欢迎来到我的频道 【点击跳转专栏】
码云链接 【点此转跳】
文章目录
- [1. 什么是库](#1. 什么是库)
- [2. 静态库](#2. 静态库)
- [2.1 静态库⽣成](#2.1 静态库⽣成)
- [2.2 静态库使⽤](#2.2 静态库使⽤)
- [2.3 从开发者视角开发库](#2.3 从开发者视角开发库)
- [2.4 从使用者视角使用库](#2.4 从使用者视角使用库)
- [1. 方法1](#1. 方法1)
- [2. 方法2](#2. 方法2)
- [3. 方法3](#3. 方法3)
- [3. 动态库](#3. 动态库)
- [3.1 动态库⽣成](#3.1 动态库⽣成)
- [3.2 动态库的使用](#3.2 动态库的使用)
- [1. 编译时查找同态库的3种方法](#1. 编译时查找同态库的3种方法)
- [2. 运行时查找动态库的问题(4种方法)](#2. 运行时查找动态库的问题(4种方法))
- [3.3 动态、静态库同时存在!](#3.3 动态、静态库同时存在!)
- [4. 外部库的使用](#4. 外部库的使用)
- [5. ELF⽂件(了解为主 不需要死磕)](#5. ELF⽂件(了解为主 不需要死磕))
- [5.1 ELF文件的组成](#5.1 ELF文件的组成)
- [1. ELF头(ELF header)](#1. ELF头(ELF header))
- [2. 程序头表(Program header table)](#2. 程序头表(Program header table))
- [3. 节头表(Section header table)](#3. 节头表(Section header table))
- [4. 节(Section)](#4. 节(Section))
- [5. 对程序头表和节头表必要的认识(浅读完1~4后看)](#5. 对程序头表和节头表必要的认识(浅读完1~4后看))
- [6. 总结:](#6. 总结:)
- [5.2 ELF从形成到加载轮廓](#5.2 ELF从形成到加载轮廓)
- [6. 理解连接与加载](#6. 理解连接与加载)
- [6.1 ELF加载与进程地址空间](#6.1 ELF加载与进程地址空间)
- [6.1.1 虚拟地址与逻辑地址](#6.1.1 虚拟地址与逻辑地址)
- [6.1.2 重新理解进程虚拟地址空间](#6.1.2 重新理解进程虚拟地址空间)
- [6.2 静态链接的原理](#6.2 静态链接的原理)
- [总结 静态链接的本质](#总结 静态链接的本质)
- [6.2 进程间如何共享库/动态库的加载](#6.2 进程间如何共享库/动态库的加载)
- [6.3 动态链接的原理](#6.3 动态链接的原理)
- [6.3.1 概要](#6.3.1 概要)
- [6.3.2 我们的可执⾏程序被编译器动了⼿脚(了解即可)](#6.3.2 我们的可执⾏程序被编译器动了⼿脚(了解即可))
- [6.3.3 动态库中的相对地址](#6.3.3 动态库中的相对地址)
- [6.3.4 动态符号表 (.dynsym)](#6.3.4 动态符号表 (.dynsym))
- [6.3.5 程序和库具体映射](#6.3.5 程序和库具体映射)
- [6.3.6 程序,怎么进⾏库函数调⽤](#6.3.6 程序,怎么进⾏库函数调⽤)
- [6.3.7 全局偏移量表GOT(global offset table)](#6.3.7 全局偏移量表GOT(global offset table))
- [6.3.8 库间依赖\延迟绑定(简单了解即可)](#6.3.8 库间依赖\延迟绑定(简单了解即可))
1. 什么是库
如果我们写了一些方法想给别人用,有什么办法呢??
(1)我直接把头文件和源文件给他(.c+.h) --->这样会让别人轻易看到你的实现
(2) 把源文件打包成库,再和头文件一起给他(.o +.h) ---> 这样别人看不到你的实现
--->所以平时为了能够不让别人轻易窃取我们的劳动成果,我们一般采用的都是第二种方法,所以这就涉及到了如何把源文件打包成库的问题--->库又分静态库和动态库
⚠️:头文件(.h)是必须公开的!!相当于给别人的一份方法使用说明书
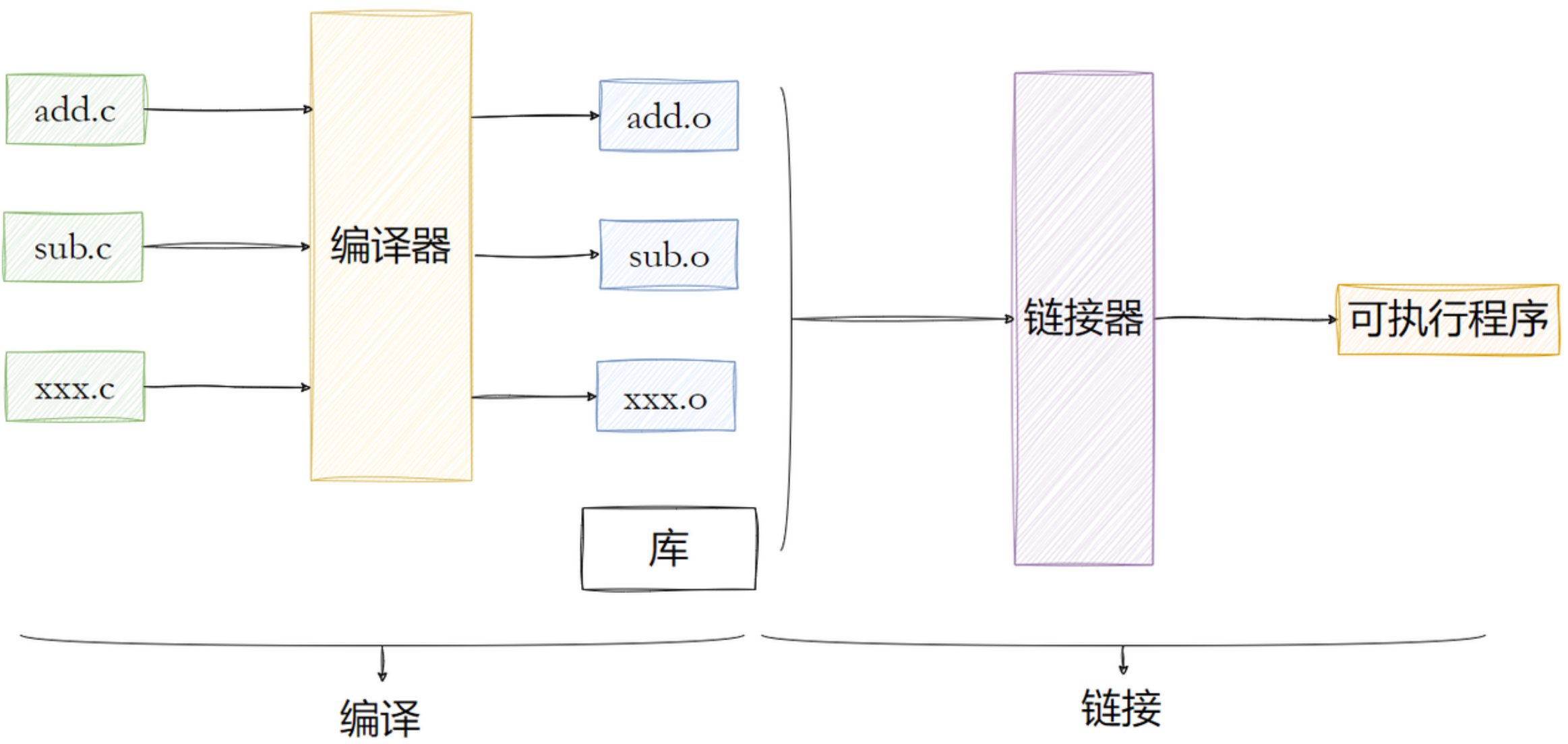
库是写好的现有的,成熟的,可以复⽤的代码。现实中每个程序都要依赖很多基础的底层库,不可能每个⼈的代码都从零开始,因此库的存在意义⾮同寻常。
本质上来说库是⼀种可执⾏代码的⼆进制形式,可以被操作系统载⼊内存执⾏。库有两种:
- 静态库 .
a[Linux]、.lib[windows] - 动态库
.so[Linux]、.dll[windows]
shell
// ubuntu 动静态库
// C
$ ls -l /lib/x86_64-linux-gnu/libc-2.31.so
-rwxr-xr-x 1 root root 2029592 May 1 02:20 /lib/x86_64-linux-gnu/libc-2.31.so
$ ls -l /lib/x86_64-linux-gnu/libc.a
-rw-r--r-- 1 root root 5747594 May 1 02:20 /lib/x86_64-linux-gnu/libc.a
//C++
$ ls /usr/lib/gcc/x86_64-linux-gnu/9/libstdc++.so -l
lrwxrwxrwx 1 root root 40 Oct 24 2022 /usr/lib/gcc/x86_64-linuxgnu/9/libstdc++.so -> ../../../x86_64-linux-gnu/libstdc++.so.6
$ ls /usr/lib/gcc/x86_64-linux-gnu/9/libstdc++.a
/usr/lib/gcc/x86_64-linux-gnu/9/libstdc++.a
// Centos 动静态库
// C
$ ls /lib64/libc-2.17.so -l
-rwxr-xr-x 1 root root 2156592 Jun 4 23:05 /lib64/libc-2.17.so
[whb@bite-alicloud ~]$ ls /lib64/libc.a -l
-rw-r--r-- 1 root root 5105516 Jun 4 23:05 /lib64/libc.a
// C++
$ ls /lib64/libstdc++.so.6 -l
lrwxrwxrwx 1 root root 19 Sep 18 20:59 /lib64/libstdc++.so.6 ->
libstdc++.so.6.0.19
$ ls /usr/lib/gcc/x86_64-redhat-linux/4.8.2/libstdc++.a -l
-rw-r--r-- 1 root root 2932366 Sep 30 2020 /usr/lib/gcc/x86_64-redhatlinux/4.8.2/libstdc++.a所谓的库 其实本质就是.o文件 我们只需要链接就可以了!
但是假如我们一共有1000个.o文件我们不可能真给用户发1000个.o文件 因为如果不小心丢一个问题可就大了 因此我们通过把众多文件打包成一个文件 .a或者.so的形式,而这个 这个就是我们常说的 动静态库!!
2. 静态库
- 静态库(.a):程序在编译链接的时候把库的代码链接到可执行文件中,程序运行的时候将不再需要静态库。
- 一个可执行程序可能用到许多的库,这些库运行有的是静态库,有的是动态库,而我们的编译默认为动态链接库,只有在该库下找不到动态
.so的时候才会采用同名静态库。我们也可以使用 gcc 的-static强转设置链接静态库。
2.1 静态库⽣成
我们有下述的文件:文件内容是啥不重要 (mystdio.c 是之前写自定义的IO库 感兴趣可以点击转跳 mystring只是随便写了点东西意思意思 毕竟这些不是重点 只是举个例子罢了)
先将
.c文件编译成.o文件

- ar :全称是 Archive(归档)。它的作用类似于我们平时用的 zip 打包工具,专门用来将多个编译好的目标文件(
.o文件)打包成一个单独的归档文件。在 C/C++ 开发中,这个归档文件通常就是我们所说的静态库 (以.a为后缀)。 - r (replace) :表示替换或插入。它会将指定的
.o文件添加到归档文件中;如果库里已经存在同名的目标文件,它会直接用新的去替换旧的。 - c (create) :表示创建。告诉
ar工具,如果指定的归档文件还不存在,就安静地创建一个新文件,而不要弹出警告提示。

t:列出静态库中的文件v: verbose详细信息

2.2 静态库使⽤
首先我们 再次创建一个文件夹(friend) 把库和.h文件(说明书🤔) 复制到该文件夹内 同时像文件夹内写入 main.c 并将其进行编译成.o文件!

main.c:
cpp
#include "mystdio.h"
#include "mystring.h"
int main()
{
myFILE *fp = myfopen("log.txt", "a"); // r, w, a, r+, w+..
mystrlen();//会打印出 "我自己的string len 函数!"
return 0;
}库⽂件名称和引⼊库的名称:去掉前缀 lib ,去掉后缀 .so , .a ,如: libc.so -> c
而关于库的使用有三种方法(具体场景请看2.4):
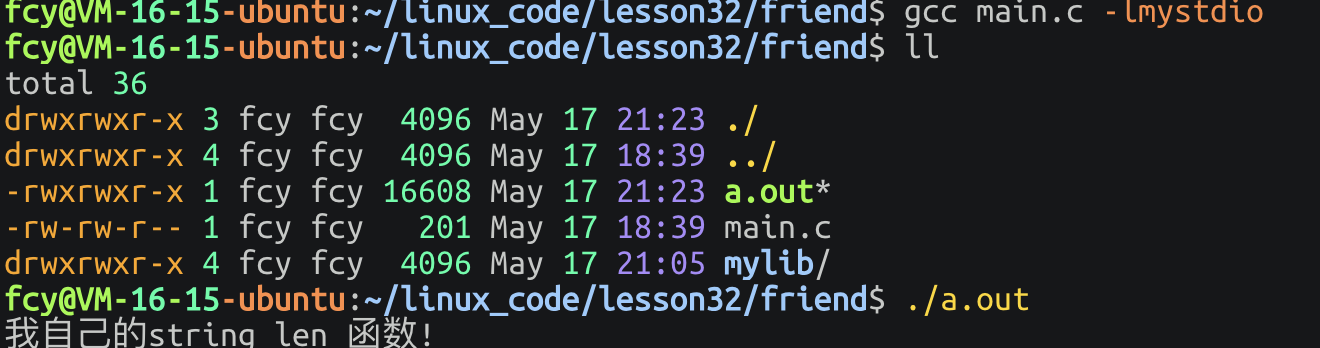
// 场景1:头⽂件和库⽂件安装到系统路径下 $ gcc main.c -lmystdio
因为gcc默认是在lib64这个路径下去找的// 场景2:头⽂件和库⽂件和我们⾃⼰的源⽂件在同⼀个路径下 $ gcc main.c -L. -lmymath
即我们当前的场景:

// 场景3:头⽂件和库⽂件有⾃⼰的独⽴路径 $ gcc main.c -I头⽂件路径 -L库⽂件路径 -lmymath
- -
L:指定库路径- -
I:指定头文件搜索路径- -
l:指定库名- 测试目标文件生成后,静态库删掉,程序照样可以运行
因为gcc是专门编译C语言的,所以默认就认识C标准库!会自动在lib64这个库中去寻找!
库不能包含main函数 因为库是默认给别人使用的!
2.3 从开发者视角开发库
作为一个开发者 你需要给别人开发一个库 应该给别人提供什么??
.a 库文件 .h 头文件(你的库的使用手册!)
所以这就是为什么Linux系统在我们安装库的时候 还会给我们提供对应的头文件!:
所以作为开发者 库和头文件是缺一不可的!
我们应该将两者一起打包给使用者
Makefile 里面的内容:
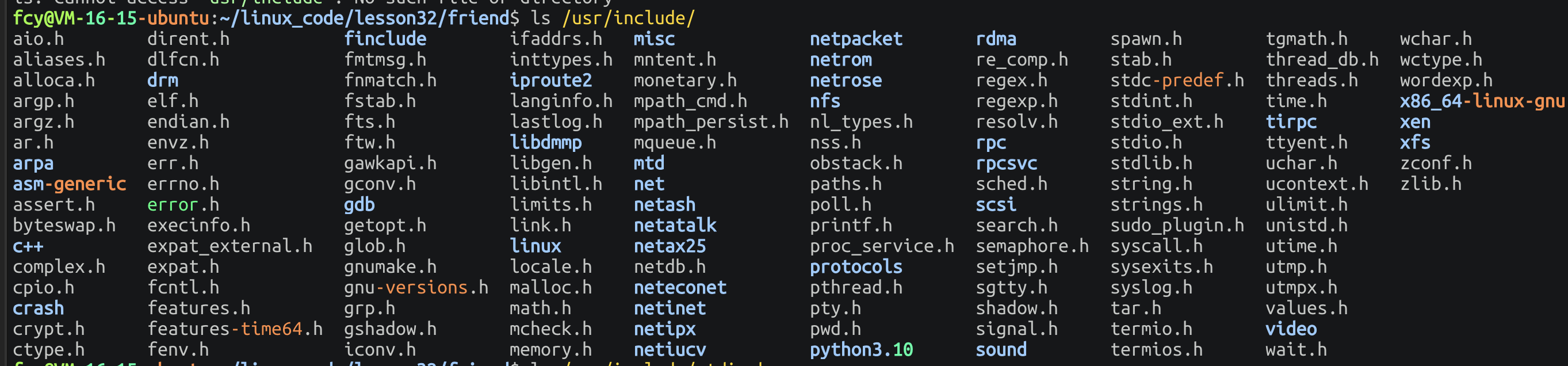
shell
libmystdio.a:mystdio.o mystring.o
ar -rc $@ $^
%.o:%.c
gcc -c $<
.PHONY:clean
clean:
rm -rf *.o *.a mylib
.PHONY:output
output:
mkdir -p mylib
mkdir -p mylib/include
mkdir -p mylib/lib
cp *.h mylib/include
cp *.a mylib/lib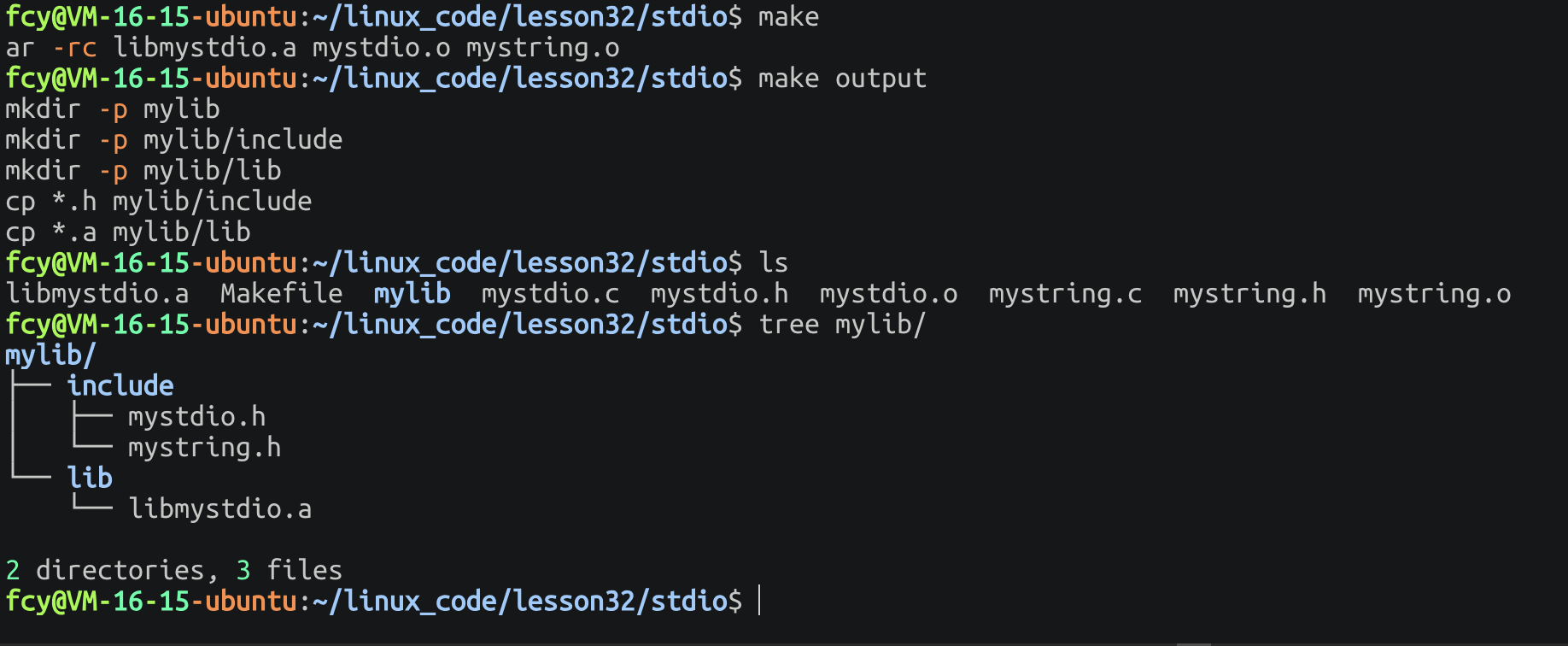
2.4 从使用者视角使用库
此时我们将 mylib 目录拷贝到使用者的目录!

1. 方法1
将我们的.h 文件拷贝到/usr/include路径下 将库拷贝到/lib64 路径下!
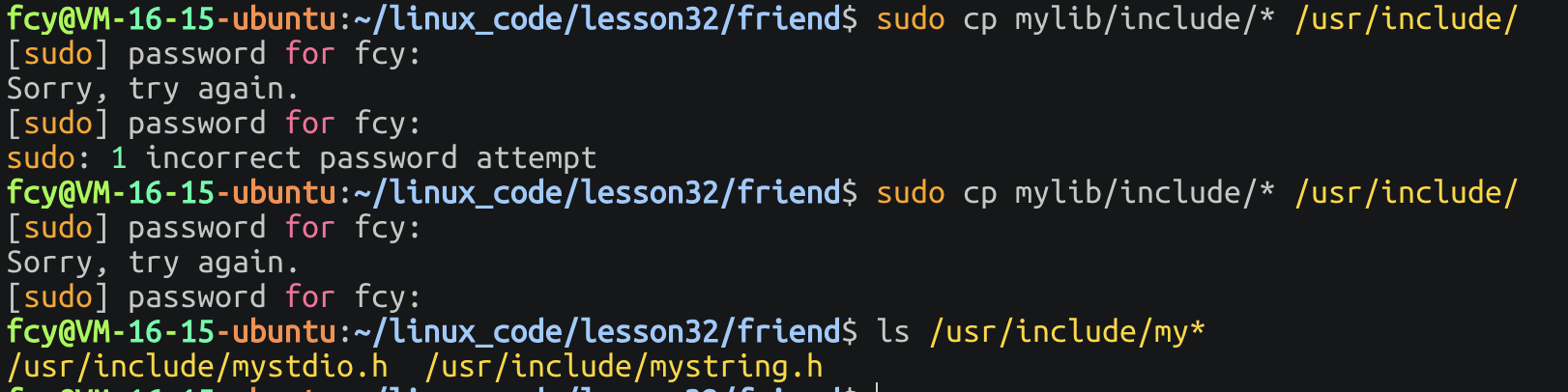

此时我们就可以说把 提供的库安装到系统里面了!此时我们就可以直接用这个库了!
ps:系统自带的库 gcc是直接认识的 我们后面安装进去的第三方库必须加个-l库名 告诉系统你要使用哪个库!
当我们不需要的时候 直接删除就可以了:

2. 方法2
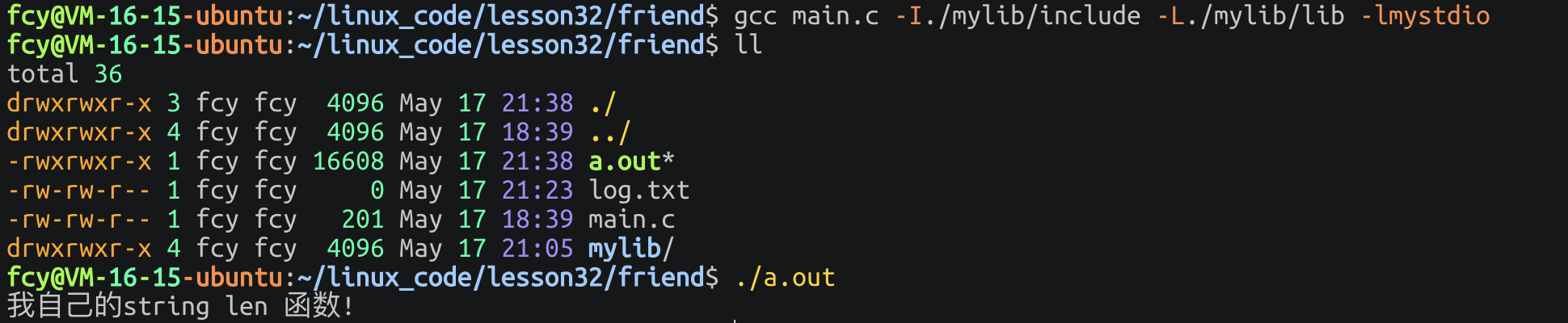
如果我就是不想安装到系统内 我想直接用 怎么办?此时我们的库和头文件都在当前目录的mylib内 编译器只能默认找到当前路径(仅对于.h)和系统默认路径(.h和库都满足) !
此时甚至 连
gcc -c main.c都跑不过去 因为预处理要展开头文件 而头文件不在当前目录:
此时就需要使用
-I -L -l这些选项来随意链接任意库(选项的具体介绍在 2.2):

3. 方法3
如果你觉得方法2太麻烦 同时方法1这种需要将库完全拷贝进去的方式 太消耗资源 其实还有一种方法 就是建立软链接!
ps: 因为头文件很小 所以直接拷贝问题也不大!!


此时我们就能像 方法1 一样直接链接了!

3. 动态库
- 动态库(
.so):程序在运行的时候才去链接动态库的代码,多个程序共享使用库的代码。 - 一个与动态库链接的可执行文件仅仅包含它用到的函数入口地址的一个表,而不是外部函数所在目标文件的整个机器码
- 在可执行文件开始运行以前,外部函数的机器码由操作系统从磁盘上的该动态库中复制到内存中,这个过程称为动态链接(
dynamic linking) - 动态库可以在多个程序间共享,所以动态链接使得可执行文件更小,节省了磁盘空间。操作系统采用虚拟内存机制允许物理内存中的一份动态库被要用到该库的所有进程共用,节省了内存和磁盘空间。
3.1 动态库⽣成
-shared: 表示生成共享库格式-fPIC: 产生位置无关码(position independent code)(6.3.7会解释的!)- 库名规则:
libxxx.so
shell
gcc -fPIC -c *.c
gcc -shared -o libmystdio.so *o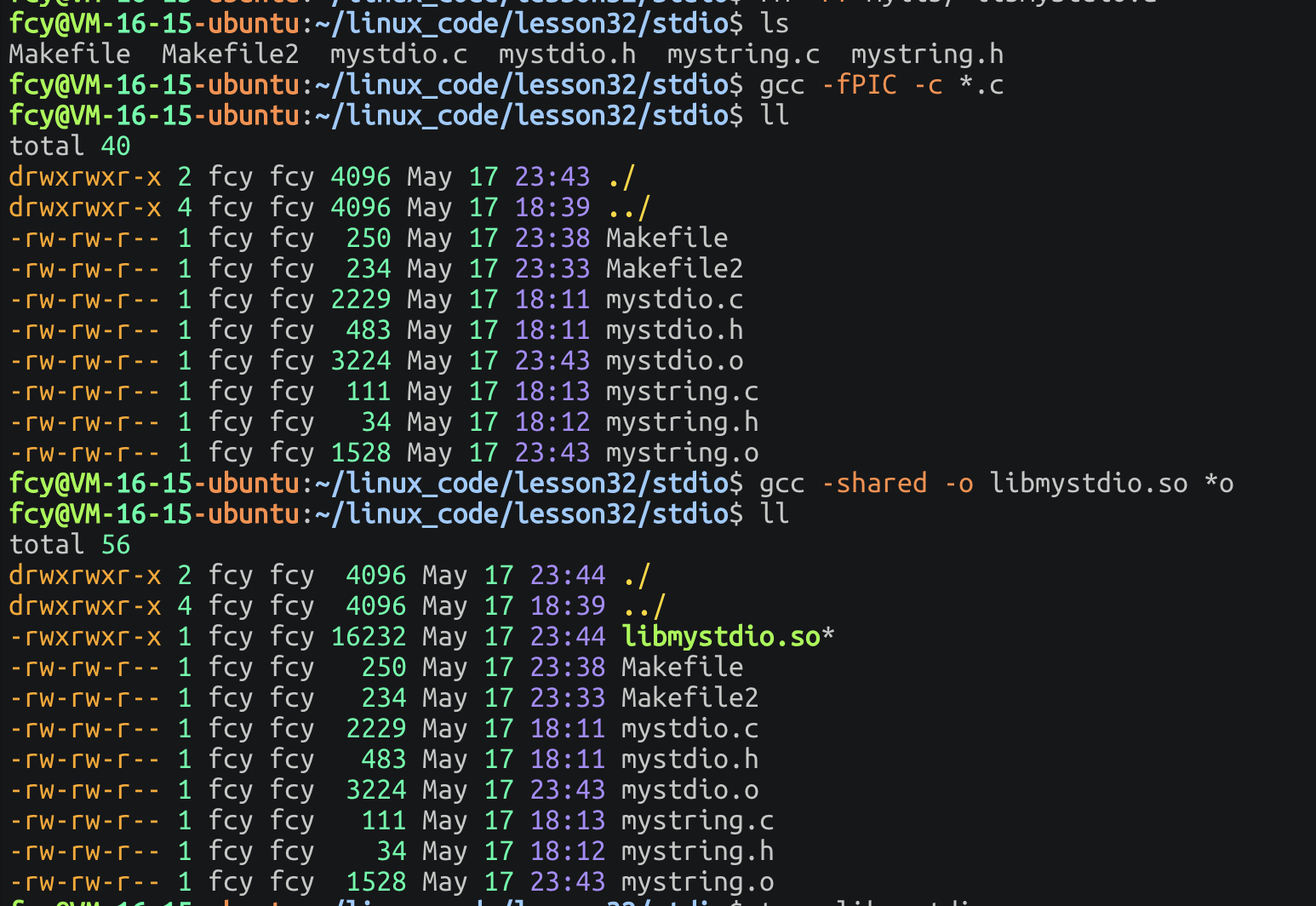
Makefile:
shell
libmystdio.so:mystdio.o mystring.o
gcc -shared -o $@ $^
%.o:%.c
gcc -fPIC -c $<
.PHONY:clean
clean:
rm -rf *.o *.so mylib
.PHONY:output
output:
mkdir -p mylib
mkdir -p mylib/include
mkdir -p mylib/lib
cp *.h mylib/include
cp *.a mylib/lib将其发布:
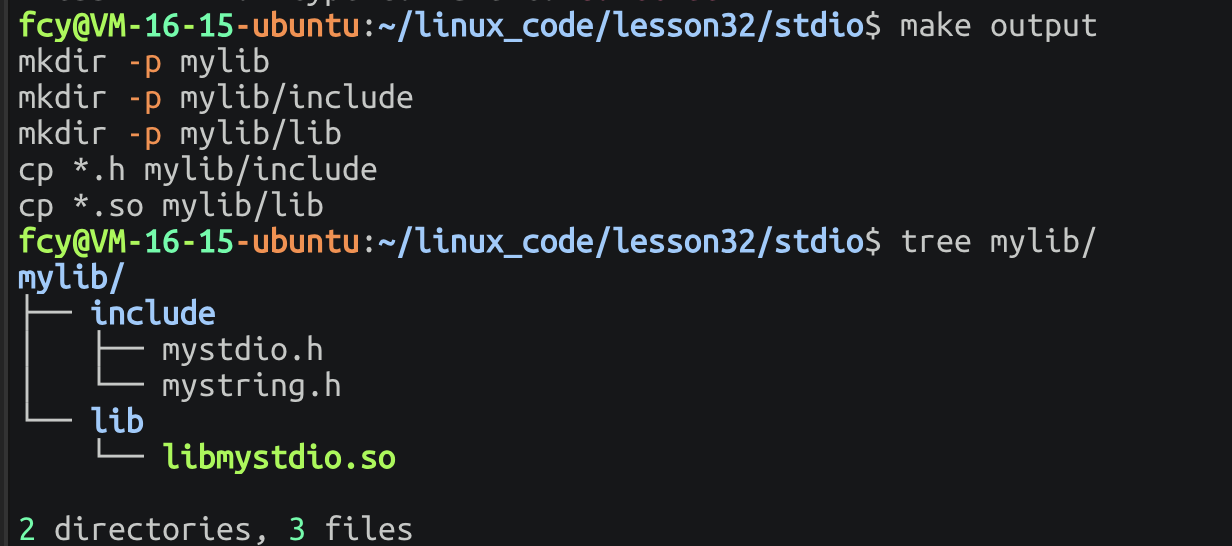
形成动态库 不用使用ar,而是继续使用gcc,这说明了 动态库才是常见场景!
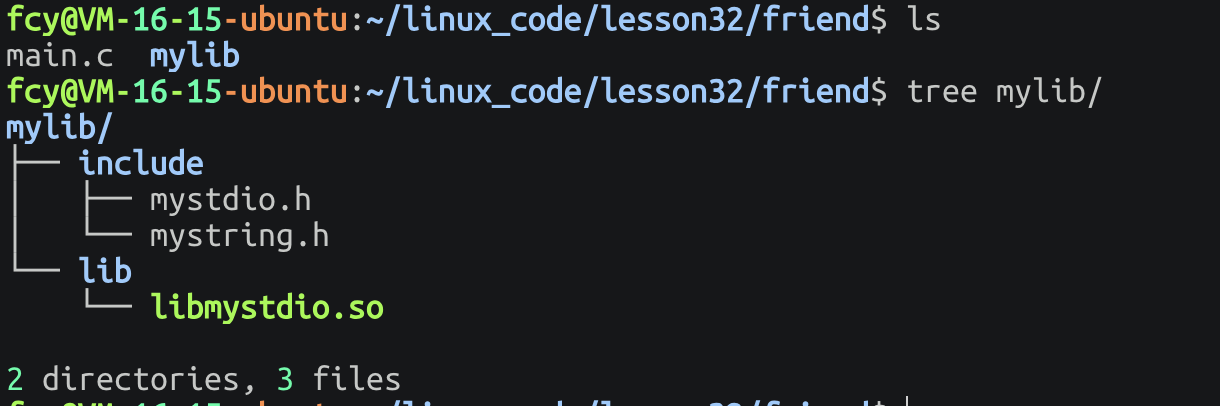
3.2 动态库的使用
老规矩 把mylib给用户拷过去:
1. 编译时查找同态库的3种方法
参考2.4的三种gcc方法
shell
// 场景1:头⽂件和库⽂件安装到系统路径下
$ gcc main.c -lmystdio
// 场景2:头⽂件和库⽂件和我们⾃⼰的源⽂件在同⼀个路径下
$ gcc main.c -L. -lmymath // 从左到右搜索-L指定的⽬录
// 场景3:头⽂件和库⽂件有⾃⼰的独⽴路径
$ gcc main.c -I头⽂件路径 -L库⽂件路径 -lmymath
当然还有个软链接的方式!这里就不展开了这里我们直接 利用L I l选项:

但是我们直接执行程序的时候却报错了:
"./target: 加载共享库时出错:libmystdio.so:无法打开共享对象文件:没有那个文件或目录"


明明之前 通过-L选项不是已经告诉库信息的位置了,为什么还会找不到呢?
因为路径告诉的是gcc编译器 当形成可执行程序的时候 gcc的工作就已经做完了!
而运行的时候 找库的是 加载器 它找不到!!你可以理解成系统它找不到库在哪里!
为什么之前使用静态库的时候没这个问题?
因为
静态库的方法是直接拷贝到程序内部的 程序运行的时候就不再需要库了;而使用动态库的时候,需要将程序和库都加载到内存才行!
至于为何能找到C标准库 那是因为C标准库是在系统默认路径下的!
那么怎么让系统快速找到库呢?
2. 运行时查找动态库的问题(4种方法)
方法1:
centos:直接把库拷贝到/lib64这个路径下!ubuntu: 直接把库拷贝到/lib这个路径下!
因为 CentOS 和 Ubuntu 在系统架构设计哲学上走了两条不同的路线,导致它们的默认库目录结构存在差异。
简单来说: CentOS 习惯用 lib64 明确区分 64 位库(因为更加直观);而 Ubuntu 则采用"多架构(Multiarch)"规范,使用更具体的路径来存放不同架构的库。
lib64 在 Ubuntu 中通常只是一个为了兼容而存在的"空壳"或符号链接,它只负责应付编译器(找静态库也就是gcc会找 加载器不会!),但骗不过程序运行时的动态加载器!
在 Ubuntu 系统中,
/lib64往往并不是真正存放文件的独立文件夹,而是指向/lib的符号链接(软连接)。

以下是ubuntu机器下的演示:

此时就可以运行了:

方法2: 采用软链接的方式!:

此时也能正常运行:

- 采用更改环境变量
LD_LIBRARY_PATH的方式:
原理是加载器除了在系统路径中找,还会在该环境变量下的路径中去找!不过大多数系统是默认没有该变量的 需要用
export命令去创建:

- 永久配置系统库路径:
ldconfig⽅案:配置/ etc/ld.so.conf.d/,ldconfig更新
a. 把你的库所在目录添加到一个 .conf 文件中(可以自己创建):

b. 然后用vim 把路径写入该文件

c. 最后刷新一下系统的库缓存 就好了!
shell
ldconfig
3.3 动态、静态库同时存在!
结论一:如果同时存在 动静态两种库,我们默认使用动态库!
如果想要使用静态库 需要使用 -static选项!(该选项如果想正确被使用 你必须有静态库才能顺利链接!即 强制所有的库,都必须有静态库版本,并且全部静态链接到我的课执行程序!)
结论二:如果你只提供静态库,即便是你采用默认的动态链接,对于 自定义库来说,也只能采用静态链接,不过系统自带的库依然还是动态链接!
4. 外部库的使用
我们现在没接触过太多的库,唯⼀接触过的就是C、C++标准库,这⾥我们可以推荐⼀个好玩的图形库:ncurses
shell
// 安装
// Centos
$ sudo yum install -y ncurses-devel
// ubuntu
$ sudo apt install -y libncurses-dev
安装后 centos默认会在
/lib64路径下而ubuntu默认在
/usr/lib/x86_64-linux-gnu/中
头文件默认在
通常存放在 /usr/include/中配置文件:通常存放在
/etc/下

然后给一段代码可以自己尝试下(代码不用理解 哥们AI写的哈哈哈哈😂)
cpp
#include <ncurses.h>
#include <math.h>
#include <stdlib.h>
#include <time.h>
#include <string.h>
#include <unistd.h>
// 定义粒子数量
#define PARTICLE_COUNT 300
// 动画帧率延时(微秒)
#define DELAY 30000
// 粒子结构体
typedef struct {
double x, y; // 当前坐标
double tx, ty; // 目标坐标(爱心轮廓上的点)
char ch; // 粒子显示的字符
int color_pair; // 颜色对
} Particle;
// 初始化 ncurses 环境和颜色
void init_curses() {
initscr(); // 启动 ncurses 模式
cbreak(); // 关闭行缓冲
noecho(); // 关闭输入回显
curs_set(0); // 隐藏光标
keypad(stdscr, TRUE); // 开启功能键支持
nodelay(stdscr, TRUE);// 非阻塞输入
start_color(); // 开启颜色支持
use_default_colors(); // 使用终端默认背景色
// 初始化几组红色系的颜色对,让粒子有深浅变化
init_pair(1, COLOR_RED, COLOR_BLACK);
init_pair(2, COLOR_MAGENTA, COLOR_BLACK);
init_pair(3, COLOR_WHITE, COLOR_BLACK);
}
int main() {
init_curses();
srand(time(NULL));
Particle particles[PARTICLE_COUNT];
int sh, sw;
getmaxyx(stdscr, sh, sw); // 获取终端宽高
// 初始化所有粒子
for (int i = 0; i < PARTICLE_COUNT; i++) {
particles[i].ch = ".*+*#@"[rand() % 6]; // 随机选取一些好看的 ASCII 字符
particles[i].color_pair = rand() % 3 + 1; // 随机分配颜色
// 初始位置设在屏幕外或随机位置
particles[i].x = rand() % sw;
particles[i].y = rand() % sh;
// 为每个粒子分配一个在爱心轮廓上的目标位置
// 爱心参数方程:
// x = 16sin^3(t)
// y = 13cos(t) - 5cos(2t) - 2cos(3t) - cos(4t)
double t = ((double)rand() / RAND_MAX) * 2 * M_PI;
double hx = 16 * pow(sin(t), 3);
double hy = -(13 * cos(t) - 5 * cos(2 * t) - 2 * cos(3 * t) - cos(4 * t));
// 缩放并居中爱心
double scale = 0.8; // 缩放系数,根据终端字体比例调整
particles[i].tx = hx * scale + sw / 2;
particles[i].ty = hy * scale + sh / 2;
}
int frame = 0;
while (1) {
clear(); // 清除上一帧的画面
// 获取按键,按 ESC (ASCII 27) 退出
int ch = getch();
if (ch == 27) break;
// 动态计算心跳缩放比例,模拟跳动
frame++;
double beat = 1.0 + 0.1 * sin(frame * 0.1);
for (int i = 0; i < PARTICLE_COUNT; i++) {
// 粒子向目标位置移动(带有缓动效果,看起来像被吸引过去)
particles[i].x += (particles[i].tx - particles[i].x) * 0.05;
particles[i].y += (particles[i].ty - particles[i].y) * 0.05;
// 加上心跳的缩放偏移
double dx = particles[i].x - sw / 2;
double dy = particles[i].y - sh / 2;
int draw_x = (int)(sw / 2 + dx * beat);
int draw_y = (int)(sh / 2 + dy * beat);
// 边界检查,防止画出屏幕外导致报错
if (draw_y >= 0 && draw_y < sh && draw_x >= 0 && draw_x < sw) {
attron(COLOR_PAIR(particles[i].color_pair));
mvaddch(draw_y, draw_x, particles[i].ch);
attroff(COLOR_PAIR(particles[i].color_pair));
}
// 偶尔随机改变粒子的目标点,产生流动闪烁的特效
if (rand() % 100 == 0) {
double t = ((double)rand() / RAND_MAX) * 2 * M_PI;
double hx = 16 * pow(sin(t), 3);
double hy = -(13 * cos(t) - 5 * cos(2 * t) - 2 * cos(3 * t) - cos(4 * t));
double scale = 0.8;
particles[i].tx = hx * scale + sw / 2;
particles[i].ty = hy * scale + sh / 2;
}
}
refresh(); // 刷新屏幕显示
usleep(DELAY); // 控制帧率
}
endwin(); // 退出 ncurses 恢复终端
return 0;
}
gcc heart.c -o heart -lncurses -lm⚠️:
-lm是因为会用到数学库(cos sin函数之类的)
效果:
5. ELF⽂件(了解为主 不需要死磕)
在编译之后会⽣成扩展名为 .o 的⽂件,它们被称作⽬标⽂件。要注意的是如果我们修改了⼀个原⽂件,那么只需要单独编译它这⼀个,⽽不需要浪费时间重新编译整个⼯程。
⽬标⽂件是⼀个⼆进制的⽂件,⽂件的格式是 ELF ,是对⼆进制代码的⼀种封装。

5.1 ELF文件的组成
其实有以下四种⽂件其实都是ELF⽂件:
- 可重定位文件(Relocatable File): 即
xxx.o文件。包含适合于与其他目标文件链接来创建可执行文件或者共享目标文件的代码和数据。 - 可执行文件(Executable File): 即可执行程序。
- 共享目标文件(Shared Object File): 即
xxx.so文件。 - 内核转储(core dumps): 存放当前进程的执行上下文,用于dump信号触发。(信号部分会细讲)
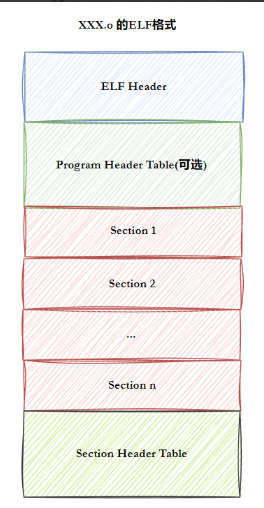
一个ELF文件由以下四部分组成:
1. ELF头(ELF header)
ELF头(ELF header):描述文件的主要特性。其位于文件的开始位置,它的主要目的是定位文件的其他部分,说人话就是类似ext文件系统中的GDT。
关于ELF header具体长什么样 可以用以下命令:
shell
readelf -h 查看的程序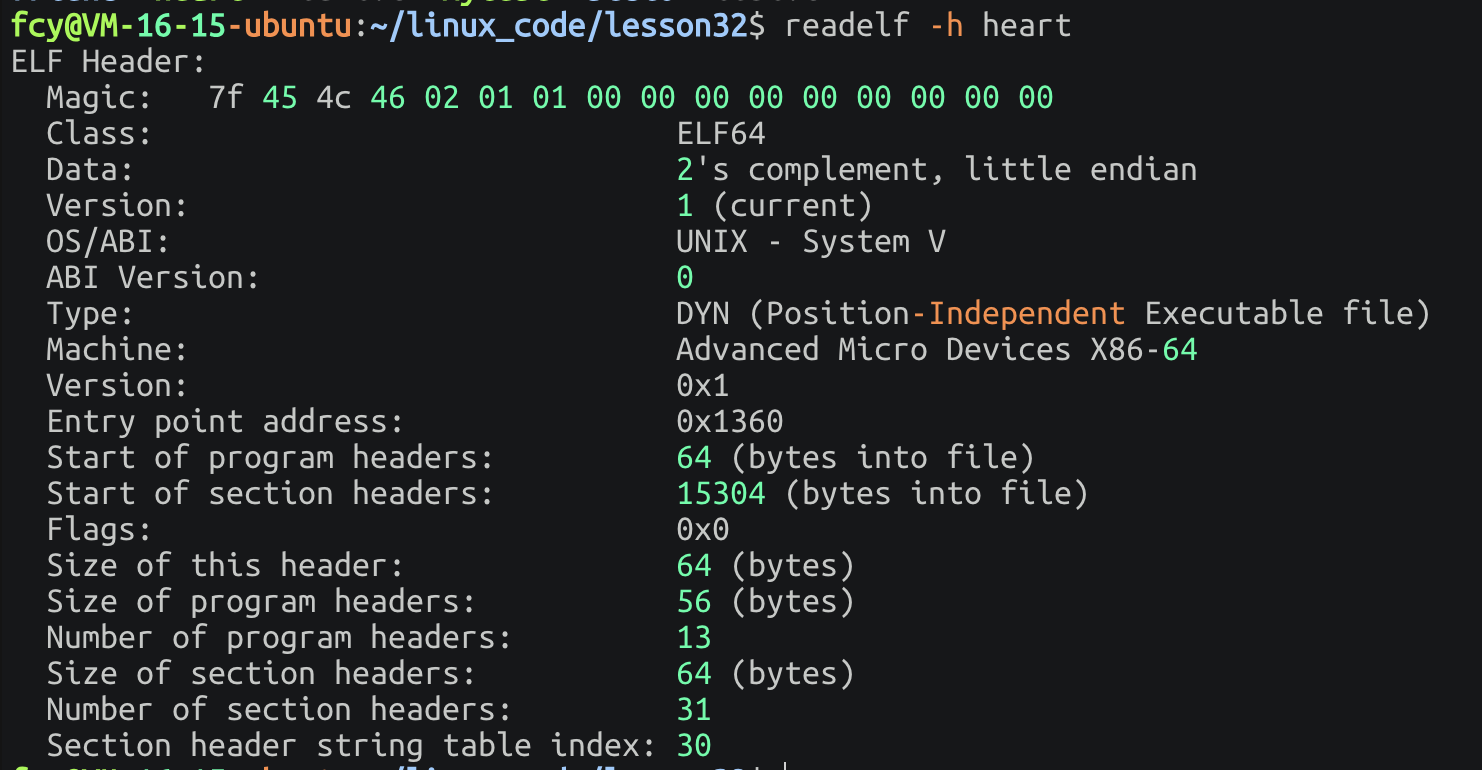

在我们眼里 这些都是文件 而我们都是把文件看成数组的(ext文件系统) ,而里面比较重要的就是Entry point address!记录了程序开始执行的地址!!!把他理解成总管理信息!
2. 程序头表(Program header table)
程序头表(Program header table):列举了所有有效的段(segments)和他们的属性(虚拟地址等)。表里记着每个段的开始的位置和位移(offset)、长度,毕竟这些段,都是紧密的放在二进制文件中,需要段表的描述信息,才能把他们每个段分割开。
在进程部分 我们学习了
虚拟地址空间(栈、堆、初始化数据区等),进程是从可执行程序中来的,那么进程是怎么知道自己一共有多少区?每个区都是些啥?即段究竟是啥!
这是 Linux 下
size命令的输出结果,它展示了可执行文件heart的内存段大小信息。( 段是什么! )
- text:代码段大小(6778 字节),存放程序的可执行指令(如函数逻辑、循环语句等)。这部分是只读的,运行时不会被修改。
- data :已初始化的数据段大小(840 字节),存放程序中显式赋值的全局变量/静态变量 (比如
int a = 10;)。- bss :未初始化的数据段大小(16 字节),存放程序中未显式赋值的全局变量/静态变量 (比如
int b;,系统会自动初始化为 0)。- dec :十进制表示的总大小(7634 字节),等于
text + data + bss(6778+840+16=7634)。- hex:十六进制表示的总大小(1dd2 是 7634 的十六进制形式)。
- filename :被分析的文件名(这里是编译后的可执行文件
heart)。
程序头表中的段是 ELF 文件在磁盘上的物理组织形式,它是给操作系统加载器看的"施工蓝图"。

shell
readelf -l 目标程序
shell
fcy@VM-16-15-ubuntu:~/linux_code/lesson32$ readelf -l heart
Elf file type is DYN (Position-Independent Executable file)
Entry point 0x1360
There are 13 program headers, starting at offset 64
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
PHDR 0x0000000000000040 0x0000000000000040 0x0000000000000040
0x00000000000002d8 0x00000000000002d8 R 0x8
INTERP 0x0000000000000318 0x0000000000000318 0x0000000000000318
0x000000000000001c 0x000000000000001c R 0x1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
LOAD 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000cc0 0x0000000000000cc0 R 0x1000
LOAD 0x0000000000001000 0x0000000000001000 0x0000000000001000
0x0000000000000f5d 0x0000000000000f5d R E 0x1000
LOAD 0x0000000000002000 0x0000000000002000 0x0000000000002000
0x000000000000018c 0x000000000000018c R 0x1000
LOAD 0x0000000000002cc8 0x0000000000003cc8 0x0000000000003cc8
0x0000000000000348 0x0000000000000368 RW 0x1000
DYNAMIC 0x0000000000002cd8 0x0000000000003cd8 0x0000000000003cd8
0x0000000000000220 0x0000000000000220 RW 0x8
NOTE 0x0000000000000338 0x0000000000000338 0x0000000000000338
0x0000000000000030 0x0000000000000030 R 0x8
NOTE 0x0000000000000368 0x0000000000000368 0x0000000000000368
0x0000000000000044 0x0000000000000044 R 0x4
GNU_PROPERTY 0x0000000000000338 0x0000000000000338 0x0000000000000338
0x0000000000000030 0x0000000000000030 R 0x8
GNU_EH_FRAME 0x0000000000002080 0x0000000000002080 0x0000000000002080
0x000000000000003c 0x000000000000003c R 0x4
GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 RW 0x10
GNU_RELRO 0x0000000000002cc8 0x0000000000003cc8 0x0000000000003cc8
0x0000000000000338 0x0000000000000338 R 0x1
Section to Segment mapping:
Segment Sections...
00
01 .interp
02 .interp .note.gnu.property .note.gnu.build-id .note.ABI-tag .gnu.hash .dynsym .dynstr .gnu.version .gnu.version_r .rela.dyn .rela.plt
03 .init .plt .plt.got .plt.sec .text .fini
04 .rodata .eh_frame_hdr .eh_frame
05 .init_array .fini_array .dynamic .got .data .bss
06 .dynamic
07 .note.gnu.property
08 .note.gnu.build-id .note.ABI-tag
09 .note.gnu.property
10 .eh_frame_hdr
11
12 .init_array .fini_array .dynamic .got 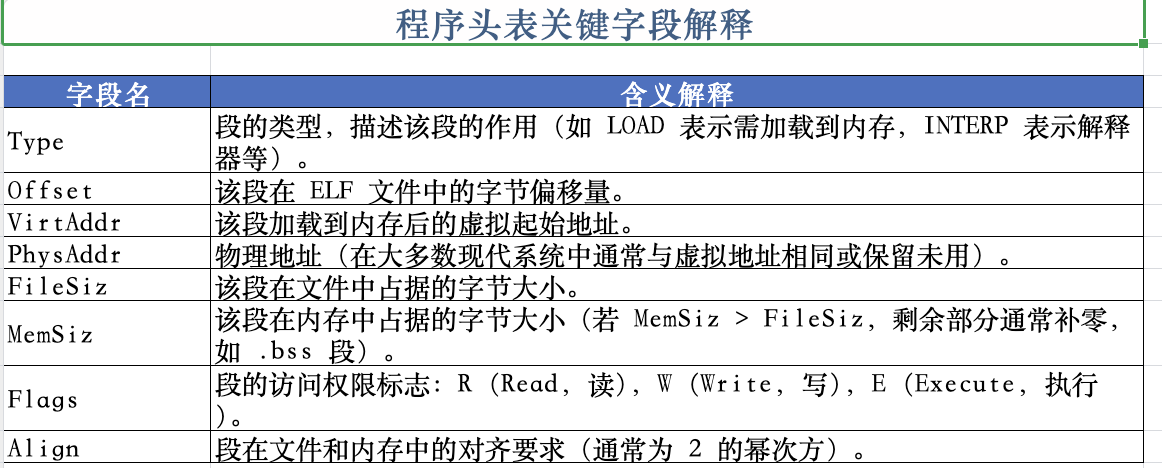
这是最重要的部分,操作系统根据这些条目建立进程的内存空间:
| 序号 | 权限 | 虚拟地址范围 | 包含内容 (Section) | 解释 |
|---|---|---|---|---|
| LOAD 1 | R (只读) | 0x000 - 0xcc0 | .interp, .dynsym, .dynstr, .rela.* 等 |
ELF头部和符号表信息。这部分包含加载所需的元数据,只读。 |
| LOAD 2 | R E (读+执行) | 0x1000 - 0x1f5d | .text, .plt, .init 等 |
代码段。包含程序的机器指令。因为代码通常不需要修改,所以是只读且可执行的。 |
| LOAD 3 | R (只读) | 0x2000 - 0x218c | .rodata, .eh_frame 等 |
只读数据段。包含常量字符串、调试帧信息等。 |
| LOAD 4 | RW (读+写) | 0x3cc8 - 0x4030 | .data, .bss, .got, .dynamic 等 |
数据段。包含全局变量等。注意:它的文件偏移是 0x2cc8,但在内存中地址是 0x3cc8(页对齐)。 |
输出底部的 Section to Segment mapping 部分非常有用,它直接告诉你对应的关系:
- Segment 03(代码段)包含了 .text(你的核心代码)。
- Segment 05(数据段)包含了 .data 和 .bss(你的全局变量)。
作者说:看不懂正常 主要是想告诉你它的结构 至于为何需要程序头表 读完 3 4 后看下5就明白了!!
3. 节头表(Section header table)
- 节头表(Section header table):包含对节(sections)的描述。
关于节头表具体长什么样 可以用以下命令:
shell
readelf -S 查看的程序
shell
fcy@VM-16-15-ubuntu:~/linux_code/lesson32$ readelf -S heart
There are 31 section headers, starting at offset 0x3bc8:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .interp PROGBITS 0000000000000318 00000318
000000000000001c 0000000000000000 A 0 0 1
[ 2] .note.gnu.pr[...] NOTE 0000000000000338 00000338
0000000000000030 0000000000000000 A 0 0 8
[ 3] .note.gnu.bu[...] NOTE 0000000000000368 00000368
0000000000000024 0000000000000000 A 0 0 4
[ 4] .note.ABI-tag NOTE 000000000000038c 0000038c
0000000000000020 0000000000000000 A 0 0 4
[ 5] .gnu.hash GNU_HASH 00000000000003b0 000003b0
0000000000000028 0000000000000000 A 6 0 8
[ 6] .dynsym DYNSYM 00000000000003d8 000003d8
0000000000000300 0000000000000018 A 7 1 8
[ 7] .dynstr STRTAB 00000000000006d8 000006d8
00000000000001c2 0000000000000000 A 0 0 1
[ 8] .gnu.version VERSYM 000000000000089a 0000089a
0000000000000040 0000000000000002 A 6 0 2
[ 9] .gnu.version_r VERNEED 00000000000008e0 000008e0
00000000000000b0 0000000000000000 A 7 4 8
[10] .rela.dyn RELA 0000000000000990 00000990
00000000000000d8 0000000000000018 A 6 0 8
[11] .rela.plt RELA 0000000000000a68 00000a68
0000000000000258 0000000000000018 AI 6 24 8
[12] .init PROGBITS 0000000000001000 00001000
000000000000001b 0000000000000000 AX 0 0 4
[13] .plt PROGBITS 0000000000001020 00001020
00000000000001a0 0000000000000010 AX 0 0 16
[14] .plt.got PROGBITS 00000000000011c0 000011c0
0000000000000010 0000000000000010 AX 0 0 16
[15] .plt.sec PROGBITS 00000000000011d0 000011d0
0000000000000190 0000000000000010 AX 0 0 16
[16] .text PROGBITS 0000000000001360 00001360
0000000000000bf0 0000000000000000 AX 0 0 16
[17] .fini PROGBITS 0000000000001f50 00001f50
000000000000000d 0000000000000000 AX 0 0 4
[18] .rodata PROGBITS 0000000000002000 00002000
0000000000000080 0000000000000000 A 0 0 16
[19] .eh_frame_hdr PROGBITS 0000000000002080 00002080
000000000000003c 0000000000000000 A 0 0 4
[20] .eh_frame PROGBITS 00000000000020c0 000020c0
00000000000000cc 0000000000000000 A 0 0 8
[21] .init_array INIT_ARRAY 0000000000003cc8 00002cc8
0000000000000008 0000000000000008 WA 0 0 8
[22] .fini_array FINI_ARRAY 0000000000003cd0 00002cd0
0000000000000008 0000000000000008 WA 0 0 8
[23] .dynamic DYNAMIC 0000000000003cd8 00002cd8
0000000000000220 0000000000000010 WA 7 0 8
[24] .got PROGBITS 0000000000003ef8 00002ef8
0000000000000108 0000000000000008 WA 0 0 8
[25] .data PROGBITS 0000000000004000 00003000
0000000000000010 0000000000000000 WA 0 0 8
[26] .bss NOBITS 0000000000004020 00003010
0000000000000010 0000000000000000 WA 0 0 32
[27] .comment PROGBITS 0000000000000000 00003010
000000000000002d 0000000000000001 MS 0 0 1
[28] .symtab SYMTAB 0000000000000000 00003040
00000000000005d0 0000000000000018 29 18 8
[29] .strtab STRTAB 0000000000000000 00003610
000000000000049c 0000000000000000 0 0 1
[30] .shstrtab STRTAB 0000000000000000 00003aac
000000000000011a 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc)【加载时分配内存】, X (execute), M (merge)【可合并(如字符串常量】, S (strings)【包含空字符结尾的字符串。】, I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
D (mbind), l (large), p (processor specific)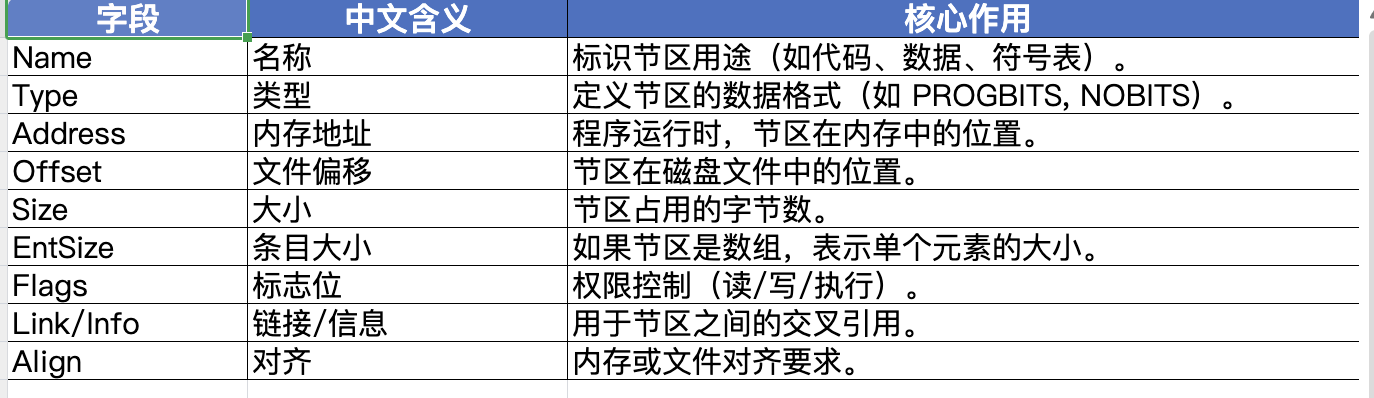
常见类型:
PROGBITS:包含程序定义的信息(如代码或数据)。
NOBITS:不占用文件空间(如 .bss 段),但在内存中分配空间。
SHT_SYMTAB / SHT_DYNSYM:符号表。
SHT_STRTAB:字符串表。
SHT_REL / SHT_RELA:重定位信息。
看不懂正常 主要是想告诉各位 有各种个样 节的信息
4. 节(Section)
- 节(Section):ELF文件中的基本组成单位,包含了特定类型的数据。ELF文件的各种信息和数据都存储在不同的节中,如代码节存储了可执行代码,数据节存储了全局变量和静态数据等。
最常见的节:
- 代码节(.text):用于保存机器指令,是程序的主要执行部分。
- 数据节(.data):保存已初始化的全局变量和局部静态变量。
严格来说没有任何指令可以看到节 但是可以通过反汇编的方式帮助我们看到节(也就是程序的内容)!
shell
objdump -S 目标程序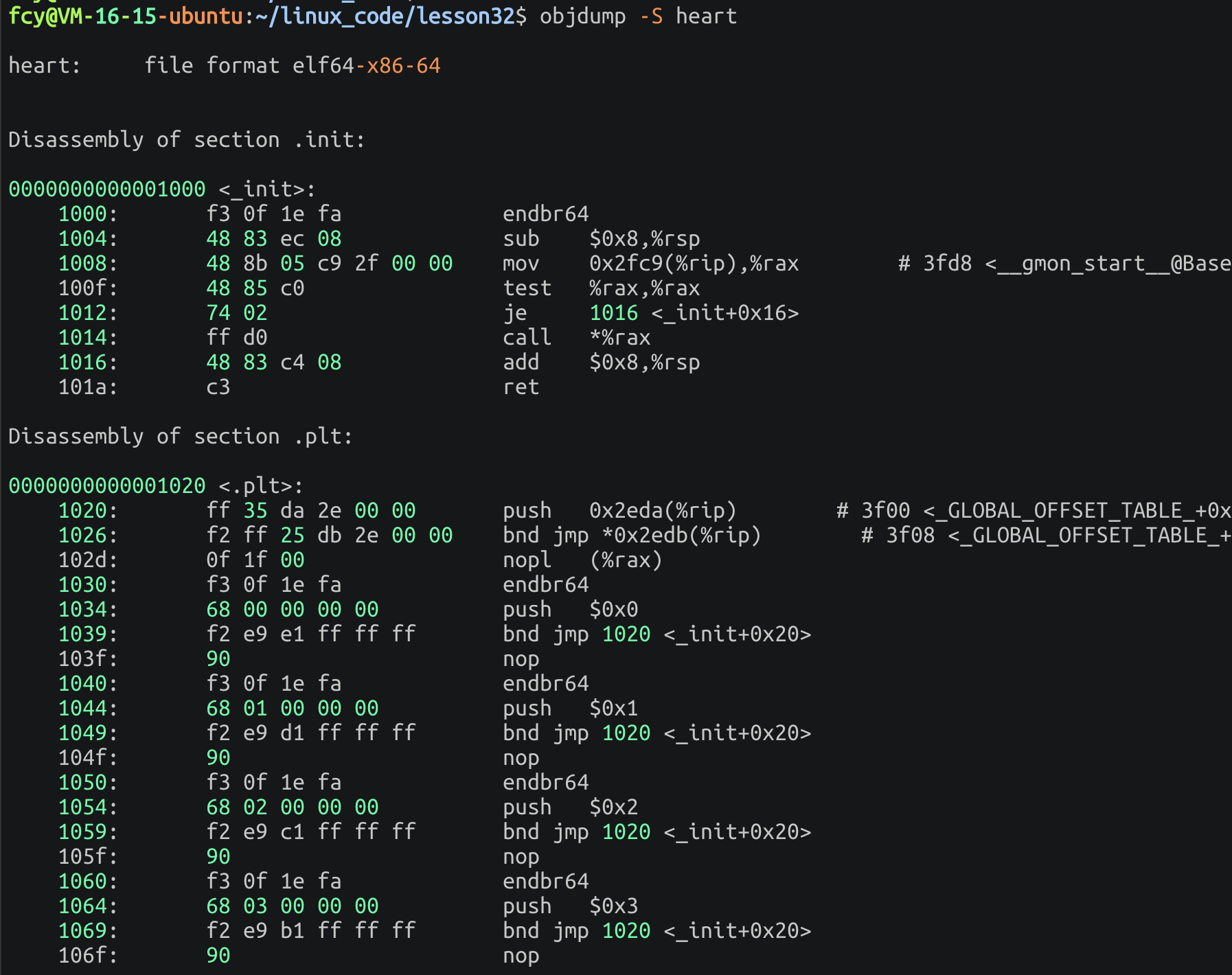
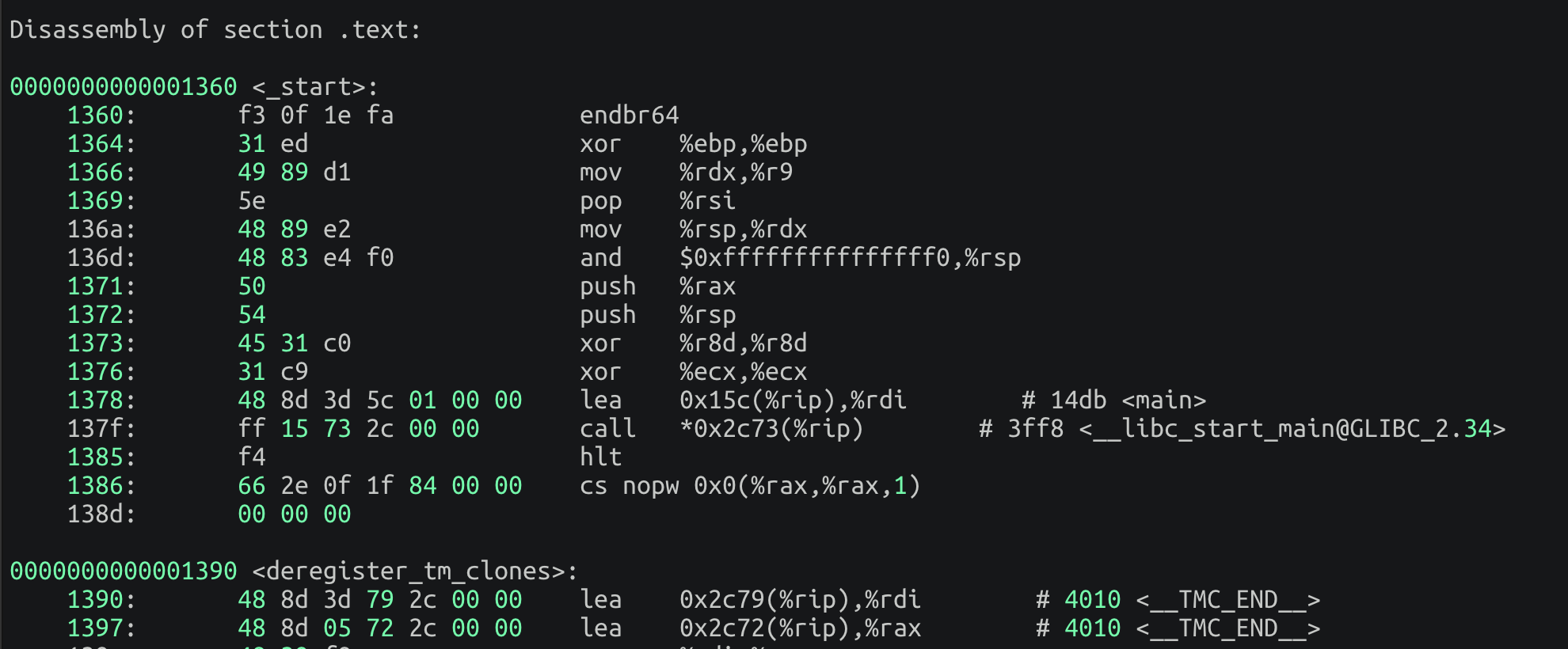
里面最重要的就是.text节 ,标志着代码的开始:
5. 对程序头表和节头表必要的认识(浅读完1~4后看)
其实说那么多 主要是想说明:ELF是没有一个个段;但是确实存在一个个节,不同的节,大小不一,但是权限是可以相同的 ELF是文件 OS是4kb为单位从磁盘读取到内存中的!
就是因为 权限大小不一 有的节只有512B 有的只有128B 那么明明有加载4kb能力确只能加载 128B 不是浪费吗??
所以为了实现更好的内存加载 我们可以把多个相同权限的节 我们在加载时候 由加载器将多个节进行合并成一个段!
所以说程序头表是用来描述操作系统如何将文件加载到内存中运行(节合并段 写着节和段的映射信息、同时还有段的管理信息)。
在加载程序(硬盘->内存)的时候先去ELF头找到程序头表,然后查程序头表确定该如何加载(节->段),然后再去查ELF头去找节头表,最后根据该表,成功找到节在哪里!!
在os中,即内存以段的形式加载管理,运行时将这些段合并为一个大段,统一按虚拟地址管理!,所在虚拟地址所说的段本质时程序头表段的集合!
6. 总结:
格式图:
作者说:关于ELF文件的具体组成 我们其实并没必要深究 这里了解个轮廓就足够我们去理解库的合并了!
5.2 ELF从形成到加载轮廓
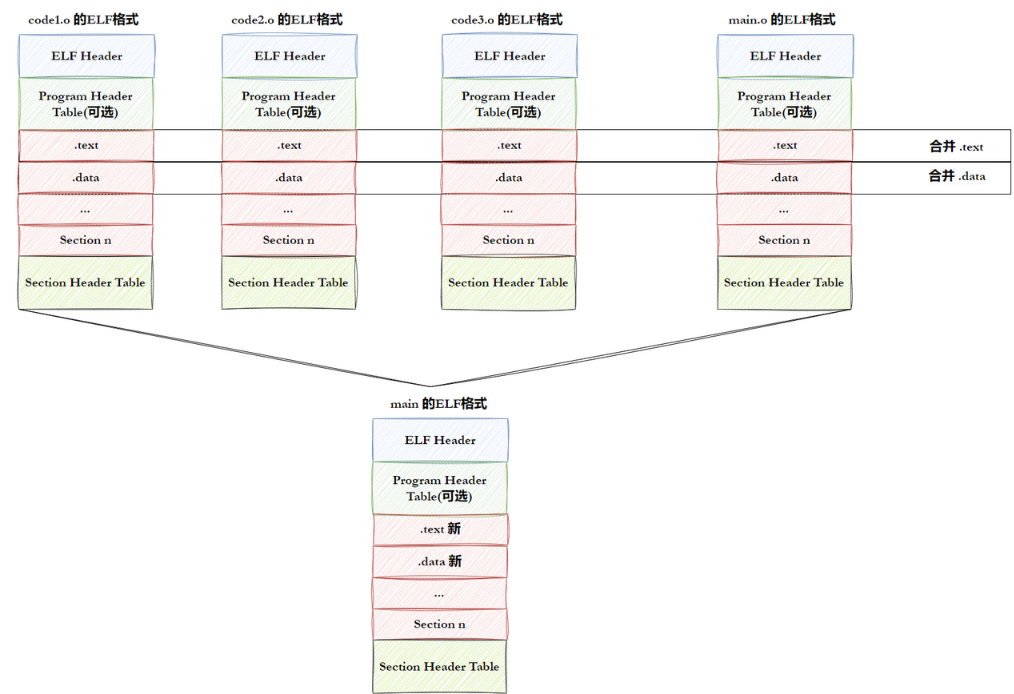
大家有没有思考过这么一个问题: 为什么.o可以形成.so库文件或者可执行程序!!
因为 .o .so甚至可执行,都是 ELF格式的!
ELF形成可执⾏
step-1: 将多份 C/C++ 源代码,翻译成为目标 .o 文件 + 动静态库(ELF)step-2:将多份 .o 文件section进行合并
6. 理解连接与加载
6.1 ELF加载与进程地址空间
6.1.1 虚拟地址与逻辑地址
真实虚拟地址 = 加载基址 + 相对偏移量
预备:
- 创建一个进程,是先创建内核进程相关数据结构?还是先加载
ELF格式的二进制文件?
答:先创建内核数据结构,再加载
ELF格式的二进制文件,甚至可以做到懒加载,即需要的时候再加载!!
- 当一个程序如果没有被加载到内存,程序有没有地址?是什么地址??
答:有地址,反汇编的时候我们不都能看到地址吗!没加载的时候不就是那个吗!
⼀个ELF程序,在没有被加载到内存的时候,本来就有地址,当代计算机⼯作的时候,都采⽤"平坦模式"进⾏⼯作。所以也要求ELF对⾃⼰的代码和数据进⾏统⼀编址:
平坦模式对我们的可执行程序中的"每一行"代码都进行了编址,原则上从 0号地址开始!可以简单理解为现代操作系统给每个进程画的一个巨大、连续且从 0 开始编号的虚拟内存图纸!
也就是说,其实虚拟地址在我们的程序还没有加载到内存的时候,就已经把可执⾏程序进⾏统⼀编址了!
从哪里结束呢?32位机器: 从全0(32个)到 全1(32位)!
这种地址叫:虚拟地址!!!严格来说 叫逻辑地址(对磁盘)!!!
进程mm_struct、vm_area_struct在进程刚刚创建的时候,初始化数据从哪⾥来的? 从ELF各个segment来,每个segment有⾃⼰的起始地址和⾃⼰的⻓度,⽤来初始化内核结构中的start, end等范围数据,另外在⽤详细地址,填充⻚表.所以说虚拟地址空间这个技术标准 不光要求你OS要遵守 编译器也要遵守!
在汇编语言这门课(哥们推荐 B站小甲鱼!)早期没有虚拟地址的时候,我们会学习的CPU(X86),会有很多的段寄存器!我们的代码加载到内存里的时候,我们的代码启始地址会保存在CS寄存器(此时保存的是真正的物理内存中地址!)下,至于代码多长还会有个寄存器来保存我们代码的偏移量!同时数据会有个DS寄存器等等 代码和数据不是存一块的!
当时就要求编译器编译代码的时候 我们需要通过寄存器进行寻址,然后强迫我们代码区(CS存储的位置)为0,然后以0号地址对为开始,然后按照偏移量开始寻址,这种方式我们称为相对地址!
像切蛋糕一样,把内存切成很多小块,代码放一块,数据放另一块,大家不能越界。
举个例子:我在操场入口的第80m处(物理地址) ,又在这棵歪脖子树(启始地址)的40m(偏移量)处!
这种 段地址+偏移量 = 逻辑地址!
但在
虚拟地址我们把代码区和数据区看成一个段(代码区数据区合并在一块),像个大通间一样 都从0开始,这样每个区我们就可以得到一个虚拟地址,往后 数据区开始是0 代码区开始是0 相当于CS刚开始都是0!!然后在磁盘角度都是0+偏移量所以也叫逻辑地址!
记住:只在OS内谈 虚拟地址;磁盘上我们称为 逻辑地址!
6.1.2 重新理解进程虚拟地址空间

我们在创建相关数据结构的时候,如何初始化呢?
首先把可执行程序,从磁盘加载到内存,虚拟地址是在磁盘里面现场的,加载到内存里面后是不是还需要 形成
在内存中的物理地址!每一行代码都有对应的物理地址!!!哪怕懒加载呢!!没有
物理地址但此时依然有虚拟地址是不是!!
那么谁来初始化
mm_struct(虚拟地址空间的结构体)呢! 区域(栈、代码区等)划分 即虚拟地址是不是都从程序头表中读现成的就行了!!然后根据存储的物理地址 我们是不是就可以直接填充页表信息了!!至此不就构建了映射关系了!!!
那么程序在哪里执行??
在
ELF头中 有一个:
这个就是程序的入口 ,
CPU怎么知道执行哪一行代码?
在
EIP(扩展指令指针寄存器)内有个PC指针,程序跑到哪里,他就指向哪里!!(存储的都是虚拟地址)在
CPU内部 还有个CR3寄存器 它会直接指向当前进程的页表!(存储的是页表的物理地址!)
MMU(Memory Management Unit,内存管理单元)是集成在 CPU 内部的一个极其核心的硬件电路模块, EIP将虚拟地址交给MMU,MMU通过CR3查找页表,从而输出物理地址!!

整个虚拟转化为物理的过程 都由CPU自己完成!!
在同一个进程中,不同文件的虚拟地址是可以重复的;在不同进程之间,相同的虚拟地址是完全没问题的。
同一进程:它们在各自的虚拟地址空间里可能正好落在同一段区间,但因为内容完全一样且是只读的,所以不仅不冲突,反而极大地提高了效率。
不同进程:这是因为每个进程都有自己独立的一套"虚拟地址图纸,其实本质是加载基址"(也就是独立的页表)。虽然它们图纸上的门牌号(虚拟地址)都是 0x400000,但通过 CPU 里的 MMU(内存管理单元)和各自独立的页表翻译后,指向的是物理内存条上完全不同的真实位置。
6.2 静态链接的原理
- 无论是自己的
.o,还是静态库中的.o,本质都是把.o文件进行连接的过程 - 所以:研究静态链接,本质就是研究
.o是如何链接的 - 静态库太大 用自己写的2个小程序就能很好的模拟出来了!
两个程序,代码如下:
cpp
$ cat hello.c
#include<stdio.h>
void run();
int main()
{
printf("hello world!\n");
run();
return 0;
}
cpp
$ cat code.c
#include<stdio.h>
void run()
{
printf("running...\n");
}然后在
shell中进行以下操作:
cpp
$ ll
-rw-rw-r-- 1 whb whb 62 Oct 31 15:36 code.c
-rw-rw-r-- 1 whb whb 103 Oct 31 15:36 hello.c
whb@bite:~/test/test/test$ gcc -c *.c
whb@bite:~/test/test/test$ gcc *.o -o main.exe
$ ll
-rw-rw-r-- 1 whb whb 62 Oct 31 15:36 code.c
-rw-rw-r-- 1 whb whb 1672 Oct 31 15:46 code.o
-rw-rw-r-- 1 whb whb 103 Oct 31 15:36 hello.c
-rw-rw-r-- 1 whb whb 1744 Oct 31 15:46 hello.o
-rwxrwxr-x 1 whb whb 16752 Oct 31 15:46 main.exe*此时:
hello.o中的main函数不认识printf和run函数code.o不认识printf函数
查看编译后的.o⽬标⽂件:
objdump -d 命令:将代码段(.text)进⾏反汇编查看
shell
# 查看code.o的代码段
$ objdump -d code.o
code.o: file format elf64-x86-64
Disassembly of section .text:
#在编译阶段,编译器根本不知道你的函数最终会被放在内存的哪个位置 所以全0!
0000000000000000 <run>:
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 48 8d 3d 00 00 00 00 lea 0x0(%rip),%rdi # f
<run+0xf>
f: e8 00 00 00 00 callq 14 <run+0x14>
14: 90 nop
15: 5d pop %rbp
16: c3 retq
# 查看hello.o的代码段
$ objdump -d hello.o
hello.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 48 8d 3d 00 00 00 00 lea 0x0(%rip),%rdi # f
<main+0xf>
f: e8 00 00 00 00 callq 14 <main+0x14>
14: b8 00 00 00 00 mov $0x0,%eax
19: e8 00 00 00 00 callq 1e <main+0x1e>
1e: b8 00 00 00 00 mov $0x0,%eax
23: 5d pop %rbp
24: c3 retq我们可以看到这里的call(f:开头的)指令,它们分别对应之前调用的printf和run函数,但是你会发现他们的跳转地址都被设成了0(e8 00 00 00 00)。那这是为什么呢?
其实就是在编译hello.c的时候,编译器是完全不知道printf和run函数的存在的,比如他们位于内存的哪个区块,代码长什么样都是不知道的。因此,编译器只能将这两个函数的跳转地址先暂时设为0。
这个地址会在哪个时候被修正?链接的时候!为了让链接器将来在链接时能够正确定位到这些被修正的地址,在代码块(.data)中还存在一个重定位表,这张表将来在链接的时候,就会根据表里记录的地址将其修正。
⚠️: 关于
printf属于动态链接 这里先不考虑!
可以用readelf -s 程序名查看重定义表:这里的
UND就是没有定义的意思
shell
# 读取code.o符号表
$ readelf -s code.o
Symbol table '.symtab' contains 13 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS code.c
2: 0000000000000000 0 SECTION LOCAL DEFAULT 1
3: 0000000000000000 0 SECTION LOCAL DEFAULT 3
4: 0000000000000000 0 SECTION LOCAL DEFAULT 4
5: 0000000000000000 0 SECTION LOCAL DEFAULT 5
6: 0000000000000000 0 SECTION LOCAL DEFAULT 7
7: 0000000000000000 0 SECTION LOCAL DEFAULT 8
8: 0000000000000000 0 SECTION LOCAL DEFAULT 9
9: 0000000000000000 0 SECTION LOCAL DEFAULT 6
10: 0000000000000000 23 FUNC GLOBAL DEFAULT 1 run
11: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND
_GLOBAL_OFFSET_TABLE_
12: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND puts
#puts:就是printf的实现
#UND就是:undefine,表⽰未定义说⽩了就是本.o⽂件找不到
# 读取hello.o符号表
whb@bite:~/test/test/test$ readelf -s hello.o
Symbol table '.symtab' contains 14 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS hello.c
2: 0000000000000000 0 SECTION LOCAL DEFAULT 1
3: 0000000000000000 0 SECTION LOCAL DEFAULT 3
4: 0000000000000000 0 SECTION LOCAL DEFAULT 4
5: 0000000000000000 0 SECTION LOCAL DEFAULT 5
6: 0000000000000000 0 SECTION LOCAL DEFAULT 7
7: 0000000000000000 0 SECTION LOCAL DEFAULT 8
8: 0000000000000000 0 SECTION LOCAL DEFAULT 9
9: 0000000000000000 0 SECTION LOCAL DEFAULT 6
10: 0000000000000000 37 FUNC GLOBAL DEFAULT 1 main
11: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND
_GLOBAL_OFFSET_TABLE_
12: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND puts
13: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND run
#puts:就是printf的实现, run就是我们⾃⼰的⽅法在hello.o中未定义(因为在code.o中)
#UND就是:undefine,表⽰未定义说⽩了就是本.o⽂件找不到
# 读取main.exe符号表
$ readelf -s main.exe
Symbol table '.dynsym' contains 7 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 NOTYPE WEAK DEFAULT UND
_ITM_deregisterTMCloneTab
2: 0000000000000000 0 FUNC GLOBAL DEFAULT UND puts@GLIBC_2.2.5
(2)
3: 0000000000000000 0 FUNC GLOBAL DEFAULT UND
__libc_start_main@GLIBC_2.2.5 (2)
4: 0000000000000000 0 NOTYPE WEAK DEFAULT UND __gmon_start__
5: 0000000000000000 0 NOTYPE WEAK DEFAULT UND
_ITM_registerTMCloneTable
6: 0000000000000000 0 FUNC WEAK DEFAULT UND
__cxa_finalize@GLIBC_2.2.5 (2)
Symbol table '.symtab' contains 67 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000318 0 SECTION LOCAL DEFAULT 1
2: 0000000000000338 0 SECTION LOCAL DEFAULT 2
3: 0000000000000358 0 SECTION LOCAL DEFAULT 3
4: 000000000000037c 0 SECTION LOCAL DEFAULT 4
5: 00000000000003a0 0 SECTION LOCAL DEFAULT 5
6: 00000000000003c8 0 SECTION LOCAL DEFAULT 6
7: 0000000000000470 0 SECTION LOCAL DEFAULT 7
8: 00000000000004f2 0 SECTION LOCAL DEFAULT 8
9: 0000000000000500 0 SECTION LOCAL DEFAULT 9
10: 0000000000000520 0 SECTION LOCAL DEFAULT 10
11: 00000000000005e0 0 SECTION LOCAL DEFAULT 11
12: 0000000000001000 0 SECTION LOCAL DEFAULT 12
13: 0000000000001020 0 SECTION LOCAL DEFAULT 13
14: 0000000000001040 0 SECTION LOCAL DEFAULT 14
15: 0000000000001050 0 SECTION LOCAL DEFAULT 15
16: 0000000000001060 0 SECTION LOCAL DEFAULT 16
17: 0000000000001208 0 SECTION LOCAL DEFAULT 17
18: 0000000000002000 0 SECTION LOCAL DEFAULT 18
19: 000000000000201c 0 SECTION LOCAL DEFAULT 19
20: 0000000000002068 0 SECTION LOCAL DEFAULT 20
21: 0000000000003db8 0 SECTION LOCAL DEFAULT 21
22: 0000000000003dc0 0 SECTION LOCAL DEFAULT 22
23: 0000000000003dc8 0 SECTION LOCAL DEFAULT 23
24: 0000000000003fb8 0 SECTION LOCAL DEFAULT 24
25: 0000000000004000 0 SECTION LOCAL DEFAULT 25
26: 0000000000004010 0 SECTION LOCAL DEFAULT 26
27: 0000000000000000 0 SECTION LOCAL DEFAULT 27
28: 0000000000000000 0 FILE LOCAL DEFAULT ABS crtstuff.c
29: 0000000000001090 0 FUNC LOCAL DEFAULT 16
deregister_tm_clones
30: 00000000000010c0 0 FUNC LOCAL DEFAULT 16 register_tm_clones
31: 0000000000001100 0 FUNC LOCAL DEFAULT 16
__do_global_dtors_aux
32: 0000000000004010 1 OBJECT LOCAL DEFAULT 26 completed.8061
33: 0000000000003dc0 0 OBJECT LOCAL DEFAULT 22
__do_global_dtors_aux_fin
34: 0000000000001140 0 FUNC LOCAL DEFAULT 16 frame_dummy
35: 0000000000003db8 0 OBJECT LOCAL DEFAULT 21
__frame_dummy_init_array_
36: 0000000000000000 0 FILE LOCAL DEFAULT ABS code.c
37: 0000000000000000 0 FILE LOCAL DEFAULT ABS hello.c
38: 0000000000000000 0 FILE LOCAL DEFAULT ABS crtstuff.c
39: 000000000000218c 0 OBJECT LOCAL DEFAULT 20 __FRAME_END__
40: 0000000000000000 0 FILE LOCAL DEFAULT ABS
41: 0000000000003dc0 0 NOTYPE LOCAL DEFAULT 21 __init_array_end
42: 0000000000003dc8 0 OBJECT LOCAL DEFAULT 23 _DYNAMIC
43: 0000000000003db8 0 NOTYPE LOCAL DEFAULT 21 __init_array_start
44: 000000000000201c 0 NOTYPE LOCAL DEFAULT 19 __GNU_EH_FRAME_HDR
0 OBJECT LOCAL DEFAULT 24
_GLOBAL_OFFSET_TABLE_
46: 0000000000001000 0 FUNC LOCAL DEFAULT 12 _init
47: 0000000000001200 5 FUNC GLOBAL DEFAULT 16 __libc_csu_fini
48: 0000000000000000 0 NOTYPE WEAK DEFAULT UND
_ITM_deregisterTMCloneTab
49: 0000000000004000 0 NOTYPE WEAK DEFAULT 25 data_start
50: 0000000000000000 0 FUNC GLOBAL DEFAULT UND puts@@GLIBC_2.2.5
51: 0000000000004010 0 NOTYPE GLOBAL DEFAULT 25 _edata
52: 0000000000001149 23 FUNC GLOBAL DEFAULT 16 run
53: 0000000000001208 0 FUNC GLOBAL HIDDEN 17 _fini
54: 0000000000000000 0 FUNC GLOBAL DEFAULT UND
__libc_start_main@@GLIBC_
55: 0000000000004000 0 NOTYPE GLOBAL DEFAULT 25 __data_start
56: 0000000000000000 0 NOTYPE WEAK DEFAULT UND __gmon_start__
57: 0000000000004008 0 OBJECT GLOBAL HIDDEN 25 __dso_handle
58: 0000000000002000 4 OBJECT GLOBAL DEFAULT 18 _IO_stdin_used
59: 0000000000001190 101 FUNC GLOBAL DEFAULT 16 __libc_csu_init
60: 0000000000004018 0 NOTYPE GLOBAL DEFAULT 26 _end
61: 0000000000001060 47 FUNC GLOBAL DEFAULT 16 _start
62: 0000000000004010 0 NOTYPE GLOBAL DEFAULT 26 __bss_start
63: 0000000000001160 37 FUNC GLOBAL DEFAULT 16 main
64: 0000000000004010 0 OBJECT GLOBAL HIDDEN 25 __TMC_END__
65: 0000000000000000 0 NOTYPE WEAK DEFAULT UND
_ITM_registerTMCloneTable
66: 0000000000000000 0 FUNC WEAK DEFAULT UND
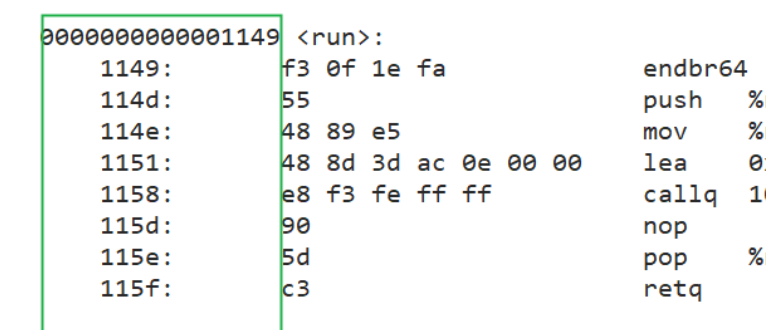
__cxa_finalize@@GLIBC_2.2两个.o进⾏合并之后,在最终的可执⾏程序中,就找到了run:
0000000000001149:其实是地址
FUNC:表⽰run符号类型是个函数
然后后面的数字 16:就是run函数所在的section被合并最终的哪⼀个section中了,16就是下标
不信 直接查看main.exe的节头表!

shell
# 读取可执⾏程序最终的所有的section清单
$ readelf -S main.exe
There are 31 section headers, starting at offset 0x39b0:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .interp PROGBITS 0000000000000318 00000318
000000000000001c 0000000000000000 A 0 0 1
[ 2] .note.gnu.propert NOTE 0000000000000338 00000338
0000000000000020 0000000000000000 A 0 0 8
[ 3] .note.gnu.build-i NOTE 0000000000000358 00000358
0000000000000024 0000000000000000 A 0 0 4
[ 4] .note.ABI-tag NOTE 000000000000037c 0000037c
0000000000000020 0000000000000000 A 0 0 4
[ 5] .gnu.hash GNU_HASH 00000000000003a0 000003a0
0000000000000024 0000000000000000 A 6 0 8
[ 6] .dynsym DYNSYM 00000000000003c8 000003c8
00000000000000a8 0000000000000018 A 7 1 8
[ 7] .dynstr STRTAB 0000000000000470 00000470
0000000000000082 0000000000000000 A 0 0 1
[ 8] .gnu.version VERSYM 00000000000004f2 000004f2
000000000000000e 0000000000000002 A 6 0 2
[ 9] .gnu.version_r VERNEED 0000000000000500 00000500
0000000000000020 0000000000000000 A 7 1 8
[10] .rela.dyn RELA 0000000000000520 00000520
00000000000000c0 0000000000000018 A 6 0 8
[11] .rela.plt RELA 00000000000005e0 000005e0
0000000000000018 0000000000000018 AI 6 24 8
[12] .init PROGBITS 0000000000001000 00001000
000000000000001b 0000000000000000 AX 0 0 4
[13] .plt PROGBITS 0000000000001020 00001020
0000000000000020 0000000000000010 AX 0 0 16
[14] .plt.got PROGBITS 0000000000001040 00001040
0000000000000010 0000000000000010 AX 0 0 16
[15] .plt.sec PROGBITS 0000000000001050 00001050
0000000000000010 0000000000000010 AX 0 0 16
[16] .text PROGBITS 0000000000001060 00001060
00000000000001a5 0000000000000000 AX 0 0 16
[17] .fini PROGBITS 0000000000001208 00001208
000000000000000d 0000000000000000 AX 0 0 4
[18] .rodata PROGBITS 0000000000002000 00002000
000000000000001c 0000000000000000 A 0 0 4
[19] .eh_frame_hdr PROGBITS 000000000000201c 0000201c
000000000000004c 0000000000000000 A 0 0 4
[20] .eh_frame PROGBITS 0000000000002068 00002068
0000000000000128 0000000000000000 A 0 0 8
[21] .init_array INIT_ARRAY 0000000000003db8 00002db8
0000000000000008 0000000000000008 WA 0 0 8
[22] .fini_array FINI_ARRAY 0000000000003dc0 00002dc0
0000000000000008 0000000000000008 WA 0 0 8
[23] .dynamic DYNAMIC 0000000000003dc8 00002dc8
00000000000001f0 0000000000000010 WA 7 0 8
[24] .got PROGBITS 0000000000003fb8 00002fb8
0000000000000048 0000000000000008 WA 0 0 8
[25] .data PROGBITS 0000000000004000 00003000
0000000000000010 0000000000000000 WA 0 0 8
[26] .bss NOBITS 0000000000004010 00003010
0000000000000008 0000000000000000 WA 0 0 1
[27] .comment PROGBITS 0000000000000000 00003010
000000000000002b 0000000000000001 MS 0 0 1
[28] .symtab SYMTAB 0000000000000000 00003040
0000000000000648 0000000000000018 29 47 8
[29] .strtab STRTAB 0000000000000000 00003688
000000000000020e 0000000000000000 0 0 1
[30] .shstrtab STRTAB 0000000000000000 00003896
000000000000011a 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
l (large), p (processor specific)hello.o和code.o的.text被合并了,是main.exe的第16个section:

关于hello.o或者code.o call后⾯的00 00 00 00有没有被修改成为具体的最终函数地址呢?
shell
$ objdump -d main.exe # 反汇编main.exe只查看代码段信息,包含源代码太长了(接近500多行),我就不展示了 直接截图一些关键的部分!
shell
Disassembly of section .text:
0000000000001060 <_start>:
....
0000000000001149 <run>:
1149: f3 0f 1e fa endbr64
114d: 55 push %rbp
114e: 48 89 e5 mov %rsp,%rbp
1151: 48 8d 3d ac 0e 00 00 lea 0xeac(%rip),%rdi
# 2004 <_IO_stdin_used+0x4>
1158: e8 f3 fe ff ff callq 1050 <puts@plt>
115d: 90 nop
115e: 5d pop %rbp
115f: c3 retq
0000000000001160 <main>:
1160: f3 0f 1e fa endbr64
1164: 55 push %rbp
1165: 48 89 e5 mov %rsp,%rbp
1168: 48 8d 3d a0 0e 00 00 lea 0xea0(%rip),%rdi
# 200f <_IO_stdin_used+0xf>
116f: e8 dc fe ff ff callq 1050 <puts@plt>
1174: b8 00 00 00 00 mov $0x0,%eax
1179: e8 cb ff ff ff callq 1149 <run>
117e: b8 00 00 00 00 mov $0x0,%eax
1183: 5d pop %rbp
1184: c3 retq
1185: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
118c: 00 00 00
118f: 90 nop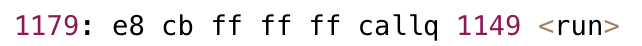
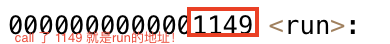
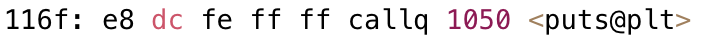
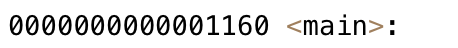
最终:
- 两个.o的代码段合并到了一起,并进行了统一的编址
- 链接的时候,会修改.o中没有确定的函数地址,在合并完成之后,进行相关call地址,完成代码调用
上述
code.o中run函数和hello.o中使用run函数 通过链接形成可执行程序的过程仅针对run函数本身而言这是属于合并的过程!虽然既不属于动也不是属于静态链接 但是该过程的原理和静态链接一模一样!!
总结 静态链接的本质
静态链接就是把库中的.o进⾏合并,和上述过程⼀样!!
所以链接其实就是将编译之后的所有⽬标⽂件连同⽤到的⼀些静态库运⾏时库组合,拼装成⼀个独⽴的可执⾏⽂件。其中就包括我们之前提到的地址修正,当所有模块组合在⼀起之后,链接器会根据我们的.o⽂件或者静态库中的重定位表找到那些需要被重定位的函数全局变量,从⽽修正它们的地址。这其实就是静态链接的过程。
静态链接是一个"合并"与"统一修改"的过程:
- 将各个目标文件合并,然后基于 0 偏移的相对位置,映射并修正为最终可执行文件中统一的虚拟内存绝对地址
- 同时会把原本文件内没有实现的函数(像
hello.c里面的run反汇编后函数地址是0)设置一个新虚拟地址。
这样,当操作系统把这个庞大的可执行文件加载到内存时,CPU 才能通过 EIP 寄存器准确地跳转到每一个函数的正确位置去执行指令。
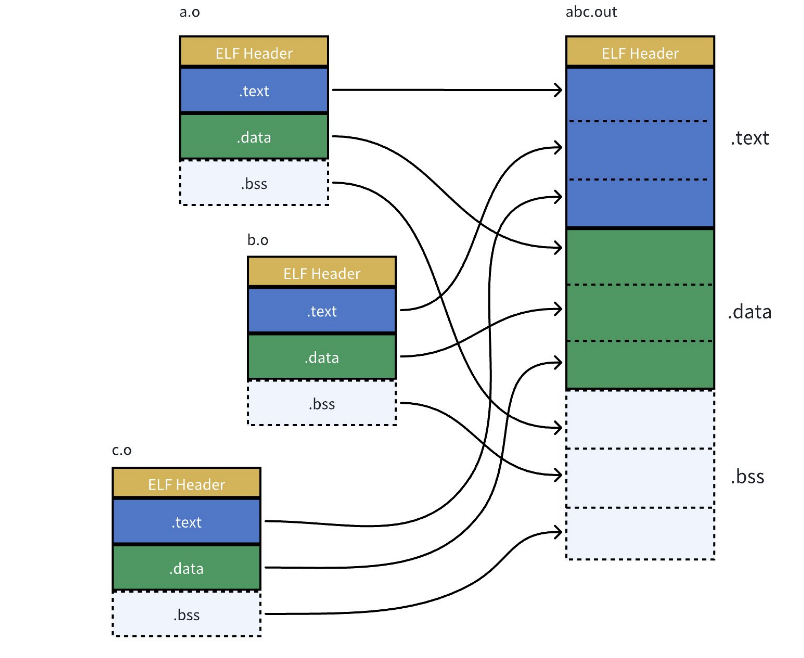
6.2 进程间如何共享库/动态库的加载
有一个动态库 进程A要用 进程B也要用 动态库可以同时映射在两个进程的页表内, 所以动态库在内存中只需要存在一份,只需要加载一次!!所以动态库也叫作共享库!
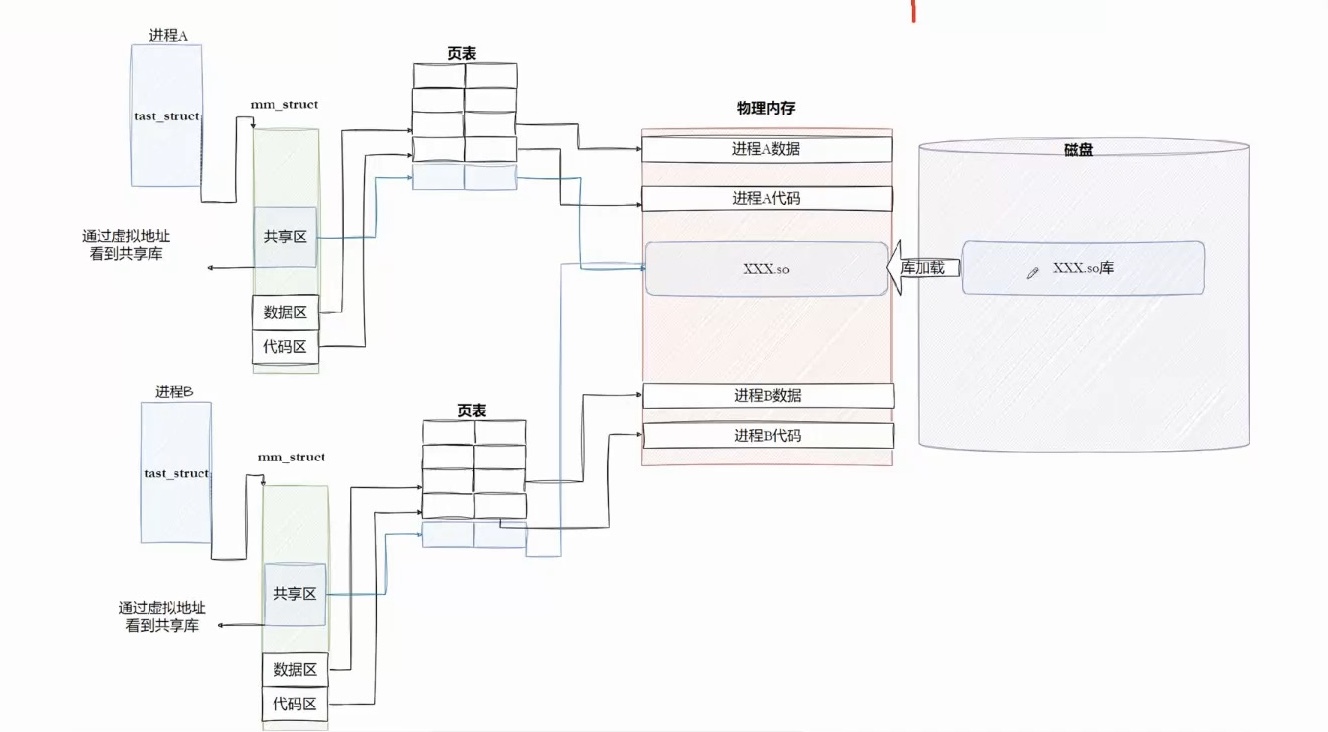
在这之前我们要有个认识 编译C、C++语言的本质是编译出CPU认识的指令集(CPU的指令集就是二进制的!)所以为什么Linux编译好的程序不能在安卓手机上跑,因为CPU的指令集不同!软件上就是 系统调用不同!
进程在加载的的时候,需要先找到库!
cpp
$ cat hello.c
#include<stdio.h>
void run();
int main()
{
printf("hello world!\n");
run();
return 0;
}
cpp
$ cat code.c
#include<stdio.h>
void run()
{
printf("running...\n");
}还是这两个程序 我们编译链接后 查看重定义表 发现puts(printf底层)依然无定义!
上面的
@GLIBC_2.2.5就是表明该库在C标准库中!只有当程序运行时,C库都需要先加载到内存,然后再由UND变成一个确定的地址!

加载库前,需要先找到库,怎么找到就需要6.1对应的方法了!
库对应于虚拟内存的共享区:
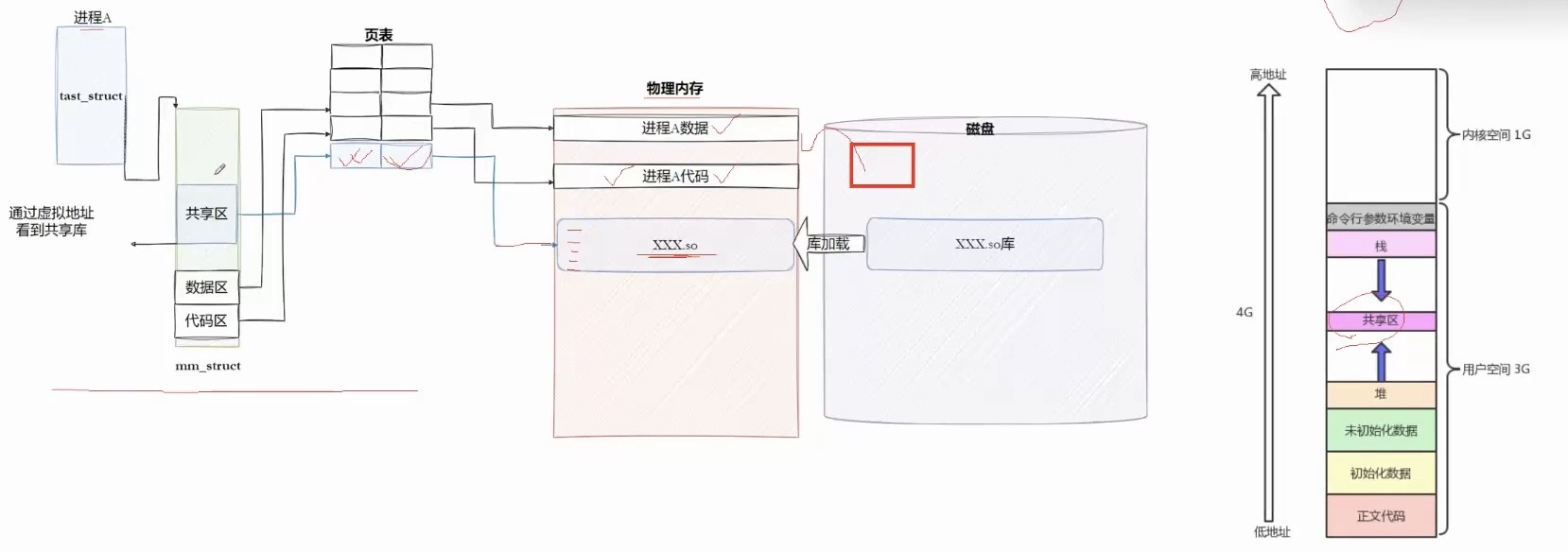
所以库函数调用的本质也是在进程的虚拟地址空间进行函数跳转!
6.3 动态链接的原理
6.3.1 概要
静态链接 最⼤的问题在于⽣成的⽂件体积⼤,并且相当耗费内存资源。随着软件复杂度的提升,我们的操作系统也越来越臃肿,不同的软件就有可能都包含了相同的功能和代码,显然会浪费⼤量的硬盘空间。
而动态库的出现,当多个进程需要用到资源的时候,只需要在内存中形成一份!
好了,问题来了: 我们的OS怎么知道哪些库已经被加载了?
所以在OS有一个数据结构专门管理这个 这里就不看了 因为真的太复杂了 知道有这个结构就行!我们可以从这个结构
得知已经加载入内存库的名字,库的虚拟地址!!
最后,要交代一个结论,动态链接实际上将链接的整个过程推迟到了程序加载的时候(即程序准备运行时,而不是gcc编译时)。比如我们去运行一个程序,操作系统会首先将程序的数据代码连同它用到的一系列动态库先加载到内存,其中每个动态库的加载地址都是不固定的,操作系统会根据当前地址空间的使用情况为它们动态分配一段内存。
当动态库被加载到内存以后,一旦它的内存地址被确定,我们就可以去修正动态库中的那些函数跳转地址了。
6.3.2 我们的可执⾏程序被编译器动了⼿脚(了解即可)
shell
$ ldd /usr/bin/ls
linux-vdso.so.1 (0x00007fffdd85f000)
libselinux.so.1 => /lib/x86_64-linux-gnu/libselinux.so.1
(0x00007f42c025a000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f42c0068000)
libpcre2-8.so.0 => /lib/x86_64-linux-gnu/libpcre2-8.so.0
(0x00007f42bffd7000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007f42bffd1000)
/lib64/ld-linux-x86-64.so.2 (0x00007f42c02b6000)
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0
(0x00007f42bffae000)
$ ldd main.exe
linux-vdso.so.1 (0x00007fff231d6000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f197ec3b000)
/lib64/ld-linux-x86-64.so.2 (0x00007f197ee3e000)基本上所有程序除了依赖C、C++标准库,还依赖:

在C/C++程序中,当程序开始执行时,它首先并不会直接跳转到main函数。实际上,程序的入口点是_start,这是一个由C运行时库(通常是glibc)或链接器(如ld)提供的特殊函数。
在_start函数中,会执行一系列初始化操作,这些操作包括:
- 设置堆栈:为程序创建一个初始的堆栈环境。
- 初始化数据段:将程序的数据段(如全局变量和静态变量)从初始化数据段复制到相应的内存位置,并清零未初始化的数据段。
- 动态链接: 这是关键的一步,
_start函数会调用动态链接器的代码来解析和加载程序所依赖的动态库(shared libraries)。动态链接器会处理所有的符号解析和重定位,确保程序中的函数调用和变量访问能够正确地映射到动态库中的实际地址。
动态链接器:
- 动态链接器(如
ld-linux.so)负责在程序运行时加载动态库。 - 当程序启动时,动态链接器会解析程序中的动态库依赖,并加载这些库到内存中。
环境变量和配置文件:
- Linux系统通过环境变量(如
LD_LIBRARY_PATH)和配置文件(如/etc/ld.so.conf及其子配置文件)来指定动态库的搜索路径。 - 这些路径会被动态链接器在加载动态库时搜索。
缓存文件:
- 为了提高动态库的加载效率,Linux系统会维护一个名为
/etc/ld.so.cache的缓存文件。 - 该文件包含了系统中所有已知动态库的路径和相关信息,动态链接器在加载动态库时会首先搜索这个缓存文件。
- 调用
__libc_start_main:一旦动态链接完成,_start函数会调用__libc_start_main(这是glibc提供的一个函数)。__libc_start_main函数负责执行一些额外的初始化工作,比如设置信号处理函数、初始化线程库(如果使用了线程)等。 - 调用
main函数:最后,__libc_start_main函数会调用程序的main函数,此时程序的执行控制权才正式交给用户编写的代码。 - 处理
main函数的返回值:当main函数返回时,__libc_start_main会负责处理这个返回值,并最终调用_exit函数来终止程序。
上述过程描述了C/C++程序在main函数之前执行的一系列操作,但这些操作对于大多数程序员来说是透明的。程序员通常只需要关注main函数中的代码,而不需要关心底层的初始化过程。然而,了解这些底层细节有助于更好地理解程序的执行流程和调试问题。
了解即可!有些不是很懂也没事
6.3.3 动态库中的相对地址
动态库为了随时进⾏加载,为了⽀持并映射到任意进程的任意位置,对动态库中的⽅法,统⼀编址,采⽤相对编址的⽅案进⾏编制的(其实可执⾏程序也⼀样,都要遵守平坦模式,只不过exe是直接加载的)。
- 可执行程序 (exe):它是主角,通常会被加载器安排在一个比较固定的起始位置(虽然也有 ASLR,但相对规律)。
- 动态库 (so) :它是配角,必须随时准备填补主角内存大院里的各种空缺,所以它对"相对编址"的依赖比可执行程序更强,也就是文中强调的 "位置无关代码(PIC)"。
动态库是没有
main函数的,动态库里面有大量的方法,每个方法都有自己的地址!都是从全0编到全F:
shell
# ubuntu下查看任意⼀个库的反汇编
objdump -S /lib/x86_64-linux-gnu/libc-2.31.so | less
# Cetnos下查看任意⼀个库的反汇编
$ objdump -S /lib64/libc-2.17.so | less6.3.4 动态符号表 (.dynsym)
静态库已经说过了其实但为了完整性再说一遍
这是最核心的"花名册"。当你编译生成 .so 文件时,编译器会把库里所有的对外函数和变量信息整理成一张表。在这张表中,每一个符号(比如 printf 或你自己写的 funcA)都有一个对应的条目,里面详细记录了它的名字、大小以及它在库内部的相对地址(也就是偏移量)。

他最后会编译的时候会存储在进程的数据区内 通过readlef -s查询
!
6.3.5 程序和库具体映射
- 动态库也是一个文件,要访问也是要被先加载(加载操作
参考ext文件系统),要加载也是要被打开的 - 让我们的进程找到动态库的本质:也是文件操作,不过我们访问库函数,通过虚拟地址进行跳转访问的,所以需要把动态库映射到进程的地址空间中(访问参考
IO部分!)
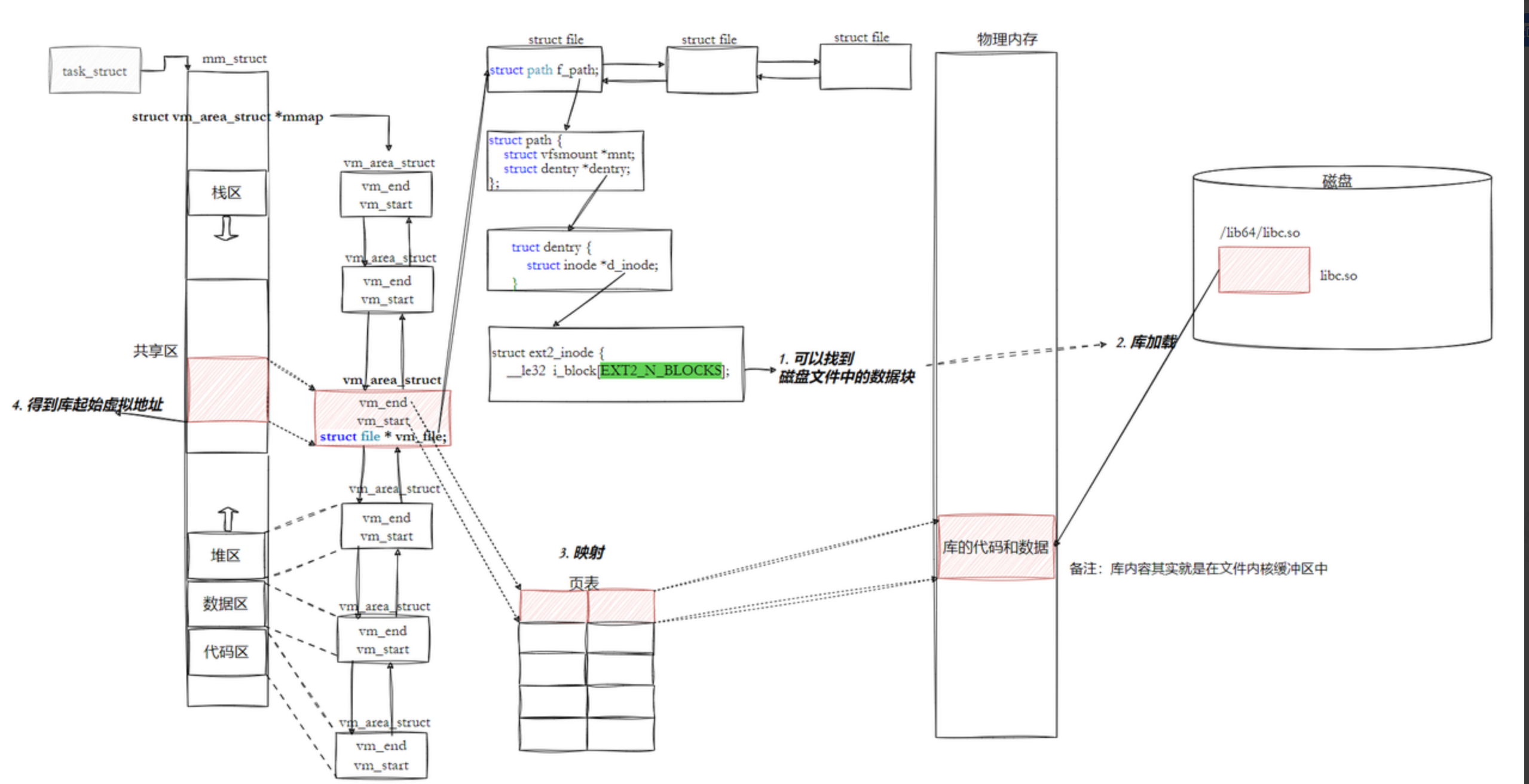
6.3.6 程序,怎么进⾏库函数调⽤
根据上面的内容,我们可以知道以下信息:
- 库已经被我们映射到了当前进程的地址空间中
- 库的虚拟起始地址我们也已经知道了
- 库中每一个方法的偏移量地址我们也知道
- 所以:访问库中任意方法,只需要知道库的
起始虚拟地址+方法偏移量即可定位库中的方法- 而且:整个调用过程,是从代码区跳转到共享区,调用完毕在返回到代码区,整个过程完全在进程地址空间中进行的
假如:编译器/链接器在gcc阶段查出 printf 在 libc.so 中的固定偏移量(例如 0x51100),并记录在你的程序里。
所以说此时偏移地址已经确定了!
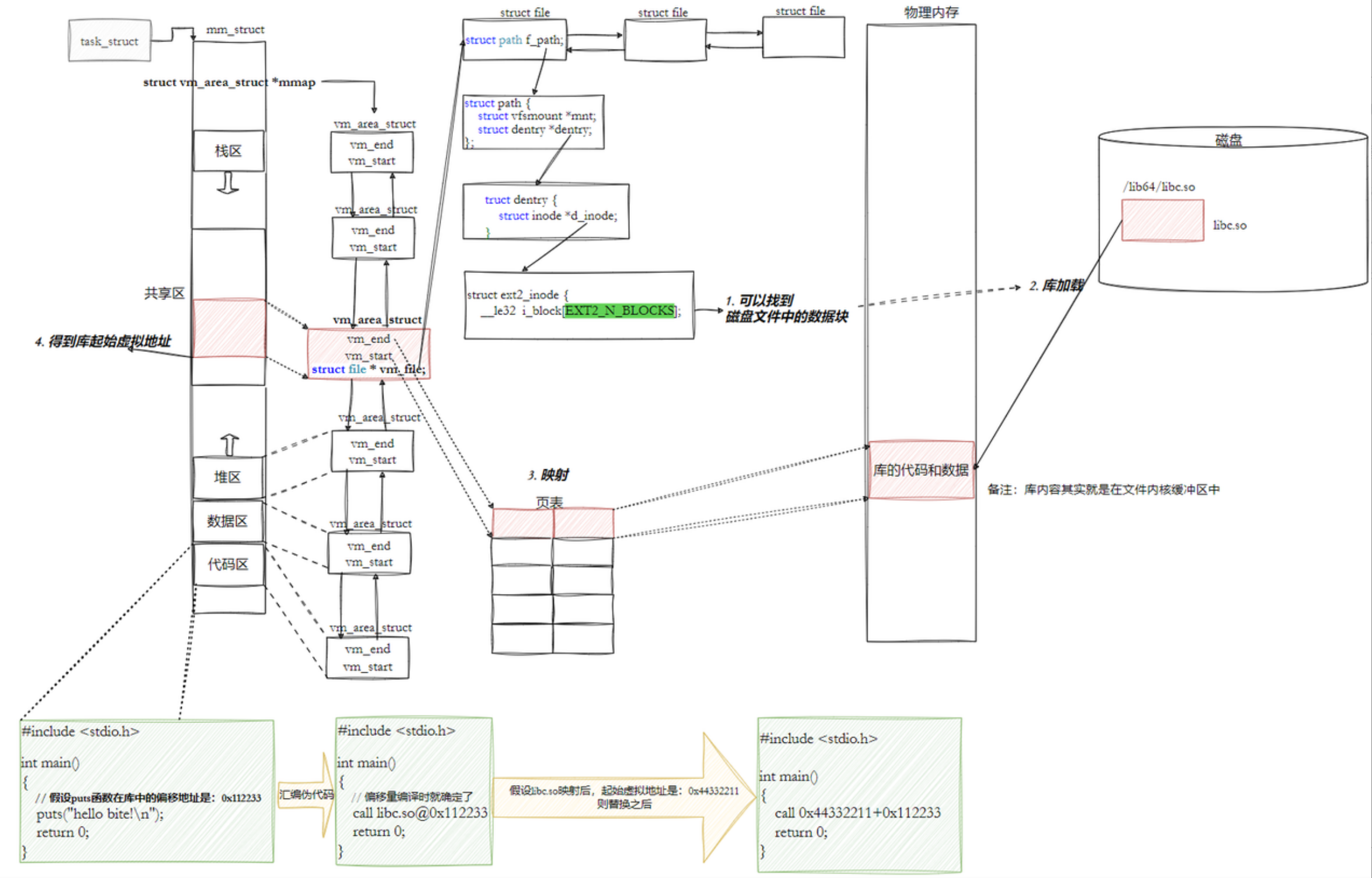
加载的时候,修改代码中call后面的0000...000最后 变成了动态库的起始虚拟地址+方法在库中的偏移量!
在内存加载的过程中加载顺序为:1.内核结构 2.动态库 3.代码和数据
6.3.7 全局偏移量表GOT(global offset table)
我们的程序运⾏之前,先把所有库加载并映射,所有库的起始虚拟地址都应该提前知道。然后对我们加载到内存中的程序的库函数调⽤进⾏地址修改,在内存中⼆次完成地址设置 (这个叫做加载地址重定位)
问题来了: 修改的是代码区?不是说代码区在进程中是只读的吗?怎么能修改呢!!

动态链接 采用的做法是在 .data (可执行程序或者库自己)中专门预留一片区域用来存放函数的跳转地址,它也被叫做全局偏移表GOT,表中每一项都是本运行模块要引用的一个全局变量或函数的地址。
- 因为
.data节是可读写的,所以可以支持动态进行修改

然后在加载到内存的时候.got 和 .data对合并到一个段内 即数据区!

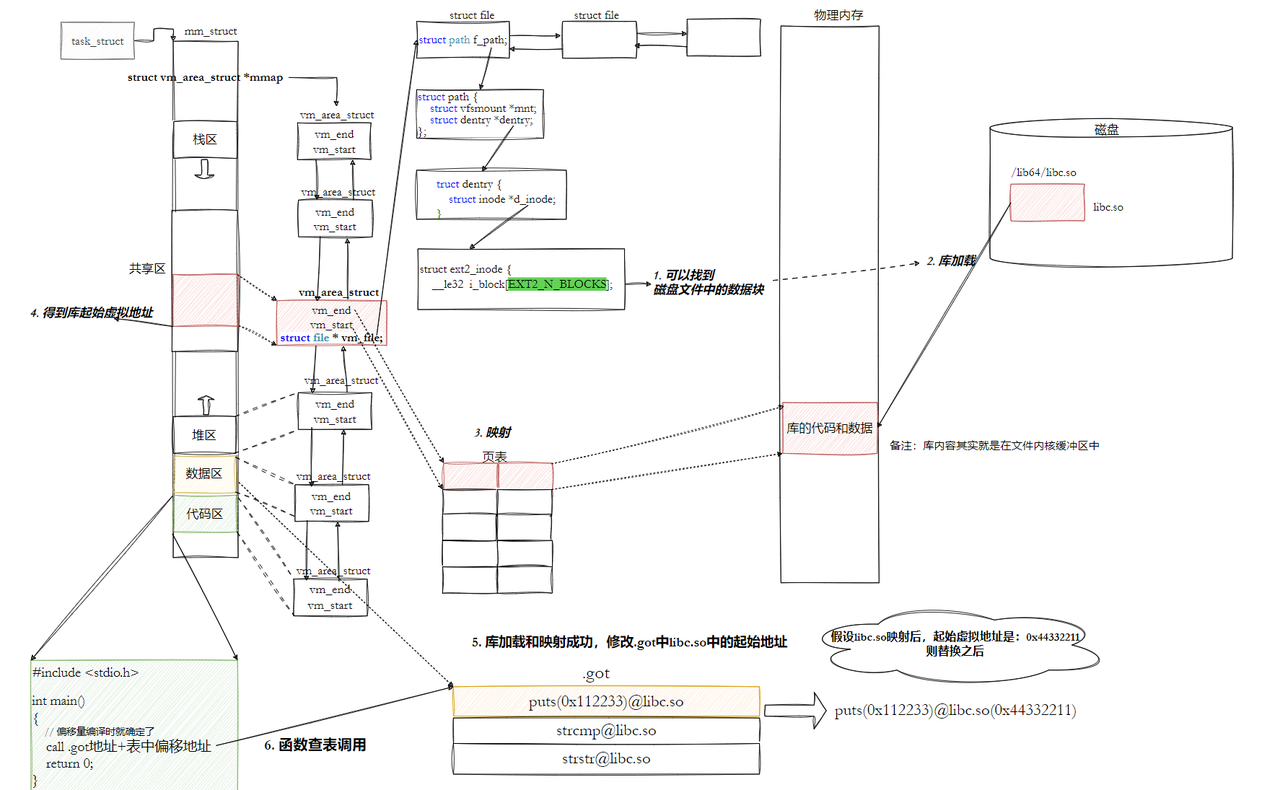
如图,在数据区里 记录了该进程用到的所有库方法的偏移地址和库的名字 !
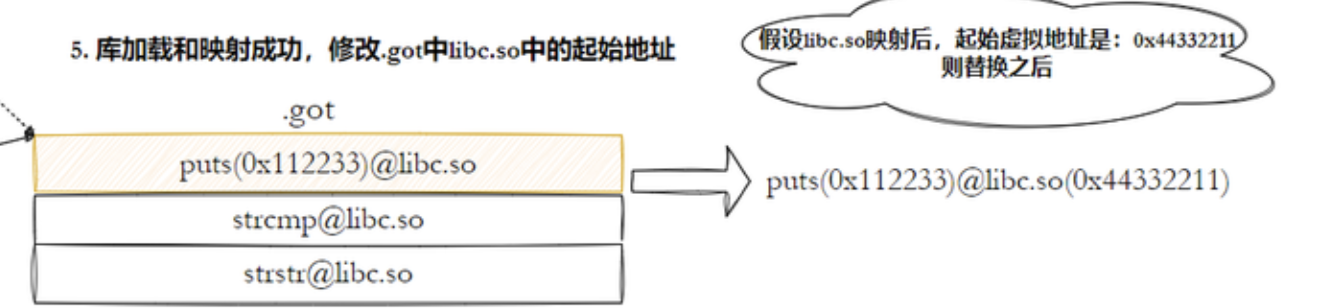
在编译的时候就会确定我们要调用的函数,我们本来是这么想的(6.3.5部分):

但实际上,编译时,此时在call后面记录的是.got地址+表中该方法的偏移量!(即我要调用的方法是在这张表的什么位置),所以当我们需要加载程序的时候(即需要运行程序的时候), 当库加载和映射成功后直接在数据区修改对应的起始地址!
- 由于代码段只读,我们不能直接修改代码段。但有了GOT表,代码便可以被所有进程共享。但在不同进程的地址空间中,各动态库的绝对地址、相对位置都不同。反映到GOT表上,就是每个进程的每个动态库都有独立的GOT表,所以进程间不能共享GOT表。
- 在单个.so下,由于GOT表与
.text的相对位置是固定的,我们完全可以利用CPU的相对寻址来找到GOT表。( 即当程序运行到 .text 段里某条需要查表的指令时,CPU 会以自己当前所在的地址为起点,加上一个编译时就计算好的固定偏移量,直接算出 GOT 表的真实地址。) - 在调用函数的时候会首先查表,然后根据表中的地址来进行跳转,这些地址在动态库加载的时候会被修改为真正的地址。
- 这种方式实现的动态链接就被叫做 PIC 地址无关代码 。 换句话说,我们的动态库不需要做任何修改,被加载到任意内存地址都能够正常运行,并且能够被所有进程共享 ,这也是为什么之前我们给编译器指定
-fPIC参数的原因,PIC=相对编址+GOT。
6.3.8 库间依赖\延迟绑定(简单了解即可)
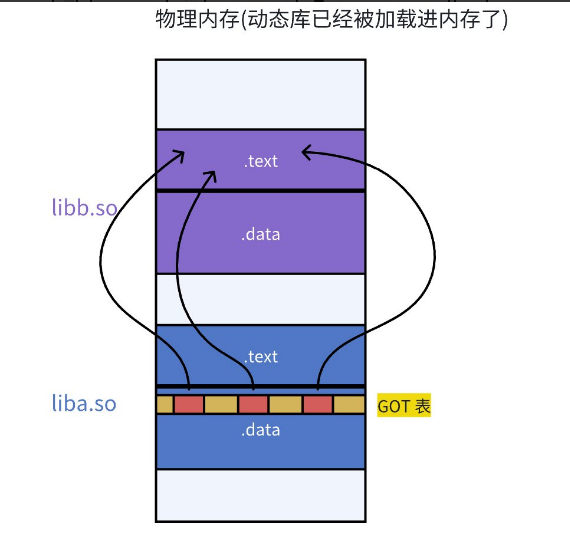
- 不仅仅有可执行程序调用库
- 库也会调用其他库!!库之间是有依赖的,如何做到库和库之间互相调用也是与地址无关的呢??
- 库中也有
.GOT(在数据段内!),和可执行程序一样!这也就是为什么大家为什么都是ELF的格式!
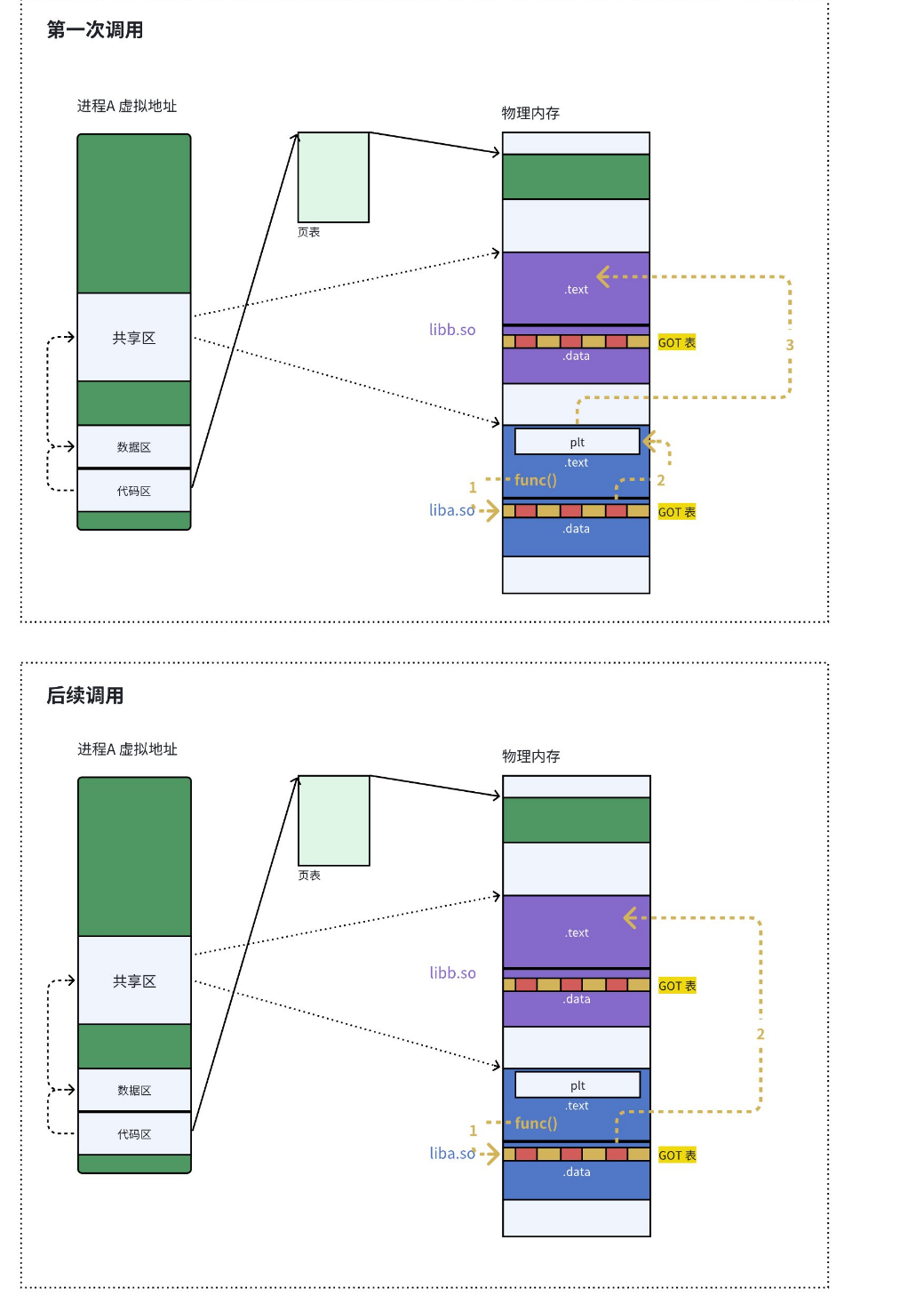
由于动态链接在程序加载(即运行)的时候需要对大量函数进行重定位(把假虚拟地址/占位符换成真虚拟地址) ,这一步显然是非常耗时的。为了进一步降低开销,我们的操作系统还做了一些其他的优化,比如延迟绑定 ,或者也叫PLT(过程连接表(Procedure Linkage Table))。与其在程序一开始就对所有函数进行重定位,不如将这个过程推迟到函数第一次被调用的时候,因为绝大多数动态库中的函数可能在程序运行期间一次都不会被使用到。
也就是如果没有这个机制 动态链接器(ld.so)就必须在程序刚开始加载的时候,把所有依赖的外部函数地址全部找出来,并提前填入 GOT 表中!(这个属于运行时加载过程)
思路是:
- 当你第一次调用 printf 函数时,程序会跳转到 PLT 中的一段"桩代码"(Stub)。这段代码发现 GOT 表里还没有 printf 的真实地址,于是它会立刻呼叫动态链接器。动态链接器赶紧去内存中找到 printf 的真实虚拟地址,并把它填入 GOT 表中。
- 当你第二次、第三次调用 printf 时,PLT 再次去查 GOT 表,发现里面已经有了现成的真实地址。于是程序直接根据这个地址跳转过去执行,完全跳过了查找的过程,速度和普通函数调用一样快。
一个库去调用另一个库的例子: