《医疗 OCR 识别 API 怎么选?(报告单 / 发票 / 检测单)》医疗票据 OCR 识别 API 多场景落地指南:医保结算 + 商保理赔 + 医疗信息化(附 Python/Java 完整示例)
导语:每天上万张医疗票据,如何做到秒级处理?
2026年,全国各级医疗机构年均产生的医疗票据数以亿计。一张住院发票,传统人工录入需要5-10分钟,错漏率超过2%。更麻烦的是,患者理赔流程从提交材料到最终赔付,平均耗时长达28个工作日,其中60%的时间消耗在人工核对环节。
医疗票据OCR技术,正是破解这些难题的核心突破口。它与通用OCR有着本质区别------通用OCR将票据识别为一段散乱文本,而医疗票据OCR需要完成的是:字段提取 + 表格解析 + 结构化输出 + 业务规则适配。本文从医保结算、商保理赔、医疗信息化三大落地场景出发,结合实际案例与 Python/Java 多语言代码示例,为你提供一套完整的落地指南。
💡 新手入门提示 :如果你对OCR的基础概念还不熟悉,建议先阅读我们之前发布的《医疗 OCR 识别 API 怎么选?(报告单 / 发票 / 检测单)》
一、医保结算场景:从人工核对到智能审核
1.1 业务痛点
医保零星报销场景中,经办机构需要处理海量手工报销票据。传统人工审核面临三大挑战:
-
材料类型庞杂:涉及身份凭证、医疗收费票据、诊断证明、检验检查报告等近百类非结构化材料;
-
版式差异极大:全国有超过3万家医疗机构,每家门诊发票、住院结算单的设计千差万别;
-
审核效率低下:单张票据录入需5-10分钟,复杂案件审核周期长达5-7个工作日。
1.2 实施路径
医保结算场景的OCR落地,通常采用以下流程:
① 票据图像采集与预处理(倾斜矫正、去噪、印章过滤);
② 版式识别与字段定位;
③ 关键信息提取(发票编号、就诊人、医保类型、费用明细);
④ 与医保目录自动比对(药品/诊疗项目的医保编码匹配);
⑤ 报销金额自动计算与审核。
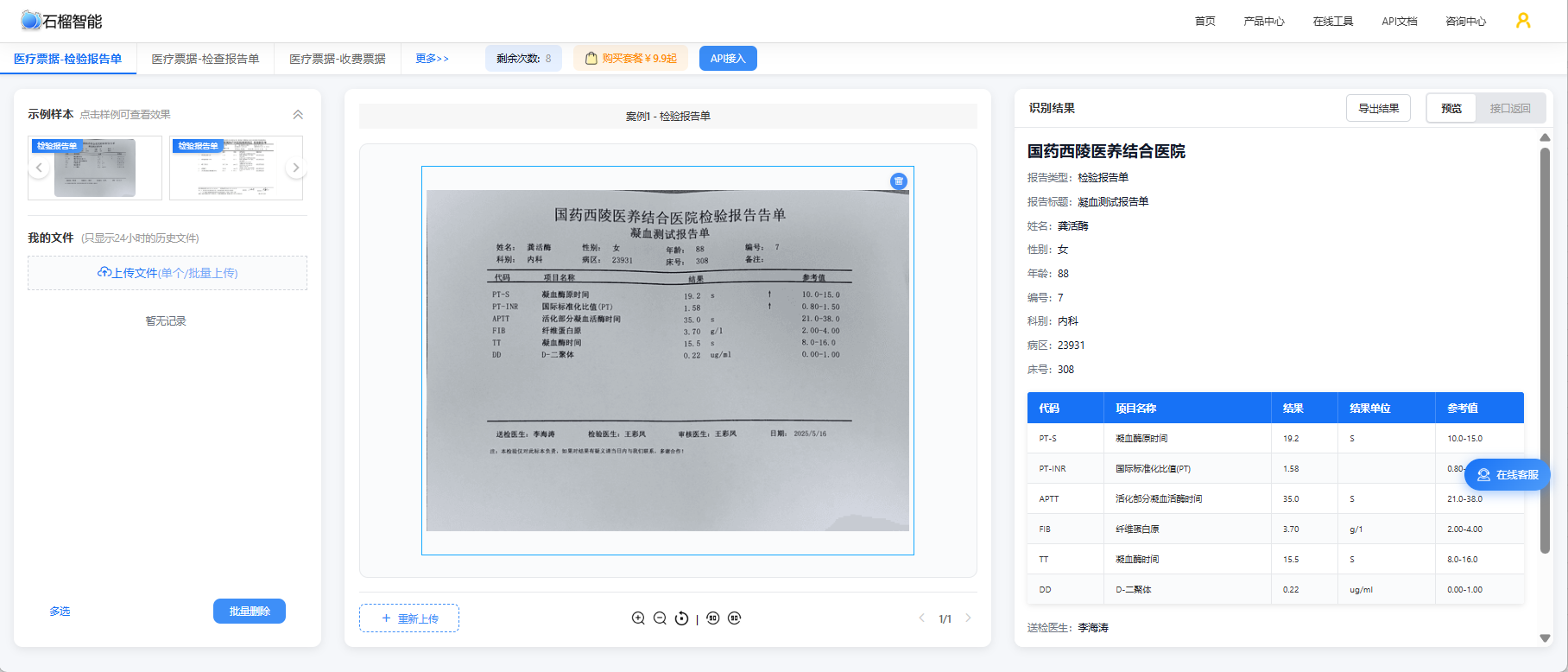
1.3 真实效果
某市医保中心引入OCR智能审核系统后,单日处理量从3万份提升至12万份,审核周期缩短80%以上。更直观的数据来自颍州区试点:截至2026年3月,OCR智能应用受理零星报销6718份,结算率达87.66%,因材料不清、项目误扣导致的退单率从原来的1.9%降至0.7%,群众平均跑腿次数从2.5次减少到1次以内。
1.4 API 调用示例(Python + Java)
以下演示如何使用医疗票据OCR API完成一张住院发票的结构化识别,识别结果输出为可直接入库的JSON格式。
【Python示例】
python
# ==============================================================================
# 免费在线体验:https://market.shiliuai.com/tools/medical-report-ocr
# API文档完整开发文档和代码示例:https://market.shiliuai.com/doc/doc-extract
# 支持免费在线体验
# API文档清晰,提供多种接入语言示例(如python、js、C#、java、php等),以及自动化脚本语言(如天诺、懒人精灵、按键精灵、易语言、EasyClick、触动精灵等)
# ==============================================================================
# -*- coding: utf-8 -*-
import requests
import base64
import json
# 请求接口
URL = "https://ocr-api.shiliuai.com/api/doc_extract/v1"
# 图片/pdf文件转base64
def get_base64(file_path):
with open(file_path, "rb") as f:
data = f.read()
return base64.b64encode(data).decode("utf8")
def demo(appcode, file_path):
# 请求头
headers = {
"Authorization": "APPCODE %s" % appcode,
"Content-Type": "application/json"
}
# 请求体
b64 = get_base64(file_path)
data = {
"file_base64": b64,
"prompt": ""
}
# 请求
response = requests.post(url=URL, headers=headers, json=data)
content = json.loads(response.content)
print(content)
if __name__ == "__main__":
appcode = "你的APPCODE"
file_path = "本地文件路径"
demo(appcode, file_path)【Java示例】
python
// ==============================================================================
// 免费在线体验:https://market.shiliuai.com/tools/medical-report-ocr
// API文档完整开发文档和代码示例:https://market.shiliuai.com/doc/doc-extract
// 支持免费在线体验
// API文档清晰,提供多种接入语言示例(如python、js、C#、java、php等),以及自动化脚本语言(如天诺、懒人精灵、按键精灵、易语言、EasyClick、触动精灵等)
// ==============================================================================
import com.alibaba.fastjson2.JSON;
import com.alibaba.fastjson2.JSONObject;
import org.apache.http.HttpResponse;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.apache.commons.io.FileUtils;
import java.io.File;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.Base64;
public class Main {
public static String get_base64(String path) {
String b64 = "";
try {
byte[] content = FileUtils.readFileToByteArray(new File(path));
b64 = Base64.getEncoder().encodeToString(content);
} catch (IOException e) {
e.printStackTrace();
}
return b64;
}
public static void main(String[] args) {
String url = "https://ocr-api.shiliuai.com/api/doc_extract/v1";// 请求接口
String appcode = "你的APPCODE";
String file_path = "本地文件路径";
Map headers = new HashMap<>();
headers.put("Authorization", "APPCODE " + appcode);
headers.put("Content-Type", "application/json");
JSONObject requestObj = new JSONObject();
requestObj.put("file_base64", get_base64(file_path));
requestObj.put("prompt", "");
String bodys = requestObj.toString();
try (CloseableHttpClient httpClient = HttpClients.createDefault()) {
HttpPost httpPost = new HttpPost(url);
for (Map.Entry entry : headers.entrySet()) {
httpPost.addHeader(entry.getKey(), entry.getValue());
}
StringEntity entity = new StringEntity(bodys, "UTF-8");
httpPost.setEntity(entity);
HttpResponse response = httpClient.execute(httpPost);
int stat = response.getStatusLine().getStatusCode();
if (stat != 200) {
System.out.println("Http code: " + stat);
return;
}
String res = EntityUtils.toString(response.getEntity());
JSONObject res_obj = JSON.parseObject(res);
System.out.println(res_obj.toJSONString());
} catch (Exception e) {
e.printStackTrace();
}
}
}API文档完整开发文档和代码示例:https://market.shiliuai.com/doc/doc-extract
💡 免费体验入口 :以上代码基于公司医疗票据OCR API实现。如果你希望先测试效果,可以前往石榴智能的医疗票据识别在线工具,无需代码即可免费上传单据进行结构化抽取测试。
二、商保理赔场景:从5天到2小时
2.1 业务痛点
商业健康险理赔的痛点不仅在于信息提取本身,更在于信息提取后的规则匹配与系统对接:
-
版式不统一:来自不同医疗机构的门诊发票、住院结算单、费用清单格式各异,人工每单录入需5-10分钟,30页单据平均耗时2.5小时,错误率高达12%;
-
规则匹配复杂:各地医保政策差异大、药品/诊疗目录更新频繁、商保条款个性化强,人工匹配极易出错;
-
系统对接难:商保核心系统、TPA审核平台、医保结算系统数据格式不统一,缺乏标准化对接协议。
2.2 实施路径
商保理赔场景的OCR落地,核心在于构建"信息抽取 + 规则匹配 + 系统对接"三位一体的解决方案:
① 多格式票据混合识别(纸质/电子发票、诊断证明等);
② ICD编码自动匹配(疾病诊断与诊疗项目合理性校验);
③ 医保目录比对(药品/诊疗项目的甲乙类、自付比例);
④ 商保条款匹配(赔付比例、免赔额、免责项目);
⑤ 理赔金额自动核定,生成结构化理赔单据。
2.3 真实效果
某健康险保险公司接入医疗票据OCR系统后,小额案件(<5000元)处理时效从72小时压缩至2小时;单张票据处理时间压缩至秒级,较传统OCR提升4倍以上。在理赔规则匹配层面,快瞳等专业服务商已内置3000万+医学实体知识数据,覆盖国家-省-市三级医保目录,匹配率可达99%。
2.4 实施建议
对于计划引入医疗票据OCR的商保机构,建议按以下路径分阶段实施:
-
阶段一(基础型) :接入API实现费用明细自动提取,代替纯人工录入;
-
阶段二(集成型) :将OCR与理赔系统深度集成,实现信息自动提取 + 目录匹配 + 金额核算的全链路自动化;
-
阶段三(智能化) :基于OCR累积的结构化数据构建风控模型,实现欺诈检测与异常预警。
三、医疗信息化场景:从数据孤岛到互联互通
3.1 业务痛点
医疗信息化建设虽已推进多年,但数据的结构化程度和数据流通效率仍是制约医院运营效率的瓶颈:
-
非结构化数据占比高:电子病历系统中,病史描述、医嘱等自由文本缺乏标准化格式,非结构化数据占比超过75%,医生查找特定病史信息平均需翻阅12页病历,耗时约8分钟;
-
系统间数据互通率低:HIS、LIS、PACS等院内系统数据互通率不足40%;
-
数据利用效率低:大量纸质材料需要人工扫码、翻拍、录入后才能进入数字系统。
3.2 实施路径
医疗信息化场景的OCR落地,目标是打通非结构化票据数据与结构化医疗系统的"最后一公里":
① 院内多源票据接入(门诊/住院发票、结算单、检验报告);
② 标准化结构化输出(转为HIS/EMR可直接消费的JSON格式);
③ 自助服务终端集成(患者持单自助办理、费用查询);
④ 数据治理与统计分析(费用趋势、诊疗项目使用率、药品占比等)。
3.3 价值体现
某省级医院部署医疗票据OCR系统后,财务部门效率提升65%,人力成本节约40%。门诊导诊机器人集成OCR技术后,可自动识别患者提供的纸质材料并引导至对应科室,导诊准确率提升至92%。
在更宏观的维度上,医疗票据OCR与电子病历系统(EMR)深度集成后,可实现:
-
自动填充患者费用信息至诊疗记录;
-
生成结构化费用报表(支持DICOM标准输出);
-
异常费用自动预警(如单日检查费超限即时提醒)。
四、技术挑战与应对方案
医疗票据OCR比通用OCR面临更严峻的挑战,主要体现在以下几个方面:
4.1 印章遮挡
红色印章覆盖关键文字是最常见且最严重的问题之一。解决思路是通过HSV颜色空间分离印章区域,再采用图像修复算法还原被覆盖文字。
4.2 版面复杂
医疗票据常采用多栏表格、手写补充等复杂排版,常规版面分割算法准确率不足60%。解决方法是通过深度学习模型(DBNet+CRNN+Transformer)实现多版式自适应识别,动态匹配票据类型。
4.3 语义理解缺失
同义词转换(如"自付一"与"个人账户支付")需要医疗领域知识图谱支撑。结合NLP技术,通过医疗知识图谱进行术语归一化和关联映射,可实现标准化输出。
五、如何选择医疗票据OCR API?
在选择医疗票据OCR API时,建议从以下三个维度进行评估:
维度一:版式自适应能力------能否自动识别不同类型的票据(门诊发票、住院结算单、检验报告等),并根据版式动态抽取关键信息,而非依赖预设模板匹配。
维度二:结构化抽取深度------是否输出"字段 + 表格 + 清单"的多层次结构化数据。检查报告需提取"检查所见"和"诊断结论",检验报告需按"项目/结果/单位/参考值"逐行对齐表格,收费票据需逐条拆分费用明细行并计算合计金额------入库前就能直接使用的才是真结构化。
维度三:业务规则适配------是否内置医保目录匹配、ICD编码映射、知识图谱校验等能力。这直接决定了识别结果能否直接用于报销计算和理赔审核。
六、多语言接入参考
石榴智能医疗票据OCR API支持免费在线体验,API文档清晰,提供多种接入语言示例(如python、js、C#、java、php等),以及自动化脚本语言(如天诺、懒人精灵、按键精灵、易语言、EasyClick、触动精灵等),可在接入文档中查看完整代码:
| 语言 | 适用场景 |
|---|---|
| Python | 数据分析、批量处理、自动化脚本 |
| Java | 企业级后端系统集成 |
| JavaScript / Node.js | Web前端调用、Serverless |
| PHP | 网站后端、云服务集成 |
| C# | .NET框架应用系统 |
医疗票据OCR API接入文档(包含完整的接口说明与各语言示例代码)
七、免费在线体验
如果你希望在实际对接API之前,先了解公司医疗票据OCR的实际效果,可以免费使用公司医疗票据识别在线工具。无需编写任何代码,上传票据图片即可即时查看结构化识别结果,支持门诊发票、住院结算单、费用清单、检验报告等多种票据类型的体验测试。
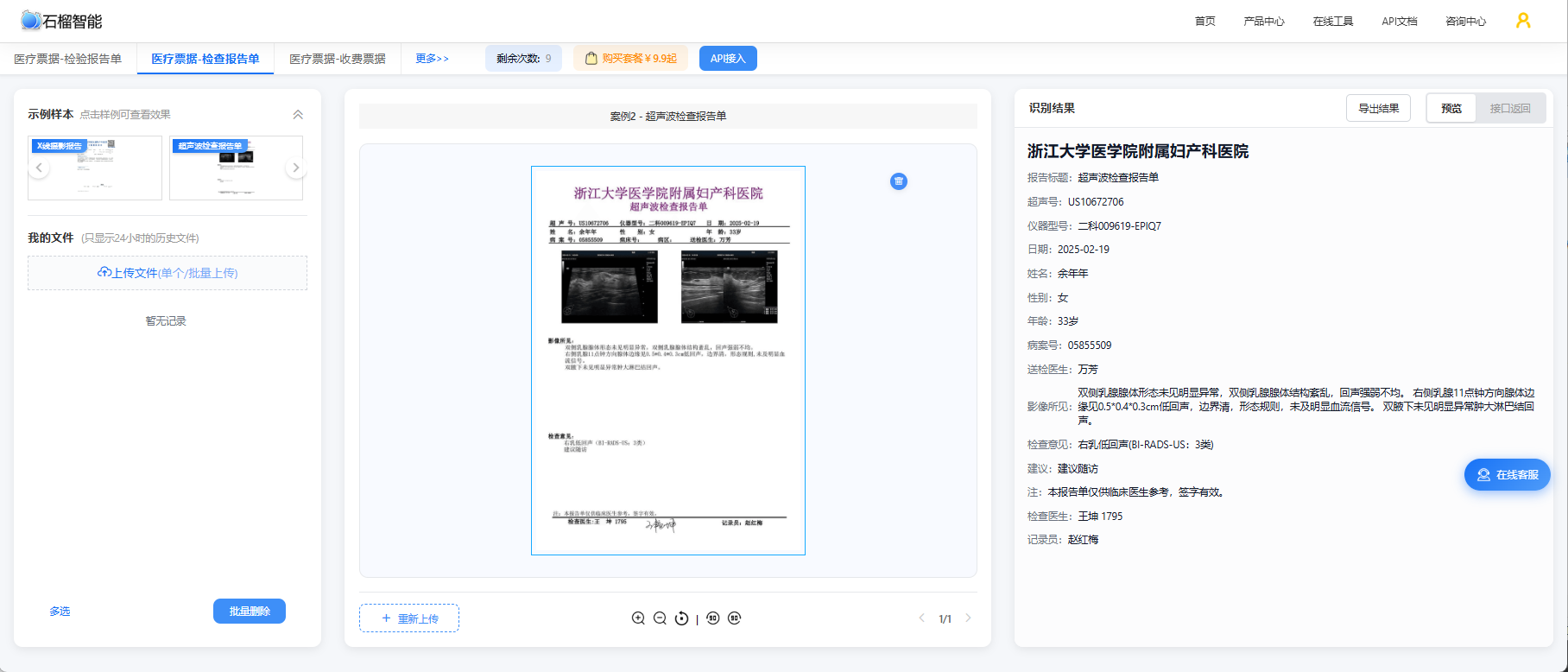
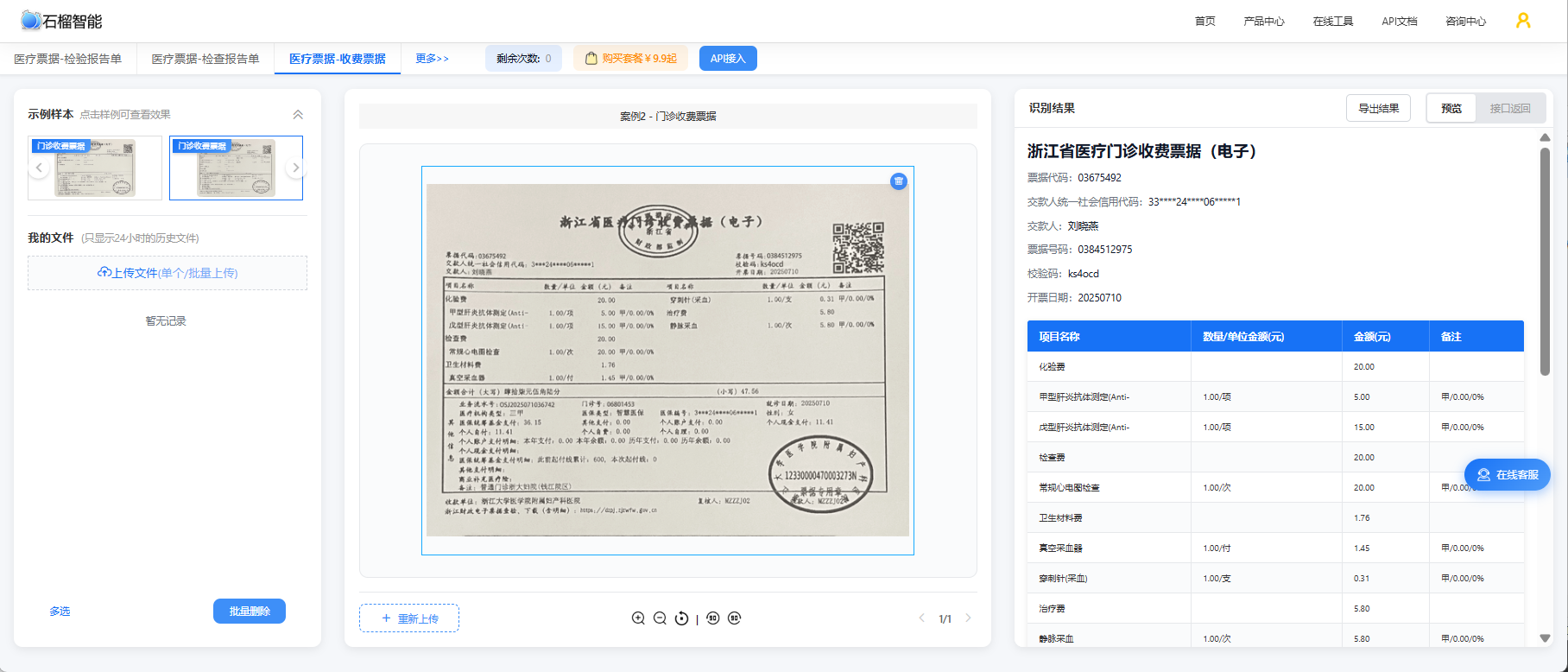
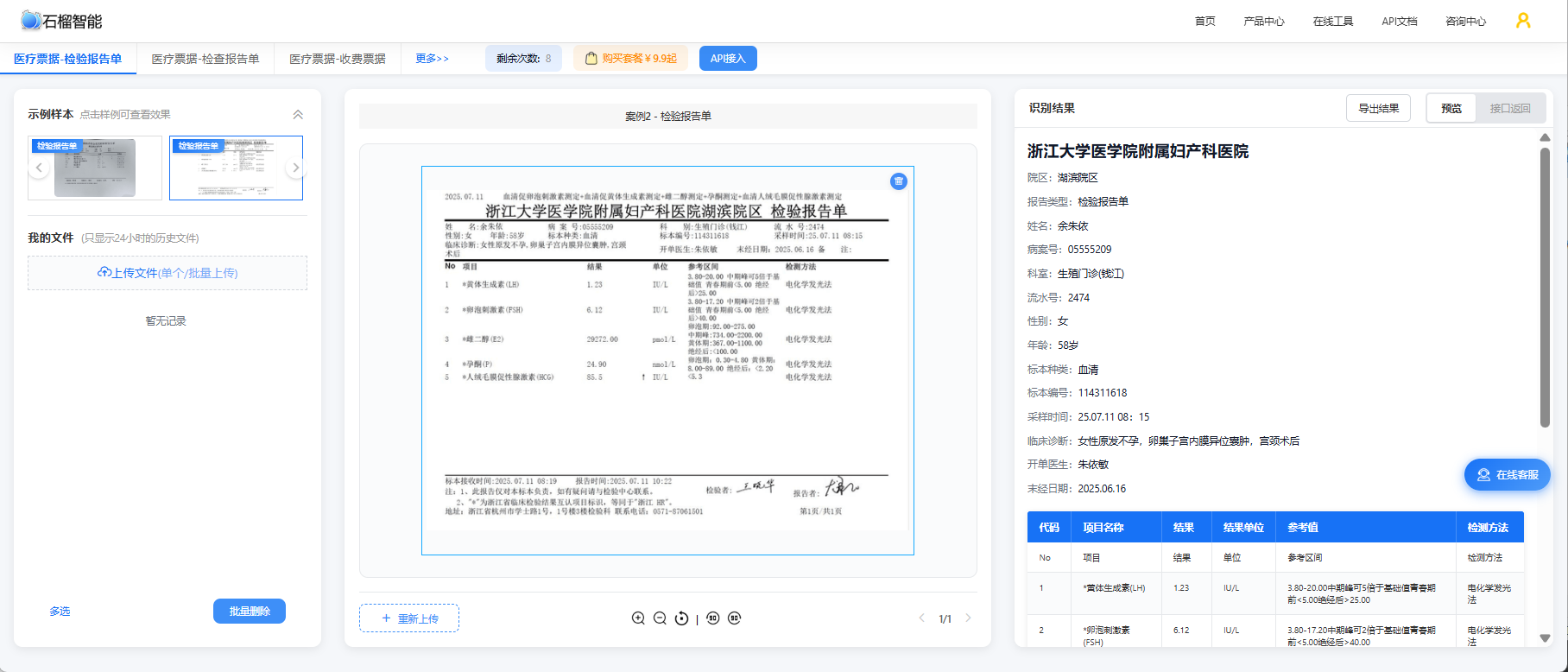
总结
医疗票据OCR识别正在从"辅助工具"进化为"核心生产力"。
无论是医保局将审核周期从数天压缩至数小时,还是商保公司将理赔时效从5天缩短至2小时,抑或是医院将财务人力成本削减40%,背后都印证同一个事实:当数据提取、规则匹配、系统对接形成闭环时,医疗单据处理的效率天花板会被彻底打破。
如果你正在规划相关业务场景的数字化转型,建议先通过免费在线工具测试票据识别效果,再根据实际需求对接API进行系统集成。
📖 系列推荐:
《医疗票据OCR识别API实战:从医保结算单到结构化数据提取》可从技术原理角度深入理解识别流程;
《发票识别OCR API接入详解》和《OCR识别不准确怎么办?》分别从基础功能和优化技巧角度提供了有价值的参考。欢迎点击账号主页查看完整系列内容。
🔖 标签:#医疗票据OCR #OCRAPI #医保结算 #商保理赔 #医疗信息化 #PythonOCR #JavaOCR