前言:
在金融科技、智能营销、风控反欺诈等领域,规则引擎已成为业务快速迭代的核心基础设施。它通过将业务规则从代码中剥离,实现策略的动态配置与热更新,让业务人员无需依赖技术团队即可调整规则逻辑。本文将基于个人设计的规则引擎,从架构设计、核心模块到落地实践,完整解析一个企业级规则引擎的实现思路。在文章开始前,我们先回顾一下当前企业级规则引擎技术面临的困境
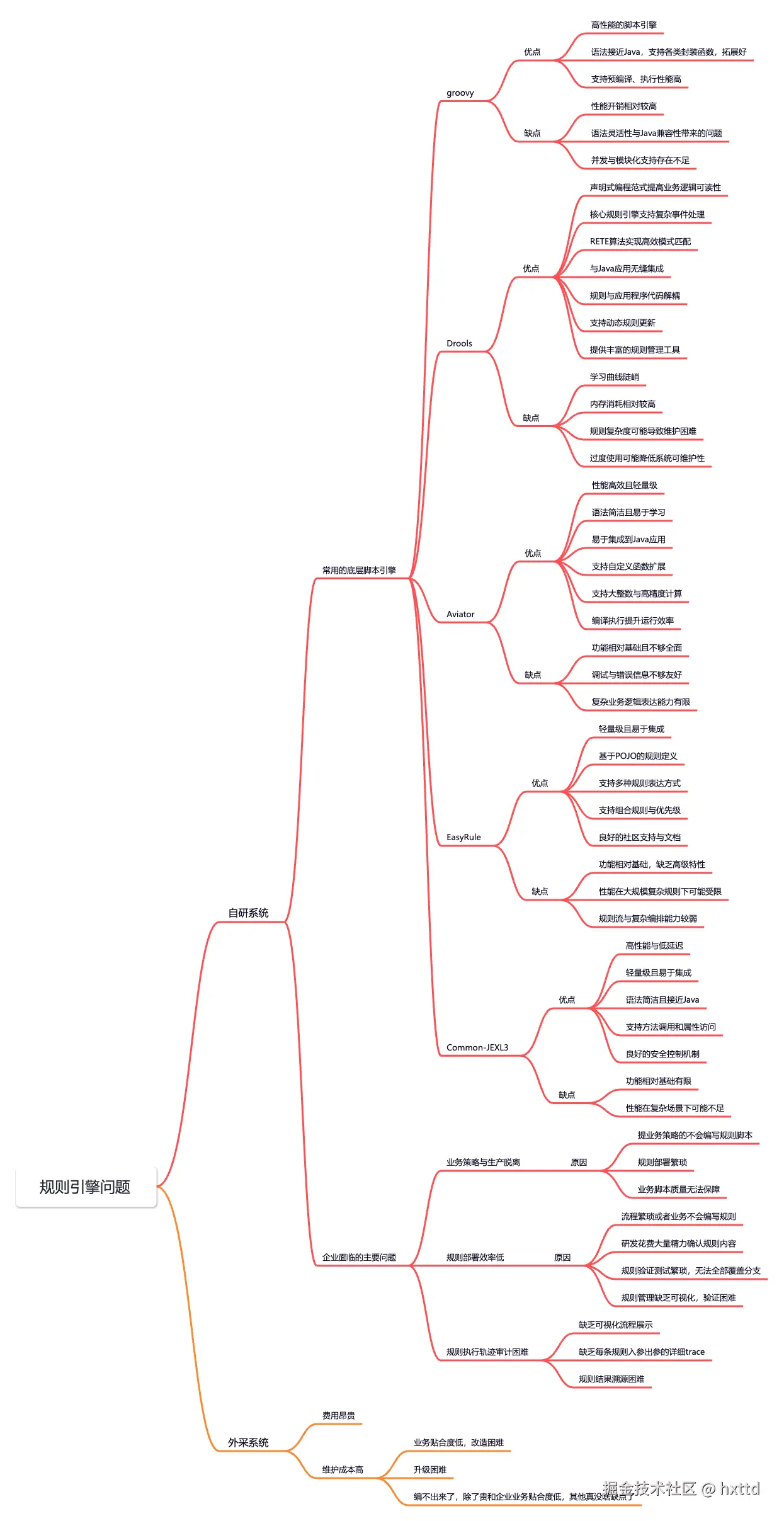
规则引擎问题.png - 点击放大查看
整体功能图
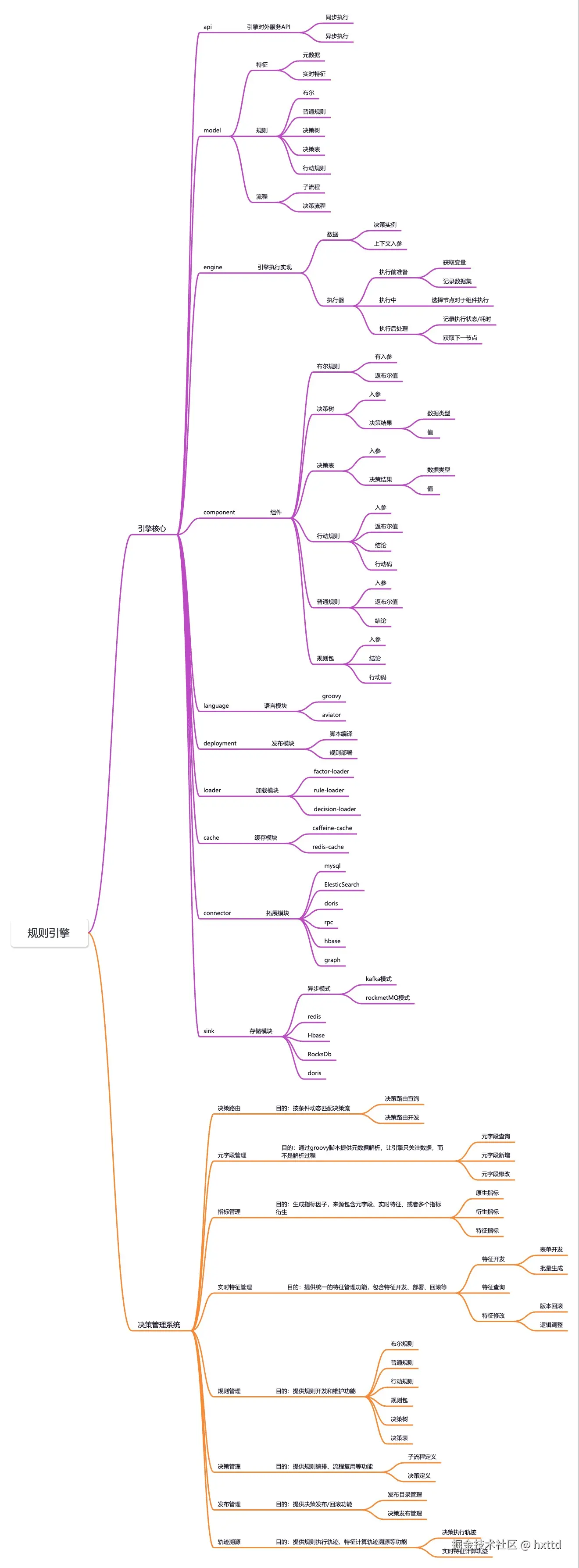
030202b6f91b47b4cd5d9e57911169a4 - 点击放大查看
一、架构设计:分层解耦,职责清晰
本系统采用分层架构设计,整体分为引擎核心与决策管理系统两大模块,各模块通过标准化接口交互,确保系统的可扩展性与可维护性。
引擎核心:执行效率与灵活性的平衡
引擎核心是规则执行的"心脏",包含API服务层、模型管理层、执行层、组件层、扩展层五大模块。
- API服务层:提供同步与异步两种执行模式,同步模式适用于实时性要求高的场景(如风控拦截),异步模式则通过Kafka/RocketMQ处理批量任务(如营销名单筛选),满足不同业务场景的性能需求。
- 模型管理层:定义了规则引擎的核心数据结构。特征模块区分元数据(如用户ID、订单金额)与实时特征(如用户近1小时登录次数),为规则计算提供数据支撑;规则模块支持布尔规则(简单条件判断)、决策树(层级化决策)、决策表(矩阵式条件匹配)等6种规则类型,覆盖从简单到复杂的业务场景;流程模块通过子流程与决策流程的编排,实现多步骤业务的可视化建模。
- 执行层:采用"执行前准备-执行中调度-执行后处理"的三阶段设计。执行前通过上下文入参初始化数据,执行中根据节点类型选择对应组件执行,执行后记录状态、耗时并确定下一节点,实现全生命周期管理。
- 组件层:封装各类规则的具体实现逻辑,如决策树组件通过入参匹配路径输出结果,行动规则组件通过动作码触发业务操作,确保逻辑复用与标准化输出。
- 扩展层:通过语言模块(Groovy/Aviator)支持脚本自定义规则,通过加载模块(factor-loader/rule-loader)实现规则热加载,通过缓存模块(Caffeine/Redis)提升数据读取性能,通过存储模块(MySQL/HBase/RocksDB)支持多数据源持久化。
决策管理系统:可视化配置与全生命周期管理
决策管理系统是规则引擎的"大脑",提供从规则开发、测试、发布到监控的全生命周期管理能力,让业务人员可自主完成规则配置。
- 决策路由:动态匹配决策流。通过条件动态匹配决策流,支持按业务类型(如信贷审批、营销活动)或数据特征(如用户等级、订单金额)路由到不同的决策流程,实现"一套引擎,多场景复用"。
- 元字段与指标管理 :数据抽象与复用。
- 元字段管理:通过Groovy脚本定义数据解析逻辑,将原始数据(如JSON、数据库记录)转换为引擎可识别的元数据,让引擎只关注业务逻辑而非数据解析过程。
- 指标管理:支持原生指标(直接取自元字段)、衍生指标(多字段计算结果,如"近7天订单金额总和")、特征指标(实时特征加工结果),形成统一的指标体系,避免重复计算。
- 实时特征管理:动态数据的高效处理。针对实时性要求高的场景(如用户行为分析),提供特征开发、部署、回滚功能。通过表单开发或批量生成方式定义特征逻辑,支持版本回滚与逻辑调整,确保实时数据的准确性与一致性。
- 规则与决策管理 :可视化编排与发布。
- 规则管理:提供可视化界面开发布尔规则、决策树、决策表等,支持规则包的批量管理与版本控制。
- 决策管理:通过拖拽式流程编排,将多个规则、子流程组合成复杂决策流,支持流程复用与条件分支配置。
- 发布管理:通过发布目录管理实现规则/决策的灰度发布与全量上线,支持发布记录查询与回滚,确保上线过程可控。
- 轨迹溯源:执行过程的透明化。记录规则执行轨迹(如哪个规则命中、输出结果)与实时特征计算轨迹(如特征值来源、计算过程),为问题排查与效果分析提供数据支撑。
二、落地实践:从设计到生产的挑战与解决
在engine的落地过程中,我们遇到了性能、扩展性、易用性三大挑战,通过以下方案逐一解决:
- 性能优化:缓存与异步化
- 通过Caffeine本地缓存+Redis分布式缓存,实现对特征数据的快速读取,避免同一交易内指标重复计算,提升规则执行效率。
- 异步执行模式结合Kafka/RocketMQ,支持每秒万级规则执行请求,满足高并发场景需求。
- 扩展性保障:插件化设计
- 语言模块支持动态加载Groovy/Aviator脚本,新增规则类型只需实现标准接口,无需修改核心代码。
- 存储模块通过Connector抽象层,支持MySQL、HBase、RocksDB等多种数据源,可根据业务需求灵活切换。
- 易用性提升:可视化与自助化
- 决策管理系统提供拖拽式流程编排、规则调试工具、执行轨迹查询等功能,业务人员可自主完成规则配置与测试,减少技术团队介入。
- 通过元字段与指标管理,将复杂的数据逻辑抽象为简单配置,降低业务人员学习成本。
三、总结与展望
通过分层架构设计、可视化决策管理、插件化扩展机制,实现了规则引擎的高性能、高扩展性与高易用性,已在金融风控、智能营销等场景落地,支持日均百万级规则执行请求。
未来,我们计划引入机器学习模型与规则引擎的融合(如模型输出作为规则输入),进一步提升决策智能化水平;同时探索边缘计算场景下的轻量化引擎部署,满足物联网设备的实时决策需求。
规则引擎的价值不仅在于技术实现,更在于如何让业务与技术高效协同。希望该系统的设计实践能为开发者提供参考,共同推动规则引擎技术的演进。