataSunkService(抽象策略) ↑ ├── FeatureDataSunkByTTLService(具体策略:TTL) ├── FeatureDataSunkByCalendarDayService(具体策略:自然日) ├── FeatureDataSunkByCalendarMonthService(具体策略:自然月) ├── FeatureDataSunkByCalendarYearService(具体策略:自然年) └── FeatureDataSunkByPersistService(具体策略:永久累计)
FeatureDataSunkFactory(上下文/工厂) └─ 根据 cumType 选择具体策略
arduino
**优势:**
- 算法独立变化,互不影响
- 易于扩展新的累计方式
- 符合开闭原则
### 6.2 工厂模式(Factory Pattern)
**应用场景:** 策略实例的创建和路由
```java
@PostConstruct
public void init() {
// 自动发现并注册所有策略实现
Map<String, AbstractFeatureDataSunkService> map =
context.getBeansOfType(AbstractFeatureDataSunkService.class);
map.forEach((key, value) -> serviceMap.put(value.getCumType(), value));
}优势:
- 自动注册,无需手动配置
- 集中管理策略实例
- 支持动态扩展
6.3 模板方法模式(Template Method Pattern)
应用场景: AbstractFeatureDataSunkService 定义算法骨架
java
// 抽象基类定义公共方法
protected Map<String, List<FeatureValueItem>> getCacheItemFromRedis(String redisKey) {
// 公共的 Redis 读取逻辑
}
// 子类实现特定算法
public abstract FeatureWindowDataDto getFeatureData(FeatureEventDataDto dto);七、性能优化
7.1 并发处理
线程池配置:
- payRcsFeatureSunkTp:数据处理线程池,用于并发处理特征累计任务
- payRcsFeatureMonitorTp:监控数据线程池,用于异步保存监控数据
并发级别:
- 事件级别并发:每个事件独立处理,互不阻塞
- 使用 CompletableFuture 实现异步编排
- allOf().join() 等待所有任务完成后返回
7.2 幂等控制
机制:
- 基于 Redis 实现,Key 格式为
pay:rcs:feature:handle:{txnId}:{featureCode} - 处理前检查 Key 是否存在,存在则跳过
- 处理完成后设置 Key 值为 "1",TTL 设为 300 秒(5 分钟)
- Redis 原子操作保证并发安全
优势:
- 防止重复累计,保证数据一致性
- 自动过期,避免内存泄漏
- 轻量级判断,性能开销极小
八、扩展性设计
8.1 新增累计方式
步骤:
- 创建策略实现类,继承 AbstractFeatureDataSunkService
- 实现 getCumType() 方法,返回自定义累计类型标识(如 "custom")
- 实现 getFeatureData(dto) 方法,编写自定义累计算法
- 添加 @Service 注解,Spring 自动扫描注册
- 在 FeatureCumTypeEnum 中添加对应枚举值
优势: 无需修改工厂类和现有代码,系统启动时自动发现并注册新策略。
8.2 新增计算方式
当前支持: SUM、COUNT、AVG、MIN、MAX
扩展方式:
- 在策略实现中根据
calateType分支处理 - 或创建新的策略类专门处理
九、监控与运维
9.1 监控指标
| 指标 | 说明 | 监控方式 |
|---|---|---|
| 写入 QPS | 每秒写入事件数 | 日志统计 |
| 写入延迟 | 从接收到写入完成的耗时 | 时间戳对比 |
| Redis 命中率 | 缓存命中比例 | Redis 监控 |
| 缓存大小 | 每个主维度的缓存条目数和字节数 | FeatureMasterValueRecord |
| 异常率 | 处理失败的比例 | 异常日志 |
9.2 日志规范
关键日志点: 警告日志: 记录已处理的重复请求(包含 txnId、featureCode)
- 错误日志:记录处理失败的异常信息(包含 txnId、eventData、异常堆栈)
- 业务日志:记录处理流程和关键节点(包含 pointCode、txnId 等业务标识)
9.3 数据追溯
追溯链路:
markdown
txnId → FeatureEventDataDto(事件流数据)
→ FeatureHistorySnapshotDto(历史快照)
→ Redis Key(当前缓存数据)
→ FeatureMasterValueRecord(主维度记录)十、最佳实践
10.1 特征设计原则
-
主维度选择
- 选择高频查询的维度作为主维度
- 常用:用户ID、设备ID、IP地址
-
从维度选择
- 需要细分统计的维度作为从维度
- 常用:商户ID、商品ID、地区
-
时间窗口设置
- TTL 模式:根据业务场景设置合理窗口
- 自然日/月/年:适合周期性统计
-
计算方式选择
- COUNT:统计次数(如登录次数)
- SUM:累计金额(如交易总额)
- AVG:平均值(如平均订单金额)
10.2 性能调优建议
Redis 配置:
- 启用持久化(AOF + RDB),保证数据安全
- 合理设置内存上限(maxmemory)
- 配置淘汰策略(volatile-ttl,优先淘汰带 TTL 的 Key)
线程池调优:
- 核心线程数:CPU 核心数 × 2
- 队列容量:根据业务峰值设置(建议 1000-5000)
- 拒绝策略:CallerRunsPolicy(调用者运行)
批量处理:
- 批量写入 Redis(Pipeline),减少网络开销
- 批量落库监控数据,降低数据库压力
十一、总结
11.1 架构优势
- 高性能:基于 Redis 的毫秒级读写,支持高并发场景
- 高可用:异步处理 + 异常隔离,单个事件失败不影响整体
- 易扩展:策略模式 + 工厂模式,新增累计方式零改造
- 可追溯:完整的监控数据落库,支持数据审计
- 幂等安全:Redis 幂等标记,防止重复累计
11.2 适用场景
- ✅ 风控反欺诈(高频交易检测)
- ✅ 用户行为分析(登录频率、操作频率)
- ✅ 交易监控(交易限额、频次控制)
- ✅ 营销活动(参与次数限制)
- ✅ 资源配额(API 调用频次限制)
11.3 技术栈
| 技术 | 用途 |
|---|---|
| Redis | 高速缓存,存储特征数据 |
| kafka/flink | kafka高并发削峰处理,flink异步实时增量计算 |
| CompletableFuture | 异步并发处理 |
| Spring | IoC 容器,策略自动注册 |
| FastJSON | JSON 序列化/反序列化 |
| 策略模式 | 多累计方式实现 |
| 工厂模式 | 策略实例管理 |
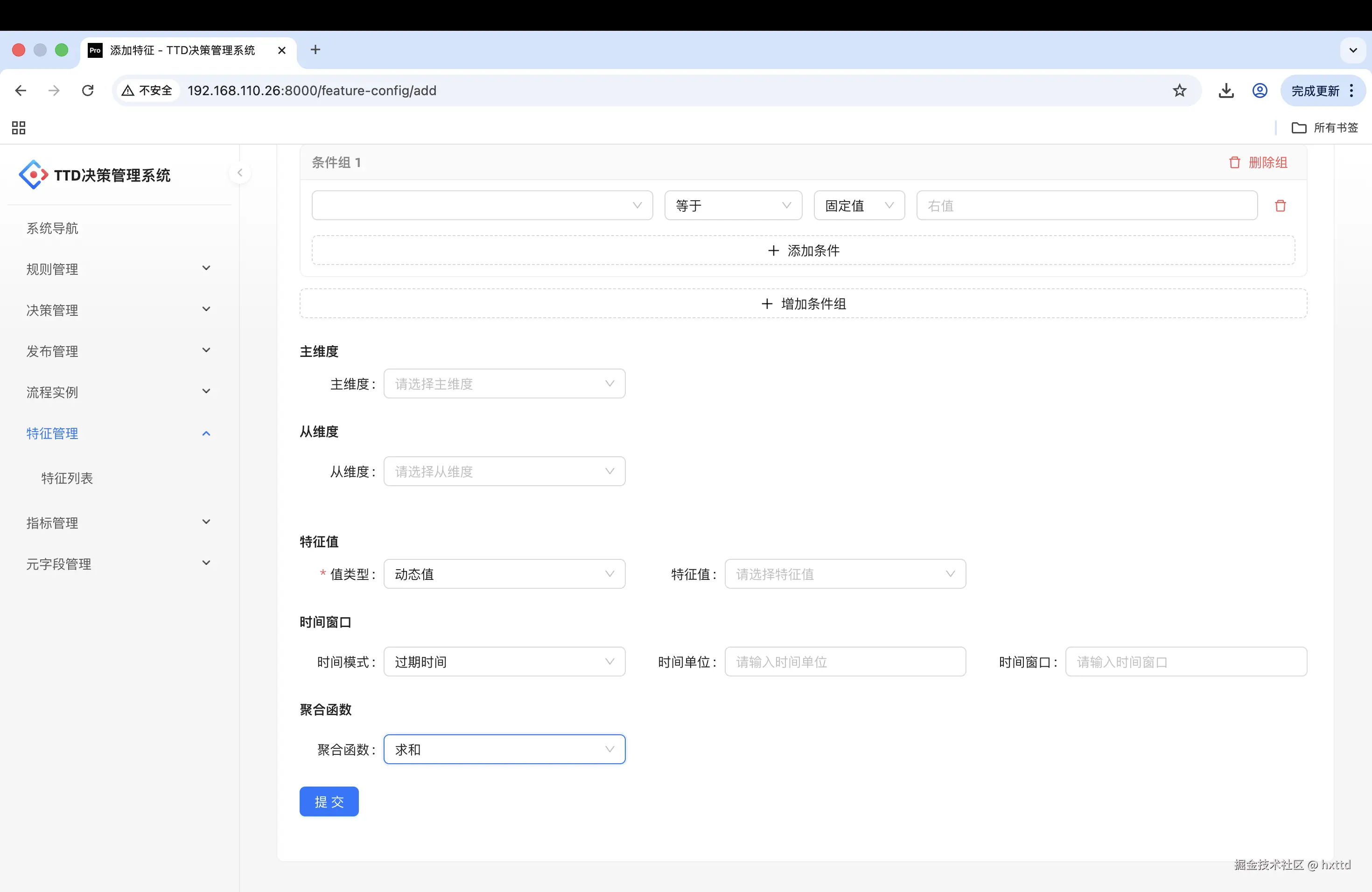
特征管理平台配置篇: 想要把系统交出去,就要懂业务人员会干什么,每个人都会填写表单和excel表格,所以针对这个场景,增强交互,条件组动态增加各种前置条件,内置表达式转换算法。将表单数据转为groovy脚本, 主从维度值也是脚本获取。变量就是特征元数据(本参考页面是将特征平台集成到决策管理系统,二者公用同一套元数据,单独特征管理平台时需要增加元数据管理模块)