万字拆解 NeckFix:AI 脖子前倾检测的算法原理与工程实现
前言
上一篇文章 介绍了 NeckFix 的功能和使用方法,这篇深入聊聊背后的技术实现。
一、整体架构
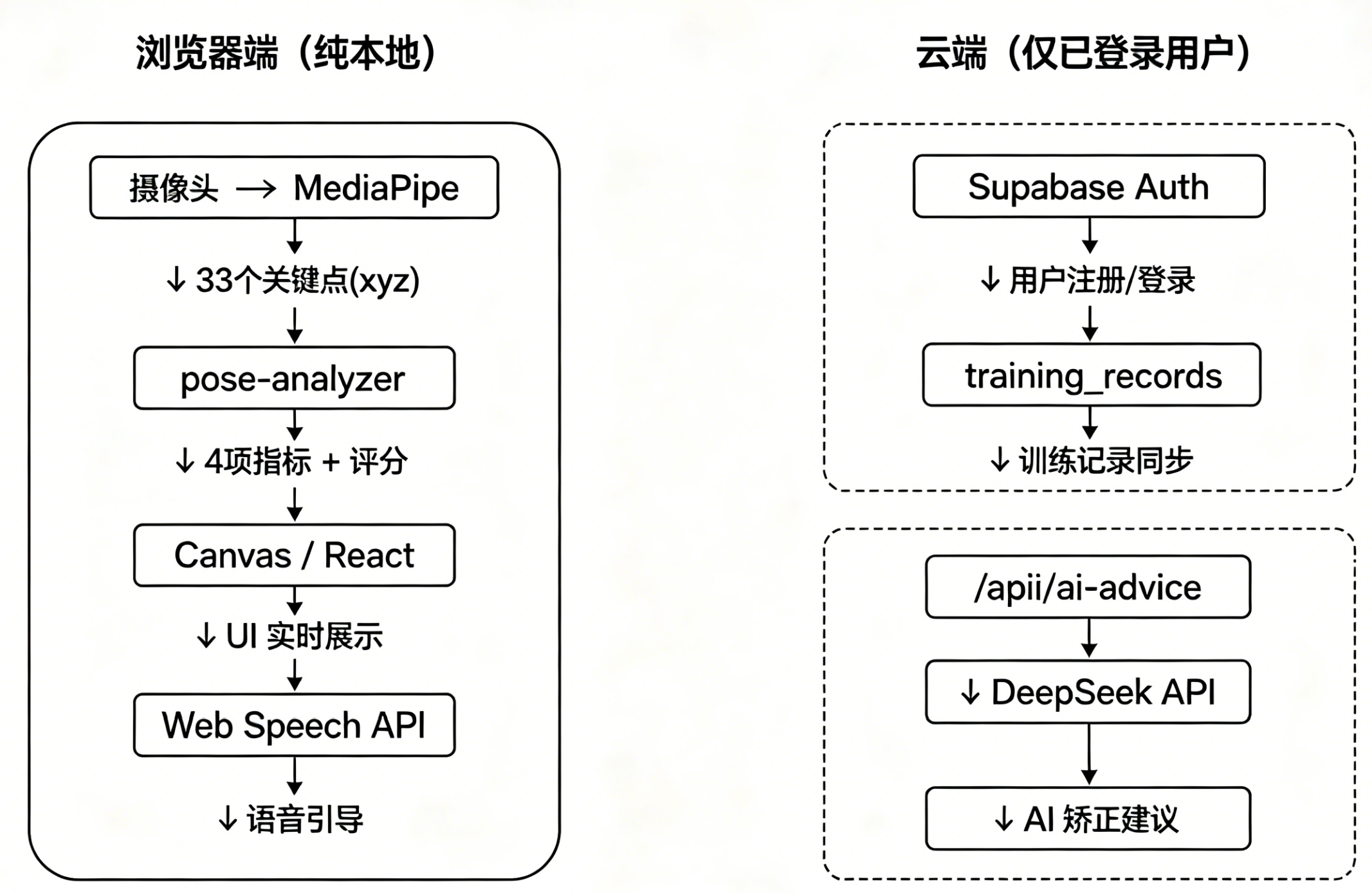
核心设计原则:所有姿态数据在浏览器本地处理,摄像头画面永不离开用户设备。只有登录后的 AI 建议请求和训练记录同步才会访问远端服务。
二、姿态检测的技术选型
为什么用 8 个关键点而不是 33 个
MediaPipe Pose 输出全身 33 个 3D 关键点,我们实际只用了 8 个:
| 关键点 | 索引 | 用途 |
|---|---|---|
| 鼻子 | 0 | Z 轴前倾深度 + Y 轴头部位置 |
| 左眼 / 右眼 | 2 / 5 | 头部侧倾角度(双眼连线 vs 水平) |
| 左耳 / 右耳 | 7 / 8 | 辅助 Y 轴指标 |
| 左肩 / 右肩 | 11 / 12 | 躯干参考系 + 耸肩检测 |
其余 25 个点为什么不用的核心原因:Z 轴局限。
Z 轴陷阱:为什么 CVA 金标准在单摄像头上行不通
颅椎角(Craniovertebral Angle,CVA)是临床评估脖子前倾的金标准。测量方式是从侧面拍照,计算耳屏(tragus)到 C7椎骨的连线与水平面的夹角。正常 ≥ 50°,低于 35° 为重度前倾。
但这个方案依赖侧面视角。当用户正对摄像头时,MediaPipe 的 Z 轴(景深)是从单张 2D图像估算的,噪声很大。我们的实测数据:
耳朵 Z 差值(耳-肩深度差):
头后缩时: 0.2446
头前伸时: 0.2439
变化幅度: 0.0007(几乎不变!)
耳朵在头部两侧,不随前伸显著移动,其 Z 值变化完全淹没在 MediaPipe
的估算噪声里。从正面单摄像头做 CVA 是不可靠的------这是反复试错后最重要的教训。
最终方案:鼻子 Z + 头部 Y 联合打分
鼻子的 Z 信号比耳朵强两个数量级:
鼻子 Z 差值(鼻-肩深度差):
头后缩时: 0.87
极限前伸: 0.96
变化幅度: 0.09(清晰可辨)
为什么鼻子 Z 更好?鼻子是面部最突出的点,前伸时它的 Z 坐标变化最显著,MediaPipe对鼻子的深度估算也最准确(面部特征密集)。
但 Z 轴还有一个问题:依赖摄像头距离。同一姿势,靠近屏幕和远离屏幕,Z差值会漂移。
我们的解决方法是 「距离提示 + 窄阈值」:
- 用肩宽占画面比例估算距离(40cm 真实肩宽 / 摄像头 FoV → 画面占比 ≈ 25-65% = 50cm)
- UI 提示用户调整到标准距离
- 在标准距离下,直接将鼻子 Z 差值线性映射到 0-100 分(各阶段分数由本人实测得出,人力有限,同志们若想更加精确测定,可自行调试)
typescript
// 阈值来自真人实测数据(50cm 标准距离)
// 后缩: noseZDiff ≈ 0.87, 极限前伸: noseZDiff ≈ 0.96
const fhpZScore = clamp(((noseZDiff - 0.84) / 0.14) * 100, 0, 100);
// 头部 Y 比:鼻子到肩膀的垂直距离 / 肩宽
// 后缩: ≈ 0.79, 前伸: ≈ 0.72
const headProtrusion = clamp(((0.82 - headYRatio) / 0.17) * 100, 0, 100);
// 综合:50% Z 深度 + 50% Y 垂直 = 兼顾前移 + 下沉
const forwardHeadAngle = clamp(fhpZScore * 0.50 + headProtrusion * 0.50, 0, 100);三、四项检测指标
1. 脖子前倾(权重 45%)
基于鼻子 Z 深度(50%)+ 头部 Y
比(50%)联合打分。兼顾了头部的水平前移和垂直下沉两个维度。
2. 耸肩程度(权重 15%)
abs(leftShoulder.y - rightShoulder.y) --- 双肩高度差。办公族右手握鼠标常见右肩上抬。
3. 头部侧倾(权重 40%)
双眼连线与水平面的夹角。测试数据:
头后缩: -6.86°(左眼略低)
头前伸: -1.09°(基本水平)
|倾斜角| < 2° 为 0 分,> 10° 为 100 分。侧倾长期不纠正会导致颈椎侧弯。
综合分级
综合分 = 100 - (前倾 × 0.45 + 耸肩 × 0.15 + 侧倾 × 0.40)
≥ 75 分 → 良好
55-74 分 → 轻度
35-54 分 → 中度
< 35 分 → 重度
四、训练模块:呼吸同步与动作演示
为什么是 4 秒呼吸周期
吸气(4s) → 屏息(4s) → 呼气(4s) → 循环。4
秒来自物理治疗指南------颈椎康复要求慢速可控,足够完成一个动作相位并稳定呼吸。
动作时长设计
所有动作时长都是 12 的倍数(36s /
48s),确保每个动作包含完整呼吸周期,不会在中间截断;
动作去重
四个核心动作(下巴后缩、颈部前屈、侧屈、肩胛收缩)各三个等级,训练计划只展示每个动作的最高难度版本:
typescript
const dedupedMap = new Map<string, Exercise>();
for (const ex of planExercises) {
const base = ex.id.replace(/-l[123]$/, ""); // 去掉后缀
dedupedMap.set(base, ex); // 后面的覆盖前面的
}
// 结果:4 个动作 × 各取最高等级语音策略:少即是多
第一版每个动作阶段都播报,结果语音还没说完动作已切换到下一阶段。Web Speech API 的 speak()是异步的,无法精确控制时间轴。最终只保留三处语音:
- 训练开始:播报动作名 + "开始"
- 动作间切换:仅滴滴声(Web Audio API oscillator beep),不语音
- 训练结束:播报"训练完成"
五、语音引导系统
5.1 Web Speech API 的限制
浏览器内置的 TTS
引擎,优点是零成本、零延迟、离线可用,缺点是语音质量取决于系统和浏览器。
5.2 语音优选策略
typescript
const prefer = [
"tingting", // macOS --- Apple 原生中文女声,最好
"huihui", // Windows --- Microsoft 中文女声
"yaoyao", // Windows 11 --- 新版女声
"xiaoxiao", // Edge/Win11 --- 神经网络语音,接近真人
"yunjian", // Edge/Win11 --- 神经网络男声
// ... 共 15 个候选项
];遍历优先级列表,找到第一个可用的中文语音。Windows 11 + Edge 浏览器能选到神经网络语音Xiaoxiao,质量最高。Chrome 在 Windows 上只能用旧版语音,质量次之。
5.3 语音播报时机
经过多次迭代,最终方案非常克制:
- 训练开始:播报动作名 + 第一条指令 + "开始"
- 训练结束:播报"训练完成"
- 动作间:只发滴滴声(Web Audio API beep),不语音
- 预览:手动点「语音讲解」才逐条播报
这样避免了语音跟不上动作变化的问题,也让用户不会被频繁打断。
六、AI 建议:从数据到自然语言
6.1 Prompt 工程
const prompt = `你是一位资深的物理治疗师和姿势矫正专家。
根据以下用户的姿态检测数据,请给出3-5条简洁实用的个性化纠正建议。
使用中文回答,语气温暖而专业,每条建议不超过40个字。
数据(过去60秒内的平均值):
- 脖子前倾程度: ${forwardHeadAngle}%
- 头部前伸程度: ${headProtrusion}%
- 耸肩程度: ${shoulderShrug}%
- 身体左右倾斜: ${bodyTilt}%
- 综合评分: ${overallScore}/100
请以康复治疗师的口吻给出建议,格式为编号列表。`;
关键设计:
- 角色设定:"资深物理治疗师"------给模型一个专业身份,输出质量明显高于直接问
- 字符限制:"每条不超过 40 字"------避免废话,也控制 token 消耗
- 数据注入:四项指标 + 综合分,让模型有据可依
6.2 API 配额保护
前端层:未登录 → 显示「登录后获取 AI 建议」按钮 → 跳转登录页
后端层:API route 校验 Supabase session → 无 session 返回 401
两层防护确保只有注册用户才能调用 DeepSeek,避免被刷量。
七、经验教训
8.1 Z 轴校准没有捷径
起初想用文献里的阈值,发现每个人离摄像头的距离、肩膀宽度都不同,固定阈值完全行不通。最后是靠真人反复测试,记录极端位姿的 Z 值,线性映射到 0-100 分。如果你的项目也用到了Z 轴数据,建议直接做真人标定。
8.2 语音播报越少越好
第一个版本每个动作阶段都播报一次,结果语音还没说完,动作已经切换到下一个阶段了。Web Speech API 的 speak() 是异步的,没法像音视频那样精确控制时间轴。最后砍掉所有中途语音,只保留开始和结束,体验反而更好。