作者介绍
陈相樵,男,西安工程大学电子信息学院,2025级研究生,张宏伟人工智能课题组
研究方向:无人机路径规划
电子邮件:3257932592@qq.com
1.LSTM原理网路介绍
LSTM是一种特殊的循环神经网络(RNN),专为解决传统RNN在处理长序列数据时遇到的梯度消失 和梯度爆炸问题而设计。其核心思想是引入一个能够长期保存信息的"细胞状态"以及一套精密的"门控机制"来调控信息流。
LSTM 内部的计算较为复杂,包含了遗忘门、输入门和输出门:
a.遗忘门,它是用来判断 cell 状态 ct-1 中哪些信息应该删除
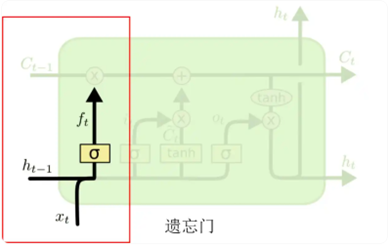
其公式如下:

输入的 h t-1 和 x t 经过 sigmoid 激活函数之后得到 f t。f t 中的值越接近 1,表示 cell 状态 c t-1 中对应位置的值更应该记住;f t 中的值越接近 0,表示 cell 状态 c t-1 中对应位置的值更应该忘记。将 f t 与 c t-1 按位相乘 ,即可以得到遗忘无用信息之后的 **c'**t-1。
b.输入门,它是用来判断哪些新的信息应该加入到 cell 状态 **c'**t-1 中
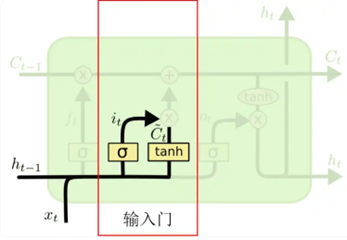
公式如下:
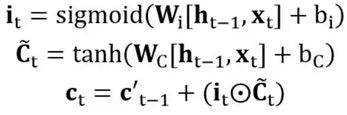
3.输出门,它是用来判断应该输出哪些信息到 ht 中
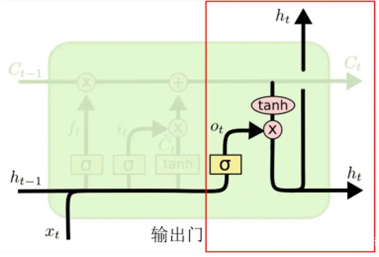
公式如下:
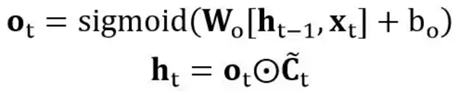
2.LSTM 如何缓解RNN中的梯度消失与爆炸
在RNN 中出现梯度消失的原因主要是梯度函数中包含一个连乘项,如果能够把连乘项去掉就可以克服梯度消失问题,可以通过使连乘项约等于 0 或者约等于 1,从而去除连乘项。RNN中时刻 t 的损失函数 L t 对于 U 、W 的梯度如下:
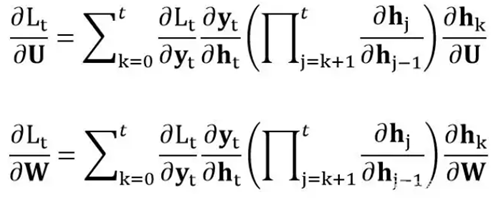
LSTM 中通过门的作用,可以使连乘项约等于 0 或者 1,如下所示:
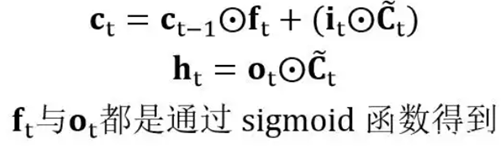
因此在 LSTM 中的连乘项变成:
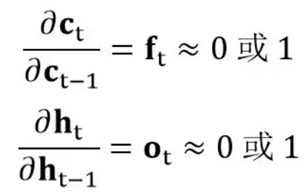
因此当门的梯度接近1时,连乘项能够保证梯度很好地在 LSTM 中传递,避免梯度消失的情况发生。而当门的梯度接近 0 时,意味着上一时刻的信息对当前时刻并没有作用,此时没有必要把梯度回传。
3.实验设计
本次实验采用的数据集为**耶拿气候数据集,**它由14个不同数据组成(如空气温度、气压、湿度、风向等),这些数据在数年间每10分钟记录一次。该数据集涵盖2009年1月1日至2016年12月31日的数据。
数据集链接如下:
https://www.kaggle.com/datasets/mnassrib/jena-climate?resource=download
数据集部分展示如下:
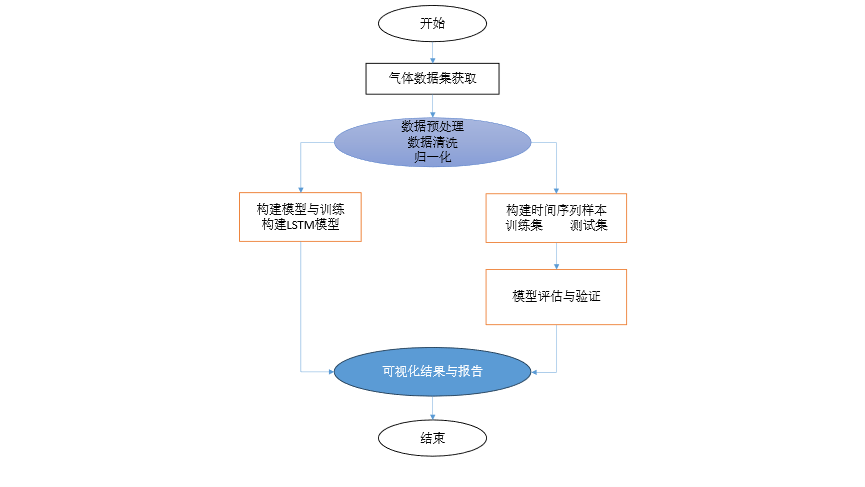
本次实验的算法流程图:
4.实验结果与分析
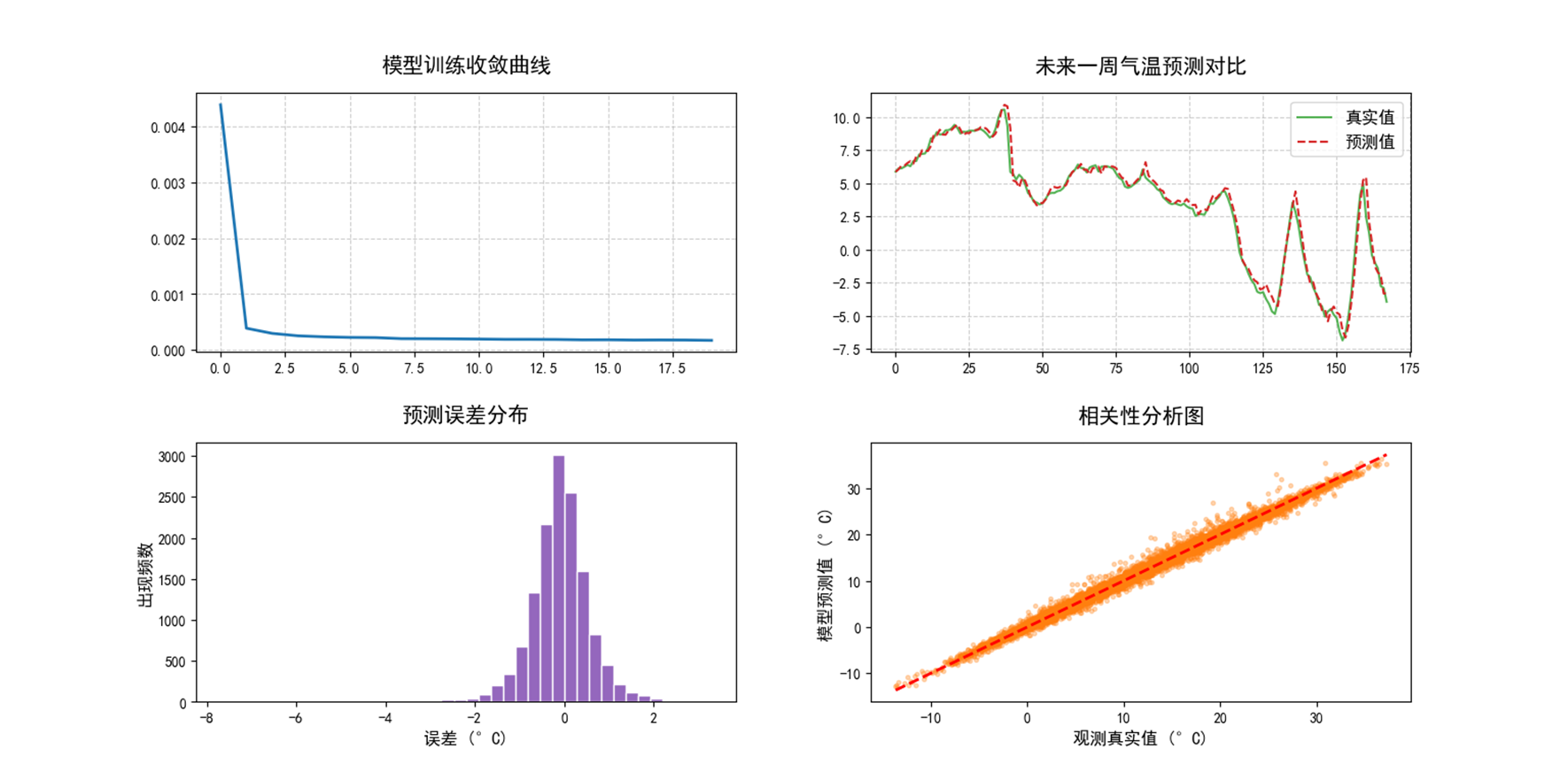
对温度预测结果:
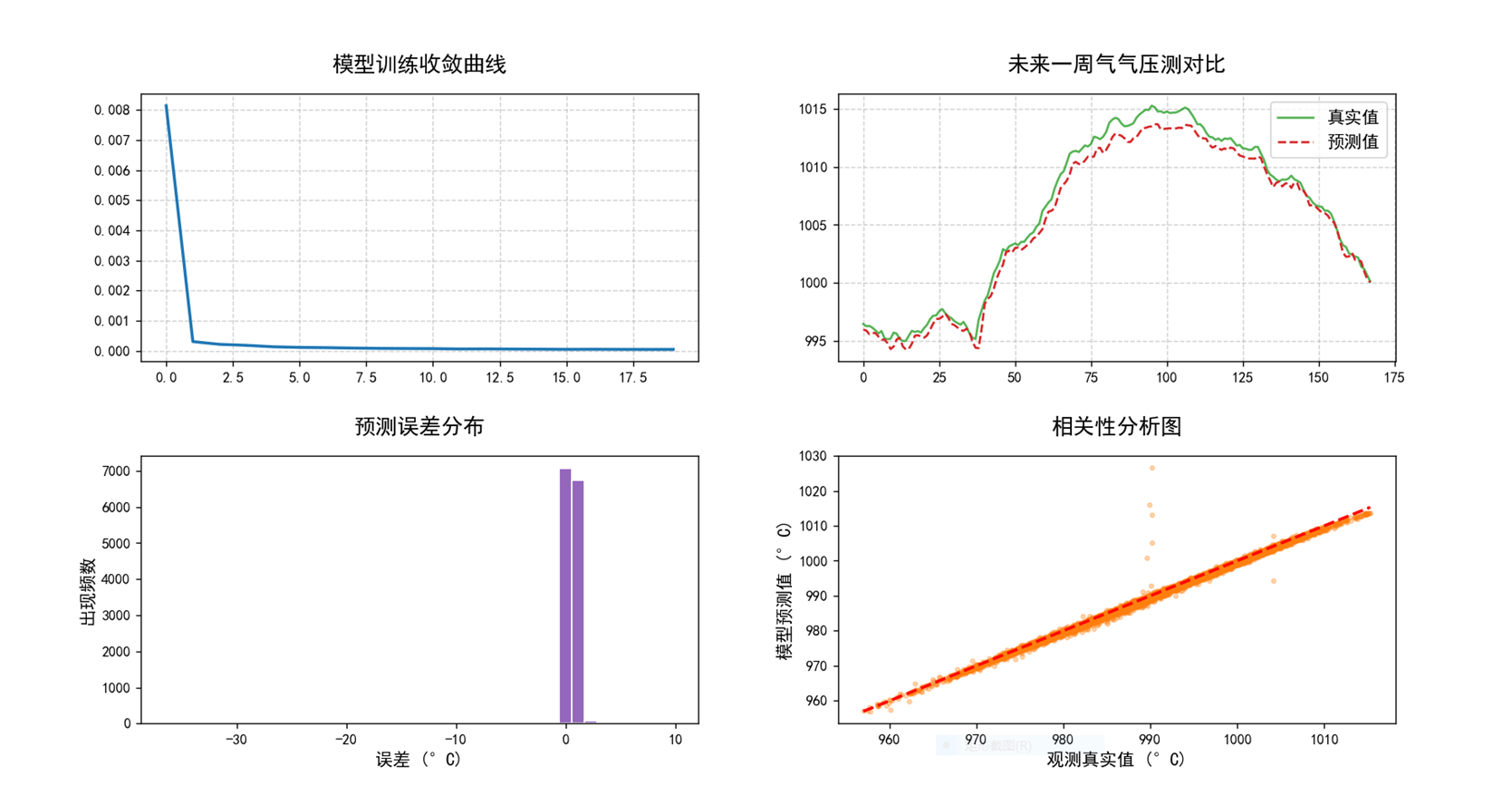
对气压预测结果:
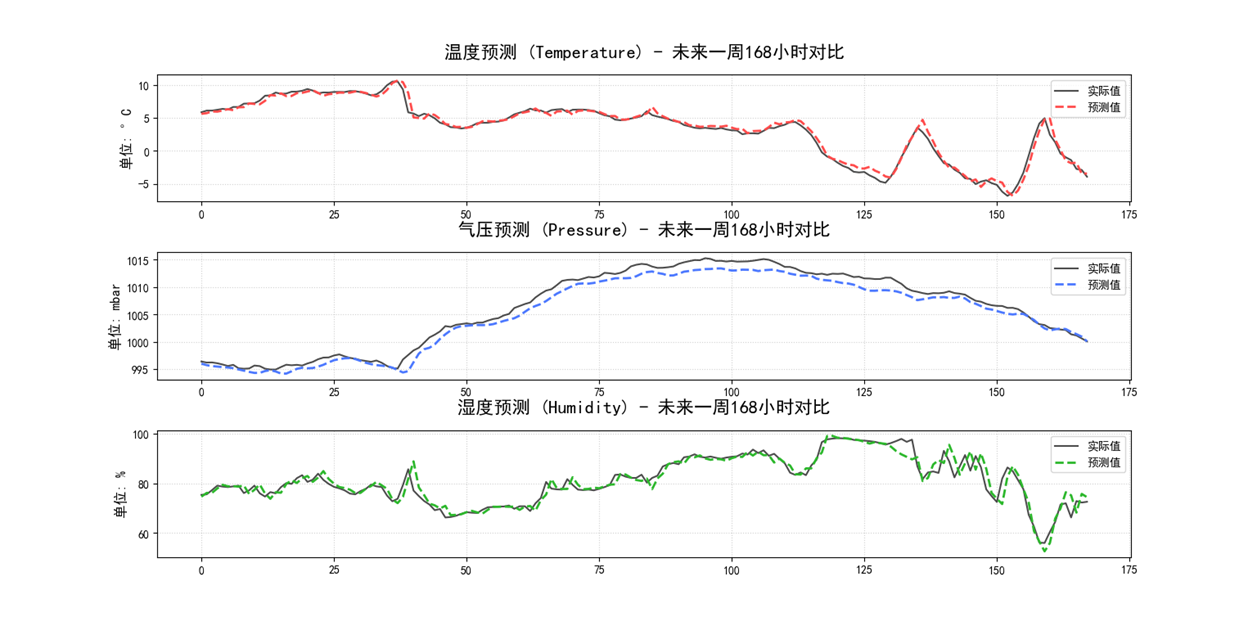
预测多变量,对温度,气压和湿度进行预测:
5.实验代码:
单次预测代码(预测气压或者温度等单个变量,属于多输入单输出)
python
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
import os
import joblib
# --- 1. 配置与数据准备 ---
FILE_NAME = 'jena_climate_2009_2016.csv'
MODEL_PATH = 'lstm_weather_model.pth'
SCALER_PATH = 'weather_scaler.gz'
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 加载并清洗数据
df = pd.read_csv(FILE_NAME)
df = df[5::6] # 每小时采样
df.index = pd.to_datetime(df['Date Time'], dayfirst=True)
df = df.drop(columns=['Date Time'])
# 自动定位气压列
TARGET_COL_IDX = [i for i, col in enumerate(df.columns) if "p (mbar)" in col][0]
# 归一化
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(df)
class WeatherDataset(Dataset):
def __init__(self, data, window_size, target_idx):
self.data = torch.FloatTensor(data)
self.window_size = window_size
self.target_idx = target_idx
def __len__(self):
return len(self.data) - self.window_size
def __getitem__(self, idx):
return (self.data[idx : idx + self.window_size],
self.data[idx + self.window_size, self.target_idx])
WINDOW_SIZE = 72
split = int(0.8 * len(scaled_data))
train_data = scaled_data[:split]
test_data = scaled_data[split:]
train_loader = DataLoader(WeatherDataset(train_data, WINDOW_SIZE, TARGET_COL_IDX), batch_size=64, shuffle=True)
test_loader = DataLoader(WeatherDataset(test_data, WINDOW_SIZE, TARGET_COL_IDX), batch_size=64, shuffle=False)
# --- 2. 模型定义 ---
class LSTMRegressor(nn.Module):
def __init__(self, input_size=14, hidden_size=64, num_layers=2):
super(LSTMRegressor, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True, dropout=0.2)
self.fc = nn.Sequential(nn.Linear(hidden_size, 16), nn.ReLU(), nn.Linear(16, 1))
def forward(self, x):
out, _ = self.lstm(x)
return self.fc(out[:, -1, :])
model = LSTMRegressor().to(DEVICE)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# --- 3. 训练逻辑 (带自动跳过) ---
train_losses = []
if os.path.exists(MODEL_PATH):
print("检测到模型已存在,正在加载...")
model.load_state_dict(torch.load(MODEL_PATH, map_location=DEVICE))
scaler = joblib.load(SCALER_PATH)
else:
print("未发现保存的模型,开始训练...")
for epoch in range(20):
model.train()
total_loss = 0
for bx, by in train_loader:
bx, by = bx.to(DEVICE), by.to(DEVICE)
optimizer.zero_grad()
loss = criterion(model(bx).squeeze(), by)
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_l = total_loss / len(train_loader)
train_losses.append(avg_l)
if (epoch+1) % 5 == 0: print(f"Epoch {epoch+1}, Loss: {avg_l:.6f}")
torch.save(model.state_dict(), MODEL_PATH)
joblib.dump(scaler, SCALER_PATH)
# --- 4. 预测评估 ---
model.eval()
preds, acts = [], []
with torch.no_grad():
for bx, by in test_loader:
preds.extend(model(bx.to(DEVICE)).cpu().numpy())
acts.extend(by.numpy())
def inv(data):
d = np.zeros((len(data), 14))
d[:, TARGET_COL_IDX] = np.array(data).flatten()
return scaler.inverse_transform(d)[:, TARGET_COL_IDX]
inv_preds, inv_acts = inv(preds), inv(acts)
plt.figure(figsize=(18, 14)) # 显著增大画布
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 调整子图间距:hspace控制上下间距,wspace控制左右间距
plt.subplots_adjust(hspace=0.35, wspace=0.25, bottom=0.1)
# 子图1:训练曲线
plt.subplot(2, 2, 1)
if train_losses:
plt.plot(train_losses, color='#1f77b4', linewidth=2)
plt.title('模型训练收敛曲线', fontsize=15, pad=15)
else:
plt.text(0.5, 0.5, '加载预训练模型\n无当前训练曲线', ha='center')
plt.grid(True, linestyle='--', alpha=0.6)
# 子图2:预测细节对比
plt.subplot(2, 2, 2)
plt.plot(inv_acts[-168:], label='真实值', color='#2ca02c', alpha=0.8)
plt.plot(inv_preds[-168:], label='预测值', color='#d62728', linestyle='--')
plt.title('未来一周气气压测对比', fontsize=15, pad=15)
plt.legend(fontsize=12)
plt.grid(True, linestyle='--', alpha=0.6)
# 子图3:误差分布
plt.subplot(2, 2, 3)
plt.hist(inv_acts - inv_preds, bins=40, color='#9467bd', edgecolor='white')
plt.title('预测误差分布', fontsize=15, pad=15)
plt.xlabel('误差 (°C)', fontsize=12)
plt.ylabel('出现频数', fontsize=12)
# 子图4:相关性分析
plt.subplot(2, 2, 4)
plt.scatter(inv_acts, inv_preds, s=8, alpha=0.3, color='#ff7f0e')
plt.plot([min(inv_acts), max(inv_acts)], [min(inv_acts), max(inv_acts)], 'r--', lw=2)
r2 = r2_score(inv_acts, inv_preds)
plt.title(f'相关性分析图', fontsize=15, pad=15)
plt.xlabel('观测真实值 (°C)', fontsize=12)
plt.ylabel('模型预测值 (°C)', fontsize=12)
plt.show()多次预测代码(可以预测多个数据,属于多输入多输出)
python
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
# --- 1. 数据预处理 ---
df = pd.read_csv('jena_climate_2009_2016.csv')
df = df[5::6] # 每小时采样一次
df.index = pd.to_datetime(df['Date Time'], dayfirst=True)
df = df.drop(columns=['Date Time'])
# 确定三个目标列的索引
TARGET_COLS = ["T (deg C)", "p (mbar)", "rh (%)"]
TARGET_IDXS = [df.columns.get_loc(c) for c in TARGET_COLS]
# 归一化
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(df)
class WeatherDataset(Dataset):
def __init__(self, data, window_size, target_indices):
self.data = torch.FloatTensor(data)
self.window_size = window_size
self.target_indices = target_indices
def __len__(self):
return len(self.data) - self.window_size
def __getitem__(self, idx):
# 输入过去72小时所有14个特征,输出未来1小时的3个特征
return (self.data[idx : idx + self.window_size],
self.data[idx + self.window_size, self.target_indices])
WINDOW_SIZE = 72
split = int(0.8 * len(scaled_data))
train_data = scaled_data[:split]
test_data = scaled_data[split:]
train_loader = DataLoader(WeatherDataset(train_data, WINDOW_SIZE, TARGET_IDXS), batch_size=64, shuffle=True)
test_loader = DataLoader(WeatherDataset(test_data, WINDOW_SIZE, TARGET_IDXS), batch_size=64, shuffle=False)
# --- 2. 模型构建 ---
class MultiTargetLSTM(nn.Module):
def __init__(self, input_size=14, hidden_size=64, output_size=3):
super(MultiTargetLSTM, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers=2, batch_first=True, dropout=0.2)
self.fc = nn.Linear(hidden_size, output_size) # 输出3个维度的预测值
def forward(self, x):
out, _ = self.lstm(x)
return self.fc(out[:, -1, :])
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = MultiTargetLSTM().to(device)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# --- 3. 训练模型 (20轮) ---
print("正在开始训练多目标预测模型...")
for epoch in range(20):
model.train()
for bx, by in train_loader:
bx, by = bx.to(device), by.to(device)
optimizer.zero_grad()
loss = criterion(model(bx), by)
loss.backward()
optimizer.step()
if (epoch+1) % 5 == 0:
print(f"Epoch {epoch+1}/20 完成训练")
# --- 4. 测试与反归一化 ---
model.eval()
all_preds, all_acts = [], []
with torch.no_grad():
for bx, by in test_loader:
all_preds.extend(model(bx.to(device)).cpu().numpy())
all_acts.extend(by.numpy())
# 用于反归一化的辅助函数
def denormalize_targets(data_matrix, target_idxs):
"""将预测/实际的3列数据还原到原始量级"""
res = []
for row in data_matrix:
dummy = np.zeros(14)
for i, idx in enumerate(target_idxs):
dummy[idx] = row[i]
inv = scaler.inverse_transform(dummy.reshape(1, -1))[0]
res.append([inv[idx] for idx in target_idxs])
return np.array(res)
inv_preds = denormalize_targets(np.array(all_preds), TARGET_IDXS)
inv_acts = denormalize_targets(np.array(all_acts), TARGET_IDXS)
# --- 5. 可视化未来一周 (168小时) 的三张独立图表 ---
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
colors = ['#ff4d4d', '#4d79ff', '#2eb82e'] # 温度(红), 气压(蓝), 湿度(绿)
titles = ['温度预测 (Temperature)', '气压预测 (Pressure)', '湿度预测 (Humidity)']
units = ['°C', 'mbar', '%']
# 创建三个独立的子图
fig, axes = plt.subplots(3, 1, figsize=(15, 18))
plt.subplots_adjust(hspace=0.4) # 拉开图片之间的上下距离
for i in range(3):
axes[i].plot(inv_acts[-168:, i], label='实际值', color='black', alpha=0.7, linewidth=1.5)
axes[i].plot(inv_preds[-168:, i], label='预测值', color=colors[i], linestyle='--', linewidth=2)
axes[i].set_title(f'{titles[i]} - 未来一周168小时对比', fontsize=16, pad=15)
axes[i].set_ylabel(f'单位: {units[i]}', fontsize=12)
axes[i].legend(loc='upper right', fontsize=10)
axes[i].grid(True, linestyle=':', alpha=0.6)
plt.show()