💜 C++ 底层矩阵 · 代码永不停歇
| 👤 作者主页 | 🔥 C++ 核心专栏 |
|---|---|
| 💾 算法题解仓库 | 📁 代码仓库 |
一、前言
前文已覆盖删除专题、合并两链、回文、奇偶、归并排序等核心题型。本文补齐链表面试的最后两块硬骨头:K 路归并 与 深拷贝 + 随机指针。每种题型提供两种经典解法,助力你应对面试官的追问与复杂场景
二、合并K个有序链表
解法一:
🤔核心思路:
分析:
前一篇我们已经提到过合并两个有序链表,这里的题目稍微复杂了一些,不过可以
复用合并两个有序链表的逻辑,将K个有序链表进行两两合并即可步骤:
- 将 K 个链表两两配对,每对合并成一个链表
- 重复上述过程,直到只剩下一个链表
- 合并两个链表的逻辑直接复用 mergeTwoLists
cpp
class Solution {
public:
//step代表着每组合并时链表个数:最开始是1、1合并,step依次乘2,接着是2、2合并......
//外层循环控制链表个数不超过链表数目
//内存循环控制链表进行合并逻辑,从索引0开始,每次跳过2*step,将lists[i]和lists[i+step]合并后放回lists[i]
ListNode* mergeKLists(vector<ListNode*>& lists) {
int n = lists.size();
if(n == 0) return nullptr;
//将lists两两组合合并
int step = 1;
while(step < n){
//每次跳过2*step
for(int i = 0;i + step<n;i += 2*step){
lists[i] = mergeTwoList(lists[i],lists[i+step]);
}
step *= 2;
}
return lists[0];
}
private:
//复用合并两个有序链表的逻辑
ListNode* mergeTwoList(ListNode* list1,ListNode* list2){
ListNode* head1 = list1,*head2 = list2;
ListNode* dummy = new ListNode(0);
ListNode* tail = dummy;
while(head1 || head2){
int val1 = head1 == nullptr ? INT_MAX : head1->val;
int val2 = head2 == nullptr ? INT_MAX : head2->val;
if(val1 < val2){
tail->next = head1;
tail = head1;
head1 = head1->next;
}
else{
tail->next = head2;
tail = head2;
head2 = head2->next;
}
}
ListNode* newHead = dummy->next;
delete dummy;
return newHead;
}
};📋 流程图示意
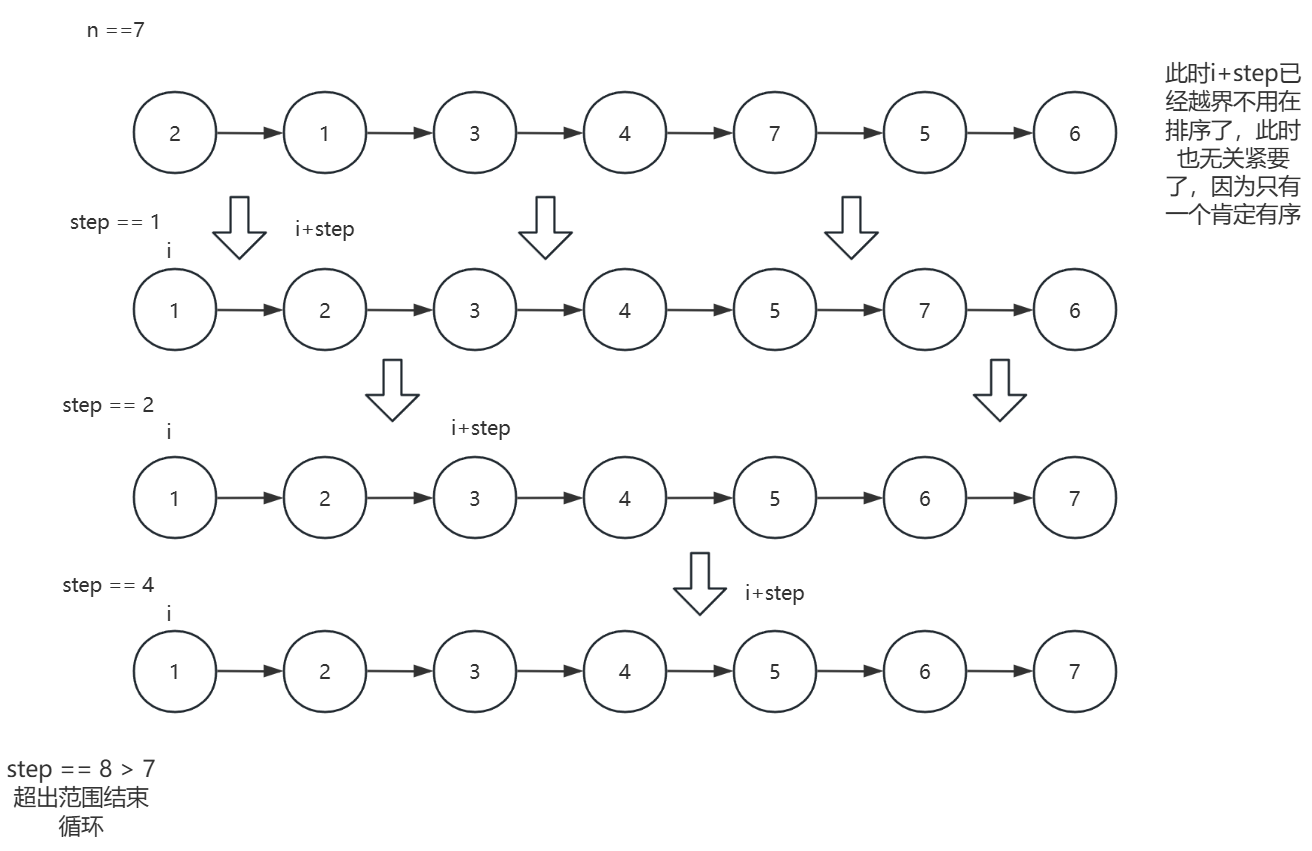
⚠️ 易错点避坑指南
- 注意处理边界情况n==0,因为返回值是lists0,需要直接返回nullptr,否则会造成越界访问
- 在内层循环时需要保证i+step在链表数量范围内
- i 的更新是 i += step * 2,因为每次合并一对之后,下一对起点要跳过刚才合并的两个区间
- 不用单独处理奇数的情况,如示意图所示,该代码也能够处理
解法二:优先级队列
🤔核心思路
利用优先级队列每次选出最小的值
- 将链表数组的头节点加入优先级队列中
- 每次弹出最小的节点,并将最小节点的next加入队列中
- 重复直到队列为空为止
😊 代码实现:
cpp
class Solution {
public:
//仿函数
struct Compare{
bool operator()(const ListNode* l1,const ListNode* l2){
return l1->val > l2->val;
}
};
//优先级队列
ListNode* mergeKLists(vector<ListNode*>& lists) {
int n = lists.size();
if(n == 0) return nullptr;
//建小堆
priority_queue<ListNode*,vector<ListNode*>,Compare> pq;
//将lists数组中的每个头节点入优先级队列
for(int i = 0;i<n;i++){
if(lists[i]) pq.push(lists[i]);
}
ListNode* dummy = new ListNode(0);
ListNode* tail = dummy;
while(!pq.empty()){
ListNode* top = pq.top();
pq.pop();
tail->next = top;
tail = top;
ListNode* next = top->next;
if(next) pq.push(next);
}
ListNode* newHead = dummy->next;
delete dummy;
return newHead;
}
};⚠️ 易错点避坑指南
- 这里的优先级队列需要自已写仿函数,并且要注意仿函数的大于表示小堆,小于表示大堆
- 注意空链表处理:只有非空头节点才入堆
- 在取出top元素之后,不要忘记删除top元素,否则会死循环
🚀 实战链接:LeetCode 23.合并K个升序序列
三、复制带随机指针的链表
解法一:哈希表
🤔核心思想
分析:
在处理一般题的时候仅需要处理next指针,这道题的核心难点就在于随机链表的处理,因为在处理到某节点时,该节点的随机节点可能在该节点的后方,这样就做不到链接随机节点了,所以可以提前用
hash表完整的存储整个链表步骤
- 第一遍遍历原链表,创建每个节点的副本,用哈希表(unordered_map)记录原节点 → 新节点的映射关系
- 第二遍遍历原链表,根据原节点的 next 和 random 指向,通过哈希表找到对应的新节点并连接
时间复杂度为O(n),空间复杂度为O(n)
😊代码实现 :
cpp
class Solution {
public:
Node* copyRandomList(Node* head) {
if(head == nullptr) return nullptr;
Node* cur = head;
unordered_map<Node*,Node*> hash;
while(cur){
hash[cur] = new Node(cur->val);
cur = cur->next;
}
cur = head;
while(cur){
hash[cur]->next = hash[cur->next];
hash[cur]->random = hash[cur->random];
cur = cur->next;
}
return hash[head];
}
};解法二:原地拆分
🤔 核心思路
分析:
前面提到问题的难点在于找不到随机节点,解法一是利用
hash存储建立关系随机节点,而解法二是利用原地拆分,在每个节点后面插入一个新节点,表示拷贝节点,这样拷贝链表就与原链表建立起了关系--每一个原链表的节点的下一个就是对应的拷贝节点,在寻找随机节点的时候,只需要找到原链表随机的下一个就可以了步骤:
- 插入拷贝节点:遍历原链表,在每个原节点后面创建一个新节点(值相同),新节点的 next 指向原节点的下一个原节点
原链表:A → B → C 变为:A → A' → B → B' → C → C'- 设置随机指针:再次遍历链表,对于每个原节点 cur,其拷贝节点 cur->next 的 random 应该指向 cur->random->next(即原 random 指向节点的拷贝节点),注意处理 cur->random 为 nullptr 的情况
- 拆分链表:将混合链表拆分为原链表和拷贝链表。恢复原链表的 next 关系,同时连接拷贝链表的 next 关系。
😊 代码实现:
cpp
class Solution {
public:
Node* copyRandomList(Node* head) {
if(head == nullptr) return nullptr;
Node* cur = head;
//第一步:在每个原节点后插入拷贝节点
while(cur){
Node* next = cur->next;
Node* newNode = new Node(cur->val);
cur->next = newNode;
newNode->next = next;
cur = next;
}
//第二步:链接随机节点
cur = head;
while(cur && cur->next){
Node* nnext = cur->next->next;
Node* newNode = cur->next;
if(cur->random) newNode->random = cur->random->next;
else newNode->random = nullptr;
cur = nnext;
}
Node* dummy = new Node(0),*tail = dummy;
//第三步:拆分拷贝节点
cur = head;
while(cur && cur->next){
tail->next = cur->next;
tail = tail->next;
Node* nnext = cur->next->next;
//恢复原链表
cur->next = nnext;
cur = nnext;
}
Node* newHead = dummy->next;
delete dummy;
return newHead;
}
};⚠️ 易错点避坑指南
- 第一步插入后,链表长度翻倍,循环更新时 cur = nnext 才是正确的原节点位置
- 第二步设置 random 时,需要确保 cur->random 不为空,否则 cur->random->next 会导致空指针崩溃
- 第三步拆分时,拆分的是cur->next,并且每次要移动两步
- 拆分后原链表结构被破坏,记得复原原链表
🚀 实战链接:LeetCode 138.随机链表的复制
四、结尾
链表专题至此已全部结束,下一专题将要着手写贪心算法了,请大家敬请期待~