前面几篇文章,我已经阐述了网络抖动对性能影响的重要性,各种有关抖动指标最终都映射到一个概念,长尾延时。
最近几年来,有太多自研的网络端到端传输协议或算法声称能降低长尾延时,我觉得名不副实,因为长尾不是协议或算法的特征,而是固有流量特征的必然结果。
在 网络的统计本质 中我提到了流量的重尾分布,本文就不再赘述它的原理,接着重尾往后说。
长尾实际上就是数学上的重尾分布在工程实践上的体现,重尾是概率分布的性质,而长尾是这类分布造成的数据性能现象的俗称,长尾效应主要体现在:
- 少数的极端事件对 P99\text{P99}P99 性能造成重大影响;
或者还可以这样讲:
- 中位数和均值差异巨大;
有点幂律的意思,其实互联网流量的帕累托分布本身就是幂律:
P(X≥x)∝x−α,α>0P(X\ge x)\propto x^{-\alpha},\quad \alpha\gt0P(X≥x)∝x−α,α>0
画图可看,这种分布的尾巴相对厚,衰减慢,这意味着虽然尾巴少见,但影响巨大,工程上被编程的人抱怨的 P99 太高,长尾高,就重尾特性在网络延迟上的表现:
- 只要少量巨慢的流,就严重影响了均值等百分位指标,而这种少量巨慢流虽少见但也频繁;
为优化长尾延时,首先要了解重尾的成因。为什么网络流量呈现重尾。
因为人的行为,网络内容大小,网络传输不是无记忆的独立事件,而是有强异质性,依赖相关性,大文件,热点访问,会话相关性,这些经聚合后自然产生幂律,重尾分布,而不是独立无记忆事件指数间隔的泊松分布。
不过一说到人的行为,社会学,统计学相关的,编程的人就不乐意了,工科生鄙视为民科。但很遗憾,没人能控制流量的重尾特征,也就无法控制长尾时延,网络的本质就是统计的。
谈到幂律,重尾,从复杂网络理论中的优先连接可以自然导出幂律公式,这里不赘述,只看到优先连接本身就是依赖相关性的一种就够了。
优先连接解释了富者愈富的累积优势,幂律正是这种正反馈的系统自组织的非线性作用的结果,而网络流量的行为是这种结果的一个实例,比如:
- 网络中存在少数巨大对象,海量小对象,而 TCP 把对象大小线性映射成字节数,并受路由,瓶颈带宽,拥塞控制等因素影响,将字节数非线性映射到不确定流持续时间;
这就是长尾的成因。而我在 网络的统计本质 中将帕累托重尾和自相似一起说,意思就是重尾分布是自相似性的生成机制,一个数学上的结果就是尺度不变性。
尺度不变性意味着消除长尾是不可能,因为在一个随机变量相互依赖的自相似世界,这就是一条放之四海而皆准的铁律,抛开网络传输,看看我们的社会,马太效应是《圣经》里说的,上帝的旨意,就算排除那些极端的对象,剩下的群体还是完全一样的分布。
重点就是相互依赖,偏好依附!
现在定量看,幂律,重尾分布的特性,以帕累托分布分析,其概率密度函数为:
f(x)=αxmαxα+1,x≥xmf(x)=\dfrac{\alpha x_m^\alpha}{x^{\alpha+1}},\quad x\ge x_mf(x)=xα+1αxmα,x≥xm
其中 xm>0x_m>0xm>0 是最小值, α>0\alpha\gt0α>0 是幂律指数,其尾概率为:
P(X>0)∝x−(α−1)P(X\gt 0)\propto x^{-(\alpha-1)}P(X>0)∝x−(α−1)
再看均值和方差:
EX=αxmα−1\text{E}X=\dfrac{\alpha x_m}{\alpha-1}EX=α−1αxm
Var(X)=αxm2(α−1)2(α−2)\text{Var}(X)=\dfrac{\alpha x_m^2}{(\alpha-1)^2(\alpha-2)}Var(X)=(α−1)2(α−2)αxm2
恐怖之处在于,当 1<α≤21\lt\alpha\le 21<α≤2,虽均值有限但方差发散到无穷大,中心极限定理不再适用,样本均值的波动不会随样本量增大而减小,当 α≤1\alpha\le 1α≤1,均值和方差均发散,大数定律也失效,这会造成抖动失控到崩溃。
所以网络中必须引入复杂的机制应对这种常规非线性效应,这就是网络中心复杂性的依据和根源。网络中心并非理想模型那样瘦。而所有应对措施只是将系统状态拉回有限状态,收敛到稳态,而非消除非线性的重尾。
必须要区分的是重尾分布和指数分布。
一提到指数分布,与重尾相似,同样会想到极小的概率出现影响极大的事件,但指数提示 xxx 作为幂出现,其概率密度函数为:
f(x)=λe−λx,x≥0f(x)=\lambda e^{-\lambda x},\quad x\ge0f(x)=λe−λx,x≥0
其中 λ>0\lambda\gt0λ>0 是速率参数,表示单位时间内事件发生的平均次数,其尾概率为:
P(X>x)=e−λxP(X\gt x)=e^{-\lambda x}P(X>x)=e−λx
这是所有人都非常熟悉的指数分布:
EX=ρ=Var(X)=1λ\text{E}X=\rho=\sqrt{\text{Var}(X)}=\dfrac{1}{\lambda}EX=ρ=Var(X) =λ1
和幂律,重尾不同,指数分布的尾部衰减极快,指数级衰减,极端大值几乎不可能出现,均值和方差非常稳定。对比图像能一眼看出:
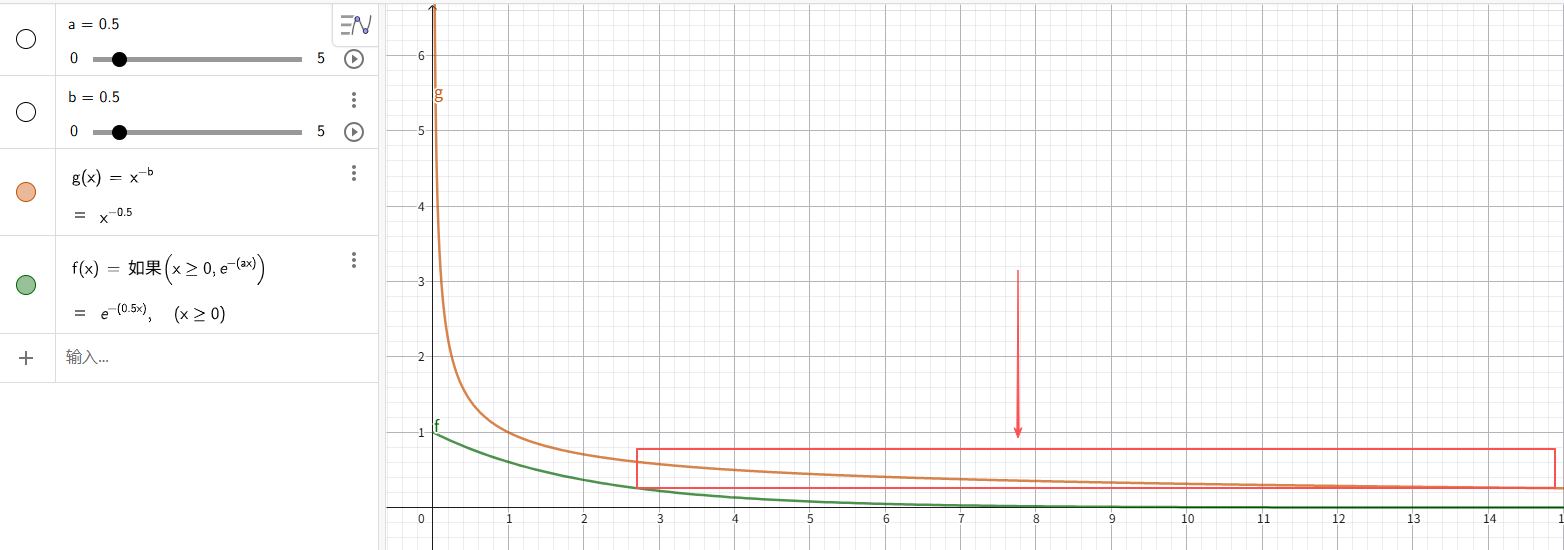
虽然在重尾分布和指数分布中,极端大值的概率都很低,但指数分布的极端值对均值和方差不产生影响,可忽略,而在重尾分布中,极端值则会产生巨大影响,不可忽略。
这种不同的背后来自它们各自的成因,和重尾成因来自异质,乘性的偏好依附不同,指数的成因则相反,它来自独立,无记忆的事件,无相互依赖,无历史依赖,非常理想的个体独立环境。
一个非负随机变量 TTT 是无记忆的,当且仅当:
P(T>t+s∣T>t)=P(T>s),∀t,s≥0P(T\gt t+s∣T\gt t)=P(T\gt s),\quad \forall t,s\ge0P(T>t+s∣T>t)=P(T>s),∀t,s≥0
意思是,已经等了 ttt 时间,并不会改变接下来还要等多久的分布,而这显然是与扎堆依赖的网络流量模式相悖,以它为基础的排队论对网络的建模类似伽利略的光滑平面,仅描述基底,而不是描述现实。
而正态分布来自中心极限定理,描述任意分布的总和,平均值的特征。如果总和,平均值都打摆子失控了,正态分布就无法描述了,因此对于发散的重尾分布,中心极限定理,大数定律就均失效了,而对于指数分布的均值,方差确定,和正态分布一起建模网络就是最理想的。
现在我们知道了网络的长尾延时来自流量的重尾分布,而流量的重尾分布又来自世界的固有行为,下载文件,热点新闻,赛事,重大事件播报,节假日周期等,这些均无法改变,因此重尾是固有的。
我早先提到过基于这些固有行为来做资源分配:
- 夜间,工作日下午,早晚高峰,周末执行不同拥塞控制;
- 工作日为不同人在不同的固定时间切换 WiFi 和蜂窝网络;
- 学习用户偏好信息,定制不同热点和赛事分配资源给个人;
- 为固定时间,路线的移动终端基于位置信息切换网络策略;
- ...
看似随机的世界并不随机,在各个尺度都有规律可循,如果获取到某人每天买两包烟的信息,那么为他提高肺病大病险保费大概率就是合理的,编程的人喜欢抬杠小概率事件也会发生,比如这人将买到的烟出门就丢掉,但统计学并不在乎这种抬杠。
正确的思路不是抬杠大概率事件有多大可能不发生,而是不管概率如何,在掌握了一定规律下,赌黑天鹅事件一定发生,然后事前调度资源,做好应对。
事实上针对双 11,12306 的资源分配已经在以年为尺度的周期上这么做了,流量本身就自相似,在更细粒度的尺度显然也可以。
这种方法的本质就是抓住重尾的成因特征,利用它们顺势而为,思路非常简洁明快。如果能相对准确预测会有大象流发生,提前为它分配资源就是显然之举。
成亿万级的参数生成一个神经网络,训练它让它学习流量生成的模式和统计规律,以此为依据为流量分配资源,理论上定能成,但内容的传输并非目标和终点,内容的理解才是,基于大模型的传输优化收益相对成本不大,正如几千年的道路并未多少进化一样,网络总之还是瘦的,堵就堵吧。
另一种方法是按照流持续时间对流量分类,我倾向于在发送端而不是转发节点进行分类,因为发送端几乎可以确定流的持续时间,这个想法我在 在数据中心网络中隔离大象流 中提到过。
至于消除流量依赖,绝无可能,在网络上没有任何一条流是独立的。
如果再听到谁家出了个不依赖外部数据的协议或算法可以降低甚至消除长尾延时,100% 的谎言,100% 的欺骗,有一个算一个,这些只是卷绩效,忽悠无知经理的伎俩。
浙江温州皮鞋湿,下雨进水不会胖。