论文: Qwen3-VL-Seg: Unlocking Open-World Referring Segmentation with Vision-Language Grounding
arXiv: 2605.07141v1
机构: 阿里巴巴通义实验室 (Tongyi Lab)
发布时间: 2026年5月8日

一、开篇:从"画框"到"描边"的鸿沟
想象一下这样的场景:你对 AI 说"请把图片里那个穿着米色帽子、背着蓝色背包的人分割出来"。现有的多模态大模型(MLLM)能精准地画出一个边界框告诉你"人在这儿",但当你需要像素级的精确轮廓------比如做图像编辑、机器人抓取、医学影像分析时------那个粗糙的矩形框完全不够用。
这就是 Open-World Referring Segmentation(开放世界指代分割) 要解决的问题:将不受约束的自然语言描述 grounding 到精确的像素级区域。
过去的方法走两条极端路线:
-
SAM 外挂派(LISA、GSVA):MLLM 出框,SAM 出 mask。效果好,但 SAM 带来巨大参数开销和部署复杂度。
-
原生轻量派(Text4Seg、UFO):直接在 MLLM 上加轻量分割头,但边界恢复能力差,"切不准"。
Qwen3-VL-Seg 的核心洞察 :MLLM 预测的边界框不是终点,而是一个语义 grounded 的结构先验 。与其把框扔掉再让 SAM 重猜,不如让框全程引导 mask 解码过程。基于此,作者设计了一个仅 17M 参数(占基础模型 0.4%)的轻量级 Box-Guided Mask Decoder,在 4B 参数规模上实现了超越 8B 模型的分割精度,且无需任何外部分割模型。
二、论文摘要翻译
开放世界指代分割要求将不受约束的语言表达锚定 到精确的像素级区域。现有的多模态大语言模型(MLLM)展现出强大的开放世界视觉定位能力,但其输出仍局限于稀疏的边界框坐标,不足以支持密集视觉预测。近期基于MLLM的分割方法要么直接预测稀疏轮廓坐标(难以重建连续物体边界),要么依赖Segment Anything Model(SAM)等外部分割基础模型,引入了显著的架构和部署开销。本文提出 Qwen3-VL-Seg,一个参数高效的框架,将MLLM预测的边界框视为语义锚定的 结构先验,并将其解码为像素级指代分割。其核心是一个轻量级的边界框引导的掩码解码器 ,结合多尺度空间特征注入、空间-语义查询构建、边界框引导的 高分辨率像素融合,以及迭代式掩码感知查询精炼,仅引入17M参数(约占基础模型的0.4%)。为支持可扩展的开放世界训练,构建了 SA1B-ORS------一个衍生自SA-1B的数据集,包含两个子集:SA1B-CoRS(类别导向样本)和SA1B-DeRS(描述性实例级样本)。为评估模型,我们策划了 ORS-Bench,一个经人工筛选的基准,包含分布内(ID)和分布外(OOD)子集,覆盖多种指代表达类型。大量实验表明,Qwen3-VL-Seg在封闭集和开放世界设定下均表现强劲,在语言密集型指令上优势显著,且具有强大的分布外泛化能力。通用多模态基准评估进一步表明,模型在面向分割的适配后仍广泛保持了通用多模态能力。
三、核心原理:Box 不是终点,而是先验
传统思路把 MLLM 的 box 输出当作"副产品"------模型既然要分割,那 box 就顺手预测一下。但 Qwen3-VL-Seg 反其道而行:Box 是 MLLM 对"目标在哪里"的最强语义-空间耦合表达,它同时携带了:
-
语义信息:框内的内容与语言描述对齐
-
空间信息:目标的位置、尺度、长宽比
-
实例身份:在复杂场景中区分不同实例
因此,作者提出边界框引导的掩码解码器**(Box-Guided Mask Decoding)** 范式:让边界框作为结构先验,贯穿 mask 解码的全过程------从查询构建、像素融合到迭代精炼。这相当于告诉解码器:"目标大概在这个区域,语义上是'那个人',请在这个约束下精细描边。"
四、架构深潜:四大模块的精密协作
整体架构如原文图1所示:
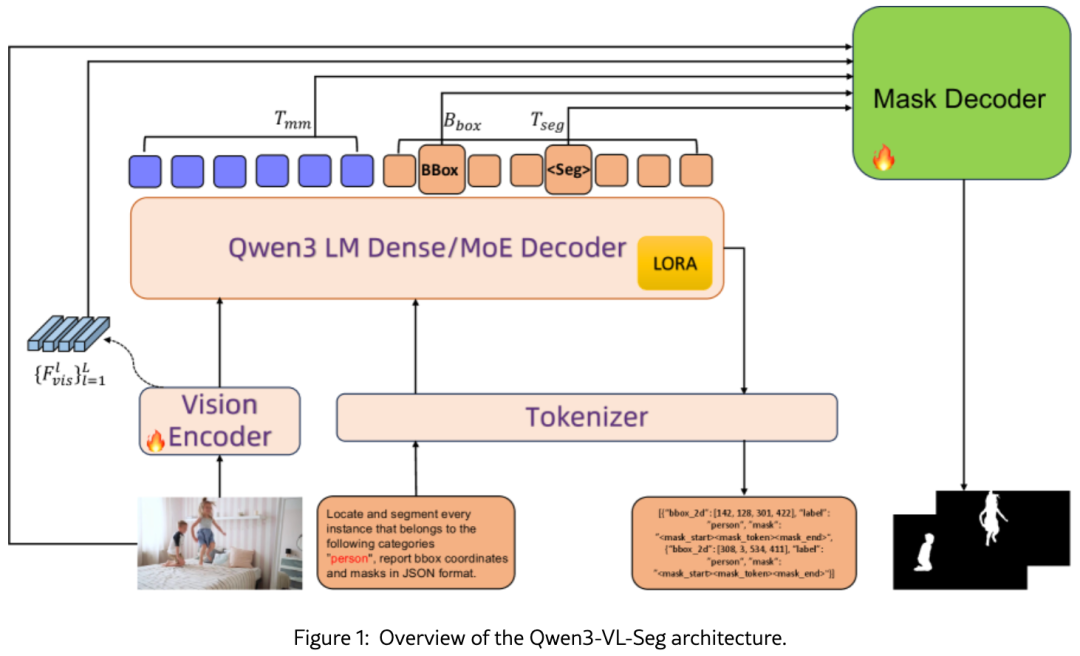
输入侧:图像经视觉编码器 Vision Encoder 提取多尺度视觉特征,文本经 Tokenizer 进入带 LoRA 微调的 Qwen3 语言稠密/专家解码器Qwen3 LM Dense/MoE Decoder。MLLM 输出四类信号:

解码侧:轻量级掩码解码器 Mask Decoder(仅 17M 参数)接收上述信号,执行粗到精的分割。
Decoder 的详细结构见图2,包含四个核心组件,下面逐一展开。
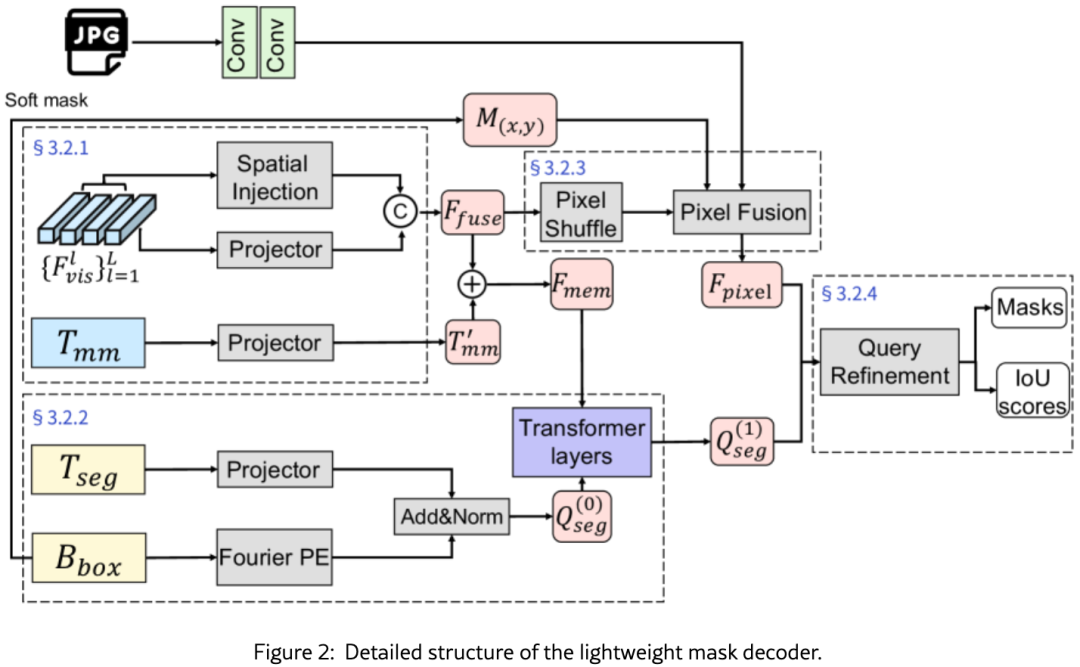
4.1 多尺度空间特征注入(Multi-scale Spatial Feature Injection)

这里 GELU 是高斯误差线性单元 Gaussian Error Linear Unit 激活函数,一种平滑的非线性激活,相比 ReLU 在负数区域仍有梯度,有助于稳定深层网络训练。DWConv 表示 Depthwise Convolution(深度可分离卷积),即对每个输入通道单独做空间卷积而不混合通道信息,计算量远低于标准卷积。GroupNorm 是 Group Normalization(组归一化),将通道分成若干组后在组内做归一化,对 batch 大小不敏感,适合小批量训练场景。s 是一个可学习的标量参数,初始值设为 10^−3,这个接近零的初始化使得适配器在微调初期近似于恒等映射,从而稳定优化过程,避免初始阶段对预训练特征的剧烈破坏。

最终的记忆特征由三部分相加得到:

4.2 空间-语义查询构建(Spatial-Semantic Query Construction)
目标查询 Object query 需要同时捕获目标的语义信息和实例级的空间身份。作者利用定位边界框作为显式的条件信号来构建查询。
设 MLLM 预测的边界框为:

初始对象查询由边界框编码和分割 token 特征融合得到:

最终,查询不再是仅依赖语言来"检索"目标,而是从一个已经 grounded 的空间先验出发,极大降低了在复杂场景中定位目标的难度。
4.3 Box 引导的高分辨率像素融合(Box-Guided High-Resolution Pixel Fusion)
为恢复精细的边界细节,模型从原始输入图像提取浅层卷积神经网络特征:

其中 I 表示输入图像,Stem 是轻量级的卷积主干网络,通常由几个卷积层和池化层组成,用于提取高分辨率但语义较浅的图像特征,这些特征保留了丰富的边缘和纹理信息。

其中 (x,y) 是特征图上的空间坐标。σ(⋅) 是 sigmoid 函数,将输入值压缩到 (0,1) 区间。α=20 控制门控边界的陡峭程度,值越大门控越接近硬阈值(类似阶跃函数),值越小过渡越平滑。四个 sigmoid 项分别控制左、右、上、下四个方向的衰减:当像素位于扩展框内部时,四个项都接近 1,门控值接近 1;当像素位于框外时,至少有一个项接近 0,门控值被抑制。若存在多个边界框,则取各框门控的空间最大值。
同时,融合后的视觉特征经两阶段 PixelShuffle 模块逐步上采样:

Upsample 表示上采样操作,PixelShuffle 是一种亚像素卷积上采样方法,通过将通道维度的像素重新排列到空间维度来实现高效上采样,避免传统插值带来的模糊。
最后将门控后的浅层特征与上采样视觉特征融合:

4.4 迭代 Mask 感知查询精炼(Iterative Mask-Aware Query Refinement)
第一遍预测后,模型利用初始 mask 对像素特征进行目标感知池化,提取精炼信号:

池化特征经投影后加回解码查询:

精炼后的查询用于第二遍 mask 预测:

这种"预测-反馈-再预测"的迭代循环,建立了查询预测与像素证据之间的显式交互,使模型能够修正初始 mask 的粗糙边界,逐步锐化物体轮廓。其工作方式类似于人类先圈出大致范围,再基于第一次描边的结果进行精细修正。
五、数据引擎:SA1B-ORS 与 ORS-Bench
好模型需要好数据。开放世界指代分割的最大瓶颈是缺乏大规模、多样化、语言-像素对齐的训练数据。
5.1 SA1B-ORS 训练集
从 SA-1B 的 200 万张原始图像中,作者构建了两个互补子集,总计 299 万样本:
| 子集 | 样本数 | 特点 | 构建流程 |
|---|---|---|---|
| SA1B-CoRS | 105万 | 类别导向,一个表达可指代同类多个实例 | 实例蒸馏 → 粗 mask 获取(Qwen3-VL-Plus + SAM2)→ 细 mask 合并 → MLLM 验证 → 指代标题生成 |
| SA1B-DeRS | 194万 | 描述性实例级,需属性/关系/上下文区分 | 指令策划(五维度:类别、属性、状态、相对位置、上下文关系)→ 认知验证(IoU>0.8 过滤)→ 显著性选择 |
图3 展示了两个子集的视觉对比,图4 和 图5 分别展示了 CoRS 和 DeRS 的构建流程。

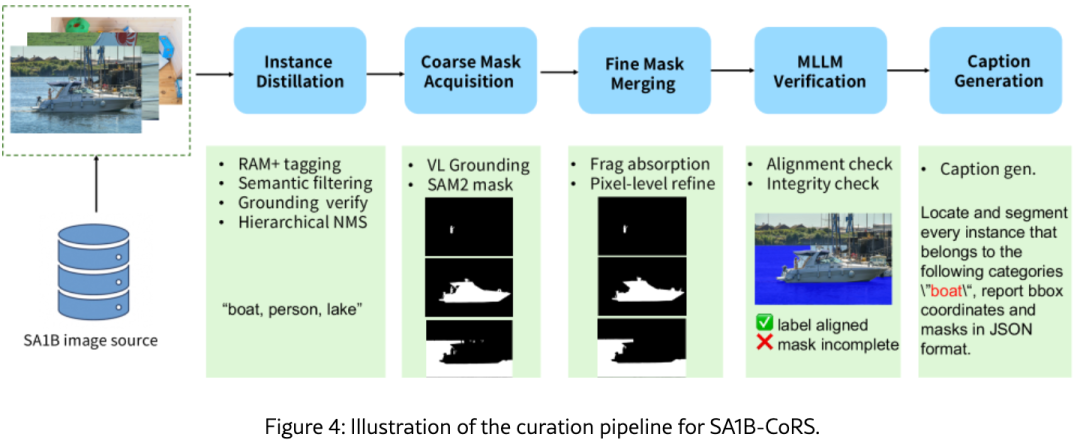
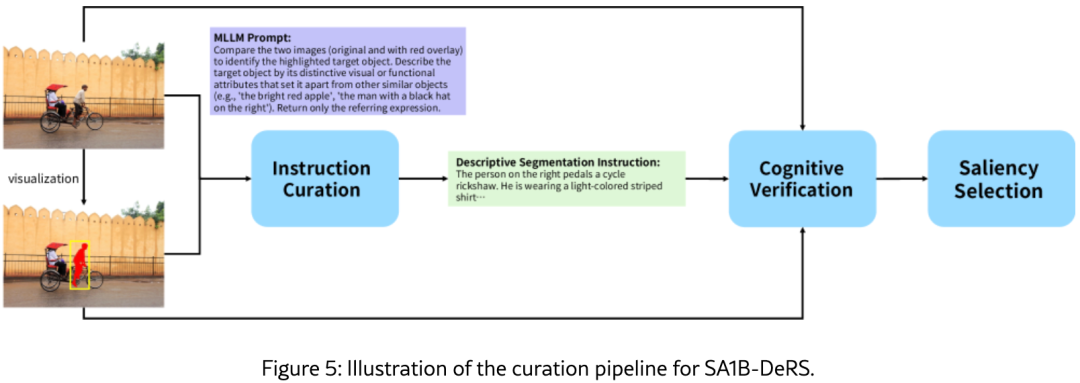
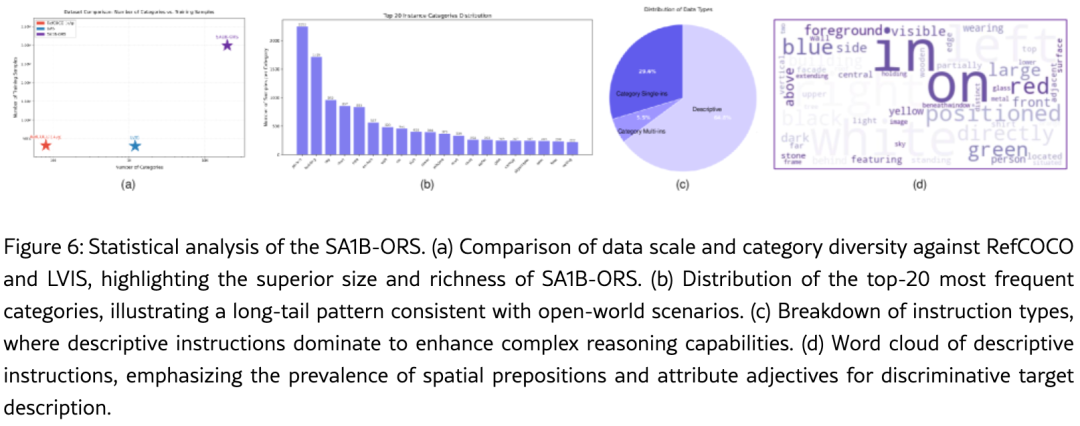
图6的统计分析显示,SA1B-ORS 在类别数量和样本规模上远超 RefCOCO 系列和 LVIS,且描述性指令占 64.8%,词云显示大量空间介词(in, above, left)和属性形容词(blue, dark, visible),确保数据集的开放世界特性。
5.2 ORS-Bench 评测基准
现有基准(RefCOCO 等)词汇封闭,无法评估真正的开放世界能力。作者构建:
-
ORS-ID-Bench(分布内):9,055 人工筛选样本,覆盖 4 种指令格式(单实例类别、多实例类别、短语级、描述性)
-
ORS-OOD-Bench(分布外):6 种分布偏移维度,每维约 200 个挑战性样本
-
类别偏移(Category)
-
实例尺度(Instance Scale)
-
指令复杂度(Instruction Complexity)
-
遮挡(Occlusion)
-
光照(Lighting)
-
风险敏感场景(Domain Risk,如自动驾驶、医学诊断)
-
六、实验条件与训练策略
6.1 两阶段训练
| 阶段 | 目标 | 训练设置 | 数据配比 |
|---|---|---|---|
| Stage 1 | 建立指代分割能力 | LLM 用 LoRA,视觉编码器 Vision Encoder 和掩码解码器 Mask Decoder 全可调 | RefCOCO 系列 + SA1B-ORS |
| Stage 2 | 恢复通用能力,保持分割性能 | 合并 Stage 1 LoRA 权重,大语言模型骨干 LLM backbone 和 掩码解码器 Mask Decoder 全微调,视觉编码器Vision Encoder 冻结 | 指代分割 : 通用多模态理解 : 多模态推理 = 3:1:2 |
Stage 2 中,推理数据通过 Qwen3-VL-Instruct 进行**离线蒸馏(off-policy distillation)**生成 STEM 聚焦数据。这种设计确保模型不会变成"只会分割的偏科生"。
6.2 评测指标
-
分割任务:mIoU(每样本平均 IoU)、cIoU(全局 IoU)、P@t(mask IoU 超过阈值 t∈{0.5,0.7,0.9} 的样本比例)
-
定位任务(REC):Prec@0.5(预测框与 GT IoU > 0.5 的比例)
-
多实例设置:匈牙利算法匹配预测与 GT mask 后计算指标
七、实验结果:硬核数据说话
7.1 封闭集指代分割(RES)
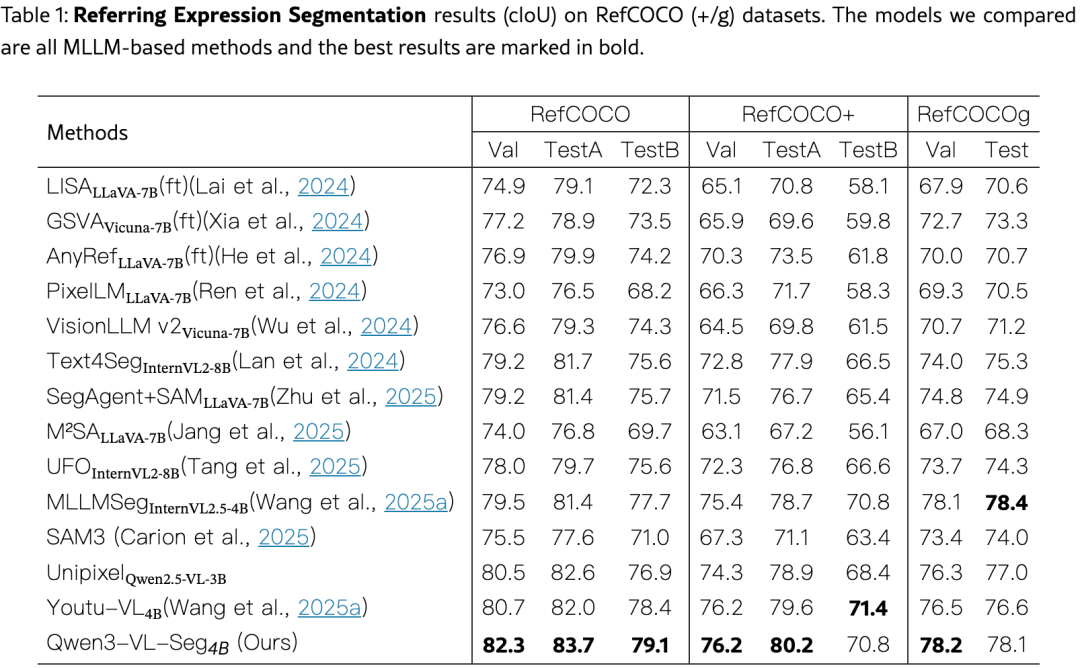
表1报告了 RefCOCO(+/g )上的 cIoU:
关键发现:
-
Qwen3-VL-Seg-4B 在 6/8 个评测 split 上取得最佳,且是唯一在 4B 规模超越 8B 模型(UFO-8B、Text4Seg-8B)的方法
-
相比 SAM-based 的 LISA,在 RefCOCO Val 上提升 7.4 分 ,RefCOCO+ TestB 提升 12.7 分
-
SAM3 作为纯分割基础模型,在指代表达分割上反而不如 MLLM-native 方法,说明语言理解对分割质量至关重要
7.2 视觉定位(REC)
表2显示,Qwen3-VL-Seg 在 REC 任务上同样强劲:
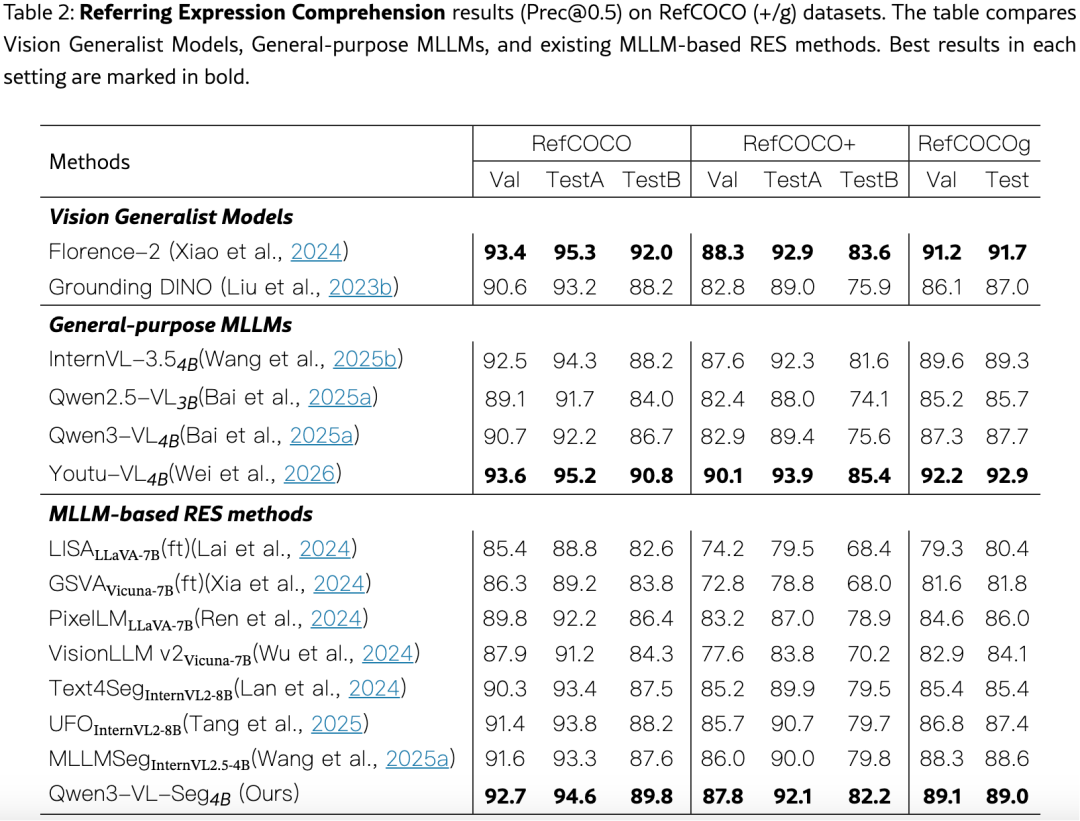
值得注意的是,Qwen3-VL-Seg相比 backbone Qwen3-VL,分割任务的训练让定位精度也提升了------例如 RefCOCO Val 从 90.7% → 92.7%,RefCOCO+ TestB 从 75.6% → 82.2%(+6.6% )。这说明像素级监督能反向精炼 MLLM 的空间感知能力。
7.3 开放世界指代分割
表3是本文最核心的实验,在 ORS-ID-Bench 上测试:
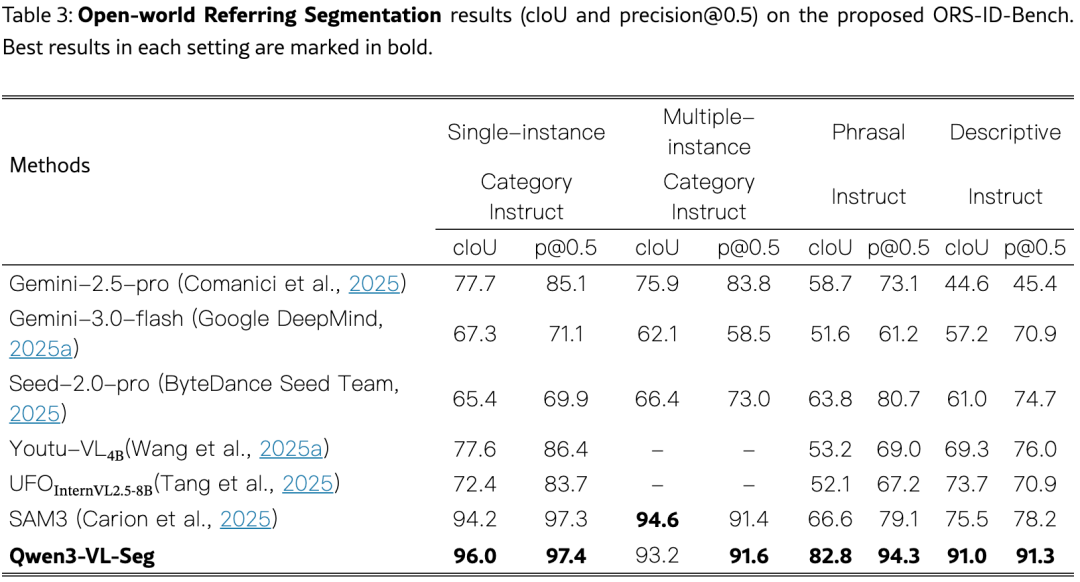
碾压级表现:
-
7/8 指标最佳,仅在多实例 cIoU 上略低于 SAM3(-1.4)
-
语言密集型场景 优势巨大:短语指令 cIoU 超越最佳基线 +19.0 ,描述性指令 cIoU 超越 +15.5
-
通用 MLLM(Gemini、Seed)在简单类别指令上尚可,一旦遇到复杂描述(如"从底部数第二个瓶子")性能断崖式下跌
-
SAM3 在类别指令上很强(靠视觉先验),但语言理解不足导致描述性指令上差距巨大
图8、9和10 提供了不同模型的定性对比,也展示了在"消防车的高架水炮"、"从底部数第二个瓶子"等细粒度场景下的精准分割。



7.4 分布外泛化
图11展示了 ORS-OOD-Bench 上的六维度评测:
| OOD 维度 | Qwen3-VL-Seg cIoU | 对比方法表现 |
|---|---|---|
| 类别偏移 | 53.49% | 显著超越其他 MLLM |
| 实例尺度 | 59.30% | 最佳 |
| 指令复杂度 | 86.22% | 最佳 |
| 光照变化 | 78.9% | 最佳 |
| 遮挡 | 83.45% | 最佳 |
| 风险敏感场景 | 8.64% | 最佳,但所有方法均大幅跌落 |
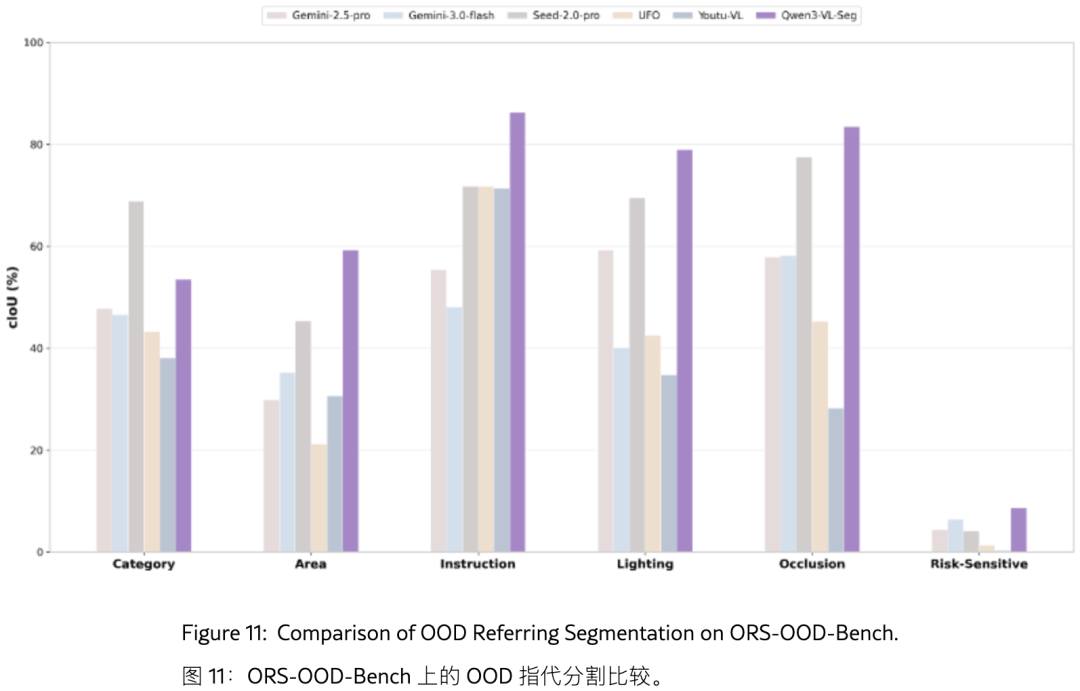
关键洞察 :尽管 Qwen3-VL-Seg 在 OOD 上全面领先,但在自动驾驶、医学诊断等风险敏感场景中,所有方法都"翻车"(cIoU 仅 8.64%)。这揭示了开放世界分割在安全关键领域仍有巨大提升空间。
7.5 通用多模态能力保持
表4验证了 Stage 2 训练的效果:
| 基准 | InternVL-3.5-4B | Qwen3-VL-4B | Qwen3-VL-Seg Stage-1 | Qwen3-VL-Seg Stage-2 |
|---|---|---|---|---|
| MMStar | 65.0 | 69.8 | 67.5 | 67.7 |
| MMBench-EN | 80.3 | 83.9 | 86.2 | 84.2 |
| MMMU-val | 66.6 | 67.4 | 63.4 | 66.2 |
| MathVision | - | 51.6 | 47.9 | 50.4 |
| CharXiv-RQ | 39.6 | 39.7 | 38.9 | 45.2 |
| RefCOCO-val | 92.5 | 91.6 | 91.8 | 92.3 |
Stage 1 后模型在感知任务(MMBench、RefCOCO)上提升,但推理任务(MMMU、MathVision)下降。Stage 2 通过混合训练恢复了通用能力,同时在 CharXiv(图表解析)和 RealWorldQA 上甚至超越了原始 backbone。这证明两阶段策略的成功------不是"偏科生",而是"全能选手"。
八、消融实验:验证每个组件的价值
表5在 RefCOCO(+/g)Val 上进行了严格消融:
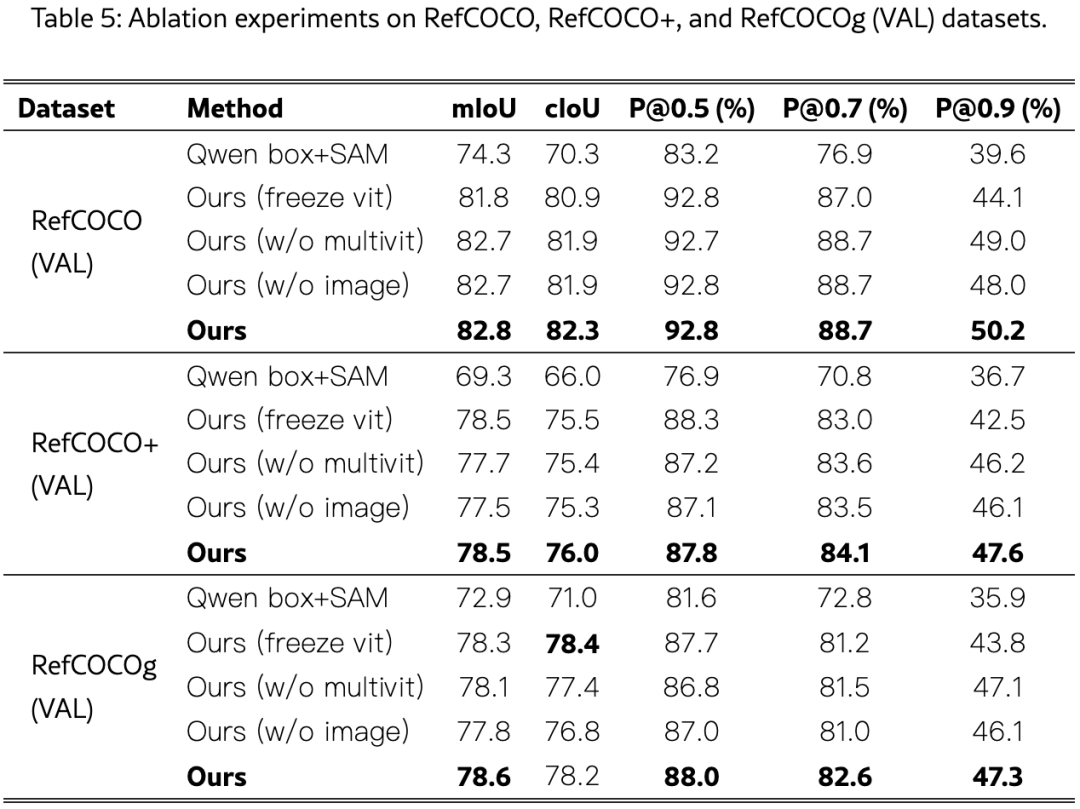
关键结论:
-
冻结 ViT 严重损害精度:P@0.9 掉 6.1 分,说明视觉骨干必须参与分割适配,不能"躺平"
-
多尺度特征不可或缺:去掉中间层特征(w/o multivit)后,cIoU 和 P@0.9 一致下降
-
浅层图像分支恢复边界:去掉高分辨率像素融合(w/o image)后性能下降,证明其对细边界的关键作用
-
P@0.9 最敏感 :各组件的增益在严格阈值下最明显,说明它们共同作用于边界质量而非粗略定位
九、创新点总结
| 创新维度 | 具体贡献 |
|---|---|
| 范式创新 | 提出面向开放世界指代分割的全链路 Box 结构先验机制 |
| 架构创新 | 在基于 17M 参数 Box-Guided Mask Decoder 的 SAM-free 轻量化架构下,4B 基座模型的精度达到了同期 8B 级 SAM-free 方法的水平 |
| 数据创新 | 构建 SA1B-ORS(约 299 万样本),相比现有 SA-1B 衍生数据在规模与粒度上扩展,含类别导向和描述性双轨监督 |
| 评测创新 | ORS-Bench 首个系统评测开放世界指代分割的 ID/OOD 基准,覆盖 6 种分布偏移 |
| 训练创新 | 采用分割适应与通用能力协同的两阶段训练策略 |
十、应用场景
Qwen3-VL-Seg 的"轻量 + 精准 + 开放世界"特性使其在以下场景极具潜力:
-
智能图像编辑:用户说"把左边穿红衣服的人抠出来换背景",模型直接输出精确 mask,无需手动描边
-
机器人视觉抓取:"拿起桌子上那个带把手的蓝色杯子"→ 像素级 mask 引导机械臂精准抓取
-
医学影像分析:"分割 CT 中左肺上叶那个不规则结节"------开放世界描述 + 精确边界对诊断至关重要
-
自动驾驶感知:ORS-OOD-Bench 已包含自动驾驶场景,虽然风险敏感场景仍有挑战,但方向明确
-
电商/内容审核:"标记图片中所有未授权的品牌 Logo"------开放世界类别 + 多实例分割
-
AR/VR 交互:用户通过自然语言描述选中虚拟/现实场景中的物体,进行交互或信息叠加
十一、结论与展望
Qwen3-VL-Seg 证明了一个重要命题:MLLM 的开放世界理解能力与像素级精确分割之间,并非必须依赖 SAM 这样的"重型桥梁"。通过将边界框作为全链路的结构先验加以系统化利用,作者以仅 17M 参数的轻量 decoder 实现了高质量的像素级分割。
这项工作也为未来指明了几个方向:
-
风险敏感场景的 OOD 泛化仍是全行业痛点(ORS-OOD-Bench 中 cIoU 仅 8.64%),需要更强的领域自适应;
-
多模态能力的进一步统一:Stage 2 的恢复策略已验证可行,未来或许能实现"分割-理解-推理"的真正三位一体;
-
更小规模的部署:4B 模型已能在边缘设备运行,17M 的 decoder 开销极低,为手机端实时开放世界分割提供了可行路径。
对于关注多模态大模型落地的朋友,这篇论文展示了 重要的技术进展,更是"轻量专用模块 + 强大基础模型"这一范式的优秀范例------避免了 参数堆砌与外挂 重型模型,而是通过巧妙的架构设计对现有能力进行了充分挖掘与高效利用。
原文链接
创作不易,禁止抄袭,转载请附上原文链接及标题