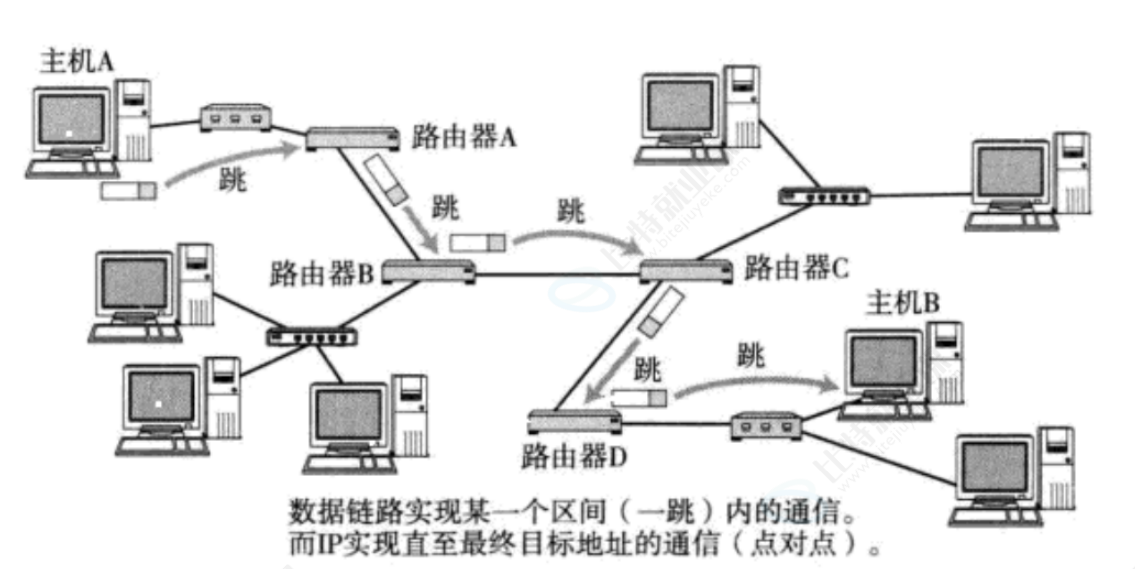
路由,简单来说就是在复杂的网络结构里,为 IP 数据包找到一条从源主机通往目标主机的传输路径,它的过程就像我们问路一样,是 一跳一跳(Hop by Hop)接力完成的。
这里的一跳 ,指的是数据链路层里相邻两个设备之间的传输区间,在以太网中就是一段从源 MAC 地址到下一跳 MAC 地址的帧传输。IP 数据包的全程传输,目标 IP 从头到尾不会改变,负责端到端的寻址;而每一跳的 MAC 地址会不断变化,只负责当前一段链路的转发。
当主机 A 要给主机 B 发数据包时,数据包会先发给网关路由器 A;路由器 A 查看目标 IP,对照自己的路由表,判断无法直接送达,就转发给下一跳路由器 B;路由器 B 再查路由表,继续转给路由器 C,接着传给路由器 D,最后由路由器 D 交付给主机 B。每经过一台路由器就是一跳,每台路由器都依靠自己的路由表判断转发方向,反复接力,直到数据包抵达最终的目标 IP。
内网路由和公网路由
路由可以按场景分为内网路由和公网路由 ,但它们本质是同一种路由原理,只是作用范围、地址类型不一样:
路由本身的核心逻辑完全一致,都是查路由表、一跳一跳转发 ,区别只在网络范围和 IP 类型。内网路由 发生在局域网、运营商内网这类私有网络里,转发的是私有 IP ,比如家庭内网、西安 / 陕西的运营商内网,只在小范围内部转发,不会出公网;公网路由 发生在全球广域网,转发的是公网 IP,在国家、国际骨干网之间跨区域转发。
内网路由只负责内部设备互通,不需要 NAT;而公网路由必须配合 NAT,内网私有 IP 先通过出口路由器伪装成公网 IP,再进入公网路由转发。不管是内网还是公网,每一台路由器都靠路由表判断下一跳,一跳一跳把数据包送到目的地,底层原理没有区别。
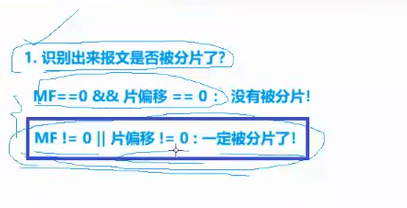
我们来看一个很关键的问题:如果发送方把一个 IP 报文拆成了 4 片发送,而接收方只收到了 3 片,那发送方该怎么补发?
有两种补发方法 :
只补发丢了的那1片
4片全部补发
答案是选第2种方法,把 4 片全部重传,而不是只补发丢失的那 1 片。因为 IP 层本身没有对单个分片的确认机制,接收方只会在收到所有分片并组装成完整报文后才会向上层交付,而不会单独对某一个分片进行确认。所以一旦有任何一片丢失,接收方就无法组装出完整报文,传输层只能通过超时重传或快重传机制,把整个原始报文重新发送一遍,而不是单独补发丢失的分片。这就意味着,只要一个报文被分片,它的丢包概率就会被放大 ------ 所有分片里只要有一个丢了,整个报文都得重传,效率也会随之降低,这也是为什么我们不建议过度依赖网络层分片的原因。
那对 IP 报文进行分片,是由网络层决定的吗?
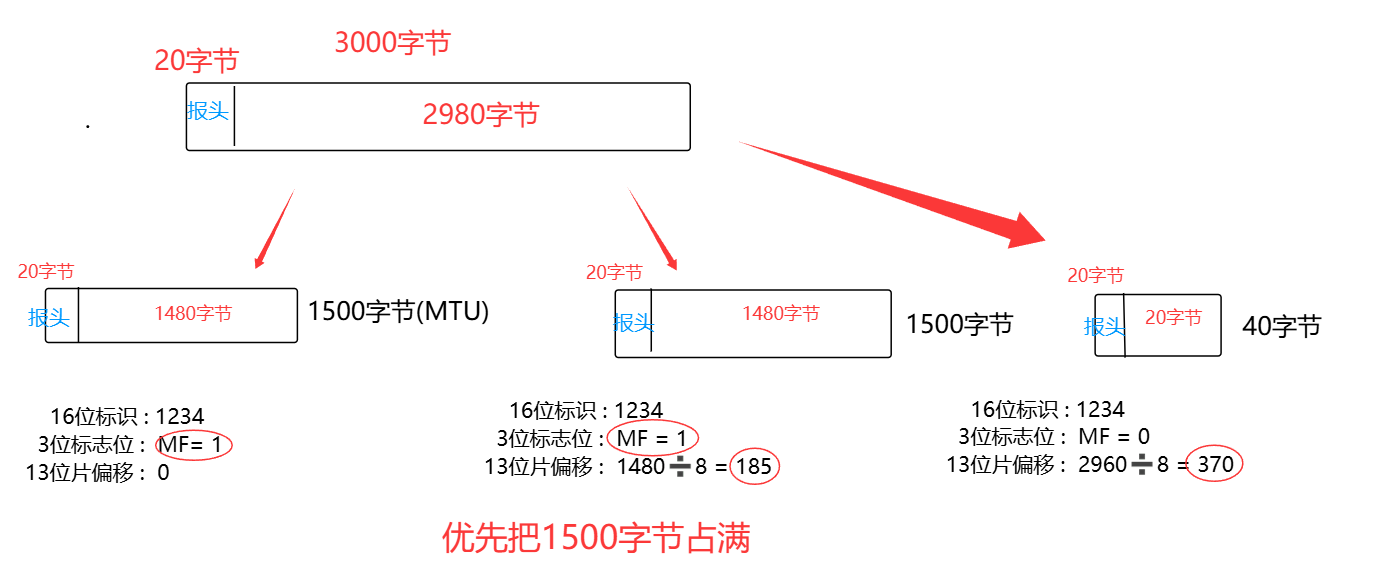
并不是网络层主动决定的,而是取决于传输层交给网络层的数据大小。如果传输层交付给 IP 层的数据过大,导致 IP 报文总长度超过了数据链路层的 MTU (1500字节),IP 层就必须进行分片;如果传输层交付的数据足够小,IP 报文总长度不超过 MTU,就不需要分片。所以,是否分片的主动权其实在传输层,这也是为什么 TCP 不会直接根据对方的滑动窗口一次性把数据全部发完的重要原因之一 ------ 它会通过 MSS(最大分段大小)机制提前把数据切割成合适的大小,让 IP 层不需要再分片,以此避免分片带来的效率和丢包问题。
最还有一个细节:即使发送方和接收方的以太网ui订单 MTU 都是 1500 字节,传输过程中也依然可能出现分片。因为数据在传输途中会经过不同的链路,中间路由器连接的网络可能支持更小的 MTU。比如发送方的 IP 报文是 1200 字节(加上 IP 头后仍小于 1500),但中间某一段链路的 MTU 只有 1000 字节,那么负责转发的路由器就必须对这个 IP 报文进行分片,才能继续传输。这种中途分片同样会带来丢包率上升的问题,所以 TCP 还会通过路径 MTU 发现(PMTUd)机制,主动探测整条路径上的最小 MTU,从源头就避免报文在传输途中被分片,进一步提升传输效率和可靠性。
我们可以计算一下,如果 TCP 和 IP 采用标准报头(20字节),那传输层给网络层的数据应该多大,才不会产生分片问题?
既然是组装,那就得现在接收方的视角,接收方会在网络层收到多个 IP 报文,网络层先做的应是先识别发来的这些报文是否分片,如果没有分片的报文就正常向上交付,如果识别出分片的报文,那又是如何识别出这个报文分了多少片?也就是怎么把分的这些片重新拼接成原始的报文,这里也就涉及到许多子问题,怎么判断哪个分片是报文的开头,哪个是结尾,如果其中某个分片丢了呢?再搞懂了上面的问题后,才能进行正确的组装。
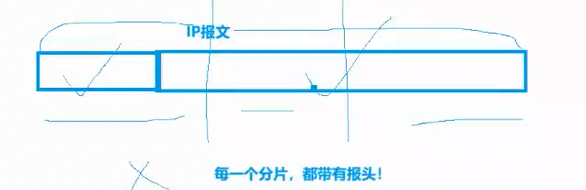
其实分片并不是把一个IP报文(IP报头+有效载荷)从左到右依次进行划分,比如分了三片,第一个分片保留原报文头、后续分片不带头部。而是每一个分片都会独立生成一份 IP 头部 ,分片之后的每一片,本身都是一个完整独立的 IP 报文,带着自己的 IP 头部在网络中传输,这些头部里就包含了标识、标志位、片偏移等信息,用来支撑接收方完成识别、排序与组装。这些分片的报头是 IP 层在执行分片操作时,自动为每一个分片生成的独立 IP 报头。
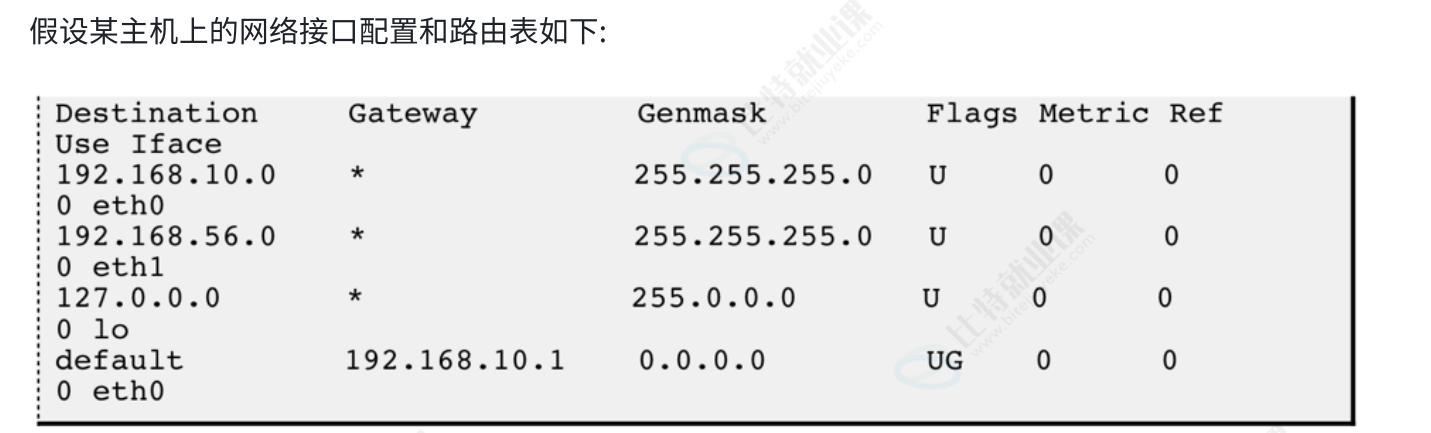
Destination:目标网段 / IP

 前提条件 :
前提条件 :

