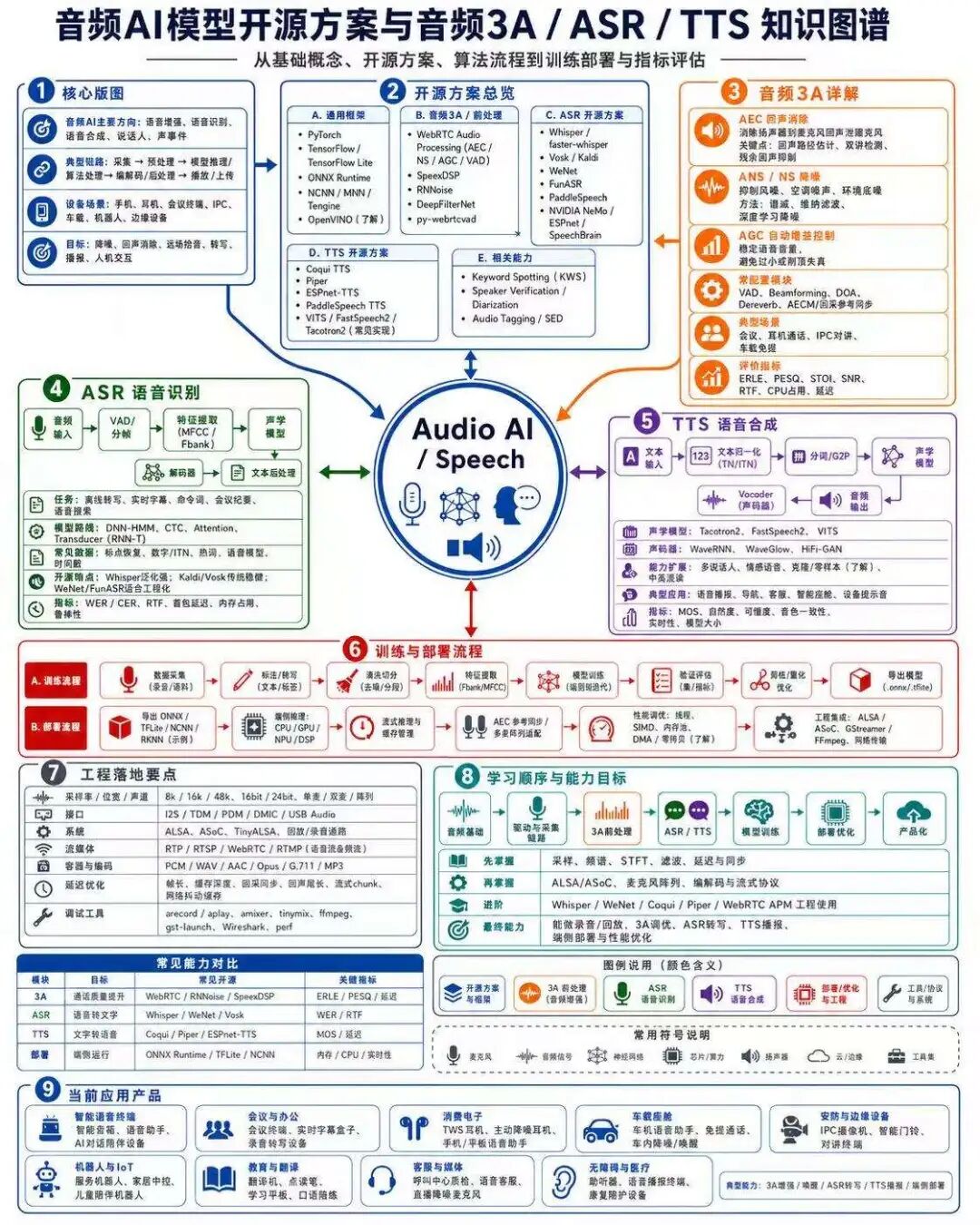
本文从工程师视角,对"音频 AI 模型开源方案与音频 3A / ASR / TTS 知识图谱"进行系统拆解。内容覆盖音频 AI 的核心版图、开源方案选型、音频 3A 原理、ASR 语音识别、TTS 语音合成、训练与部署流程、工程落地要点、应用产品形态与学习路线。
这不是单纯介绍几个模型或几个算法库,而是从"真实产品如何落地"的角度,把采集、前处理、模型推理、训练优化、端侧部署、指标评估和应用场景串成一条完整链路。
一、先建立整体认知:音频 AI 不是单一模型,而是一条完整工程链路
很多人刚接触音频 AI 时,会把它理解成:
go
ASR = 语音识别模型
TTS = 语音合成模型
3A = 调一个 WebRTC Audio Processing 库这种理解没有错,但不够工程化。
真正的音频 AI 产品通常是一条完整链路:
go
麦克风 / 音频文件 / 网络流
↓
音频采集与解码
↓
重采样 / 分帧 / 格式转换
↓
音频前处理:AEC / NS / AGC / VAD / Beamforming
↓
特征提取:FBank / MFCC / STFT / Mel
↓
AI 模型:ASR / TTS / KWS / 声纹 / 声事件检测
↓
后处理:标点 / ITN / 热词 / 音色控制 / 结果融合
↓
端侧部署:ONNX / TFLite / NCNN / RKNN / TensorRT
↓
产品集成:ALSA / ASoC / FFmpeg / GStreamer / WebRTC / RTP所以音频 AI 的核心不是"会跑一个模型",而是理解:
go
声音怎么采集?
噪声怎么处理?
回声怎么消除?
语音怎么切分?
模型输入是什么?
模型输出怎么解释?
怎么做到实时?
怎么部署到端侧?
怎么评估效果?
怎么接入真实产品?二、核心版图:音频 AI 的主要方向
图片中"核心版图"部分包含几个关键词:
go
语音增强
语音识别
语音合成
说话人
声事件
采集 → 预处理 → 模型推理 / 算法处理 → 编解码 / 后处理 → 播放 / 上传从工程角度看,音频 AI 可以分成五大方向。
2.1 语音增强:让声音更干净、更清楚
语音增强的目标是提升语音质量。
常见任务包括:
go
降噪
去混响
回声消除
人声增强
语音分离
自动增益
风噪抑制
键盘声抑制典型应用:
go
视频会议
智能音箱
车载语音
耳机通话
IPC 对讲
机器人交互
直播连麦
远程教育语音增强通常位于 ASR 或语音通话之前。
如果前端处理不好,后面的 ASR 模型再强,也可能识别率下降。
2.2 ASR:Automatic Speech Recognition,语音识别
ASR 的目标是:
go
语音信号 → 文本典型场景:
go
语音输入法
会议转写
实时字幕
语音命令
智能客服
车载语音助手
语音质检
课堂录音转写ASR 关注的核心指标:
go
WER:词错误率
CER:字错误率
RTF:实时率
首包延迟
端到端延迟
内存占用
鲁棒性对于中文任务,常用 CER;对于英文任务,常用 WER。
2.3 TTS:Text To Speech,语音合成
TTS 的目标是:
go
文本 → 语音波形典型场景:
go
导航播报
智能客服
语音助手
机器人播报
儿童故事机
无障碍朗读
车机语音提示
智能硬件提示音TTS 关注的核心指标:
go
MOS 主观听感
自然度
可懂度
音色一致性
情感表现
实时性
模型大小
端侧运行能力TTS 不只是"能发声",更重要的是"自然、清晰、稳定、低延迟"。
2.4 说话人相关任务
说话人方向包括:
go
Speaker Verification:说话人验证
Speaker Identification:说话人识别
Speaker Diarization:说话人分离 / 分角色
Voiceprint:声纹识别典型应用:
go
声纹登录
会议中区分谁在说话
客服质检
司法录音分析
多人访谈转写
智能门锁其中 Speaker Diarization 在会议场景中非常重要。
它解决的问题不是"说了什么",而是:
go
谁在什么时候说了什么?2.5 声事件检测与音频分类
声事件检测不是识别人说话内容,而是识别环境中发生了什么声音。
常见任务:
go
Audio Tagging
Sound Event Detection
Keyword Spotting
异常声音检测
环境声音分类典型声音事件:
go
玻璃破碎
婴儿哭声
狗叫
警报声
枪声
机械异响
车辆鸣笛
门铃声典型应用:
go
安防监控
智能家居
工业设备检测
车载安全
医疗看护
公共安全三、开源方案总览:如何选择框架和模型
图片中把开源方案分成:
go
A. 通用框架
B. 音频 3A / 前处理
C. ASR 开源方案
D. TTS 开源方案
E. 相关能力工程上选型时,需要区分:
go
训练框架
推理框架
算法库
模型仓库
端侧部署框架
业务集成框架3.1 通用训练与推理框架
图片中列出的通用框架包括:
go
PyTorch
TensorFlow / TensorFlow Lite
ONNX Runtime
NCNN / MNN
Tengine
OpenVINO可以按用途分成两类。
3.1.1 训练框架
常见训练框架:
go
PyTorch
TensorFlow特点:
go
生态成熟
模型多
调试方便
适合研究和训练
社区资源丰富现在语音识别、语音合成、语音增强的大量开源项目都基于 PyTorch。
3.1.2 端侧推理框架
常见推理框架:
go
ONNX Runtime
TensorFlow Lite
NCNN
MNN
Tengine
OpenVINO
TensorRT
RKNN它们主要解决:
go
模型怎么跑得更快?
怎么减少内存?
怎么用 NPU / GPU / DSP?
怎么做 int8 量化?
怎么在 ARM 上实时运行?工程选型建议:
| 场景 | 推荐关注 |
|---|---|
| PC / 服务器推理 | ONNX Runtime / TensorRT |
| Android / 移动端 | TFLite / NCNN / MNN |
| 国产嵌入式平台 | Tengine / MNN / NCNN / RKNN |
| Intel 平台 | OpenVINO |
| Rockchip 平台 | RKNN / rknn-toolkit / rknpu runtime |
3.2 音频 3A / 前处理开源方案
图片中列出的前处理方案包括:
go
WebRTC Audio Processing
SpeexDSP
RNNoise
DeepFilterNet
py-webrtcvad3.2.1 WebRTC Audio Processing
WebRTC Audio Processing 是非常经典的实时音频前处理库,常用于会议、通话、对讲等场景。
常见模块包括:
go
AEC:回声消除
NS:噪声抑制
AGC:自动增益
VAD:语音活动检测
High Pass Filter:高通滤波
Transient Suppression:瞬态噪声抑制特点:
go
工程成熟
实时性强
适合通话场景
生态广泛
可移植到嵌入式设备局限:
go
参数调优复杂
对参考信号同步要求高
复杂噪声下不如深度学习模型3.2.2 SpeexDSP
SpeexDSP 是传统 DSP 风格的音频处理库。
功能包括:
go
回声消除
降噪
自动增益
重采样
抖动缓冲优点:
go
轻量
易集成
适合低算力设备缺点:
go
算法较传统
复杂噪声场景效果有限3.2.3 RNNoise
RNNoise 是一个经典的轻量神经网络降噪方案。
它的特点是:
go
传统 DSP + 小型 RNN 模型
低复杂度
实时性较好
适合语音降噪适合场景:
go
低算力端侧降噪
实时语音增强
嵌入式语音输入前处理3.2.4 DeepFilterNet
DeepFilterNet 是深度学习语音增强方案,主要用于降噪和语音增强。
特点:
go
复杂噪声下效果较好
模型能力强
适合高质量语音增强工程上要关注:
go
模型大小
实时性
CPU / NPU 占用
延迟
帧长
推理框架支持3.2.5 py-webrtcvad
py-webrtcvad 是 WebRTC VAD 的 Python 封装。
主要用于:
go
判断一帧音频是否包含语音
静音切分
ASR 前端切句
降低无效推理它适合做数据处理和原型验证,但真正工程部署时通常会直接集成 C/C++ 版本。
3.3 ASR 开源方案
图片中列出的 ASR 开源方案包括:
go
Whisper / faster-whisper
Vosk / Kaldi
WeNet
FunASR
PaddleSpeech
NVIDIA NeMo
ESPnet
SpeechBrain3.3.1 Whisper / faster-whisper
Whisper 是当前非常流行的通用 ASR 模型。
优点:
go
多语言能力强
鲁棒性好
对噪声和口音适应较好
可做转写和翻译
开箱效果较好faster-whisper 则更偏工程部署,基于 CTranslate2 做推理优化。
适合场景:
go
离线转写
会议记录
字幕生成
多语言识别
录音文件处理需要注意:
go
模型较大
流式实时能力需要额外工程处理
端侧部署需要压缩和加速3.3.2 Kaldi / Vosk
Kaldi 是传统 ASR 工程框架的代表,Vosk 是基于 Kaldi 的轻量部署方案。
特点:
go
工程体系成熟
支持离线识别
可部署在端侧
适合命令词和小词表场景Kaldi 学习成本较高,但对于理解 ASR 传统架构非常有价值。
3.3.3 WeNet
WeNet 是面向流式和非流式 ASR 的端到端语音识别框架。
特点:
go
支持流式识别
工程化程度较好
适合中文 ASR
支持 CTC / Attention / Transducer 等模型思路适合场景:
go
实时字幕
语音助手
在线语音识别
端云结合识别3.3.4 FunASR
FunASR 是比较适合快速搭建中文语音识别系统的开源方案。
常见能力包括:
go
语音识别
标点恢复
热词
时间戳
说话人相关能力适合:
go
中文 ASR 原型验证
会议转写
语音应用快速落地3.3.5 ESPnet / SpeechBrain / NeMo
这些框架更偏研究和综合语音任务平台。
特点:
go
模型丰富
任务覆盖广
适合训练和实验
适合研究人员和算法工程师包括任务:
go
ASR
TTS
Speaker Verification
Speech Enhancement
Diarization
Audio Classification3.4 TTS 开源方案
图片中列出的 TTS 方案包括:
go
Coqui TTS
Piper
ESPnet-TTS
PaddleSpeech TTS
VITS
FastSpeech2
Tacotron23.4.1 Coqui TTS
Coqui TTS 是较完整的 TTS 训练和推理工具链。
特点:
go
模型种类多
训练流程完整
社区资源丰富
适合自定义声音训练3.4.2 Piper
Piper 是轻量化 TTS 方案,适合端侧部署。
特点:
go
推理快
资源占用较低
适合嵌入式语音播报适合:
go
智能家居
离线语音播报
机器人提示音
车机播报3.4.3 ESPnet-TTS / PaddleSpeech TTS
这类框架适合研究和工程结合,支持多种声学模型和声码器。
常见模型:
go
Tacotron2
FastSpeech2
VITS
HiFi-GAN
WaveRNN
WaveGlow3.5 相关能力:KWS、声纹、音频分类
图片中还列出:
go
Keyword Spotting
Speaker Verification
Diarization
Audio Tagging
SED这些能力经常和 ASR / TTS / 3A 组合使用。
KWS:关键词检测
典型场景:
go
你好小微
小爱同学
Hey Siri
OK GoogleKWS 通常要求:
go
低功耗
低延迟
低误唤醒
高召回率
可常驻运行Speaker Verification:说话人验证
判断当前声音是不是某个人。
典型场景:
go
声纹登录
身份认证
门锁验证
金融认证Diarization:说话人分离
回答:
go
谁在什么时候说话?常用于:
go
会议转写
多人访谈
客服质检
法庭记录Audio Tagging / SED
识别环境声音或事件。
典型场景:
go
安防异常声音检测
工业设备异响检测
婴儿哭声检测
玻璃破碎检测四、音频 3A 详解
图片中"音频 3A 详解"包括:
go
AEC 回声消除
ANS / NS 降噪
AGC 自动增益控制
配套模块
典型场景
评价指标音频 3A 是音频前端处理的核心,尤其在通话、会议、对讲和语音交互中非常重要。
4.1 AEC:Acoustic Echo Cancellation,声学回声消除
4.1.1 回声是怎么产生的?
在会议设备、手机免提、智能音箱中,扬声器播放的声音会被麦克风重新采集。
例如:
go
远端说话
↓
本地扬声器播放
↓
声音经过空气传播和房间反射
↓
本地麦克风采集到扬声器声音
↓
再发回远端
↓
远端听到自己的回声这就是声学回声。
4.1.2 AEC 基本原理
AEC 需要两个信号:
go
麦克风信号 mic
扬声器参考信号 reference基本模型:
go
mic = near_speech + echo + noise
echo_estimate = adaptive_filter(reference)
output = mic - echo_estimate也就是说,AEC 会根据播放参考信号估计回声路径,然后从麦克风信号中减掉估计出来的回声。
4.1.3 AEC 的核心难点
AEC 难点很多:
go
回声路径随环境变化
播放和采集存在延迟
扬声器可能有非线性失真
房间混响复杂
双讲场景容易误消人声
设备时钟可能漂移尤其是双讲场景:
go
远端在说话
本地也在说话这时 AEC 既要消除远端回声,又不能把本地人声消掉,非常考验算法稳定性。
4.1.4 AEC 工程关键点
工程落地时重点关注:
go
参考信号是否正确
播放和采集是否同步
回声尾长是否足够
延迟估计是否准确
双讲检测是否稳定
残余回声抑制是否自然常见问题:
| 现象 | 可能原因 |
|---|---|
| 回声消不掉 | 参考信号错误、延迟不准、尾长不足 |
| 本地声音被压制 | 双讲检测失败 |
| 声音忽大忽小 | AGC 和 AEC 配合不好 |
| 有金属音 | 过度抑制或非线性处理异常 |
4.2 ANS / NS:噪声抑制
4.2.1 噪声类型
常见噪声包括:
go
空调声
风噪
键盘声
电流声
车噪
人群背景声
机械噪声
环境混响NS 的目标是:
go
保留语音
抑制噪声
尽量减少语音失真4.2.2 传统降噪方法
传统方法包括:
go
频谱减法
维纳滤波
MMSE
噪声谱估计
语音存在概率估计一般流程:
go
分帧
↓
STFT
↓
估计噪声谱
↓
计算增益 / mask
↓
抑制噪声频段
↓
iSTFT4.2.3 深度学习降噪
深度学习降噪通常让模型预测:
go
频谱 mask
增强后的频谱
增强后的波形代表方向:
go
RNNoise
DeepFilterNet
DCCRN
Demucs 类模型优势:
go
复杂噪声下效果更好
能学习语音和噪声特征
主观听感更自然挑战:
go
算力占用高
延迟控制难
模型部署复杂
可能产生音乐噪声或语音失真4.3 AGC:Automatic Gain Control,自动增益控制
AGC 的目标是让语音音量保持在合适范围。
问题场景:
go
说话人离麦克风远,声音太小
突然大声说话,声音过大
不同人说话音量差异大
录音电平不稳定AGC 会动态调整增益:
go
输入电平检测
↓
目标电平计算
↓
增益平滑
↓
峰值限制
↓
输出稳定音量工程要点:
go
attack 时间
release 时间
目标电平
最大增益
限幅器
噪声门限常见问题:
go
增益太大导致噪声被放大
增益变化太快产生泵声
限幅不好导致削波
和 AEC / NS 顺序不合理4.4 配套模块:VAD、Beamforming、DOA、Dereverb
4.4.1 VAD:语音活动检测
VAD 用于判断当前帧是否有人声。
用途:
go
静音切分
ASR 前端
节省算力
语音唤醒
降噪辅助
会议分段4.4.2 Beamforming:波束形成
Beamforming 需要多麦阵列。
目标:
go
增强目标方向语音
抑制其他方向噪声
提升远场语音质量典型应用:
go
智能音箱
会议设备
车载语音
机器人4.4.3 DOA:声源定位
DOA 用于估计声音来自哪个方向。
常用原理:
go
不同麦克风之间的到达时间差
相位差
阵列几何关系应用:
go
摄像头自动转向
会议发言人定位
机器人听声辨位4.4.4 Dereverb:去混响
混响来自房间反射。
去混响目标是提升语音清晰度和 ASR 识别率。
4.5 音频 3A 评价指标
图片中列出:
go
ERLE
PESQ
STOI
SNR
RTF
CPU 占用
延迟解释如下:
| 指标 | 含义 |
|---|---|
| ERLE | 回声返回损耗增强,衡量 AEC 效果 |
| PESQ | 感知语音质量 |
| STOI | 语音可懂度 |
| SNR | 信噪比 |
| RTF | 实时率,越小越好 |
| CPU 占用 | 端侧运行成本 |
| 延迟 | 实时通话关键指标 |
工程上不能只看一个指标。
例如降噪很强但语音失真严重,ASR 可能反而变差。
五、ASR 语音识别原理
图片中的 ASR 流程是:
go
音频输入
↓
VAD / 分帧
↓
特征提取:MFCC / FBank
↓
声学模型
↓
解码器
↓
文本后处理5.1 音频输入与分帧
ASR 处理的是连续语音,但模型通常按帧处理。
常见参数:
go
采样率:16kHz / 8kHz / 48kHz
帧长:20ms / 25ms
帧移:10ms
格式:PCM S16LE / Float32分帧后通常会加窗:
go
Hamming Window
Hann Window然后做频域分析。
5.2 特征提取:MFCC / FBank
FBank
FBank 是 Mel Filter Bank 特征,是现代 ASR 中非常常用的输入特征。
流程:
go
PCM
↓
分帧加窗
↓
FFT
↓
功率谱
↓
Mel 滤波器组
↓
log
↓
FBank 特征MFCC
MFCC 在 FBank 基础上再做 DCT,得到倒谱系数。
传统 ASR 常用 MFCC,端到端模型更常用 FBank 或 log-Mel。
5.3 声学模型
声学模型负责把音频特征映射成文本相关单元。
常见模型结构:
go
DNN-HMM
CTC
Attention
Transformer
Conformer
RNN-T / TransducerDNN-HMM
传统 ASR 体系,HMM 负责时序建模,DNN 负责声学建模。
CTC
CTC 解决输入输出长度不一致问题,不需要帧级对齐。
Attention / Transformer
适合端到端建模,表达能力强。
RNN-T / Transducer
适合流式识别,可以边听边输出。
Conformer
结合 CNN 和 Transformer,常见于现代 ASR,既建模局部特征,也建模长距离上下文。
5.4 解码器
解码器把模型输出转换为最终文本。
常见方法:
go
Greedy Search
Beam Search
CTC Prefix Beam Search
Attention Rescoring
Language Model Fusion
Hotword Biasing工程中常见需求:
go
热词增强
命令词识别
时间戳输出
流式 partial result
标点恢复
数字规范化5.5 文本后处理
ASR 输出通常还需要后处理:
go
标点恢复
ITN 逆文本规范化
数字格式化
热词修正
敏感词过滤
分段
时间戳对齐例子:
go
一九九八年三月五日
→ 1998年3月5日
今天气温二十三点五度
→ 今天气温23.5度5.6 ASR 工程指标
ASR 常用指标:
go
WER
CER
RTF
首包延迟
端到端延迟
内存占用
CPU / NPU 占用
鲁棒性工程上要区分:
go
离线转写:更关注准确率
实时识别:更关注延迟和流式能力
端侧识别:更关注模型大小和算力
命令词识别:更关注误唤醒率和召回率六、TTS 语音合成原理
图片中的 TTS 流程是:
go
文本输入
↓
文本归一化 TN / ITN
↓
分词 / G2P
↓
声学模型
↓
Vocoder 声码器
↓
音频输出6.1 文本归一化
TTS 不能直接把原始文本丢给模型,因为文本中有大量非标准写法。
例如:
go
2026年
3.14
¥25.8
AI
USB
10:30这些都需要转换成可朗读形式。
文本归一化解决:
go
数字读法
日期读法
时间读法
金额读法
单位读法
英文缩写
符号处理6.2 分词与 G2P
G2P 是 Grapheme To Phoneme,即字形到音素。
中文 TTS 中通常涉及:
go
分词
多音字消歧
拼音转换
声调预测
韵律边界预测英文 TTS 中涉及:
go
单词到音标
重音
连读
弱读G2P 做不好,TTS 会出现读错字、断句怪、语调不自然等问题。
6.3 声学模型
声学模型负责把文本或音素序列转换成声学特征。
常见模型:
go
Tacotron2
FastSpeech2
VITS
Glow-TTS
Grad-TTSTacotron2
自回归模型,经典但推理速度相对慢,可能出现漏读、重复读。
FastSpeech2
非自回归模型,速度快、稳定性好,适合工程部署。
VITS
端到端生成式 TTS,声音自然度较好,常用于高质量语音合成。
6.4 Vocoder 声码器
声码器把声学特征转换成波形。
常见声码器:
go
WaveNet
WaveRNN
WaveGlow
HiFi-GAN
BigVGAN现代工程中 HiFi-GAN 类声码器使用较多,因为:
go
音质好
推理快
可端侧优化6.5 TTS 高级能力
图片中提到:
go
多说话人
情感语音
克隆 / 零样本
中英混读扩展能力包括:
go
音色克隆
语速控制
音高控制
情绪控制
风格迁移
多语言合成
个性化音色这些能力通常需要更复杂的数据、模型和后处理。
6.6 TTS 评价指标
常见指标:
go
MOS
自然度
可懂度
音色一致性
实时性
模型大小工程上要关注:
go
合成延迟
首包延迟
流式播放能力
端侧 CPU 占用
模型体积
多音字准确率
长文本稳定性七、训练与部署流程
图片中训练与部署流程分为:
go
A. 训练流程
B. 部署流程7.1 训练流程
图片中的训练流程是:
go
数据采集
↓
标注 / 转写
↓
清洗切分
↓
特征提取
↓
模型训练
↓
验证评估
↓
剪枝 / 量化 / 优化
↓
导出模型7.1.1 数据采集
数据是模型效果上限。
不同任务需要不同数据:
| 任务 | 数据 |
|---|---|
| ASR | 语音 + 文本标注 |
| TTS | 文本 + 高质量录音 |
| 降噪 | 干净语音 + 噪声 |
| AEC | 麦克风信号 + 参考信号 |
| 声纹 | 说话人音频 |
| 声事件 | 音频片段 + 事件标签 |
7.1.2 标注与转写
ASR 需要准确转写文本。
TTS 需要文本与录音匹配。
声事件检测需要时间段标签。
标注质量直接影响模型效果。
7.1.3 清洗与切分
数据清洗包括:
go
去除坏样本
去除过长静音
去除噪声异常样本
统一采样率
响度归一化
切分语音片段
文本规范化7.1.4 特征提取
常见特征:
go
FBank
MFCC
Mel Spectrogram
STFT
Pitch
EnergyASR 常用 FBank。
TTS 常用 Mel Spectrogram。
语音增强常用 STFT 或波形输入。
7.1.5 模型训练
训练阶段关注:
go
模型结构
损失函数
优化器
学习率
batch size
数据增强
训练稳定性
过拟合常见增强方式:
go
加噪
混响
速度扰动
音量扰动
SpecAugment
随机裁剪7.1.6 验证评估
ASR 看:
go
WER
CER
RTFTTS 看:
go
MOS
自然度
发音准确率
音色一致性降噪看:
go
PESQ
STOI
SNR
主观听感7.1.7 模型优化与导出
端侧部署前常做:
go
剪枝
量化
蒸馏
算子融合
模型压缩导出格式:
go
ONNX
TFLite
NCNN
RKNN7.2 部署流程
图片中的部署流程包括:
go
导出 ONNX / TFLite / NCNN / RKNN
端侧推理 CPU / GPU / NPU / DSP
流式推理与缓存管理
AEC 参考同步 / 多麦阵列适配
性能优化:线程、SIMD、内存池、DMA
工程集成:ALSA / ASoC / GStreamer / FFmpeg / 网络传输7.2.1 模型格式转换
常见转换链路:
go
PyTorch
↓
ONNX
↓
ONNX Runtime / TensorRT / RKNN / NCNN或者:
go
TensorFlow
↓
TFLite
↓
端侧推理注意事项:
go
算子是否支持
动态 shape 是否支持
量化方式是否一致
输入输出布局是否正确
精度是否下降7.2.2 端侧推理
端侧推理需要关注:
go
CPU 占用
NPU 利用率
内存占用
模型加载时间
实时性
线程调度
功耗音频模型尤其关注:
go
流式输入
状态缓存
低延迟
稳定实时7.2.3 流式推理
语音任务通常不能等用户说完很久才处理,而是要边采集边处理。
流式推理需要:
go
环形缓冲区
分帧
滑窗
状态缓存
chunk 处理
延迟控制ASR 流式识别要处理:
go
partial result
final result
endpoint detection
上下文缓存7.2.4 工程集成
最终模型要接入真实系统:
go
ALSA / ASoC 采集
音频重采样
音频前处理
模型推理
结果输出
网络传输
业务逻辑例如语音助手:
go
ALSA 采集
↓
AEC / NS / AGC
↓
VAD
↓
KWS
↓
ASR
↓
NLU
↓
TTS
↓
ALSA 播放八、工程落地要点
图片中"工程落地要点"包括:
go
采样率 / 位宽 / 声道
接口
系统
流媒体
容器与编码
延迟优化
调试工具8.1 采样率 / 位宽 / 声道
常见配置:
go
8kHz / 16kHz / 48kHz
16bit / 24bit
单麦 / 双麦 / 阵列工程建议:
| 场景 | 常用采样率 |
|---|---|
| 电话语音 | 8kHz |
| ASR | 16kHz |
| 会议 / 通话 | 16kHz / 48kHz |
| 高质量音频 | 44.1kHz / 48kHz |
8.2 音频接口
常见接口:
go
I2S
TDM
PDM
DMIC
USB Audio工程上要关注:
go
通道顺序
采样率
位宽
主从模式
时钟同步
DMA buffer8.3 系统层
常见系统组件:
go
ALSA
ASoC
TinyALSA
回放 / 录音通路调试命令:
go
arecord -l
aplay -l
arecord -D hw:0,0 -f S16_LE -r 16000 -c 2 test.wav
aplay test.wav
amixer
tinymix8.4 流媒体
音频常见协议:
go
RTP
RTSP
WebRTC
RTMP语音通信优先关注:
go
低延迟
抖动缓冲
丢包恢复
回声消除
音频同步8.5 容器与编码
常见格式:
go
PCM
WAV
AAC
Opus
G.711
MP3工程选型:
| 场景 | 推荐 |
|---|---|
| 原始采集 | PCM / WAV |
| 实时通信 | Opus |
| MP4 录制 | AAC |
| 电话 / 对讲 | G.711 |
| 通用播放 | MP3 / AAC |
8.6 延迟优化
延迟来源:
go
帧长
缓冲深度
回采同步
回声尾长
流式 chunk
网络抖动缓冲优化思路:
go
减小帧长
减少缓存层级
优化线程调度
使用实时优先级
减少拷贝
固定音频时钟
降低模型推理延迟8.7 调试工具
常用工具:
go
arecord
aplay
amixer
tinymix
ffmpeg
gst-launch
Wireshark
perf典型排查:
go
没声音 → 查声卡、mixer、路由、采样率
声音卡顿 → 查 buffer、CPU、线程、DMA
有回声 → 查 AEC reference、延迟、双讲
识别率低 → 查采样率、前处理、噪声、模型输入
延迟高 → 查帧长、缓存、网络、模型推理九、当前应用产品
图片底部列出当前音频 AI 的应用产品形态,包括:
go
智能语音终端
会议与办公
消费电子
车载智能
安防与边缘设备
机器人与 IoT
教育与阅读
客服与媒体
无障碍与医疗9.1 智能语音终端
典型产品:
go
智能音箱
语音助手
AI 对话陪伴设备核心能力:
go
唤醒词检测
远场语音识别
语音合成
多轮对话
音频 3A9.2 会议与办公
典型产品:
go
会议终端
实时字幕盒子
录音转写设备
会议纪要系统核心能力:
go
AEC
NS
Beamforming
ASR
Diarization
会议摘要
关键词提取9.3 消费电子
典型产品:
go
TWS 耳机
主动降噪耳机
手机语音助手
平板语音助手核心能力:
go
通话降噪
回声消除
低功耗唤醒
本地语音识别
语音播报9.4 车载智能
典型产品:
go
车机语音助手
免提通话
车内降噪
语音控制难点:
go
车噪复杂
多人说话
远场拾音
唤醒鲁棒性
低延迟交互9.5 安防与边缘设备
典型产品:
go
IPC 摄像机
楼宇门铃
智能门锁
对讲终端核心能力:
go
语音对讲
噪声抑制
异常声音检测
本地 ASR
低功耗运行9.6 机器人与 IoT
典型产品:
go
服务机器人
家庭中控
儿童陪伴机器人
工业机器人核心能力:
go
远场拾音
语音识别
语音合成
声源定位
多模态交互9.7 教育与阅读
典型产品:
go
翻译机
点读笔
学习平板
口语陪练核心能力:
go
ASR 评测
TTS 朗读
发音评分
离线识别
多语言支持9.8 客服与媒体
典型产品:
go
呼叫中心质检
语音客服
直播降噪麦克风
自动字幕生成核心能力:
go
ASR
说话人分离
情绪识别
关键词检测
降噪增强9.9 无障碍与医疗
典型产品:
go
助听器
语音播报终端
康复辅助设备
医疗语音记录核心能力:
go
语音增强
实时字幕
语音播报
噪声抑制
个性化听力补偿十、学习顺序与能力目标
图片中给出的学习顺序是:
go
音频基础
↓
驱动与采集链路
↓
3A 前处理
↓
ASR / TTS
↓
模型训练
↓
部署优化
↓
产品化建议按以下路径执行。
10.1 第一阶段:音频基础
重点掌握:
go
采样率
位宽
声道
PCM
WAV
STFT
FFT
滤波
分帧
延迟
同步10.2 第二阶段:驱动与采集链路
重点掌握:
go
ALSA
ASoC
I2S
TDM
PDM
DMIC
麦克风阵列
DMA
mixer route目标是能稳定录音和播放。
10.3 第三阶段:3A 前处理
重点掌握:
go
AEC
NS
AGC
VAD
Beamforming
DOA
Dereverb目标是提升语音质量,为 ASR 和通话打基础。
10.4 第四阶段:ASR / TTS
重点掌握:
go
Whisper
WeNet
FunASR
Vosk
Coqui
Piper
VITS
FastSpeech目标是能完成:
go
语音转文字
文字转语音
离线转写
实时识别
端侧播报10.5 第五阶段:模型训练
重点掌握:
go
数据采集
数据标注
特征提取
模型训练
模型评估
数据增强目标是能根据业务数据微调或训练模型。
10.6 第六阶段:部署优化
重点掌握:
go
ONNX
TFLite
NCNN
RKNN
量化
剪枝
多线程
SIMD
NPU 加速
流式推理目标是能在端侧实时运行。
10.7 第七阶段:产品化
重点掌握:
go
稳定性
低延迟
功耗
异常恢复
日志系统
升级机制
业务集成目标是从 demo 变成产品。
十一、常见能力对比
图片底部有一个常见能力对比表,可以扩展如下:
| 模块 | 目标 | 常见方案 | 关键指标 |
|---|---|---|---|
| 3A | 通话质量提升 | WebRTC / RNNoise / SpeexDSP | ERLE / PESQ / 延迟 |
| ASR | 语音转文字 | Whisper / WeNet / Vosk / FunASR | WER / CER / RTF |
| TTS | 文字转语音 | Coqui / Piper / ESPnet-TTS / VITS | MOS / 延迟 / 模型大小 |
| 部署 | 端侧运行 | ONNX Runtime / TFLite / NCNN / RKNN | 内存 / CPU / 实时性 |
十二、工程师视角总结
音频 AI 不是简单调用一个模型,也不是只会跑 Whisper 或 TTS demo。
真正的音频 AI 工程要打通:
go
音频采集
↓
格式转换
↓
音频 3A
↓
特征提取
↓
ASR / TTS / KWS / 声纹 / 声事件模型
↓
模型优化
↓
端侧部署
↓
产品集成工程师需要具备三类能力:
go
第一,音频基础能力:懂采样、频谱、滤波、延迟、同步。
第二,算法理解能力:懂 3A、ASR、TTS、KWS、声纹、声事件。
第三,工程落地能力:懂 ALSA、ASoC、模型部署、性能优化、产品集成。最终目标是:
go
能做录音 / 回放
能调通音频 3A
能做 ASR 转写
能做 TTS 播报
能训练和优化模型
能部署到嵌入式端侧
能解决延迟、噪声、回声、性能和稳定性问题这才是音频 AI / Speech 工程化落地的完整能力闭环。