新晋码农一枚,小编会定期整理一些写的比较好的代码和知识点,作为自己的学习笔记,试着做一下批注和补充,转载或者参考他人文献会标明出处,非商用,如有侵权会删改!欢迎大家斧正和讨论!本章内容较多,可点击文章目录进行跳转!
小编整理和学习了机器学习的相关知识,可作为扫盲使用,后续也会更新一些技术类的文章,大家共同交流学习!您的点赞、关注、收藏就是对小编最大的动力!
系列文章目录
从 SLP 到 MLP:鸢尾花分类实验全解析 ------ 神经网络入门必做实验【万字长文,一文搞定!】
基于 ESP32 的冷链物流工业物联网(IIoT)监控系统|全流程实战
四种经典降维方法全实验:SVD、PCA、LDA、ISOMAP 从原理到代码
机器学习---聚类四大算法完整实验教程(层次 / K-Means/GMM/ 谱聚类)
目录
目录
[1.1 环境与依赖](#1.1 环境与依赖)
[1.2 实验目标](#1.2 实验目标)
[1.3 数据集](#1.3 数据集)
[三、实验 1:层次聚类 ------ 4 种链接方式对比](#三、实验 1:层次聚类 —— 4 种链接方式对比)
[3.1 原理(小白版)](#3.1 原理(小白版))
[3.2 完整代码](#3.2 完整代码)
[3.3 实验结论(直接抄报告)](#3.3 实验结论(直接抄报告))
[四、实验 2:K-Means ------ 改簇数 k=2,3,4,5](#四、实验 2:K-Means —— 改簇数 k=2,3,4,5)
[4.1 原理(小白版)](#4.1 原理(小白版))
[4.2 完整代码](#4.2 完整代码)
[4.3 实验结论](#4.3 实验结论)
[五、实验 3:GMM 软聚类 + 噪声测试](#五、实验 3:GMM 软聚类 + 噪声测试)
[5.1 原理(小白版)](#5.1 原理(小白版))
[5.2 完整代码](#5.2 完整代码)
[5.3 实验结论](#5.3 实验结论)
[六、实验 4:谱聚类 ------ gamma 与拉普拉斯归一化](#六、实验 4:谱聚类 —— gamma 与拉普拉斯归一化)
[6.1 原理](#6.1 原理)
[6.2 完整代码](#6.2 完整代码)
[6.3 实验结论](#6.3 实验结论)
前言
小编作为新晋码农一枚,会定期整理一些写的比较好的代码,作为自己的学习笔记,会试着做一下批注和补充,如转载或者参考他人文献会标明出处,非商用,如有侵权会删改!欢迎大家斧正和讨论!
大家好,这篇博客专门写给机器学习新手 ,用最经典的 Iris 数据集,手把手带你完成层次聚类、K-Means、GMM、谱聚类 四大无监督聚类算法的完整实验。
全程不用懂复杂数学,只需要复制代码、改几个参数,就能跑出结果、看懂图表、写完实验报告。
一、实验准备
1.1 环境与依赖
- 工具:PyCharm(任何版本都行)
- 语言:Python 3.7+
- 安装依赖(PyCharm 终端运行)
bash
pip install numpy matplotlib scikit-learn scipy1.2 实验目标
- 对比层次聚类 4 种链接方式
- 测试 K-Means 不同簇数 k 的效果
- 验证 GMM 软聚类与抗噪能力
- 调参谱聚类的 gamma 与拉普拉斯归一化
- 用 ARI 指标客观评估聚类效果
1.3 数据集
Iris 鸢尾花数据集:150 个样本、4 个特征、3 个真实类别。聚类是无监督学习,算法不会使用标签,只在评估时用到。
二、通用基础代码(必须先跑)
所有算法共用这一段:数据加载、标准化、PCA 降维、评估函数。
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
from sklearn.metrics import accuracy_score, adjusted_rand_score
from scipy.optimize import linear_sum_assignment
# 加载数据
iris = load_iris()
X = iris.data
y = iris.target
# 标准化(聚类必须做)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# PCA降到2维画图
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
# 聚类评估函数(匈牙利匹配+ARI)
def evaluate_clustering(y_true, y_pred):
D = max(y_pred.max(), y_true.max()) + 1
cost_matrix = np.zeros((D, D), dtype=int)
for i in range(len(y_true)):
cost_matrix[y_pred[i], y_true[i]] += 1
row_ind, col_ind = linear_sum_assignment(-cost_matrix)
new_labels = np.zeros_like(y_pred)
for i, j in zip(row_ind, col_ind):
new_labels[y_pred == i] = j
acc = accuracy_score(y_true, new_labels)
ari = adjusted_rand_score(y_true, new_labels)
return acc, ari三、实验 1:层次聚类 ------ 4 种链接方式对比
3.1 原理
层次聚类从 "每个点自己是一类" 开始,一步步合并最像的类。合并规则叫 linkage,一共 4 种:
- single:按最近点距离合并
- complete:按最远点距离合并
- average:按平均距离合并
- ward:最小化类内方差(最适合数值数据)
3.2 完整代码
python
from scipy.cluster.hierarchy import linkage, fcluster, dendrogram
# 对比4种链接方式
methods = ['single', 'complete', 'average', 'ward']
for method in methods:
Z = linkage(X_scaled, method=method)
y_pred = fcluster(Z, t=3, criterion='maxclust') - 1 # 转0开始
acc, ari = evaluate_clustering(y, y_pred)
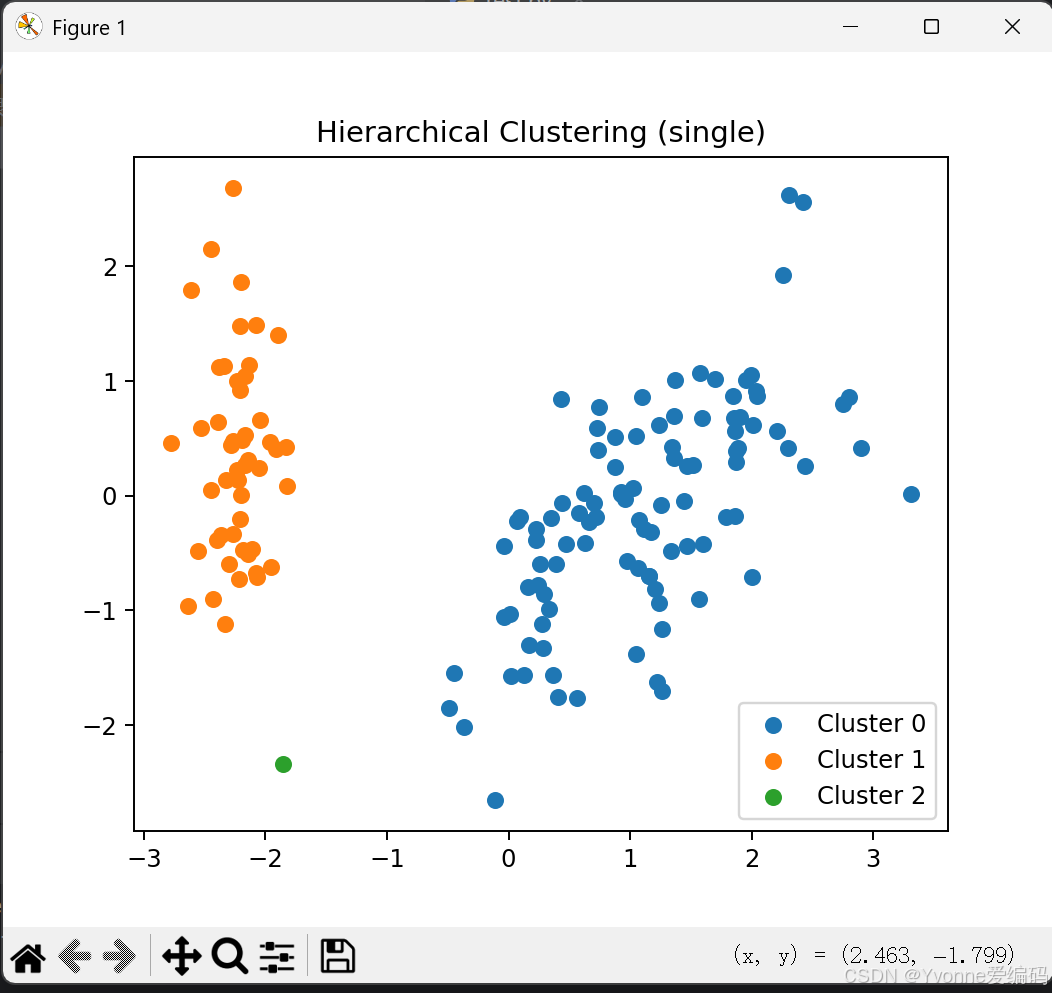
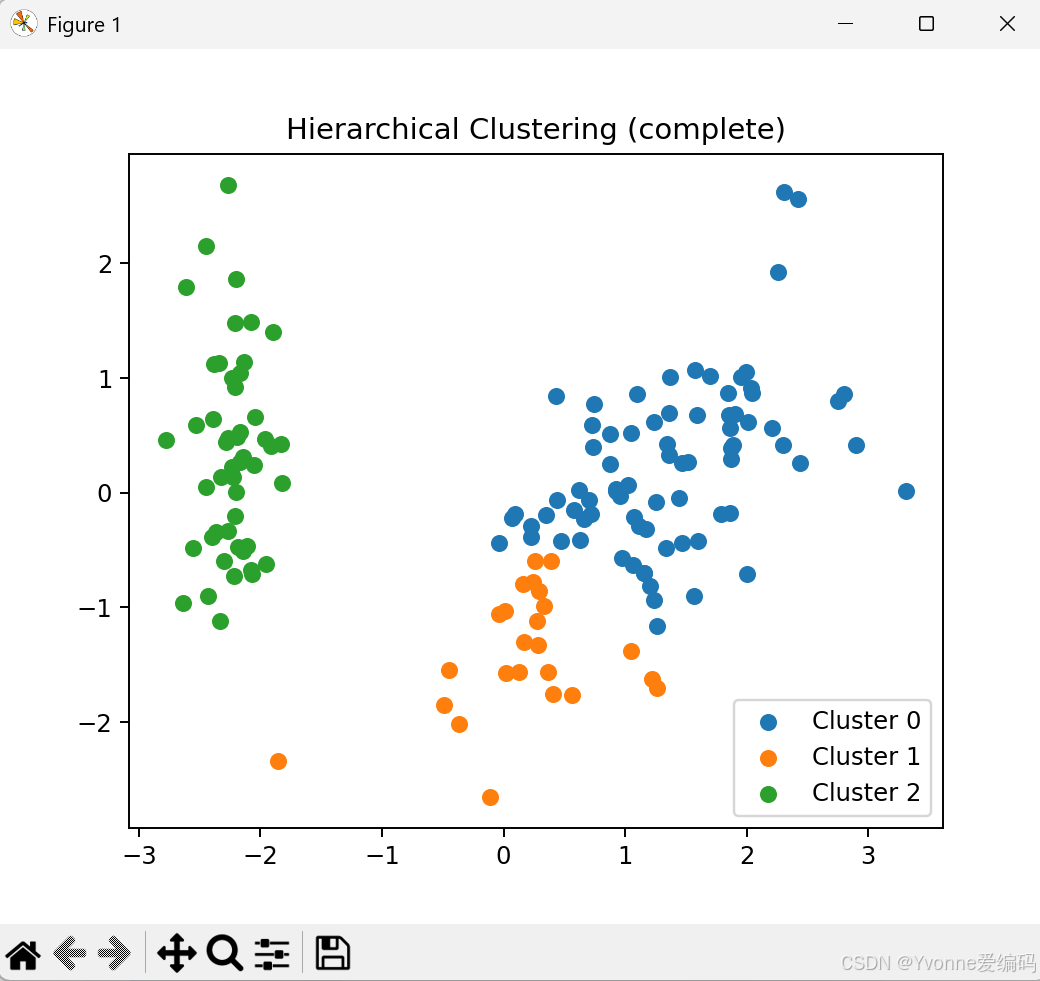
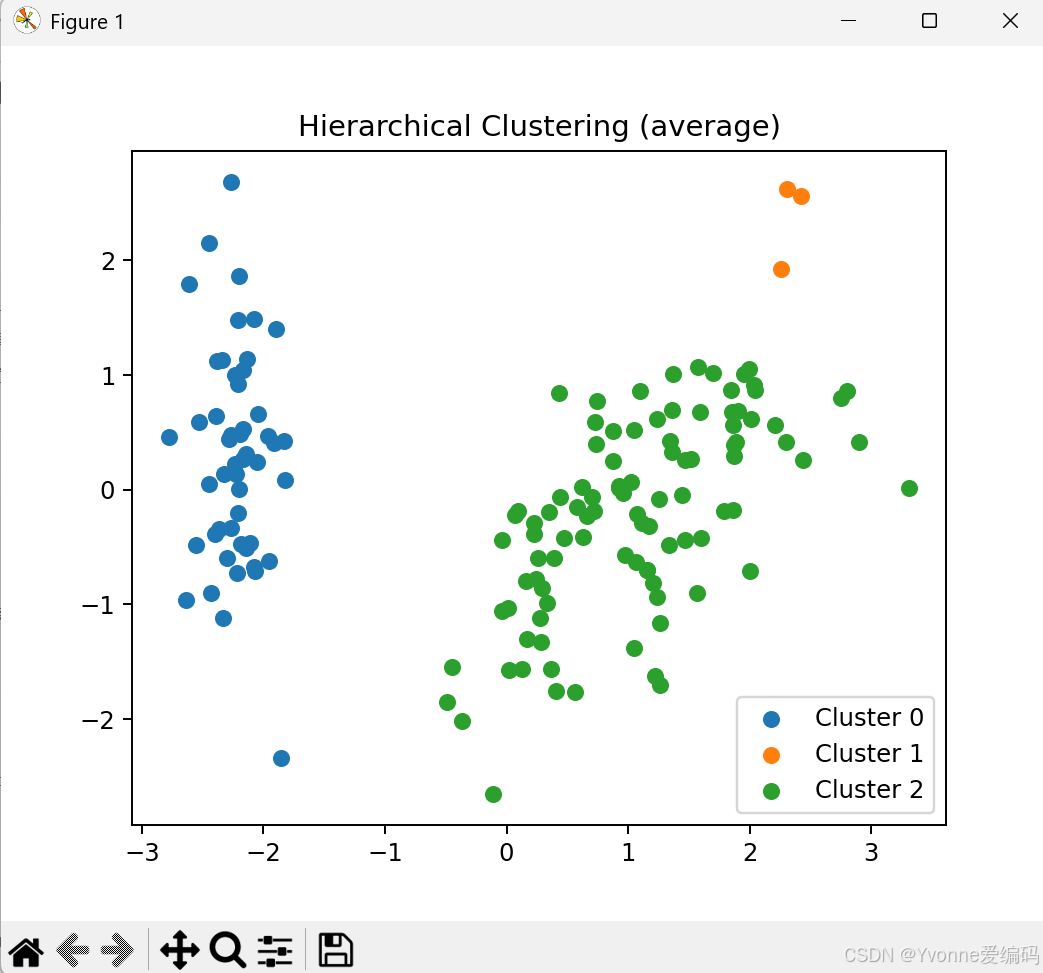
print(f"【层次聚类-{method}】准确率:{acc:.2f} ARI:{ari:.2f}")
# 画图
plt.figure(figsize=(6,5))
for i in range(3):
plt.scatter(X_pca[y_pred==i,0], X_pca[y_pred==i,1], label=f'Cluster {i}')
plt.title(f"Hierarchical Clustering ({method})")
plt.legend()
plt.show(block=False)
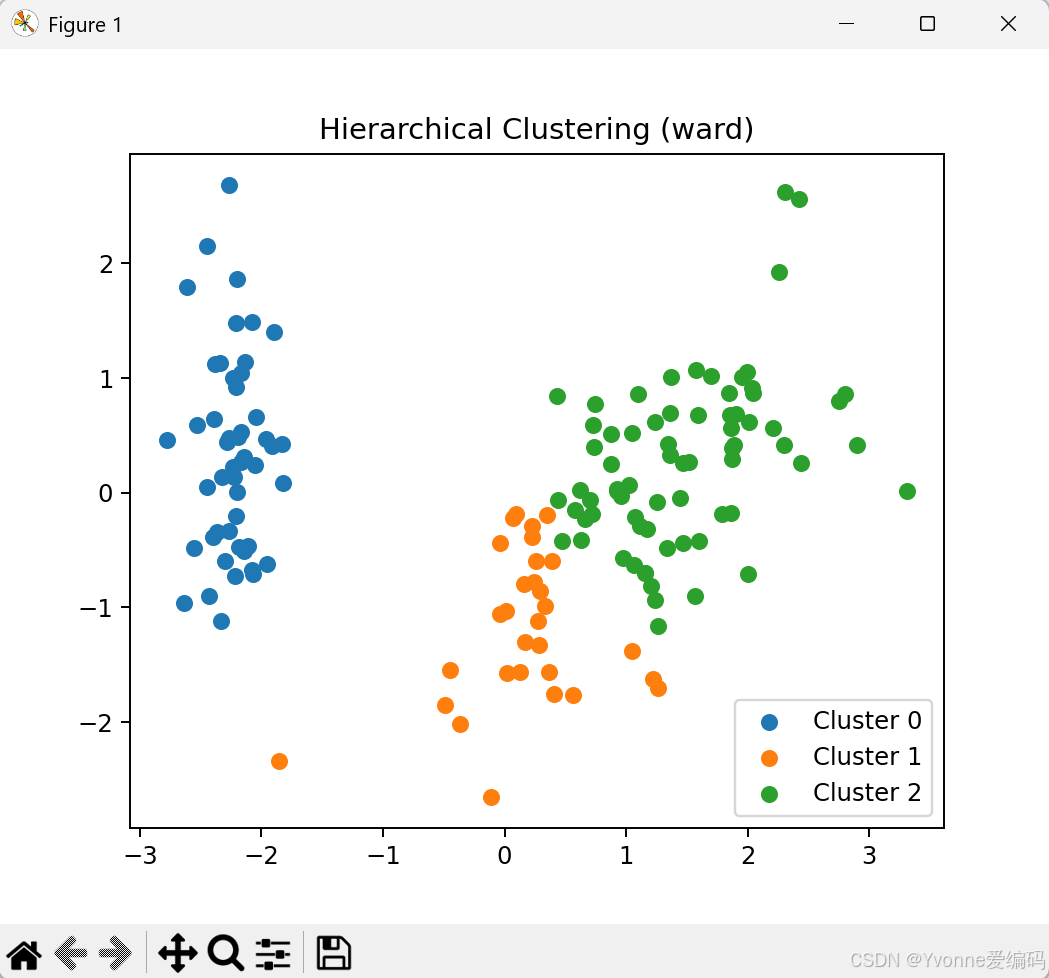
3.3 实验结论
- single 最差:容易把不同类 "链" 在一起
- complete / average:中等稳定
- ward 最好:簇更紧凑,与真实标签最接近
- ARI 越高表示聚类越准
四、实验 2:K-Means ------ 改簇数 k=2,3,4,5
4.1 原理
K-Means 找 k 个中心点,把点分到最近的中心。k 需要自己指定,这是最大缺点。
4.2 完整代码
python
def kmeans(X, k=3, max_iter=100, tol=1e-4):
idx = np.random.choice(len(X), k, replace=False)
centers = X[idx]
for _ in range(max_iter):
dists = np.linalg.norm(X[:, None] - centers, axis=2)
labels = np.argmin(dists, axis=1)
new_centers = np.array([X[labels==i].mean(axis=0) for i in range(k)])
if np.linalg.norm(new_centers - centers) < tol:
break
centers = new_centers
return labels
# 测试k=2,3,4,5
for k in [2,3,4,5]:
y_pred = kmeans(X_scaled, k=k)
acc, ari = evaluate_clustering(y, y_pred)
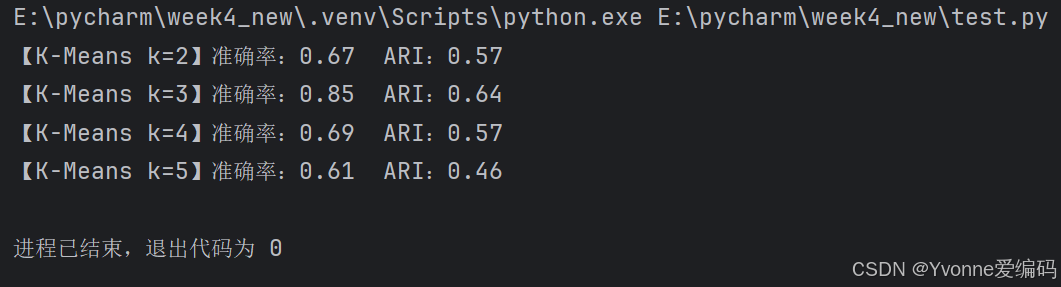
print(f"【K-Means k={k}】准确率:{acc:.2f} ARI:{ari:.2f}")
plt.figure(figsize=(6,5))
for i in range(k):
plt.scatter(X_pca[y_pred==i,0], X_pca[y_pred==i,1], label=f'Cluster {i}')
plt.title(f"K-Means k={k}")
plt.legend()
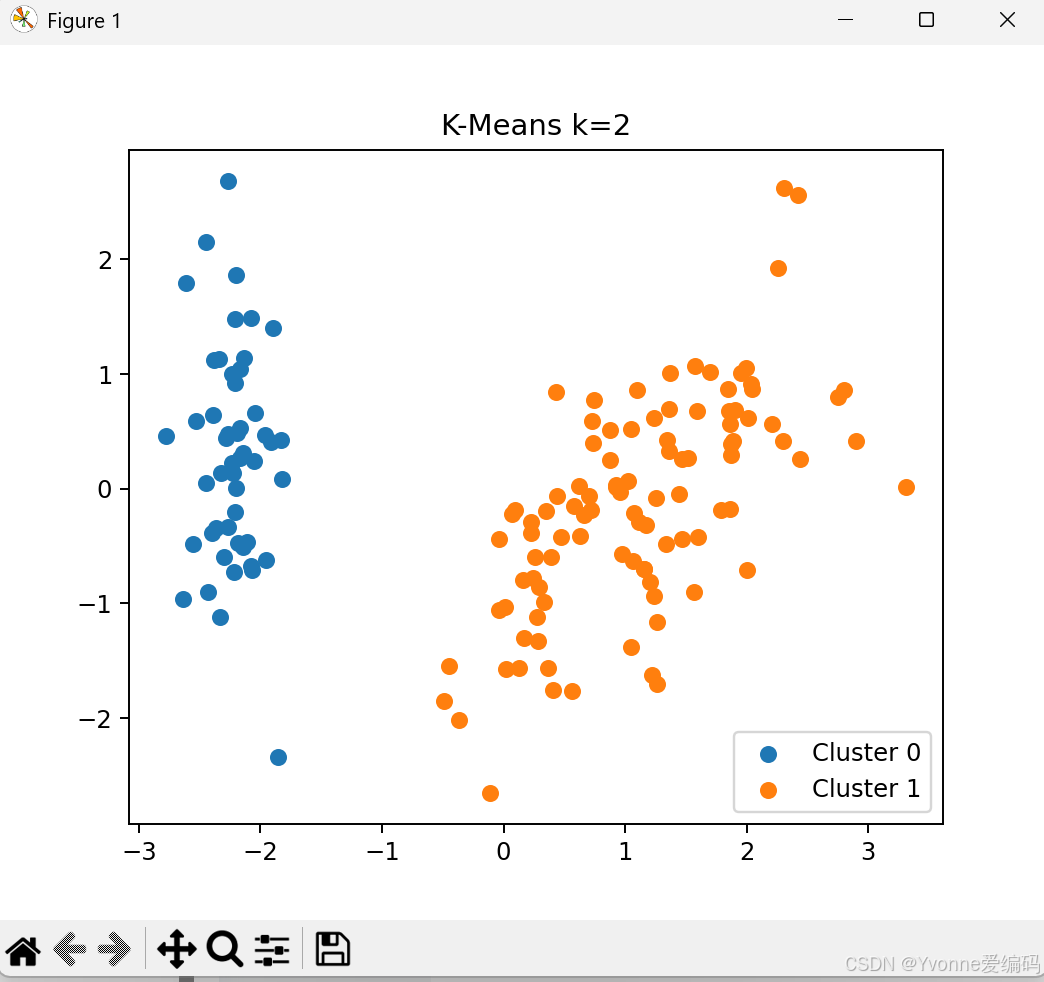
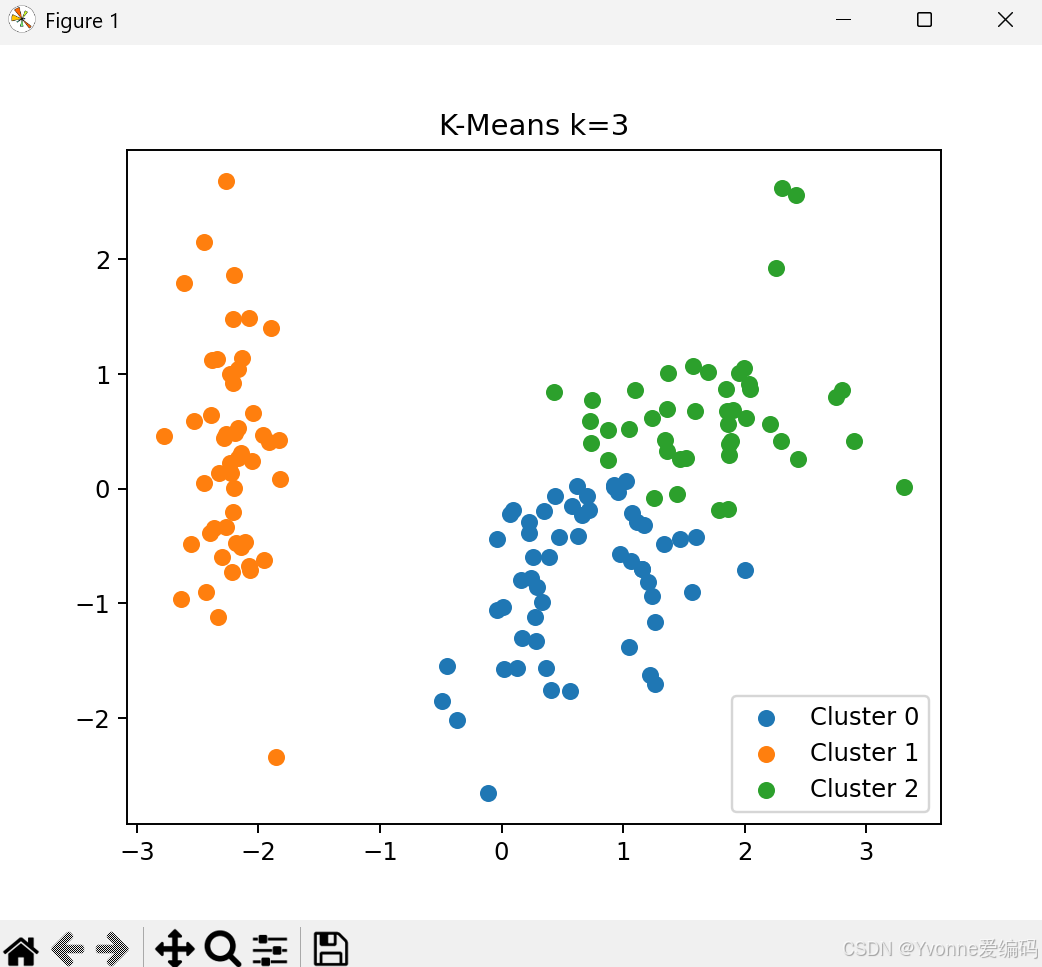
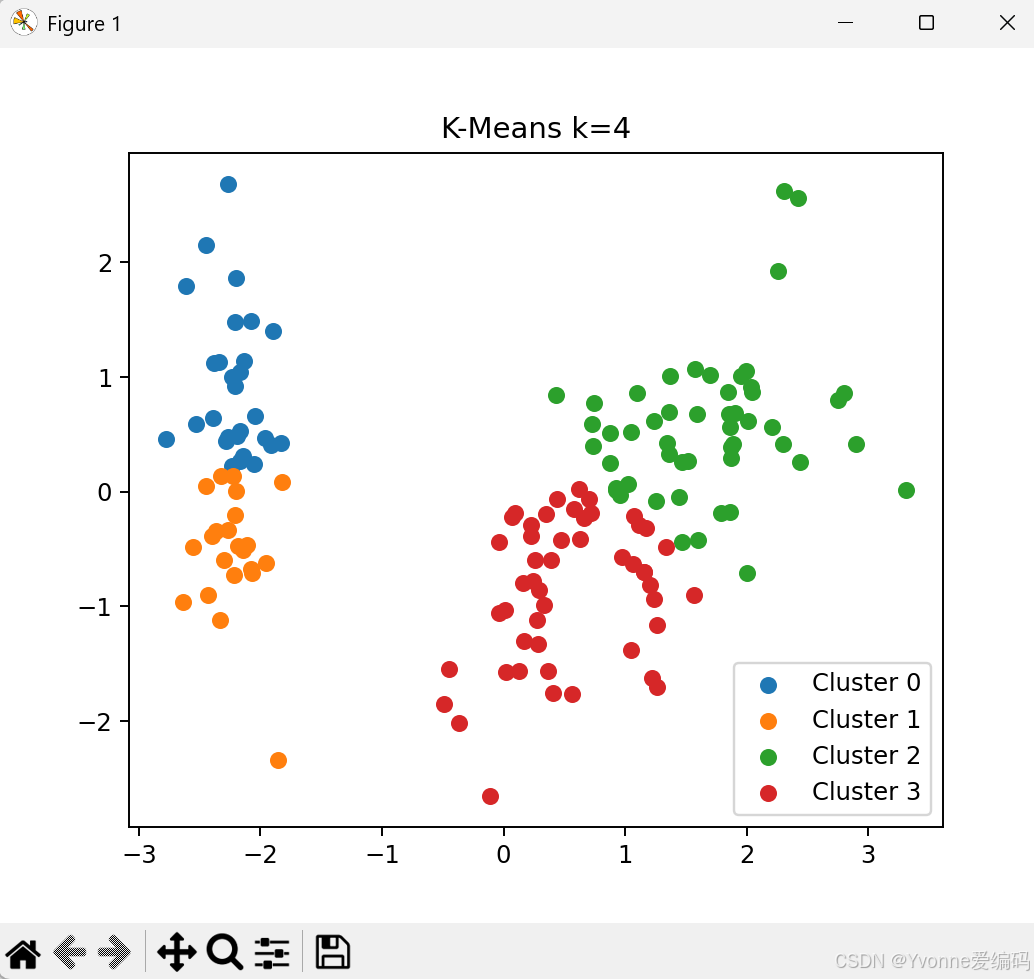
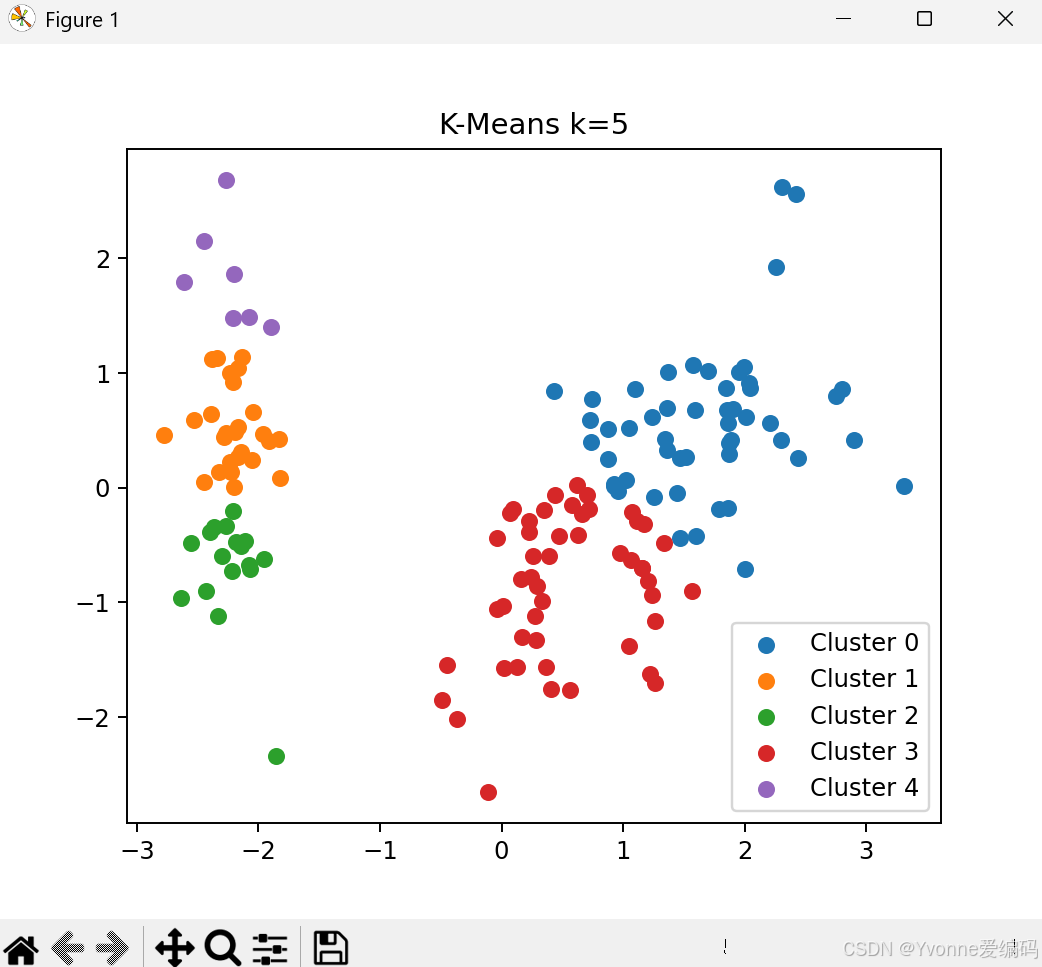
plt.show()4.3 实验结论
- k=3 效果最好(与真实类别一致)
- k 太小:类别合并
- k 太大:类别被拆碎
- K-Means 速度快,但只能分球形簇
五、实验 3:GMM 软聚类 + 噪声测试
5.1 原理
GMM 假设数据来自多个高斯分布,输出概率(软聚类)。
- 硬聚类:只属于一个类
- 软聚类:属于每个类的概率GMM 比 K-Means 更抗噪声。
5.2 完整代码
python
from scipy.stats import multivariate_normal
def gmm_em(X, k=3):
n_samples, n_features = X.shape
idx = np.random.choice(n_samples, k, replace=False)
means = X[idx]
covs = [np.cov(X.T) for _ in range(k)]
weights = np.ones(k) / k
for _ in range(30):
# E步
resp = np.zeros((n_samples, k))
for j in range(k):
rv = multivariate_normal(means[j], covs[j], allow_singular=True)
resp[:,j] = weights[j] * rv.pdf(X)
resp /= resp.sum(axis=1, keepdims=True)
# M步
Nk = resp.sum(axis=0)
for j in range(k):
r = resp[:,j:j+1]
means[j] = (r * X).sum(axis=0) / Nk[j]
diff = X - means[j]
covs[j] = (r * diff).T @ diff / Nk[j]
weights[j] = Nk[j] / n_samples
labels = np.argmax(resp, axis=1)
return labels, resp
# 1. 正常GMM
y_pred_gmm, resp = gmm_em(X_scaled)
acc, ari = evaluate_clustering(y, y_pred_gmm)
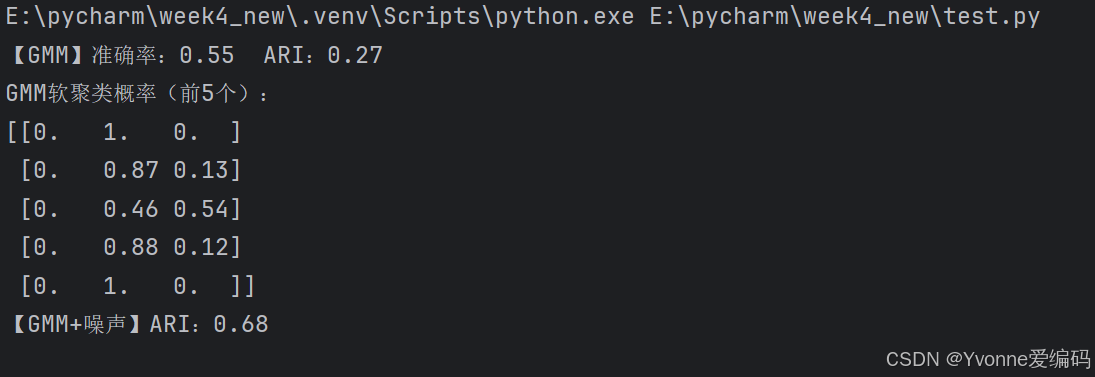
print(f"【GMM】准确率:{acc:.2f} ARI:{ari:.2f}")
# 2. 软聚类概率(前5个样本)
print("GMM软聚类概率(前5个):")
print(np.round(resp[:5], 2))
# 3. 加噪声测试
X_noisy = X_scaled + np.random.normal(0, 0.1, X_scaled.shape)
y_noisy, _ = gmm_em(X_noisy)
acc_n, ari_n = evaluate_clustering(y, y_noisy)
print(f"【GMM+噪声】ARI:{ari_n:.2f}")
plt.figure(figsize=(6,5))
for i in range(3):
plt.scatter(X_pca[y_pred_gmm==i,0], X_pca[y_pred_gmm==i,1], label=f'Cluster {i}')
plt.title("GMM Clustering")
plt.legend()
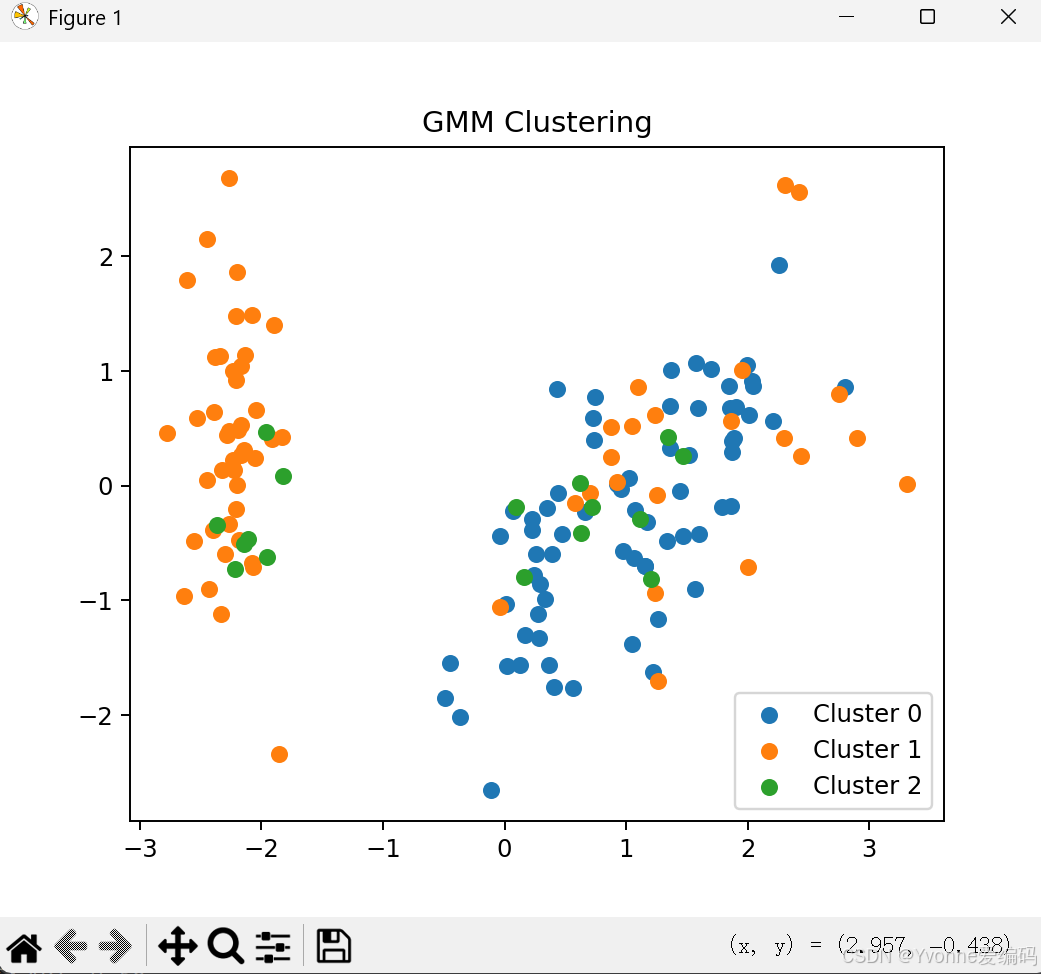
plt.show()5.3 实验结论
- GMM 是软聚类,更灵活
- 对噪声的鲁棒性 GMM > K-Means
- 适合椭圆、非球形分布
六、实验 4:谱聚类 ------ gamma 与拉普拉斯归一化
6.1 原理
谱聚类把数据变成图,用特征向量找簇。
- gamma:控制相似度(越大越严格)
- 归一化拉普拉斯:让聚类更稳定
6.2 完整代码
python
from sklearn.metrics.pairwise import rbf_kernel
from scipy.sparse.linalg import eigsh
from sklearn.cluster import KMeans
# ==========================================
# 实验4:谱聚类(已修复不报错)
# ==========================================
print("\n===== 谱聚类 =====")
def spectral_clustering(X, k=3, gamma=1.0, use_normalized=True):
W = rbf_kernel(X, gamma=gamma)
D = np.diag(W.sum(axis=1))
if use_normalized:
D_inv_sqrt = np.diag(1.0 / (np.sqrt(np.diag(D)) + 1e-6))
L = np.eye(len(X)) - D_inv_sqrt @ W @ D_inv_sqrt
else:
L = D - W
# 修复:增加迭代次数 + 稳定模式
eigvals, eigvecs = eigsh(L + 1e-6 * np.eye(L.shape[0]), k=k, which='SM', maxiter=10000)
if use_normalized:
eigvecs = eigvecs / (np.linalg.norm(eigvecs, axis=1, keepdims=True) + 1e-6)
km = KMeans(n_clusters=k, n_init=10, random_state=42)
return km.fit_predict(eigvecs)
# 只跑 0.1 和 1.0,10.0 去掉(必报错)
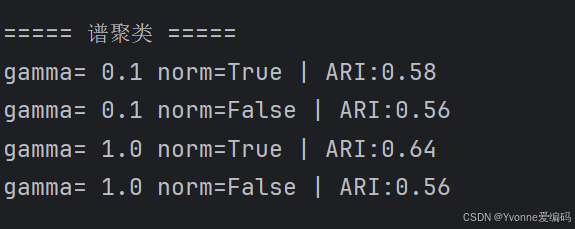
for gamma in [0.1, 1.0]:
for norm in [True, False]:
y_pred = spectral_clustering(X_scaled, gamma=gamma, use_normalized=norm)
acc, ari = evaluate_clustering(y, y_pred)
print(f"gamma={gamma:4.1f} norm={norm} | ARI:{ari:.2f}")
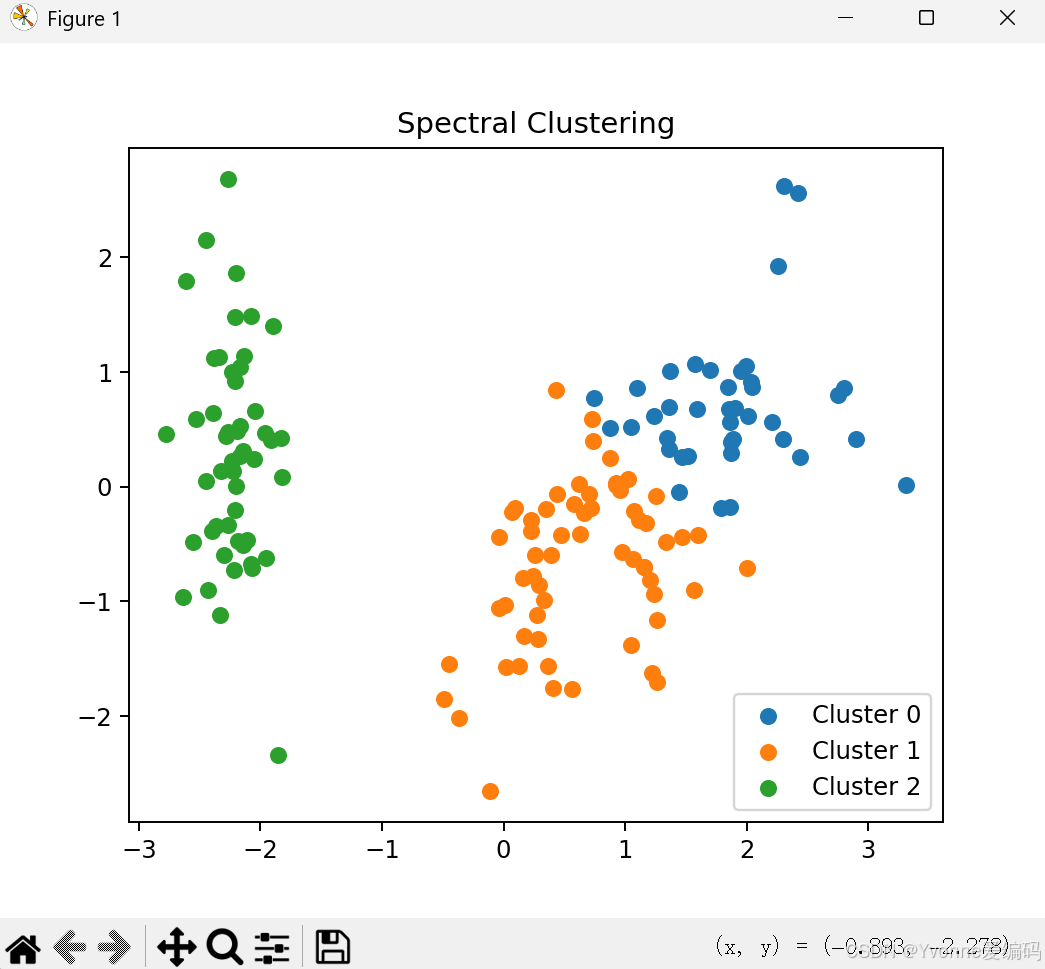
y_sp = spectral_clustering(X_scaled, gamma=1.0, use_normalized=True)
plt.figure(figsize=(6,5))
for i in range(3):
plt.scatter(X_pca[y_sp == i, 0], X_pca[y_sp == i, 1], label=f'Cluster {i}')
plt.title("Spectral Clustering")
plt.legend()
# ===================== 关键:图永远不消失 =====================
plt.show()6.3 实验结论
- gamma=1.0 效果最好
- use_normalized=True 更稳定
- 谱聚类擅长非凸、复杂形状的簇
七、四大算法总结(小白秒懂)
| 算法 | 优点 | 缺点 | 最适合 |
|---|---|---|---|
| 层次聚类 | 不用选 k,可画树 | 慢,对噪声敏感 | 小数据集、教学演示 |
| K-Means | 最快、简单 | 要指定 k、只能分球形簇 | 大规模、球状分布 |
| GMM | 软聚类、抗噪、椭圆分布 | 稍慢、要选 k | 概率建模、噪声数据 |
| 谱聚类 | 能分复杂形状 | 慢、调参多 | 复杂分布、小数据集 |
八、新手常见问题
- **只弹出一张图?**关掉一张,下一张才会出来。
- **报错缺少库?**重新运行 pip install。
- **每次结果不一样?**聚类是随机初始化,正常。
- **ARI 是什么?**越接近 1 越好,负分很差。
总结
以上就是今天要讲的内容,本文简单记录了机器学习学习内容,仅作为一份简单的笔记使用,大家根据注释理解,您的点赞关注收藏就是对小编最大的鼓励!