摘要:遗传算法(Genetic Algorithm, GA)不是简单地"随机试很多次",而是一套围绕"编码、评价、选择、重组、扰动"展开的自适应概率搜索框架。它适合处理不可导、多峰、约束复杂、搜索空间巨大的优化问题。进一步地,当问题从单目标扩展到多目标时,所谓"最优解"不再是一个点,而是一组互不支配的 Pareto 最优解。本文把遗传算法、约束处理、选择压力、多目标排序和模式理论串成一条主线:遗传算法如何在编码空间中积累有价值的信息,并逐步逼近高质量解集。
第一部分:从优化问题说起,为什么需要遗传算法
优化问题的本质,是在一堆候选方案中找到更好的方案。单目标优化比较直接:如果目标是最大化收益,就找收益最高的解;如果目标是最小化成本,就找成本最低的解。传统优化方法常常依赖函数的连续性、可导性、凸性或梯度信息,这在规则清楚、函数形态良好的问题中很有效。
但工程问题经常不那么理想。目标函数可能不可导,甚至没有显式表达式;搜索空间可能非常大;局部最优点可能很多;约束条件还可能让大量候选解变得不合法或不可行。此时,如果仍然只沿着梯度方向走,很容易卡在局部最优,或者根本没有梯度可用。
遗传算法的切入点不同。它不要求知道目标函数怎么求导,只要求能够给一个候选解打分。算法把候选解看成"个体",把一批个体组成"种群",通过适应度评价决定哪些个体更值得保留,再通过交叉和变异产生新个体。它属于一种自适应概率搜索技术,既不是盲目随机,也不是严格确定性搜索,而是在随机扰动中加入选择压力。
遗传算法的优势可以概括为三点。第一,它只依赖目标函数值,对问题本身的数学形式依赖较小。第二,它天然是种群搜索,多个个体并行探索不同区域,不容易只盯着一个点。第三,它能够通过交叉和变异不断重组已有信息,把局部优秀结构组合成更好的整体解。
第二部分:遗传算法的第一件事,是把现实解变成可进化的染色体
遗传算法并不直接操作现实问题中的变量,而是操作变量的编码。现实问题中的解所在空间叫解空间,编码后形成的染色体所在空间叫编码空间。编码做得好,算法的搜索就顺;编码做得差,交叉和变异可能频繁制造无意义个体。
以二进制编码为例,若变量 xjx_jxj 的取值范围是 aj,bja_j,b_jaj,bj,并要求精度为 10−410^{-4}10−4,则二进制位数 mjm_jmj 需要满足:
2mj−1<(bj−aj)×104≤2mj−1 2^{m_j-1} < (b_j-a_j)\times 10^4 \le 2^{m_j}-1 2mj−1<(bj−aj)×104≤2mj−1
二进制子串映射成实数变量的公式为:
xj=aj+decimal(substringj)2mj−1(bj−aj) x_j=a_j+\frac{\operatorname{decimal}(\operatorname{substring}_j)}{2^{m_j}-1}(b_j-a_j) xj=aj+2mj−1decimal(substringj)(bj−aj)
这里的 decimal(substringj)\operatorname{decimal}(\operatorname{substring}_j)decimal(substringj) 表示第 jjj 个变量对应二进制子串的十进制值。这个过程完成了从"基因型"到"表现型"的转换。
编码方式可以按符号分为二进制编码、实数编码、整数排列编码、一般数据结构编码;按结构分为一维编码和多维编码;按长度分为固定长度编码和可变长度编码;按内容分为只编码解,或同时编码"解 + 参数"。这不是形式分类,而是直接影响搜索质量。
编码还必须考虑三个核心问题:
- 合法性:染色体是否能表示问题中的一个解。
- 可行性:解码后的解是否满足约束、落在可行域中。
- 映射唯一性:染色体与解之间的映射是否清晰、稳定。
合法性不等于可行性。一个染色体可能能解码成问题中的一个方案,但该方案违反约束,所以是合法但不可行。面对交叉、变异产生的不合法或不可行解,常见处理方式有修复、拒绝、惩罚项。进化算法求解约束优化问题时,外罚函数法很常见,因为它不要求初始群体全部可行,而且某些不可行解可能携带靠近最优区域的信息。经验上,依赖"不可行解到可行域距离"的罚函数,通常优于只统计违反约束条数的罚函数。
第三部分:一轮进化到底发生了什么
遗传算法的一轮迭代可以理解为五件事:初始化、评估、选择、交叉、变异。
初始化就是生成第一批候选解。方法可以完全随机,也可以根据先验知识构造。种群规模太小,保留的信息不足,容易早熟收敛;种群规模太大,计算成本又会变高。种群规模本质上是在"信息多样性"和"计算量"之间做平衡。
评估依赖适应度函数。适应度越高,个体越可能留下来。对最大化问题,目标函数通常可以直接作为适应度函数;对最小化问题,需要把目标函数变换成"越大越好"的形式。适应度函数的选择会影响收敛速度,也会影响算法能否找到真正有价值的解。
轮盘赌选择是最典型的概率选择。设种群总适应度为:
F=∑k=1popSizeeval(vk) F=\sum_{k=1}^{popSize}eval(v_k) F=k=1∑popSizeeval(vk)
染色体 vkv_kvk 的选择概率为:
pk=eval(vk)F p_k=\frac{eval(v_k)}{F} pk=Feval(vk)
累积概率为:
qk=∑j=1kpj q_k=\sum_{j=1}^{k}p_j qk=j=1∑kpj
随机生成 r∈0,1r\in0,1r∈0,1,若 qk−1<r≤qkq_{k-1}<r\le q_kqk−1<r≤qk,就选择第 kkk 条染色体。因为每个个体在轮盘上占据的区间长度正好等于 pkp_kpk,所以适应度越高,被选中的概率越大。
交叉模拟基因重组。单点交叉随机选择两个父代,再随机选一个切点,交换切点之后的片段,生成子代。伪代码如下:
text
Algorithm: One-cut Point Crossover
input: crossover probability pc, parent P_k, k = 1, 2, ..., popSize
output: offspring C
for k <- 1 to floor(popSize / 2) do
if pc >= random[0, 1] then
repeat
i <- random[1, popSize]
j <- random[1, popSize]
until i != j
p <- random[1, l - 1]
C_i <- P_i[1:p-1] // P_j[p:l]
C_j <- P_j[1:p-1] // P_i[p:l]
end if
end for变异负责引入新信息。按位变异会遍历染色体每一位,并以概率 pMp_MpM 翻转该位;单点随机变异则先判断整条染色体是否触发变异,触发后随机选择一个基因位翻转。变异概率过低,种群缺乏探索;变异概率过高,算法会接近随机搜索。
完整流程可以概括为:
text
initialize P(t)
fitness eval(P)
while not termination condition:
crossover P(t) to yield C(t)
mutation C(t)
fitness eval(C)
select P(t+1) from P(t) and C(t)
t <- t + 1
output best solution第四部分:真正难的是选择压力与多样性的平衡
遗传算法不是单纯"保留最强者"就能成功。如果选择压力太弱,优秀个体无法被放大,搜索效率低;如果选择压力太强,早期的某个优秀个体会迅速统治种群,导致早熟收敛。算法的核心不是一味追求强选择,而是在竞争和多样性之间保持平衡。
一次随机采样(SUS)就是为了降低轮盘赌的随机波动。标准轮盘赌选择 NNN 个个体时,要独立转动 NNN 次轮盘;SUS 只生成一次随机数,然后设置 NNN 个等距指针。指针间距为:
d=1N d=\frac{1}{N} d=N1
第 kkk 个指针位置为:
pk=r+(k−1)d,k=1,2,...,N p_k=r+(k-1)d,\quad k=1,2,\dots,N pk=r+(k−1)d,k=1,2,...,N
这种方法让实际选中次数更接近期望值。
确定性选择更直接。(μ+λ)(\mu+\lambda)(μ+λ)-selection 从 μ\muμ 个父代和 λ\lambdaλ 个子代合并后的 μ+λ\mu+\lambdaμ+λ 个体中选出最好的 μ\muμ 个,父代中的优秀个体可以继续保留,因此选择压力更大。(μ,λ)(\mu,\lambda)(μ,λ)-selection 只从 λ\lambdaλ 个子代中选出最好的 μ\muμ 个,选择压力相对较小。精英选择则会在最优个体未被比例选择选中时强制保留。
竞赛选择兼具随机性和确定性。每次随机抽取 ttt 个个体,返回其中最好的一个。ttt 越大,选择压力越强;t=2t=2t=2 时就是二元竞赛选择。
除了选择方式,适应度变换也会调节竞争强度。例如线性变换:
fk′=afk+b f'_k=af_k+b fk′=afk+b
归一化变换:
fk′=fk−fmin+γfmax−fmin+γ f'k=\frac{f_k-f{min}+\gamma}{f_{max}-f_{min}+\gamma} fk′=fmax−fmin+γfk−fmin+γ
Boltzmann 变换:
fk′=efk/T f'_k=e^{f_k/T} fk′=efk/T
这些变换的作用,是避免适应度差距过小导致竞争不足,也避免差距过大导致早熟。
适应度共享进一步从"多样性"角度控制种群。它会惩罚过度聚集的个体,让种群分散到多个有潜力的区域。共享函数常写为:
Sh(d)={1−(dσshare)α,d<σshare0,otherwise Sh(d)= \begin{cases} 1-\left(\dfrac{d}{\sigma_{share}}\right)^\alpha, & d<\sigma_{share}\\ 0, & otherwise \end{cases} Sh(d)=⎩ ⎨ ⎧1−(σshared)α,0,d<σshareotherwise
个体 iii 的小生境计数为:
mi=∑j=1popSizeSh(dij) m_i=\sum_{j=1}^{popSize}Sh(d_{ij}) mi=j=1∑popSizeSh(dij)
共享适应度为:
fi′=fimi f'_i=\frac{f_i}{m_i} fi′=mifi
小生境半径越大,对聚集个体的惩罚越强。这个思想在多目标优化中尤其重要,因为我们不希望所有个体挤在 Pareto 前沿的一个小角落。
第五部分:从单目标到多目标,最优解变成了 Pareto 前沿
单目标优化中,最优解可以直接比较:谁的目标函数更好,谁就更优。多目标优化则不同。一个方案可能成本低但速度慢,另一个方案速度快但成本高。它们之间没有绝对优劣,只能讨论是否支配。
若不存在另一个点能在所有目标上都优于某点,则该点是非支配点。决策空间中对应这些非支配点的解,称为 Pareto 最优解、有效解或非劣解。所有非支配点组成的集合,就是 Pareto 前沿。
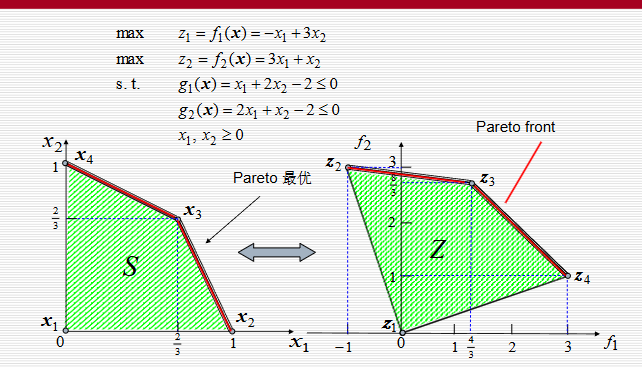
遗传算法扩展到多目标优化时,目标从"找到一个最好个体"变成"找到一组尽量逼近 Pareto 前沿且分布均匀的解"。因此,多目标遗传算法需要同时解决两件事:排序和多样性。
Goldberg 方法的思路是分层排序。首先找出所有非支配个体,赋予 Rank 1;然后移除这些个体,在剩余个体中继续找非支配个体,赋予 Rank 2;如此循环直到整个种群完成排序。
moGA 根据支配关系给个体赋等级。非支配染色体为 Rank 1;其他个体的等级与支配它的个体数量有关,通常是"支配它的个体数量 + 1"。平局可以通过随机选择打破。
NSGA 则在非支配排序基础上强调多样性。第一层非支配个体先获得较大的虚拟适应度,再通过共享机制削弱拥挤区域的繁殖优势;然后忽略第一层个体,继续识别第二层非支配前沿,并赋予较小的虚拟适应度。这个过程持续到整个种群被划分到多个前沿中。
随机余数比例选择可进一步降低采样误差。先计算个体理论期望复制次数:
Ei=N⋅fi∑j=1Nfj E_i=N\cdot\frac{f_i}{\sum_{j=1}^{N}f_j} Ei=N⋅∑j=1Nfjfi
把整数部分 ⌊Ei⌋\lfloor E_i\rfloor⌊Ei⌋ 作为确定性复制次数,余数部分再进行随机抽样。这样既能保证高适应度个体获得基本生存权,也能保留一定随机性。不过如果早期出现超级个体,它也可能被过度复制,引发早熟收敛。
第六部分:模式理论解释遗传算法为什么能积累有效信息
到这里,遗传算法的操作层已经清楚:编码、选择、交叉、变异。但还有一个更深的问题:为什么这些操作不是乱改字符串,而能逐步积累有用信息?模式理论给出了一个解释。
个体是由 000 和 111 构成的二进制串。模式则由 000、111 和通配符 * 构成。通配符表示该位置不限制取值。例如 1*0** 表示第一位为 1、第三位为 0 的所有个体。
模式阶 o(s)o(s)o(s) 是模式中明确字符的个数。模式定义长度 δ(s)\delta(s)δ(s) 是最后一个明确字符位置与第一个明确字符位置之差。直观上,低阶模式限制少,短定义长度模式跨度小,不容易被交叉破坏。
对于长度为 lll 的二进制字符串,未确定字符串可形成的模式总数为:
3l=(2+1)l 3^l=(2+1)^l 3l=(2+1)l
而某一条已经确定的二进制字符串所含模式数最多为:
2l 2^l 2l
设第 ttt 代中属于模式 sss 的个体数量为 m(s,t)m(s,t)m(s,t),该模式平均适应度为 fˉ(s)\bar f(s)fˉ(s),群体平均适应度为 Fˉ\bar FFˉ。复制操作后:
m(s,t+1)=m(s,t)⋅fˉ(s)Fˉ m(s,t+1)=m(s,t)\cdot\frac{\bar f(s)}{\bar F} m(s,t+1)=m(s,t)⋅Fˉfˉ(s)
如果 fˉ(s)>Fˉ\bar f(s)>\bar Ffˉ(s)>Fˉ,该模式数量增长;反之减少。若 fˉ(s)=Fˉ(1+c)\bar f(s)=\bar F(1+c)fˉ(s)=Fˉ(1+c),则:
m(s,t+1)=m(s,1)(1+c)t m(s,t+1)=m(s,1)(1+c)^t m(s,t+1)=m(s,1)(1+c)t
说明高于平均适应度的模式会以指数形式增加。
交叉会破坏定义长度较长的模式。模式被破坏的概率近似为:
Pd=δ(s)l−1 P_d=\frac{\delta(s)}{l-1} Pd=l−1δ(s)
若交叉概率为 pcp_cpc,模式存活概率下限为:
1−pcδ(s)l−1 1-p_c\frac{\delta(s)}{l-1} 1−pcl−1δ(s)
变异会破坏明确位较多的模式。模式存活概率为:
(1−pm)o(s) (1-p_m)^{o(s)} (1−pm)o(s)
当 pm≪1p_m\ll1pm≪1 时:
(1−pm)o(s)≈1−pmo(s) (1-p_m)^{o(s)}\approx1-p_mo(s) (1−pm)o(s)≈1−pmo(s)
综合复制、交叉、变异,可得到模式定理的基本形式:
m(s,t+1)≥m(s,t)fˉ(s)Fˉ(1−pcδ(s)l−1−pmo(s)) m(s,t+1)\ge m(s,t)\frac{\bar f(s)}{\bar F} \left(1-p_c\frac{\delta(s)}{l-1}-p_mo(s)\right) m(s,t+1)≥m(s,t)Fˉfˉ(s)(1−pcl−1δ(s)−pmo(s))
这说明:短定义长度、低阶、平均适应度高于群体平均适应度的模式,更容易在遗传算法中被保留下来并快速增长。这就是遗传算法能够积累"好基因块"的理论基础。
第七部分:重新理解遗传算法
遗传算法不是把生物概念生搬硬套到计算机中,也不是简单随机试错。它的核心逻辑是:
编码让现实问题变成可演化的结构;适应度函数提供环境选择压力;选择放大优秀结构;交叉重组已有信息;变异引入新信息;适应度共享和多目标排序维持解集多样性;模式理论解释为什么优秀局部结构能被保留下来。
当问题是单目标时,遗传算法试图找到一个高质量解;当问题是多目标时,它试图逼近一整条 Pareto 前沿。理解这一点后,再看轮盘赌、SUS、NSGA、模式定理,就不会觉得它们是分散的知识点,而是同一个搜索框架中不同层面的机制:如何表示信息,如何筛选信息,如何重组信息,以及如何证明信息会被积累。