

🔥个人主页:代码不加冰(欢迎来访)
🎬作者简介:java后端学习者
❄️个人专栏:LeetCode刷题日记 ,苍穹外卖日记,SSM框架深入,JavaWeb,
✨命运的结局尽可永在,不屈的挑战却不可须臾或缺!
大家好,我是代码不加冰,今天刚刚考完六级,啥单词都不记得了,全靠蒙了,保佑我能及格吧,今天到了我们的每日刷题环节。
题目背景:
给定一个可包含重复数字的序列
nums,按任意顺序 返回所有不重复的全排列。示例 1:
输入:nums = [1,1,2] 输出: [[1,1,2], [1,2,1], [2,1,1]]示例 2:
输入:nums = [1,2,3] 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]提示:
1 <= nums.length <= 8-10 <= nums[i] <= 10
题目分析:
这道题的题目很简洁,是我们前面做过的全排列的变式,也是利用回溯算法来解决的,具体的差异让我们看看吧。
可以用一句话概括:46 题的输入数字"独一无二",而 47 题的输入数字"有重复",但两道题都要求最终的排列结果不能重复。
题目区别
为了更直观地理解,我们可以从以下三个维度来看它们的区别:
1. 输入与输出的对比
假设两道题的输入数组长度都为 3:
维度 第 46 题:全排列 (Permutations) 第 47 题:全排列 II (Permutations II) 输入数组 nums = [1, 2, 3](无重复数字)nums = [1, 1, 2](有重复数字)排列总数 3! = 6 种结果 只有 3 种结果(去重后) 最终答案 [[1,2,3], [1,3,2], [2,1,3], [2,3,1], [3,1,2], [3,2,1]][[1,1,2], [1,2,1], [2,1,1]]2. 决策树(搜索空间)的区别
第 46 题 :因为每个数字都不同,只要保证在同一条路径上不重复使用同一个位置的数字 即可(代码里用一个简单的
used数组或contains()就能搞定)。第 47 题 :因为有重复数字(比如两个
1),如果像 46 题那样直接去搜,就会出现两条一模一样的路径(比如"第一个 1 配合 2"和"第二个 1 配合 2")。这就需要剪枝,把重复的分支在萌芽状态就砍掉。3.代码实现上的区别
两道题都使用回溯法,但第 47 题多了两处关键改动
// ======= 区别 1:47 题必须先排序 ======= Arrays.sort(nums);为什么要排序 只有让相同的数字挨在一起(比如
[1, 1, 2]),我们才能在遍历到第二个1时,轻易地通过nums[i] == nums[i-1]发现它和前一个数字重复了。
// ======= 区别 2:47 题多了核心剪枝条件 ======= if (i > 0 && nums[i] == nums[i - 1] && !used[i - 1]) { continue; }这行代码在干嘛, 当我们准备选择当前的
nums[i]时,如果发现它和前一个数字nums[i-1]一样,并且!used[i-1](意味着前一个1在当前层已经被用过并撤销了),那就说明以这个数字开头的排列我们刚才已经完全穷举过了 。为了避免创造出重复的兄弟分支,直接continue跳过。
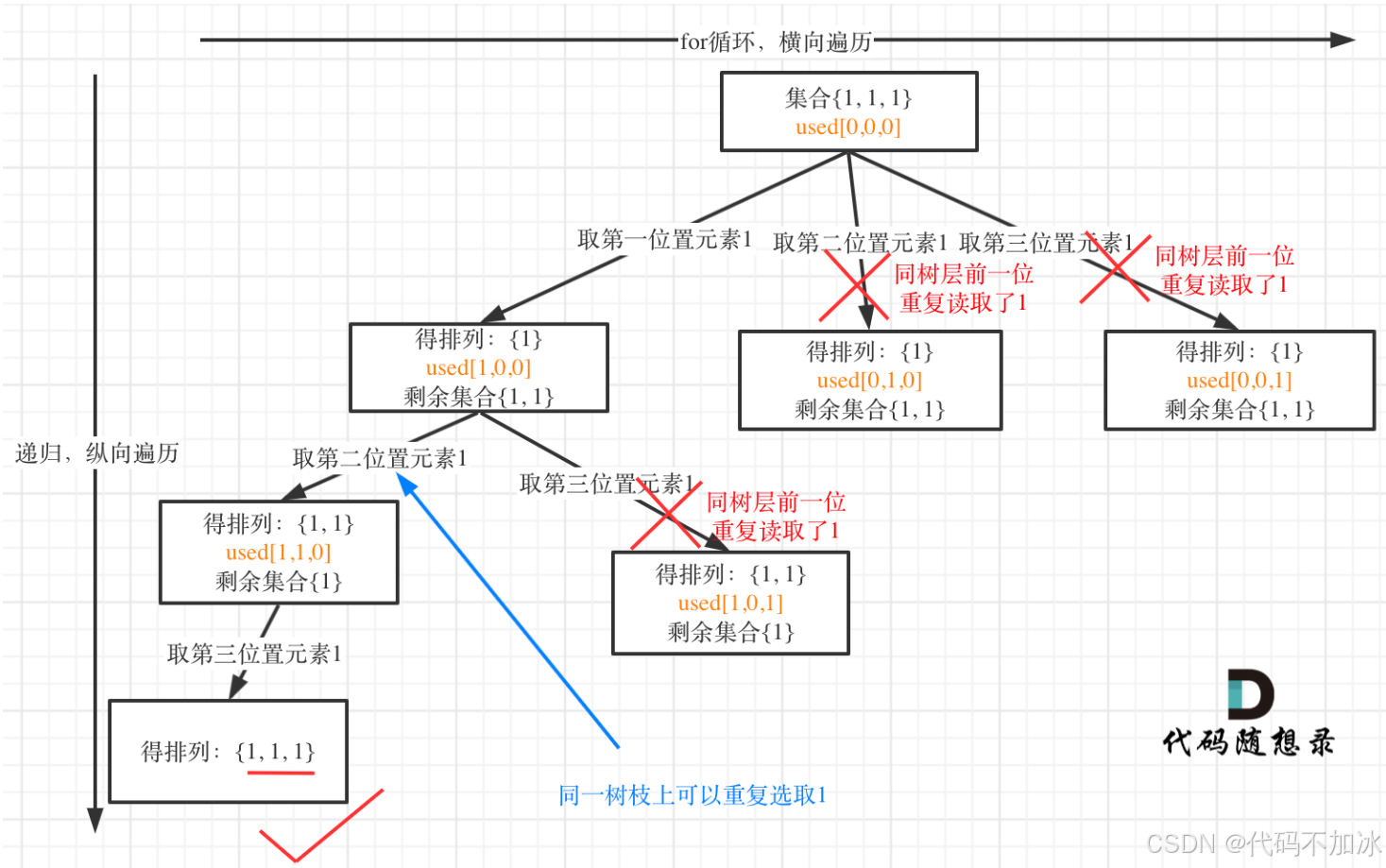
核心去重代码
关键的剪枝代码就是这一行:
if (i > 0 && nums[i] == nums[i - 1] && !used[i - 1]) { continue; }注意这里的
!used[i - 1],它是实现树层去重的灵魂。为什么
used[i - 1]是去树层当满足
nums[i] == nums[i - 1]时,有两种情况:情况 A:
used[i - 1] == true(树枝上重复,不剪枝)这意味着
nums[i - 1](前一个 1)已经被选过了,并且现在正处于递归的更深层(也就是在同一条树枝上)。
- 合法性 :这是合法的!因为我们要凑出
[1, 1, 2]这样的排列,第一个1和第二个1同时出现在一条路径里是完全没问题的。所以这时候!used[i - 1]为false,不会触发continue,程序继续向下搜索。情况 B:
used[i - 1] == false(树层上重复,必须剪枝)这意味着
nums[i - 1](前一个 1)现在是空闲的。
为什么它是空闲的? 因为它刚刚被使用完,并且在回溯的过程中被撤销了选择 (
used[i - 1]被重新置为了false)。场景还原:在决策树的第一层:
我们先选了第一个
1(nums[0]),一路向下递归,拿到了所有以第一个1开头的排列(比如[1, 1, 2],[1, 2, 1])。接着,我们回溯,把第一个
1释放掉,此时used[0]变回false。循环继续,
i移到了第二个1(nums[1])。此时,nums[1] == nums[0]成立,且used[0] == false。这就触发了剪枝。 因为如果允许选择第二个
1开头,那么后续必定会复制出一套一模一样的[1, 1, 2]分支。我们来看看这个过程的直观对比:
一句话总结 : 如果
used[i - 1] == false,说明左边那个和自己一样的数字已经把属于它的所有排列情况都穷举完了。此时轮到你,你如果再上场,只会把人家走过的老路再走一遍,产生一堆一模一样的双胞胎答案,所以必须在这里把它拦截(剪枝)。
举例分析:
例子:
nums = [1, 1, 2](排序后还是[1, 1, 2])java
if (i > 0 && nums[i] == nums[i - 1] && !used[i - 1]) continue;
!used[i - 1]表示前一个相同元素在树层的同一层中没有被使用(也就是刚被回溯撤销过)。此时如果选了当前元素,就会产生和之前选前一个元素时完全相同的排列 → 跳过
初始状态
text
nums = [1a, 1b, 2] (a和b值相同,用来区分位置) used = [false, false, false]第一层(选第一个数)
i = 0 (1a)
used[0] = false,且前一个不存在 → 选择 1a状态:
path = [1a],used = [T, F, F]→ 进入下一层i = 1 (1b)(当 i=0 回溯回来后)
used[1]=false
nums[1]==nums[0]且!used[0]==true(因为 1a 在这一层 并没有被使用,它已经被撤销了)→ 被跳过 ✅ 这是去重的关键:避免同一层选 1b 产生
[1b,...]和[1a,...]重复i = 2 (2)
used[2]=false,且与前一个 1b 不同 → 选择 2状态:
path = [2],used = [F, F, T]→ 进入下一层第二层(路径 1a 时的下一层)
当前
path = [1a],used = [T, F, F]i = 0 →
used[0]=true跳过i = 1 (1b) →
used[1]=false, 前一个是 1a(值相同但 nums1!=nums0,值是相同的,但 i>0 && nums1==nums0 && !used0==false(used0 是 true)→ 不跳过,因为 !used0 为 false,所以这里允许选择 1b)✅ 选择 1b:
path=[1a,1b],used=[T,T,F]→ 下一层i = 2 (2) → 后面会选到
[1a,2]第三层(路径 1a,1b)
path=[1a,1b],used=[T,T,F]只剩 i=2 (2) 可选 →
path=[1a,1b,2]→ 收集结果[1,1,2]回溯后到
[1a],继续 i=2 选 2 →[1a,2],再选 1b →[1a,2,1b]→ 结果[1,2,1]回到第一层,处理 i=2 (2)
当
[1a]和[1b被跳过]都处理完后,回到第一层 i=2(初始第一层,不是子层)
used = [F,F,F]但之前第一层选过 1a,现在要选 2:选 2 →
path=[2],used=[F,F,T]→ 下一层在子层里,1a 和 1b 都可以选(不会重复,因为值相同但 used 条件不同)
产生
[2,1a,1b]→ 结果[2,1,1]
关于撤销的逻辑,还是有很多新手搞不明白的:
只要记住上面时候是递归的结束就可以了,因为递归结束return 之后,会返回到上一层递归函数中,执行上一层递归函数中 backtrack() 调用后面的代码(即撤销代码)。
还有一个树枝重复元素的处理,有两种写法:
可以直接
if (used[i] == false) {
used[i] = true;//标记同⼀树⽀nums[i]使⽤过,防止同一树枝重复使用
path.add(nums[i]);
backTrack(nums, used);
path.remove(path.size() - 1);//回溯,说明同⼀树层nums[i]使⽤过,防止下一树层重复
used[i] = false;//回溯
}也可以先判断:
// 如果当前数字已经被使用过,直接跳过
if (used[i]) {
continue;
}题目答案:
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class Solution {
public List<List<Integer>> permuteUnique(int[] nums) {
List<List<Integer>> res = new ArrayList<>();
if (nums == null || nums.length == 0) {
return res;
}
// 1. 必须先排序,这是去重的前提
Arrays.sort(nums);
// 记录数字是否被使用过
boolean[] used = new boolean[nums.length];
// 2. 开始回溯
backtrack(nums, used, new ArrayList<>(), res);
return res;
}
private void backtrack(int[] nums, boolean[] used, List<Integer> track, List<List<Integer>> res) {
// 触发结束条件:走完了一条完整的路径
if (track.size() == nums.length) {
res.add(new ArrayList<>(track));
return;
}
for (int i = 0; i < nums.length; i++) {
// 如果当前数字已经被使用过,直接跳过
if (used[i]) {
continue;
}
// 核心剪枝条件:去重
// nums[i] == nums[i - 1] 说明当前数字和上一个数字相同
// !used[i - 1] 说明上一个相同的数字在当前层已经被撤销/使用过了
if (i > 0 && nums[i] == nums[i - 1] && !used[i - 1]) {
continue;
}
// 做选择
track.add(nums[i]);
used[i] = true;
// 进入下一层决策树
backtrack(nums, used, track, res);
// 撤销选择(回溯)
used[i] = false;
track.remove(track.size() - 1);
}
}
}