系统整体架构流程图
用户请求与三级缓存架构简易版
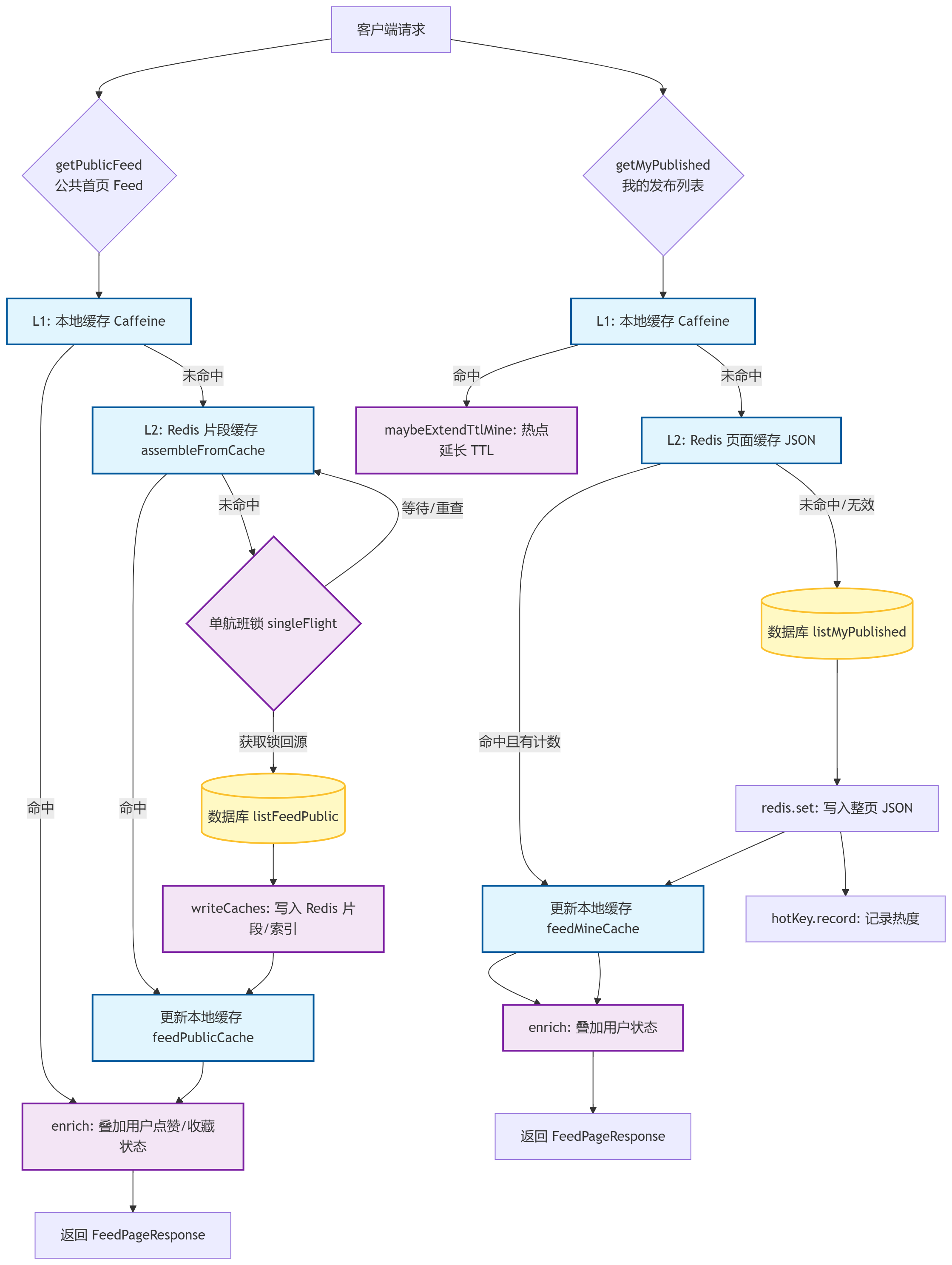
三级缓存架构

一、业务背景与核心痛点
针对首页公共Feed、我的文章双场景,Feed流系统存在典型高并发读写痛点:
-
峰值压力大:热点页面QPS极高,数据库频繁面临击穿、洪峰压力
-
延迟要求高:用户侧需要秒级响应,传统单级Redis缓存存在网络、序列化开销
-
数据一致性难平衡:高频更新、点赞收藏计数变更,无法做到强一致,需要秒级最终一致
-
个性化与公共缓存冲突:用户点赞、收藏等个人态会污染公共缓存,导致命中率暴跌
核心架构目标:极致降低读延迟、收敛后端DB压力、保障秒级最终一致、解耦页面装配与个性化逻辑。
二、核心架构思想
摒弃传统单级缓存粗暴方案,确立两大核心设计哲学,支撑整套三级缓存体系:
-
动静解耦、分层装配:页面骨架(静态结构)+ 条目碎片(动态内容)+ 用户个性化(实时覆盖)三层完全解耦
-
缓存分层、成本逐级递增:本地内存→Redis骨架→Redis碎片→DB,按访问成本、速度、命中率分层治理
-
缓存只读公共态,个性化上层叠加:彻底杜绝个性化数据污染公共缓存
-
事件失效+定时纠偏:实现高性能下的秒级最终一致
-
idsKey 存当前页面文章ID"1234567890", "1234567891", "1234567892", ..., "1234567909"
↑ ↑ ↑ ↑
第1篇文章ID 第2篇文章ID 第3篇文章ID 第20篇文章ID
三、三级缓存分层架构详解
按照「速度从快到慢、成本从低到高、数据粒度从粗到细」分层设计
1. L2 本地内存缓存(Caffeine)------ 热点极致加速层
-
公共页面缓存key:
javaprivate String cacheKey(int page, int size) { return "feed:public:" + size + ":" + page + ":v" + LAYOUT_VER; }LAYOUY_VER 缓存版本号:后续可以通过修改这个批量让缓存失效 -
存储内容:完整Feed页面响应(条目数组(这一页的具体数据)、分页、hasMore)
-
适用场景:公共Feed热点页、个人近期知文热页
-
核心优势:无网络IO、无需序列化,毫秒级返回,扛峰值QPS
-
策略:短TTL+热键动态续期,热点常驻缓存
java// 对返回列表中的每个条目进行热度统计--并试图延长TTL for (FeedItemResponse item : local.items()) { recordItemHotKey(item.id()); }同时维护一个hasMore键判断是不是还有下一页,这个键设置前端是否还显示下一页按钮
java
String hasMoreKey = "feed:public:ids:" + safeSize + ":" + hourSlot + ":" + safePage + ":hasMore";- 隔离能力:命中直接返回,不再穿透Redis与DB
2. L1Redis页面骨架缓存 ------ 页面装配调度层
-
存储内容:页面ID列表、hasMore分页元数据、轻量索引
-
核心定位:解决页面结构复用,稳定装配链路
-
设计价值:无需DB查询,仅通过ID索引拼装页面,规避重复排序、分页计算
-
TTL策略:短TTL+随机抖动,规避大面积同时失效
3. L0 Redis碎片缓存 ------ 数据最小粒度层
-
存储内容:单条目维度碎片(作者、封面、时间、置顶标记、点赞/收藏计数)
-
核心定位:可复用的最小数据单元,支持跨页面、跨场景复用
-
能力:批量读取、缺片按需回源补齐,提升装配成功率与命中率
-
TTL策略:三级最长,保证碎片高可用
四、完整读写链路流程(贴合源码)
1. 读链路:自上而下逐级命中
- 优先查询 L2 本地缓存,命中直接返回+个性化叠加,并尝试进行热度统计缓存时间延长
**本地缓存key:**String localPageKey = cacheKey(safePage, safeSize);
java
private String cacheKey(int page, int size) {
return "feed:public:" + size + ":" + page + ":v" + LAYOUT_VER;
}
java
FeedPageResponse local = feedPublicCache.getIfPresent(localPageKey);
if (local != null && local.items() != null) {
// 对返回列表中的每个条目进行热度统计--并试图延长TTL
for (FeedItemResponse item : local.items()) {
recordItemHotKey(item.id());
}
log.info("feed.public source=local localPageKey={} page={} size={}", localPageKey, safePage, safeSize);
List<FeedItemResponse> enrichedLocal = enrich(local.items(), currentUserIdNullable);
return new FeedPageResponse(enrichedLocal, local.page(), local.size(), local.hasMore());
}- L2未命中 → 查询 L1 页面骨架,拿到ID列表批量拉取 L0 碎片拼装页面
**文章ID列表缓存key:**里面存的是当前小时这个里面存的是当前小时sagePage页的safeSize个文章ID列表
java
long hourSlot = System.currentTimeMillis() / 3600000L;
String idsKey = "feed:public:ids:" + safeSize + ":" + hourSlot + ":" + safePage;**是否还有下一页key:**用来记录是否还有下一页,过期时间很短,记录前端是否显示下一页列表
java
String hasMoreKey = "feed:public:ids:" + safeSize + ":" + hourSlot + ":" + safePage + ":hasMore";批量获取元数据,将数据存到公共缓存中-----这里虽然存的是个性数据,但每次用都会调用方法覆盖为调用用户的个人数据,没有影响
java
// 构造内容元数据(标题,内容等)的 Redis Key
List<String> itemKeys = new ArrayList<>(idList.size());
for (String id : idList) {
itemKeys.add("feed:item:" + id);
}
// 批量获取知文 元数据
List<String> itemJsons = redis.opsForValue().multiGet(itemKeys);-
L1未命中 → 触发单航班机制,唯一请求回源DB
-
回源成功后自下而上回填 L0/L1/L2,形成闭环加速
2. 写回回填机制
-
DB回源后,优先写入L0碎片、再L1骨架、最后L2完整页面
-
分层独立TTL+抖动策略,平滑失效流量
3. 个性化叠加机制
-
公共缓存只存公共状态:不包含like/favor用户态
-
返回前内存实时叠加用户个性化状态,不写缓存
-
彻底解决缓存碎片化、命中率下降问题
java
synchronized (lock) {
// 重查 L2 缓存,避免重复回源
FeedPageResponse again = assembleFromCache(idsKey, hasMoreKey, safePage, safeSize, currentUserIdNullable);
if (again != null) {
feedPublicCache.put(localPageKey, again);
// 对返回列表中的每个条目进行热度统计
if (again.items() != null) {
for (FeedItemResponse item : again.items()) {
recordItemHotKey(item.id());
}
}
log.info("feed.public source=3tier(after-flight) localPageKey={} page={} size={}", localPageKey, safePage, safeSize);
singleFlight.remove(idsKey);
return again;
}
// 数据库回源:读取 size+1 以判断是否有下一页,后裁剪为当前页
int offset = (safePage - 1) * safeSize;
List<KnowPostFeedRow> rows = mapper.listFeedPublic(safeSize + 1, offset);
boolean hasMore = rows.size() > safeSize;
if (hasMore) {
rows = rows.subList(0, safeSize);
}
// 构建基础列表(计数已填充),liked/faved 置为 null 以免污染用户维度缓存
List<FeedItemResponse> items = mapRowsToItems(rows, null, false);
FeedPageResponse respForCache = new FeedPageResponse(items, safePage, safeSize, hasMore);
// 片段缓存(ids/item/count)TTL 更长并加入随机抖动,降低同一时刻大量过期
int baseTtl = 60;
//使用高并发线程安全工具,生成随机数0-29
int jitter = ThreadLocalRandom.current().nextInt(30);
Duration frTtl = Duration.ofSeconds(baseTtl + jitter);
// 写入片段缓存与本地缓存
writeCaches(localPageKey, idsKey, hasMoreKey, safeSize, rows, items, hasMore, frTtl);
feedPublicCache.put(localPageKey, respForCache);
// 返回时覆盖用户维度状态,不写回缓存
List<FeedItemResponse> enriched = enrich(items, currentUserIdNullable);
log.info("feed.public source=db localPageKey={} page={} size={} hasMore={}", localPageKey, safePage, safeSize, hasMore);
// 释放单航班锁,允许后续请求正常进入
singleFlight.remove(idsKey);
return new FeedPageResponse(enriched, safePage, safeSize, hasMore);
}五、高并发防护体系
1. Single-Flight 单航班机制 ------ 防缓存击穿
以页面骨架Key为航班锁,并发同一页面仅一次DB回源,其余请求等待缓存结果,彻底解决缓存失效瞬间的DB击穿、惊群效应。
举例来说:
1000 个用户同时请求第 1 页(缓存都未命中)
↓
999 个用户等待,1 个用户去查数据库
↓
数据库查询完成,写入缓存
↓
1000 个用户都获得相同的数据
锁的竞争过程:
时间线:
─────┬──────────────────────────────────────────
│
0ms│ 请求 1 获得锁,进入同步块
│ 请求 2-1000 在锁外等待(BLOCKED 状态)
│
│ ┌────────────────────────────────────┐
│ │ 请求 1 执行: │
│ │ 1. 重查 L2 缓存(未命中) │
│ │ 2. 查询数据库(耗时 50ms) │
│ │ 3. 写入 Redis 缓存 │
│ │ 4. 写入 Caffeine 缓存 │
│ │ 5. 调用 enrich() 叠加个性化状态 │
│ │ 6. 返回响应 │
│ │ 7. singleFlight.remove(idsKey) │
│ └────────────────────────────────────┘
│
55ms│ 请求 1 释放锁
│
56ms│ 请求 2 获得锁,进入同步块
│ ┌────────────────────────────────────┐
│ │ 请求 2 执行: │
│ │ 1. 重查 L2 缓存(✅ 命中!) │
│ │ 2. 写入 Caffeine 缓存 │
│ │ 3. 调用 enrich() 叠加个性化状态 │
│ │ 4. 返回响应(无需查数据库) │
│ │ 5. singleFlight.remove(idsKey) │
│ └────────────────────────────────────┘
│
57ms│ 请求 2 释放锁
│
58ms│ 请求 3 获得锁,进入同步块
│ ┌────────────────────────────────────┐
│ │ 请求 3 执行: │
│ │ 1. 重查 L2 缓存(✅ 命中!) │
│ │ 2. 直接返回(连 Caffeine 都不用写) │
│ └────────────────────────────────────┘
│
59ms│ 请求 3 释放锁
│
│ ... 请求 4-1000 依次快速返回
│
100ms│ 所有 1000 个请求都已完成 ✅
─────┴──────────────────────────────────────────
2. 双删失效策略 ------ 解决数据不一致
内容更新、置顶、可见性变更时,执行「立即删除+延迟二次删除」,杜绝并发回源旧值覆盖问题,保障秒级最终一致。
/**
* 为什么要先删除缓存:
* 时间线:
* T1: 线程 A 开始执行 confirmContent()
* T2: 线程 A 执行第一次 delete → 清除旧缓存 ✅(如果没有这个删除,B会把数据库中旧数据写到缓存,如果在高并发下,此时有多个读取了旧数据)
* T3: 线程 B 调用 getDetail() 查询同一条知文
* T4: 线程 B 发现缓存未命中 → 但此时数据库还未更新
* T5: 线程 B 等待...(或读取到旧数据,但不会写回缓存,因为 SingleFlight 机制)
* T6: 线程 A 执行 mapper.updateContent() → 数据库更新为【新数据】
* T7: 线程 A 执行第二次 delete → 清除可能在 T4-T6 期间产生的脏缓存 ✅
* T8: 线程 C 调用 getDetail() → 缓存未命中 → 从数据库读取【新数据】→ 写入缓存 ✅
* 防止并发污染:在数据库更新前清除旧缓存,避免并发请求在更新期间读取并回填旧数据
* 保证最终一致性:通过"更新前删除 + 更新后删除"的双删策略,确保缓存最终一定是最新数据
* 降低脏数据窗口期:将缓存不一致的时间窗口压缩到最小
*/3. 热键动态TTL扩缩容
基于滑动窗口热度探测,热点页面自动延长L2缓存TTL,让高频流量永久滞留在缓存层,极致削峰。
4. 小时分片Key设计
分页维度+时间分片组合Key,规避整点大面积缓存失效,平滑流量波动。
选择小时的原因:
合理的 Key 数量:一天 24 个时段,不会过多
自然的业务周期:用户行为通常以小时为单位变化
足够的时间分散:60-90 秒的 TTL 在一个小时内均匀分布
便于清理:过期的时段可以批量删除
5. 随机防抖设计
设计片段缓存和随机防抖缓存,防止高并发下大量缓存同时过期造成缓存雪崩
java
// 片段缓存(ids/item/count)TTL 更长并加入随机抖动,降低同一时刻大量过期
int baseTtl = 60;
//使用高并发线程安全工具,生成随机数0-29
int jitter = ThreadLocalRandom.current().nextInt(30);
Duration frTtl = Duration.ofSeconds(baseTtl + jitter);六、数据一致性方案:秒级最终一致
-
基础数据:内容变更事件驱动双删,实时失效
-
计数数据:增量事件入聚合桶 + 定时任务折叠纠偏
-
缺片兜底:碎片缺失时批量回源补齐,自动修复缓存脏数据/缺失数据
七、架构设计权衡与取舍
-
为什么不做单级缓存? 单级本地缓存成本高、单级Redis延迟高、单级碎片装配复杂度高,三级分层各司其职,兼顾延迟、成本、稳定性。
-
为什么个性化不进缓存? 避免缓存维度爆炸、命中率暴跌、雪崩风险抬升,实现公共缓存全局复用。
-
为什么用抖动TTL? 打散过期时间,杜绝缓存集中失效洪峰。
-
为什么采用事件+定时双保障? 兼顾实时失效与兜底纠偏,实现性能与一致性平衡。
八、最终落地效果
-
热点页面本地命中率极高,P99延迟大幅下降
-
绝大多数请求拦截在缓存层,DB QPS极致收敛
-
彻底解决峰值惊群、击穿、数据不一致问题
-
实现「热点本地返回、普通Redis拼装、极少落DB」的最优流量模型
九、总结与架构复用思想
整套三级缓存架构,通过分层存储、动静解耦、读写分离、个性后置、并发防护、最终一致纠偏,完美解决高并发Feed流的性能与一致性矛盾,可通用落地于所有信息流、列表页、推荐流等高读低改业务场景。