1 引言
1.1 线性一致性
什么是线性一致性?
线性一致性是分布式系统中最强的一致性模型,它要求系统表现得好像只有一个数据副本,且所有操作都是原子性的。简单说,就是让分布式系统看起来像单机系统一样。
线性一致性是分布式系统中最强的一致性保证,基于分布式的CAP理论,那么其代价最高的。在实际系统设计中,需要根据业务需求在一致性和性能之间做出权衡。对于需要强一致性的关键场景,线性一致性是必要的;对于可以容忍短暂不一致的非关键场景,可以选择更弱的一致性模型以获得更好的性能。
1.2 背景
raft算法是一个经过严格证明的线性一致性算法,在市面上很多成熟的框架如ETCD、Tidb等也得到很广泛的应用。理论上讲如果一切都按着raft论文进行实现就不会有什么安全性的问题。但是,在实际生产应用中使用raft必须需要经过一些优化。因此,本文将基于对线性一致性读方法及实现展开一系列的探究和讨论。
1.3 矛盾
Raft 是一个强一致性 共识算法,所有写操作都必须经过日志复制、多数派提交后才能生效。对于传统的读操作 ------ Read as Write (也称为 "Write-Read" 或 "Read via Write")。是 Raft 中实现线性一致读的最简单、最直接的方法,其核心思想是:将读请求转化为写请求来处理,通过日志复制来保证线性一致性。其流程图与写操作一致如下所示:

那么就会出现很大的性能问题:
- 日志膨胀:每个读请求都产生日志条目
- 磁盘 I/O:每个读请求都需要持久化日志
- 网络开销:每个读请求都需要复制到多数节点
- 吞吐量限制:受限于 Raft 日志复制吞吐量
其实,在 Raft 论文里面,提到了一种通过 clock + heartbeat 的 lease read的优化方法可以用来提高读操作的效率使得读操作实际不需要去做Raft的日志传播,且又能够保证raft的安全性的问题。那么这个方法是什么原理呢?我们来逐步解析其中的奥秘。
2 Lease Read算法
首先我们可以明确的一点,如果raft共识算法没问题,那么从leader的状态机中读取的数据一定是可靠的,因为leader的状态机应用必须得到大多数节点的认可才能进行日志的应用,也就是说leader节点状态机上有的数据大多数节点都会有。
那么LeaseRead算法也是建立在了这个前提之上。我们只要确保我们读的是leader节点,并且确保leader节点在当前时刻没有被其他follower节点所替代即仍然维持着leader的权威,那么就可以认为读取的数据是安全的。
那么可以将问题简化 ------ 只要保证读取的节点是leader就可以满足顺序一致性的读取。那么如何确保leader一定是leader呢?
- 通过自身判断?当然不行,网络分区时会出现多个leader
- 向follower发送rpc确定自己是leader?这个方法没问题,但是开销堪比直接把读操作当作日志
机智的人们想出了一个好办法,就是所谓Lease Read的机制,既不需要把读当作日志,也不需要每次读操作发送RPC确定自己是leader
因此,LeaseRead(租约读) 的核心思想是:
Leader 通过心跳机制维护一个"租约期",在租约期内,Leader 可以确信自己仍然是合法的 Leader(没有发生网络分区导致其他节点选举出新 Leader)。因此,Leader 可以直接读取本地状态机,无需再次确认自己的 Leader 身份。
leader发送每次心跳RPC的时候,会首先记录一个时间点 start,当系统大部分节点都回复RPC时,我们就可以认为 leader 的 lease 有效期可以到 start + election timeout + clock drift bound(正负未知)这个时间点。因为 follower 至少在 election timeout的时间之后才会重新发生选举,所以在理想状态上来讲这套机制是有效的

3 Lease Read算法 ------ 实现篇
在我的上面基于raft的分布式kv存储系统中,也简易的添加了lease Read + ReadIndex算法的实现。这里对一些核心的数据结构以及部分核心API进行讲解,更多详细的实现可以直接看上面的源码的实现。
这里简单讲一些ReadIndex,后面也会详细讲解。ReadIndex 是 etcd 提出的线性读方案,核心思想:读操作也需要像写操作一样,等待当前时刻之前所有已提交的日志都应用到状态机后,才能读取。这样可以保证读到的数据包含所有之前已确认的写操作。
3.1 LeaseState(租约状态)
Go
// src/raft/raft.go
type LeaseState struct {
IsLeader bool // 是否是 Leader
LeaseValid bool // 租约是否有效
ReadIndex int // 当前可安全读取的日志索引
LeaseExpiration time.Time // 租约过期时间
}3.2 Raft节点中Lease相关字段
Go
// src/raft/raft.go
type Raft struct {
// ... 其他字段 ...
lastHeartbeatTime time.Time // 上次收到心跳的时间
leaseExpiration time.Time // 租约过期时间(本地计算)
leaseReadIndex int // 租约对应的可读索引
leaseDuration time.Duration // 租约时长(默认 400ms)
enableLeaseRead bool // 是否启用 LeaseRead
leaseState atomic.Value // 原子存储的 LeaseState(线程安全)
}3.3 完整流程
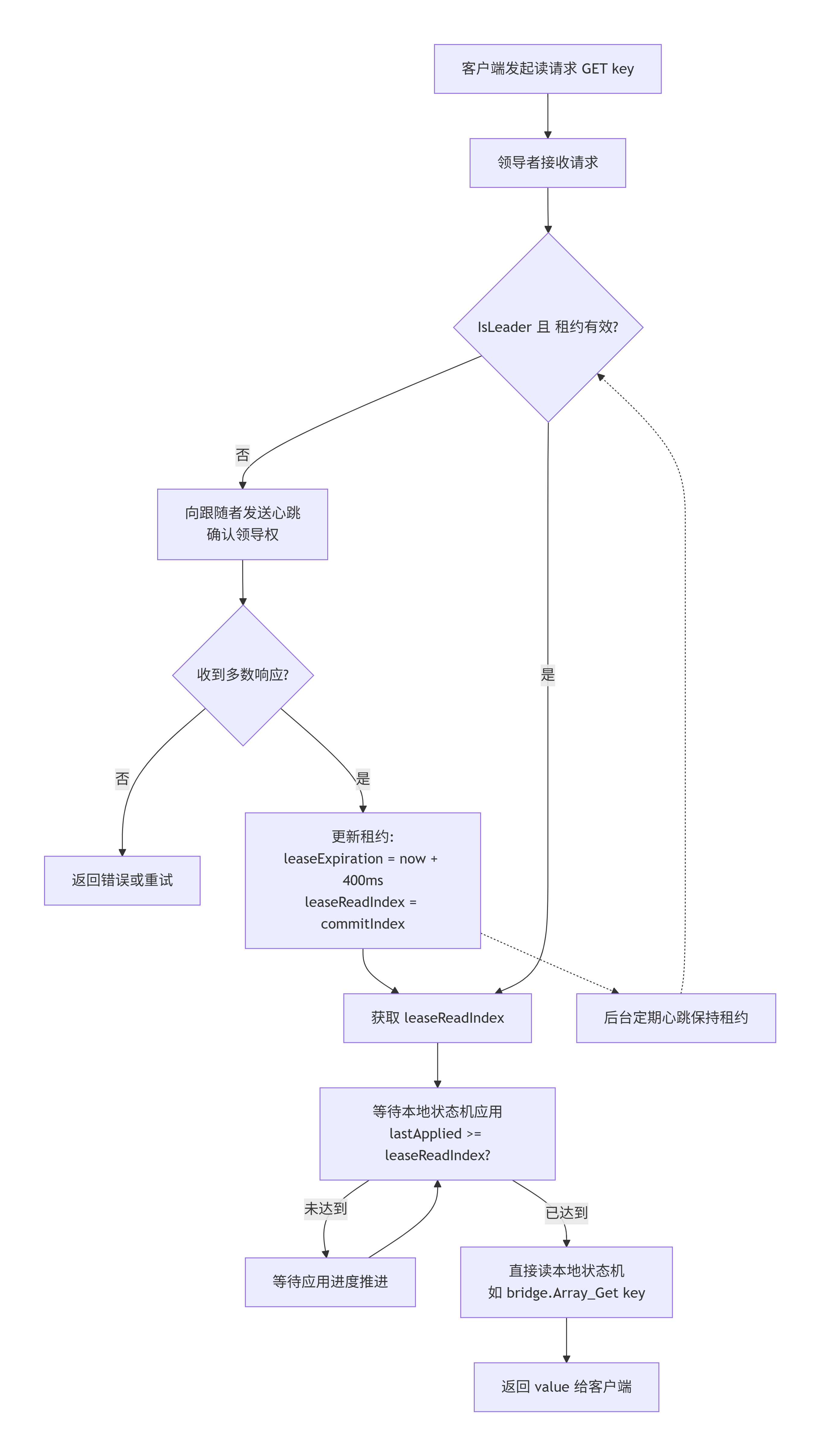
阶段1:leader选举成功,初始化Lease
Go
// src/raft/raft.go:becomeLeaderLocked()
func (rf *Raft) becomeLeaderLocked() {
rf.role = Leader
// ... 初始化 nextIndex, matchIndex ...
rf.updateLease() // <-- 成为 Leader 时立即更新 Lease
go rf.heartbeatTicker(rf.currentTerm)
// ...
}阶段2:心跳成功,更新Lease
Go
// src/raft/raft_heartbeat.go:sendHeartbeat()
func (rf *Raft) sendHeartbeat(server int, term int) {
// ... 发送 AppendEntries RPC ...
reply := &AppendEntriesReply{}
ok := rf.sendAppendEntries(server, args, reply)
if !ok {
return
}
rf.mu.Lock()
if reply.Term > rf.currentTerm {
rf.becomeFollowerLocked(reply.Term)
rf.mu.Unlock()
return
}
if reply.Success {
rf.updateLease() // <-- 心跳成功,更新 Lease
}
rf.mu.Unlock()
}阶段3:updateLease更新租约
Go
// src/raft/raft.go:updateLease()
func (rf *Raft) updateLease() {
now := time.Now()
rf.lastHeartbeatTime = now
rf.leaseExpiration = now.Add(rf.leaseDuration) // 400ms 后过期
rf.leaseReadIndex = rf.commitIndex // 当前已提交的日志索引
rf.leaseState.Store(&LeaseState{
IsLeader: true,
LeaseValid: true,
ReadIndex: rf.commitIndex,
LeaseExpiration: rf.leaseExpiration,
})
}关键点:
- leaseDuration = 400ms:租约时长,必须小于超时时间(500ms-1500ms),确保在租约过期前不会选举出新leader
- leaseReadIndex = commitIndex:记录当前已提交日志,读操作必须等待状态机应用到这个索引
阶段4:客户端读请求,执行LeaseRead
Go
// src/mnet/protocol.go:checkLeaseRead()
func checkLeaseRead(rf *raft.Raft, safeWrite func([]byte)) bool {
// Step 1: 检查是否是 Leader
if !rf.IsLeader() {
sendRESPResponse(safeWrite, "error", "ERR not leader")
return false
}
// Step 2: 检查租约是否有效
if !rf.IsLeaseValid() {
sendRESPResponse(safeWrite, "error", "ERR lease expired")
return false
}
// Step 3: 获取 ReadIndex
readIndex := rf.GetLeaseReadIndex()
// Step 4: 等待状态机应用到 ReadIndex
if !rf.WaitForApplied(readIndex) {
sendRESPResponse(safeWrite, "error", "ERR wait for apply timeout")
return false
}
return true // 可以安全读取本地状态机
}阶段5:IsLeaseValid()检查租约
Go
// src/raft/raft.go:IsLeaseValid()
func (rf *Raft) IsLeaseValid() bool {
state := rf.getLeaseState()
if state == nil {
return false
}
return state.IsLeader && time.Now().Before(state.LeaseExpiration)
}关键点:
- 使用atomtic.Load()读取,无需加锁
- 检查两个条件:是leader + 租期未过期
阶段6:WaitForApplied()等待日志应用
Go
// src/raft/raft.go:WaitForApplied()
func (rf *Raft) WaitForApplied(index int) bool {
timeout := time.After(100 * time.Millisecond)
for {
rf.mu.Lock()
applied := rf.lastApplied
rf.mu.Unlock()
if applied >= index {
return true // 已应用到目标索引
}
select {
case <-time.After(1 * time.Millisecond):
continue // 继续轮询
case <-timeout:
return false // 超时
}
}
}关键点:
- 轮询检查lastApplied >= readIndex
- 超时时间100ms,防止无限等待
- 每次检查释放锁,避免阻塞其他操作
4 Lease Read算法问题及解决方案
4.1 问题
然而,其实在市面上很多成熟生产级的raft的框架几乎都不使用Lease Read算法进行优化。其原因是Lease Read算法有一个很致命的缺陷 ------ 其固有的时钟漂移问题。
什么是时钟漂移?简单而言,时钟漂移是指每台机器的物理时钟以略微不同的速率运行。每台机器的时间流逝速率不同,导致它们对"相同时间长度"的感知不同。在我的代码中的实现:
Go
func (rf *Raft) updateLease() {
now := time.Now() // ← 使用的是 wall clock(墙上时钟)
rf.leaseExpiration = now.Add(rf.leaseDuration)
// ...
}
func (rf *Raft) IsLeaseValid() bool {
return state.IsLeader && time.Now().Before(state.LeaseExpiration) // ← 比较的是 wall clock
}问题: time.Now() 是墙上时钟,会受 NTP 同步、闰秒、用户手动调整等影响。如果 Leader 的时钟比 Follower 快,可能出现:
Go
Leader 时钟: 10:00:00(实际 09:59:55)
Follower 时钟: 09:59:55(正确时间)
Leader 更新 Lease: expiration = 10:00:00 + 400ms = 10:00:00.400
Leader 在 10:00:00.200 认为 Lease 仍然有效
但此时实际时间只过了 200ms,Follower 的选举超时还没到期
如果网络分区,Follower 可能在 09:59:56 开始选举(已经过了 1s 选举超时)
新 Leader 在 09:59:57 选出
此时旧 Leader 在 10:00:00.200 仍然认为自己是合法 Leader,继续服务读请求
→ 双 Leader,脏读!这在实验/教学环境下可以成立,但生产环境不成立。因此,越来越多成熟的raft框架放弃lease Read,因为时钟漂移不可避免
- ✅ 时钟漂移是物理现象,无法完全消除
- ✅ 即使使用 NTP,也只能减少,不能消除
- ✅ 在关键系统中,不能依赖时钟同步假设
- ✅ etcd 选择安全性优先,使用不依赖时钟的算法
或者也可以像 Google Spanner 那样投入巨大成本来严格控制时钟误差,但是这并不划算。因此,对于大多数系统来说,像 etcd 这样选择更安全的算法是更实际的选择。
4.2 解决方案
那么对于我这个简易的系统,我是否也可以进行优化呢?
方案 1:使用单调时钟(Monotonic Clock)
Go 1.9+ 的 time.Time 内部同时包含 wall clock 和 monotonic clock。使用 time.Since() 可以自动使用 monotonic clock:
Go
// 生产级实现
type Raft struct {
leaseStartTime time.Time // 使用 monotonic clock
leaseDuration time.Duration
}
func (rf *Raft) updateLease() {
rf.leaseStartTime = time.Now() // Now() 包含 monotonic reading
rf.leaseReadIndex = rf.commitIndex
}
func (rf *Raft) IsLeaseValid() bool {
// time.Since 优先使用 monotonic clock,不受 wall clock 调整影响
return time.Since(rf.leaseStartTime) < rf.leaseDuration
}方案 2:基于心跳计数器的 Lease(完全避免时钟)
Go
type Raft struct {
heartbeatSuccessCount int32 // 连续心跳成功次数
requiredHeartbeats int32 // 需要连续成功多少次才算有效 Lease
}
func (rf *Raft) updateLease() {
atomic.AddInt32(&rf.heartbeatSuccessCount, 1)
}
func (rf *Raft) IsLeaseValid() bool {
return atomic.LoadInt32(&rf.heartbeatSuccessCount) >= rf.requiredHeartbeats
}
// 心跳失败或变为 Follower 时重置
func (rf *Raft) resetLease() {
atomic.StoreInt32(&rf.heartbeatSuccessCount, 0)
}优点:完全不依赖时钟,只依赖事件(心跳成功次数)。
方案 3:ReadIndex 回退(早期etcd 实际采用)
etcd 的 LeaseRead 有一个安全兜底:
Go
func (rf *Raft) checkLeaseRead() bool {
// 1. 先检查 Lease(快速路径)
if rf.IsLeaseValid() {
return true
}
// 2. Lease 过期,回退到 ReadIndex(慢速路径,但安全)
return rf.readIndexFallback()
}
func (rf *Raft) readIndexFallback() bool {
// 发送心跳确认自己是 Leader
// 等待心跳成功
// 返回
}优点:Lease 有效时走快速路径,Lease 有问题时回退到安全的 ReadIndex。
5 成熟raft框架对于线性一致性读的实现
Lease Read 算法理论上可以优化 ReadIndex 的性能问题,因为它避免了每次读操作的心跳确认开销。但是,Lease Read 的安全性建立在时钟同步假设上,而时钟漂移在分布式系统中是难以完全避免的问题。etcd 作为 Kubernetes 等关键系统的元数据存储,选择了安全性优先的策略,使用更安全的 ReadIndex 算法,并通过批量处理、流水线优化、Follower Read 等机制来提升性能,而不是依赖有时钟安全风险的 Lease Read。
本小节只做一些初步的框架的理解,不涉及源码的解读。有关源码的实现可以看etcd或者tidb的相关源码:
ETCD:https://github.com/etcd-io/etcd
TIDB:https://github.com/pingcap/tidb
5.1 etcd
etcd-raft通过一种称为ReadIndex的机制来实现线性一致读,其基本原理也很简单:
- 心跳消息是特殊的 Raft 消息,用于确认 Leader 身份
- Leader 需要等待多数派(n/2 + 1)节点的响应
- 如果收到多数派响应 → Leader 确认自己仍是合法 Leader
- 如果未收到多数派响应 → Leader 知道自己可能已经不是 Leader,拒绝读请求
与 Lease Read 的本质区别
- ReadIndex:
- 每次读都需要一次心跳确认
- 不依赖时钟,只依赖消息传递
- 更安全,适合时钟不可靠环境
- Lease Read:
- 在租约有效期内无需心跳确认
- 依赖时钟同步假设
- 性能更好,但有时钟漂移风险
简单来说,所谓lease Read算法是在牺牲安全性的前提下提高读性能 的一种方法,etcd其实也支持lease Read的算法,但是对于绝大多数生产环境,保持 ETCD 默认的 ReadOnlySafe(ReadIndex)模式即可,它在保证线性一致性的同时提供了足够的性能。只有在特定优化场景且能严格控制时钟同步时,才考虑使用 ReadOnlyLeaseBased。
5.2 tidb
对于tidb关于线性一致性读的实现可能相对来说更加复杂,关于tidb的事务系统目前作者的理解还不是很深刻,以后有时间会进一步的研究tidb的底层实现细节,这里就简单的进行阐述。
TiDB 采用 TSO(Timestamp Oracle) + Percolator 事务模型 实现线性一致性读。其核心原理:通过中心化的 TSO(Timestamp Oracle)服务分配全局单调递增的时间戳,建立全序关系,结合 MVCC(多版本并发控制)保证读操作能看到一致的数据快照。
TiDB 线性一致性读核心:
- TSO 全局时间戳:中心化服务分配单调递增时间戳
- Percolator 事务模型:基于 MVCC 和两阶段提交
- MVCC 多版本:按时间戳版本读取数据,保证快照隔离
- 灵活的读一致性:支持强一致性读和 Follower Read
5.3 区别
| 维度 | ETCD | TiDB |
|---|---|---|
| 基础机制 | Raft 共识 | 全局时间戳排序 |
| 时钟依赖 | ReadIndex 不依赖,LeaseRead 依赖 | 不依赖节点时钟,依赖中心 TSO |
| 读扩展性 | 有限(依赖 Leader) | 好(支持 Follower Read) |
| 数据模型 | Key-Value | 关系型(SQL) |
| 适用场景 | 元数据、协调服务 | 业务数据、复杂查询 |
6 附录
测试结果:
| 指标 | 直接读取Leader状态机 (leaseRead) | Raft一致性读 (每次走Raft协议) | 最终一致性读 (任意节点读取) |
| 总请求数 | 10,000 | 10,000 | 10,000 |
| 总耗时 | 596.11ms | 54.04s | 629.24ms |
| 吞吐量 (req/s) | 16,775.42 | 185.05 | 15,892.23 |
| 平均延迟 | 560.53μs | 53.72ms | 586.89μs |
| 最小延迟 | 80.56μs | 5.25ms | 79.35μs |
| 最大延迟 | 22.98ms | 161.24ms | 21.46ms |
| P95延迟 | 1.61ms | 99.36ms | 1.69ms |
| P99延迟 | 5.06ms | 120.49ms | 5.80ms |
| 错误数 | 0 | 0 | 0 |
|---|
可以看出:
-
Raft 一致性读在我的实现中采用了最严格的模式:每个读请求会包装为一个日志条目,经过磁盘持久化、多数派提交、状态机应用后才能返回。这引入了磁盘 fsync 和网络 RPC 的延迟,在我的测试环境下单次约 50ms,因此吞吐只有 185 QPS。
-
Lease Read 只需要 Leader 确认租约有效(本地内存检查),然后直接读本地状态机。它完全绕过了磁盘 I/O 和网络交互,因此延迟降低到微秒级,吞吐接近单机状态机的极限。