写在前面
Spark Core 是整个 Spark 生态的基石,提供了最基础与最核心的功能。理解 Spark Core,是掌握 Spark SQL、Spark Streaming、MLlib 等上层组件的前提。本文将系统讲解 RDD 编程模型、转换算子与行动算子、RDD 序列化、依赖关系、持久化机制,以及累加器和广播变量 等核心概念。
目录
- [一、Spark Core 概述](#一、Spark Core 概述)
- 二、RDD:弹性分布式数据集
- [三、RDD 创建方式](#三、RDD 创建方式)
- [四、RDD 转换算子(Transformation)](#四、RDD 转换算子(Transformation))
- [五、RDD 行动算子(Action)](#五、RDD 行动算子(Action))
- [六、RDD 序列化与闭包检查](#六、RDD 序列化与闭包检查)
- [七、RDD 依赖关系与 Stage 划分](#七、RDD 依赖关系与 Stage 划分)
- [八、RDD 持久化机制](#八、RDD 持久化机制)
- [九、RDD 分区器](#九、RDD 分区器)
- 十、累加器:分布式共享只写变量
- 十一、广播变量:分布式共享只读变量
- 十二、综合案例实战
- 十三、总结
一、Spark Core 概述
1.1 Spark Core 是什么?
Spark Core 是 Spark 框架最基础与最核心的功能模块,所有其他功能(Spark SQL、Spark Streaming、MLlib、GraphX)都是在 Spark Core 的基础上进行扩展的。

Spark Core 的核心职责:
| 功能 | 说明 |
|---|---|
| 任务调度 | 将用户程序分解为 Task,分发到集群执行 |
| 内存管理 | RDD 的缓存与持久化,内存与磁盘自动切换 |
| 错误恢复 | 基于 RDD 血缘(Lineage)的容错机制 |
| 存储系统 | 支持 HDFS、S3、Cassandra 等多种数据源 |
| 计算引擎 | 基于 DAG 的优化执行引擎 |
1.2 Spark Core 与 Hadoop MapReduce 对比
| 对比项 | Hadoop MapReduce | Spark Core |
|---|---|---|
| 计算模型 | Map → Reduce 固定流程 | DAG 灵活调度 |
| 中间结果存储 | 写入 HDFS(磁盘) | 内存缓存 + 磁盘 |
| 迭代计算 | 每次迭代都读写磁盘 | 内存迭代,速度提升 10~100 倍 |
| 容错机制 | 任务重算 | RDD 血缘(Lineage)重算 |
| 编程复杂度 | 需编写 Mapper 和 Reducer | 丰富的算子 API |
| 实时性 | 批处理-only | 批处理 + 流处理统一 |
1.3 Spark 运行架构回顾
在深入 RDD 之前,我们先回顾 Spark 的运行架构:
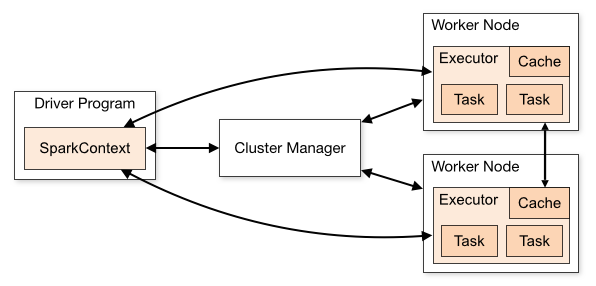
核心组件:
- Driver Program:运行 main 函数,创建 SparkContext,负责作业调度
- Cluster Manager:资源调度器(Standalone/YARN/Mesos/K8s)
- Worker Node:工作节点,运行 Executor 进程
- Executor:执行任务,存储数据,通过 Block Manager 管理缓存
二、RDD:弹性分布式数据集
2.1 什么是 RDD?
RDD(Resilient Distributed Dataset) 叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。
核心定义 :RDD 是一个抽象的、不可变的、可分区的、可并行计算的数据集合。它封装了计算逻辑,而不是数据本身。
RDD 的五大特性:
- 【弹性】存储弹性:内存与磁盘自动切换
- 【弹性】容错弹性:数据丢失可通过血缘自动恢复
- 【弹性】计算弹性:计算出错自动重试(默认4次)
- 【弹性】分片弹性:可根据需要重新分区
- 【分布式】数据分布在集群不同节点,支持并行计算
2.2 RDD 的弹性体现在哪里?
| 弹性维度 | 说明 |
|---|---|
| 存储弹性 | 内存不足时,自动将数据溢写到磁盘 |
| 容错弹性 | 分区数据丢失,根据血缘关系自动重算 |
| 计算弹性 | Task 失败自动重试,Stage 失败重新调度 |
| 分片弹性 | 通过 repartition、coalesce 动态调整分区数 |
2.3 RDD 的执行原理
RDD 在整个 Spark 执行流程中,主要承担封装计算逻辑的角色:
┌─────────────┐ ┌─────────────┐ ┌────────────┐ ┌─────────────────┐
│ Driver │ → │ DAG │ → │ TaskSet │→ │ Executor │
│ (RDD逻辑) │ │ Scheduler │ │ (任务) │ │ (执行任务+缓存) │
└─────────────┘ └─────────────┘ └────────────┘ └─────────────────┘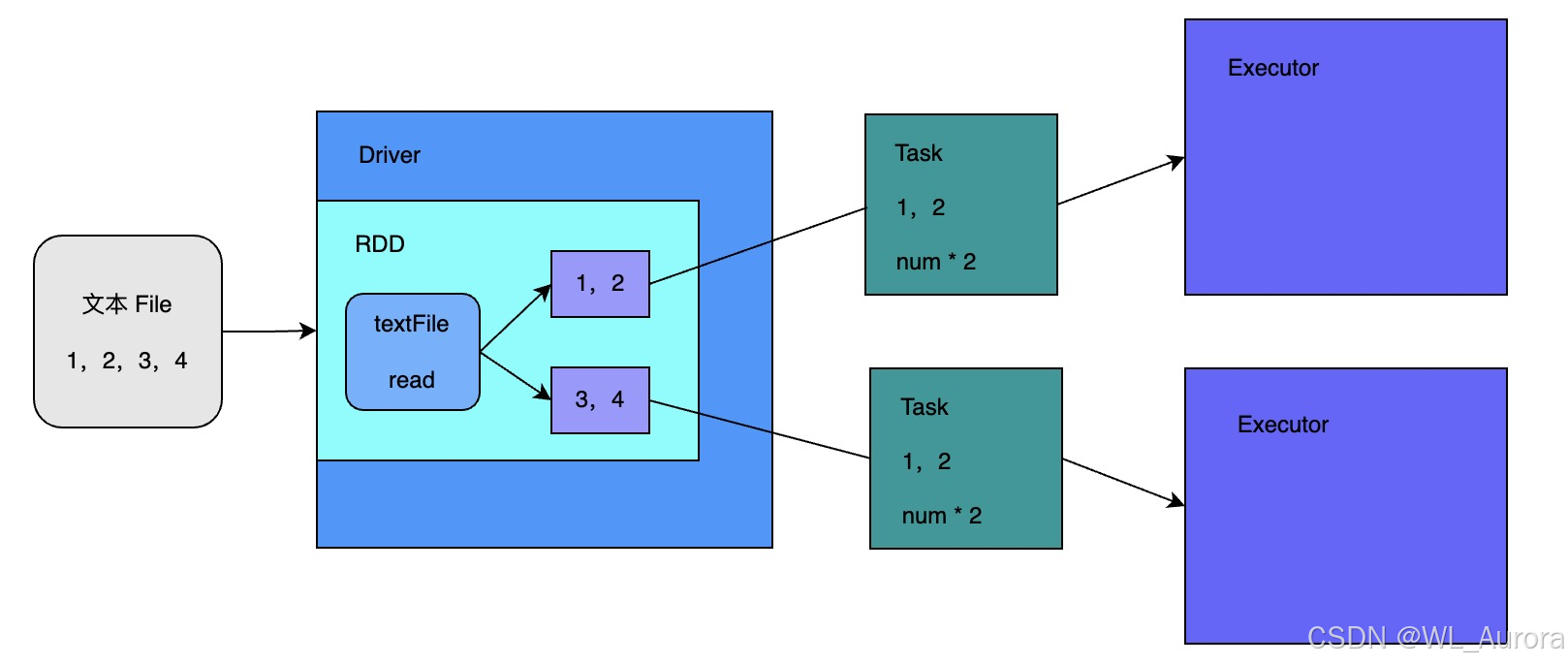
执行流程:
- Driver 将 RDD 计算逻辑封装为 Task
- DAG Scheduler 将 Task 划分为 Stage
- Task Scheduler 将 Task 分发到 Executor
- Executor 执行 Task,并将结果返回 Driver
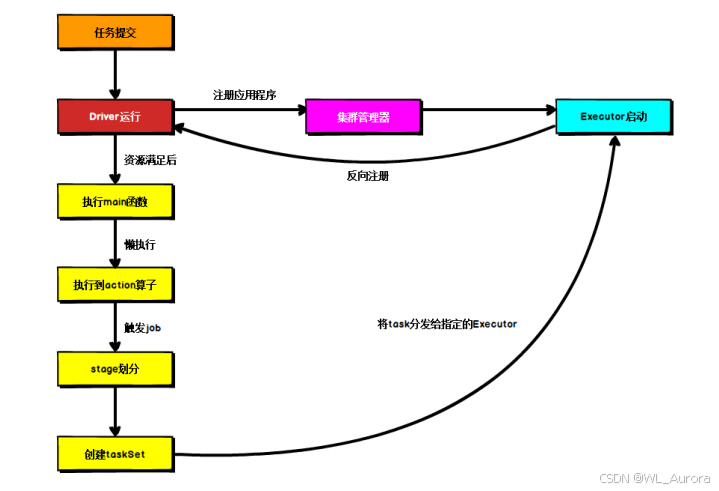
三、RDD 创建方式
Spark 中创建 RDD 有 四种方式:
3.1 从集合(内存)中创建 RDD
Spark 提供了两个方法:parallelize 和 makeRDD。
scala
import org.apache.spark.{SparkConf, SparkContext}
// 创建 SparkContext
val conf = new SparkConf().setMaster("local[*]").setAppName("RDDCreate")
val sc = new SparkContext(conf)
// 方式一:parallelize
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5))
// 方式二:makeRDD(底层就是调用 parallelize)
val rdd2 = sc.makeRDD(List(1, 2, 3, 4, 5))
// 指定分区数
val rdd3 = sc.makeRDD(List(1, 2, 3, 4, 5), 3)
rdd3.glom().collect().foreach(arr => println(arr.mkString(",")))
// 输出:
// 1,2
// 3,4
// 5makeRDD 源码解析:
scala
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices) // 底层就是调用 parallelize
}3.2 从外部存储(文件)创建 RDD
支持本地文件系统、HDFS、HBase、S3 等所有 Hadoop 支持的数据集。
scala
// 读取本地文件
val fileRDD: RDD[String] = sc.textFile("input/word.txt")
// 读取 HDFS 文件
val hdfsRDD: RDD[String] = sc.textFile("hdfs://namenode:8020/data/input.txt")
// 读取整个目录
val dirRDD: RDD[String] = sc.textFile("input/")
// 读取时指定最小分区数
val rdd = sc.textFile("input/word.txt", 2)文件读取的分区规则:
Spark 读取文件时,按照 Hadoop 的切片规则进行分区。默认情况下,每个 HDFS Block(128MB)对应一个分区。
scala
// 核心源码逻辑:
// splitSize = max(minSize, min(goalSize, blockSize))
// 其中:goalSize = totalSize / numSplits3.3 从其他 RDD 创建
通过已有的 RDD 进行转换操作,生成新的 RDD。这是 Spark 中最常见的 RDD 创建方式。
scala
val rdd1 = sc.makeRDD(List(1, 2, 3, 4, 5))
// 通过 map 转换创建新 RDD
val rdd2 = rdd1.map(_ * 2)
// 通过 filter 转换创建新 RDD
val rdd3 = rdd1.filter(_ > 2)3.4 直接创建 RDD(new)
使用 new 的方式直接构造 RDD,一般由 Spark 框架自身使用,用户开发中很少直接使用。
scala
// 用户开发中不推荐直接使用
// val rdd = new MyRDD(sc, ...)四、RDD 转换算子(Transformation)
转换算子 是 RDD 的核心操作,特点是懒执行------不会立即触发计算,只是记录计算逻辑,等到 Action 算子触发时才真正执行。
4.1 Value 类型算子
1) map:映射转换
scala
// 函数签名
def map[U: ClassTag](f: T => U): RDD[U]
// 功能:将数据逐条进行映射转换
val rdd = sc.makeRDD(List(1, 2, 3, 4))
val mapRDD = rdd.map(_ * 2) // 每个元素乘以2
mapRDD.collect().foreach(println) // 2, 4, 6, 8
// 类型转换
val strRDD = rdd.map(num => "" + num) // Int -> Stringmap vs mapPartitions 对比:
| 特性 | map | mapPartitions |
|---|---|---|
| 处理粒度 | 逐条处理 | 按分区批量处理 |
| 性能 | 较低(频繁函数调用) | 较高(批量处理) |
| 内存占用 | 低 | 高(需缓存整个分区数据) |
| 适用场景 | 简单转换 | 需要连接外部资源(如数据库) |
2) mapPartitions:分区批量处理
scala
// 函数签名
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U]
// 功能:以分区为单位进行批处理
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 2)
val mpRDD = rdd.mapPartitions(iter => {
// 获取每个分区的最大值
List(iter.max).iterator
})
mpRDD.collect().foreach(println) // 输出每个分区的最大值3) flatMap:扁平映射
scala
// 函数签名
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U]
// 功能:将数据扁平化后再映射
val rdd = sc.makeRDD(List(
List(1, 2), List(3, 4), List(5, 6)
), 1)
val flatRDD = rdd.flatMap(list => list)
flatRDD.collect().foreach(println) // 1, 2, 3, 4, 5, 6
// 经典应用:WordCount 分词
val lines = sc.makeRDD(List("hello world", "hello spark"))
val words = lines.flatMap(_.split(" "))4) glom:分区数据数组化
scala
// 函数签名
def glom(): RDD[Array[T]]
// 功能:将同一个分区的数据转换为数组
val rdd = sc.makeRDD(List(1, 2, 3, 4), 2)
val glomRDD = rdd.glom()
glomRDD.collect().foreach(arr => println(arr.mkString(",")))
// 输出:
// 1,2
// 3,4
// 应用:计算所有分区最大值之和
val maxSum = rdd.glom().map(_.max).reduce(_ + _)5) groupBy:分组
scala
// 函数签名
def groupBy[K](f: T => K)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])]
// 功能:按指定规则分组,会触发 Shuffle
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 2)
val groupRDD = rdd.groupBy(_ % 2)
groupRDD.collect().foreach(println)
// 输出:
// (0,CompactBuffer(2, 4, 6))
// (1,CompactBuffer(1, 3, 5))⚠️ 注意 :groupBy 会触发 Shuffle 操作,数据会被打乱重新组合,极端情况下可能导致数据倾斜。
6) filter:过滤
scala
// 函数签名
def filter(f: T => Boolean): RDD[T]
// 功能:按条件筛选数据
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6))
val filterRDD = rdd.filter(_ % 2 == 0)
filterRDD.collect().foreach(println) // 2, 4, 6
// ⚠️ 注意:过滤后分区不变,但分区内数据可能不均衡,可能导致数据倾斜7) sample:抽样
scala
// 函数签名
def sample(
withReplacement: Boolean,
fraction: Double,
seed: Long = Utils.random.nextLong): RDD[T]
// 功能:从数据集中抽样
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10))
// 不放回抽样(伯努利算法)
val sample1 = rdd.sample(false, 0.5)
// 放回抽样(泊松算法)
val sample2 = rdd.sample(true, 2.0)参数说明:
| 参数 | 说明 |
|---|---|
withReplacement |
false:不放回;true:放回 |
fraction |
抽样比例/重复次数 |
seed |
随机种子,保证可重复性 |
8) distinct:去重
scala
// 函数签名
def distinct()(implicit ord: Ordering[T] = null): RDD[T]
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
// 功能:去重
val rdd = sc.makeRDD(List(1, 2, 3, 4, 1, 2, 3, 5))
val distinctRDD = rdd.distinct()
distinctRDD.collect().foreach(println) // 1, 2, 3, 4, 5
// 指定去重后的分区数
val distinctRDD2 = rdd.distinct(2)9) coalesce / repartition:重分区
scala
// 函数签名
def coalesce(numPartitions: Int, shuffle: Boolean = false, ...): RDD[T]
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
// 功能:缩减或扩大分区
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 6)
// coalesce:缩减分区,默认不 Shuffle(数据不打乱)
val coalesceRDD = rdd.coalesce(2)
// repartition:扩大或缩减分区,一定会 Shuffle
val repartitionRDD = rdd.repartition(10)coalesce vs repartition 对比:
| 特性 | coalesce | repartition |
|---|---|---|
| Shuffle | 默认 false(可选 true) | 一定 true |
| 扩大分区 | 不支持(必须 Shuffle) | 支持 |
| 缩减分区 | 支持(高效) | 支持 |
| 使用场景 | 大数据集过滤后缩减分区 | 需要均衡分区数据 |
10) sortBy:排序
scala
// 函数签名
def sortBy[K](
f: (T) => K,
ascending: Boolean = true,
numPartitions: Int = this.partitions.length)
(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]
// 功能:按指定规则排序
val rdd = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3), ("a", 4)))
// 按 Key 降序排序
val sortRDD = rdd.sortBy(_._1, ascending = false)
sortRDD.collect().foreach(println)4.2 双 Value 类型算子
11) intersection:交集
scala
// 函数签名
def intersection(other: RDD[T]): RDD[T]
// 功能:求两个 RDD 的交集
val rdd1 = sc.makeRDD(List(1, 2, 3, 4))
val rdd2 = sc.makeRDD(List(3, 4, 5, 6))
val intersectionRDD = rdd1.intersection(rdd2)
intersectionRDD.collect().foreach(println) // 3, 412) union:并集
scala
// 函数签名
def union(other: RDD[T]): RDD[T]
// 功能:求并集(不去重)
val unionRDD = rdd1.union(rdd2)
unionRDD.collect().foreach(println) // 1, 2, 3, 4, 3, 4, 5, 613) subtract:差集
scala
// 函数签名
def subtract(other: RDD[T]): RDD[T]
// 功能:以第一个 RDD 为主,去除共同元素
val subtractRDD = rdd1.subtract(rdd2)
subtractRDD.collect().foreach(println) // 1, 214) zip:拉链
scala
// 函数签名
def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)]
// 功能:将两个 RDD 的元素组合为元组
val rdd1 = sc.makeRDD(List(1, 2, 3))
val rdd2 = sc.makeRDD(List("a", "b", "c"))
val zipRDD = rdd1.zip(rdd2)
zipRDD.collect().foreach(println)
// 输出:(1,a), (2,b), (3,c)⚠️ zip 使用前提:
- 两个 RDD 的数据类型可以不同
- 两个 RDD 的分区数必须相同
- 两个 RDD 每个分区的元素数量必须相同
4.3 Key-Value 类型算子
15) partitionBy:按 Key 重分区
scala
// 函数签名
def partitionBy(partitioner: Partitioner): RDD[(K, V)]
// 功能:按指定分区器重新分区
import org.apache.spark.HashPartitioner
val rdd = sc.makeRDD(Array((1, "aaa"), (2, "bbb"), (3, "ccc"), (4, "ddd")), 3)
// 使用 HashPartitioner 分为 2 个分区
val partitionRDD = rdd.partitionBy(new HashPartitioner(2))
partitionRDD.glom().collect().foreach(arr => println(arr.mkString(",")))16) reduceByKey:按 Key 聚合
scala
// 函数签名
def reduceByKey(func: (V, V) => V): RDD[(K, V)]
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]
// 功能:将相同 Key 的 Value 聚合
val rdd = sc.makeRDD(List(("a", 1), ("b", 2), ("a", 3), ("b", 4)))
val reduceRDD = rdd.reduceByKey(_ + _)
reduceRDD.collect().foreach(println)
// 输出:(a,4), (b,6)reduceByKey vs groupByKey 对比:
| 特性 | reduceByKey | groupByKey |
|---|---|---|
| Shuffle 前预聚合 | ✅ 有(分区内先聚合) | ❌ 无(直接分组) |
| Shuffle 数据量 | 少 | 多 |
| 功能 | 分组 + 聚合 | 仅分组 |
| 性能 | 高 | 低 |
| 适用场景 | 需要聚合时 | 仅需分组时 |
17) groupByKey:按 Key 分组
scala
// 函数签名
def groupByKey(): RDD[(K, Iterable[V])]
// 功能:将相同 Key 的 Value 分组
val groupRDD = rdd.groupByKey()
groupRDD.collect().foreach(println)
// 输出:(a,CompactBuffer(1, 3)), (b,CompactBuffer(2, 4))18) aggregateByKey:分区内/间不同规则聚合
scala
// 函数签名
def aggregateByKey[U: ClassTag](zeroValue: U)
(seqOp: (U, V) => U, combOp: (U, U) => U): RDD[(K, U)]
// 功能:分区内和分区间可以使用不同的计算规则
val rdd = sc.makeRDD(List(
("a", 1), ("a", 2), ("c", 3),
("b", 4), ("c", 5), ("c", 6)
), 2)
// 需求:取出每个分区内相同 key 的最大值,然后分区间相加
val aggRDD = rdd.aggregateByKey(10)(
(x, y) => math.max(x, y), // 分区内:取最大值(初始值10参与比较)
(x, y) => x + y // 分区间:相加
)
aggRDD.collect().foreach(println)
// 输出:(a,20), (b,10), (c,20)aggregateByKey 参数解析:
| 参数 | 说明 |
|---|---|
zeroValue |
初始值,分区内计算的第一个参数 |
seqOp |
分区内计算规则 (初始值, Value) => 结果 |
combOp |
分区间计算规则 (结果1, 结果2) => 最终结果 |
19) foldByKey:简化版 aggregateByKey
scala
// 函数签名
def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]
// 功能:当分区内和分区间计算规则相同时,简化写法
val rdd = sc.makeRDD(List(("a", 1), ("a", 2), ("b", 3)))
// 等同于 aggregateByKey,但规则相同
val foldRDD = rdd.foldByKey(0)(_ + _)20) combineByKey:最通用的聚合算子
scala
// 函数签名
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C): RDD[(K, C)]
// 功能:最通用的 key-value 聚合函数,允许返回值类型与输入不同
val list = List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98))
val rdd = sc.makeRDD(list, 2)
// 需求:求每个 key 的平均值
val combineRDD = rdd.combineByKey(
(_, 1), // createCombiner:第一个值转换为 (value, 1)
(acc: (Int, Int), v) => (acc._1 + v, acc._2 + 1), // mergeValue:累加值和计数
(acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2) // mergeCombiners
)
// 计算平均值
val avgRDD = combineRDD.map { case (key, (sum, count)) => (key, sum / count) }
avgRDD.collect().foreach(println)
// 输出:(a,91), (b,95)四大聚合算子对比:
| 算子 | 初始值处理 | 分区内规则 | 分区间规则 | 返回值类型 |
|---|---|---|---|---|
reduceByKey |
第一个 Value | 相同 | 相同 | 同输入 |
foldByKey |
与初始值计算 | 相同 | 相同 | 同输入 |
aggregateByKey |
与初始值计算 | 可不同 | 可不同 | 可不同 |
combineByKey |
自定义转换 | 可不同 | 可不同 | 可不同 |
21) sortByKey:按 Key 排序
scala
// 函数签名
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length): RDD[(K, V)]
// 功能:按 Key 排序(Key 必须实现 Ordered 接口)
val rdd = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)))
val sortRDD = rdd.sortByKey(ascending = false)
sortRDD.collect().foreach(println)
// 输出:(c,3), (b,2), (a,1)22) join:内连接
scala
// 函数签名
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
// 功能:两个 RDD 按 Key 内连接
val rdd1 = sc.makeRDD(Array((1, "a"), (2, "b"), (3, "c")))
val rdd2 = sc.makeRDD(Array((1, 4), (2, 5), (3, 6)))
val joinRDD = rdd1.join(rdd2)
joinRDD.collect().foreach(println)
// 输出:(1,(a,4)), (2,(b,5)), (3,(c,6))23) leftOuterJoin / rightOuterJoin:外连接
scala
// 左外连接
val leftJoinRDD = rdd1.leftOuterJoin(rdd2)
// 输出:(1,(a,Some(4))), (2,(b,Some(5))), (3,(c,Some(6)))
// 右外连接
val rightJoinRDD = rdd1.rightOuterJoin(rdd2)24) cogroup:分组连接
scala
// 函数签名
def cogroup[W](other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))]
// 功能:将两个 RDD 中相同 Key 的数据分组到一起
val rdd1 = sc.makeRDD(List(("a", 1), ("a", 2), ("c", 3)))
val rdd2 = sc.makeRDD(List(("a", 4), ("b", 5), ("c", 6)))
val cogroupRDD = rdd1.cogroup(rdd2)
cogroupRDD.collect().foreach(println)
// 输出:
// (a,(CompactBuffer(1, 2),CompactBuffer(4)))
// (b,(CompactBuffer(),CompactBuffer(5)))
// (c,(CompactBuffer(3),CompactBuffer(6)))五、RDD 行动算子(Action)
行动算子会触发真正的计算,将结果返回 Driver 或写入外部存储。
5.1 基础行动算子
1) reduce:聚合
scala
// 函数签名
def reduce(f: (T, T) => T): T
// 功能:聚合 RDD 所有元素
val rdd = sc.makeRDD(List(1, 2, 3, 4))
val sum = rdd.reduce(_ + _)
println(sum) // 102) collect:收集到 Driver
scala
// 函数签名
def collect(): Array[T]
// 功能:将所有数据收集到 Driver 端(⚠️ 数据量大时慎用)
val rdd = sc.makeRDD(List(1, 2, 3, 4))
val array = rdd.collect()
array.foreach(println)3) count / first / take / takeOrdered
scala
val rdd = sc.makeRDD(List(3, 1, 4, 2, 5))
// 返回元素个数
println(rdd.count()) // 5
// 返回第一个元素
println(rdd.first()) // 3
// 返回前 n 个元素
rdd.take(3).foreach(println) // 3, 1, 4
// 返回排序后的前 n 个元素
rdd.takeOrdered(3).foreach(println) // 1, 2, 34) aggregate / fold
scala
// aggregate:分区内和分区间规则可不同
val rdd = sc.makeRDD(List(1, 2, 3, 4), 2)
val result = rdd.aggregate(10)(_ + _, _ + _)
// 分区内:(10+1+2)=13, (10+3+4)=17
// 分区间:10+13+17=40
println(result) // 40
// fold:aggregate 的简化版,规则相同
val foldResult = rdd.fold(10)(_ + _)5) countByKey:按 Key 计数
scala
// 函数签名
def countByKey(): Map[K, Long]
// 功能:统计每种 Key 的个数
val rdd = sc.makeRDD(List(("a", 1), ("a", 2), ("b", 3), ("c", 4), ("c", 5)))
val countMap = rdd.countByKey()
countMap.foreach(println)
// 输出:a -> 2, b -> 1, c -> 26) save 相关算子
scala
// 保存为 Text 文件
rdd.saveAsTextFile("output")
// 保存为 SequenceFile(Key-Value 格式)
rdd.saveAsSequenceFile("output_seq")
// 保存为对象文件(Java 序列化)
rdd.saveAsObjectFile("output_obj")7) foreach:分布式遍历
scala
// 函数签名
def foreach(f: T => Unit): Unit
// 功能:分布式遍历每个元素(在 Executor 端执行)
val rdd = sc.makeRDD(List(1, 2, 3, 4))
// ⚠️ 这是分布式打印,顺序不固定,可能在不同节点输出
rdd.foreach(println)
// 如果需要有序输出,先 collect 再 foreach(但数据量大时慎用)
rdd.collect().foreach(println)foreach vs foreachPartition 对比:
| 特性 | foreach | foreachPartition |
|---|---|---|
| 处理粒度 | 逐条 | 按分区 |
| 性能 | 低 | 高(适合批量操作) |
| 使用场景 | 简单操作 | 需要连接外部资源(如数据库) |
六、RDD 序列化与闭包检查
6.1 闭包检查原理
在 Spark 中,算子以外的代码在 Driver 端执行,算子内的代码在 Executor 端执行 。当算子内使用了算子外的变量时,就形成了闭包。Spark 会在任务计算前检测闭包内的对象是否可以序列化。
scala
object SerializableDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("SerialDemo").setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(Array("hello world", "hello spark", "hive", "atguigu"))
// 创建 Search 对象
val search = new Search("hello")
// ❌ 错误:Task not serializable(Search 类未序列化)
// search.getMatch1(rdd).collect().foreach(println)
// ✅ 正确:Search 继承 Serializable
search.getMatch2(rdd).collect().foreach(println)
sc.stop()
}
}
// ❌ 未序列化
class Search1(query: String) {
def isMatch(s: String): Boolean = s.contains(query)
def getMatch1(rdd: RDD[String]): RDD[String] = rdd.filter(isMatch)
}
// ✅ 已序列化
class Search2(query: String) extends Serializable {
def isMatch(s: String): Boolean = s.contains(query)
def getMatch2(rdd: RDD[String]): RDD[String] = rdd.filter(isMatch)
}6.2 Kryo 序列化框架
Java 的序列化虽然通用,但比较重(字节多)。Spark 2.0+ 支持 Kryo 序列化,速度是 Java 序列化的 10 倍。
scala
val conf = new SparkConf()
.setAppName("KryoDemo")
.setMaster("local[*]")
// 替换默认序列化机制
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 注册需要 Kryo 序列化的自定义类
.registerKryoClasses(Array(classOf[Searcher]))
val sc = new SparkContext(conf)
// 使用 Kryo 序列化的自定义类
case class Searcher(val query: String) {
def isMatch(s: String) = s.contains(query)
}
val rdd = sc.makeRDD(Array("hello world", "hello atguigu", "atguigu", "hahah"), 2)
val searcher = new Searcher("hello")
val result = rdd.filter(searcher.isMatch)
result.collect().foreach(println)⚠️ 注意 :即使使用 Kryo,自定义类也必须继承 Serializable 接口。
七、RDD 依赖关系与 Stage 划分
7.1 RDD 血缘关系(Lineage)
RDD 只支持粗粒度转换,会记录一系列 Lineage(血统),以便恢复丢失的分区。
scala
val fileRDD = sc.textFile("input/1.txt")
println(fileRDD.toDebugString)
// 输出:
// (2) input/1.txt MapPartitionsRDD[1] at textFile at ...
// | input/1.txt HadoopRDD[0] at textFile at ...
val wordRDD = fileRDD.flatMap(_.split(" "))
println(wordRDD.toDebugString)
val mapRDD = wordRDD.map((_, 1))
println(mapRDD.toDebugString)
val resultRDD = mapRDD.reduceByKey(_ + _)
println(resultRDD.toDebugString)7.2 窄依赖 vs 宽依赖
| 依赖类型 | 定义 | 图示 | 是否 Shuffle |
|---|---|---|---|
| 窄依赖 | 父 RDD 的每个 Partition 最多被子 RDD 的一个 Partition 使用 | 独生子女 | ❌ 否 |
| 宽依赖 | 父 RDD 的每个 Partition 被子 RDD 的多个 Partition 使用 | 多生 | ✅ 是 |
窄依赖算子: map、filter、union、join(已哈希分区)
宽依赖算子: groupByKey、reduceByKey、sortByKey、join(未分区)
7.3 Stage 划分原理
DAG Scheduler 根据宽依赖(Shuffle)将 Job 划分为多个 Stage:
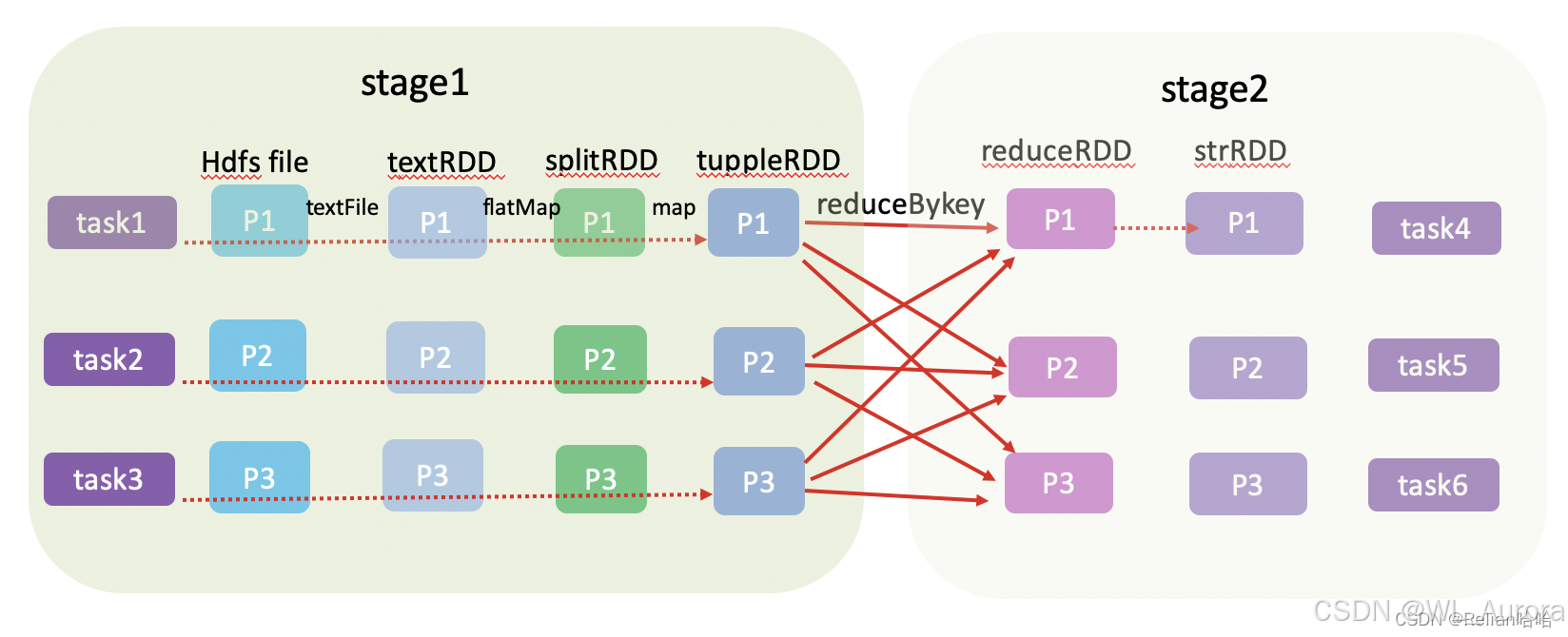
Stage = 宽依赖个数 + 1
7.4 Task 划分
| 层级 | 定义 | 关系 |
|---|---|---|
| Application | 一个 SparkContext 对应一个应用 | 1 |
| Job | 一个 Action 算子生成一个 Job | 1 → n |
| Stage | 根据宽依赖划分 | 1 → n |
| Task | Stage 中最后一个 RDD 的分区数 | 1 → n |
注意 :Application → Job → Stage → Task 每一层都是 1 对 n 的关系。
八、RDD 持久化机制
8.1 Cache / Persist 缓存
RDD 通过 cache() 或 persist() 将计算结果缓存,默认缓存在 JVM 堆内存中。
scala
val rdd = sc.makeRDD(List("hello", "spark", "hello", "world"))
// 缓存 RDD(默认 MEMORY_ONLY)
val wordRDD = rdd.flatMap(_.split(" "))
wordRDD.cache()
// 触发缓存(Action 算子触发)
wordRDD.count()
// 再次使用,直接从缓存读取
wordRDD.collect().foreach(println)存储级别:
| 级别 | 使用磁盘 | 使用内存 | 使用堆外内存 | 不序列化 | 副本数 |
|---|---|---|---|---|---|
NONE |
❌ | ❌ | ❌ | - | - |
MEMORY_ONLY |
❌ | ✅ | ❌ | ✅ | 1 |
MEMORY_ONLY_SER |
❌ | ✅ | ❌ | ❌ | 1 |
MEMORY_AND_DISK |
✅ | ✅ | ❌ | ✅ | 1 |
MEMORY_AND_DISK_SER |
✅ | ✅ | ❌ | ❌ | 1 |
DISK_ONLY |
✅ | ❌ | ❌ | ❌ | 1 |
OFF_HEAP |
❌ | ❌ | ✅ | ❌ | 1 |
scala
// 指定存储级别
import org.apache.spark.storage.StorageLevel
wordRDD.persist(StorageLevel.MEMORY_AND_DISK_SER_2)
// MEMORY_AND_DISK_SER_2:内存+磁盘,序列化,2个副本缓存容错机制:
缓存有可能丢失(内存不足被清理),RDD 的血缘关系保证了即使缓存丢失也能重算恢复,只需计算丢失的部分,无需重算全部。
8.2 Checkpoint 检查点
检查点通过将 RDD 中间结果写入磁盘(通常是 HDFS),切断血缘依赖,减少容错成本。
scala
// 设置检查点目录
sc.setCheckpointDir("hdfs://localhost:8020/checkpoint")
// 创建 RDD
val lineRDD = sc.textFile("input/1.txt")
val wordRDD = lineRDD.flatMap(_.split(" "))
val wordToOneRDD = wordRDD.map(word => (word, 1))
// 先缓存,避免 checkpoint 时重新计算
wordToOneRDD.cache()
// 设置检查点
wordToOneRDD.checkpoint()
// 触发执行
wordToOneRDD.count()Cache vs Checkpoint 对比:
| 特性 | Cache | Checkpoint |
|---|---|---|
| 血缘关系 | 不切断 | 切断 |
| 存储位置 | 内存/磁盘(本地) | HDFS(高可靠) |
| 可靠性 | 低(可能丢失) | 高(HDFS 多副本) |
| 性能 | 快 | 慢(需写 HDFS) |
| 建议 | 重复使用但可靠性要求不高 | 血缘过长、可靠性要求高 |
最佳实践 :对需要 checkpoint 的 RDD 先 cache(),这样 checkpoint 时只需从缓存读取,避免重新计算。
九、RDD 分区器
9.1 HashPartitioner(默认)
scala
class HashPartitioner(partitions: Int) extends Partitioner {
def numPartitions: Int = partitions
def getPartition(key: Any): Int = key match {
case null => 0
case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)
}
}原理:对 Key 计算 hashCode,取模分区数得到分区 ID。
9.2 RangePartitioner
scala
class RangePartitioner[K : Ordering : ClassTag, V](
partitions: Int,
rdd: RDD[_ <: Product2[K, V]],
private var ascending: Boolean = true)
extends Partitioner原理 :将数据按 Key 排序后,尽量均衡地划分到各个分区。适用于排序场景(如 sortByKey)。
9.3 自定义分区器
scala
import org.apache.spark.Partitioner
// 自定义分区器:按域名分区
class DomainPartitioner extends Partitioner {
override def numPartitions: Int = 3
override def getPartition(key: Any): Int = {
val domain = key.toString
if (domain.endsWith(".com")) 0
else if (domain.endsWith(".org")) 1
else 2
}
}
// 使用自定义分区器
val rdd = sc.makeRDD(Array(("a.com", 1), ("b.org", 2), ("c.net", 3)))
val partitionedRDD = rdd.partitionBy(new DomainPartitioner())十、累加器:分布式共享只写变量
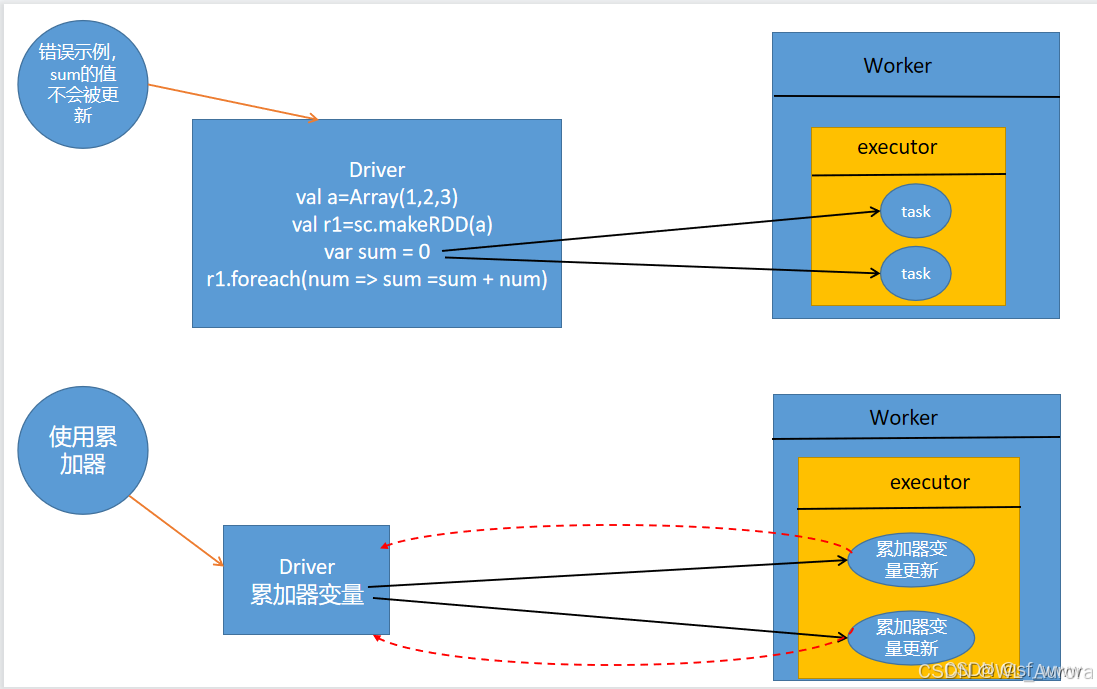
10.1 累加器原理
累加器用来把 Executor 端变量信息聚合到 Driver 端。在 Driver 定义的变量,Executor 每个 Task 都会得到一份副本,更新后传回 Driver 合并。
10.2 系统累加器
scala
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5))
// 声明累加器
val sum = sc.longAccumulator("sum")
// 在 Executor 端使用累加器
rdd.foreach(num => sum.add(num))
// 在 Driver 端获取累加器的值
println("sum = " + sum.value) // sum = 15⚠️ 注意 :累加器在 Action 算子 中才能正确累加,在 Transformation 中可能因 Task 重试导致重复计算。
10.3 自定义累加器
实现 WordCount 累加器:
scala
import org.apache.spark.util.AccumulatorV2
import scala.collection.mutable
class WordCountAccumulator extends AccumulatorV2[String, mutable.Map[String, Long]] {
var map: mutable.Map[String, Long] = mutable.Map()
// 累加器是否为初始状态
override def isZero: Boolean = map.isEmpty
// 复制累加器
override def copy(): AccumulatorV2[String, mutable.Map[String, Long]] = {
val newAcc = new WordCountAccumulator
newAcc.map = this.map.clone()
newAcc
}
// 重置累加器
override def reset(): Unit = map.clear()
// 向累加器增加数据
override def add(word: String): Unit = {
map(word) = map.getOrElse(word, 0L) + 1L
}
// 合并累加器
override def merge(other: AccumulatorV2[String, mutable.Map[String, Long]]): Unit = {
val map2 = other.value
map2.foreach { case (word, count) =>
map(word) = map.getOrElse(word, 0L) + count
}
}
// 返回累加器结果
override def value: mutable.Map[String, Long] = map
}
// 使用自定义累加器
val acc = new WordCountAccumulator
sc.register(acc, "wordCount")
val rdd = sc.makeRDD(List("hello", "spark", "hello", "world", "spark"))
rdd.foreach(word => acc.add(word))
acc.value.foreach(println)
// 输出:hello -> 2, spark -> 2, world -> 1十一、广播变量:分布式共享只读变量
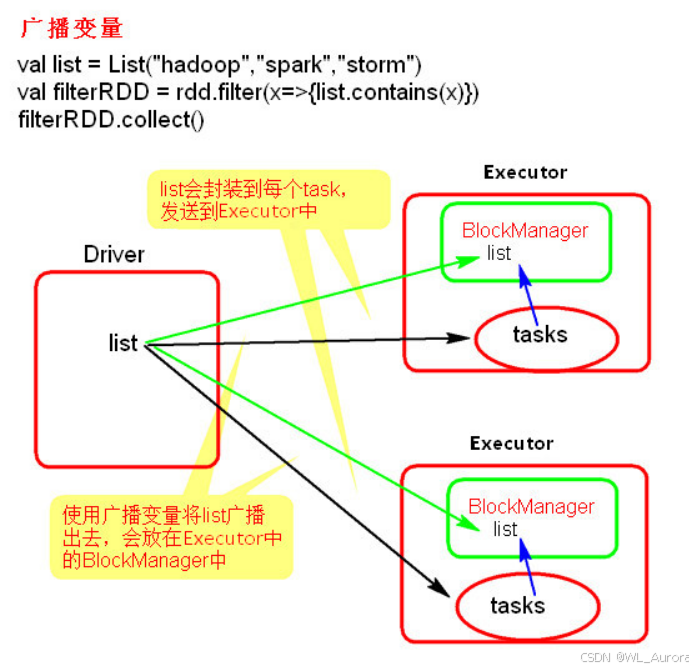
11.1 广播变量原理
广播变量用来高效分发较大的只读对象到所有工作节点。避免为每个 Task 单独发送相同的数据。
11.2 广播变量使用
scala
val rdd1 = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3), ("d", 4)), 4)
// 需要关联的数据
val list = List(("a", 4), ("b", 5), ("c", 6), ("d", 7))
// 声明广播变量
val broadcast = sc.broadcast(list)
// 使用广播变量进行关联
val resultRDD = rdd1.map { case (key, num1) =>
var num2 = 0
// 从广播变量中查找匹配数据
for ((k, v) <- broadcast.value) {
if (k == key) num2 = v
}
(key, (num1, num2))
}
resultRDD.collect().foreach(println)
// 输出:(a,(1,4)), (b,(2,5)), (c,(3,6)), (d,(4,7))使用场景:
- 大表 Join 小表时,广播小表
- 分发配置信息、字典数据
- 机器学习中的模型参数分发
十二、综合案例实战
12.1 案例:Top10 热门品类统计
需求:统计电商网站中每个品类的点击数、下单数、支付数,取 Top10。
数据格式:
日期_用户ID_SessionID_页面ID_动作时间_搜索关键词_点击品类ID_点击产品ID_下单品类IDs_下单产品IDs_支付品类IDs_支付产品IDs_城市ID实现方案一:分别统计再聚合
scala
// 1. 读取数据
val actionRDD = sc.textFile("data/user_visit_action.txt")
// 2. 分别统计点击、下单、支付
val clickRDD = actionRDD.filter(_.split("_")(6) != "-1")
.map(line => {
val fields = line.split("_")
(fields(6), 1) // (品类ID, 1)
})
.reduceByKey(_ + _) // (品类ID, 点击数)
val orderRDD = actionRDD.filter(_.split("_")(8) != "null")
.flatMap(line => {
val fields = line.split("_")
val ids = fields(8).split(",")
ids.map(id => (id, 1))
})
.reduceByKey(_ + _) // (品类ID, 下单数)
val payRDD = actionRDD.filter(_.split("_")(10) != "null")
.flatMap(line => {
val fields = line.split("_")
val ids = fields(10).split(",")
ids.map(id => (id, 1))
})
.reduceByKey(_ + _) // (品类ID, 支付数)
// 3. 聚合三个统计结果
val cogroupRDD = clickRDD.cogroup(orderRDD, payRDD)
val resultRDD = cogroupRDD.map { case (cid, (clickIter, orderIter, payIter)) =>
val clickCnt = clickIter.headOption.getOrElse(0)
val orderCnt = orderIter.headOption.getOrElse(0)
val payCnt = payIter.headOption.getOrElse(0)
(cid, (clickCnt, orderCnt, payCnt))
}
// 4. 排序取 Top10
val top10 = resultRDD
.sortBy(_._2, ascending = false)
.take(10)
top10.foreach(println)实现方案二:使用累加器(最优方案)
scala
// 自定义累加器,一次性统计三种指标
class CategoryCountAccumulator extends AccumulatorV2[String, mutable.Map[String, (Long, Long, Long)]] {
var map = mutable.Map[String, (Long, Long, Long)]()
override def isZero: Boolean = map.isEmpty
override def copy() = { ... }
override def reset(): Unit = map.clear()
override def add(v: String): Unit = {
val fields = v.split("_")
val cid = fields(0)
val actionType = fields(1) // click/order/pay
val (click, order, pay) = map.getOrElse(cid, (0L, 0L, 0L))
actionType match {
case "click" => map(cid) = (click + 1, order, pay)
case "order" => map(cid) = (click, order + 1, pay)
case "pay" => map(cid) = (click, order, pay + 1)
}
}
override def merge(other: ...): Unit = { ... }
override def value = map
}
// 使用累加器统计
val acc = new CategoryCountAccumulator
sc.register(acc)
actionRDD.foreach(line => {
val fields = line.split("_")
if (fields(6) != "-1") acc.add(fields(6) + "_click")
if (fields(8) != "null") fields(8).split(",").foreach(id => acc.add(id + "_order"))
if (fields(10) != "null") fields(10).split(",").foreach(id => acc.add(id + "_pay"))
})
// 获取结果并排序
val result = acc.value.toList
.map { case (cid, (click, order, pay)) => (cid, (click, order, pay)) }
.sortBy(_._2)(Ordering[(Long, Long, Long)].on(x => (x._1, x._2, x._3)).reverse)
.take(10)十三、总结
13.1 Spark Core 核心知识点回顾
RDD(弹性分布式数据集)
├── 创建:parallelize / textFile / 转换 / new
├── 转换算子(懒执行)
│ ├── Value:map / flatMap / filter / groupBy ...
│ ├── 双Value:intersection / union / subtract / zip
│ └── Key-Value:reduceByKey / groupByKey / sortByKey
├── 行动算子(触发计算)
│ ├── collect / reduce / count / first / take
│ ├── saveAsTextFile / saveAsSequenceFile
│ └── foreach / foreachPartition
├── 序列化:Serializable / Kryo
├── 依赖:窄依赖 vs 宽依赖 → Stage 划分
├── 持久化:cache / persist / checkpoint
└── 分区器:HashPartitioner / RangePartitioner
分布式共享变量
├── 累加器:Accumulator(只写)
└── 广播变量:Broadcast(只读)
13.2 关键概念对比表
| 概念 | 特点 | 使用场景 |
|---|---|---|
| Transformation | 懒执行,返回新 RDD | 数据转换处理 |
| Action | 触发计算,返回结果或写入存储 | 获取结果、持久化 |
| 窄依赖 | 不 Shuffle,流水线执行 | map、filter 等 |
| 宽依赖 | 需 Shuffle,划分 Stage | reduceByKey、groupByKey 等 |
| cache | 内存缓存,不切断血缘 | 重复使用 RDD |
| checkpoint | 写入 HDFS,切断血缘 | 血缘过长、可靠性要求高 |
| 累加器 | Executor → Driver 聚合 | 计数、求和等聚合操作 |
| 广播变量 | Driver → Executor 分发 | 大表 Join 小表、配置分发 |
13.3 性能优化建议
- 优先使用 reduceByKey 替代 groupByKey:减少 Shuffle 数据量
- 合理使用 mapPartitions 替代 map:批量处理,减少函数调用开销
- 及时使用 unpersist 释放缓存:避免内存占用过多
- 使用 Kryo 序列化:提升序列化性能 10 倍
- 避免在 Transformation 中使用累加器:可能导致重复计算
- 广播大变量:避免每个 Task 都发送一份
创作不易,如果觉得有帮助,请点赞 👍、收藏 ⭐、关注 💖!