我最近踩了个坑,卧槽,差点把整个 RAG 系统的检索精度搞崩。
事情是这样的。我们在做企业级知识库检索,权限控制细化到文件夹和文档维度。用户只能看到自己有权限的内容,这个需求很常见。为了实现这个,我们在 Elasticsearch (ES) 里做了混合检索------文本查询加向量检索,听起来很完美对吧。
问题出在融合阶段。
用户的查询是"查找型号 ABCD 的文档",这个查询会被拆成两部分:文本部分去跑 BM25,向量部分去跑 kNN。听起来没问题。但我当时脑子一热,把整个查询字符串都传给了向量检索部分。
我当时就愣住了,因为向量检索开始"变笨"了。
你想啊,向量检索的本质是语义匹配。它应该只负责找到语义上最接近的文档,权限控制应该通过 filter 来实现。但我把"型号 ABCD"这个业务关键词也塞进了向量查询里,结果向量检索开始在向量空间里找包含"型号"和"ABCD"语义的文档。
这完全搞错了分工。

陷阱一:语义空间中的"关键词污染"
为什么把业务关键词塞进向量模型会导致精度下降?这需要从 Embedding 的本质说起。
当我们把"查找型号 ABCD 的文档"整句送入 Embedding 模型时,模型会试图对这句话的整体意图进行编码。在多维向量空间中:
- "查找...的文档"决定了句子的行为特征。
- "型号"决定了业务领域特征。
- "ABCD"是一个高度特异性的无语义 Token。
对于向量检索(特别是基于稠密向量 Dense Vector)而言,它极度不擅长处理这种精确的无实义字符(如特定编号、ID、乱码缩写)。强制让向量去匹配"ABCD",不仅会稀释"查找文档"这一核心意图的权重,还会导致召回大量可能包含 A、B、C、D 字母但毫无关联的废数据。
正确的逻辑流应该是这样的(架构图解):

陷阱二:must 与 filter 的底层机制差异
我花了一天时间才搞清楚 ES 内部的底层机制。
ES 的 bool query 里有四个关键部分:must、should、filter、must_not。很多初学者以为它们只是逻辑上的"与或非",但在 ES 的底层算分引擎(Lucene)中,它们的待遇天差地别:
- must / should (Query Context) :
- 核心职责:不但要判断"是否匹配",还要计算"匹配度有多高"(算分)。
- 底层开销:每次都要走 BM25 算法计算 TF-IDF,耗费 CPU。
- filter / must_not (Filter Context) :
- 核心职责:二元判断,只回答 Yes 或 No。
- 底层优化(杀手锏) :ES 会自动将 Filter 结果缓存为 Roaring Bitmaps(咆哮位图)。位图的交并集运算极快,且完全跳过算分阶段。
权限过滤应该是硬性的、二元的------你有权限或者没有。它不应该影响语义检索的排序。如果把权限放在 must 里,权限本身就成了一个"算分因子",这不仅让排序逻辑扭曲,还白白浪费了 ES 的 Bitset 缓存优化机制。
🧠 算法深潜:为什么必须在"检索时过滤 (Pre-filtering)"?
这里有个关键细节:权限过滤在文本检索和向量检索里都要做,而且要做在检索阶段(Pre-filter),绝不能是检索后过滤(Post-filter)。
1. 资源浪费与 Top-K 截断灾难
如果你用 Post-filter:ES 的 kNN 先检索出 Top 100 最相关的文档,然后你拿出权限列表一过滤,发现其中 95 个你都没权限!最后只剩下 5 个文档返回给用户。用户会觉得:"你们的库里怎么什么都没有?"
2. HNSW 算法的图遍历机制
ES 的向量检索底层使用的是 HNSW(分层可导航小世界) 算法。这是一种基于图的近似最近邻搜索。
如果在 HNSW 遍历图之后再做过滤(Post-filter),会导致原有的图连通性遭到破坏。
而在 ES 8.x 版本后,官方对 kNN 引入了强大的 Pre-filter 机制 :它会在 HNSW 遍历图节点的计算距离之前,先通过 Filter 的位图检查该节点是否符合权限,如果不符合,直接跳过计算。
正确的 ES 查询 DSL 应该如下构建:
plain
{
"query": {
"bool": {
"must": [
{
"match": {
"content": {
"query": "型号 ABCD",
"boost": 1.2 // 适当提高精确匹配的权重
}
}
}
],
"filter": [
{
"terms": {
"document_id": ["doc_123", "doc_456", "doc_789"]
}
}
]
}
},
"knn": {
"field": "embedding",
"query_vector": [0.1, 0.5, -0.3, ...],
"k": 50,
"num_candidates": 100,
// 【关键】kNN 内部专属的 filter,实现 Pre-filtering
"filter": {
"terms": {
"document_id": ["doc_123", "doc_456", "doc_789"]
}
}
}
}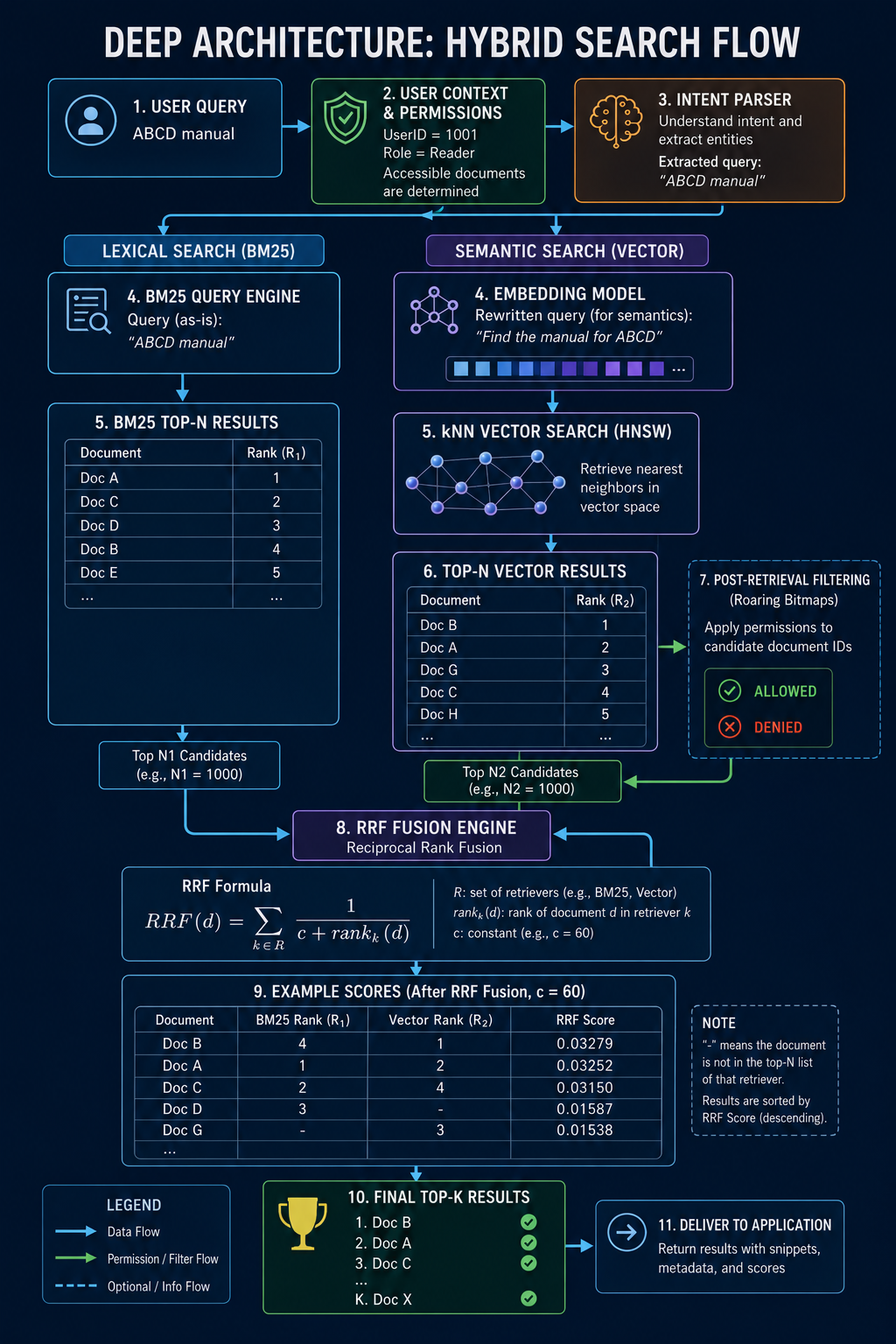
🧮 混合检索的灵魂:RRF 算法数学推演
现在说说 RRF(Reciprocal Rank Fusion,倒数排名融合)。这是混合检索里另一个坑点,但也是最好用的工具。
因为文本检索(BM25)的得分通常是无界的(例如 10.5, 24.3),而向量检索(余弦相似度)的得分是在 -1, 1 或 0, 1 之间。分数尺度不同,直接相加毫无意义。
RRF 放弃了绝对分数,只看排名 (Rank)。它的数学公式非常优雅:
RRF_Score(d)=∑r∈R1k+rankr(d)RRF\Score(d) = \sum{r \in R} \frac{1}{k + rank_r(d)}RRF_Score(d)=r∈R∑k+rankr(d)1
- ddd: 具体文档
- RRR: 不同的检索系统(比如 BM25 和 kNN)
- rankr(d)rank_r(d)rankr(d): 文档 ddd 在该系统中的排名
- kkk: 平滑常数,默认 60。
让我们来看一个实际的算例,理解 RRF 为什么牛逼:
假设有两个文档,常数 k=60k = 60k=60:
- 文档 A:文本匹配极度完美(排第 1 名),但语义稍有偏差(排第 20 名)。
- 文档 B:文本匹配还不错(排第 5 名),语义匹配也不错(排第 5 名)。
计算它们的 RRF 分数:
- Score(A)=160+1+160+20≈0.01639+0.01250=0.02889Score(A) = \frac{1}{60 + 1} + \frac{1}{60 + 20} \approx 0.01639 + 0.01250 = \mathbf{0.02889}Score(A)=60+11+60+201≈0.01639+0.01250=0.02889
- Score(B)=160+5+160+5≈0.01538+0.01538=0.03076Score(B) = \frac{1}{60 + 5} + \frac{1}{60 + 5} \approx 0.01538 + 0.01538 = \mathbf{0.03076}Score(B)=60+51+60+51≈0.01538+0.01538=0.03076
结果:文档 B 的最终得分更高!
这正是我们想要的混合检索效果:惩罚"偏科生",奖励综合素质高的文档。
plain
{
"retriever": {
"rrf": {
"retrievers": [
{ "standard": { /* 文本检索逻辑 */ } },
{ "knn": { /* 向量检索逻辑 */ } }
],
"rank_constant": 20,
"rank_window_size": 100
}
}
}在这个配置里,我把 rank_constant调到了 20。这意味着公式的分母变小,排名靠前的文档(如 Rank 1 和 Rank 2)之间的分数差距会被拉大,融合结果会更依赖两个检索系统头部的高排名文档。

💡 总结与架构反思
回到我踩的那个坑。修复之后的检索精度明显提升了:
- 向量检索 不再被业务关键词干扰,它专注于计算"距离"。
- 文本检索 负责硬核的"词元匹配"。
- RRF 负责公平地把两者的排名融合起来。
- 权限过滤 以最高效的位图形式,在图遍历前完成拦截。
架构设计有时候就是这么简单。把该做的事交给该做的部分,不要越界。
我最近在读一些关于检索系统架构的书,发现一个有趣的观点:好的架构不是把功能堆砌在一起,而是把功能拆分开,让每个部分只做一件事(单一职责原则)。ES 的 bool query 设计正是这种思想的完美体现。
希望这篇文能帮到正在搭建 RAG 系统的你。如果踩了类似的坑,欢迎来信交流。
码字不易,感谢"在看"。