目录
[1. UDP 的问题](#1. UDP 的问题)
[2. TCP 解决了什么](#2. TCP 解决了什么)
[二、TCP Socket API](#二、TCP Socket API)
[1. socket / bind](#1. socket / bind)
[2. listen / accept](#2. listen / accept)
[3. recv / send / close](#3. recv / send / close)
[三、TCP 与 UDP 区别](#三、TCP 与 UDP 区别)
[四、TCP EchoServer 架构](#四、TCP EchoServer 架构)
[1. 单线程串行的局限](#1. 单线程串行的局限)
[2. 线程池](#2. 线程池)
[3. TCP 高并发回显服务器实现](#3. TCP 高并发回显服务器实现)
[4. 业务层装配](#4. 业务层装配)
[五、 多客户端并发验证](#五、 多客户端并发验证)
[1. 编译与拉起服务](#1. 编译与拉起服务)
[2. 多终端并发测试](#2. 多终端并发测试)
一、为什么需要TCP
在之前的博客中,我们从基础的 UDP Echo Server 逐步探索到高并发的 UDP 聊天室。整个过程中,UDP 协议给我们最直接的体验就是 "高效便捷":创建套接字后就能直接使用 sendto 发送数据包,代码结构简洁明了
然而,若尝试通过 UDP 协议传输 2GB 高清电影或构建零容错的网上银行系统,便会立即暴露出UDP 的固有缺陷
面对日益复杂的互联网应用场景,我们将告别UDP协议,正式进入网络编程的核心领域------TCP Socket 编程
1. UDP 的问题
UDP 协议的核心特点是只负责发送数据包,不保证传输结果,既不确认送达也不承诺可靠性。这种特性在以下应用场景中会显现出明显的局限性:
-
不可靠性:UDP 在传输层没有确认机制。当你在打网络游戏或者看直播时,偶尔丢一两个报文,无非是画面卡顿一下或语音漏掉一个字,应用层完全可以容忍。但如果是在传输一份软件安装包、一份核心数据库备份,内核只要丢掉哪怕 1 个字节的数据,整份文件就会直接损坏损坏崩溃
-
无序性:网络链路错综复杂,客户端先后发出的数据包 A 和数据包 B,由于在路由器之间选择的转发路径不同,极有可能出现数据包 B 先于 A 到达服务端的现象。UDP 对此束手无策,它会按照收到的顺序交给应用层,导致接收端解析出来的文本变成一堆乱码
-
面向数据报:UDP 严格限制了单包的数据载荷。如果你要发送一个大文本,你必须在应用层自己写一套复杂的 "分片、编号、组装、校验" 逻辑。这相当于把本该由传输层完成的任务,强加给了应用层
2. TCP 解决了什么
为了在充满不确定性的 IP 网络之上搭建一条安全、可靠的数据通道,TCP协议应运而生。相较于 UDP,TCP 在底层实现了质的飞跃,彻底解决了上述所有痛点:
-
可靠传输 : TCP 引入了极其严密的确认应答机制 与超时重传机制。简单来说,发送方发出的每一个字节,接收方都必须给予明确的收到答复。如果因为网络抖动导致丢包,发送方在等待一段时间后没有收到应答,就会重新发送该包,直到对方安全收到为止
-
有序到达 : TCP 报头中携带了 32 位序列号。哪怕网络链路再混乱、数据包到达的先后顺序再颠倒,接收端的 TCP 协议栈也会按照序列号把数据重新排列,确保应用层读取到的数据和发送顺序百分之百一致
-
流量与拥塞控制 : TCP 能通过滑动窗口机制实时感知到接收端网络缓冲区的剩余容量(流量控制 ),避免发得太快把对方无法接收;同时,它还能通过算法感知整个互联网链路的拥堵程度(拥塞控制),网络堵塞时主动减速,网络顺畅时再逐步提速
-
面向字节流: TCP 和 UDP 在编程实现上的核心差异在于数据传输方式。TCP 协议如同一条现成的输水管道:发送端可以逐字节传输(每次写入 1 字节),也能批量发送数据(如一次性写入 10KB);接收端同样灵活,既可小量读取(每次 10 字节),也能直接接收大块数据。TCP 协议消除了应用层消息的固定边界,将数据转换为连续的字节流
UDP 追求的是速度与轻量 ,适合实时性要求高但允许少量丢包的场景(如音视频点播、在线游戏);而 TCP 追求的是稳妥与精确,如 HTTPS 网页浏览、文件传输 FTP、远程登录 SSH
二、TCP Socket API
如果直接去查 Linux 手册,往往只能看到函数签名。但作为开发者,我们更应该探寻其背后的设计哲学:为什么操作系统要提供这些 API?不提供行不行?它们究竟在帮应用层解决什么底层的工程困境?
1. socket / bind
socket:
cpp
#include <sys/types.h>
#include <sys/socket.h>
int socket(int domain, int type, int protocol);
参数解析:
- domain:协议族/域
- type:套接字类型
- protocol:具体的协议。通常直接填 0,系统会根据前两个参数自动推导
返回值:
成功返回一个全新的文件描述符;失败返回 -1 并设置 errno-
为什么需要它 : 在内核看来,一切皆文件。socket 的本质,就是让操作系统在 PCB 的文件描述符表里,分配一个索引槽位,并初始化一套专属于 TCP 协议的网络状态机与缓冲区
-
这相当于你决定要开一家餐厅,向工商局申请到了一个合法的经营资质,并租下了一间毛坯房。此时,这间店还只是一个空壳子,没有任何人知道它,它也没法营业
bind:
cpp
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
参数解析:
- sockfd:由 socket() 创建的文件描述符
- addr:指向结构体 sockaddr 的指针,包含要绑定的 IP 和端口
- addrlen:传入的地址结构体的长度
返回值:
成功返回 0;失败返回 -1-
为什么需要它 : 创建完套接字后如果不进行绑定,内核就不知道当网卡收到一个发往某个端口的数据包时,究竟该递交给哪一个进程。bind 的目的,就是把文件描述符锁在某个具体的物理网卡 IP 和具体的端口上
-
这相当于你给你的毛坯房挂上了一块牌匾,明确了门牌号:xxx大道 8080 号。从此,食客们(客户端)想来吃饭,只要顺着这个明确的地址就能找到你
2. listen / accept
listen:
cpp
int listen(int sockfd, int backlog);
参数解析:
- sockfd:已经绑定好 IP/Port 的监听套接字
- backlog:底层全连接队列的最大长度。简单来说,就是操作系统允许在服务器还没来得及 accept 之前,排队等待处理的连接请求的最大数量
返回值:
成功返回 0;失败返回 -1-
为什么需要它 : 在默认情况下,任何新建的套接字都是主动的 ------也就是说,系统默认你创建它是为了去连接别人(比如做客户端)。但服务器必须是被动的 ,它需要等待客户端的连接。 listen 的核心诉求,就是彻底强转套接字的状态,将其变为监听状态。更重要的是,它会在内核中开辟出两个极其关键的队列(半连接队列与全连接队列),用来容纳那些已经发起建连请求、正在排队的客户
-
这相当于你在餐厅门口正式挂上了 "营业中" 的霓虹灯 ,并且在店门口雇佣了一位迎宾员(此时的套接字叫做 listen_sockfd)
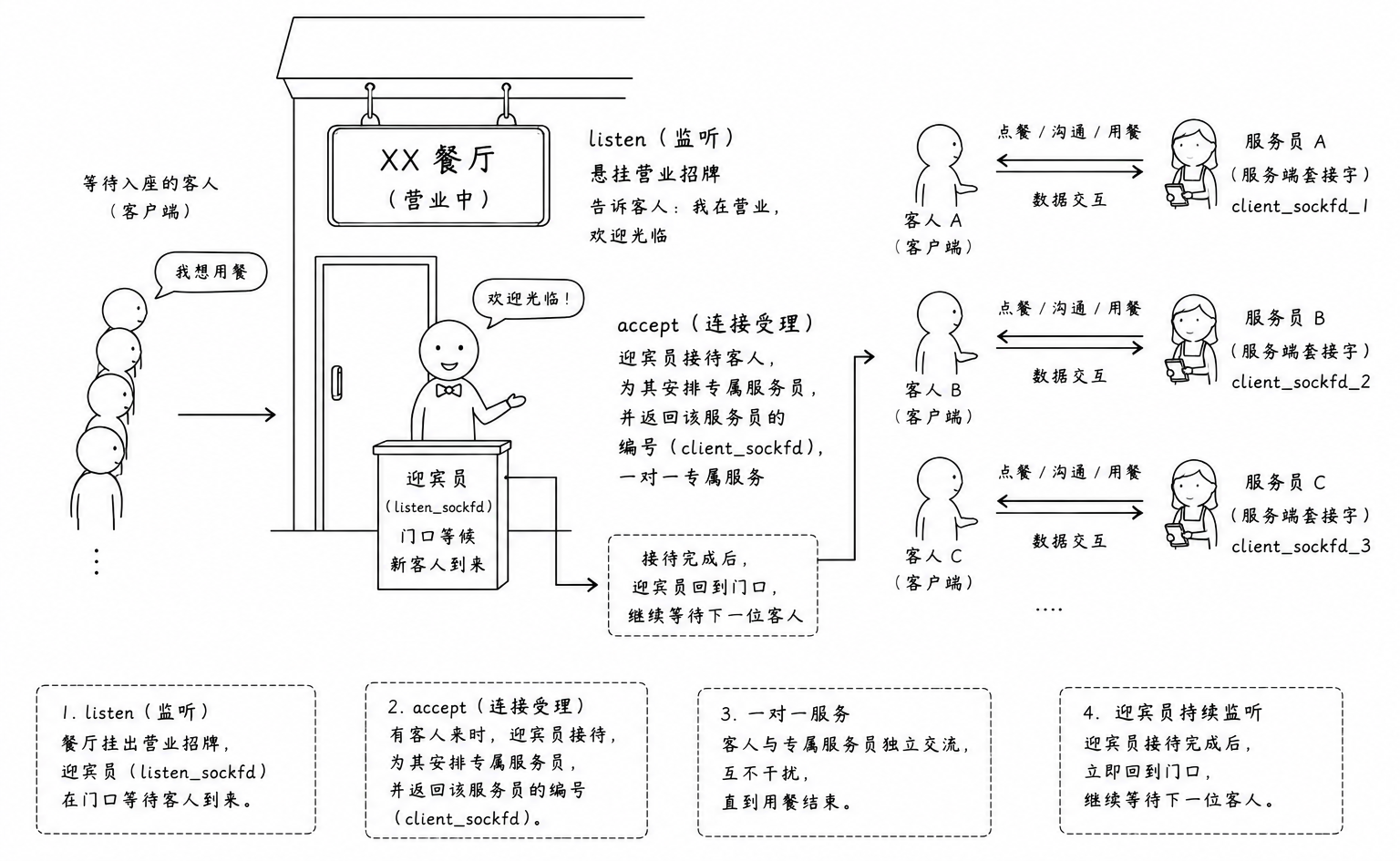
accept:
cpp
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
参数解析:
- sockfd:服务器的监听套接字
- addr:输出型参数。用来获取客户端的 IP 和端口号
如果不在乎客户端是谁,可以填 NULL
- addrlen:输入输出型参数。传入客户端结构体的大小,
函数返回时会被修改为实际写入的地址长度
返回值:
成功时返回一个全新的文件描述符。失败返回 -1-
为什么需要它: 这是 TCP 编程中最容易产生误解的关键点。当 listen_sockfd 发现全连接队列中已有就绪的客户端时,需要通过 accept 操作将这个客户端 "带入" 服务流程。本质上,accept 的作用就是从已建立的连接队列中提取一个有效的连接实例
accept 执行成功后,会**返回一个全新的文件描述符(我们称之为 client_sockfd)**此后所有的业务数据交互(读写消息),全部通过这个新套接字来进行
-
当门口的迎宾经理发现有人排到头了,他就会立刻叫来一个服务员(client_sockfd),对他说:你把这组客人领到 5 号桌,今天他们这一桌的点菜买单,全由你 1 对 1 负责
交代完后,迎宾经理转身立刻回到了大门口,继续盯着大门等待下一个客人。而客人则跟着专属服务员坐到桌前,开始享受就餐服务
3. recv / send / close
recv / send:
cpp
#include <sys/types.h>
#include <sys/socket.h>
ssize_t recv(int sockfd, void *buf, size_t len, int flags);
参数解析:
- sockfd:accept 返回的负责特定连接的服务套接字
- buf:指向一块内存缓冲区的指针,用来存放接收到的数据
- len:期望接收的数据最大字节数(即 buf 的大小)
- flags:控制标志,通常填 0
返回值:
> 0:实际读取到的字节数
== 0:表示对端关闭了连接。服务器应该立即停止读写并关闭该 fd
< 0:读取出错
cpp
ssize_t send(int sockfd, const void *buf, size_t len, int flags);
参数解析:
- sockfd:负责该连接的套接字
- buf:指向要发送的数据缓冲区的指针
- len:要发送的数据字节数
- flags:发送标志,通常填 0
返回值:
成功返回实际发送的字节数;失败返回 -1-
为什么需要它: 由于 TCP 是面向字节流的,我们不再使用 UDP 的 recvfrom / sendto(因为不需要每次都手动填写对端的 IP 和端口了,专属服务员和这一桌客人的通道已经绑定)。 我们通过 recv 从内核的接收缓冲区里接收对方发来的字节,或者通过 send 将响应字节发送至对方缓冲区
-
这就进入了真正的就餐环节。食客对服务员说:我要一份红烧肉(recv 接收请求),服务员通知后厨做完后,把红烧肉端上桌(send 响应结果)。这个过程中,大门口的迎宾经理完全不参与
close:
cpp
#include <unistd.h>
int close(int fd);
参数解析: fd 为需要关闭的套接字(监听套接字或服务套接字均可)
返回值: 成功返回 0;失败返回 -1
底层行为: 调用 close 会触发 TCP 的四次挥手断开连接流程-
为什么需要它 : 任何一方调用 close,都是通知操作系统:我们之间的底层字节流通道需要开始执行四次挥手了。一旦挥手完毕,内核会彻底注销掉对应的文件描述符,释放其占用的所有缓冲区资源
-
食客吃饱喝足,起身结账离开。服务员(client_sockfd)将桌子上的残渣剩饭清理干净,将桌椅复位。这个服务员就此准备去接待下一桌被迎宾经理带进来的新食客(资源回收与复用)
三、TCP 与 UDP 区别
此时我们可以解答一个常见的底层面试题:
为什么 TCP 必须需要 accept,而 UDP 绝对不需要
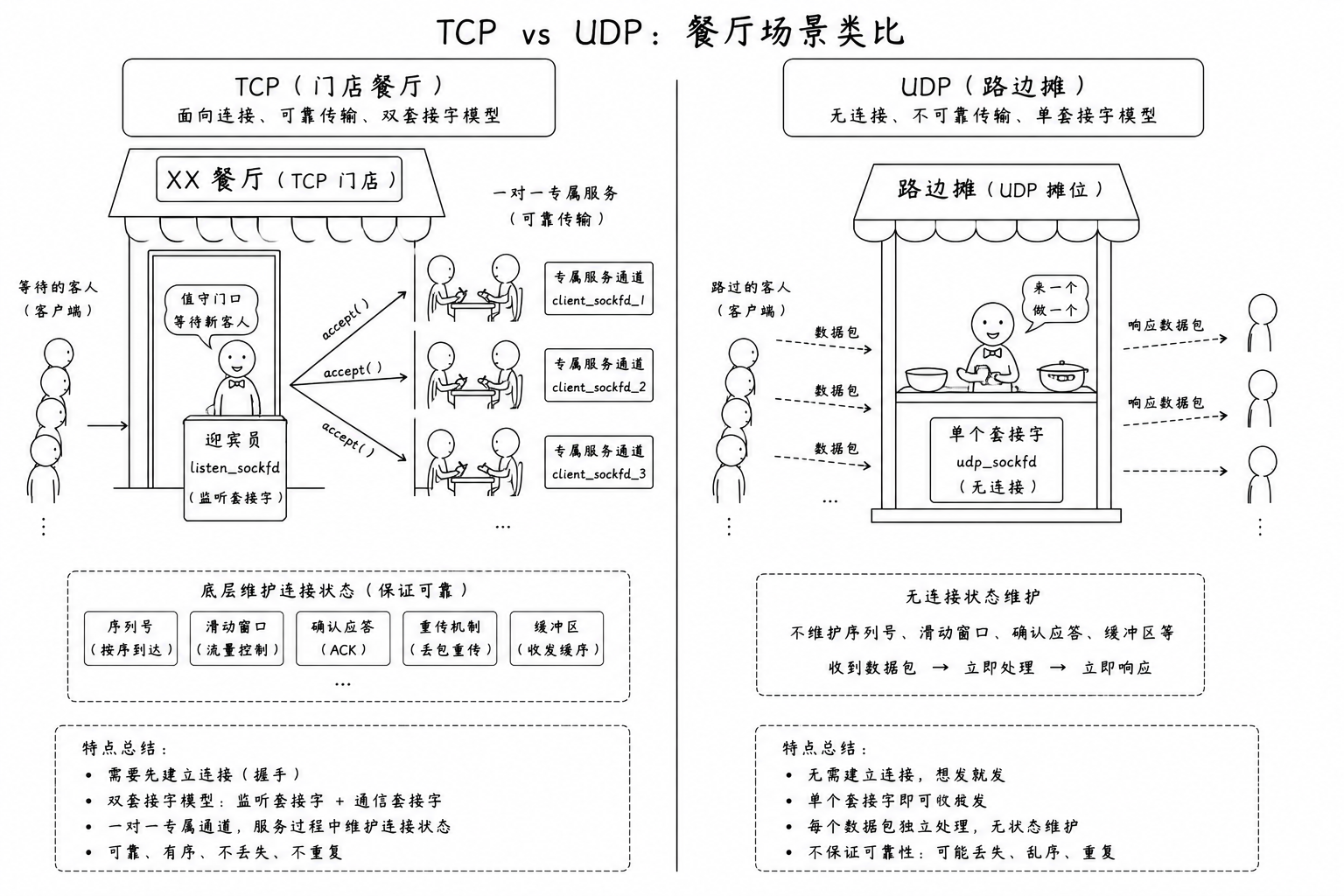
-
TCP 承诺的是绝对可靠的字节流服务 。为了保证不丢包、不乱序,它在底层必须为每一条连接都独立维护一套序列号、滑动窗口、流量控制缓冲区以及计时器。 这就注定了它必须采用双套接字模型。如果不通过 accept 分离出一个专属服务员(client_sockfd),那么主线程迎宾经理就会被某一个客人的点菜(耗时 I/O 读写)死死卡住,导致整家餐厅在同一时间只能接待一个客人
-
UDP 协议中没有连接的概念。它不需要维护复杂的窗口和状态,来一个包就处理一个包。 它就像一个路边摊------摊主(UDP sockfd)不需要雇佣什么迎宾经理,也不需要什么专属服务员。任何食客大步走过来,大喊一声 "来个煎饼",摊主做完直接扔给他,食客拿了就走。摊主不需要记住他是谁,也不需要为他开辟任何专属空间。 因此,UDP 只需要一个套接字,就能凭借单线程对抗全网的并发冲击
四、TCP EchoServer 架构
在理解了 TCP 的 API 后,我们将手写一个高并发的 TCP EchoServer(回显服务器)
在动笔写代码前,我们必须先看清一个经典架构陷阱:单线程串行陷阱。通过拆解这个陷阱,我们就能极其顺畅地过渡到为什么必须要用线程池来托管 TCP 连接
1. 单线程串行的局限
如果我们沿用 UDP 的开发思维,写出如下的伪代码:
cpp
// 错误示范:单线程串行 TCP 服务器
void Start() {
while (true) {
// 1. 迎宾经理接到一个新客人,分发一个专属服务员 client_sockfd
int client_sockfd = accept(listen_sockfd, ...);
// 2. 独占式地为当前这一桌客人提供 1对1 服务
while (true) {
char buf[1024];
ssize_t n = recv(client_sockfd, buf, sizeof(buf), 0); // 阻塞在这里!
if (n <= 0) break; // 客户端下线才退出
send(client_sockfd, buf, n, 0);
}
close(client_sockfd); // 交互结束后才去接下一个
}
}这种架构在应对多客户端并发时是灾难性的: 当客户端 A 成功连接(accept 返回)后,服务器的唯一执行流会直接深陷在内层的 while 循环中。此时,如果客户端 A 只是连接而不发送任何数据,服务器线程就会死死阻塞在 recv上
这就导致外层的 accept 循环根本没有机会再次执行。此时如果有其他客户端尝试连接,它们只能被堆积在操作系统的全连接队列里。在用户端表现为:客户端 B 显示连接成功,但发送任何消息都石沉大海,直到客户端 A 主动断开,服务器才会处理客户端 B
2. 线程池
为了确保主线程持续高效地处理新连接请求,当通过 accept 获取到新的 client_sockfd 后,必须立即将其转交给其他线程处理,避免阻塞主线程的处理流程
由于我们在前几篇博客中已经封装好了通用的单例线程池与网络地址工具类(InetAddr),我们在此处不做赘述。我们的核心工作是:如何将一个长期的 TCP 读写会话,打包成一个任务塞进线程池?
与 UDP "来一个报文就处理完毕" 不同,TCP 的一个任务代表了一条长期的生命周期通道
-
主线程(生产者):只管调用 accept。一拿到 client_sockfd,立刻用 C++11 Lambda 表达式将其和业务逻辑捆绑,做成一个 Task 推进线程池队列,随后秒回 accept 准备迎接下一个连接
-
工作线程(消费者):从任务队列中取到这个 Task 后,会接管这个 client_sockfd,并在后台独立执行 while(recv) 循环。该循环会一直持续,直到客户端主动断开连接(recv 返回 0)或出错
工业级开发铁律:文件描述符泄漏防范
工作线程在退出 while(recv) 循环、结束业务时,必须调用 close(client_sockfd)! 因为每一个 TCP 连接都对应一个独立的文件描述符,而单个进程可开启的文件描述符上限是极其有限的(默认通常是 1024)。如果不由工作线程负责关闭,每来一个用户就会废掉一个槽位,服务器运行一段时间后就会抛出错误,导致整个系统瘫痪
3. TCP 高并发回显服务器实现
下面是完整的高并发 TCP 网络引擎实现。全面践行了去业务化的解耦思想:
cpp
#pragma once
#include <iostream>
#include <string>
#include <cstring>
#include <functional>
#include <memory>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include "InetAddr.hpp" // 复用此前封装的地址转换工具
#include "ThreadPool.hpp" // 复用此前封装的单例线程池
class TcpServer {
public:
// 业务层回调函数规范:传入服务套接字和客户端地址信息
using business_cb_t = std::function<void(int, const InetAddr&)>;
using Task = std::function<void()>;
TcpServer(uint16_t port, business_cb_t cb, const std::string& ip = "0.0.0.0")
: _listen_sockfd(-1), _port(port), _cb(cb), _ip(ip), _is_running(false) {}
~TcpServer() {
if (_listen_sockfd >= 0) close(_listen_sockfd);
}
// 初始化 TCP 监听环境
bool Init() {
// 1. 创建套接字 (SOCK_STREAM)
_listen_sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (_listen_sockfd < 0) {
std::cerr << "TcpServer: Create listen socket failed" << std::endl;
return false;
}
// 允许地址和端口复用,防止服务器重启时遭遇 Time-Wait 端口锁定
int opt = 1;
setsockopt(_listen_sockfd, SOL_SOCKET, SO_REUSEADDR | SO_REUSEPORT, &opt, sizeof(opt));
// 2. 绑定网络地址
struct sockaddr_in local;
std::memset(&local, 0, sizeof(local));
local.sin_family = AF_INET;
local.sin_port = htons(_port);
inet_pton(AF_INET, _ip.c_str(), &local.sin_addr);
if (bind(_listen_sockfd, (struct sockaddr*)&local, sizeof(local)) < 0) {
std::cerr << "TcpServer: Bind failed" << std::endl;
return false;
}
// 3. 将套接字转换为被动监听状态,设置全连接队列最大长度为 32
if (listen(_listen_sockfd, 32) < 0) {
std::cerr << "TcpServer: Listen failed" << std::endl;
return false;
}
std::cout << "TcpServer: Init success. Listen socket fd: " << _listen_sockfd << std::endl;
return true;
}
// 主线程事件循环
void Start() {
_is_running = true;
// 激活后台高并发线程池
auto* pool = ThreadPool<Task>::GetInstance();
std::cout << "主线程等待连接..." << std::endl;
while (_is_running) {
struct sockaddr_in peer;
socklen_t len = sizeof(peer);
// 4. 阻塞等待新连接
int client_sockfd = accept(_listen_sockfd, (struct sockaddr*)&peer, &len);
if (client_sockfd < 0) {
std::cerr << "TcpServer: Accept connection warning" << std::endl;
continue;
}
InetAddr client_addr(peer);
std::cout << "成功捕获新连接, 分配临时 fd: " << client_sockfd
<< " 来自: " << client_addr.PrintStr() << std::endl;
// 5. 打包 Lambda Task
// 必须按值捕获 client_sockfd,防止多圈循环覆盖导致数据污染
Task session_task = [this, client_sockfd, client_addr]() {
// 回调外部注入的具体业务
this->_cb(client_sockfd, client_addr);
// 业务执行完毕后,由工作线程关闭该套接字,防止描述符泄漏
close(client_sockfd);
std::cout << "客户端会话结束, fd: " << client_sockfd
<< " 已释放." << std::endl;
};
// 6. 派发给单例线程池的工作队列,主线程不作停留
pool->Enqueue(session_task);
}
}
private:
int _listen_sockfd;
uint16_t _port;
business_cb_t _cb;
std::string _ip;
bool _is_running;
};4. 业务层装配
在主程序中,我们实现标准的应用层 Echo(回显) 逻辑,并在实例化服务器时将其注入:
cpp
#include "TcpServer.hpp"
#include <algorithm>
// 具体的应用层业务:字节流回显交互
void EchoService(int sockfd, const InetAddr& peer) {
char buffer[4096]; // 4KB 核心读取缓冲区
std::cout << " -> 工作线程创建成功: " << peer.PrintStr() << std::endl;
while (true) {
// 从套接字中接收应用层原始字节
ssize_t n = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
if (n > 0) {
buffer[n] = '\0';
std::string client_data = buffer;
// 过滤掉客户端发来的无意义空回车
if (client_data == "\n" || client_data == "\r\n") continue;
std::cout << " [" << peer.PrintStr() << "] 发来数据: " << client_data;
// 原样响应
std::string response = "server: " + client_data;
send(sockfd, response.c_str(), response.size(), 0);
}
else if (n == 0) {
// recv 返回 0,代表对端客户端调用 close 关闭了发送端
std::cout << " -> [Service Log] 客户端: " << peer.PrintStr()
<< " 退出" << std::endl;
break;
}
else {
// 读取异常
std::cerr << " -> 未知系统异常." << std::endl;
break;
}
}
}
int main() {
// 实例化 TCP 服务器,绑定 8080 端口,并注入 EchoService 业务回调
std::unique_ptr<TcpServer> server(new TcpServer(8080, EchoService));
if (server->Init()) {
server->Start();
}
return 0;
}五、 多客户端并发验证
编写完毕后,我们可以直接利用 Linux 系统自带的网络瑞士军刀------telnet 或 nc (Netcat) 命令,来对我们的线程池 TCP 服务器进行抗并发冲击验证
1. 编译与拉起服务
在终端执行以下指令完成编译并运行:
cpp
g++ -std=c++11 main.cc -o tcp_echo_server
./tcp_echo_server服务端打印输出:
bash
TcpServer: Init success. Listen socket fd: 3
主线程等待连接...2. 多终端并发测试
为了彻底验证我们打破了单线程串行死锁,我们同时打开 3 个全新的 Linux 终端窗口,扮演三个并发涌入的客户端
(1) 终端 1 接入:
bash
nc 127.0.0.1 8080此时我们在终端 1 中保持静默,不敲击任何字符
(2) 终端 2 接入:
bash
nc 127.0.0.1 8080紧接着在终端 2 中敲入:Hello TCP
终端二瞬间收到相应

(3) 观察服务端的调度日志
回到运行着编译后程序的控制台,你会清晰地看到如下由于多线程并发的交错日志
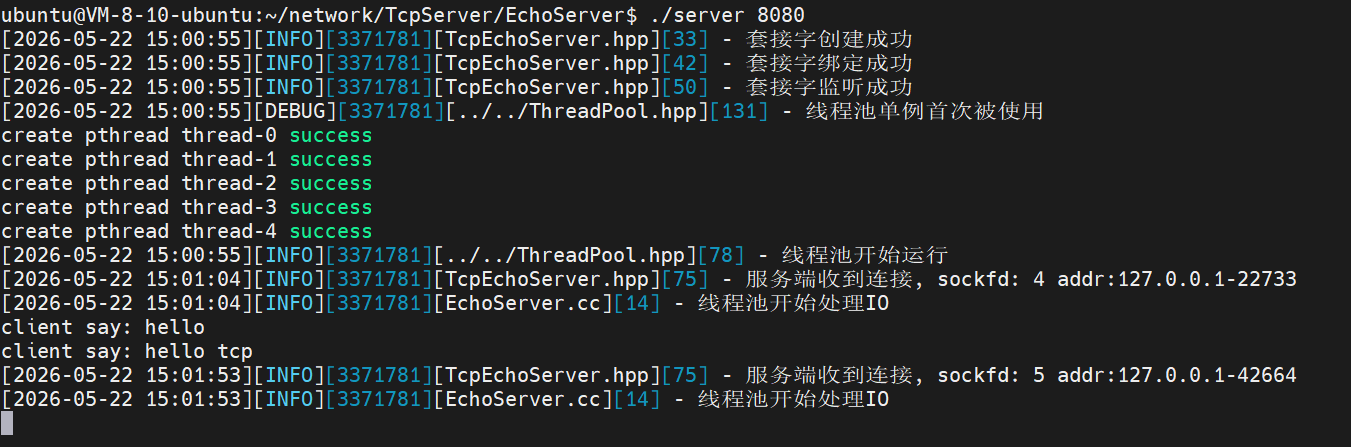
仔细观察可以发现,即便客户端 1(fd: 4)连入后死死占着通道不发数据,主线程也完全没有被卡死。它迅速把 fd: 4 抛给了线程池里的工作线程 A,并在下一秒瞬间回到 accept 处,成功捕获了随后赶来的客户端 2(fd: 5),并将其抛给工作线程 B 独立服务
两个客户端在不同的工作线程私有栈中并发、同时运行。这就证明我们构建的 「基于内核连接队列 + 线程池异步长连接托管」 架构,完美实现了 TCP 协议下的高并发回显业务
总结
综上所述,从 socket、bind、listen 到 accept,再到 recv 与 send,我们已经正式完成了 TCP Socket 编程的入门,并真正实现了第一个基于 TCP 的 EchoServer
相比 UDP,TCP 最大的特点不再只是收发数据,而是连接管理
服务端通过 listen 建立监听队列,再通过 accept 从内核中获取一个已经建立好的连接,而后续真正负责通信的,也不再是监听 socket,而是 accept 返回的新连接 socket。也正因如此,TCP 编程相比 UDP,会多出一整套连接建立与连接维护机制
与此同时,通过线程池对连接任务进行并发处理,我们也进一步体会到了现代服务器程序的基本运行模型:
accept 连接
→ 分发任务
→ worker 线程处理 IO
而这其实已经非常接近真实服务器程序的核心结构
至此,我们已经完成了 TCP 基础通信阶段的学习。但目前我们的 EchoServer 仍然只能完成 "原样返回" 这种简单逻辑,还无法真正执行复杂业务
在下一篇中,我们将继续基于 TCP,实现一个能够远程执行命令并返回结果的 CommandServer,进一步理解:网络通信 + 业务处理是如何真正结合起来构成一个完整网络服务的
